 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Class Activation Map-based Weakly supervised Hemorrhage Segmentation using Resnet-LSTM in Non-Contrast Computed Tomography images
Sep 28, 2023
In clinical settings, intracranial hemorrhages (ICH) are routinely diagnosed using non-contrast CT (NCCT) for severity assessment. Accurate automated segmentation of ICH lesions is the initial and essential step, immensely useful for such assessment. However, compared to other structural imaging modalities such as MRI, in NCCT images ICH appears with very low contrast and poor SNR. Over recent years, deep learning (DL)-based methods have shown great potential, however, training them requires a huge amount of manually annotated lesion-level labels, with sufficient diversity to capture the characteristics of ICH. In this work, we propose a novel weakly supervised DL method for ICH segmentation on NCCT scans, using image-level binary classification labels, which are less time-consuming and labor-efficient when compared to the manual labeling of individual ICH lesions. Our method initially determines the approximate location of ICH using class activation maps from a classification network, which is trained to learn dependencies across contiguous slices. We further refine the ICH segmentation using pseudo-ICH masks obtained in an unsupervised manner. The method is flexible and uses a computationally light architecture during testing. On evaluating our method on the validation data of the MICCAI 2022 INSTANCE challenge, our method achieves a Dice value of 0.55, comparable with those of existing weakly supervised method (Dice value of 0.47), despite training on a much smaller training data.
Understanding Pose and Appearance Disentanglement in 3D Human Pose Estimation
Sep 20, 2023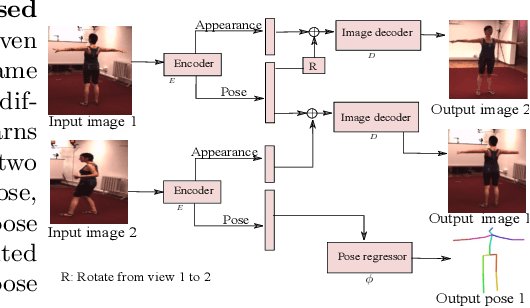
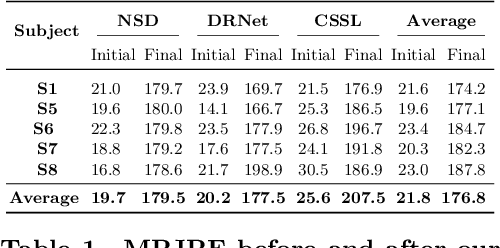


As 3D human pose estimation can now be achieved with very high accuracy in the supervised learning scenario, tackling the case where 3D pose annotations are not available has received increasing attention. In particular, several methods have proposed to learn image representations in a self-supervised fashion so as to disentangle the appearance information from the pose one. The methods then only need a small amount of supervised data to train a pose regressor using the pose-related latent vector as input, as it should be free of appearance information. In this paper, we carry out in-depth analysis to understand to what degree the state-of-the-art disentangled representation learning methods truly separate the appearance information from the pose one. First, we study disentanglement from the perspective of the self-supervised network, via diverse image synthesis experiments. Second, we investigate disentanglement with respect to the 3D pose regressor following an adversarial attack perspective. Specifically, we design an adversarial strategy focusing on generating natural appearance changes of the subject, and against which we could expect a disentangled network to be robust. Altogether, our analyses show that disentanglement in the three state-of-the-art disentangled representation learning frameworks if far from complete, and that their pose codes contain significant appearance information. We believe that our approach provides a valuable testbed to evaluate the degree of disentanglement of pose from appearance in self-supervised 3D human pose estimation.
How to turn your camera into a perfect pinhole model
Sep 20, 2023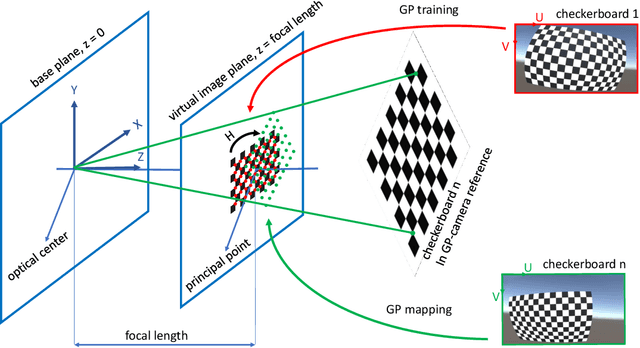
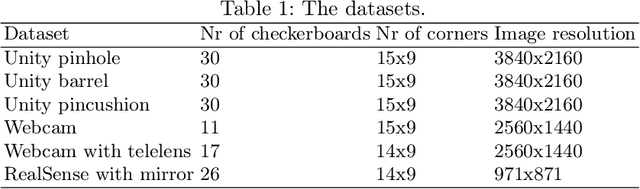

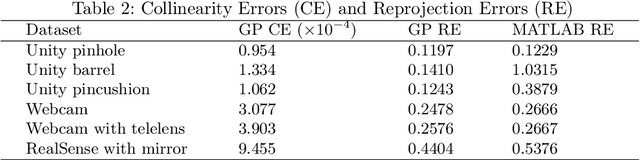
Camera calibration is a first and fundamental step in various computer vision applications. Despite being an active field of research, Zhang's method remains widely used for camera calibration due to its implementation in popular toolboxes. However, this method initially assumes a pinhole model with oversimplified distortion models. In this work, we propose a novel approach that involves a pre-processing step to remove distortions from images by means of Gaussian processes. Our method does not need to assume any distortion model and can be applied to severely warped images, even in the case of multiple distortion sources, e.g., a fisheye image of a curved mirror reflection. The Gaussian processes capture all distortions and camera imperfections, resulting in virtual images as though taken by an ideal pinhole camera with square pixels. Furthermore, this ideal GP-camera only needs one image of a square grid calibration pattern. This model allows for a serious upgrade of many algorithms and applications that are designed in a pure projective geometry setting but with a performance that is very sensitive to nonlinear lens distortions. We demonstrate the effectiveness of our method by simplifying Zhang's calibration method, reducing the number of parameters and getting rid of the distortion parameters and iterative optimization. We validate by means of synthetic data and real world images. The contributions of this work include the construction of a virtual ideal pinhole camera using Gaussian processes, a simplified calibration method and lens distortion removal.
MaxSR: Image Super-Resolution Using Improved MaxViT
Jul 14, 2023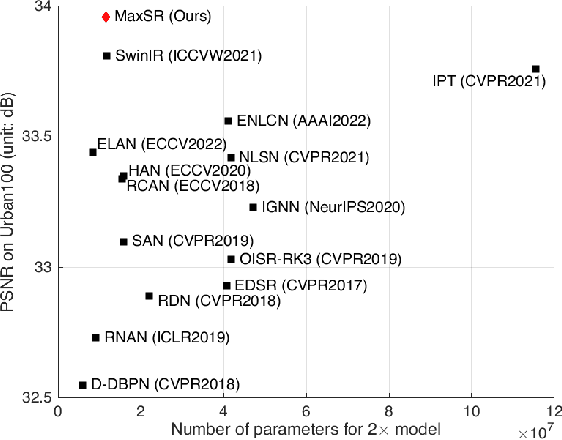

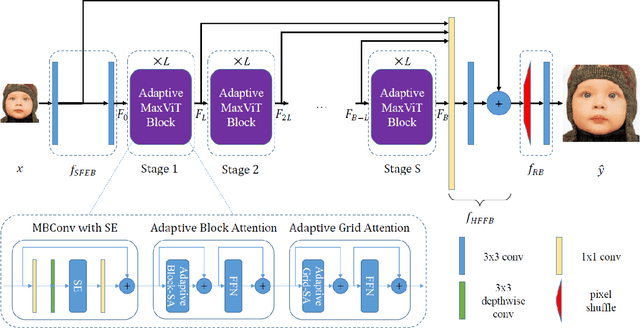
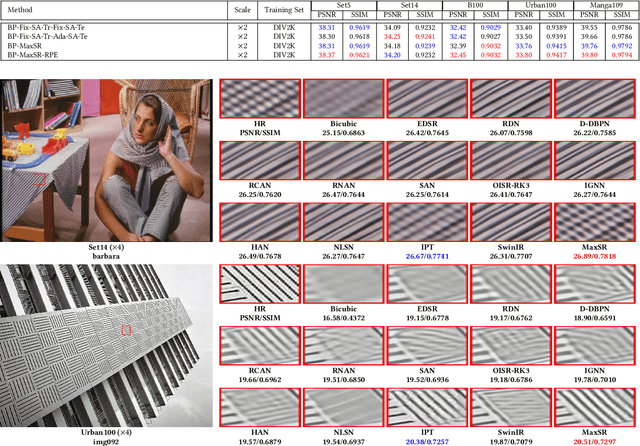
While transformer models have been demonstrated to be effective for natural language processing tasks and high-level vision tasks, only a few attempts have been made to use powerful transformer models for single image super-resolution. Because transformer models have powerful representation capacity and the in-built self-attention mechanisms in transformer models help to leverage self-similarity prior in input low-resolution image to improve performance for single image super-resolution, we present a single image super-resolution model based on recent hybrid vision transformer of MaxViT, named as MaxSR. MaxSR consists of four parts, a shallow feature extraction block, multiple cascaded adaptive MaxViT blocks to extract deep hierarchical features and model global self-similarity from low-level features efficiently, a hierarchical feature fusion block, and finally a reconstruction block. The key component of MaxSR, i.e., adaptive MaxViT block, is based on MaxViT block which mixes MBConv with squeeze-and-excitation, block attention and grid attention. In order to achieve better global modelling of self-similarity in input low-resolution image, we improve block attention and grid attention in MaxViT block to adaptive block attention and adaptive grid attention which do self-attention inside each window across all grids and each grid across all windows respectively in the most efficient way. We instantiate proposed model for classical single image super-resolution (MaxSR) and lightweight single image super-resolution (MaxSR-light). Experiments show that our MaxSR and MaxSR-light establish new state-of-the-art performance efficiently.
Cross-dimensional transfer learning in medical image segmentation with deep learning
Jul 29, 2023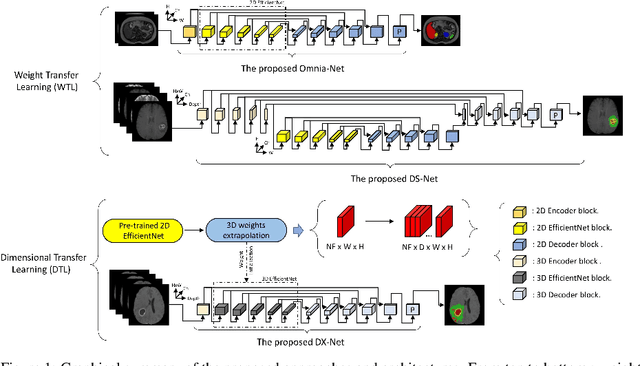

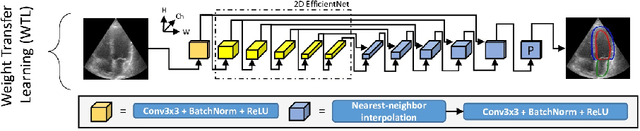
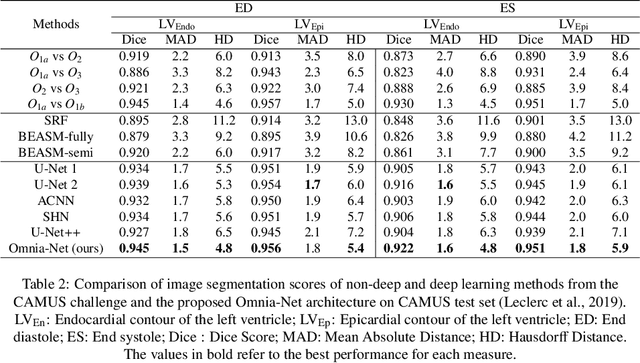
Over the last decade, convolutional neural networks have emerged and advanced the state-of-the-art in various image analysis and computer vision applications. The performance of 2D image classification networks is constantly improving and being trained on databases made of millions of natural images. However, progress in medical image analysis has been hindered by limited annotated data and acquisition constraints. These limitations are even more pronounced given the volumetry of medical imaging data. In this paper, we introduce an efficient way to transfer the efficiency of a 2D classification network trained on natural images to 2D, 3D uni- and multi-modal medical image segmentation applications. In this direction, we designed novel architectures based on two key principles: weight transfer by embedding a 2D pre-trained encoder into a higher dimensional U-Net, and dimensional transfer by expanding a 2D segmentation network into a higher dimension one. The proposed networks were tested on benchmarks comprising different modalities: MR, CT, and ultrasound images. Our 2D network ranked first on the CAMUS challenge dedicated to echo-cardiographic data segmentation and surpassed the state-of-the-art. Regarding 2D/3D MR and CT abdominal images from the CHAOS challenge, our approach largely outperformed the other 2D-based methods described in the challenge paper on Dice, RAVD, ASSD, and MSSD scores and ranked third on the online evaluation platform. Our 3D network applied to the BraTS 2022 competition also achieved promising results, reaching an average Dice score of 91.69% (91.22%) for the whole tumor, 83.23% (84.77%) for the tumor core, and 81.75% (83.88%) for enhanced tumor using the approach based on weight (dimensional) transfer. Experimental and qualitative results illustrate the effectiveness of our methods for multi-dimensional medical image segmentation.
* 30 pages, 12 figures, 6 tables, Accepted for publication in the Journal of Medical Image Analysis
Boundary Difference Over Union Loss For Medical Image Segmentation
Aug 01, 2023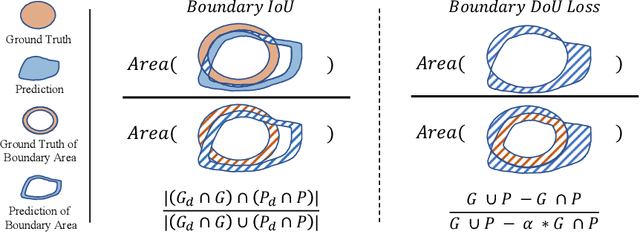
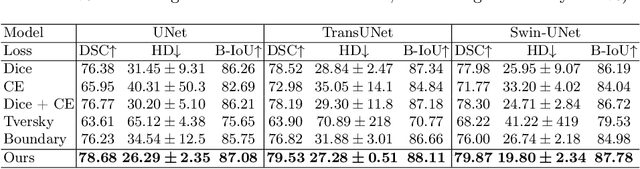
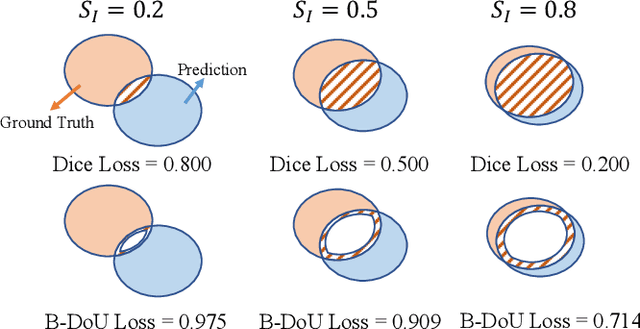
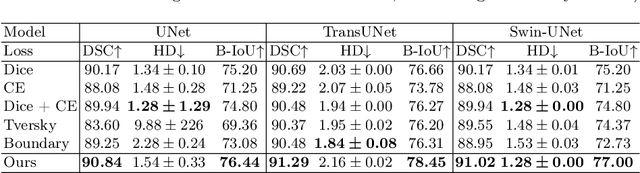
Medical image segmentation is crucial for clinical diagnosis. However, current losses for medical image segmentation mainly focus on overall segmentation results, with fewer losses proposed to guide boundary segmentation. Those that do exist often need to be used in combination with other losses and produce ineffective results. To address this issue, we have developed a simple and effective loss called the Boundary Difference over Union Loss (Boundary DoU Loss) to guide boundary region segmentation. It is obtained by calculating the ratio of the difference set of prediction and ground truth to the union of the difference set and the partial intersection set. Our loss only relies on region calculation, making it easy to implement and training stable without needing any additional losses. Additionally, we use the target size to adaptively adjust attention applied to the boundary regions. Experimental results using UNet, TransUNet, and Swin-UNet on two datasets (ACDC and Synapse) demonstrate the effectiveness of our proposed loss function. Code is available at https://github.com/sunfan-bvb/BoundaryDoULoss.
EqGAN: Feature Equalization Fusion for Few-shot Image Generation
Jul 27, 2023Due to the absence of fine structure and texture information, existing fusion-based few-shot image generation methods suffer from unsatisfactory generation quality and diversity. To address this problem, we propose a novel feature Equalization fusion Generative Adversarial Network (EqGAN) for few-shot image generation. Unlike existing fusion strategies that rely on either deep features or local representations, we design two separate branches to fuse structures and textures by disentangling encoded features into shallow and deep contents. To refine image contents at all feature levels, we equalize the fused structure and texture semantics at different scales and supplement the decoder with richer information by skip connections. Since the fused structures and textures may be inconsistent with each other, we devise a consistent equalization loss between the equalized features and the intermediate output of the decoder to further align the semantics. Comprehensive experiments on three public datasets demonstrate that, EqGAN not only significantly improves generation performance with FID score (by up to 32.7%) and LPIPS score (by up to 4.19%), but also outperforms the state-of-the-arts in terms of accuracy (by up to 1.97%) for downstream classification tasks.
Learning Through Guidance: Knowledge Distillation for Endoscopic Image Classification
Aug 17, 2023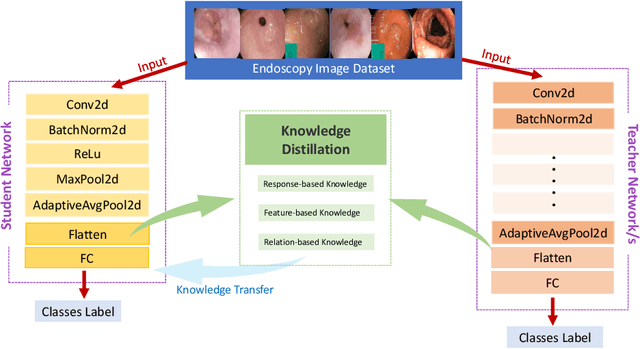
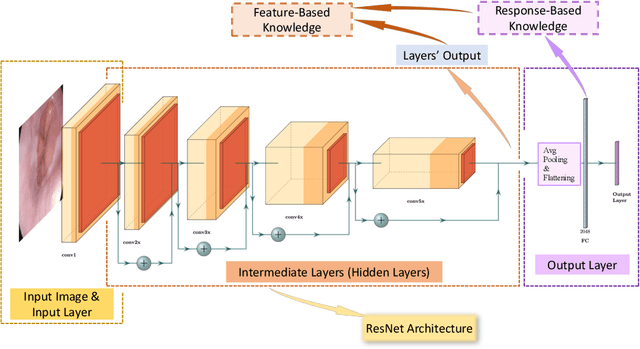
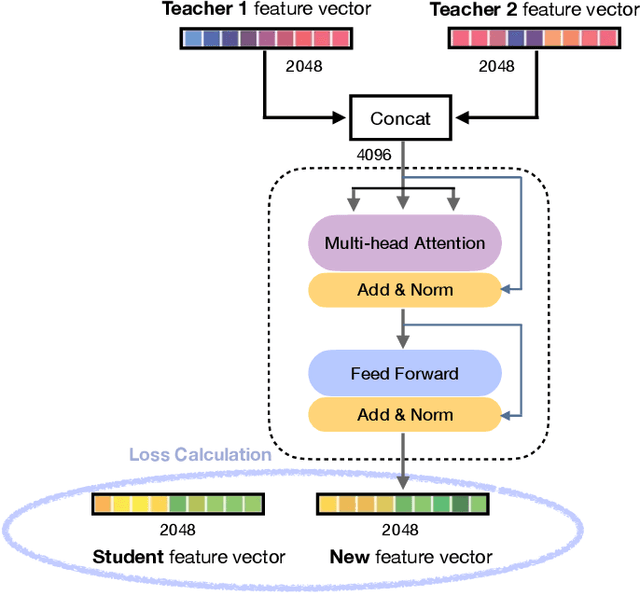
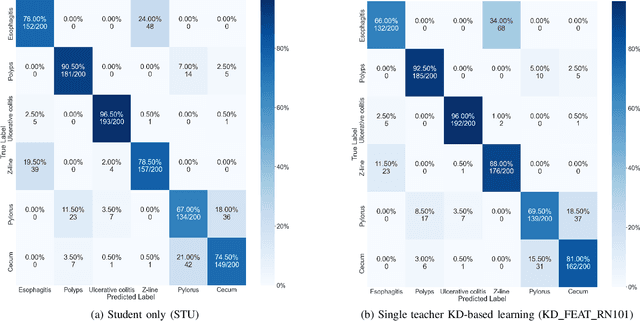
Endoscopy plays a major role in identifying any underlying abnormalities within the gastrointestinal (GI) tract. There are multiple GI tract diseases that are life-threatening, such as precancerous lesions and other intestinal cancers. In the usual process, a diagnosis is made by a medical expert which can be prone to human errors and the accuracy of the test is also entirely dependent on the expert's level of experience. Deep learning, specifically Convolution Neural Networks (CNNs) which are designed to perform automatic feature learning without any prior feature engineering, has recently reported great benefits for GI endoscopy image analysis. Previous research has developed models that focus only on improving performance, as such, the majority of introduced models contain complex deep network architectures with a large number of parameters that require longer training times. However, there is a lack of focus on developing lightweight models which can run in low-resource environments, which are typically encountered in medical clinics. We investigate three KD-based learning frameworks, response-based, feature-based, and relation-based mechanisms, and introduce a novel multi-head attention-based feature fusion mechanism to support relation-based learning. Compared to the existing relation-based methods that follow simplistic aggregation techniques of multi-teacher response/feature-based knowledge, we adopt the multi-head attention technique to provide flexibility towards localising and transferring important details from each teacher to better guide the student. We perform extensive evaluations on two widely used public datasets, KVASIR-V2 and Hyper-KVASIR, and our experimental results signify the merits of our proposed relation-based framework in achieving an improved lightweight model (only 51.8k trainable parameters) that can run in a resource-limited environment.
Towards Content-based Pixel Retrieval in Revisited Oxford and Paris
Sep 11, 2023
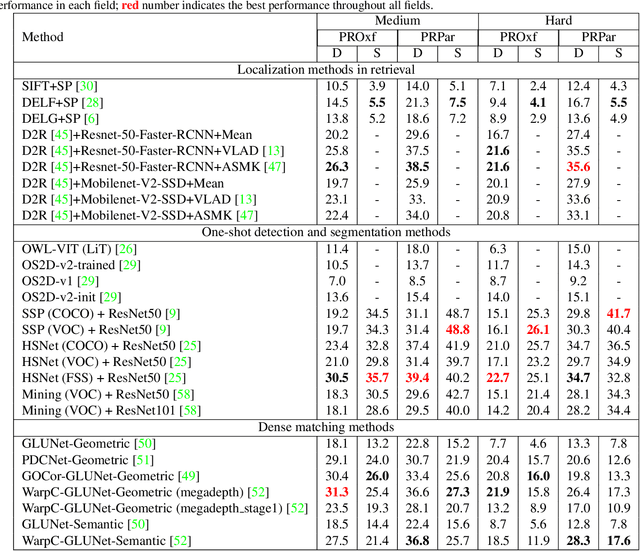
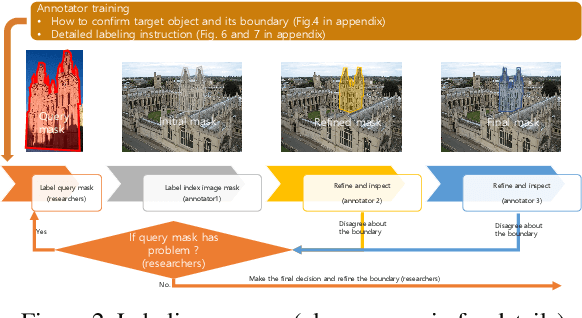
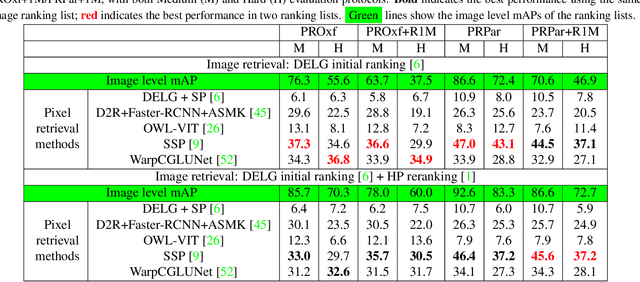
This paper introduces the first two pixel retrieval benchmarks. Pixel retrieval is segmented instance retrieval. Like semantic segmentation extends classification to the pixel level, pixel retrieval is an extension of image retrieval and offers information about which pixels are related to the query object. In addition to retrieving images for the given query, it helps users quickly identify the query object in true positive images and exclude false positive images by denoting the correlated pixels. Our user study results show pixel-level annotation can significantly improve the user experience. Compared with semantic and instance segmentation, pixel retrieval requires a fine-grained recognition capability for variable-granularity targets. To this end, we propose pixel retrieval benchmarks named PROxford and PRParis, which are based on the widely used image retrieval datasets, ROxford and RParis. Three professional annotators label 5,942 images with two rounds of double-checking and refinement. Furthermore, we conduct extensive experiments and analysis on the SOTA methods in image search, image matching, detection, segmentation, and dense matching using our pixel retrieval benchmarks. Results show that the pixel retrieval task is challenging to these approaches and distinctive from existing problems, suggesting that further research can advance the content-based pixel-retrieval and thus user search experience. The datasets can be downloaded from \href{https://github.com/anguoyuan/Pixel_retrieval-Segmented_instance_retrieval}{this link}.
NDC-Scene: Boost Monocular 3D Semantic Scene Completion in Normalized Device Coordinates Space
Sep 27, 2023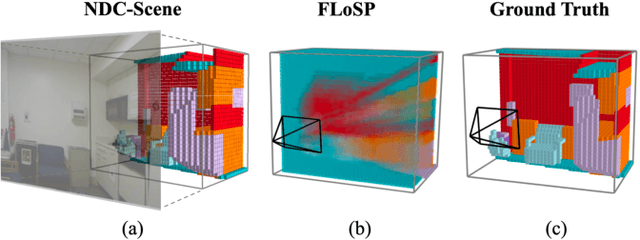
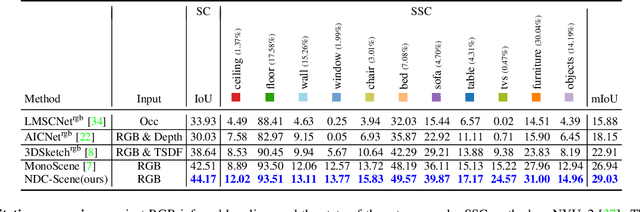

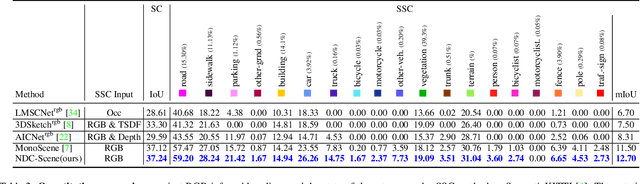
Monocular 3D Semantic Scene Completion (SSC) has garnered significant attention in recent years due to its potential to predict complex semantics and geometry shapes from a single image, requiring no 3D inputs. In this paper, we identify several critical issues in current state-of-the-art methods, including the Feature Ambiguity of projected 2D features in the ray to the 3D space, the Pose Ambiguity of the 3D convolution, and the Computation Imbalance in the 3D convolution across different depth levels. To address these problems, we devise a novel Normalized Device Coordinates scene completion network (NDC-Scene) that directly extends the 2D feature map to a Normalized Device Coordinates (NDC) space, rather than to the world space directly, through progressive restoration of the dimension of depth with deconvolution operations. Experiment results demonstrate that transferring the majority of computation from the target 3D space to the proposed normalized device coordinates space benefits monocular SSC tasks. Additionally, we design a Depth-Adaptive Dual Decoder to simultaneously upsample and fuse the 2D and 3D feature maps, further improving overall performance. Our extensive experiments confirm that the proposed method consistently outperforms state-of-the-art methods on both outdoor SemanticKITTI and indoor NYUv2 datasets. Our code are available at https://github.com/Jiawei-Yao0812/NDCScene.