 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HTC-DC Net: Monocular Height Estimation from Single Remote Sensing Images
Sep 28, 2023
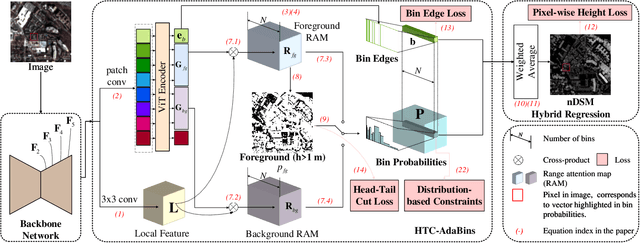
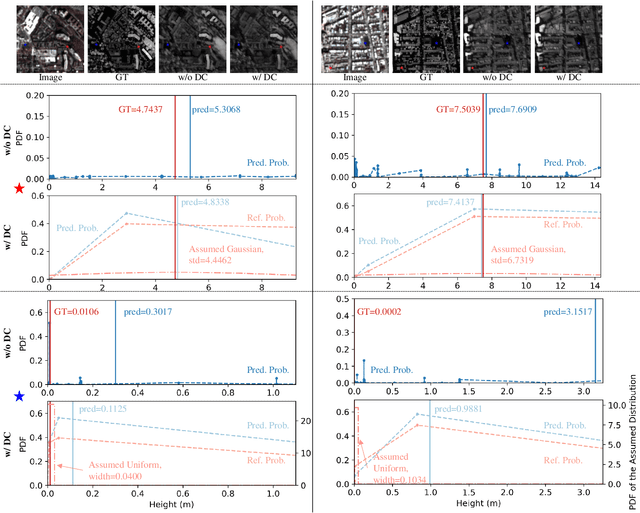
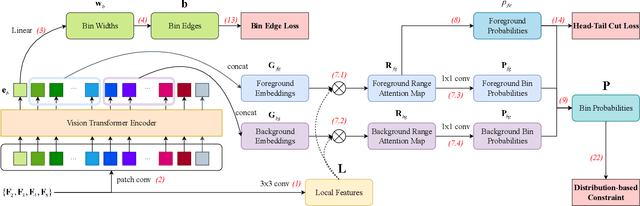
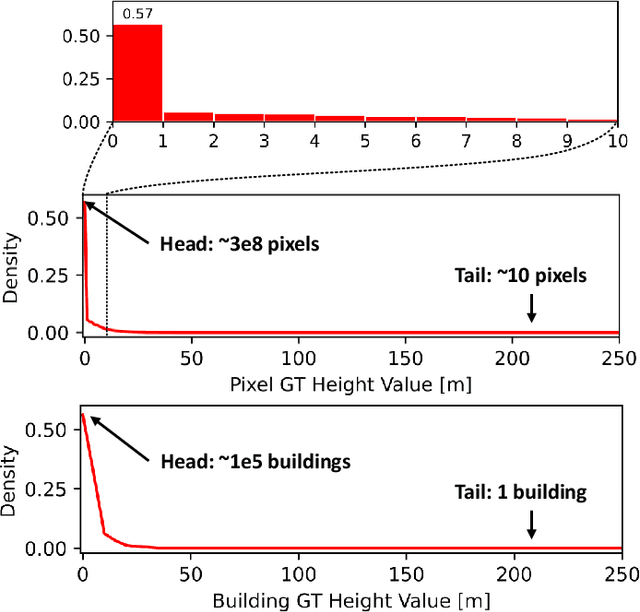
3D geo-information is of great significance for understanding the living environment; however, 3D perception from remote sensing data, especially on a large scale, is restricted. To tackle this problem, we propose a method for monocular height estimation from optical imagery, which is currently one of the richest sources of remote sensing data. As an ill-posed problem, monocular height estimation requires well-designed networks for enhanced representations to improve performance. Moreover, the distribution of height values is long-tailed with the low-height pixels, e.g., the background, as the head, and thus trained networks are usually biased and tend to underestimate building heights. To solve the problems, instead of formalizing the problem as a regression task, we propose HTC-DC Net following the classification-regression paradigm, with the head-tail cut (HTC) and the distribution-based constraints (DCs) as the main contributions. HTC-DC Net is composed of the backbone network as the feature extractor, the HTC-AdaBins module, and the hybrid regression process. The HTC-AdaBins module serves as the classification phase to determine bins adaptive to each input image. It is equipped with a vision transformer encoder to incorporate local context with holistic information and involves an HTC to address the long-tailed problem in monocular height estimation for balancing the performances of foreground and background pixels. The hybrid regression process does the regression via the smoothing of bins from the classification phase, which is trained via DCs. The proposed network is tested on three datasets of different resolutions, namely ISPRS Vaihingen (0.09 m), DFC19 (1.3 m) and GBH (3 m). Experimental results show the superiority of the proposed network over existing methods by large margins. Extensive ablation studies demonstrate the effectiveness of each design component.
Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography
Sep 22, 2023Accurate segmentation is essential for echocardiography-based assessment of cardiovascular diseases (CVDs). However, the variability among sonographers and the inherent challenges of ultrasound images hinder precise segmentation. By leveraging the joint representation of image and text modalities, Vision-Language Segmentation Models (VLSMs) can incorporate rich contextual information, potentially aiding in accurate and explainable segmentation. However, the lack of readily available data in echocardiography hampers the training of VLSMs. In this study, we explore using synthetic datasets from Semantic Diffusion Models (SDMs) to enhance VLSMs for echocardiography segmentation. We evaluate results for two popular VLSMs (CLIPSeg and CRIS) using seven different kinds of language prompts derived from several attributes, automatically extracted from echocardiography images, segmentation masks, and their metadata. Our results show improved metrics and faster convergence when pretraining VLSMs on SDM-generated synthetic images before finetuning on real images. The code, configs, and prompts are available at https://github.com/naamiinepal/synthetic-boost.
CCSPNet-Joint: Efficient Joint Training Method for Traffic Sihn Detection Under Extreme Conditions
Sep 13, 2023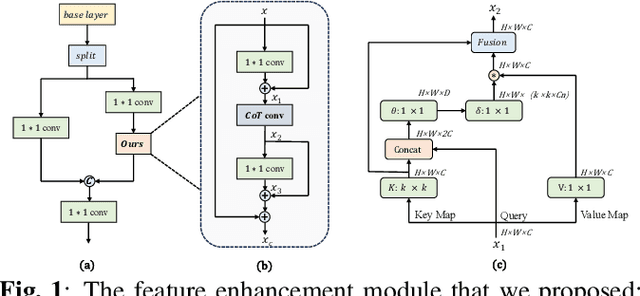
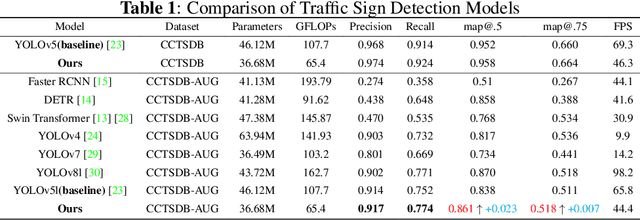
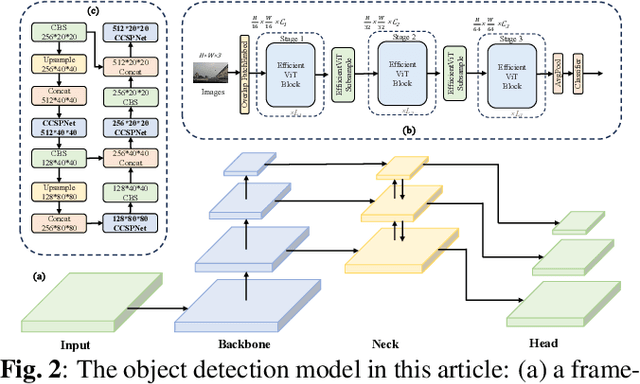
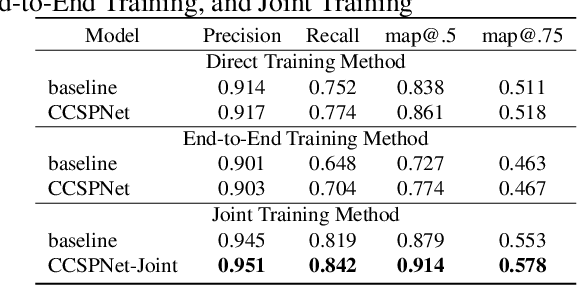
Traffic sign detection is an important research direction in intelligent driving. Unfortunately, existing methods often overlook extreme conditions such as fog, rain, and motion blur. Moreover, the end-to-end training strategy for image denoising and object detection models fails to utilize inter-model information effectively. To address these issues, we propose CCSPNet, an efficient feature extraction module based on Transformers and CNNs, which effectively leverages contextual information, achieves faster inference speed and provides stronger feature enhancement capabilities. Furthermore, we establish the correlation between object detection and image denoising tasks and propose a joint training model, CCSPNet-Joint, to improve data efficiency and generalization. Finally, to validate our approach, we create the CCTSDB-AUG dataset for traffic sign detection in extreme scenarios. Extensive experiments have shown that CCSPNet achieves state-of-the-art performance in traffic sign detection under extreme conditions. Compared to end-to-end methods, CCSPNet-Joint achieves a 5.32% improvement in precision and an 18.09% improvement in mAP@.5.
Dynamic Hyperbolic Attention Network for Fine Hand-object Reconstruction
Sep 06, 2023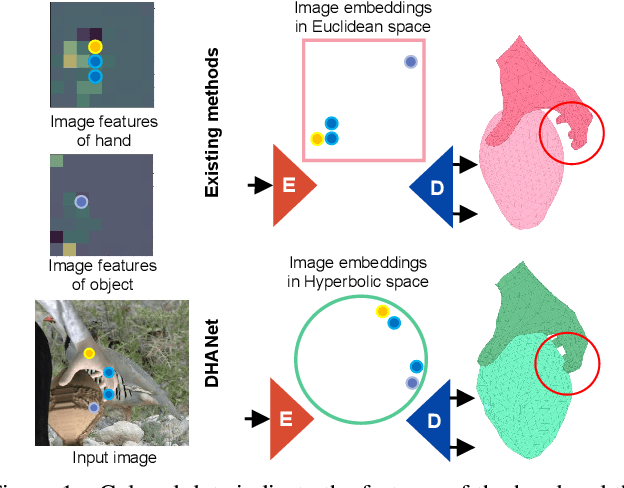
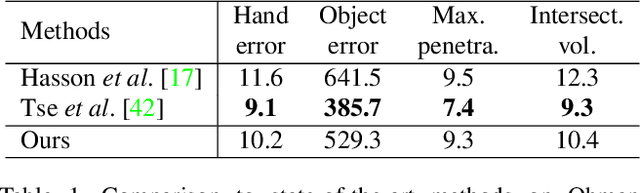
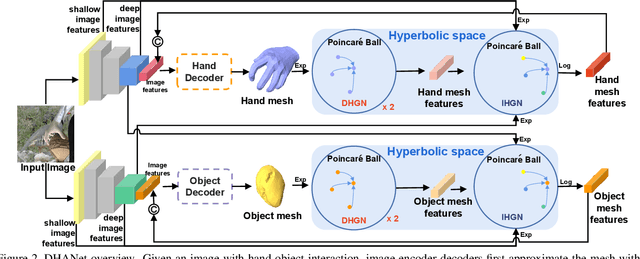
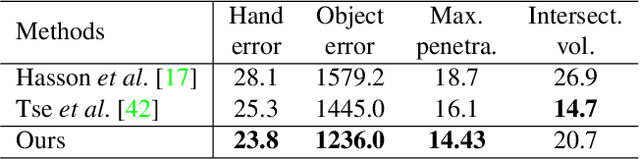
Reconstructing both objects and hands in 3D from a single RGB image is complex. Existing methods rely on manually defined hand-object constraints in Euclidean space, leading to suboptimal feature learning. Compared with Euclidean space, hyperbolic space better preserves the geometric properties of meshes thanks to its exponentially-growing space distance, which amplifies the differences between the features based on similarity. In this work, we propose the first precise hand-object reconstruction method in hyperbolic space, namely Dynamic Hyperbolic Attention Network (DHANet), which leverages intrinsic properties of hyperbolic space to learn representative features. Our method that projects mesh and image features into a unified hyperbolic space includes two modules, ie. dynamic hyperbolic graph convolution and image-attention hyperbolic graph convolution. With these two modules, our method learns mesh features with rich geometry-image multi-modal information and models better hand-object interaction. Our method provides a promising alternative for fine hand-object reconstruction in hyperbolic space. Extensive experiments on three public datasets demonstrate that our method outperforms most state-of-the-art methods.
DONNAv2 -- Lightweight Neural Architecture Search for Vision tasks
Sep 26, 2023With the growing demand for vision applications and deployment across edge devices, the development of hardware-friendly architectures that maintain performance during device deployment becomes crucial. Neural architecture search (NAS) techniques explore various approaches to discover efficient architectures for diverse learning tasks in a computationally efficient manner. In this paper, we present the next-generation neural architecture design for computationally efficient neural architecture distillation - DONNAv2 . Conventional NAS algorithms rely on a computationally extensive stage where an accuracy predictor is learned to estimate model performance within search space. This building of accuracy predictors helps them predict the performance of models that are not being finetuned. Here, we have developed an elegant approach to eliminate building the accuracy predictor and extend DONNA to a computationally efficient setting. The loss metric of individual blocks forming the network serves as the surrogate performance measure for the sampled models in the NAS search stage. To validate the performance of DONNAv2 we have performed extensive experiments involving a range of diverse vision tasks including classification, object detection, image denoising, super-resolution, and panoptic perception network (YOLOP). The hardware-in-the-loop experiments were carried out using the Samsung Galaxy S10 mobile platform. Notably, DONNAv2 reduces the computational cost of DONNA by 10x for the larger datasets. Furthermore, to improve the quality of NAS search space, DONNAv2 leverages a block knowledge distillation filter to remove blocks with high inference costs.
Benchmarking Encoder-Decoder Architectures for Biplanar X-ray to 3D Shape Reconstruction
Sep 26, 2023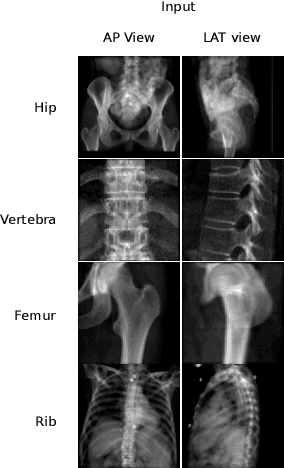
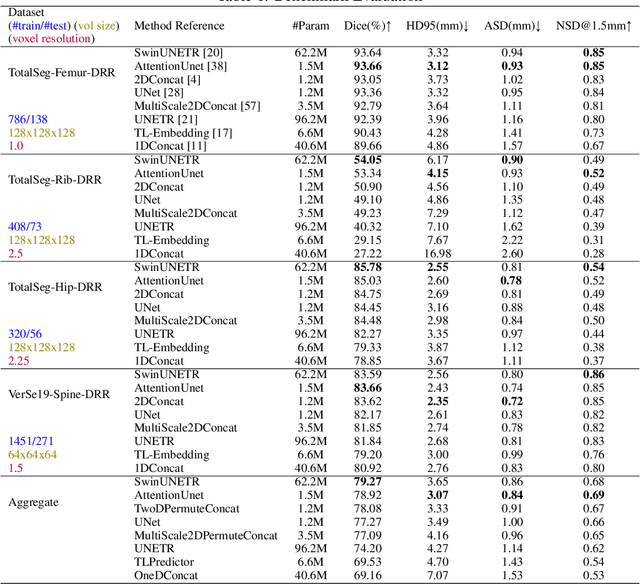
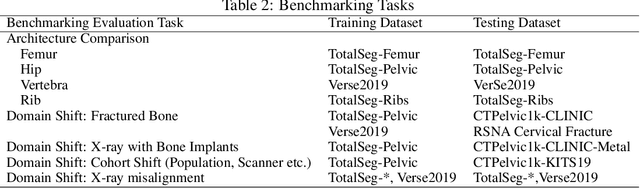
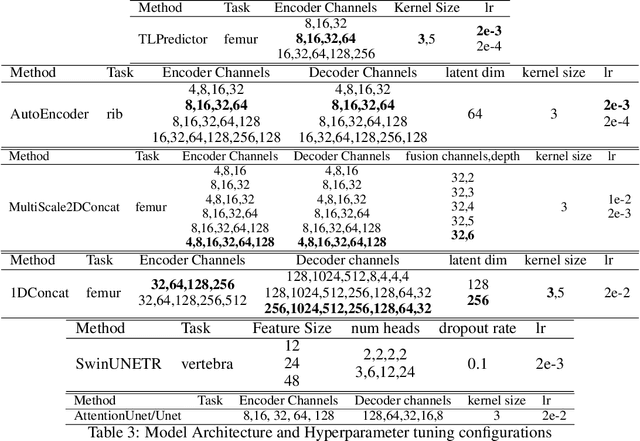
Various deep learning models have been proposed for 3D bone shape reconstruction from two orthogonal (biplanar) X-ray images. However, it is unclear how these models compare against each other since they are evaluated on different anatomy, cohort and (often privately held) datasets. Moreover, the impact of the commonly optimized image-based segmentation metrics such as dice score on the estimation of clinical parameters relevant in 2D-3D bone shape reconstruction is not well known. To move closer toward clinical translation, we propose a benchmarking framework that evaluates tasks relevant to real-world clinical scenarios, including reconstruction of fractured bones, bones with implants, robustness to population shift, and error in estimating clinical parameters. Our open-source platform provides reference implementations of 8 models (many of whose implementations were not publicly available), APIs to easily collect and preprocess 6 public datasets, and the implementation of automatic clinical parameter and landmark extraction methods. We present an extensive evaluation of 8 2D-3D models on equal footing using 6 public datasets comprising images for four different anatomies. Our results show that attention-based methods that capture global spatial relationships tend to perform better across all anatomies and datasets; performance on clinically relevant subgroups may be overestimated without disaggregated reporting; ribs are substantially more difficult to reconstruct compared to femur, hip and spine; and the dice score improvement does not always bring a corresponding improvement in the automatic estimation of clinically relevant parameters.
Pick the Best Pre-trained Model: Towards Transferability Estimation for Medical Image Segmentation
Jul 22, 2023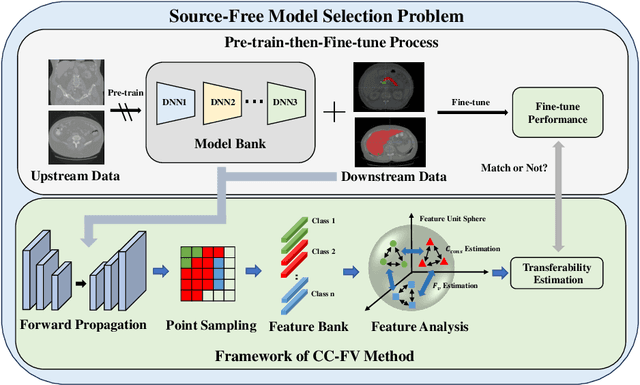
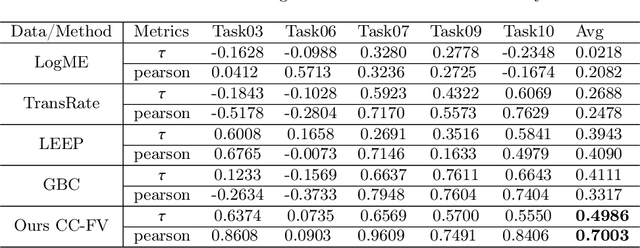
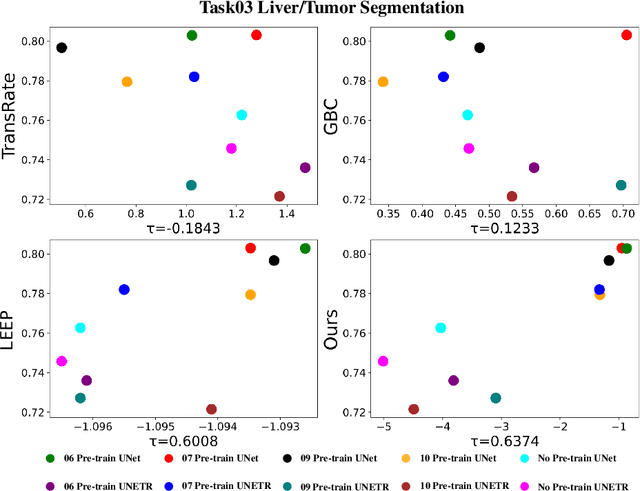
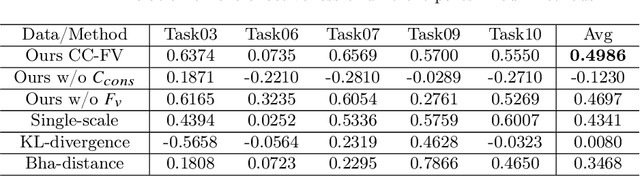
Transfer learning is a critical technique in training deep neural networks for the challenging medical image segmentation task that requires enormous resources. With the abundance of medical image data, many research institutions release models trained on various datasets that can form a huge pool of candidate source models to choose from. Hence, it's vital to estimate the source models' transferability (i.e., the ability to generalize across different downstream tasks) for proper and efficient model reuse. To make up for its deficiency when applying transfer learning to medical image segmentation, in this paper, we therefore propose a new Transferability Estimation (TE) method. We first analyze the drawbacks of using the existing TE algorithms for medical image segmentation and then design a source-free TE framework that considers both class consistency and feature variety for better estimation. Extensive experiments show that our method surpasses all current algorithms for transferability estimation in medical image segmentation. Code is available at https://github.com/EndoluminalSurgicalVision-IMR/CCFV
Exploring the Influence of Information Entropy Change in Learning Systems
Sep 19, 2023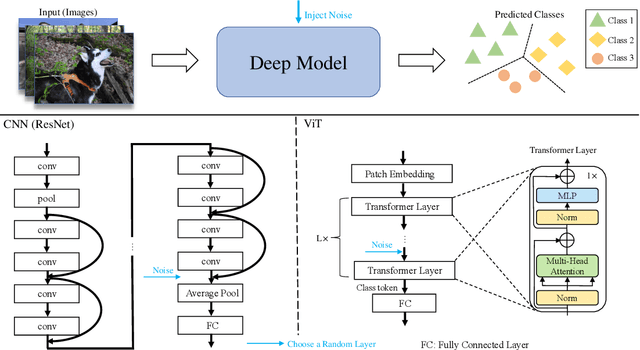


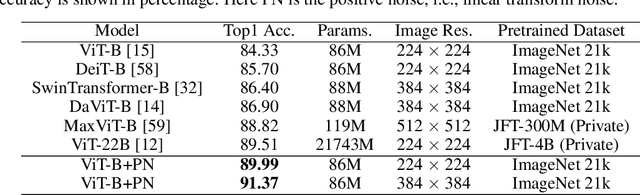
In this work, we explore the influence of entropy change in deep learning systems by adding noise to the inputs/latent features. The applications in this paper focus on deep learning tasks within computer vision, but the proposed theory can be further applied to other fields. Noise is conventionally viewed as a harmful perturbation in various deep learning architectures, such as convolutional neural networks (CNNs) and vision transformers (ViTs), as well as different learning tasks like image classification and transfer learning. However, this paper aims to rethink whether the conventional proposition always holds. We demonstrate that specific noise can boost the performance of various deep architectures under certain conditions. We theoretically prove the enhancement gained from positive noise by reducing the task complexity defined by information entropy and experimentally show the significant performance gain in large image datasets, such as the ImageNet. Herein, we use the information entropy to define the complexity of the task. We categorize the noise into two types, positive noise (PN) and harmful noise (HN), based on whether the noise can help reduce the complexity of the task. Extensive experiments of CNNs and ViTs have shown performance improvements by proactively injecting positive noise, where we achieved an unprecedented top 1 accuracy of over 95% on ImageNet. Both theoretical analysis and empirical evidence have confirmed that the presence of positive noise can benefit the learning process, while the traditionally perceived harmful noise indeed impairs deep learning models. The different roles of noise offer new explanations for deep models on specific tasks and provide a new paradigm for improving model performance. Moreover, it reminds us that we can influence the performance of learning systems via information entropy change.
HRFNet: High-Resolution Forgery Network for Localizing Satellite Image Manipulation
Jul 20, 2023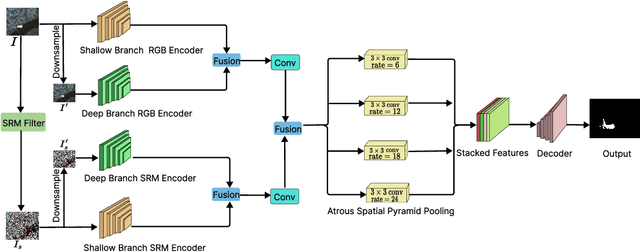

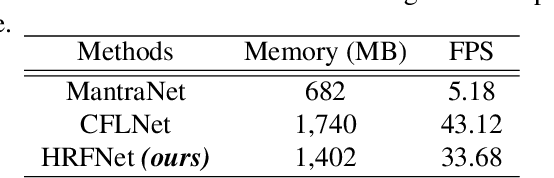

Existing high-resolution satellite image forgery localization methods rely on patch-based or downsampling-based training. Both of these training methods have major drawbacks, such as inaccurate boundaries between pristine and forged regions, the generation of unwanted artifacts, etc. To tackle the aforementioned challenges, inspired by the high-resolution image segmentation literature, we propose a novel model called HRFNet to enable satellite image forgery localization effectively. Specifically, equipped with shallow and deep branches, our model can successfully integrate RGB and resampling features in both global and local manners to localize forgery more accurately. We perform various experiments to demonstrate that our method achieves the best performance, while the memory requirement and processing speed are not compromised compared to existing methods.
Image Synthesis under Limited Data: A Survey and Taxonomy
Jul 31, 2023Deep generative models, which target reproducing the given data distribution to produce novel samples, have made unprecedented advancements in recent years. Their technical breakthroughs have enabled unparalleled quality in the synthesis of visual content. However, one critical prerequisite for their tremendous success is the availability of a sufficient number of training samples, which requires massive computation resources. When trained on limited data, generative models tend to suffer from severe performance deterioration due to overfitting and memorization. Accordingly, researchers have devoted considerable attention to develop novel models that are capable of generating plausible and diverse images from limited training data recently. Despite numerous efforts to enhance training stability and synthesis quality in the limited data scenarios, there is a lack of a systematic survey that provides 1) a clear problem definition, critical challenges, and taxonomy of various tasks; 2) an in-depth analysis on the pros, cons, and remain limitations of existing literature; as well as 3) a thorough discussion on the potential applications and future directions in the field of image synthesis under limited data. In order to fill this gap and provide a informative introduction to researchers who are new to this topic, this survey offers a comprehensive review and a novel taxonomy on the development of image synthesis under limited data. In particular, it covers the problem definition, requirements, main solutions, popular benchmarks, and remain challenges in a comprehensive and all-around manner.