 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FairRAG: Fair Human Generation via Fair Retrieval Augmentation
Mar 29, 2024

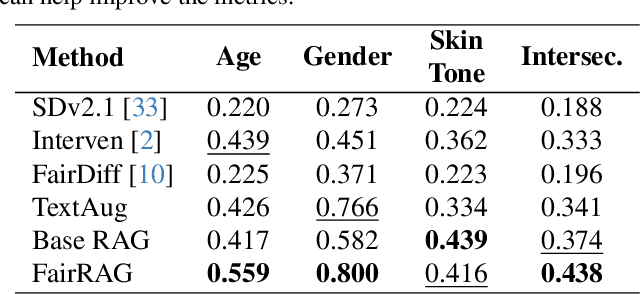
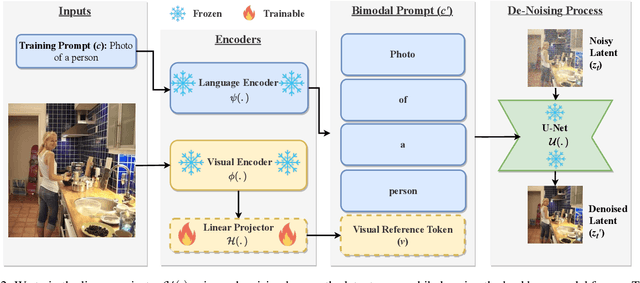
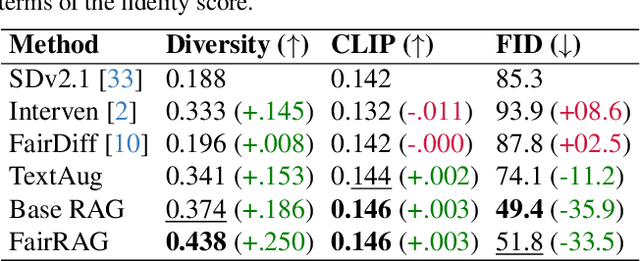
Existing text-to-image generative models reflect or even amplify societal biases ingrained in their training data. This is especially concerning for human image generation where models are biased against certain demographic groups. Existing attempts to rectify this issue are hindered by the inherent limitations of the pre-trained models and fail to substantially improve demographic diversity. In this work, we introduce Fair Retrieval Augmented Generation (FairRAG), a novel framework that conditions pre-trained generative models on reference images retrieved from an external image database to improve fairness in human generation. FairRAG enables conditioning through a lightweight linear module that projects reference images into the textual space. To enhance fairness, FairRAG applies simple-yet-effective debiasing strategies, providing images from diverse demographic groups during the generative process. Extensive experiments demonstrate that FairRAG outperforms existing methods in terms of demographic diversity, image-text alignment, and image fidelity while incurring minimal computational overhead during inference.
Attention-based Shape-Deformation Networks for Artifact-Free Geometry Reconstruction of Lumbar Spine from MR Images
Mar 30, 2024Lumbar disc degeneration, a progressive structural wear and tear of lumbar intervertebral disc, is regarded as an essential role on low back pain, a significant global health concern. Automated lumbar spine geometry reconstruction from MR images will enable fast measurement of medical parameters to evaluate the lumbar status, in order to determine a suitable treatment. Existing image segmentation-based techniques often generate erroneous segments or unstructured point clouds, unsuitable for medical parameter measurement. In this work, we present TransDeformer: a novel attention-based deep learning approach that reconstructs the contours of the lumbar spine with high spatial accuracy and mesh correspondence across patients, and we also present a variant of TransDeformer for error estimation. Specially, we devise new attention modules with a new attention formula, which integrates image features and tokenized contour features to predict the displacements of the points on a shape template without the need for image segmentation. The deformed template reveals the lumbar spine geometry in the input image. We develop a multi-stage training strategy to enhance model robustness with respect to template initialization. Experiment results show that our TransDeformer generates artifact-free geometry outputs, and its variant predicts the error of a reconstructed geometry. Our code is available at https://github.com/linchenq/TransDeformer-Mesh.
Safeguarding Medical Image Segmentation Datasets against Unauthorized Training via Contour- and Texture-Aware Perturbations
Mar 21, 2024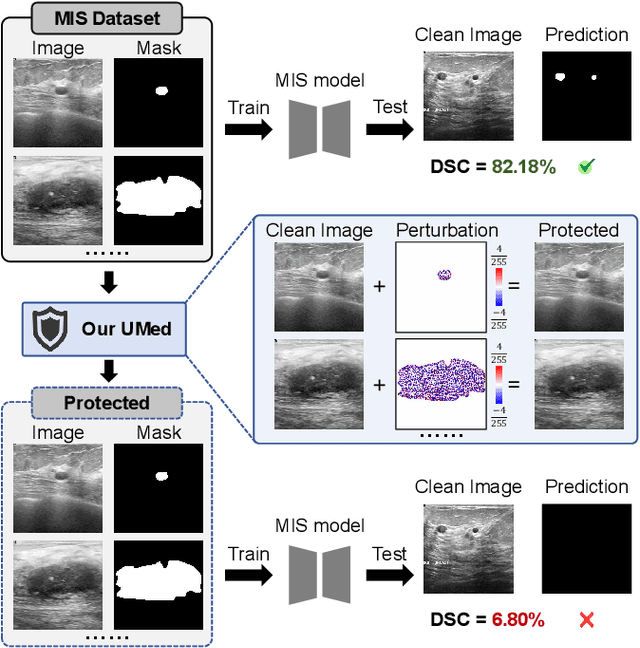
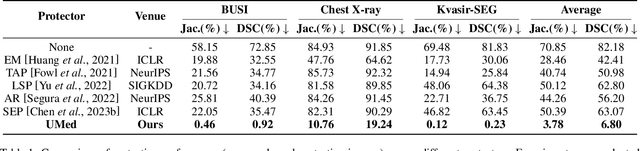
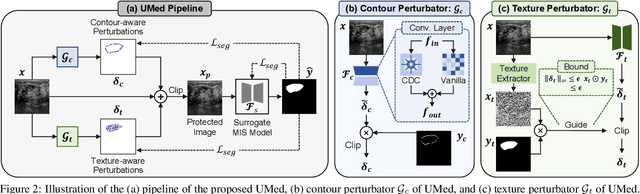
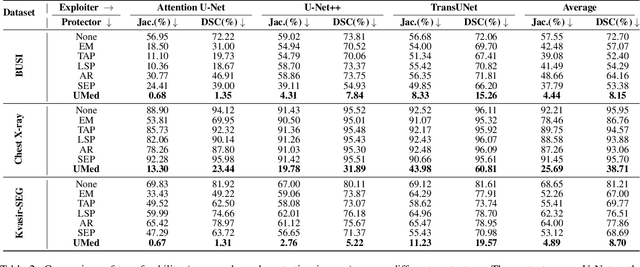
The widespread availability of publicly accessible medical images has significantly propelled advancements in various research and clinical fields. Nonetheless, concerns regarding unauthorized training of AI systems for commercial purposes and the duties of patient privacy protection have led numerous institutions to hesitate to share their images. This is particularly true for medical image segmentation (MIS) datasets, where the processes of collection and fine-grained annotation are time-intensive and laborious. Recently, Unlearnable Examples (UEs) methods have shown the potential to protect images by adding invisible shortcuts. These shortcuts can prevent unauthorized deep neural networks from generalizing. However, existing UEs are designed for natural image classification and fail to protect MIS datasets imperceptibly as their protective perturbations are less learnable than important prior knowledge in MIS, e.g., contour and texture features. To this end, we propose an Unlearnable Medical image generation method, termed UMed. UMed integrates the prior knowledge of MIS by injecting contour- and texture-aware perturbations to protect images. Given that our target is to only poison features critical to MIS, UMed requires only minimal perturbations within the ROI and its contour to achieve greater imperceptibility (average PSNR is 50.03) and protective performance (clean average DSC degrades from 82.18% to 6.80%).
AddSR: Accelerating Diffusion-based Blind Super-Resolution with Adversarial Diffusion Distillation
Apr 03, 2024Blind super-resolution methods based on stable diffusion showcase formidable generative capabilities in reconstructing clear high-resolution images with intricate details from low-resolution inputs. However, their practical applicability is often hampered by poor efficiency, stemming from the requirement of thousands or hundreds of sampling steps. Inspired by the efficient text-to-image approach adversarial diffusion distillation (ADD), we design AddSR to address this issue by incorporating the ideas of both distillation and ControlNet. Specifically, we first propose a prediction-based self-refinement strategy to provide high-frequency information in the student model output with marginal additional time cost. Furthermore, we refine the training process by employing HR images, rather than LR images, to regulate the teacher model, providing a more robust constraint for distillation. Second, we introduce a timestep-adapting loss to address the perception-distortion imbalance problem introduced by ADD. Extensive experiments demonstrate our AddSR generates better restoration results, while achieving faster speed than previous SD-based state-of-the-art models (e.g., 7x faster than SeeSR).
Multi-task Magnetic Resonance Imaging Reconstruction using Meta-learning
Mar 29, 2024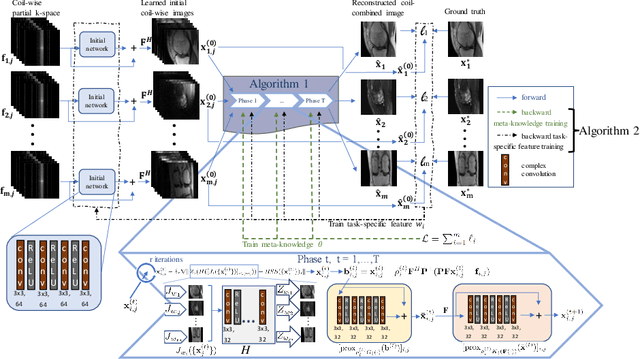

Using single-task deep learning methods to reconstruct Magnetic Resonance Imaging (MRI) data acquired with different imaging sequences is inherently challenging. The trained deep learning model typically lacks generalizability, and the dissimilarity among image datasets with different types of contrast leads to suboptimal learning performance. This paper proposes a meta-learning approach to efficiently learn image features from multiple MR image datasets. Our algorithm can perform multi-task learning to simultaneously reconstruct MR images acquired using different imaging sequences with different image contrasts. The experiment results demonstrate the ability of our new meta-learning reconstruction method to successfully reconstruct highly-undersampled k-space data from multiple MRI datasets simultaneously, outperforming other compelling reconstruction methods previously developed for single-task learning.
TraveLER: A Multi-LMM Agent Framework for Video Question-Answering
Apr 01, 2024Recently, Large Multimodal Models (LMMs) have made significant progress in video question-answering using a frame-wise approach by leveraging large-scale, image-based pretraining in a zero-shot manner. While image-based methods for videos have shown impressive performance, a current limitation is that they often overlook how key timestamps are selected and cannot adjust when incorrect timestamps are identified. Moreover, they are unable to extract details relevant to the question, instead providing general descriptions of the frame. To overcome this, we design a multi-LMM agent framework that travels along the video, iteratively collecting relevant information from keyframes through interactive question-asking until there is sufficient information to answer the question. Specifically, we propose TraveLER, a model that can create a plan to "Traverse" through the video, ask questions about individual frames to "Locate" and store key information, and then "Evaluate" if there is enough information to answer the question. Finally, if there is not enough information, our method is able to "Replan" based on its collected knowledge. Through extensive experiments, we find that the proposed TraveLER approach improves performance on several video question-answering benchmarks, such as NExT-QA, STAR, and Perception Test, without the need to fine-tune on specific datasets.
Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want
Apr 01, 2024
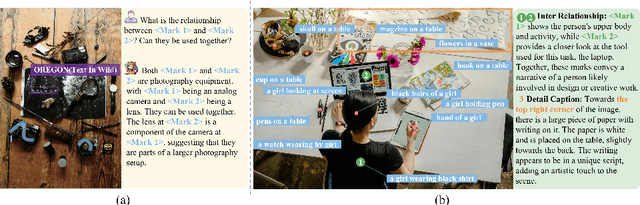
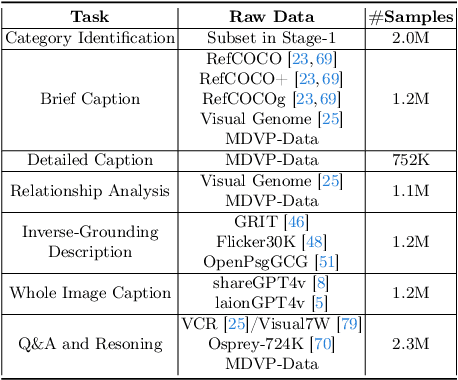
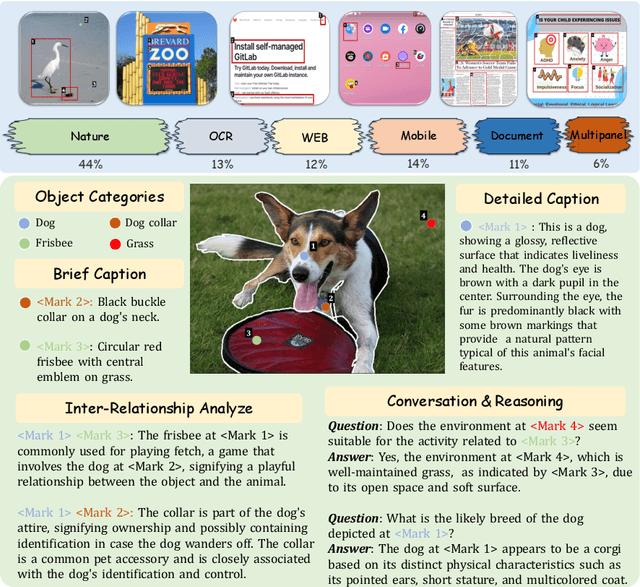
The interaction between humans and artificial intelligence (AI) is a crucial factor that reflects the effectiveness of multimodal large language models (MLLMs). However, current MLLMs primarily focus on image-level comprehension and limit interaction to textual instructions, thereby constraining their flexibility in usage and depth of response. In this paper, we introduce the Draw-and-Understand project: a new model, a multi-domain dataset, and a challenging benchmark for visual prompting. Specifically, we propose SPHINX-V, a new end-to-end trained Multimodal Large Language Model (MLLM) that connects a vision encoder, a visual prompt encoder and an LLM for various visual prompts (points, bounding boxes, and free-form shape) and language understanding. To advance visual prompting research for MLLMs, we introduce MDVP-Data and MDVP-Bench. MDVP-Data features a multi-domain dataset containing 1.6M unique image-visual prompt-text instruction-following samples, including natural images, document images, OCR images, mobile screenshots, web screenshots, and multi-panel images. Furthermore, we present MDVP-Bench, a comprehensive and challenging benchmark to assess a model's capability in understanding visual prompting instructions. Our experiments demonstrate SPHINX-V's impressive multimodal interaction capabilities through visual prompting, revealing significant improvements in detailed pixel-level description and question-answering abilities.
Monocular Identity-Conditioned Facial Reflectance Reconstruction
Mar 30, 2024Recent 3D face reconstruction methods have made remarkable advancements, yet there remain huge challenges in monocular high-quality facial reflectance reconstruction. Existing methods rely on a large amount of light-stage captured data to learn facial reflectance models. However, the lack of subject diversity poses challenges in achieving good generalization and widespread applicability. In this paper, we learn the reflectance prior in image space rather than UV space and present a framework named ID2Reflectance. Our framework can directly estimate the reflectance maps of a single image while using limited reflectance data for training. Our key insight is that reflectance data shares facial structures with RGB faces, which enables obtaining expressive facial prior from inexpensive RGB data thus reducing the dependency on reflectance data. We first learn a high-quality prior for facial reflectance. Specifically, we pretrain multi-domain facial feature codebooks and design a codebook fusion method to align the reflectance and RGB domains. Then, we propose an identity-conditioned swapping module that injects facial identity from the target image into the pre-trained autoencoder to modify the identity of the source reflectance image. Finally, we stitch multi-view swapped reflectance images to obtain renderable assets. Extensive experiments demonstrate that our method exhibits excellent generalization capability and achieves state-of-the-art facial reflectance reconstruction results for in-the-wild faces. Our project page is https://xingyuren.github.io/id2reflectance/.
Attire-Based Anomaly Detection in Restricted Areas Using YOLOv8 for Enhanced CCTV Security
Mar 31, 2024This research introduces an innovative security enhancement approach, employing advanced image analysis and soft computing. The focus is on an intelligent surveillance system that detects unauthorized individuals in restricted areas by analyzing attire. Traditional security measures face challenges in monitoring unauthorized access. Leveraging YOLOv8, an advanced object detection algorithm, our system identifies authorized personnel based on their attire in CCTV footage. The methodology involves training the YOLOv8 model on a comprehensive dataset of uniform patterns, ensuring precise recognition in specific regions. Soft computing techniques enhance adaptability to dynamic environments and varying lighting conditions. This research contributes to image analysis and soft computing, providing a sophisticated security solution. Emphasizing uniform-based anomaly detection, it establishes a foundation for robust security systems in restricted areas. The outcomes highlight the potential of YOLOv8-based surveillance in ensuring safety in sensitive locations.
One-Step Image Translation with Text-to-Image Models
Mar 18, 2024
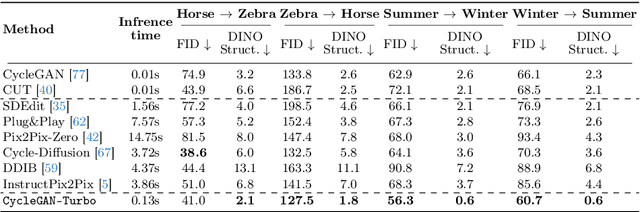
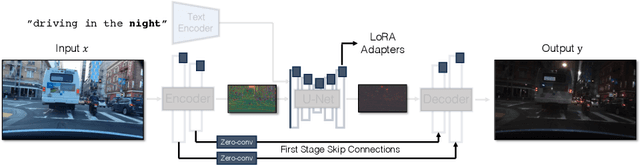
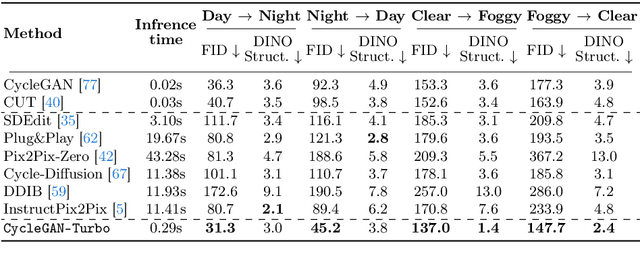
In this work, we address two limitations of existing conditional diffusion models: their slow inference speed due to the iterative denoising process and their reliance on paired data for model fine-tuning. To tackle these issues, we introduce a general method for adapting a single-step diffusion model to new tasks and domains through adversarial learning objectives. Specifically, we consolidate various modules of the vanilla latent diffusion model into a single end-to-end generator network with small trainable weights, enhancing its ability to preserve the input image structure while reducing overfitting. We demonstrate that, for unpaired settings, our model CycleGAN-Turbo outperforms existing GAN-based and diffusion-based methods for various scene translation tasks, such as day-to-night conversion and adding/removing weather effects like fog, snow, and rain. We extend our method to paired settings, where our model pix2pix-Turbo is on par with recent works like Control-Net for Sketch2Photo and Edge2Image, but with a single-step inference. This work suggests that single-step diffusion models can serve as strong backbones for a range of GAN learning objectives. Our code and models are available at https://github.com/GaParmar/img2img-turbo.