 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Locally Stylized Neural Radiance Fields
Sep 19, 2023
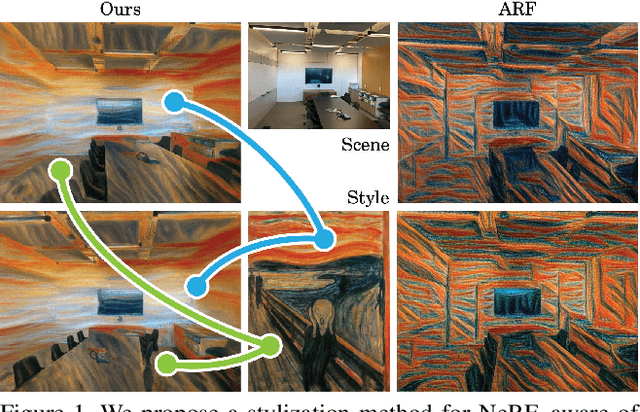

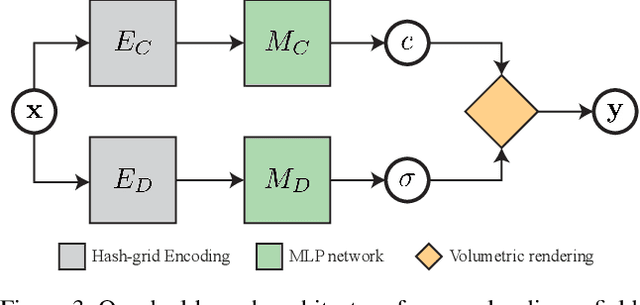

In recent years, there has been increasing interest in applying stylization on 3D scenes from a reference style image, in particular onto neural radiance fields (NeRF). While performing stylization directly on NeRF guarantees appearance consistency over arbitrary novel views, it is a challenging problem to guide the transfer of patterns from the style image onto different parts of the NeRF scene. In this work, we propose a stylization framework for NeRF based on local style transfer. In particular, we use a hash-grid encoding to learn the embedding of the appearance and geometry components, and show that the mapping defined by the hash table allows us to control the stylization to a certain extent. Stylization is then achieved by optimizing the appearance branch while keeping the geometry branch fixed. To support local style transfer, we propose a new loss function that utilizes a segmentation network and bipartite matching to establish region correspondences between the style image and the content images obtained from volume rendering. Our experiments show that our method yields plausible stylization results with novel view synthesis while having flexible controllability via manipulating and customizing the region correspondences.
MiAMix: Enhancing Image Classification through a Multi-stage Augmented Mixed Sample Data Augmentation Method
Aug 15, 2023
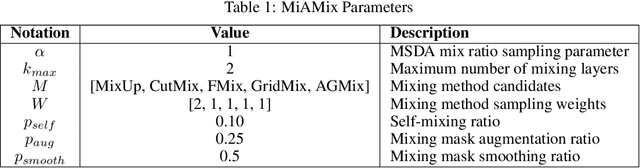
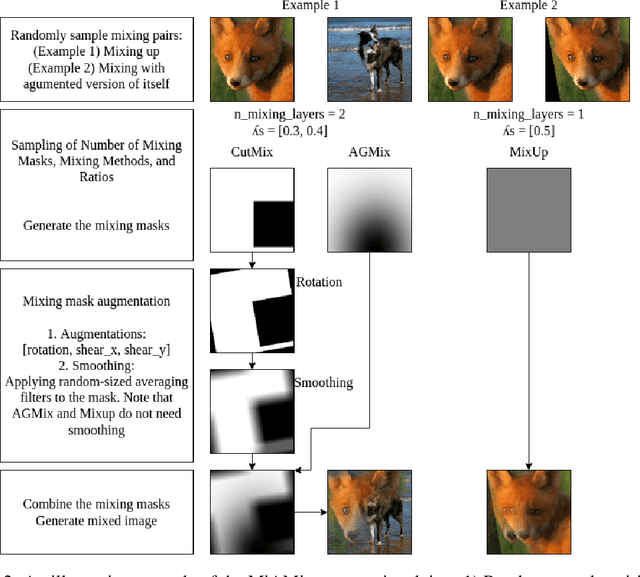
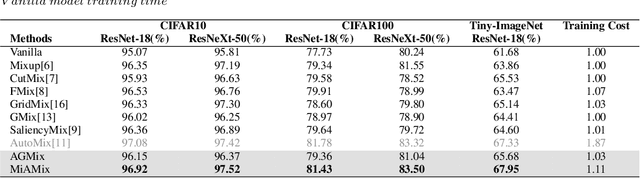
Despite substantial progress in the field of deep learning, overfitting persists as a critical challenge, and data augmentation has emerged as a particularly promising approach due to its capacity to enhance model generalization in various computer vision tasks. While various strategies have been proposed, Mixed Sample Data Augmentation (MSDA) has shown great potential for enhancing model performance and generalization. We introduce a novel mixup method called MiAMix, which stands for Multi-stage Augmented Mixup. MiAMix integrates image augmentation into the mixup framework, utilizes multiple diversified mixing methods concurrently, and improves the mixing method by randomly selecting mixing mask augmentation methods. Recent methods utilize saliency information and the MiAMix is designed for computational efficiency as well, reducing additional overhead and offering easy integration into existing training pipelines. We comprehensively evaluate MiaMix using four image benchmarks and pitting it against current state-of-the-art mixed sample data augmentation techniques to demonstrate that MIAMix improves performance without heavy computational overhead.
Parametric entropy based Cluster Centriod Initialization for k-means clustering of various Image datasets
Aug 15, 2023
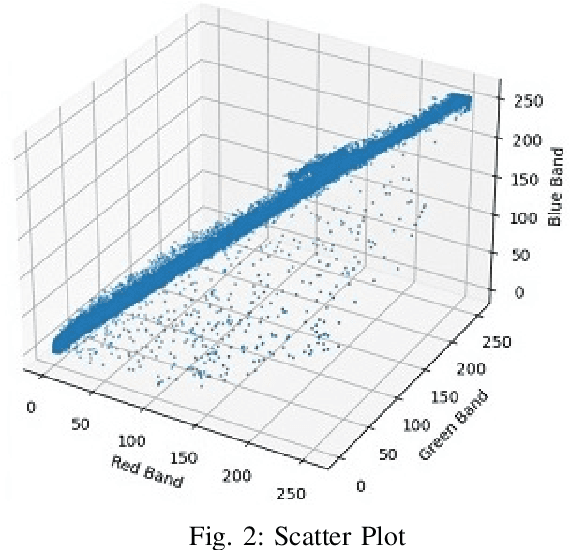
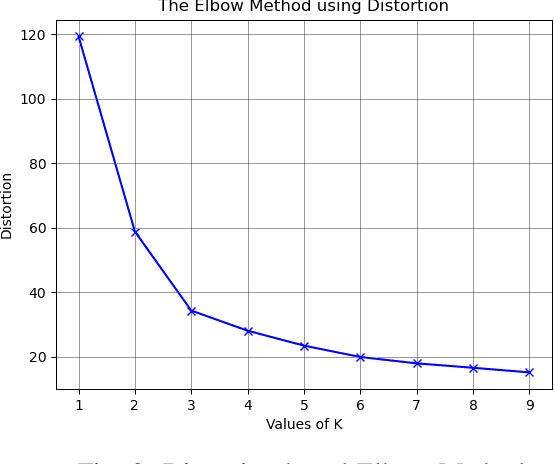
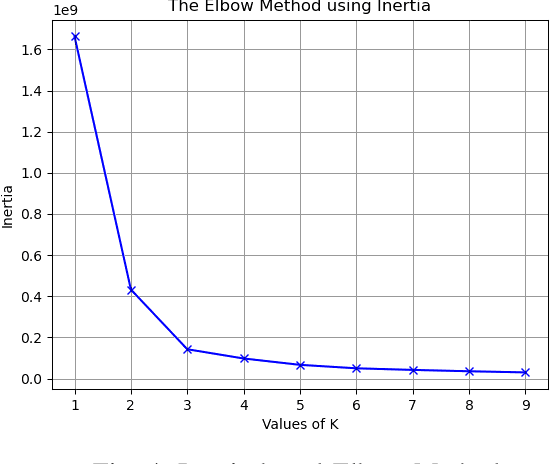
One of the most employed yet simple algorithm for cluster analysis is the k-means algorithm. k-means has successfully witnessed its use in artificial intelligence, market segmentation, fraud detection, data mining, psychology, etc., only to name a few. The k-means algorithm, however, does not always yield the best quality results. Its performance heavily depends upon the number of clusters supplied and the proper initialization of the cluster centroids or seeds. In this paper, we conduct an analysis of the performance of k-means on image data by employing parametric entropies in an entropy based centroid initialization method and propose the best fitting entropy measures for general image datasets. We use several entropies like Taneja entropy, Kapur entropy, Aczel Daroczy entropy, Sharma Mittal entropy. We observe that for different datasets, different entropies provide better results than the conventional methods. We have applied our proposed algorithm on these datasets: Satellite, Toys, Fruits, Cars, Brain MRI, Covid X-Ray.
Deep Richardson-Lucy Deconvolution for Low-Light Image Deblurring
Aug 10, 2023
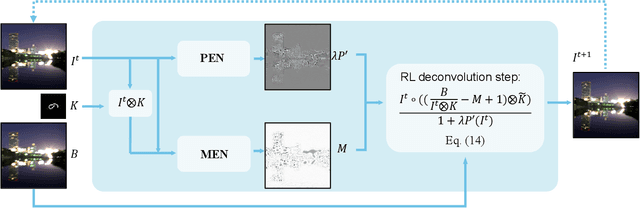

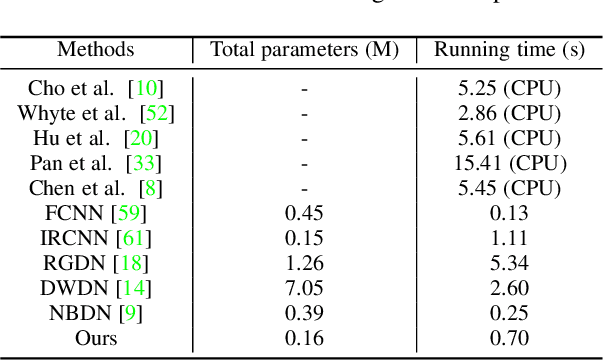
Images taken under the low-light condition often contain blur and saturated pixels at the same time. Deblurring images with saturated pixels is quite challenging. Because of the limited dynamic range, the saturated pixels are usually clipped in the imaging process and thus cannot be modeled by the linear blur model. Previous methods use manually designed smooth functions to approximate the clipping procedure. Their deblurring processes often require empirically defined parameters, which may not be the optimal choices for different images. In this paper, we develop a data-driven approach to model the saturated pixels by a learned latent map. Based on the new model, the non-blind deblurring task can be formulated into a maximum a posterior (MAP) problem, which can be effectively solved by iteratively computing the latent map and the latent image. Specifically, the latent map is computed by learning from a map estimation network (MEN), and the latent image estimation process is implemented by a Richardson-Lucy (RL)-based updating scheme. To estimate high-quality deblurred images without amplified artifacts, we develop a prior estimation network (PEN) to obtain prior information, which is further integrated into the RL scheme. Experimental results demonstrate that the proposed method performs favorably against state-of-the-art algorithms both quantitatively and qualitatively on synthetic and real-world images.
Text2Layer: Layered Image Generation using Latent Diffusion Model
Jul 19, 2023



Layer compositing is one of the most popular image editing workflows among both amateurs and professionals. Motivated by the success of diffusion models, we explore layer compositing from a layered image generation perspective. Instead of generating an image, we propose to generate background, foreground, layer mask, and the composed image simultaneously. To achieve layered image generation, we train an autoencoder that is able to reconstruct layered images and train diffusion models on the latent representation. One benefit of the proposed problem is to enable better compositing workflows in addition to the high-quality image output. Another benefit is producing higher-quality layer masks compared to masks produced by a separate step of image segmentation. Experimental results show that the proposed method is able to generate high-quality layered images and initiates a benchmark for future work.
FourLLIE: Boosting Low-Light Image Enhancement by Fourier Frequency Information
Aug 06, 2023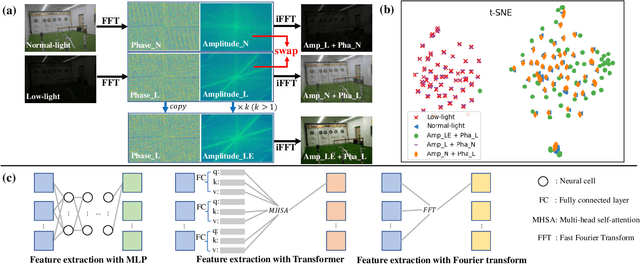
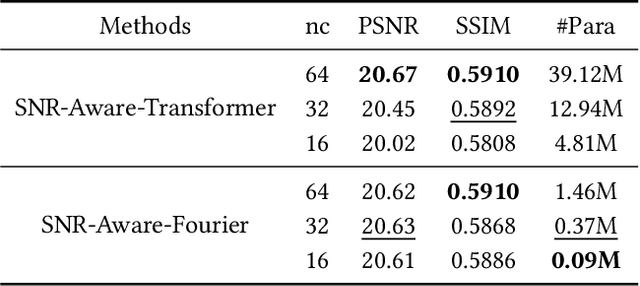
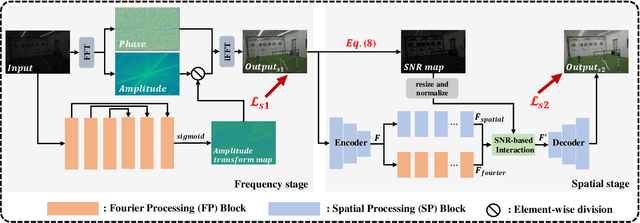
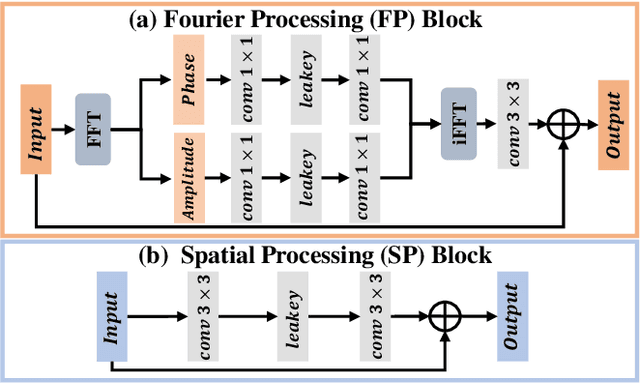
Recently, Fourier frequency information has attracted much attention in Low-Light Image Enhancement (LLIE). Some researchers noticed that, in the Fourier space, the lightness degradation mainly exists in the amplitude component and the rest exists in the phase component. By incorporating both the Fourier frequency and the spatial information, these researchers proposed remarkable solutions for LLIE. In this work, we further explore the positive correlation between the magnitude of amplitude and the magnitude of lightness, which can be effectively leveraged to improve the lightness of low-light images in the Fourier space. Moreover, we find that the Fourier transform can extract the global information of the image, and does not introduce massive neural network parameters like Multi-Layer Perceptrons (MLPs) or Transformer. To this end, a two-stage Fourier-based LLIE network (FourLLIE) is proposed. In the first stage, we improve the lightness of low-light images by estimating the amplitude transform map in the Fourier space. In the second stage, we introduce the Signal-to-Noise-Ratio (SNR) map to provide the prior for integrating the global Fourier frequency and the local spatial information, which recovers image details in the spatial space. With this ingenious design, FourLLIE outperforms the existing state-of-the-art (SOTA) LLIE methods on four representative datasets while maintaining good model efficiency.
3D-U-SAM Network For Few-shot Tooth Segmentation in CBCT Images
Sep 20, 2023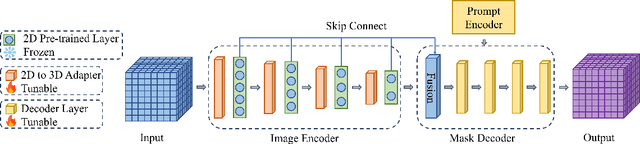
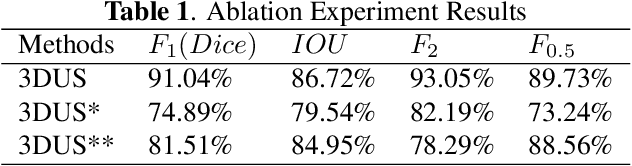
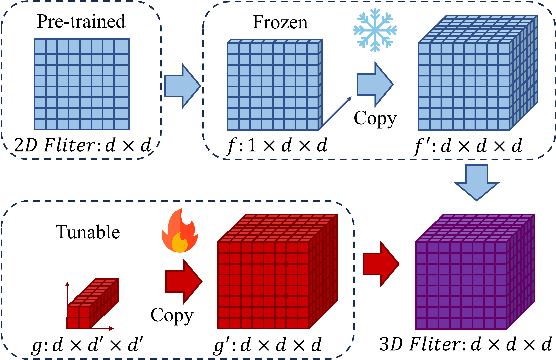
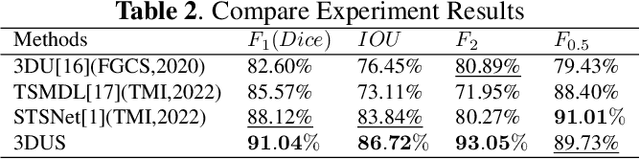
Accurate representation of tooth position is extremely important in treatment. 3D dental image segmentation is a widely used method, however labelled 3D dental datasets are a scarce resource, leading to the problem of small samples that this task faces in many cases. To this end, we address this problem with a pretrained SAM and propose a novel 3D-U-SAM network for 3D dental image segmentation. Specifically, in order to solve the problem of using 2D pre-trained weights on 3D datasets, we adopted a convolution approximation method; in order to retain more details, we designed skip connections to fuse features at all levels with reference to U-Net. The effectiveness of the proposed method is demonstrated in ablation experiments, comparison experiments, and sample size experiments.
ImageBrush: Learning Visual In-Context Instructions for Exemplar-Based Image Manipulation
Aug 02, 2023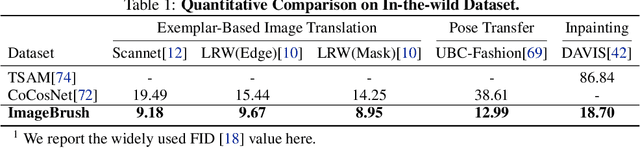
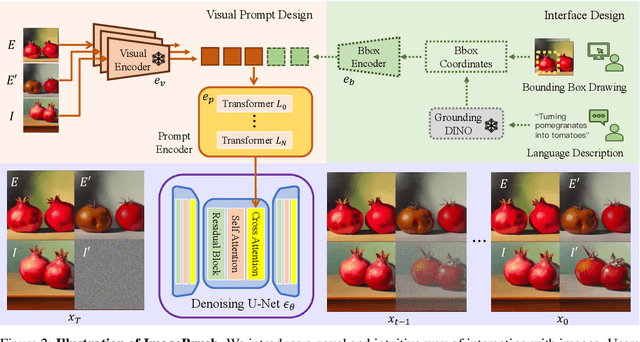

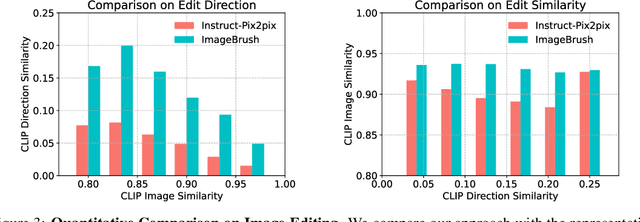
While language-guided image manipulation has made remarkable progress, the challenge of how to instruct the manipulation process faithfully reflecting human intentions persists. An accurate and comprehensive description of a manipulation task using natural language is laborious and sometimes even impossible, primarily due to the inherent uncertainty and ambiguity present in linguistic expressions. Is it feasible to accomplish image manipulation without resorting to external cross-modal language information? If this possibility exists, the inherent modality gap would be effortlessly eliminated. In this paper, we propose a novel manipulation methodology, dubbed ImageBrush, that learns visual instructions for more accurate image editing. Our key idea is to employ a pair of transformation images as visual instructions, which not only precisely captures human intention but also facilitates accessibility in real-world scenarios. Capturing visual instructions is particularly challenging because it involves extracting the underlying intentions solely from visual demonstrations and then applying this operation to a new image. To address this challenge, we formulate visual instruction learning as a diffusion-based inpainting problem, where the contextual information is fully exploited through an iterative process of generation. A visual prompting encoder is carefully devised to enhance the model's capacity in uncovering human intent behind the visual instructions. Extensive experiments show that our method generates engaging manipulation results conforming to the transformations entailed in demonstrations. Moreover, our model exhibits robust generalization capabilities on various downstream tasks such as pose transfer, image translation and video inpainting.
Consistency Models as a Rich and Efficient Policy Class for Reinforcement Learning
Sep 29, 2023Score-based generative models like the diffusion model have been testified to be effective in modeling multi-modal data from image generation to reinforcement learning (RL). However, the inference process of diffusion model can be slow, which hinders its usage in RL with iterative sampling. We propose to apply the consistency model as an efficient yet expressive policy representation, namely consistency policy, with an actor-critic style algorithm for three typical RL settings: offline, offline-to-online and online. For offline RL, we demonstrate the expressiveness of generative models as policies from multi-modal data. For offline-to-online RL, the consistency policy is shown to be more computational efficient than diffusion policy, with a comparable performance. For online RL, the consistency policy demonstrates significant speedup and even higher average performances than the diffusion policy.
Generalized Schrödinger Bridge Matching
Oct 03, 2023Modern distribution matching algorithms for training diffusion or flow models directly prescribe the time evolution of the marginal distributions between two boundary distributions. In this work, we consider a generalized distribution matching setup, where these marginals are only implicitly described as a solution to some task-specific objective function. The problem setup, known as the Generalized Schr\"odinger Bridge (GSB), appears prevalently in many scientific areas both within and without machine learning. We propose Generalized Schr\"odinger Bridge Matching (GSBM), a new matching algorithm inspired by recent advances, generalizing them beyond kinetic energy minimization and to account for task-specific state costs. We show that such a generalization can be cast as solving conditional stochastic optimal control, for which efficient variational approximations can be used, and further debiased with the aid of path integral theory. Compared to prior methods for solving GSB problems, our GSBM algorithm always preserves a feasible transport map between the boundary distributions throughout training, thereby enabling stable convergence and significantly improved scalability. We empirically validate our claims on an extensive suite of experimental setups, including crowd navigation, opinion depolarization, LiDAR manifolds, and image domain transfer. Our work brings new algorithmic opportunities for training diffusion models enhanced with task-specific optimality structures.