 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MMICL: Empowering Vision-language Model with Multi-Modal In-Context Learning
Sep 14, 2023
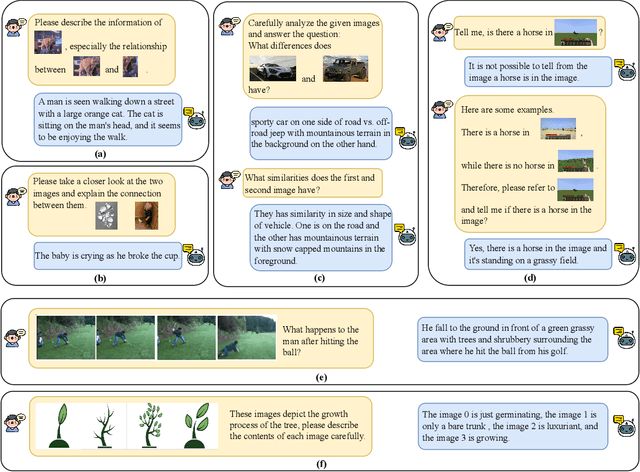
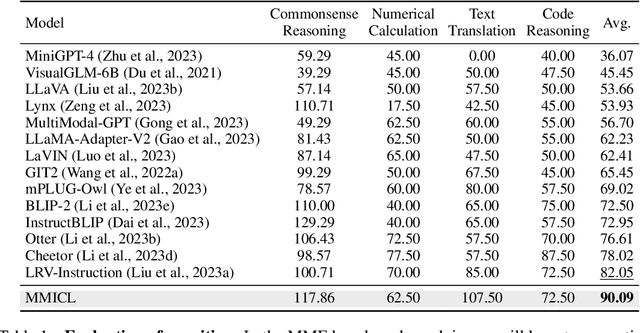
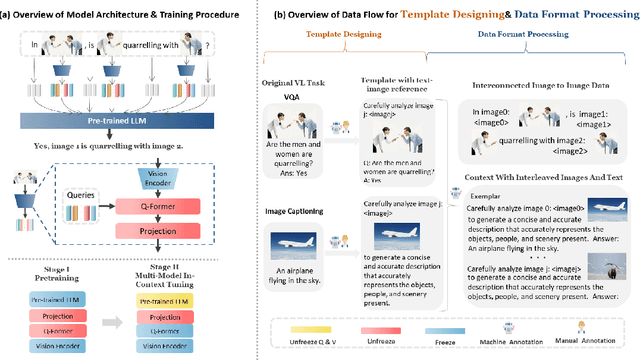
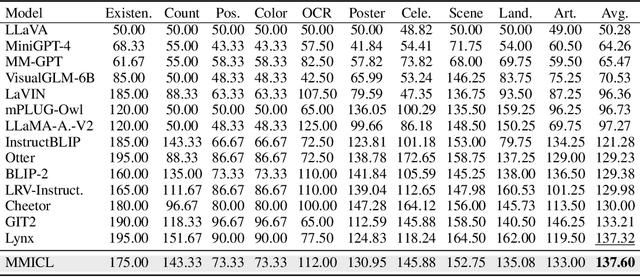
Starting from the resurgence of deep learning, vision-language models (VLMs) benefiting from large language models (LLMs) have never been so popular. However, while LLMs can utilize extensive background knowledge and task information with in-context learning, most VLMs still struggle with understanding complex multi-modal prompts with multiple images. The issue can traced back to the architectural design of VLMs or pre-training data. Specifically, the current VLMs primarily emphasize utilizing multi-modal data with a single image some, rather than multi-modal prompts with interleaved multiple images and text. Even though some newly proposed VLMs could handle user prompts with multiple images, pre-training data does not provide more sophisticated multi-modal prompts than interleaved image and text crawled from the web. We propose MMICL to address the issue by considering both the model and data perspectives. We introduce a well-designed architecture capable of seamlessly integrating visual and textual context in an interleaved manner and MIC dataset to reduce the gap between the training data and the complex user prompts in real-world applications, including: 1) multi-modal context with interleaved images and text, 2) textual references for each image, and 3) multi-image data with spatial, logical, or temporal relationships. Our experiments confirm that MMICL achieves new stat-of-the-art zero-shot and few-shot performance on a wide range of general vision-language tasks, especially for complex reasoning benchmarks including MME and MMBench. Our analysis demonstrates that MMICL effectively deals with the challenge of complex multi-modal prompt understanding. The experiments on ScienceQA-IMG also show that MMICL successfully alleviates the issue of language bias in VLMs, which we believe is the reason behind the advanced performance of MMICL.
Exploring Annotation-free Image Captioning with Retrieval-augmented Pseudo Sentence Generation
Jul 28, 2023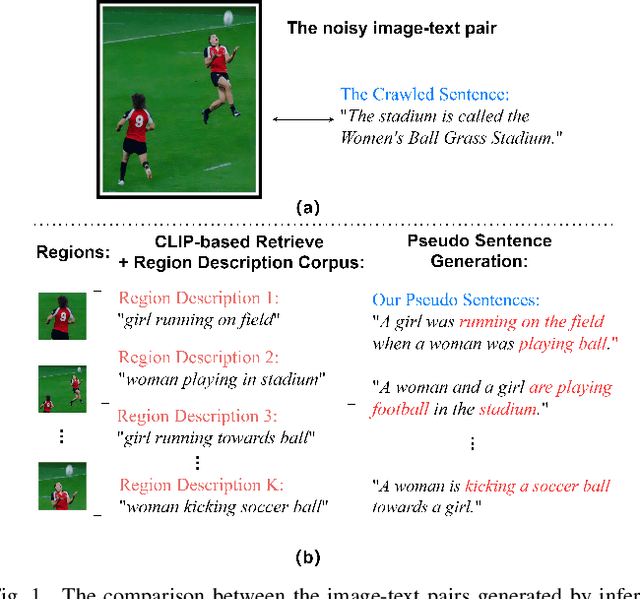
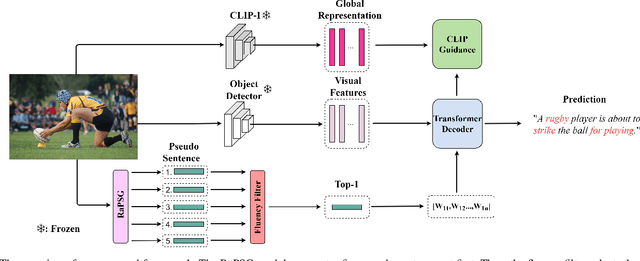
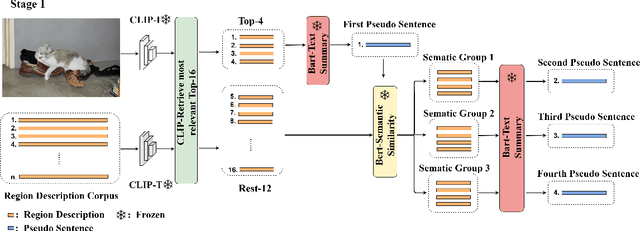
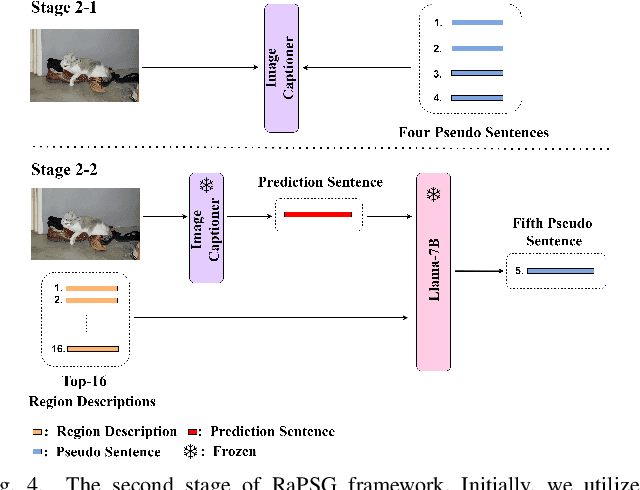
Training an image captioner without annotated image-sentence pairs has gained traction in recent years. Previous approaches can be categorized into two strategies: crawling sentences from mismatching corpora and aligning them with the given images as pseudo annotations, or pre-training the captioner using external image-text pairs. However, the aligning setting seems to reach its performance limit due to the quality problem of pairs, and pre-training requires significant computational resources. To address these challenges, we propose a new strategy ``LPM + retrieval-augmented learning" where the prior knowledge from large pre-trained models (LPMs) is leveraged as supervision, and a retrieval process is integrated to further reinforce its effectiveness. Specifically, we introduce Retrieval-augmented Pseudo Sentence Generation (RaPSG), which adopts an efficient approach to retrieve highly relevant short region descriptions from the mismatching corpora and use them to generate a variety of pseudo sentences with distinct representations as well as high quality via LPMs. In addition, a fluency filter and a CLIP-guided training objective are further introduced to facilitate model optimization. Experimental results demonstrate that our method surpasses the SOTA pre-training model (Flamingo3B) by achieving a CIDEr score of 78.1 (+5.1) while utilizing only 0.3% of its trainable parameters (1.3B VS 33M). Importantly, our approach eliminates the need of computationally expensive pre-training processes on external datasets (e.g., the requirement of 312M image-text pairs for Flamingo3B). We further show that with a simple extension, the generated pseudo sentences can be deployed as weak supervision to boost the 1% semi-supervised image caption benchmark up to 93.4 CIDEr score (+8.9) which showcases the versatility and effectiveness of our approach.
NLCUnet: Single-Image Super-Resolution Network with Hairline Details
Jul 22, 2023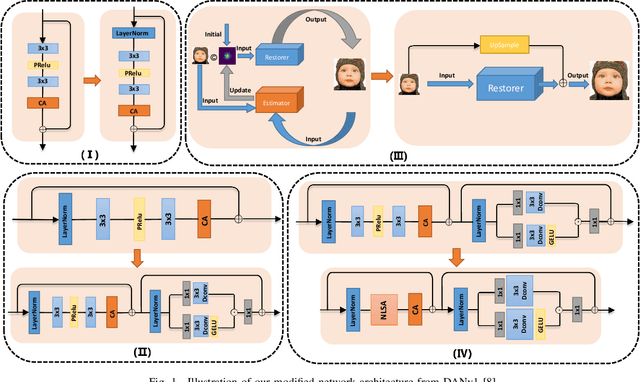
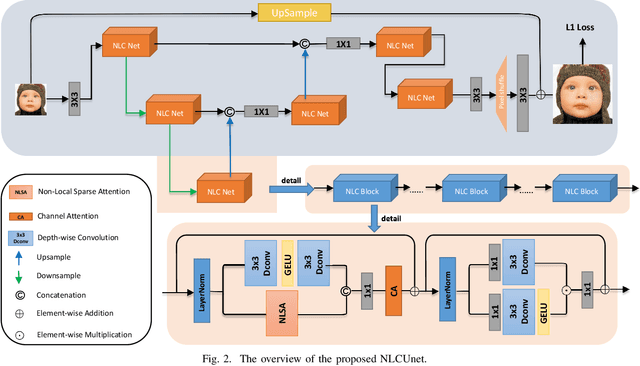


Pursuing the precise details of super-resolution images is challenging for single-image super-resolution tasks. This paper presents a single-image super-resolution network with hairline details (termed NLCUnet), including three core designs. Specifically, a non-local attention mechanism is first introduced to restore local pieces by learning from the whole image region. Then, we find that the blur kernel trained by the existing work is unnecessary. Based on this finding, we create a new network architecture by integrating depth-wise convolution with channel attention without the blur kernel estimation, resulting in a performance improvement instead. Finally, to make the cropped region contain as much semantic information as possible, we propose a random 64$\times$64 crop inside the central 512$\times$512 crop instead of a direct random crop inside the whole image of 2K size. Numerous experiments conducted on the benchmark DF2K dataset demonstrate that our NLCUnet performs better than the state-of-the-art in terms of the PSNR and SSIM metrics and yields visually favorable hairline details.
Logarithmic Mathematical Morphology: theory and applications
Sep 05, 2023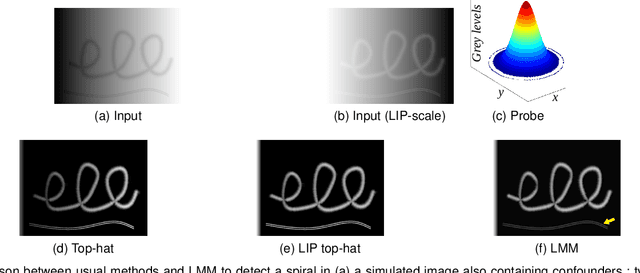
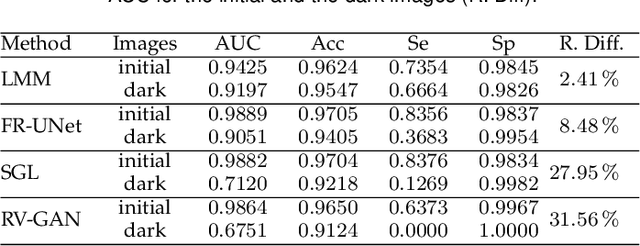
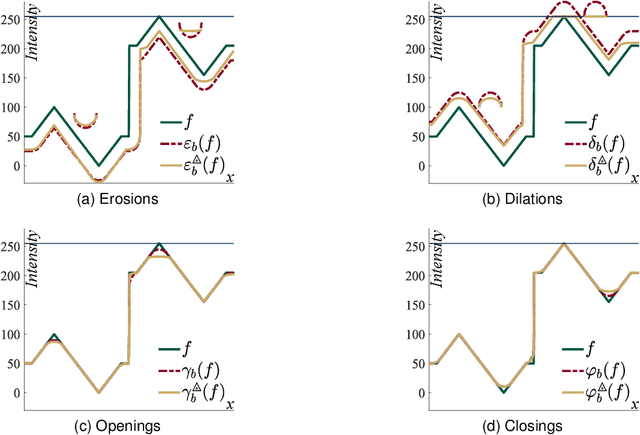
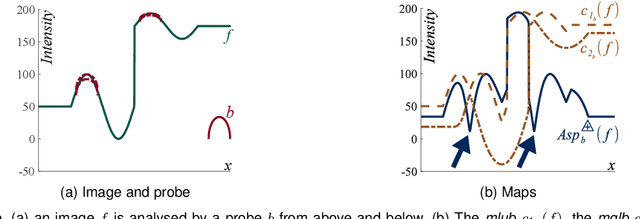
Classically, in Mathematical Morphology, an image (i.e., a grey-level function) is analysed by another image which is named the structuring element or the structuring function. This structuring function is moved over the image domain and summed to the image. However, in an image presenting lighting variations, the analysis by a structuring function should require that its amplitude varies according to the image intensity. Such a property is not verified in Mathematical Morphology for grey level functions, when the structuring function is summed to the image with the usual additive law. In order to address this issue, a new framework is defined with an additive law for which the amplitude of the structuring function varies according to the image amplitude. This additive law is chosen within the Logarithmic Image Processing framework and models the lighting variations with a physical cause such as a change of light intensity or a change of camera exposure-time. The new framework is named Logarithmic Mathematical Morphology (LMM) and allows the definition of operators which are robust to such lighting variations. In images with uniform lighting variations, those new LMM operators perform better than usual morphological operators. In eye-fundus images with non-uniform lighting variations, a LMM method for vessel segmentation is compared to three state-of-the-art approaches. Results show that the LMM approach has a better robustness to such variations than the three others.
Multisource Holography
Sep 19, 2023
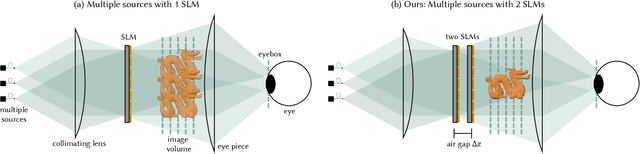
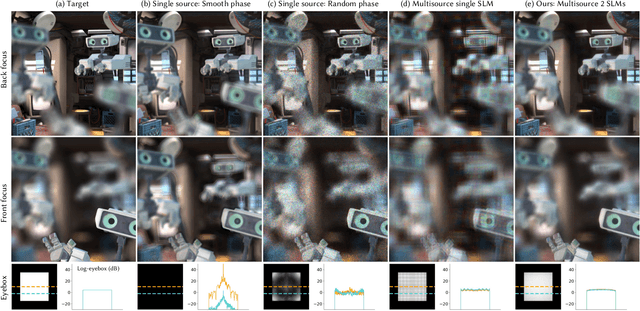
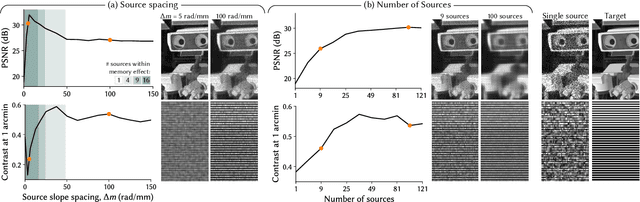
Holographic displays promise several benefits including high quality 3D imagery, accurate accommodation cues, and compact form-factors. However, holography relies on coherent illumination which can create undesirable speckle noise in the final image. Although smooth phase holograms can be speckle-free, their non-uniform eyebox makes them impractical, and speckle mitigation with partially coherent sources also reduces resolution. Averaging sequential frames for speckle reduction requires high speed modulators and consumes temporal bandwidth that may be needed elsewhere in the system. In this work, we propose multisource holography, a novel architecture that uses an array of sources to suppress speckle in a single frame without sacrificing resolution. By using two spatial light modulators, arranged sequentially, each source in the array can be controlled almost independently to create a version of the target content with different speckle. Speckle is then suppressed when the contributions from the multiple sources are averaged at the image plane. We introduce an algorithm to calculate multisource holograms, analyze the design space, and demonstrate up to a 10 dB increase in peak signal-to-noise ratio compared to an equivalent single source system. Finally, we validate the concept with a benchtop experimental prototype by producing both 2D images and focal stacks with natural defocus cues.
Learning End-to-End Channel Coding with Diffusion Models
Sep 19, 2023The training of neural encoders via deep learning necessitates a differentiable channel model due to the backpropagation algorithm. This requirement can be sidestepped by approximating either the channel distribution or its gradient through pilot signals in real-world scenarios. The initial approach draws upon the latest advancements in image generation, utilizing generative adversarial networks (GANs) or their enhanced variants to generate channel distributions. In this paper, we address this channel approximation challenge with diffusion models, which have demonstrated high sample quality in image generation. We offer an end-to-end channel coding framework underpinned by diffusion models and propose an efficient training algorithm. Our simulations with various channel models establish that our diffusion models learn the channel distribution accurately, thereby achieving near-optimal end-to-end symbol error rates (SERs). We also note a significant advantage of diffusion models: A robust generalization capability in high signal-to-noise ratio regions, in contrast to GAN variants that suffer from error floor. Furthermore, we examine the trade-off between sample quality and sampling speed, when an accelerated sampling algorithm is deployed, and investigate the effect of the noise scheduling on this trade-off. With an apt choice of noise scheduling, sampling time can be significantly reduced with a minor increase in SER.
Learning Through Guidance: Knowledge Distillation for Endoscopic Image Classification
Aug 17, 2023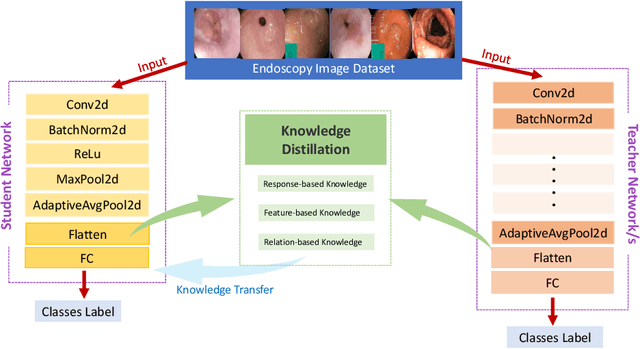
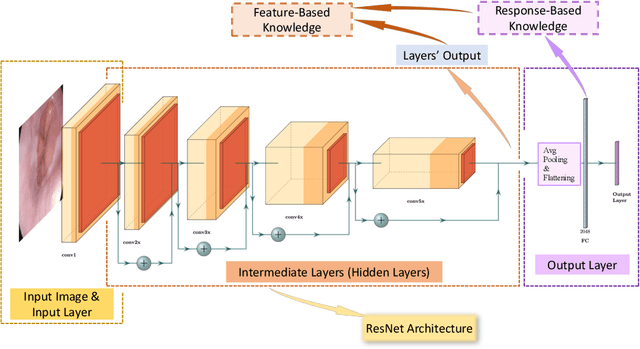
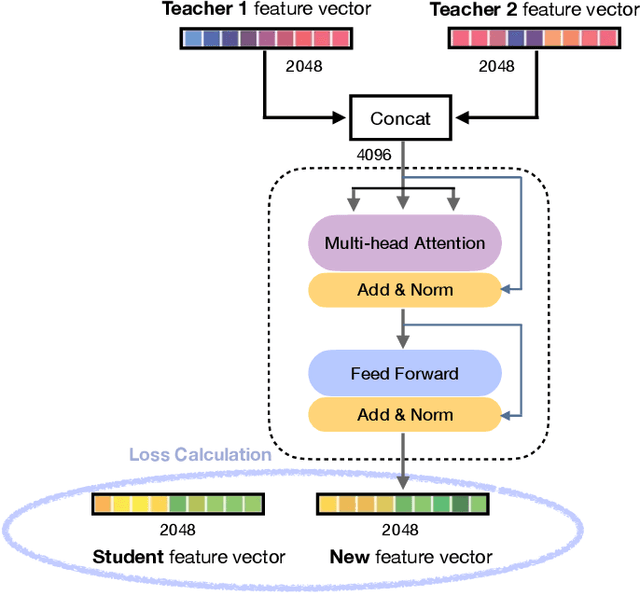
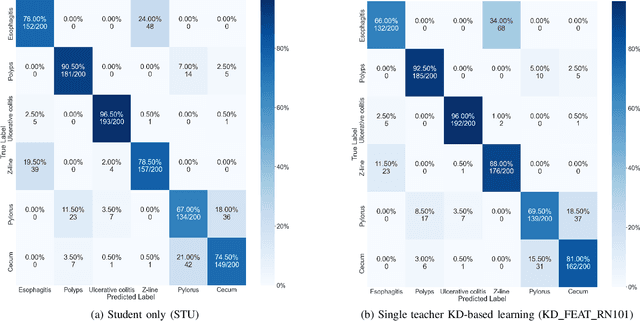
Endoscopy plays a major role in identifying any underlying abnormalities within the gastrointestinal (GI) tract. There are multiple GI tract diseases that are life-threatening, such as precancerous lesions and other intestinal cancers. In the usual process, a diagnosis is made by a medical expert which can be prone to human errors and the accuracy of the test is also entirely dependent on the expert's level of experience. Deep learning, specifically Convolution Neural Networks (CNNs) which are designed to perform automatic feature learning without any prior feature engineering, has recently reported great benefits for GI endoscopy image analysis. Previous research has developed models that focus only on improving performance, as such, the majority of introduced models contain complex deep network architectures with a large number of parameters that require longer training times. However, there is a lack of focus on developing lightweight models which can run in low-resource environments, which are typically encountered in medical clinics. We investigate three KD-based learning frameworks, response-based, feature-based, and relation-based mechanisms, and introduce a novel multi-head attention-based feature fusion mechanism to support relation-based learning. Compared to the existing relation-based methods that follow simplistic aggregation techniques of multi-teacher response/feature-based knowledge, we adopt the multi-head attention technique to provide flexibility towards localising and transferring important details from each teacher to better guide the student. We perform extensive evaluations on two widely used public datasets, KVASIR-V2 and Hyper-KVASIR, and our experimental results signify the merits of our proposed relation-based framework in achieving an improved lightweight model (only 51.8k trainable parameters) that can run in a resource-limited environment.
Semantic-Aware Image Compressed Sensing
Jul 11, 2023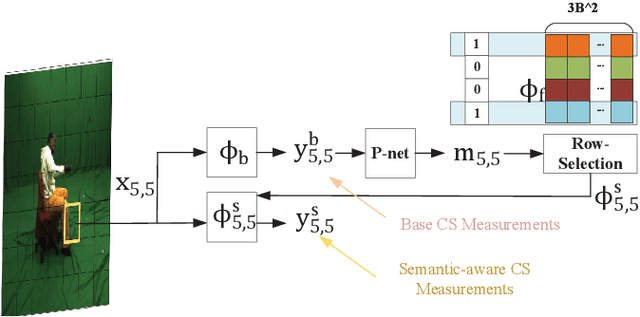
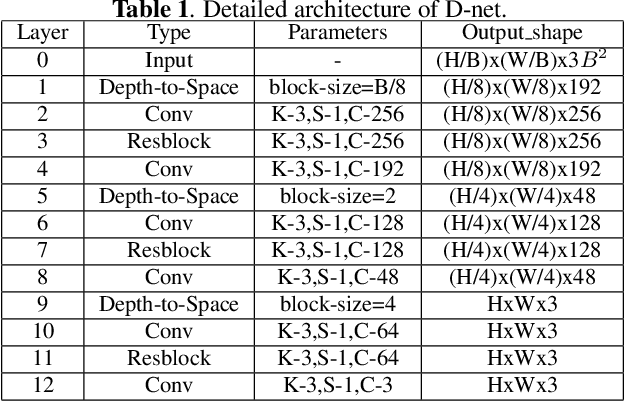
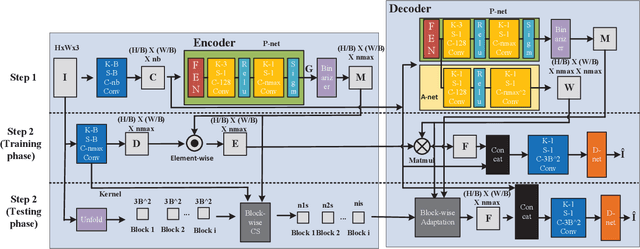
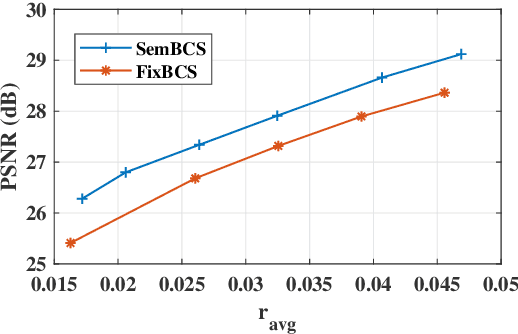
Deep learning based image compressed sensing (CS) has achieved great success. However, existing CS systems mainly adopt a fixed measurement matrix to images, ignoring the fact the optimal measurement numbers and bases are different for different images. To further improve the sensing efficiency, we propose a novel semantic-aware image CS system. In our system, the encoder first uses a fixed number of base CS measurements to sense different images. According to the base CS results, the encoder then employs a policy network to analyze the semantic information in images and determines the measurement matrix for different image areas. At the decoder side, a semantic-aware initial reconstruction network is developed to deal with the changes of measurement matrices used at the encoder. A rate-distortion training loss is further introduced to dynamically adjust the average compression ratio for the semantic-aware CS system and the policy network is trained jointly with the encoder and the decoder in an en-to-end manner by using some proxy functions. Numerical results show that the proposed semantic-aware image CS system is superior to the traditional ones with fixed measurement matrices.
Contrast-augmented Diffusion Model with Fine-grained Sequence Alignment for Markup-to-Image Generation
Aug 02, 2023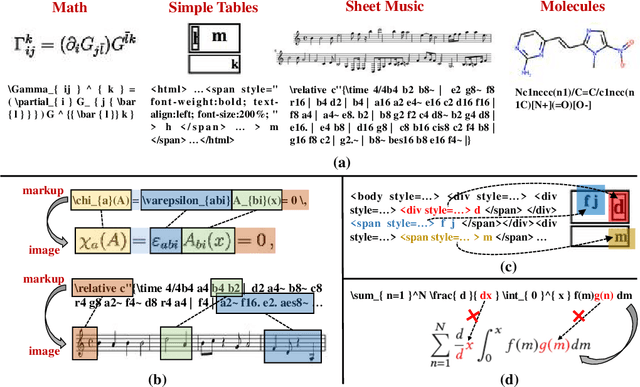
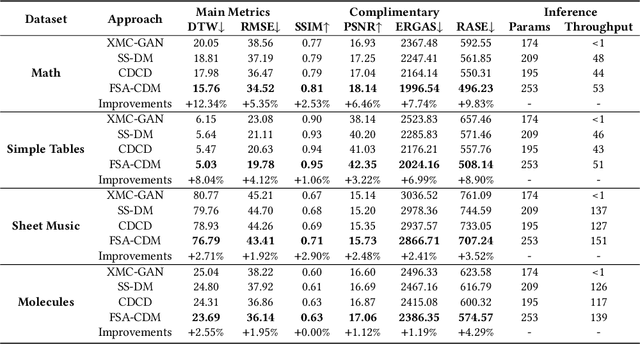
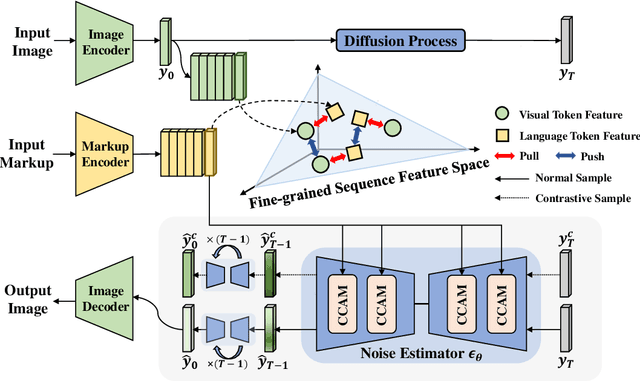
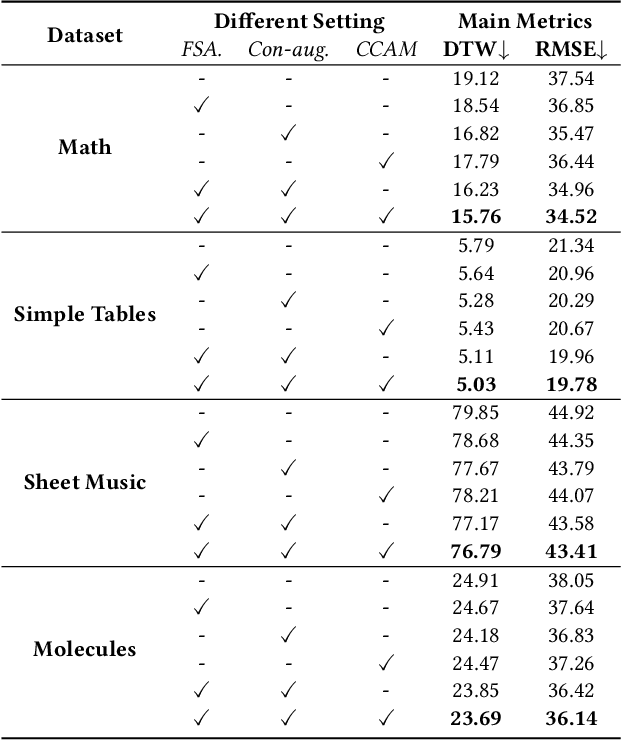
The recently rising markup-to-image generation poses greater challenges as compared to natural image generation, due to its low tolerance for errors as well as the complex sequence and context correlations between markup and rendered image. This paper proposes a novel model named "Contrast-augmented Diffusion Model with Fine-grained Sequence Alignment" (FSA-CDM), which introduces contrastive positive/negative samples into the diffusion model to boost performance for markup-to-image generation. Technically, we design a fine-grained cross-modal alignment module to well explore the sequence similarity between the two modalities for learning robust feature representations. To improve the generalization ability, we propose a contrast-augmented diffusion model to explicitly explore positive and negative samples by maximizing a novel contrastive variational objective, which is mathematically inferred to provide a tighter bound for the model's optimization. Moreover, the context-aware cross attention module is developed to capture the contextual information within markup language during the denoising process, yielding better noise prediction results. Extensive experiments are conducted on four benchmark datasets from different domains, and the experimental results demonstrate the effectiveness of the proposed components in FSA-CDM, significantly exceeding state-of-the-art performance by about 2%-12% DTW improvements. The code will be released at https://github.com/zgj77/FSACDM.
Accelerating Deep Neural Networks via Semi-Structured Activation Sparsity
Sep 27, 2023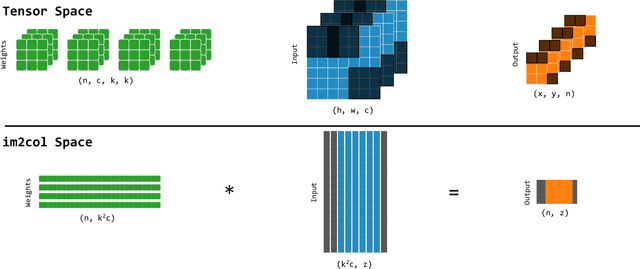
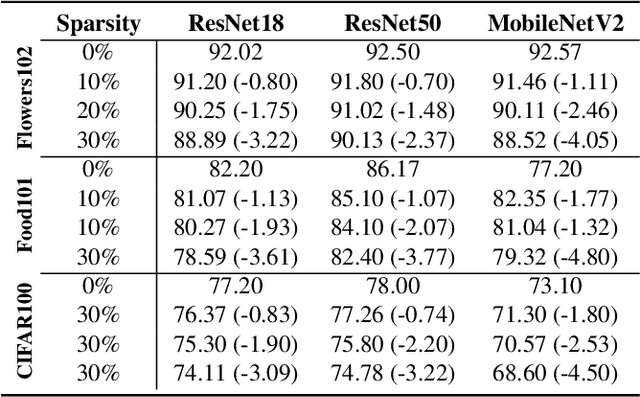
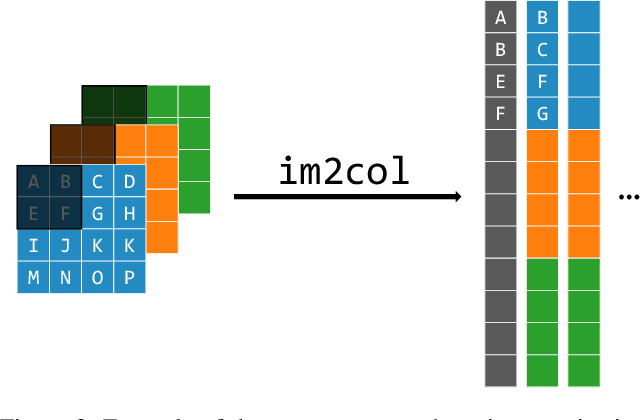
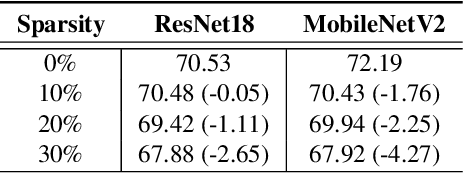
The demand for efficient processing of deep neural networks (DNNs) on embedded devices is a significant challenge limiting their deployment. Exploiting sparsity in the network's feature maps is one of the ways to reduce its inference latency. It is known that unstructured sparsity results in lower accuracy degradation with respect to structured sparsity but the former needs extensive inference engine changes to get latency benefits. To tackle this challenge, we propose a solution to induce semi-structured activation sparsity exploitable through minor runtime modifications. To attain high speedup levels at inference time, we design a sparse training procedure with awareness of the final position of the activations while computing the General Matrix Multiplication (GEMM). We extensively evaluate the proposed solution across various models for image classification and object detection tasks. Remarkably, our approach yields a speed improvement of $1.25 \times$ with a minimal accuracy drop of $1.1\%$ for the ResNet18 model on the ImageNet dataset. Furthermore, when combined with a state-of-the-art structured pruning method, the resulting models provide a good latency-accuracy trade-off, outperforming models that solely employ structured pruning techniques.