 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ECoDepth: Effective Conditioning of Diffusion Models for Monocular Depth Estimation
Mar 28, 2024
In the absence of parallax cues, a learning-based single image depth estimation (SIDE) model relies heavily on shading and contextual cues in the image. While this simplicity is attractive, it is necessary to train such models on large and varied datasets, which are difficult to capture. It has been shown that using embeddings from pre-trained foundational models, such as CLIP, improves zero shot transfer in several applications. Taking inspiration from this, in our paper we explore the use of global image priors generated from a pre-trained ViT model to provide more detailed contextual information. We argue that the embedding vector from a ViT model, pre-trained on a large dataset, captures greater relevant information for SIDE than the usual route of generating pseudo image captions, followed by CLIP based text embeddings. Based on this idea, we propose a new SIDE model using a diffusion backbone which is conditioned on ViT embeddings. Our proposed design establishes a new state-of-the-art (SOTA) for SIDE on NYUv2 dataset, achieving Abs Rel error of 0.059(14% improvement) compared to 0.069 by the current SOTA (VPD). And on KITTI dataset, achieving Sq Rel error of 0.139 (2% improvement) compared to 0.142 by the current SOTA (GEDepth). For zero-shot transfer with a model trained on NYUv2, we report mean relative improvement of (20%, 23%, 81%, 25%) over NeWCRFs on (Sun-RGBD, iBims1, DIODE, HyperSim) datasets, compared to (16%, 18%, 45%, 9%) by ZoeDepth. The code is available at https://ecodepth-iitd.github.io
WIA-LD2ND: Wavelet-based Image Alignment for Self-supervised Low-Dose CT Denoising
Mar 19, 2024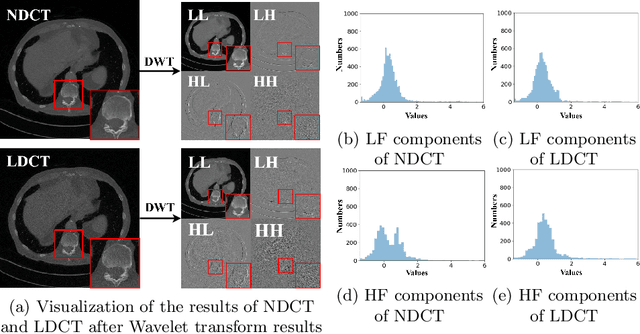
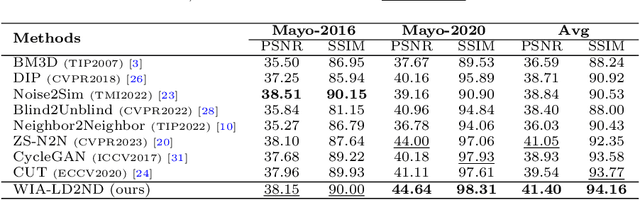

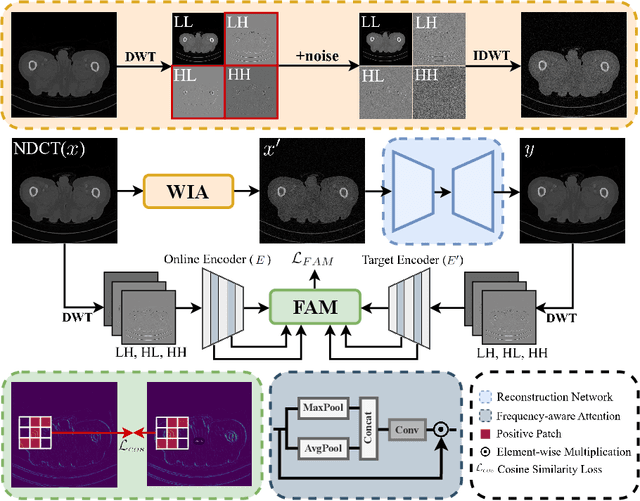
In clinical examinations and diagnoses, low-dose computed tomography (LDCT) is crucial for minimizing health risks compared with normal-dose computed tomography (NDCT). However, reducing the radiation dose compromises the signal-to-noise ratio, leading to degraded quality of CT images. To address this, we analyze LDCT denoising task based on experimental results from the frequency perspective, and then introduce a novel self-supervised CT image denoising method called WIA-LD2ND, only using NDCT data. The proposed WIA-LD2ND comprises two modules: Wavelet-based Image Alignment (WIA) and Frequency-Aware Multi-scale Loss (FAM). First, WIA is introduced to align NDCT with LDCT by mainly adding noise to the high-frequency components, which is the main difference between LDCT and NDCT. Second, to better capture high-frequency components and detailed information, Frequency-Aware Multi-scale Loss (FAM) is proposed by effectively utilizing multi-scale feature space. Extensive experiments on two public LDCT denoising datasets demonstrate that our WIA-LD2ND, only uses NDCT, outperforms existing several state-of-the-art weakly-supervised and self-supervised methods.
LayerDiff: Exploring Text-guided Multi-layered Composable Image Synthesis via Layer-Collaborative Diffusion Model
Mar 18, 2024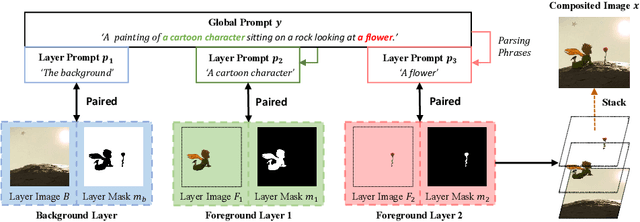
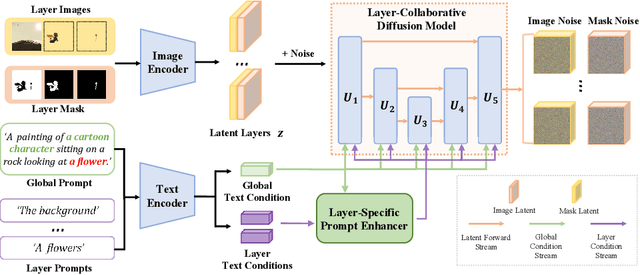

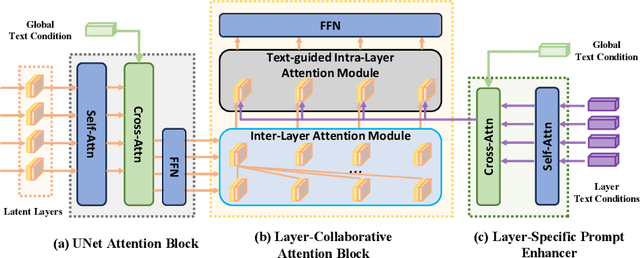
Despite the success of generating high-quality images given any text prompts by diffusion-based generative models, prior works directly generate the entire images, but cannot provide object-wise manipulation capability. To support wider real applications like professional graphic design and digital artistry, images are frequently created and manipulated in multiple layers to offer greater flexibility and control. Therefore in this paper, we propose a layer-collaborative diffusion model, named LayerDiff, specifically designed for text-guided, multi-layered, composable image synthesis. The composable image consists of a background layer, a set of foreground layers, and associated mask layers for each foreground element. To enable this, LayerDiff introduces a layer-based generation paradigm incorporating multiple layer-collaborative attention modules to capture inter-layer patterns. Specifically, an inter-layer attention module is designed to encourage information exchange and learning between layers, while a text-guided intra-layer attention module incorporates layer-specific prompts to direct the specific-content generation for each layer. A layer-specific prompt-enhanced module better captures detailed textual cues from the global prompt. Additionally, a self-mask guidance sampling strategy further unleashes the model's ability to generate multi-layered images. We also present a pipeline that integrates existing perceptual and generative models to produce a large dataset of high-quality, text-prompted, multi-layered images. Extensive experiments demonstrate that our LayerDiff model can generate high-quality multi-layered images with performance comparable to conventional whole-image generation methods. Moreover, LayerDiff enables a broader range of controllable generative applications, including layer-specific image editing and style transfer.
Bilateral Propagation Network for Depth Completion
Apr 01, 2024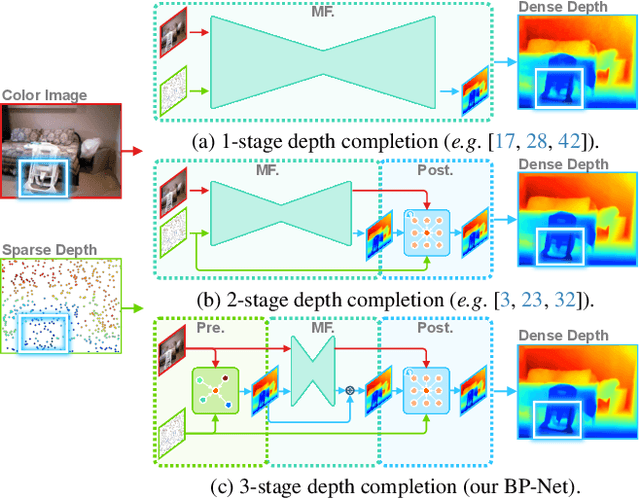
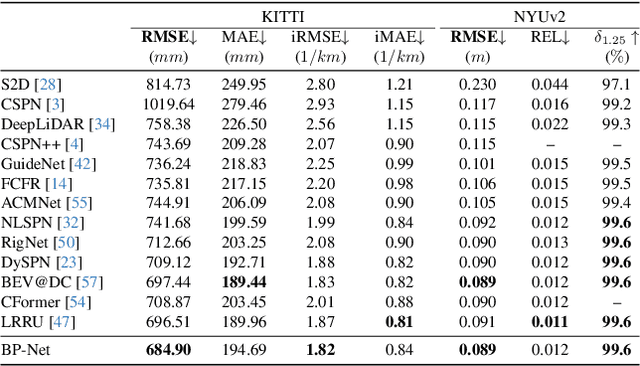
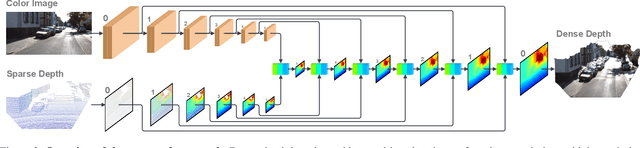
Depth completion aims to derive a dense depth map from sparse depth measurements with a synchronized color image. Current state-of-the-art (SOTA) methods are predominantly propagation-based, which work as an iterative refinement on the initial estimated dense depth. However, the initial depth estimations mostly result from direct applications of convolutional layers on the sparse depth map. In this paper, we present a Bilateral Propagation Network (BP-Net), that propagates depth at the earliest stage to avoid directly convolving on sparse data. Specifically, our approach propagates the target depth from nearby depth measurements via a non-linear model, whose coefficients are generated through a multi-layer perceptron conditioned on both \emph{radiometric difference} and \emph{spatial distance}. By integrating bilateral propagation with multi-modal fusion and depth refinement in a multi-scale framework, our BP-Net demonstrates outstanding performance on both indoor and outdoor scenes. It achieves SOTA on the NYUv2 dataset and ranks 1st on the KITTI depth completion benchmark at the time of submission. Experimental results not only show the effectiveness of bilateral propagation but also emphasize the significance of early-stage propagation in contrast to the refinement stage. Our code and trained models will be available on the project page.
Multi-criteria Token Fusion with One-step-ahead Attention for Efficient Vision Transformers
Apr 01, 2024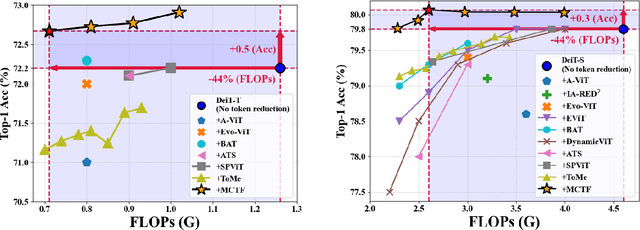
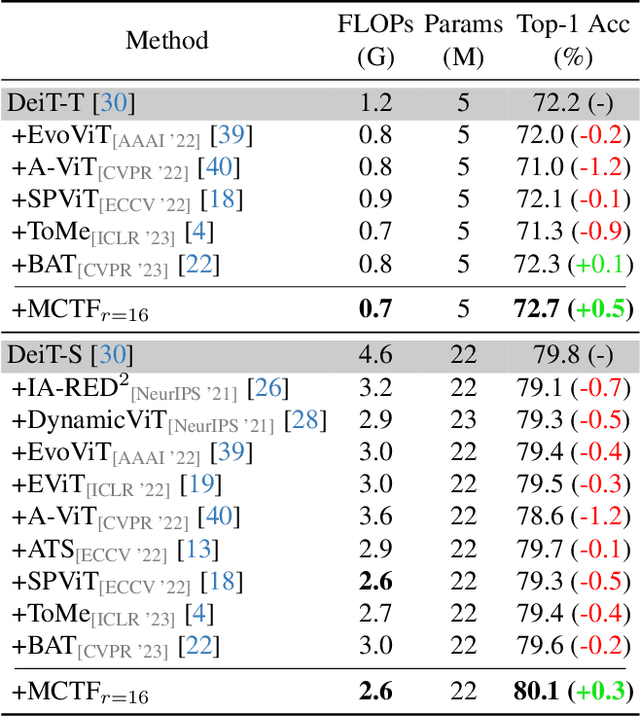
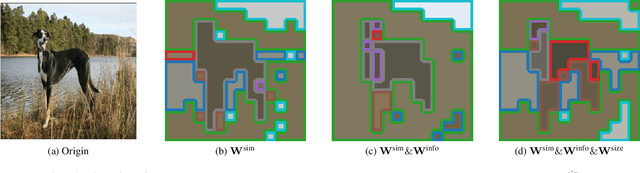
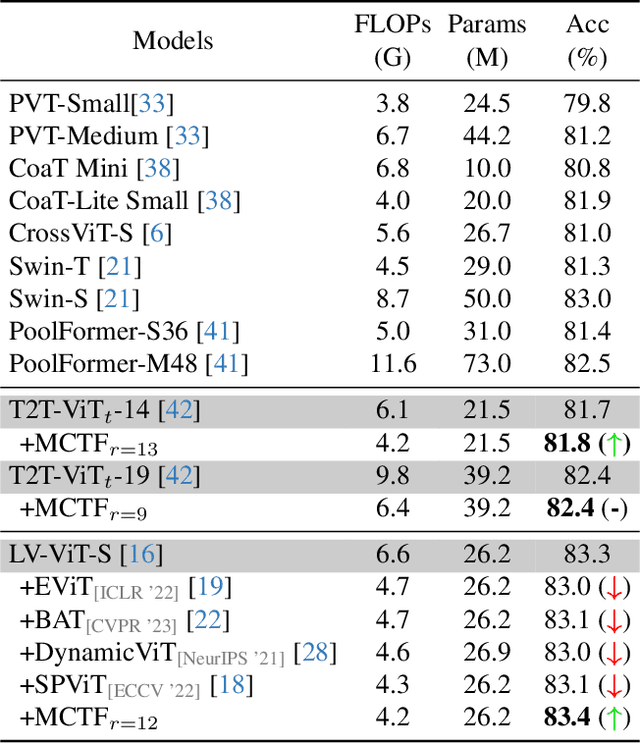
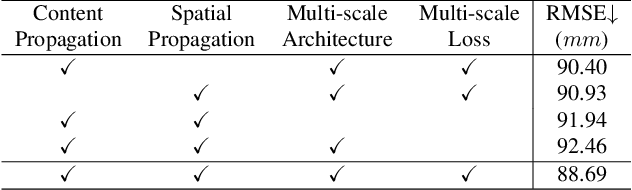
Vision Transformer (ViT) has emerged as a prominent backbone for computer vision. For more efficient ViTs, recent works lessen the quadratic cost of the self-attention layer by pruning or fusing the redundant tokens. However, these works faced the speed-accuracy trade-off caused by the loss of information. Here, we argue that token fusion needs to consider diverse relations between tokens to minimize information loss. In this paper, we propose a Multi-criteria Token Fusion (MCTF), that gradually fuses the tokens based on multi-criteria (e.g., similarity, informativeness, and size of fused tokens). Further, we utilize the one-step-ahead attention, which is the improved approach to capture the informativeness of the tokens. By training the model equipped with MCTF using a token reduction consistency, we achieve the best speed-accuracy trade-off in the image classification (ImageNet1K). Experimental results prove that MCTF consistently surpasses the previous reduction methods with and without training. Specifically, DeiT-T and DeiT-S with MCTF reduce FLOPs by about 44% while improving the performance (+0.5%, and +0.3%) over the base model, respectively. We also demonstrate the applicability of MCTF in various Vision Transformers (e.g., T2T-ViT, LV-ViT), achieving at least 31% speedup without performance degradation. Code is available at https://github.com/mlvlab/MCTF.
Force-EvT: A Closer Look at Robotic Gripper Force Measurement with Event-based Vision Transformer
Apr 01, 2024Robotic grippers are receiving increasing attention in various industries as essential components of robots for interacting and manipulating objects. While significant progress has been made in the past, conventional rigid grippers still have limitations in handling irregular objects and can damage fragile objects. We have shown that soft grippers offer deformability to adapt to a variety of object shapes and maximize object protection. At the same time, dynamic vision sensors (e.g., event-based cameras) are capable of capturing small changes in brightness and streaming them asynchronously as events, unlike RGB cameras, which do not perform well in low-light and fast-moving environments. In this paper, a dynamic-vision-based algorithm is proposed to measure the force applied to the gripper. In particular, we first set up a DVXplorer Lite series event camera to capture twenty-five sets of event data. Second, motivated by the impressive performance of the Vision Transformer (ViT) algorithm in dense image prediction tasks, we propose a new approach that demonstrates the potential for real-time force estimation and meets the requirements of real-world scenarios. We extensively evaluate the proposed algorithm on a wide range of scenarios and settings, and show that it consistently outperforms recent approaches.
Towards Label-Efficient Human Matting: A Simple Baseline for Weakly Semi-Supervised Trimap-Free Human Matting
Apr 01, 2024This paper presents a new practical training method for human matting, which demands delicate pixel-level human region identification and significantly laborious annotations. To reduce the annotation cost, most existing matting approaches often rely on image synthesis to augment the dataset. However, the unnaturalness of synthesized training images brings in a new domain generalization challenge for natural images. To address this challenge, we introduce a new learning paradigm, weakly semi-supervised human matting (WSSHM), which leverages a small amount of expensive matte labels and a large amount of budget-friendly segmentation labels, to save the annotation cost and resolve the domain generalization problem. To achieve the goal of WSSHM, we propose a simple and effective training method, named Matte Label Blending (MLB), that selectively guides only the beneficial knowledge of the segmentation and matte data to the matting model. Extensive experiments with our detailed analysis demonstrate our method can substantially improve the robustness of the matting model using a few matte data and numerous segmentation data. Our training method is also easily applicable to real-time models, achieving competitive accuracy with breakneck inference speed (328 FPS on NVIDIA V100 GPU). The implementation code is available at \url{https://github.com/clovaai/WSSHM}.
Can Biases in ImageNet Models Explain Generalization?
Apr 01, 2024The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
Uncertainty Driven Active Learning for Image Segmentation in Underwater Inspection
Mar 20, 2024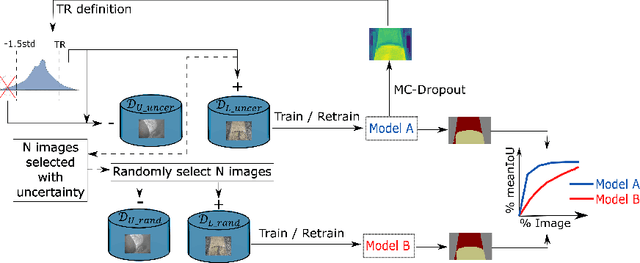
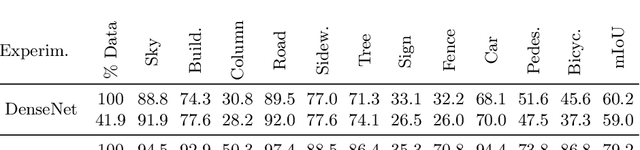


Active learning aims to select the minimum amount of data to train a model that performs similarly to a model trained with the entire dataset. We study the potential of active learning for image segmentation in underwater infrastructure inspection tasks, where large amounts of data are typically collected. The pipeline inspection images are usually semantically repetitive but with great variations in quality. We use mutual information as the acquisition function, calculated using Monte Carlo dropout. To assess the effectiveness of the framework, DenseNet and HyperSeg are trained with the CamVid dataset using active learning. In addition, HyperSeg is trained with a pipeline inspection dataset of over 50,000 images. For the pipeline dataset, HyperSeg with active learning achieved 67.5% meanIoU using 12.5% of the data, and 61.4% with the same amount of randomly selected images. This shows that using active learning for segmentation models in underwater inspection tasks can lower the cost significantly.
TBI Image/Text (TBI-IT): Comprehensive Text and Image Datasets for Traumatic Brain Injury Research
Mar 14, 2024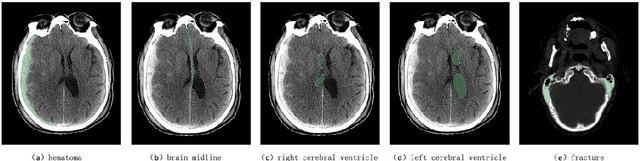

In this paper, we introduce a new dataset in the medical field of Traumatic Brain Injury (TBI), called TBI-IT, which includes both electronic medical records (EMRs) and head CT images. This dataset is designed to enhance the accuracy of artificial intelligence in the diagnosis and treatment of TBI. This dataset, built upon the foundation of standard text and image data, incorporates specific annotations within the EMRs, extracting key content from the text information, and categorizes the annotation content of imaging data into five types: brain midline, hematoma, left cerebral ventricle, right cerebral ventricle and fracture. TBI-IT aims to be a foundational dataset for feature learning in image segmentation tasks and named entity recognition.