 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Assessing the quality of information extraction
Apr 05, 2024
Advances in large language models have notably enhanced the efficiency of information extraction from unstructured and semi-structured data sources. As these technologies become integral to various applications, establishing an objective measure for the quality of information extraction becomes imperative. However, the scarcity of labeled data presents significant challenges to this endeavor. In this paper, we introduce an automatic framework to assess the quality of the information extraction and its completeness. The framework focuses on information extraction in the form of entity and its properties. We discuss how to handle the input/output size limitations of the large language models and analyze their performance when iteratively extracting the information. Finally, we introduce metrics to evaluate the quality of the extraction and provide an extensive discussion on how to interpret the metrics.
Span-Oriented Information Extraction -- A Unifying Perspective on Information Extraction
Mar 18, 2024Information Extraction refers to a collection of tasks within Natural Language Processing (NLP) that identifies sub-sequences within text and their labels. These tasks have been used for many years to link extract relevant information and to link free text to structured data. However, the heterogeneity among information extraction tasks impedes progress in this area. We therefore offer a unifying perspective centered on what we define to be spans in text. We then re-orient these seemingly incongruous tasks into this unified perspective and then re-present the wide assortment of information extraction tasks as variants of the same basic Span-Oriented Information Extraction task.
Leveraging Data Augmentation for Process Information Extraction
Apr 11, 2024Business Process Modeling projects often require formal process models as a central component. High costs associated with the creation of such formal process models motivated many different fields of research aimed at automated generation of process models from readily available data. These include process mining on event logs, and generating business process models from natural language texts. Research in the latter field is regularly faced with the problem of limited data availability, hindering both evaluation and development of new techniques, especially learning-based ones. To overcome this data scarcity issue, in this paper we investigate the application of data augmentation for natural language text data. Data augmentation methods are well established in machine learning for creating new, synthetic data without human assistance. We find that many of these methods are applicable to the task of business process information extraction, improving the accuracy of extraction. Our study shows, that data augmentation is an important component in enabling machine learning methods for the task of business process model generation from natural language text, where currently mostly rule-based systems are still state of the art. Simple data augmentation techniques improved the $F_1$ score of mention extraction by 2.9 percentage points, and the $F_1$ of relation extraction by $4.5$. To better understand how data augmentation alters human annotated texts, we analyze the resulting text, visualizing and discussing the properties of augmented textual data. We make all code and experiments results publicly available.
RealKIE: Five Novel Datasets for Enterprise Key Information Extraction
Mar 29, 2024
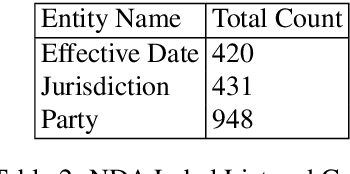
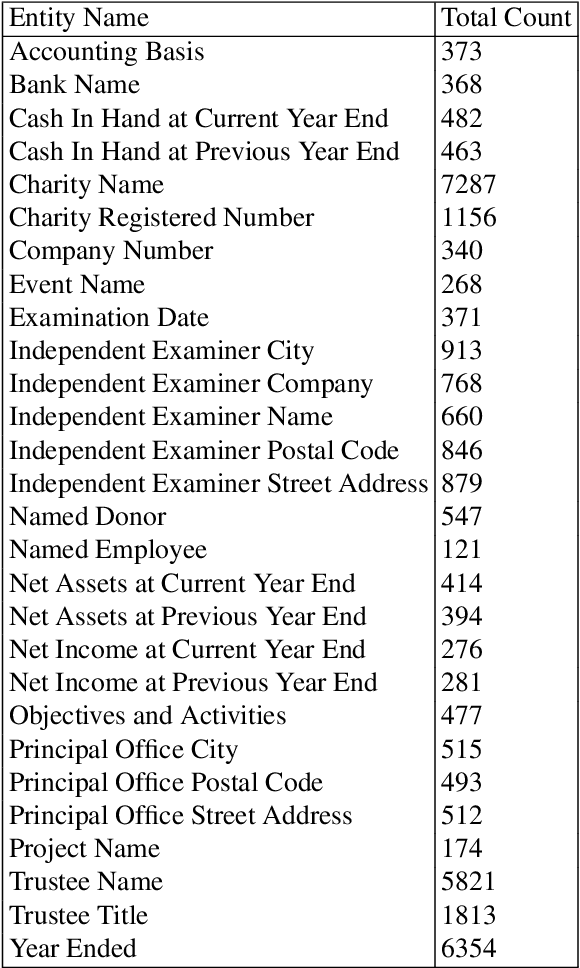
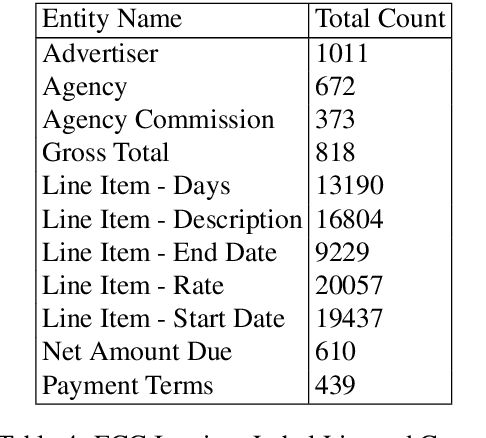
We introduce RealKIE, a benchmark of five challenging datasets aimed at advancing key information extraction methods, with an emphasis on enterprise applications. The datasets include a diverse range of documents including SEC S1 Filings, US Non-disclosure Agreements, UK Charity Reports, FCC Invoices, and Resource Contracts. Each presents unique challenges: poor text serialization, sparse annotations in long documents, and complex tabular layouts. These datasets provide a realistic testing ground for key information extraction tasks like investment analysis and legal data processing. In addition to presenting these datasets, we offer an in-depth description of the annotation process, document processing techniques, and baseline modeling approaches. This contribution facilitates the development of NLP models capable of handling practical challenges and supports further research into information extraction technologies applicable to industry-specific problems. The annotated data and OCR outputs are available to download at https://indicodatasolutions.github.io/RealKIE/ code to reproduce the baselines will be available shortly.
OpenChemIE: An Information Extraction Toolkit For Chemistry Literature
Apr 01, 2024Information extraction from chemistry literature is vital for constructing up-to-date reaction databases for data-driven chemistry. Complete extraction requires combining information across text, tables, and figures, whereas prior work has mainly investigated extracting reactions from single modalities. In this paper, we present OpenChemIE to address this complex challenge and enable the extraction of reaction data at the document level. OpenChemIE approaches the problem in two steps: extracting relevant information from individual modalities and then integrating the results to obtain a final list of reactions. For the first step, we employ specialized neural models that each address a specific task for chemistry information extraction, such as parsing molecules or reactions from text or figures. We then integrate the information from these modules using chemistry-informed algorithms, allowing for the extraction of fine-grained reaction data from reaction condition and substrate scope investigations. Our machine learning models attain state-of-the-art performance when evaluated individually, and we meticulously annotate a challenging dataset of reaction schemes with R-groups to evaluate our pipeline as a whole, achieving an F1 score of 69.5%. Additionally, the reaction extraction results of \ours attain an accuracy score of 64.3% when directly compared against the Reaxys chemical database. We provide OpenChemIE freely to the public as an open-source package, as well as through a web interface.
Evaluating Generative Language Models in Information Extraction as Subjective Question Correction
Apr 04, 2024Modern Large Language Models (LLMs) have showcased remarkable prowess in various tasks necessitating sophisticated cognitive behaviors. Nevertheless, a paradoxical performance discrepancy is observed, where these models underperform in seemingly elementary tasks like relation extraction and event extraction due to two issues in conventional evaluation. (1) The imprecision of existing evaluation metrics that struggle to effectively gauge semantic consistency between model outputs and ground truth, and (2) The inherent incompleteness of evaluation benchmarks, primarily due to restrictive human annotation schemas, resulting in underestimated LLM performances. Inspired by the principles in subjective question correction, we propose a new evaluation method, SQC-Score. This method innovatively utilizes LLMs, fine-tuned through subjective question correction data, to refine matching between model outputs and golden labels. Additionally, by incorporating a Natural Language Inference (NLI) model, SQC-Score enriches golden labels, addressing benchmark incompleteness by acknowledging correct yet previously omitted answers. Results on three information extraction tasks show that SQC-Score is more preferred by human annotators than the baseline metrics. Utilizing SQC-Score, we conduct a comprehensive evaluation of the state-of-the-art LLMs and provide insights for future research for information extraction. Dataset and associated codes can be accessed at https://github.com/THU-KEG/SQC-Score.
How much reliable is ChatGPT's prediction on Information Extraction under Input Perturbations?
Apr 07, 2024In this paper, we assess the robustness (reliability) of ChatGPT under input perturbations for one of the most fundamental tasks of Information Extraction (IE) i.e. Named Entity Recognition (NER). Despite the hype, the majority of the researchers have vouched for its language understanding and generation capabilities; a little attention has been paid to understand its robustness: How the input-perturbations affect 1) the predictions, 2) the confidence of predictions and 3) the quality of rationale behind its prediction. We perform a systematic analysis of ChatGPT's robustness (under both zero-shot and few-shot setup) on two NER datasets using both automatic and human evaluation. Based on automatic evaluation metrics, we find that 1) ChatGPT is more brittle on Drug or Disease replacements (rare entities) compared to the perturbations on widely known Person or Location entities, 2) the quality of explanations for the same entity considerably differ under different types of "Entity-Specific" and "Context-Specific" perturbations and the quality can be significantly improved using in-context learning, and 3) it is overconfident for majority of the incorrect predictions, and hence it could lead to misguidance of the end-users.
BuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.
Is There a One-Model-Fits-All Approach to Information Extraction? Revisiting Task Definition Biases
Mar 25, 2024Definition bias is a negative phenomenon that can mislead models. Definition bias in information extraction appears not only across datasets from different domains but also within datasets sharing the same domain. We identify two types of definition bias in IE: bias among information extraction datasets and bias between information extraction datasets and instruction tuning datasets. To systematically investigate definition bias, we conduct three probing experiments to quantitatively analyze it and discover the limitations of unified information extraction and large language models in solving definition bias. To mitigate definition bias in information extraction, we propose a multi-stage framework consisting of definition bias measurement, bias-aware fine-tuning, and task-specific bias mitigation. Experimental results demonstrate the effectiveness of our framework in addressing definition bias. Resources of this paper can be found at https://github.com/EZ-hwh/definition-bias
Automatic Information Extraction From Employment Tribunal Judgements Using Large Language Models
Mar 19, 2024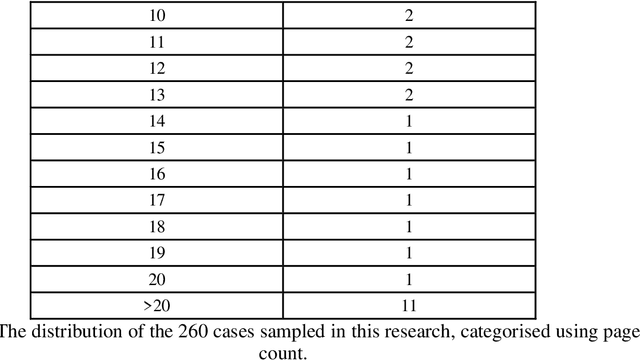
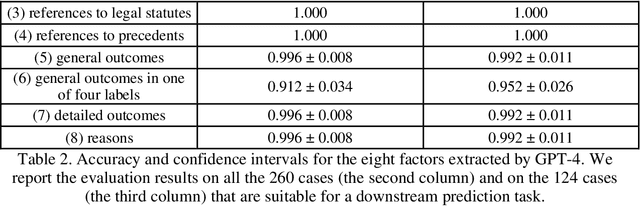
Court transcripts and judgments are rich repositories of legal knowledge, detailing the intricacies of cases and the rationale behind judicial decisions. The extraction of key information from these documents provides a concise overview of a case, crucial for both legal experts and the public. With the advent of large language models (LLMs), automatic information extraction has become increasingly feasible and efficient. This paper presents a comprehensive study on the application of GPT-4, a large language model, for automatic information extraction from UK Employment Tribunal (UKET) cases. We meticulously evaluated GPT-4's performance in extracting critical information with a manual verification process to ensure the accuracy and relevance of the extracted data. Our research is structured around two primary extraction tasks: the first involves a general extraction of eight key aspects that hold significance for both legal specialists and the general public, including the facts of the case, the claims made, references to legal statutes, references to precedents, general case outcomes and corresponding labels, detailed order and remedies and reasons for the decision. The second task is more focused, aimed at analysing three of those extracted features, namely facts, claims and outcomes, in order to facilitate the development of a tool capable of predicting the outcome of employment law disputes. Through our analysis, we demonstrate that LLMs like GPT-4 can obtain high accuracy in legal information extraction, highlighting the potential of LLMs in revolutionising the way legal information is processed and utilised, offering significant implications for legal research and practice.