 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Performance Metrics for Probabilistic Ordinal Classifiers
Sep 15, 2023
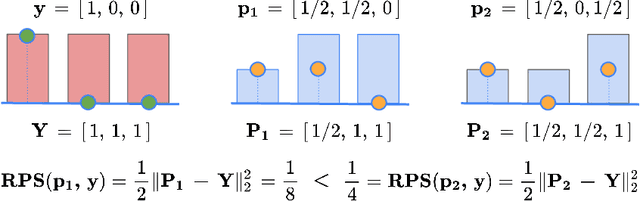
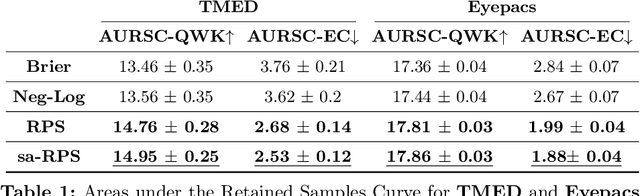
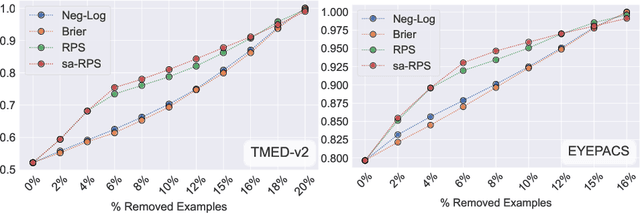
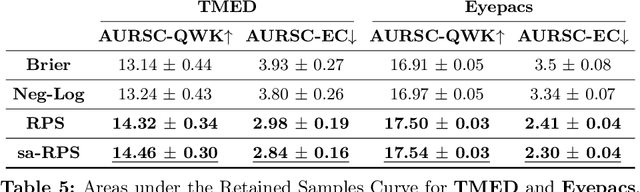
Ordinal classification models assign higher penalties to predictions further away from the true class. As a result, they are appropriate for relevant diagnostic tasks like disease progression prediction or medical image grading. The consensus for assessing their categorical predictions dictates the use of distance-sensitive metrics like the Quadratic-Weighted Kappa score or the Expected Cost. However, there has been little discussion regarding how to measure performance of probabilistic predictions for ordinal classifiers. In conventional classification, common measures for probabilistic predictions are Proper Scoring Rules (PSR) like the Brier score, or Calibration Errors like the ECE, yet these are not optimal choices for ordinal classification. A PSR named Ranked Probability Score (RPS), widely popular in the forecasting field, is more suitable for this task, but it has received no attention in the image analysis community. This paper advocates the use of the RPS for image grading tasks. In addition, we demonstrate a counter-intuitive and questionable behavior of this score, and propose a simple fix for it. Comprehensive experiments on four large-scale biomedical image grading problems over three different datasets show that the RPS is a more suitable performance metric for probabilistic ordinal predictions. Code to reproduce our experiments can be found at https://github.com/agaldran/prob_ord_metrics .
A multimodal deep learning architecture for smoking detection with a small data approach
Sep 19, 2023Introduction: Covert tobacco advertisements often raise regulatory measures. This paper presents that artificial intelligence, particularly deep learning, has great potential for detecting hidden advertising and allows unbiased, reproducible, and fair quantification of tobacco-related media content. Methods: We propose an integrated text and image processing model based on deep learning, generative methods, and human reinforcement, which can detect smoking cases in both textual and visual formats, even with little available training data. Results: Our model can achieve 74\% accuracy for images and 98\% for text. Furthermore, our system integrates the possibility of expert intervention in the form of human reinforcement. Conclusions: Using the pre-trained multimodal, image, and text processing models available through deep learning makes it possible to detect smoking in different media even with few training data.
Topology-inspired Cross-domain Network for Developmental Cervical Stenosis Quantification
Sep 18, 2023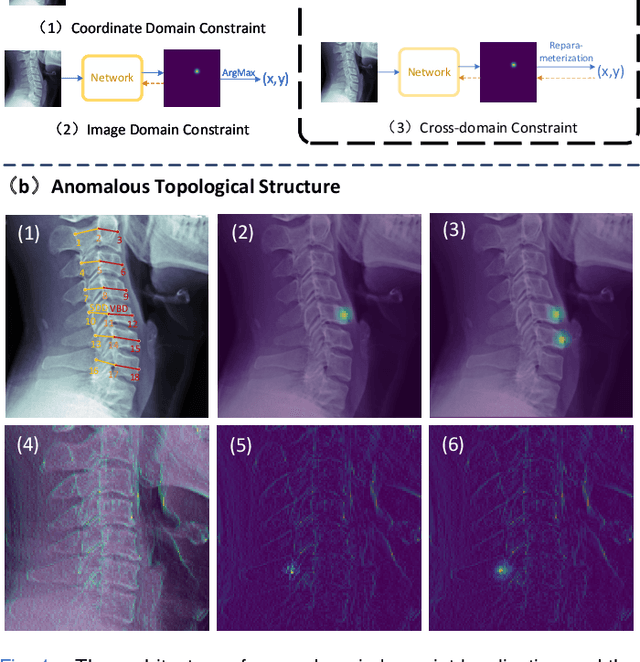
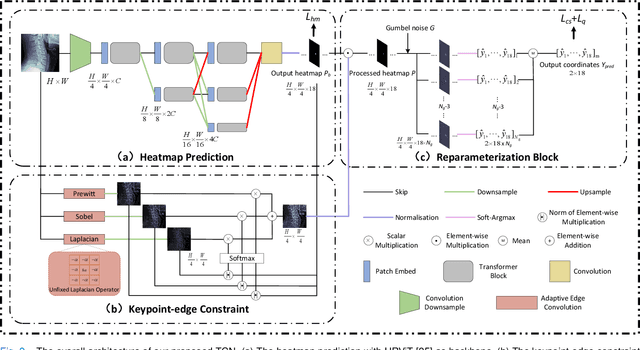
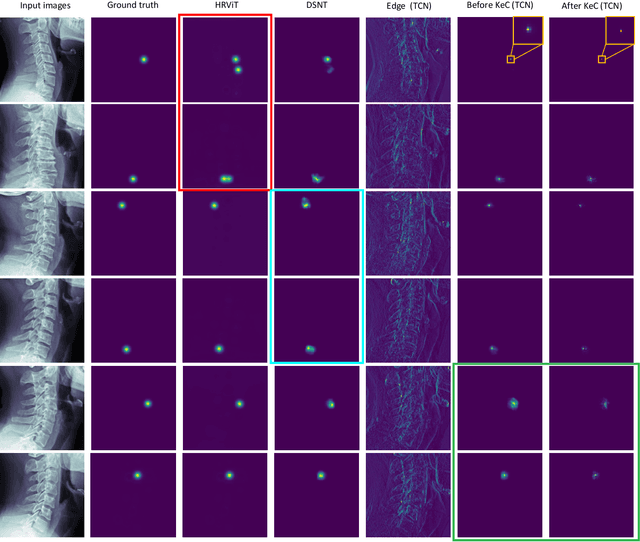
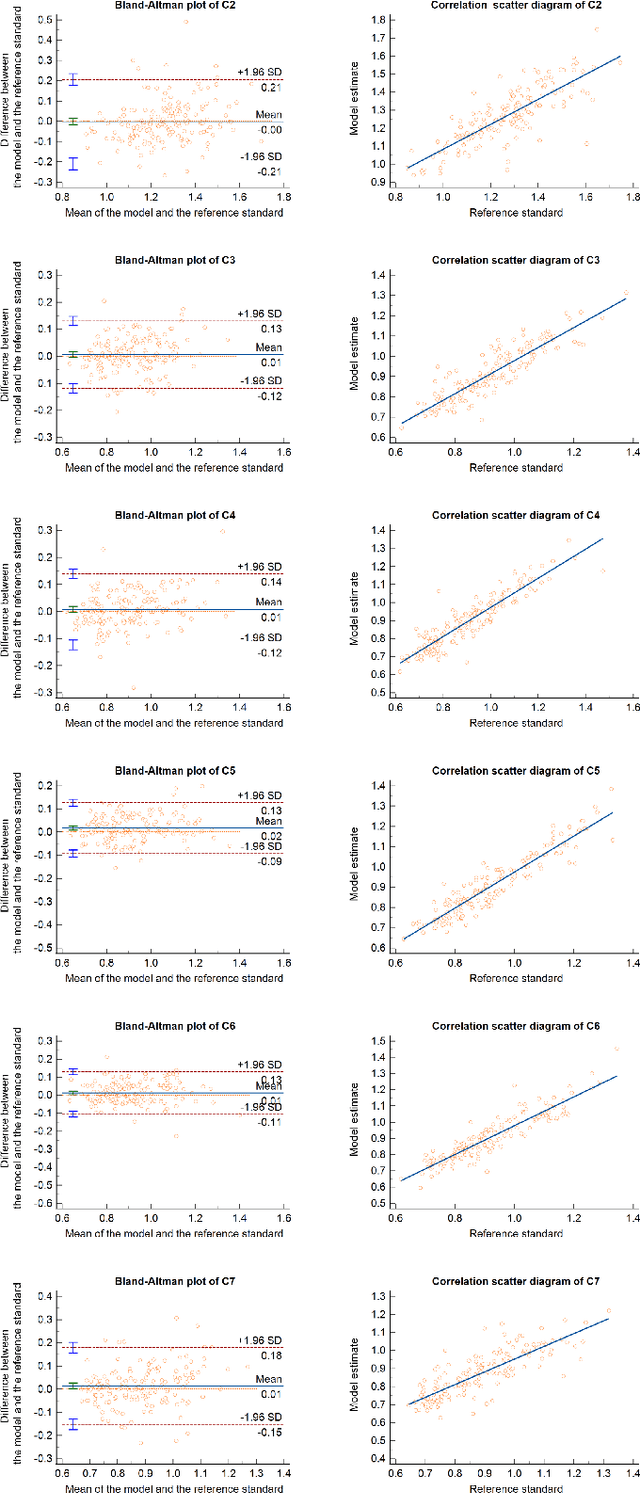
Developmental Canal Stenosis (DCS) quantification is crucial in cervical spondylosis screening. Compared with quantifying DCS manually, a more efficient and time-saving manner is provided by deep keypoint localization networks, which can be implemented in either the coordinate or the image domain. However, the vertebral visualization features often lead to abnormal topological structures during keypoint localization, including keypoint distortion with edges and weakly connected structures, which cannot be fully suppressed in either the coordinate or image domain alone. To overcome this limitation, a keypoint-edge and a reparameterization modules are utilized to restrict these abnormal structures in a cross-domain manner. The keypoint-edge constraint module restricts the keypoints on the edges of vertebrae, which ensures that the distribution pattern of keypoint coordinates is consistent with those for DCS quantification. And the reparameterization module constrains the weakly connected structures in image-domain heatmaps with coordinates combined. Moreover, the cross-domain network improves spatial generalization by utilizing heatmaps and incorporating coordinates for accurate localization, which avoids the trade-off between these two properties in an individual domain. Comprehensive results of distinct quantification tasks show the superiority and generability of the proposed Topology-inspired Cross-domain Network (TCN) compared with other competing localization methods.
High Dynamic Range Image Reconstruction via Deep Explicit Polynomial Curve Estimation
Jul 31, 2023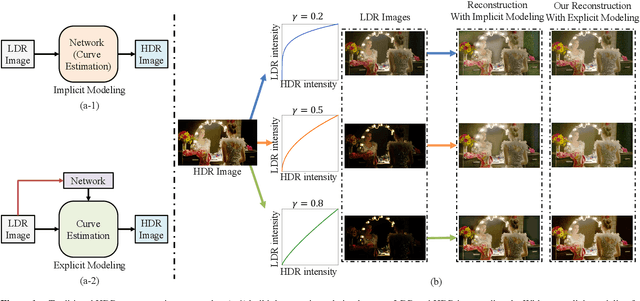
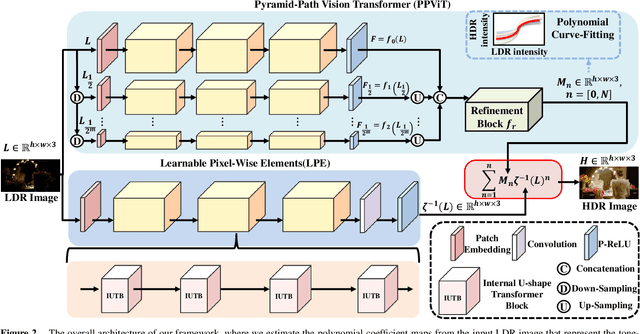
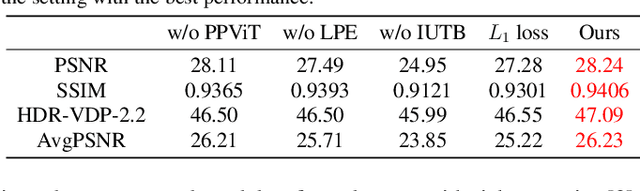
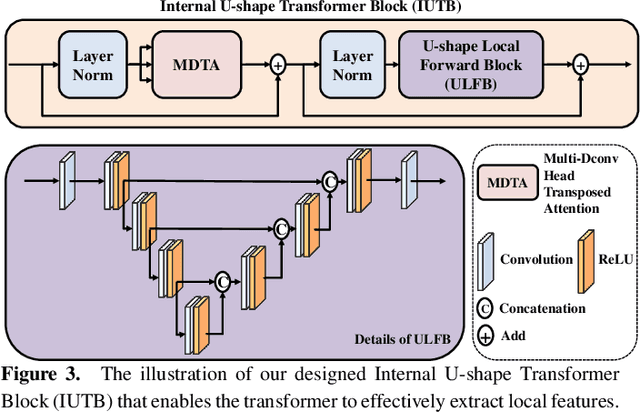
Due to limited camera capacities, digital images usually have a narrower dynamic illumination range than real-world scene radiance. To resolve this problem, High Dynamic Range (HDR) reconstruction is proposed to recover the dynamic range to better represent real-world scenes. However, due to different physical imaging parameters, the tone-mapping functions between images and real radiance are highly diverse, which makes HDR reconstruction extremely challenging. Existing solutions can not explicitly clarify a corresponding relationship between the tone-mapping function and the generated HDR image, but this relationship is vital when guiding the reconstruction of HDR images. To address this problem, we propose a method to explicitly estimate the tone mapping function and its corresponding HDR image in one network. Firstly, based on the characteristics of the tone mapping function, we construct a model by a polynomial to describe the trend of the tone curve. To fit this curve, we use a learnable network to estimate the coefficients of the polynomial. This curve will be automatically adjusted according to the tone space of the Low Dynamic Range (LDR) image, and reconstruct the real HDR image. Besides, since all current datasets do not provide the corresponding relationship between the tone mapping function and the LDR image, we construct a new dataset with both synthetic and real images. Extensive experiments show that our method generalizes well under different tone-mapping functions and achieves SOTA performance.
Communication-Efficient Framework for Distributed Image Semantic Wireless Transmission
Aug 08, 2023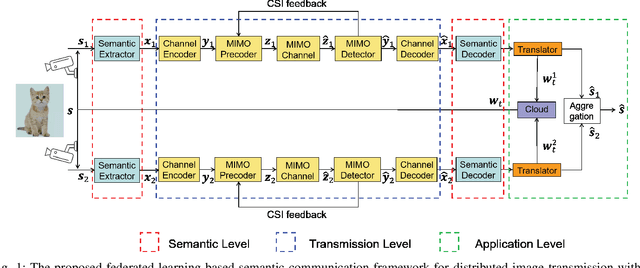
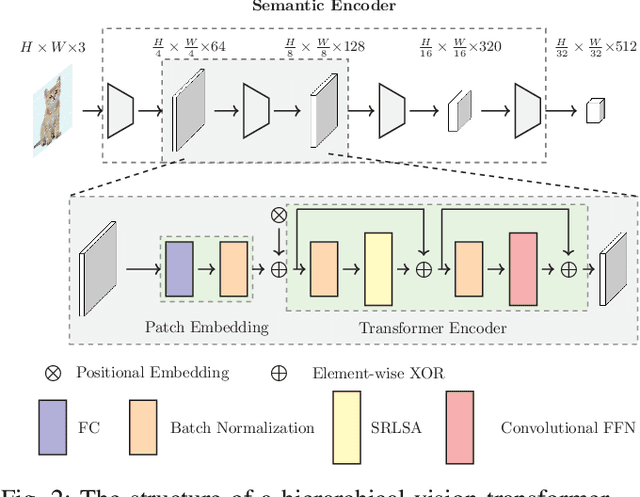
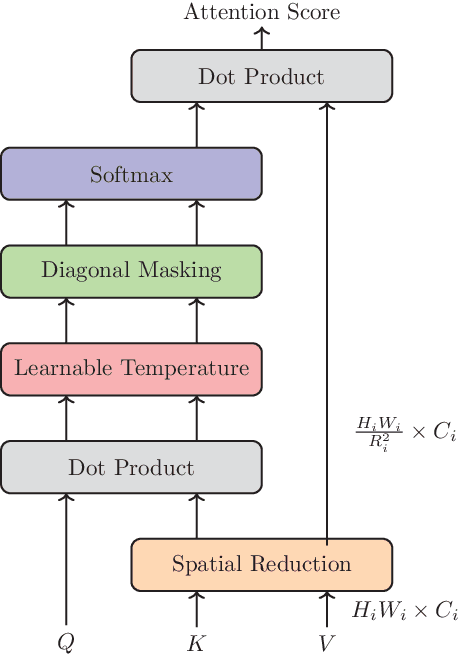
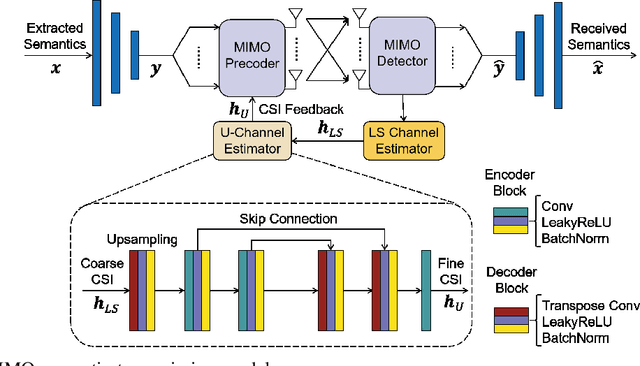
Multi-node communication, which refers to the interaction among multiple devices, has attracted lots of attention in many Internet-of-Things (IoT) scenarios. However, its huge amounts of data flows and inflexibility for task extension have triggered the urgent requirement of communication-efficient distributed data transmission frameworks. In this paper, inspired by the great superiorities on bandwidth reduction and task adaptation of semantic communications, we propose a federated learning-based semantic communication (FLSC) framework for multi-task distributed image transmission with IoT devices. Federated learning enables the design of independent semantic communication link of each user while further improves the semantic extraction and task performance through global aggregation. Each link in FLSC is composed of a hierarchical vision transformer (HVT)-based extractor and a task-adaptive translator for coarse-to-fine semantic extraction and meaning translation according to specific tasks. In order to extend the FLSC into more realistic conditions, we design a channel state information-based multiple-input multiple-output transmission module to combat channel fading and noise. Simulation results show that the coarse semantic information can deal with a range of image-level tasks. Moreover, especially in low signal-to-noise ratio and channel bandwidth ratio regimes, FLSC evidently outperforms the traditional scheme, e.g. about 10 peak signal-to-noise ratio gain in the 3 dB channel condition.
Lung Diseases Image Segmentation using Faster R-CNNs
Sep 10, 2023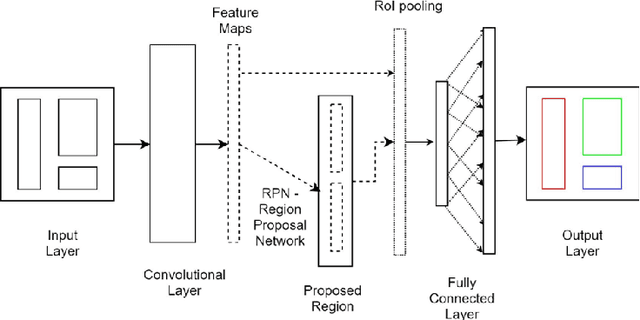
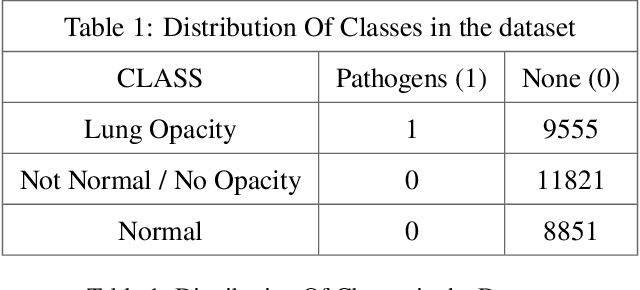
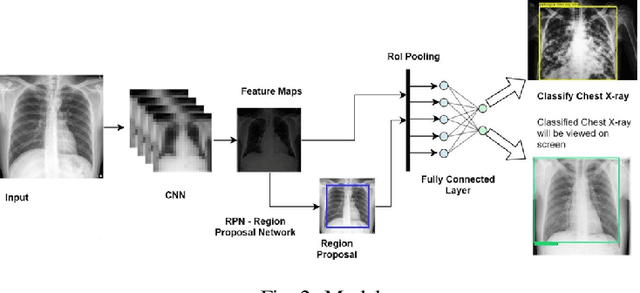
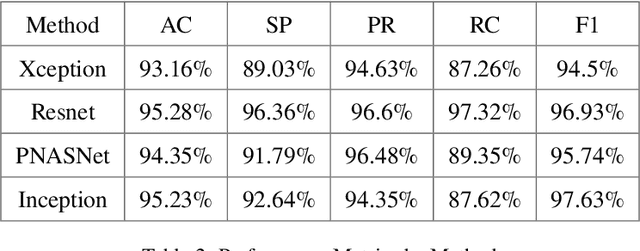
Lung diseases are a leading cause of child mortality in the developing world, with India accounting for approximately half of global pneumonia deaths (370,000) in 2016. Timely diagnosis is crucial for reducing mortality rates. This paper introduces a low-density neural network structure to mitigate topological challenges in deep networks. The network incorporates parameters into a feature pyramid, enhancing data extraction and minimizing information loss. Soft Non-Maximal Suppression optimizes regional proposals generated by the Region Proposal Network. The study evaluates the model on chest X-ray images, computing a confusion matrix to determine accuracy, precision, sensitivity, and specificity. We analyze loss functions, highlighting their trends during training. The regional proposal loss and classification loss assess model performance during training and classification phases. This paper analysis lung disease detection and neural network structures.
Randomized Dimension Reduction with Statistical Guarantees
Oct 03, 2023Large models and enormous data are essential driving forces of the unprecedented successes achieved by modern algorithms, especially in scientific computing and machine learning. Nevertheless, the growing dimensionality and model complexity, as well as the non-negligible workload of data pre-processing, also bring formidable costs to such successes in both computation and data aggregation. As the deceleration of Moore's Law slackens the cost reduction of computation from the hardware level, fast heuristics for expensive classical routines and efficient algorithms for exploiting limited data are increasingly indispensable for pushing the limit of algorithm potency. This thesis explores some of such algorithms for fast execution and efficient data utilization. From the computational efficiency perspective, we design and analyze fast randomized low-rank decomposition algorithms for large matrices based on "matrix sketching", which can be regarded as a dimension reduction strategy in the data space. These include the randomized pivoting-based interpolative and CUR decomposition discussed in Chapter 2 and the randomized subspace approximations discussed in Chapter 3. From the sample efficiency perspective, we focus on learning algorithms with various incorporations of data augmentation that improve generalization and distributional robustness provably. Specifically, Chapter 4 presents a sample complexity analysis for data augmentation consistency regularization where we view sample efficiency from the lens of dimension reduction in the function space. Then in Chapter 5, we introduce an adaptively weighted data augmentation consistency regularization algorithm for distributionally robust optimization with applications in medical image segmentation.
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Oct 03, 2023Although Large Language Models (LLMs) and Large Multimodal Models (LMMs) exhibit impressive skills in various domains, their ability for mathematical reasoning within visual contexts has not been formally examined. Equipping LLMs and LMMs with this capability is vital for general-purpose AI assistants and showcases promising potential in education, data analysis, and scientific discovery. To bridge this gap, we present MathVista, a benchmark designed to amalgamate challenges from diverse mathematical and visual tasks. We first taxonomize the key task types, reasoning skills, and visual contexts from the literature to guide our selection from 28 existing math-focused and visual question answering datasets. Then, we construct three new datasets, IQTest, FunctionQA, and PaperQA, to accommodate for missing types of visual contexts. The problems featured often require deep visual understanding beyond OCR or image captioning, and compositional reasoning with rich domain-specific tools, thus posing a notable challenge to existing models. We conduct a comprehensive evaluation of 11 prominent open-source and proprietary foundation models (LLMs, LLMs augmented with tools, and LMMs), and early experiments with GPT-4V. The best-performing model, Multimodal Bard, achieves only 58% of human performance (34.8% vs 60.3%), indicating ample room for further improvement. Given this significant gap, MathVista fuels future research in the development of general-purpose AI agents capable of tackling mathematically intensive and visually rich real-world tasks. Preliminary tests show that MathVista also presents challenges to GPT-4V, underscoring the benchmark's importance. The project is available at https://mathvista.github.io/.
GenCO: Generating Diverse Solutions to Design Problems with Combinatorial Nature
Oct 03, 2023Generating diverse objects (e.g., images) using generative models (such as GAN or VAE) has achieved impressive results in the recent years, to help solve many design problems that are traditionally done by humans. Going beyond image generation, we aim to find solutions to more general design problems, in which both the diversity of the design and conformity of constraints are important. Such a setting has applications in computer graphics, animation, industrial design, material science, etc, in which we may want the output of the generator to follow discrete/combinatorial constraints and penalize any deviation, which is non-trivial with existing generative models and optimization solvers. To address this, we propose GenCO, a novel framework that conducts end-to-end training of deep generative models integrated with embedded combinatorial solvers, aiming to uncover high-quality solutions aligned with nonlinear objectives. While structurally akin to conventional generative models, GenCO diverges in its role - it focuses on generating instances of combinatorial optimization problems rather than final objects (e.g., images). This shift allows finer control over the generated outputs, enabling assessments of their feasibility and introducing an additional combinatorial loss component. We demonstrate the effectiveness of our approach on a variety of generative tasks characterized by combinatorial intricacies, including game level generation and map creation for path planning, consistently demonstrating its capability to yield diverse, high-quality solutions that reliably adhere to user-specified combinatorial properties.
Tree based Single LED Indoor Visible Light Positioning Technique
Sep 29, 2023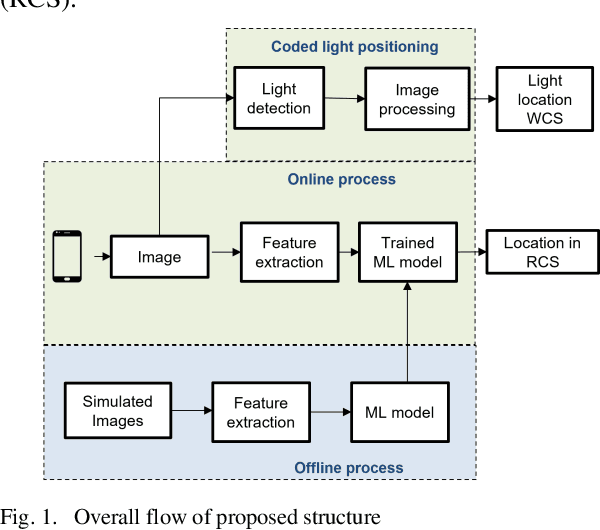
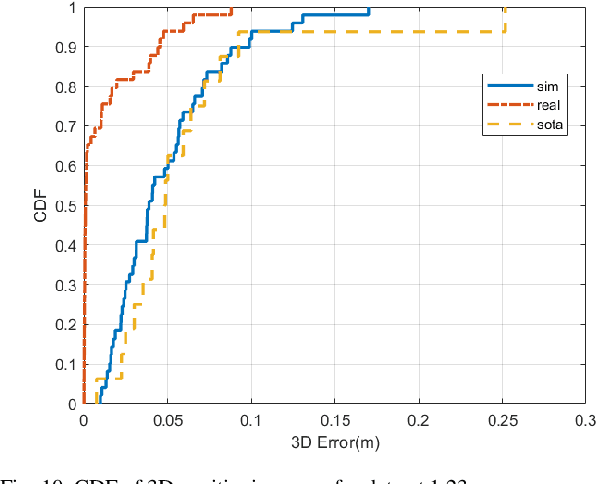
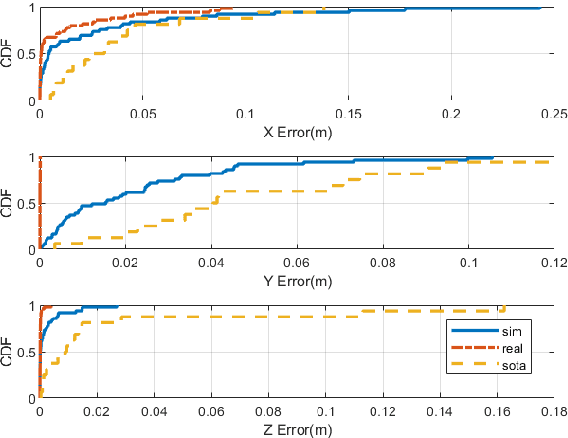
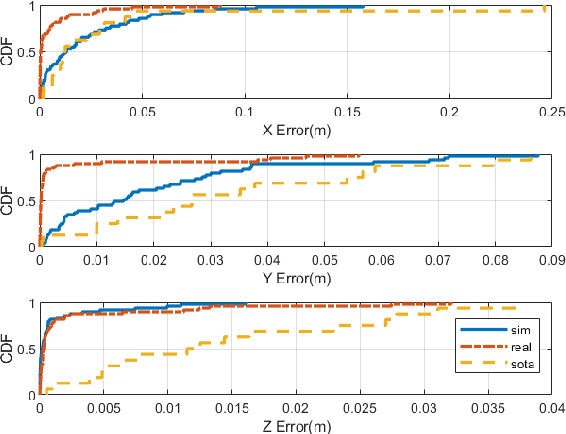
Visible light positioning(VLP) has gained prominence as a highly accurate indoor positioning technique. Few techniques consider the practical limitations of implementing VLP systems for indoor positioning. These limitations range from having a single LED in the field of view(FoV) of the image sensor to not having enough images for training deep learning techniques. Practical implementation of indoor positioning techniques needs to leverage the ubiquity of smartphones, which is the case with VLP using complementary metal oxide semiconductor(CMOS) sensors. Images for VLP can be gathered only after the lights in question have been installed making it a cumbersome process. These limitations are addressed in the proposed technique, which uses simulated data of a single LED to train machine learning models and test them on actual images captured from a similar experimental setup. Such testing produced mean three dimensional(3D) positioning error of 2.88 centimeters while training with real images achieves accuracy of less than one centimeter compared to 6.26 centimeters of the closest competitor.