 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
Sep 21, 2023
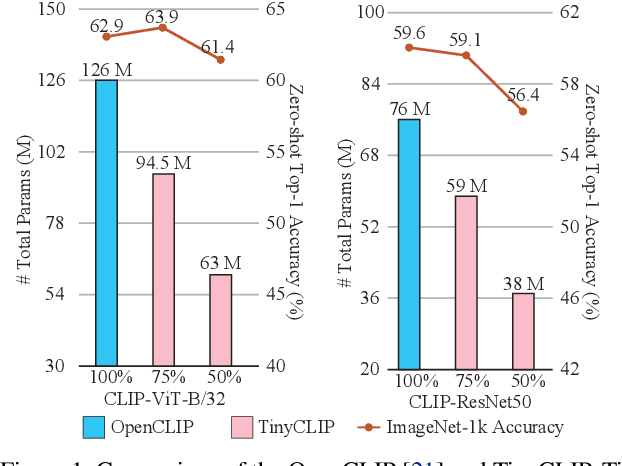
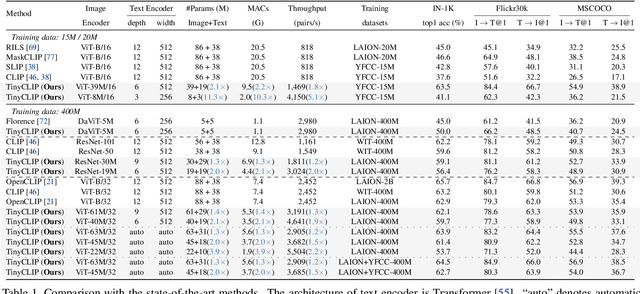
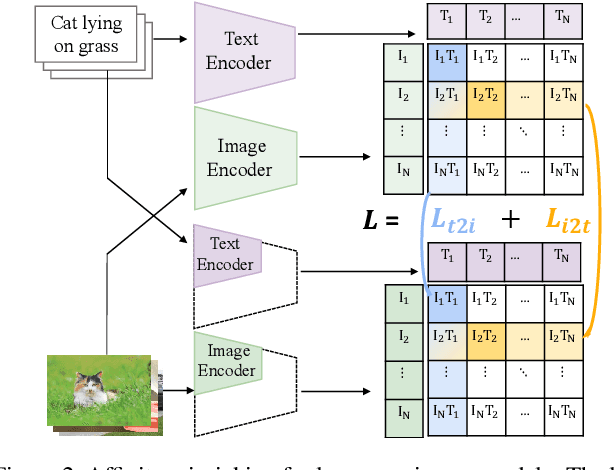

In this paper, we propose a novel cross-modal distillation method, called TinyCLIP, for large-scale language-image pre-trained models. The method introduces two core techniques: affinity mimicking and weight inheritance. Affinity mimicking explores the interaction between modalities during distillation, enabling student models to mimic teachers' behavior of learning cross-modal feature alignment in a visual-linguistic affinity space. Weight inheritance transmits the pre-trained weights from the teacher models to their student counterparts to improve distillation efficiency. Moreover, we extend the method into a multi-stage progressive distillation to mitigate the loss of informative weights during extreme compression. Comprehensive experiments demonstrate the efficacy of TinyCLIP, showing that it can reduce the size of the pre-trained CLIP ViT-B/32 by 50%, while maintaining comparable zero-shot performance. While aiming for comparable performance, distillation with weight inheritance can speed up the training by 1.4 - 7.8 $\times$ compared to training from scratch. Moreover, our TinyCLIP ViT-8M/16, trained on YFCC-15M, achieves an impressive zero-shot top-1 accuracy of 41.1% on ImageNet, surpassing the original CLIP ViT-B/16 by 3.5% while utilizing only 8.9% parameters. Finally, we demonstrate the good transferability of TinyCLIP in various downstream tasks. Code and models will be open-sourced at https://aka.ms/tinyclip.
Quasi-Monte Carlo for 3D Sliced Wasserstein
Sep 21, 2023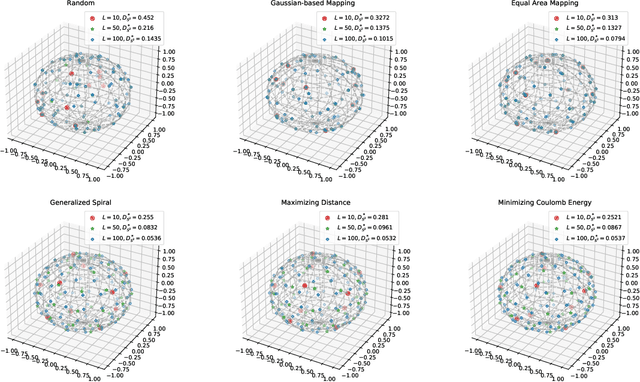
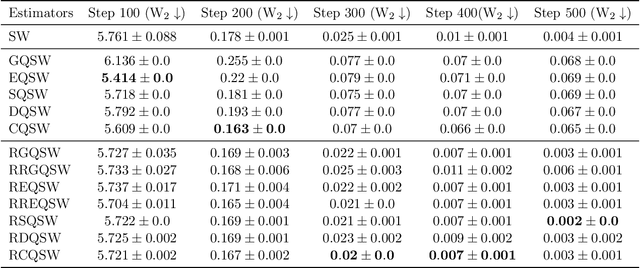
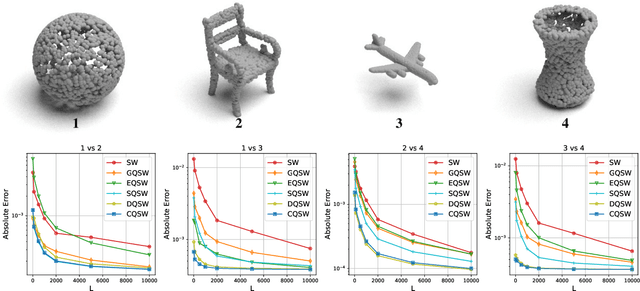
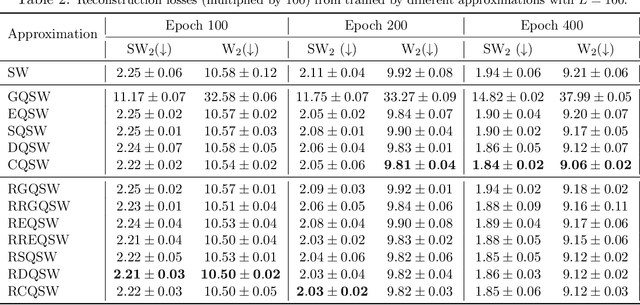
Monte Carlo (MC) approximation has been used as the standard computation approach for the Sliced Wasserstein (SW) distance, which has an intractable expectation in its analytical form. However, the MC method is not optimal in terms of minimizing the absolute approximation error. To provide a better class of empirical SW, we propose quasi-sliced Wasserstein (QSW) approximations that rely on Quasi-Monte Carlo (QMC) methods. For a comprehensive investigation of QMC for SW, we focus on the 3D setting, specifically computing the SW between probability measures in three dimensions. In greater detail, we empirically verify various ways of constructing QMC points sets on the 3D unit-hypersphere, including Gaussian-based mapping, equal area mapping, generalized spiral points, and optimizing discrepancy energies. Furthermore, to obtain an unbiased estimation for stochastic optimization, we extend QSW into Randomized Quasi-Sliced Wasserstein (RQSW) by introducing randomness to the discussed low-discrepancy sequences. For theoretical properties, we prove the asymptotic convergence of QSW and the unbiasedness of RQSW. Finally, we conduct experiments on various 3D tasks, such as point-cloud comparison, point-cloud interpolation, image style transfer, and training deep point-cloud autoencoders, to demonstrate the favorable performance of the proposed QSW and RQSW variants.
MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation
Sep 21, 2023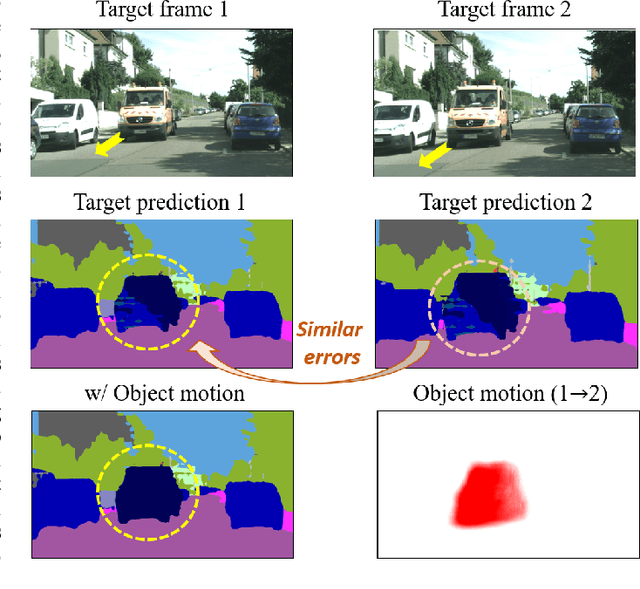
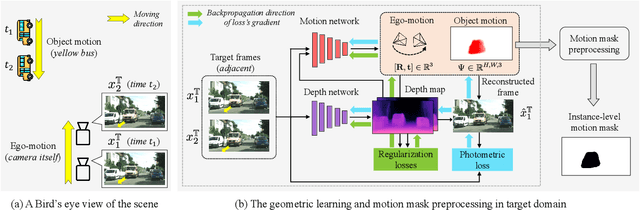
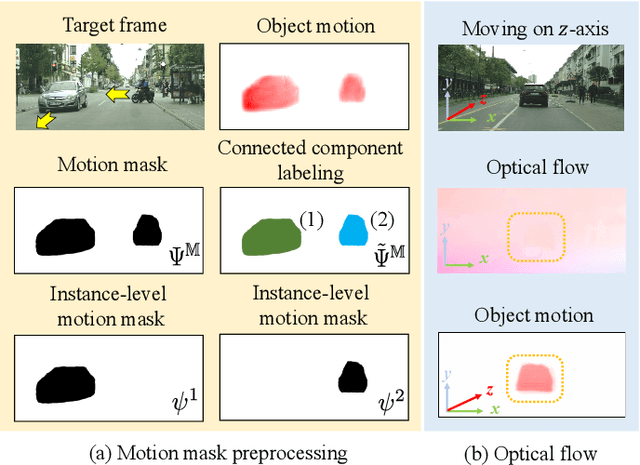
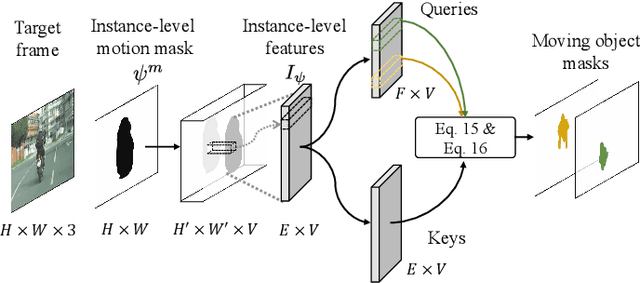
Unsupervised domain adaptation (UDA) is an effective approach to handle the lack of annotations in the target domain for the semantic segmentation task. In this work, we consider a more practical UDA setting where the target domain contains sequential frames of the unlabeled videos which are easy to collect in practice. A recent study suggests self-supervised learning of the object motion from unlabeled videos with geometric constraints. We design a motion-guided domain adaptive semantic segmentation framework (MoDA), that utilizes self-supervised object motion to learn effective representations in the target domain. MoDA differs from previous methods that use temporal consistency regularization for the target domain frames. Instead, MoDA deals separately with the domain alignment on the foreground and background categories using different strategies. Specifically, MoDA contains foreground object discovery and foreground semantic mining to align the foreground domain gaps by taking the instance-level guidance from the object motion. Additionally, MoDA includes background adversarial training which contains a background category-specific discriminator to handle the background domain gaps. Experimental results on multiple benchmarks highlight the effectiveness of MoDA against existing approaches in the domain adaptive image segmentation and domain adaptive video segmentation. Moreover, MoDA is versatile and can be used in conjunction with existing state-of-the-art approaches to further improve performance.
Crop Row Switching for Vision-Based Navigation: A Comprehensive Approach for Efficient Crop Field Navigation
Sep 21, 2023Vision-based mobile robot navigation systems in arable fields are mostly limited to in-row navigation. The process of switching from one crop row to the next in such systems is often aided by GNSS sensors or multiple camera setups. This paper presents a novel vision-based crop row-switching algorithm that enables a mobile robot to navigate an entire field of arable crops using a single front-mounted camera. The proposed row-switching manoeuvre uses deep learning-based RGB image segmentation and depth data to detect the end of the crop row, and re-entry point to the next crop row which would be used in a multi-state row switching pipeline. Each state of this pipeline use visual feedback or wheel odometry of the robot to successfully navigate towards the next crop row. The proposed crop row navigation pipeline was tested in a real sugar beet field containing crop rows with discontinuities, varying light levels, shadows and irregular headland surfaces. The robot could successfully exit from one crop row and re-enter the next crop row using the proposed pipeline with absolute median errors averaging at 19.25 cm and 6.77{\deg} for linear and rotational steps of the proposed manoeuvre.
Enhancing Bloodstain Analysis Through AI-Based Segmentation: Leveraging Segment Anything Model for Crime Scene Investigation
Aug 27, 2023
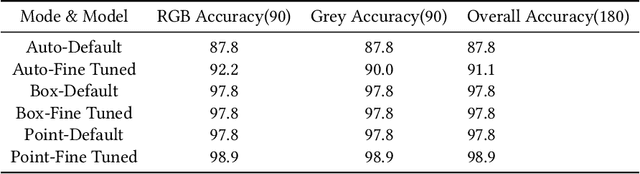


Bloodstain pattern analysis plays a crucial role in crime scene investigations by providing valuable information through the study of unique blood patterns. Conventional image analysis methods, like Thresholding and Contrast, impose stringent requirements on the image background and is labor-intensive in the context of droplet image segmentation. The Segment Anything Model (SAM), a recently proposed method for extensive image recognition, is yet to be adequately assessed for its accuracy and efficiency on bloodstain image segmentation. This paper explores the application of pre-trained SAM and fine-tuned SAM on bloodstain image segmentation with diverse image backgrounds. Experiment results indicate that both pre-trained and fine-tuned SAM perform the bloodstain image segmentation task with satisfactory accuracy and efficiency, while fine-tuned SAM achieves an overall 2.2\% accuracy improvement than pre-trained SAM and 4.70\% acceleration in terms of speed for image recognition. Analysis of factors that influence bloodstain recognition is carried out. This research demonstrates the potential application of SAM on bloodstain image segmentation, showcasing the effectiveness of Artificial Intelligence application in criminology research. We release all code and demos at \url{https://github.com/Zdong104/Bloodstain_Analysis_Ai_Tool}
Quaternion tensor ring decomposition and application for color image inpainting
Jul 20, 2023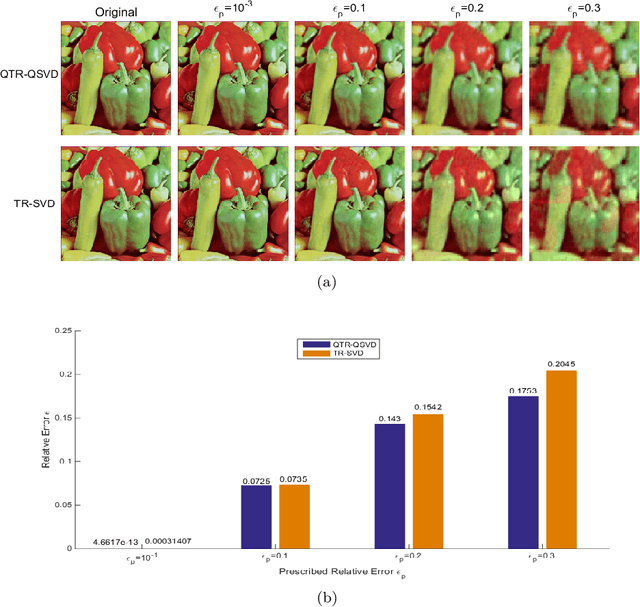
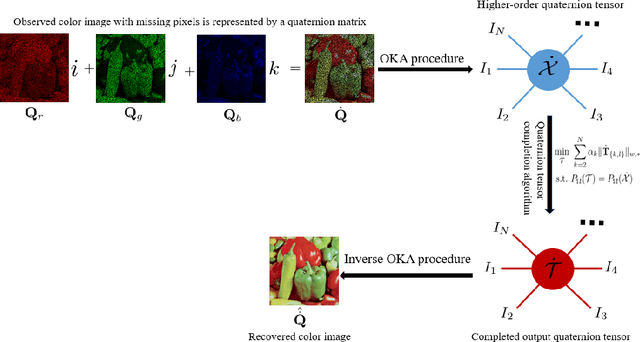
In recent years, tensor networks have emerged as powerful tools for solving large-scale optimization problems. One of the most promising tensor networks is the tensor ring (TR) decomposition, which achieves circular dimensional permutation invariance in the model through the utilization of the trace operation and equitable treatment of the latent cores. On the other hand, more recently, quaternions have gained significant attention and have been widely utilized in color image processing tasks due to their effectiveness in encoding color pixels. Therefore, in this paper, we propose the quaternion tensor ring (QTR) decomposition, which inherits the powerful and generalized representation abilities of the TR decomposition while leveraging the advantages of quaternions for color pixel representation. In addition to providing the definition of QTR decomposition and an algorithm for learning the QTR format, this paper also proposes a low-rank quaternion tensor completion (LRQTC) model and its algorithm for color image inpainting based on the QTR decomposition. Finally, extensive experiments on color image inpainting demonstrate that the proposed QTLRC method is highly competitive.
TSSAT: Two-Stage Statistics-Aware Transformation for Artistic Style Transfer
Sep 12, 2023
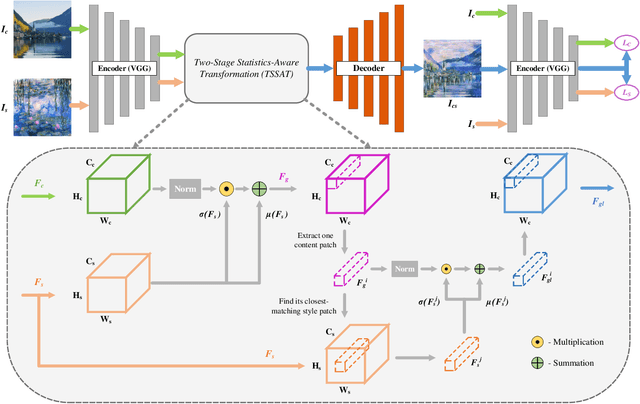

Artistic style transfer aims to create new artistic images by rendering a given photograph with the target artistic style. Existing methods learn styles simply based on global statistics or local patches, lacking careful consideration of the drawing process in practice. Consequently, the stylization results either fail to capture abundant and diversified local style patterns, or contain undesired semantic information of the style image and deviate from the global style distribution. To address this issue, we imitate the drawing process of humans and propose a Two-Stage Statistics-Aware Transformation (TSSAT) module, which first builds the global style foundation by aligning the global statistics of content and style features and then further enriches local style details by swapping the local statistics (instead of local features) in a patch-wise manner, significantly improving the stylization effects. Moreover, to further enhance both content and style representations, we introduce two novel losses: an attention-based content loss and a patch-based style loss, where the former enables better content preservation by enforcing the semantic relation in the content image to be retained during stylization, and the latter focuses on increasing the local style similarity between the style and stylized images. Extensive qualitative and quantitative experiments verify the effectiveness of our method.
Multispectral Image Segmentation in Agriculture: A Comprehensive Study on Fusion Approaches
Jul 31, 2023Multispectral imagery is frequently incorporated into agricultural tasks, providing valuable support for applications such as image segmentation, crop monitoring, field robotics, and yield estimation. From an image segmentation perspective, multispectral cameras can provide rich spectral information, helping with noise reduction and feature extraction. As such, this paper concentrates on the use of fusion approaches to enhance the segmentation process in agricultural applications. More specifically, in this work, we compare different fusion approaches by combining RGB and NDVI as inputs for crop row detection, which can be useful in autonomous robots operating in the field. The inputs are used individually as well as combined at different times of the process (early and late fusion) to perform classical and DL-based semantic segmentation. In this study, two agriculture-related datasets are subjected to analysis using both deep learning (DL)-based and classical segmentation methodologies. The experiments reveal that classical segmentation methods, utilizing techniques such as edge detection and thresholding, can effectively compete with DL-based algorithms, particularly in tasks requiring precise foreground-background separation. This suggests that traditional methods retain their efficacy in certain specialized applications within the agricultural domain. Moreover, among the fusion strategies examined, late fusion emerges as the most robust approach, demonstrating superiority in adaptability and effectiveness across varying segmentation scenarios. The dataset and code is available at https://github.com/Cybonic/MISAgriculture.git.
USL-Net: Uncertainty Self-Learning Network for Unsupervised Skin Lesion Segmentation
Sep 23, 2023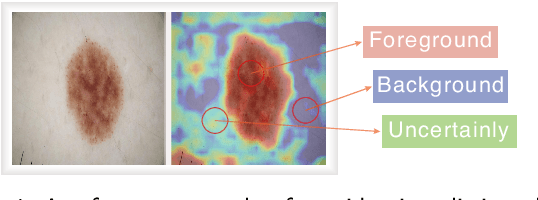
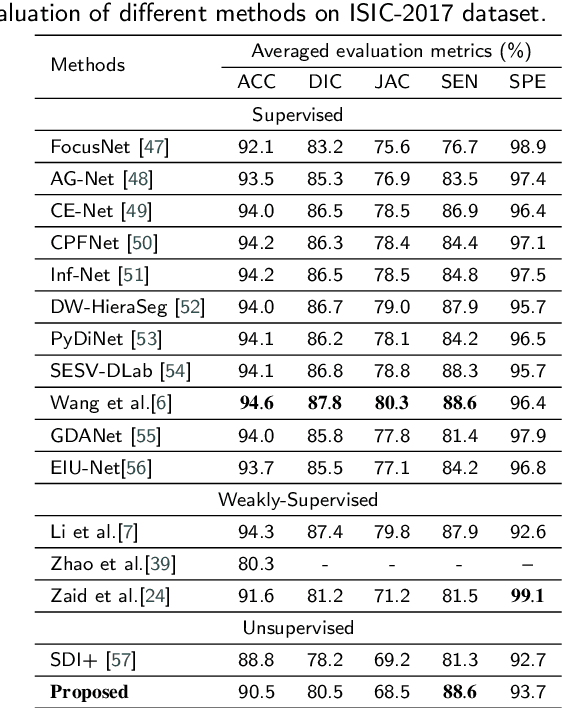
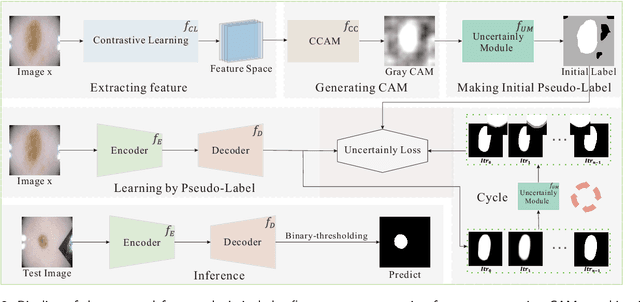
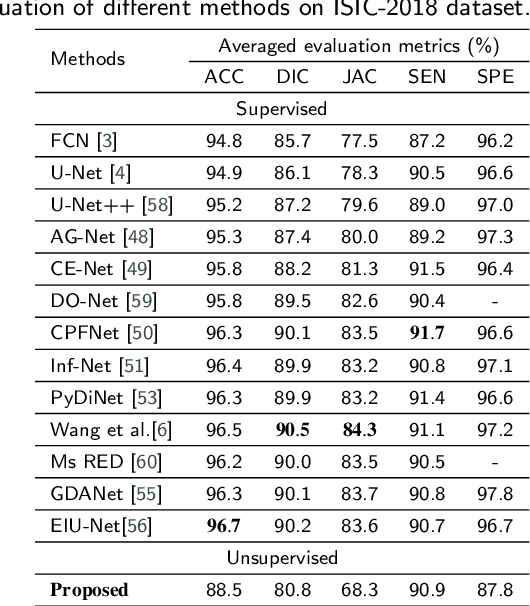
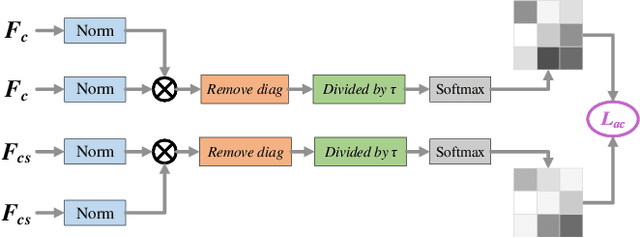
Unsupervised skin lesion segmentation offers several benefits, including conserving expert human resources, reducing discrepancies due to subjective human labeling, and adapting to novel environments. However, segmenting dermoscopic images without manual labeling guidance presents significant challenges due to dermoscopic image artifacts such as hair noise, blister noise, and subtle edge differences. To address these challenges, we introduce an innovative Uncertainty Self-Learning Network (USL-Net) designed for skin lesion segmentation. The USL-Net can effectively segment a range of lesions, eliminating the need for manual labeling guidance. Initially, features are extracted using contrastive learning, followed by the generation of Class Activation Maps (CAMs) as saliency maps using these features. The different CAM locations correspond to the importance of the lesion region based on their saliency. High-saliency regions in the map serve as pseudo-labels for lesion regions while low-saliency regions represent the background. However, intermediate regions can be hard to classify, often due to their proximity to lesion edges or interference from hair or blisters. Rather than risk potential pseudo-labeling errors or learning confusion by forcefully classifying these regions, we consider them as uncertainty regions, exempting them from pseudo-labeling and allowing the network to self-learn. Further, we employ connectivity detection and centrality detection to refine foreground pseudo-labels and reduce noise-induced errors. The application of cycle refining enhances performance further. Our method underwent thorough experimental validation on the ISIC-2017, ISIC-2018, and PH2 datasets, demonstrating that its performance is on par with weakly supervised and supervised methods, and exceeds that of other existing unsupervised methods.
DARC: Distribution-Aware Re-Coloring Model for Generalizable Nucleus Segmentation
Sep 01, 2023
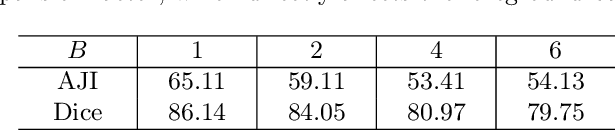
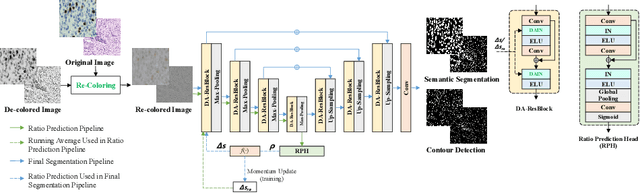
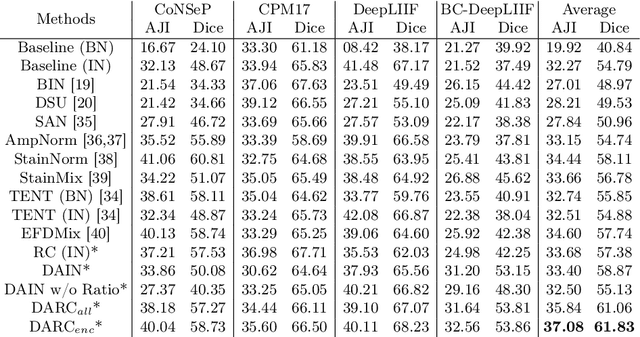
Nucleus segmentation is usually the first step in pathological image analysis tasks. Generalizable nucleus segmentation refers to the problem of training a segmentation model that is robust to domain gaps between the source and target domains. The domain gaps are usually believed to be caused by the varied image acquisition conditions, e.g., different scanners, tissues, or staining protocols. In this paper, we argue that domain gaps can also be caused by different foreground (nucleus)-background ratios, as this ratio significantly affects feature statistics that are critical to normalization layers. We propose a Distribution-Aware Re-Coloring (DARC) model that handles the above challenges from two perspectives. First, we introduce a re-coloring method that relieves dramatic image color variations between different domains. Second, we propose a new instance normalization method that is robust to the variation in foreground-background ratios. We evaluate the proposed methods on two H$\&$E stained image datasets, named CoNSeP and CPM17, and two IHC stained image datasets, called DeepLIIF and BC-DeepLIIF. Extensive experimental results justify the effectiveness of our proposed DARC model. Codes are available at \url{https://github.com/csccsccsccsc/DARC