 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extreme Image Compression using Fine-tuned VQGAN Models
Aug 07, 2023




Recent advances in generative compression methods have demonstrated remarkable progress in enhancing the perceptual quality of compressed data, especially in scenarios with low bitrates. Nevertheless, their efficacy and applicability in achieving extreme compression ratios ($<0.1$ bpp) still remain constrained. In this work, we propose a simple yet effective coding framework by introducing vector quantization (VQ)-based generative models into the image compression domain. The main insight is that the codebook learned by the VQGAN model yields strong expressive capacity, facilitating efficient compression of continuous information in the latent space while maintaining reconstruction quality. Specifically, an image can be represented as VQ-indices by finding the nearest codeword, which can be encoded using lossless compression methods into bitstreams. We then propose clustering a pre-trained large-scale codebook into smaller codebooks using the K-means algorithm. This enables images to be represented as diverse ranges of VQ-indices maps, resulting in variable bitrates and different levels of reconstruction quality. Extensive qualitative and quantitative experiments on various datasets demonstrate that the proposed framework outperforms the state-of-the-art codecs in terms of perceptual quality-oriented metrics and human perception under extremely low bitrates.
Enabling Quartile-based Estimated-Mean Gradient Aggregation As Baseline for Federated Image Classifications
Sep 21, 2023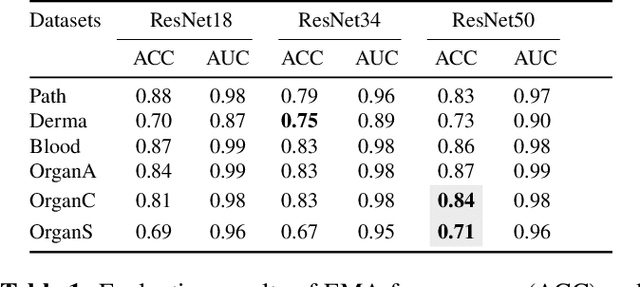
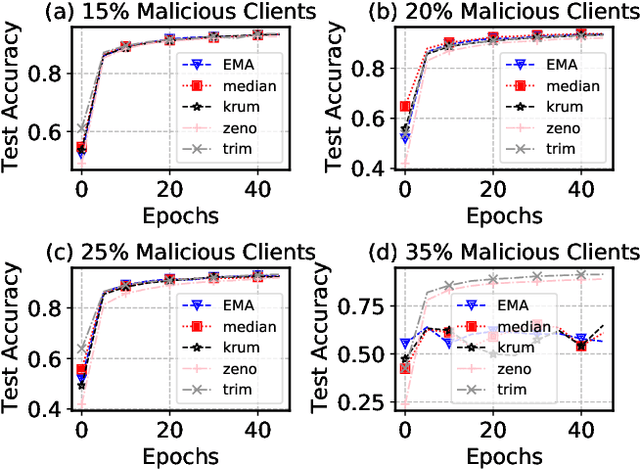
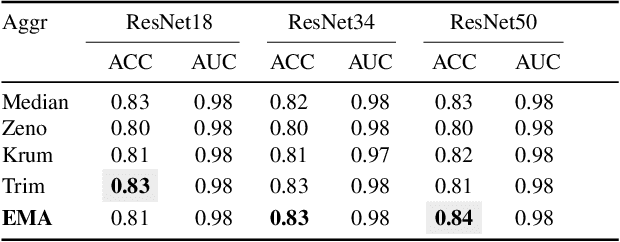
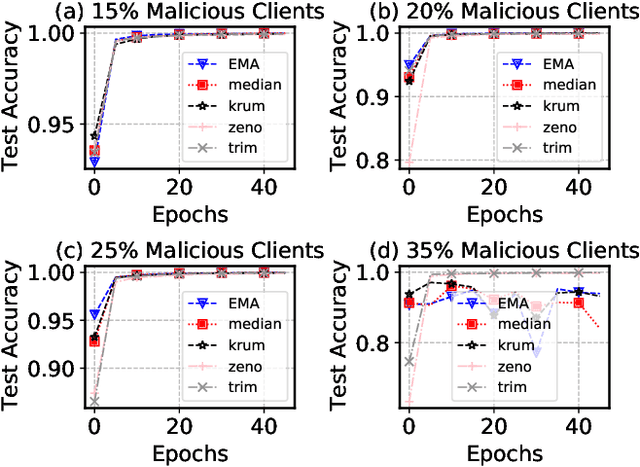
Federated Learning (FL) has revolutionized how we train deep neural networks by enabling decentralized collaboration while safeguarding sensitive data and improving model performance. However, FL faces two crucial challenges: the diverse nature of data held by individual clients and the vulnerability of the FL system to security breaches. This paper introduces an innovative solution named Estimated Mean Aggregation (EMA) that not only addresses these challenges but also provides a fundamental reference point as a $\mathsf{baseline}$ for advanced aggregation techniques in FL systems. EMA's significance lies in its dual role: enhancing model security by effectively handling malicious outliers through trimmed means and uncovering data heterogeneity to ensure that trained models are adaptable across various client datasets. Through a wealth of experiments, EMA consistently demonstrates high accuracy and area under the curve (AUC) compared to alternative methods, establishing itself as a robust baseline for evaluating the effectiveness and security of FL aggregation methods. EMA's contributions thus offer a crucial step forward in advancing the efficiency, security, and versatility of decentralized deep learning in the context of FL.
HiFiHR: Enhancing 3D Hand Reconstruction from a Single Image via High-Fidelity Texture
Aug 25, 2023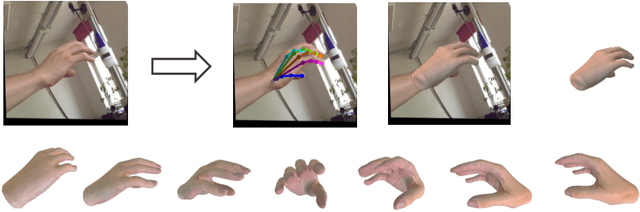
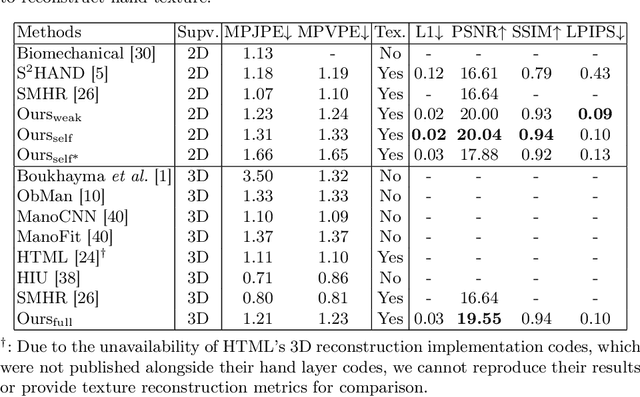
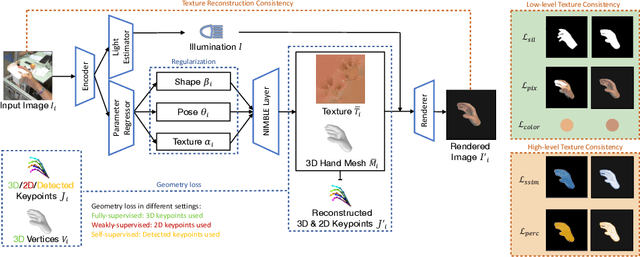
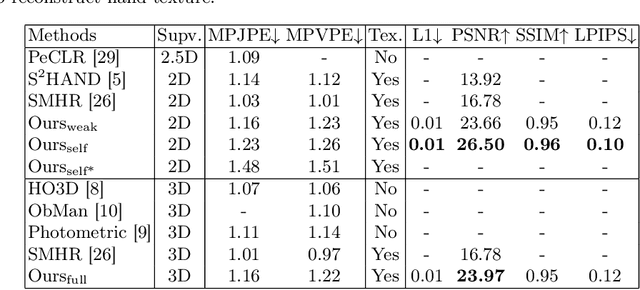
We present HiFiHR, a high-fidelity hand reconstruction approach that utilizes render-and-compare in the learning-based framework from a single image, capable of generating visually plausible and accurate 3D hand meshes while recovering realistic textures. Our method achieves superior texture reconstruction by employing a parametric hand model with predefined texture assets, and by establishing a texture reconstruction consistency between the rendered and input images during training. Moreover, based on pretraining the network on an annotated dataset, we apply varying degrees of supervision using our pipeline, i.e., self-supervision, weak supervision, and full supervision, and discuss the various levels of contributions of the learned high-fidelity textures in enhancing hand pose and shape estimation. Experimental results on public benchmarks including FreiHAND and HO-3D demonstrate that our method outperforms the state-of-the-art hand reconstruction methods in texture reconstruction quality while maintaining comparable accuracy in pose and shape estimation. Our code is available at https://github.com/viridityzhu/HiFiHR.
FP-PET: Large Model, Multiple Loss And Focused Practice
Sep 22, 2023This study presents FP-PET, a comprehensive approach to medical image segmentation with a focus on CT and PET images. Utilizing a dataset from the AutoPet2023 Challenge, the research employs a variety of machine learning models, including STUNet-large, SwinUNETR, and VNet, to achieve state-of-the-art segmentation performance. The paper introduces an aggregated score that combines multiple evaluation metrics such as Dice score, false positive volume (FPV), and false negative volume (FNV) to provide a holistic measure of model effectiveness. The study also discusses the computational challenges and solutions related to model training, which was conducted on high-performance GPUs. Preprocessing and postprocessing techniques, including gaussian weighting schemes and morphological operations, are explored to further refine the segmentation output. The research offers valuable insights into the challenges and solutions for advanced medical image segmentation.
Invisible Watermarking for Audio Generation Diffusion Models
Sep 22, 2023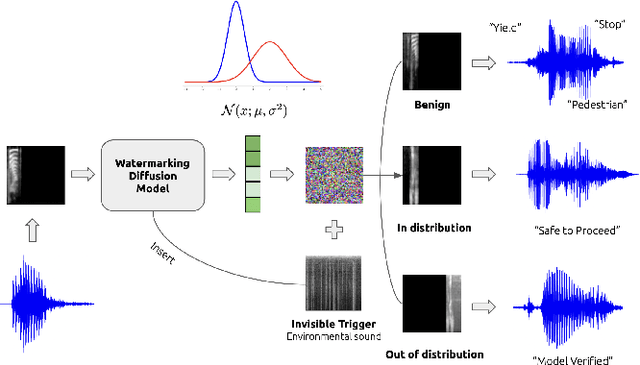

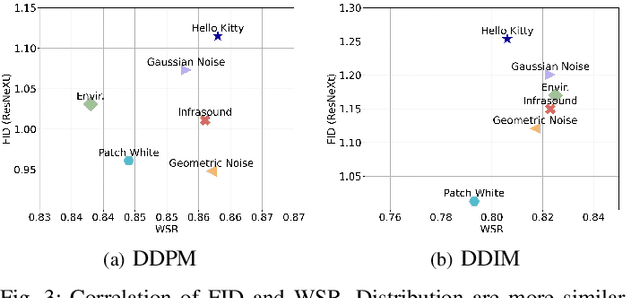
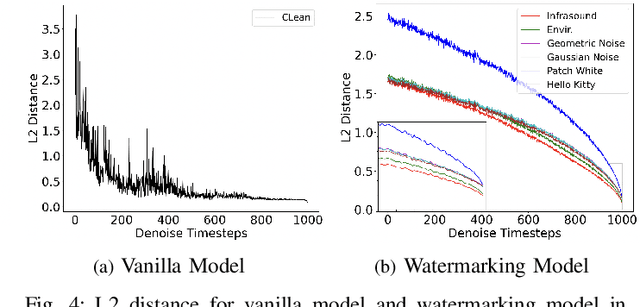
Diffusion models have gained prominence in the image domain for their capabilities in data generation and transformation, achieving state-of-the-art performance in various tasks in both image and audio domains. In the rapidly evolving field of audio-based machine learning, safeguarding model integrity and establishing data copyright are of paramount importance. This paper presents the first watermarking technique applied to audio diffusion models trained on mel-spectrograms. This offers a novel approach to the aforementioned challenges. Our model excels not only in benign audio generation, but also incorporates an invisible watermarking trigger mechanism for model verification. This watermark trigger serves as a protective layer, enabling the identification of model ownership and ensuring its integrity. Through extensive experiments, we demonstrate that invisible watermark triggers can effectively protect against unauthorized modifications while maintaining high utility in benign audio generation tasks.
Intriguing Properties of Diffusion Models: A Large-Scale Dataset for Evaluating Natural Attack Capability in Text-to-Image Generative Models
Aug 30, 2023


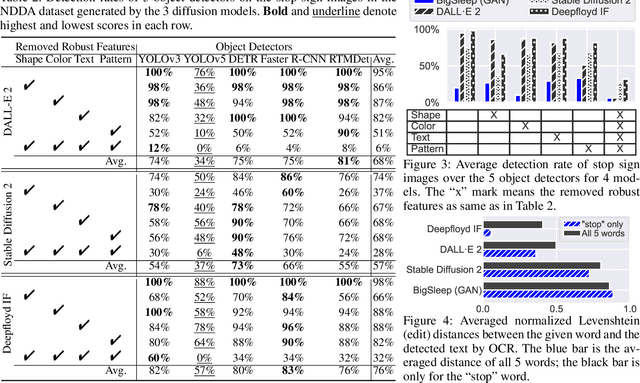
Denoising probabilistic diffusion models have shown breakthrough performance that can generate more photo-realistic images or human-level illustrations than the prior models such as GANs. This high image-generation capability has stimulated the creation of many downstream applications in various areas. However, we find that this technology is indeed a double-edged sword: We identify a new type of attack, called the Natural Denoising Diffusion (NDD) attack based on the finding that state-of-the-art deep neural network (DNN) models still hold their prediction even if we intentionally remove their robust features, which are essential to the human visual system (HVS), by text prompts. The NDD attack can generate low-cost, model-agnostic, and transferrable adversarial attacks by exploiting the natural attack capability in diffusion models. Motivated by the finding, we construct a large-scale dataset, Natural Denoising Diffusion Attack (NDDA) dataset, to systematically evaluate the risk of the natural attack capability of diffusion models with state-of-the-art text-to-image diffusion models. We evaluate the natural attack capability by answering 6 research questions. Through a user study to confirm the validity of the NDD attack, we find that the NDD attack can achieve an 88% detection rate while being stealthy to 93% of human subjects. We also find that the non-robust features embedded by diffusion models contribute to the natural attack capability. To confirm the model-agnostic and transferrable attack capability, we perform the NDD attack against an AD vehicle and find that 73% of the physically printed attacks can be detected as a stop sign. We hope that our study and dataset can help our community to be aware of the risk of diffusion models and facilitate further research toward robust DNN models.
You Do Not Need Additional Priors in Camouflage Object Detection
Oct 01, 2023
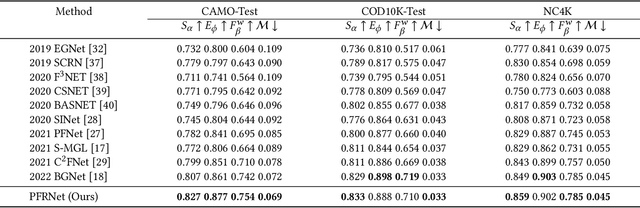
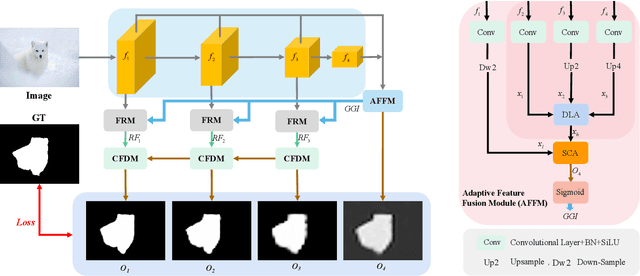
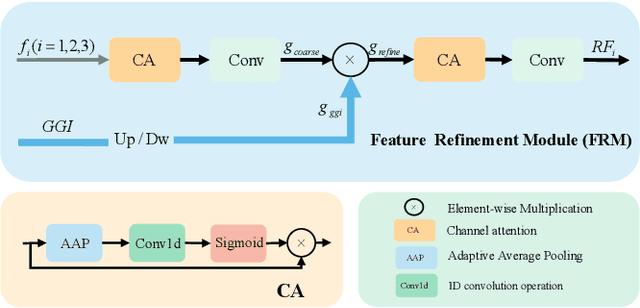
Camouflage object detection (COD) poses a significant challenge due to the high resemblance between camouflaged objects and their surroundings. Although current deep learning methods have made significant progress in detecting camouflaged objects, many of them heavily rely on additional prior information. However, acquiring such additional prior information is both expensive and impractical in real-world scenarios. Therefore, there is a need to develop a network for camouflage object detection that does not depend on additional priors. In this paper, we propose a novel adaptive feature aggregation method that effectively combines multi-layer feature information to generate guidance information. In contrast to previous approaches that rely on edge or ranking priors, our method directly leverages information extracted from image features to guide model training. Through extensive experimental results, we demonstrate that our proposed method achieves comparable or superior performance when compared to state-of-the-art approaches.
GETAvatar: Generative Textured Meshes for Animatable Human Avatars
Oct 04, 2023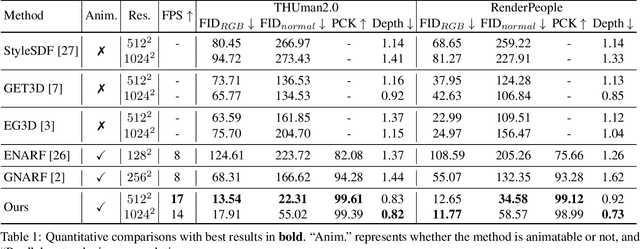
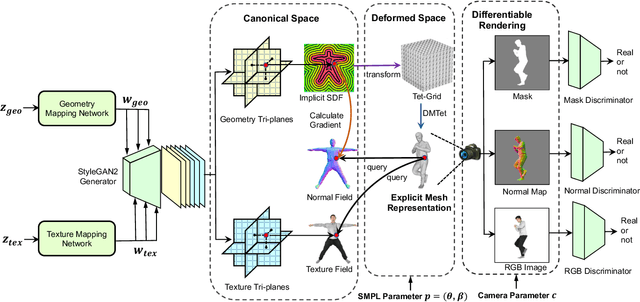
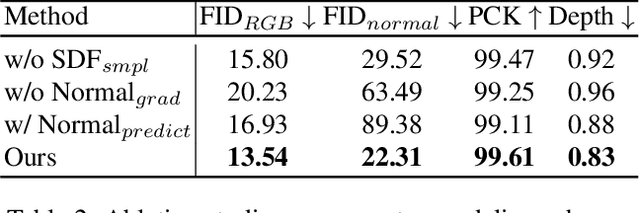

We study the problem of 3D-aware full-body human generation, aiming at creating animatable human avatars with high-quality textures and geometries. Generally, two challenges remain in this field: i) existing methods struggle to generate geometries with rich realistic details such as the wrinkles of garments; ii) they typically utilize volumetric radiance fields and neural renderers in the synthesis process, making high-resolution rendering non-trivial. To overcome these problems, we propose GETAvatar, a Generative model that directly generates Explicit Textured 3D meshes for animatable human Avatar, with photo-realistic appearance and fine geometric details. Specifically, we first design an articulated 3D human representation with explicit surface modeling, and enrich the generated humans with realistic surface details by learning from the 2D normal maps of 3D scan data. Second, with the explicit mesh representation, we can use a rasterization-based renderer to perform surface rendering, allowing us to achieve high-resolution image generation efficiently. Extensive experiments demonstrate that GETAvatar achieves state-of-the-art performance on 3D-aware human generation both in appearance and geometry quality. Notably, GETAvatar can generate images at 512x512 resolution with 17FPS and 1024x1024 resolution with 14FPS, improving upon previous methods by 2x. Our code and models will be available.
MedSyn: Text-guided Anatomy-aware Synthesis of High-Fidelity 3D CT Images
Oct 06, 2023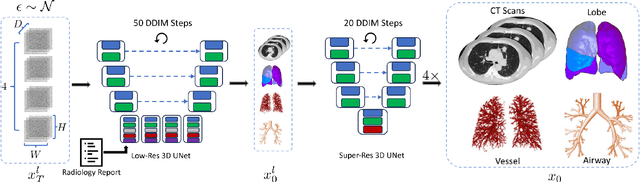
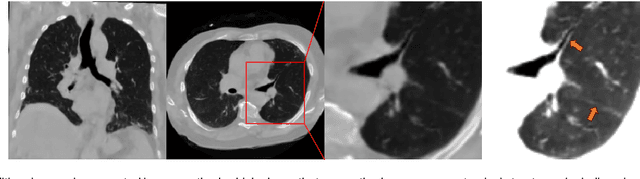
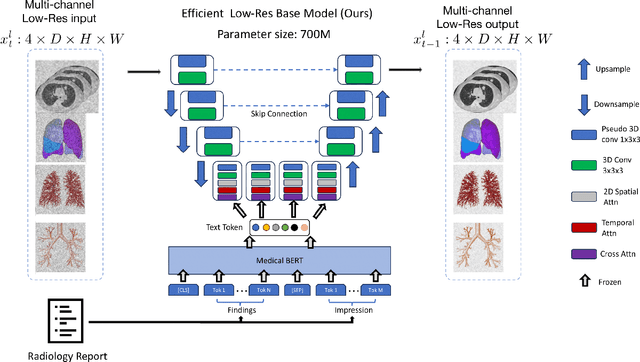
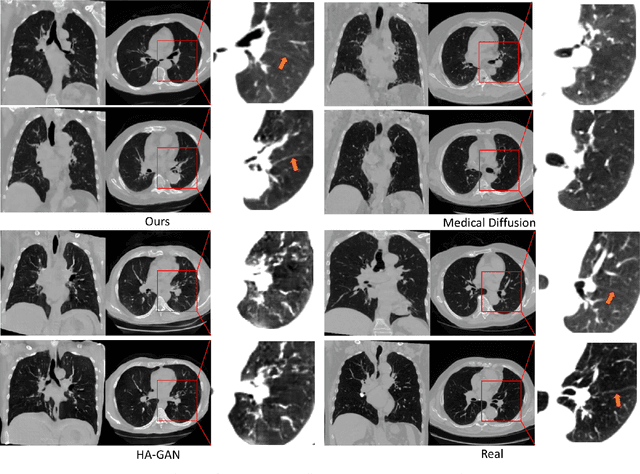
This paper introduces an innovative methodology for producing high-quality 3D lung CT images guided by textual information. While diffusion-based generative models are increasingly used in medical imaging, current state-of-the-art approaches are limited to low-resolution outputs and underutilize radiology reports' abundant information. The radiology reports can enhance the generation process by providing additional guidance and offering fine-grained control over the synthesis of images. Nevertheless, expanding text-guided generation to high-resolution 3D images poses significant memory and anatomical detail-preserving challenges. Addressing the memory issue, we introduce a hierarchical scheme that uses a modified UNet architecture. We start by synthesizing low-resolution images conditioned on the text, serving as a foundation for subsequent generators for complete volumetric data. To ensure the anatomical plausibility of the generated samples, we provide further guidance by generating vascular, airway, and lobular segmentation masks in conjunction with the CT images. The model demonstrates the capability to use textual input and segmentation tasks to generate synthesized images. The results of comparative assessments indicate that our approach exhibits superior performance compared to the most advanced models based on GAN and diffusion techniques, especially in accurately retaining crucial anatomical features such as fissure lines, airways, and vascular structures. This innovation introduces novel possibilities. This study focuses on two main objectives: (1) the development of a method for creating images based on textual prompts and anatomical components, and (2) the capability to generate new images conditioning on anatomical elements. The advancements in image generation can be applied to enhance numerous downstream tasks.
CUPre: Cross-domain Unsupervised Pre-training for Few-Shot Cell Segmentation
Oct 06, 2023While pre-training on object detection tasks, such as Common Objects in Contexts (COCO) [1], could significantly boost the performance of cell segmentation, it still consumes on massive fine-annotated cell images [2] with bounding boxes, masks, and cell types for every cell in every image, to fine-tune the pre-trained model. To lower the cost of annotation, this work considers the problem of pre-training DNN models for few-shot cell segmentation, where massive unlabeled cell images are available but only a small proportion is annotated. Hereby, we propose Cross-domain Unsupervised Pre-training, namely CUPre, transferring the capability of object detection and instance segmentation for common visual objects (learned from COCO) to the visual domain of cells using unlabeled images. Given a standard COCO pre-trained network with backbone, neck, and head modules, CUPre adopts an alternate multi-task pre-training (AMT2) procedure with two sub-tasks -- in every iteration of pre-training, AMT2 first trains the backbone with cell images from multiple cell datasets via unsupervised momentum contrastive learning (MoCo) [3], and then trains the whole model with vanilla COCO datasets via instance segmentation. After pre-training, CUPre fine-tunes the whole model on the cell segmentation task using a few annotated images. We carry out extensive experiments to evaluate CUPre using LIVECell [2] and BBBC038 [4] datasets in few-shot instance segmentation settings. The experiment shows that CUPre can outperform existing pre-training methods, achieving the highest average precision (AP) for few-shot cell segmentation and detection.