 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Face Identity-Aware Disentanglement in StyleGAN
Sep 21, 2023

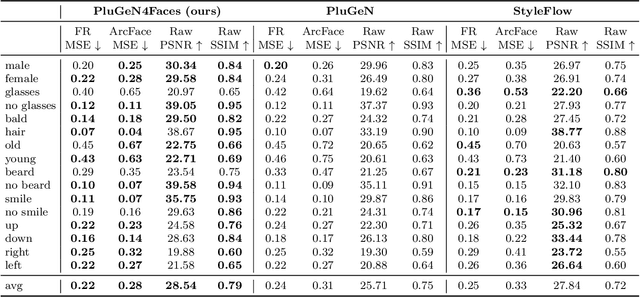
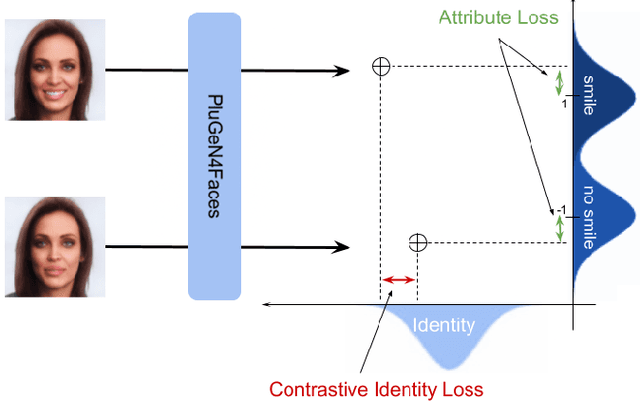
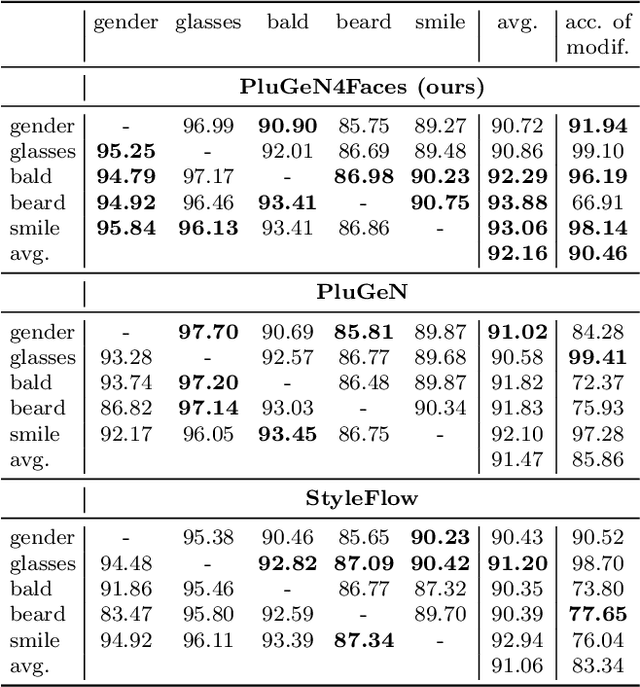
Conditional GANs are frequently used for manipulating the attributes of face images, such as expression, hairstyle, pose, or age. Even though the state-of-the-art models successfully modify the requested attributes, they simultaneously modify other important characteristics of the image, such as a person's identity. In this paper, we focus on solving this problem by introducing PluGeN4Faces, a plugin to StyleGAN, which explicitly disentangles face attributes from a person's identity. Our key idea is to perform training on images retrieved from movie frames, where a given person appears in various poses and with different attributes. By applying a type of contrastive loss, we encourage the model to group images of the same person in similar regions of latent space. Our experiments demonstrate that the modifications of face attributes performed by PluGeN4Faces are significantly less invasive on the remaining characteristics of the image than in the existing state-of-the-art models.
Improving Medical Image Classification in Noisy Labels Using Only Self-supervised Pretraining
Aug 08, 2023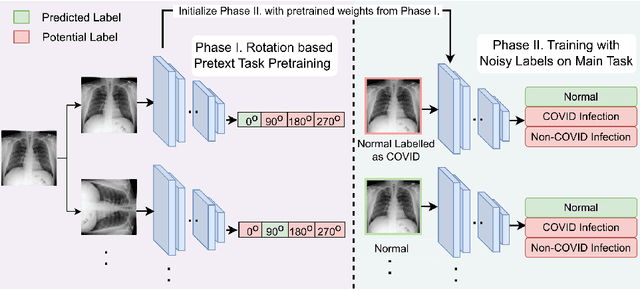
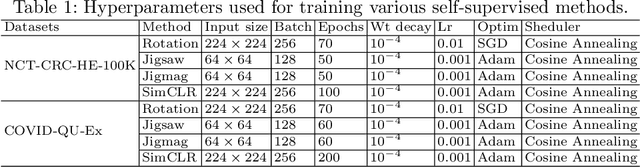
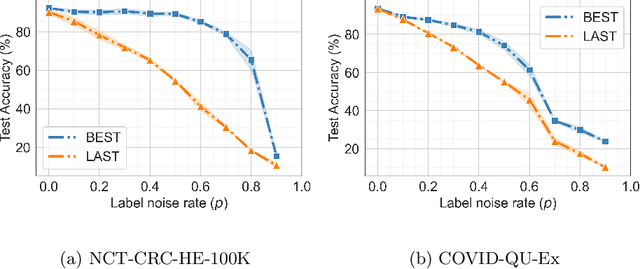
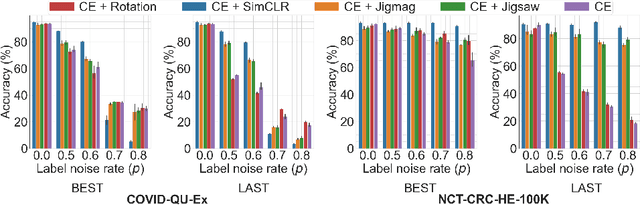
Noisy labels hurt deep learning-based supervised image classification performance as the models may overfit the noise and learn corrupted feature extractors. For natural image classification training with noisy labeled data, model initialization with contrastive self-supervised pretrained weights has shown to reduce feature corruption and improve classification performance. However, no works have explored: i) how other self-supervised approaches, such as pretext task-based pretraining, impact the learning with noisy label, and ii) any self-supervised pretraining methods alone for medical images in noisy label settings. Medical images often feature smaller datasets and subtle inter class variations, requiring human expertise to ensure correct classification. Thus, it is not clear if the methods improving learning with noisy labels in natural image datasets such as CIFAR would also help with medical images. In this work, we explore contrastive and pretext task-based self-supervised pretraining to initialize the weights of a deep learning classification model for two medical datasets with self-induced noisy labels -- NCT-CRC-HE-100K tissue histological images and COVID-QU-Ex chest X-ray images. Our results show that models initialized with pretrained weights obtained from self-supervised learning can effectively learn better features and improve robustness against noisy labels.
PromptPaint: Steering Text-to-Image Generation Through Paint Medium-like Interactions
Aug 09, 2023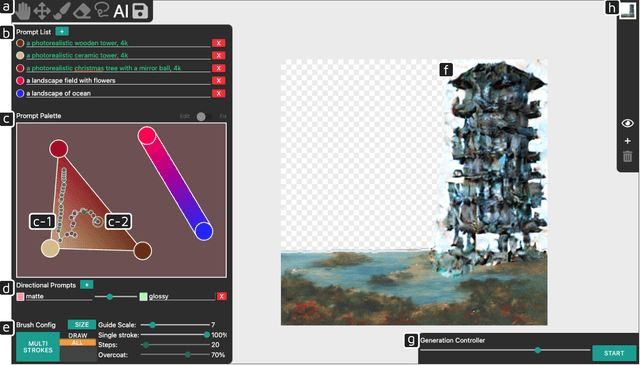

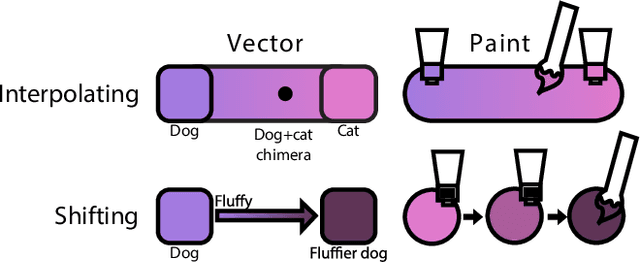

While diffusion-based text-to-image (T2I) models provide a simple and powerful way to generate images, guiding this generation remains a challenge. For concepts that are difficult to describe through language, users may struggle to create prompts. Moreover, many of these models are built as end-to-end systems, lacking support for iterative shaping of the image. In response, we introduce PromptPaint, which combines T2I generation with interactions that model how we use colored paints. PromptPaint allows users to go beyond language to mix prompts that express challenging concepts. Just as we iteratively tune colors through layered placements of paint on a physical canvas, PromptPaint similarly allows users to apply different prompts to different canvas areas and times of the generative process. Through a set of studies, we characterize different approaches for mixing prompts, design trade-offs, and socio-technical challenges for generative models. With PromptPaint we provide insight into future steerable generative tools.
YODA: You Only Diffuse Areas. An Area-Masked Diffusion Approach For Image Super-Resolution
Aug 15, 2023
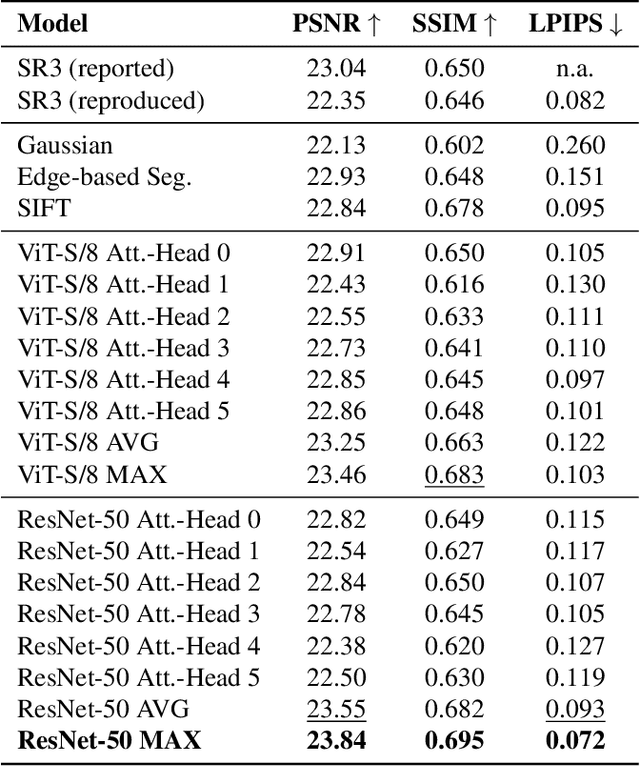
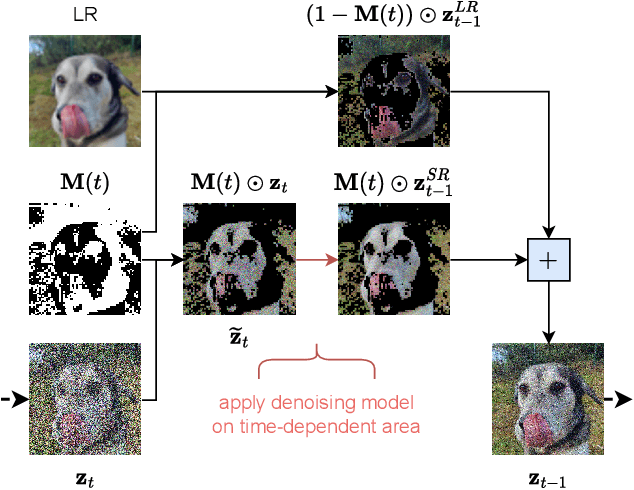
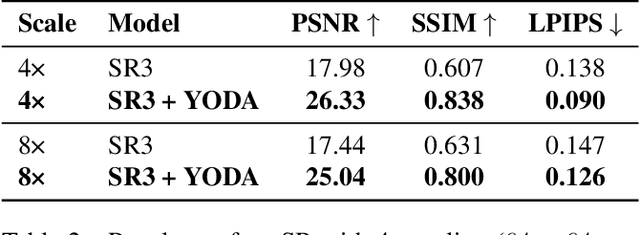
This work introduces "You Only Diffuse Areas" (YODA), a novel method for partial diffusion in Single-Image Super-Resolution (SISR). The core idea is to utilize diffusion selectively on spatial regions based on attention maps derived from the low-resolution image and the current time step in the diffusion process. This time-dependent targeting enables a more effective conversion to high-resolution outputs by focusing on areas that benefit the most from the iterative refinement process, i.e., detail-rich objects. We empirically validate YODA by extending leading diffusion-based SISR methods SR3 and SRDiff. Our experiments demonstrate new state-of-the-art performance gains in face and general SR across PSNR, SSIM, and LPIPS metrics. A notable finding is YODA's stabilization effect on training by reducing color shifts, especially when induced by small batch sizes, potentially contributing to resource-constrained scenarios. The proposed spatial and temporal adaptive diffusion mechanism opens promising research directions, including developing enhanced attention map extraction techniques and optimizing inference latency based on sparser diffusion.
DreamLLM: Synergistic Multimodal Comprehension and Creation
Sep 20, 2023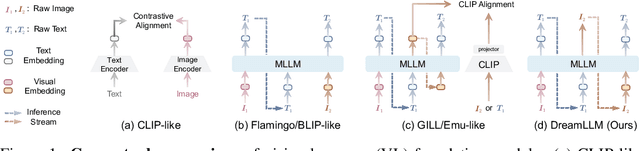
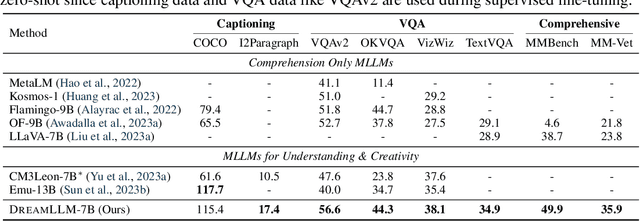
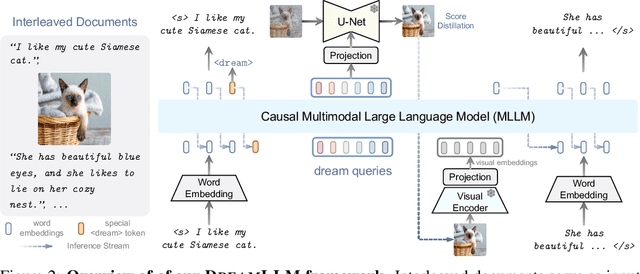
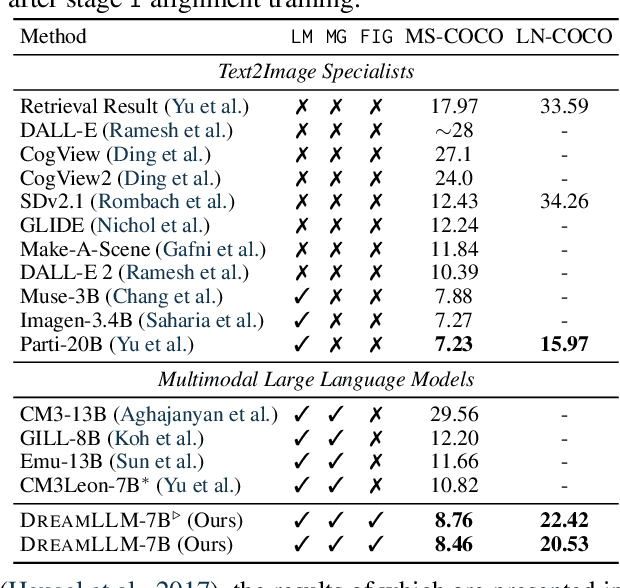
This paper presents DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models (MLLMs) empowered with frequently overlooked synergy between multimodal comprehension and creation. DreamLLM operates on two fundamental principles. The first focuses on the generative modeling of both language and image posteriors by direct sampling in the raw multimodal space. This approach circumvents the limitations and information loss inherent to external feature extractors like CLIP, and a more thorough multimodal understanding is obtained. Second, DreamLLM fosters the generation of raw, interleaved documents, modeling both text and image contents, along with unstructured layouts. This allows DreamLLM to learn all conditional, marginal, and joint multimodal distributions effectively. As a result, DreamLLM is the first MLLM capable of generating free-form interleaved content. Comprehensive experiments highlight DreamLLM's superior performance as a zero-shot multimodal generalist, reaping from the enhanced learning synergy.
Enhancing Sharpness-Aware Optimization Through Variance Suppression
Sep 28, 2023Sharpness-aware minimization (SAM) has well documented merits in enhancing generalization of deep neural networks, even without sizable data augmentation. Embracing the geometry of the loss function, where neighborhoods of 'flat minima' heighten generalization ability, SAM seeks 'flat valleys' by minimizing the maximum loss caused by an adversary perturbing parameters within the neighborhood. Although critical to account for sharpness of the loss function, such an 'over-friendly adversary' can curtail the outmost level of generalization. The novel approach of this contribution fosters stabilization of adversaries through variance suppression (VaSSO) to avoid such friendliness. VaSSO's provable stability safeguards its numerical improvement over SAM in model-agnostic tasks, including image classification and machine translation. In addition, experiments confirm that VaSSO endows SAM with robustness against high levels of label noise.
CCEdit: Creative and Controllable Video Editing via Diffusion Models
Sep 28, 2023
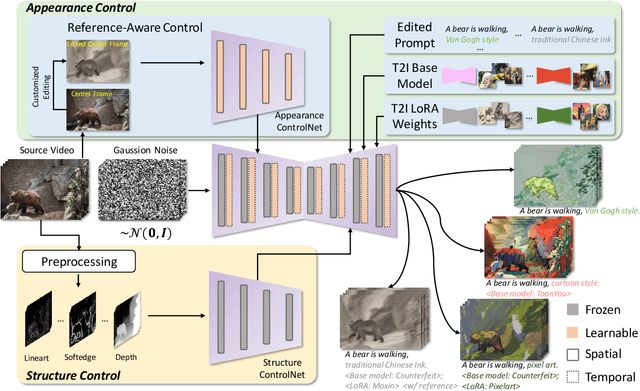
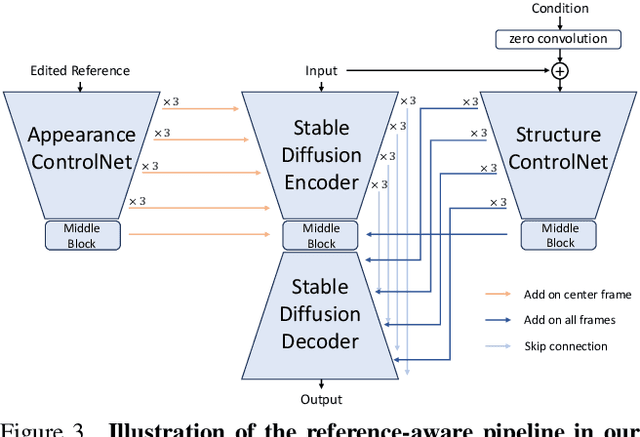
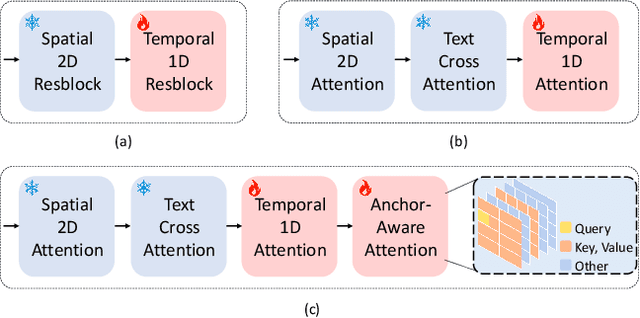
In this work, we present CCEdit, a versatile framework designed to address the challenges of creative and controllable video editing. CCEdit accommodates a wide spectrum of user editing requirements and enables enhanced creative control through an innovative approach that decouples video structure and appearance. We leverage the foundational ControlNet architecture to preserve structural integrity, while seamlessly integrating adaptable temporal modules compatible with state-of-the-art personalization techniques for text-to-image generation, such as DreamBooth and LoRA.Furthermore, we introduce reference-conditioned video editing, empowering users to exercise precise creative control over video editing through the more manageable process of editing key frames. Our extensive experimental evaluations confirm the exceptional functionality and editing capabilities of the proposed CCEdit framework. Demo video is available at https://www.youtube.com/watch?v=UQw4jq-igN4.
Two-Step Active Learning for Instance Segmentation with Uncertainty and Diversity Sampling
Sep 28, 2023Training high-quality instance segmentation models requires an abundance of labeled images with instance masks and classifications, which is often expensive to procure. Active learning addresses this challenge by striving for optimum performance with minimal labeling cost by selecting the most informative and representative images for labeling. Despite its potential, active learning has been less explored in instance segmentation compared to other tasks like image classification, which require less labeling. In this study, we propose a post-hoc active learning algorithm that integrates uncertainty-based sampling with diversity-based sampling. Our proposed algorithm is not only simple and easy to implement, but it also delivers superior performance on various datasets. Its practical application is demonstrated on a real-world overhead imagery dataset, where it increases the labeling efficiency fivefold.
Intriguing properties of generative classifiers
Sep 28, 2023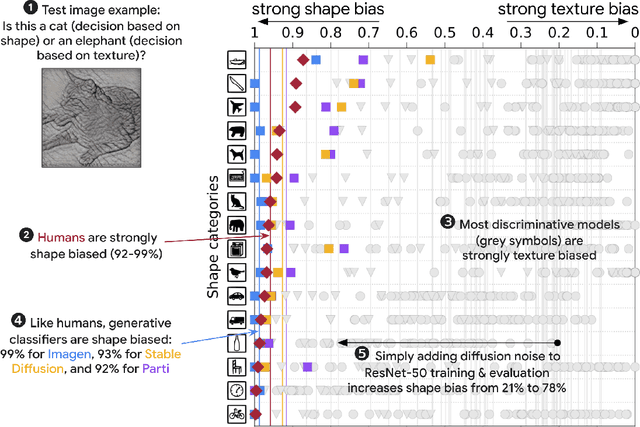
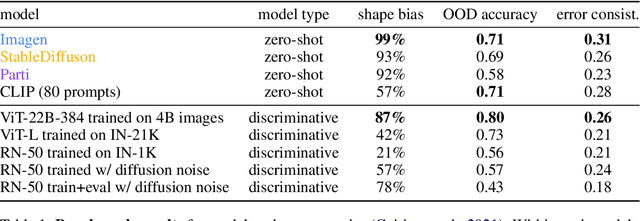

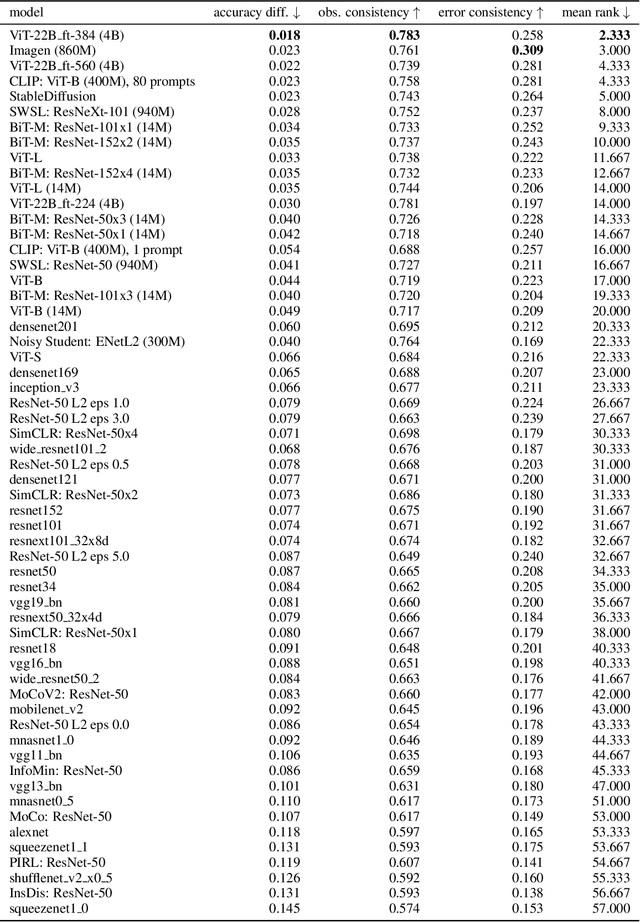
What is the best paradigm to recognize objects -- discriminative inference (fast but potentially prone to shortcut learning) or using a generative model (slow but potentially more robust)? We build on recent advances in generative modeling that turn text-to-image models into classifiers. This allows us to study their behavior and to compare them against discriminative models and human psychophysical data. We report four intriguing emergent properties of generative classifiers: they show a record-breaking human-like shape bias (99% for Imagen), near human-level out-of-distribution accuracy, state-of-the-art alignment with human classification errors, and they understand certain perceptual illusions. Our results indicate that while the current dominant paradigm for modeling human object recognition is discriminative inference, zero-shot generative models approximate human object recognition data surprisingly well.
Masked-Attention Diffusion Guidance for Spatially Controlling Text-to-Image Generation
Aug 11, 2023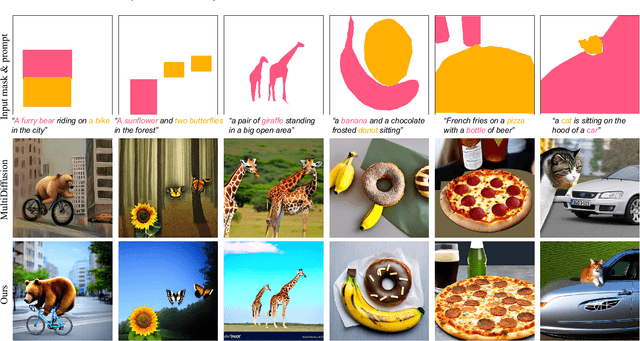

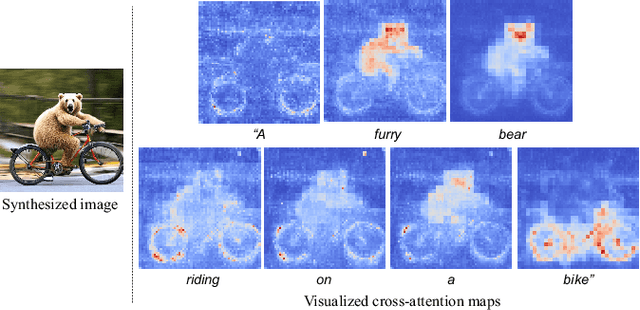
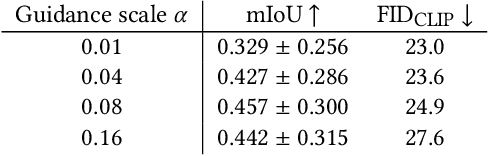
Text-to-image synthesis has achieved high-quality results with recent advances in diffusion models. However, text input alone has high spatial ambiguity and limited user controllability. Most existing methods allow spatial control through additional visual guidance (e.g, sketches and semantic masks) but require additional training with annotated images. In this paper, we propose a method for spatially controlling text-to-image generation without further training of diffusion models. Our method is based on the insight that the cross-attention maps reflect the positional relationship between words and pixels. Our aim is to control the attention maps according to given semantic masks and text prompts. To this end, we first explore a simple approach of directly swapping the cross-attention maps with constant maps computed from the semantic regions. Moreover, we propose masked-attention guidance, which can generate images more faithful to semantic masks than the first approach. Masked-attention guidance indirectly controls attention to each word and pixel according to the semantic regions by manipulating noise images fed to diffusion models. Experiments show that our method enables more accurate spatial control than baselines qualitatively and quantitatively.