 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Transformers for Wireless Communications: A Case Study in Beam Prediction
Sep 21, 2023
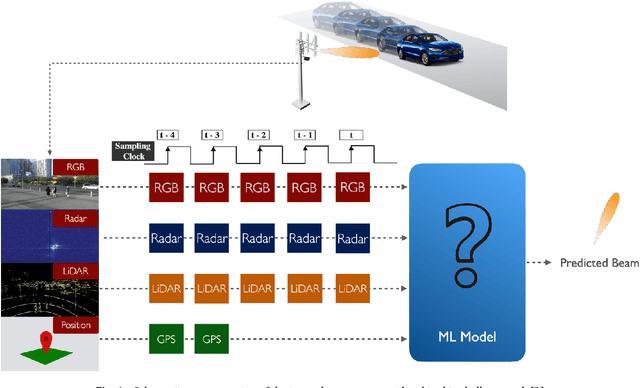
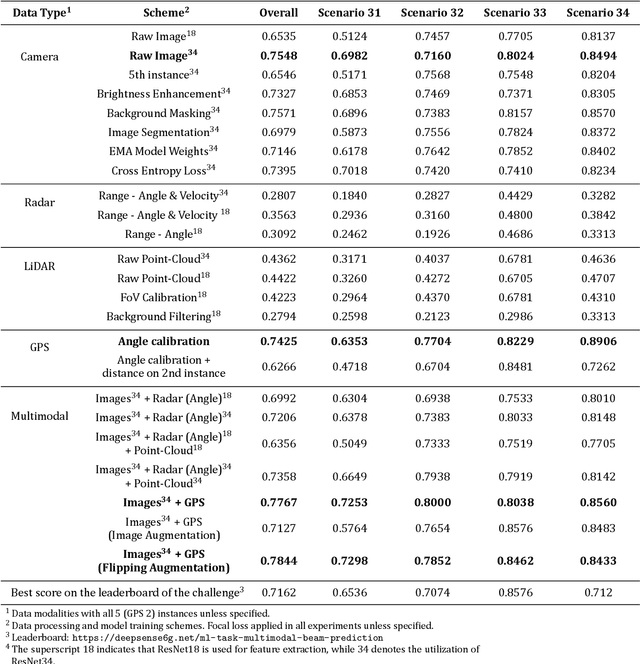
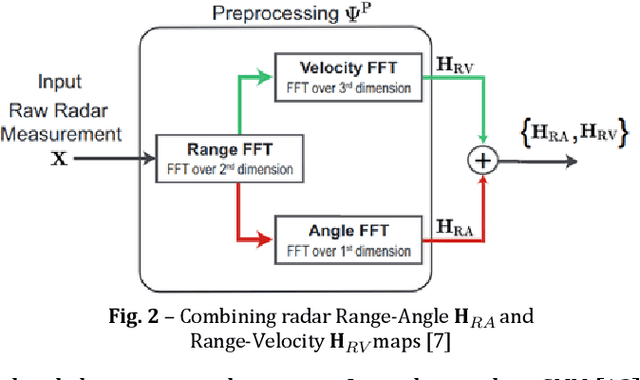
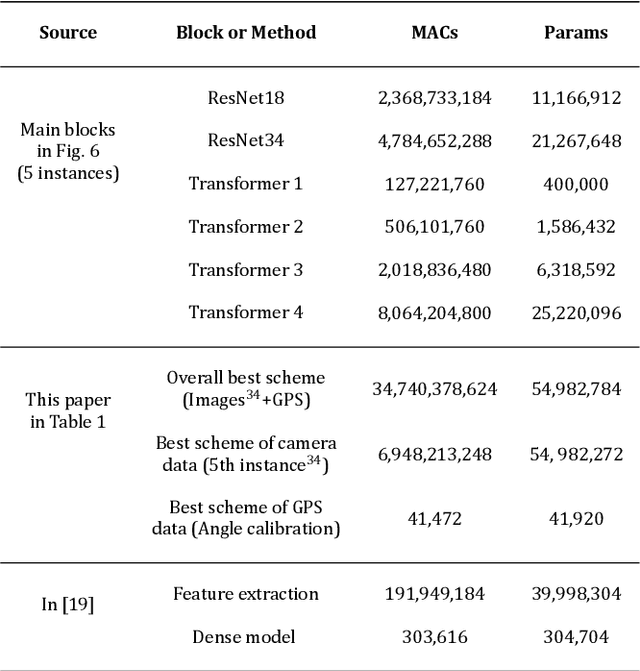
Wireless communications at high-frequency bands with large antenna arrays face challenges in beam management, which can potentially be improved by multimodality sensing information from cameras, LiDAR, radar, and GPS. In this paper, we present a multimodal transformer deep learning framework for sensing-assisted beam prediction. We employ a convolutional neural network to extract the features from a sequence of images, point clouds, and radar raw data sampled over time. At each convolutional layer, we use transformer encoders to learn the hidden relations between feature tokens from different modalities and time instances over abstraction space and produce encoded vectors for the next-level feature extraction. We train the model on a combination of different modalities with supervised learning. We try to enhance the model over imbalanced data by utilizing focal loss and exponential moving average. We also evaluate data processing and augmentation techniques such as image enhancement, segmentation, background filtering, multimodal data flipping, radar signal transformation, and GPS angle calibration. Experimental results show that our solution trained on image and GPS data produces the best distance-based accuracy of predicted beams at 78.44%, with effective generalization to unseen day scenarios near 73% and night scenarios over 84%. This outperforms using other modalities and arbitrary data processing techniques, which demonstrates the effectiveness of transformers with feature fusion in performing radio beam prediction from images and GPS. Furthermore, our solution could be pretrained from large sequences of multimodality wireless data, on fine-tuning for multiple downstream radio network tasks.
Exploring Annotation-free Image Captioning with Retrieval-augmented Pseudo Sentence Generation
Jul 28, 2023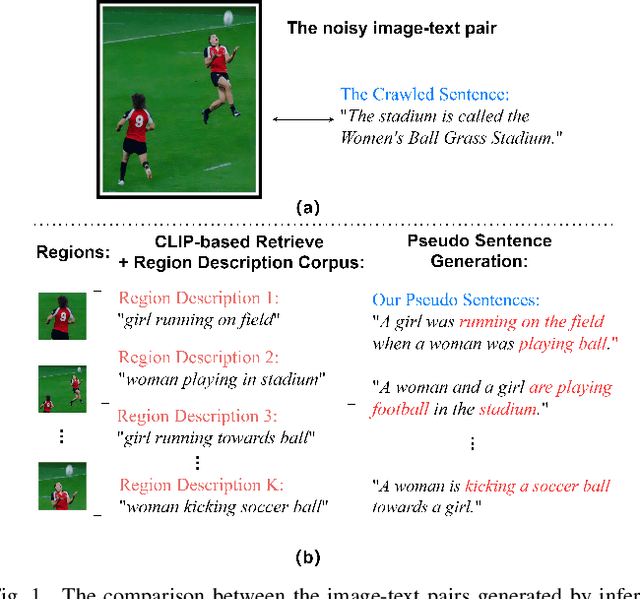
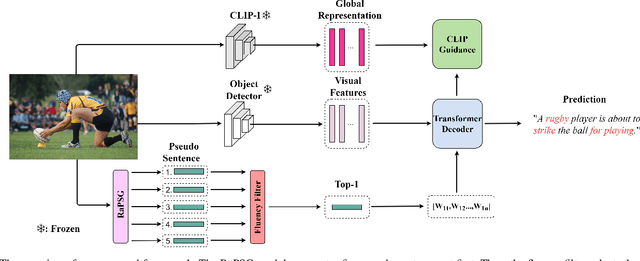
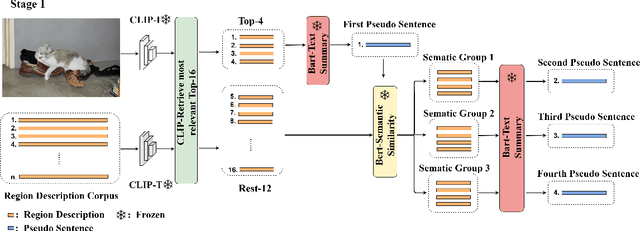
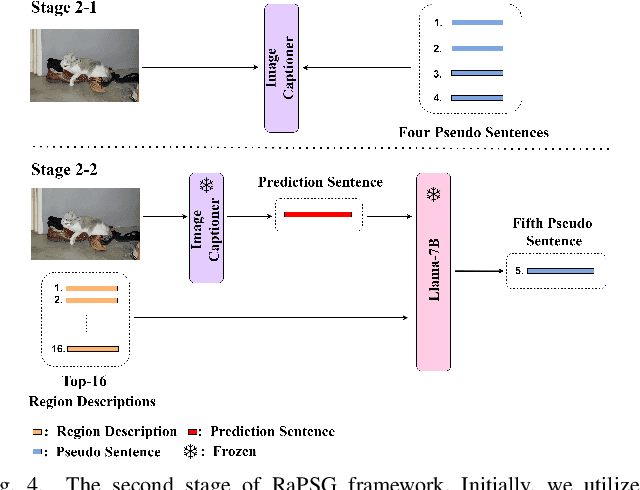
Training an image captioner without annotated image-sentence pairs has gained traction in recent years. Previous approaches can be categorized into two strategies: crawling sentences from mismatching corpora and aligning them with the given images as pseudo annotations, or pre-training the captioner using external image-text pairs. However, the aligning setting seems to reach its performance limit due to the quality problem of pairs, and pre-training requires significant computational resources. To address these challenges, we propose a new strategy ``LPM + retrieval-augmented learning" where the prior knowledge from large pre-trained models (LPMs) is leveraged as supervision, and a retrieval process is integrated to further reinforce its effectiveness. Specifically, we introduce Retrieval-augmented Pseudo Sentence Generation (RaPSG), which adopts an efficient approach to retrieve highly relevant short region descriptions from the mismatching corpora and use them to generate a variety of pseudo sentences with distinct representations as well as high quality via LPMs. In addition, a fluency filter and a CLIP-guided training objective are further introduced to facilitate model optimization. Experimental results demonstrate that our method surpasses the SOTA pre-training model (Flamingo3B) by achieving a CIDEr score of 78.1 (+5.1) while utilizing only 0.3% of its trainable parameters (1.3B VS 33M). Importantly, our approach eliminates the need of computationally expensive pre-training processes on external datasets (e.g., the requirement of 312M image-text pairs for Flamingo3B). We further show that with a simple extension, the generated pseudo sentences can be deployed as weak supervision to boost the 1% semi-supervised image caption benchmark up to 93.4 CIDEr score (+8.9) which showcases the versatility and effectiveness of our approach.
CMUNeXt: An Efficient Medical Image Segmentation Network based on Large Kernel and Skip Fusion
Aug 03, 2023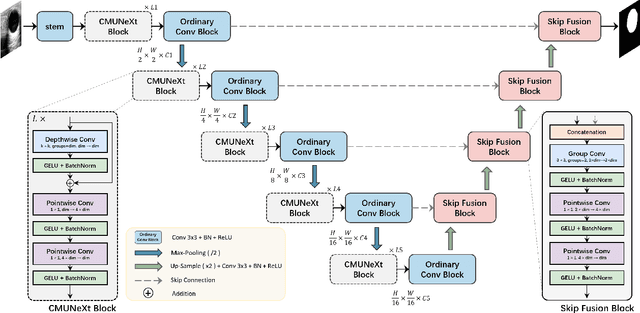
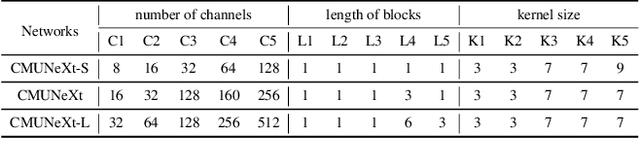
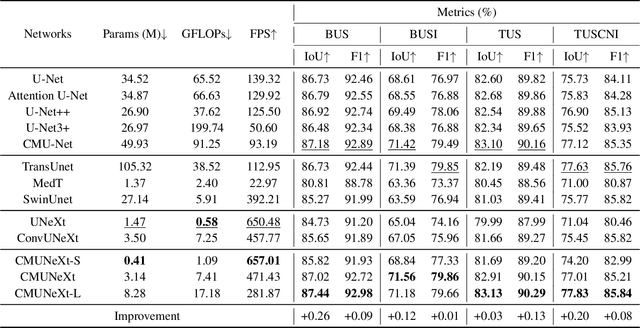
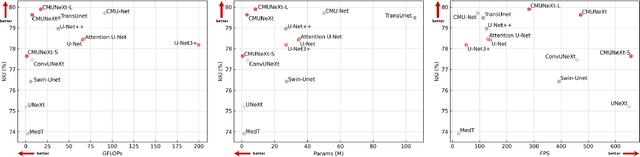
The U-shaped architecture has emerged as a crucial paradigm in the design of medical image segmentation networks. However, due to the inherent local limitations of convolution, a fully convolutional segmentation network with U-shaped architecture struggles to effectively extract global context information, which is vital for the precise localization of lesions. While hybrid architectures combining CNNs and Transformers can address these issues, their application in real medical scenarios is limited due to the computational resource constraints imposed by the environment and edge devices. In addition, the convolutional inductive bias in lightweight networks adeptly fits the scarce medical data, which is lacking in the Transformer based network. In order to extract global context information while taking advantage of the inductive bias, we propose CMUNeXt, an efficient fully convolutional lightweight medical image segmentation network, which enables fast and accurate auxiliary diagnosis in real scene scenarios. CMUNeXt leverages large kernel and inverted bottleneck design to thoroughly mix distant spatial and location information, efficiently extracting global context information. We also introduce the Skip-Fusion block, designed to enable smooth skip-connections and ensure ample feature fusion. Experimental results on multiple medical image datasets demonstrate that CMUNeXt outperforms existing heavyweight and lightweight medical image segmentation networks in terms of segmentation performance, while offering a faster inference speed, lighter weights, and a reduced computational cost. The code is available at https://github.com/FengheTan9/CMUNeXt.
NLCUnet: Single-Image Super-Resolution Network with Hairline Details
Jul 22, 2023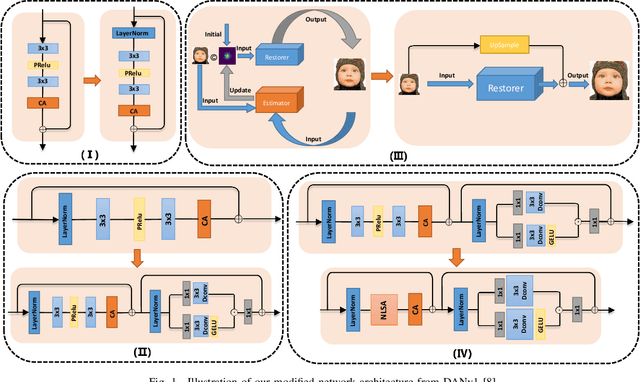
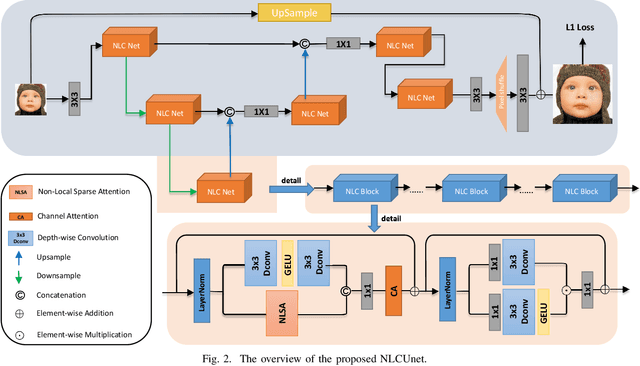


Pursuing the precise details of super-resolution images is challenging for single-image super-resolution tasks. This paper presents a single-image super-resolution network with hairline details (termed NLCUnet), including three core designs. Specifically, a non-local attention mechanism is first introduced to restore local pieces by learning from the whole image region. Then, we find that the blur kernel trained by the existing work is unnecessary. Based on this finding, we create a new network architecture by integrating depth-wise convolution with channel attention without the blur kernel estimation, resulting in a performance improvement instead. Finally, to make the cropped region contain as much semantic information as possible, we propose a random 64$\times$64 crop inside the central 512$\times$512 crop instead of a direct random crop inside the whole image of 2K size. Numerous experiments conducted on the benchmark DF2K dataset demonstrate that our NLCUnet performs better than the state-of-the-art in terms of the PSNR and SSIM metrics and yields visually favorable hairline details.
Semantic-Aware Image Compressed Sensing
Jul 11, 2023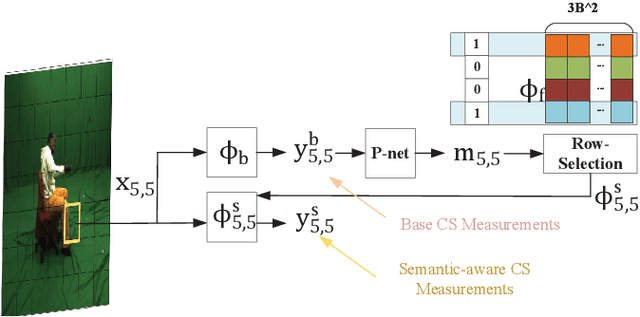
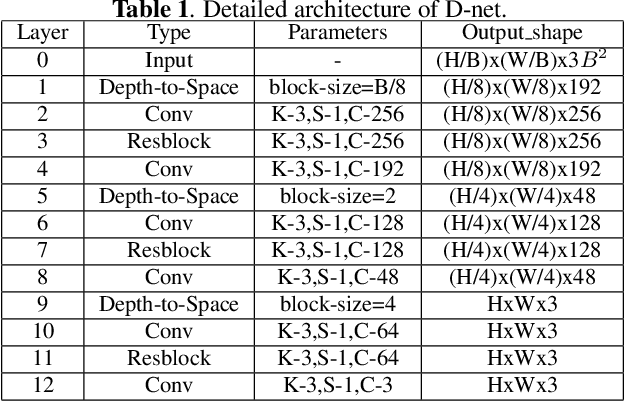
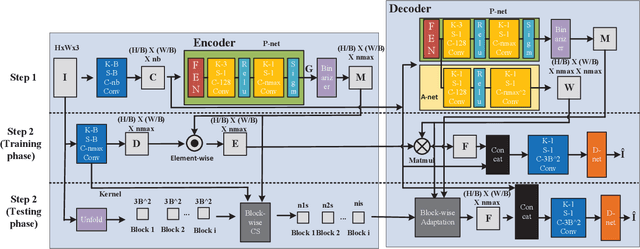
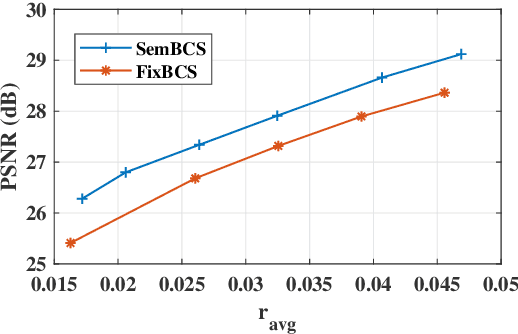
Deep learning based image compressed sensing (CS) has achieved great success. However, existing CS systems mainly adopt a fixed measurement matrix to images, ignoring the fact the optimal measurement numbers and bases are different for different images. To further improve the sensing efficiency, we propose a novel semantic-aware image CS system. In our system, the encoder first uses a fixed number of base CS measurements to sense different images. According to the base CS results, the encoder then employs a policy network to analyze the semantic information in images and determines the measurement matrix for different image areas. At the decoder side, a semantic-aware initial reconstruction network is developed to deal with the changes of measurement matrices used at the encoder. A rate-distortion training loss is further introduced to dynamically adjust the average compression ratio for the semantic-aware CS system and the policy network is trained jointly with the encoder and the decoder in an en-to-end manner by using some proxy functions. Numerical results show that the proposed semantic-aware image CS system is superior to the traditional ones with fixed measurement matrices.
Tell Me a Story! Narrative-Driven XAI with Large Language Models
Sep 29, 2023


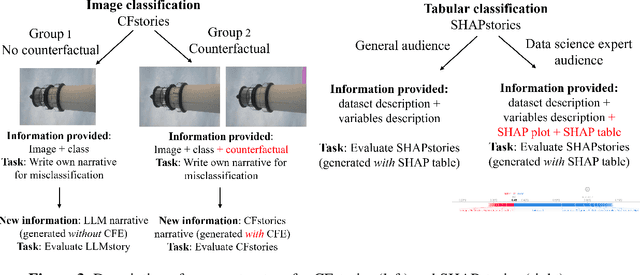
In today's critical domains, the predominance of black-box machine learning models amplifies the demand for Explainable AI (XAI). The widely used SHAP values, while quantifying feature importance, are often too intricate and lack human-friendly explanations. Furthermore, counterfactual (CF) explanations present `what ifs' but leave users grappling with the 'why'. To bridge this gap, we introduce XAIstories. Leveraging Large Language Models, XAIstories provide narratives that shed light on AI predictions: SHAPstories do so based on SHAP explanations to explain a prediction score, while CFstories do so for CF explanations to explain a decision. Our results are striking: over 90% of the surveyed general audience finds the narrative generated by SHAPstories convincing. Data scientists primarily see the value of SHAPstories in communicating explanations to a general audience, with 92% of data scientists indicating that it will contribute to the ease and confidence of nonspecialists in understanding AI predictions. Additionally, 83% of data scientists indicate they are likely to use SHAPstories for this purpose. In image classification, CFstories are considered more or equally convincing as users own crafted stories by over 75% of lay user participants. CFstories also bring a tenfold speed gain in creating a narrative, and improves accuracy by over 20% compared to manually created narratives. The results thereby suggest that XAIstories may provide the missing link in truly explaining and understanding AI predictions.
When Epipolar Constraint Meets Non-local Operators in Multi-View Stereo
Sep 29, 2023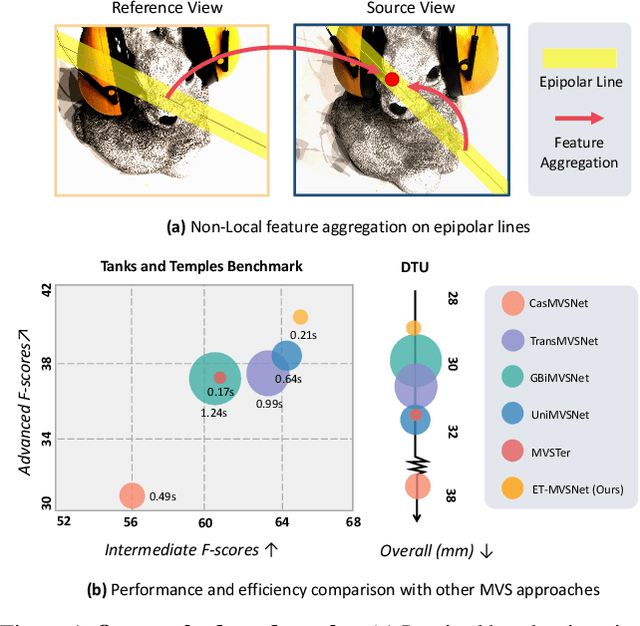
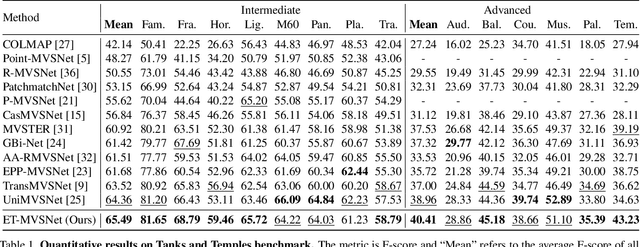
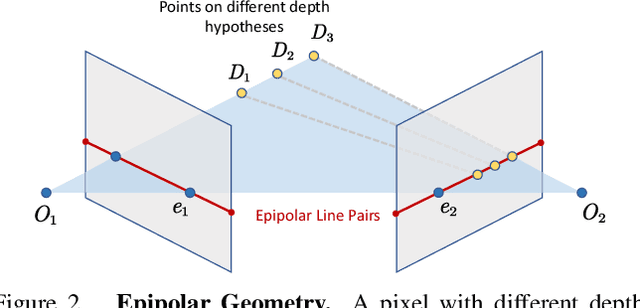
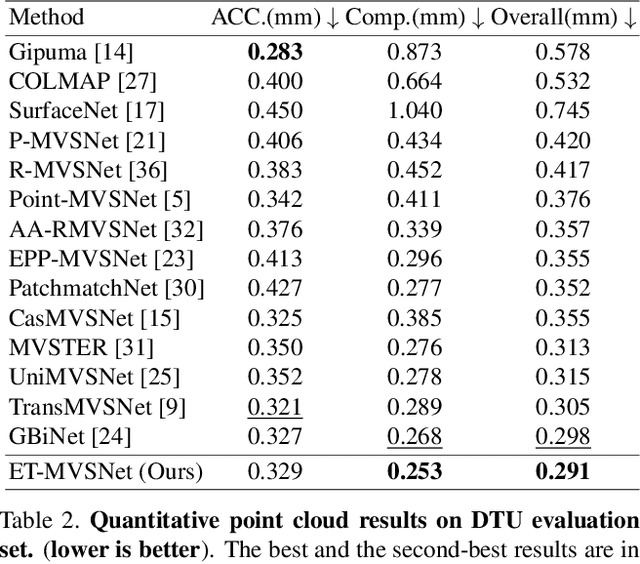
Learning-based multi-view stereo (MVS) method heavily relies on feature matching, which requires distinctive and descriptive representations. An effective solution is to apply non-local feature aggregation, e.g., Transformer. Albeit useful, these techniques introduce heavy computation overheads for MVS. Each pixel densely attends to the whole image. In contrast, we propose to constrain non-local feature augmentation within a pair of lines: each point only attends the corresponding pair of epipolar lines. Our idea takes inspiration from the classic epipolar geometry, which shows that one point with different depth hypotheses will be projected to the epipolar line on the other view. This constraint reduces the 2D search space into the epipolar line in stereo matching. Similarly, this suggests that the matching of MVS is to distinguish a series of points lying on the same line. Inspired by this point-to-line search, we devise a line-to-point non-local augmentation strategy. We first devise an optimized searching algorithm to split the 2D feature maps into epipolar line pairs. Then, an Epipolar Transformer (ET) performs non-local feature augmentation among epipolar line pairs. We incorporate the ET into a learning-based MVS baseline, named ET-MVSNet. ET-MVSNet achieves state-of-the-art reconstruction performance on both the DTU and Tanks-and-Temples benchmark with high efficiency. Code is available at https://github.com/TQTQliu/ET-MVSNet.
PartDiff: Image Super-resolution with Partial Diffusion Models
Jul 21, 2023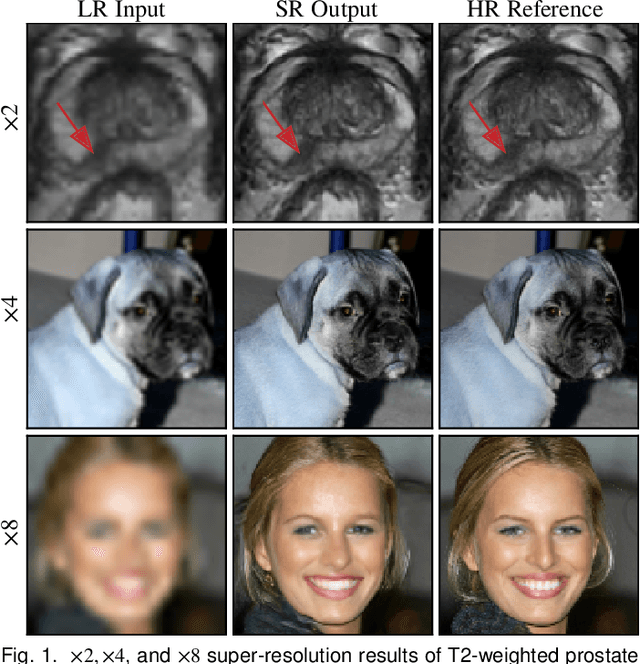
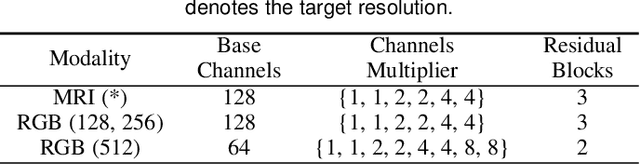

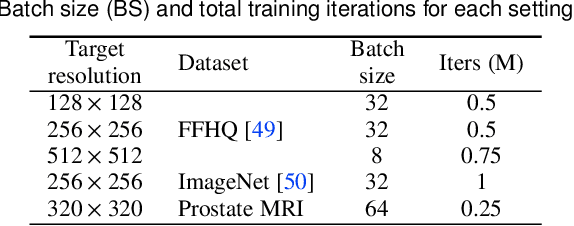
Denoising diffusion probabilistic models (DDPMs) have achieved impressive performance on various image generation tasks, including image super-resolution. By learning to reverse the process of gradually diffusing the data distribution into Gaussian noise, DDPMs generate new data by iteratively denoising from random noise. Despite their impressive performance, diffusion-based generative models suffer from high computational costs due to the large number of denoising steps.In this paper, we first observed that the intermediate latent states gradually converge and become indistinguishable when diffusing a pair of low- and high-resolution images. This observation inspired us to propose the Partial Diffusion Model (PartDiff), which diffuses the image to an intermediate latent state instead of pure random noise, where the intermediate latent state is approximated by the latent of diffusing the low-resolution image. During generation, Partial Diffusion Models start denoising from the intermediate distribution and perform only a part of the denoising steps. Additionally, to mitigate the error caused by the approximation, we introduce "latent alignment", which aligns the latent between low- and high-resolution images during training. Experiments on both magnetic resonance imaging (MRI) and natural images show that, compared to plain diffusion-based super-resolution methods, Partial Diffusion Models significantly reduce the number of denoising steps without sacrificing the quality of generation.
Dynamic Visual Prompt Tuning for Parameter Efficient Transfer Learning
Sep 12, 2023Parameter efficient transfer learning (PETL) is an emerging research spot that aims to adapt large-scale pre-trained models to downstream tasks. Recent advances have achieved great success in saving storage and computation costs. However, these methods do not take into account instance-specific visual clues for visual tasks. In this paper, we propose a Dynamic Visual Prompt Tuning framework (DVPT), which can generate a dynamic instance-wise token for each image. In this way, it can capture the unique visual feature of each image, which can be more suitable for downstream visual tasks. We designed a Meta-Net module that can generate learnable prompts based on each image, thereby capturing dynamic instance-wise visual features. Extensive experiments on a wide range of downstream recognition tasks show that DVPT achieves superior performance than other PETL methods. More importantly, DVPT even outperforms full fine-tuning on 17 out of 19 downstream tasks while maintaining high parameter efficiency. Our code will be released soon.
Towards High-Quality Specular Highlight Removal by Leveraging Large-Scale Synthetic Data
Sep 12, 2023
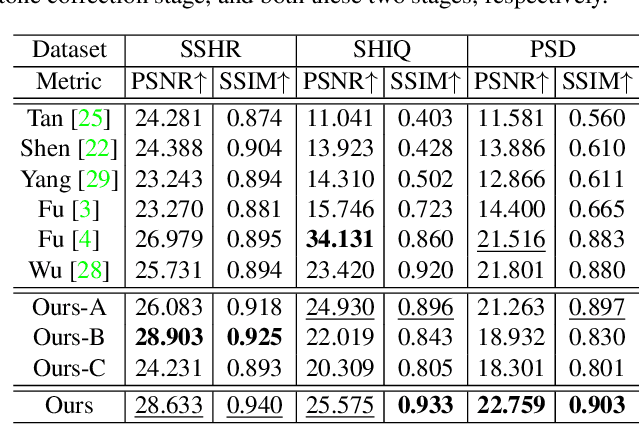
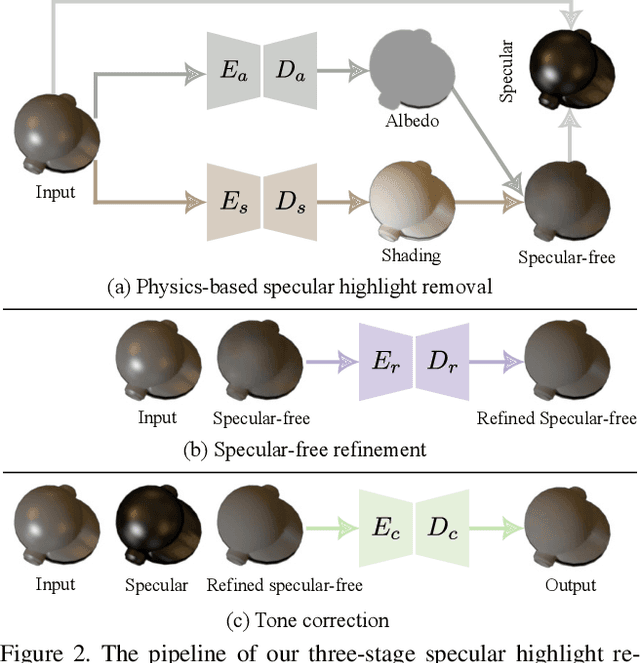

This paper aims to remove specular highlights from a single object-level image. Although previous methods have made some progresses, their performance remains somewhat limited, particularly for real images with complex specular highlights. To this end, we propose a three-stage network to address them. Specifically, given an input image, we first decompose it into the albedo, shading, and specular residue components to estimate a coarse specular-free image. Then, we further refine the coarse result to alleviate its visual artifacts such as color distortion. Finally, we adjust the tone of the refined result to match that of the input as closely as possible. In addition, to facilitate network training and quantitative evaluation, we present a large-scale synthetic dataset of object-level images, covering diverse objects and illumination conditions. Extensive experiments illustrate that our network is able to generalize well to unseen real object-level images, and even produce good results for scene-level images with multiple background objects and complex lighting.