 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prescanning Assembly Optimization Criteria for Computed Tomography
Sep 29, 2023
Computerized Tomography assembly and system configuration are optimized for enhanced invertibility in sparse data reconstruction. Assembly generating maximum principal components/condition number of weight matrix is designated as best configuration. The gamma CT system is used for testing. The unoptimized sample location placement with 7.7% variation results in a maximum 50% root mean square error, 16.5% loss of similarity index, and 40% scattering noise in the reconstructed image relative to the optimized sample location when the proposed criteria are used. The method can help to automate the CT assembly, resulting in relatively artifact-free recovery and reducing the iteration to figure out the best scanning configuration for a given sample size, thus saving time, dosage, and operational cost.
Reconstructing Existing Levels through Level Inpainting
Sep 29, 2023Procedural Content Generation (PCG) and Procedural Content Generation via Machine Learning (PCGML) have been used in prior work for generating levels in various games. This paper introduces Content Augmentation and focuses on the subproblem of level inpainting, which involves reconstructing and extending video game levels. Drawing inspiration from image inpainting, we adapt two techniques from this domain to address our specific use case. We present two approaches for level inpainting: an Autoencoder and a U-net. Through a comprehensive case study, we demonstrate their superior performance compared to a baseline method and discuss their relative merits. Furthermore, we provide a practical demonstration of both approaches for the level inpainting task and offer insights into potential directions for future research.
FashionFlow: Leveraging Diffusion Models for Dynamic Fashion Video Synthesis from Static Imagery
Sep 29, 2023Our study introduces a new image-to-video generator called FashionFlow. By utilising a diffusion model, we are able to create short videos from still images. Our approach involves developing and connecting relevant components with the diffusion model, which sets our work apart. The components include the use of pseudo-3D convolutional layers to generate videos efficiently. VAE and CLIP encoders capture vital characteristics from still images to influence the diffusion model. Our research demonstrates a successful synthesis of fashion videos featuring models posing from various angles, showcasing the fit and appearance of the garment. Our findings hold great promise for improving and enhancing the shopping experience for the online fashion industry.
WiDEVIEW: An UltraWideBand and Vision Dataset for Deciphering Pedestrian-Vehicle Interactions
Sep 27, 2023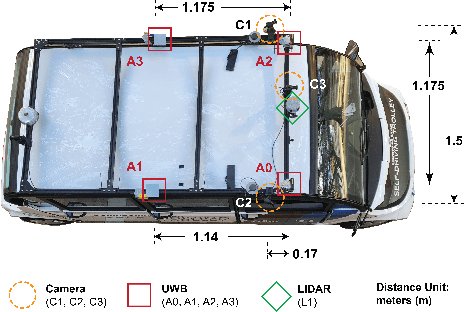

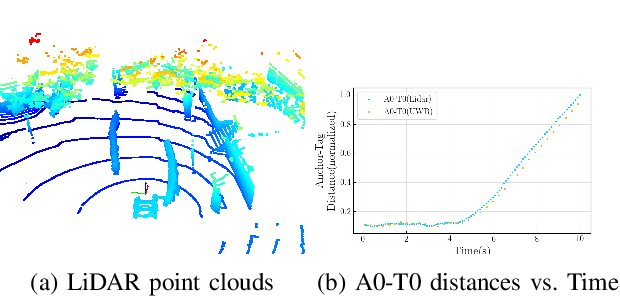
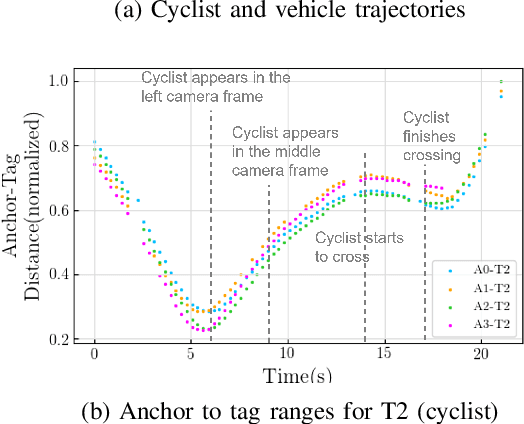
Robust and accurate tracking and localization of road users like pedestrians and cyclists is crucial to ensure safe and effective navigation of Autonomous Vehicles (AVs), particularly so in urban driving scenarios with complex vehicle-pedestrian interactions. Existing datasets that are useful to investigate vehicle-pedestrian interactions are mostly image-centric and thus vulnerable to vision failures. In this paper, we investigate Ultra-wideband (UWB) as an additional modality for road users' localization to enable a better understanding of vehicle-pedestrian interactions. We present WiDEVIEW, the first multimodal dataset that integrates LiDAR, three RGB cameras, GPS/IMU, and UWB sensors for capturing vehicle-pedestrian interactions in an urban autonomous driving scenario. Ground truth image annotations are provided in the form of 2D bounding boxes and the dataset is evaluated on standard 2D object detection and tracking algorithms. The feasibility of UWB is evaluated for typical traffic scenarios in both line-of-sight and non-line-of-sight conditions using LiDAR as ground truth. We establish that UWB range data has comparable accuracy with LiDAR with an error of 0.19 meters and reliable anchor-tag range data for up to 40 meters in line-of-sight conditions. UWB performance for non-line-of-sight conditions is subjective to the nature of the obstruction (trees vs. buildings). Further, we provide a qualitative analysis of UWB performance for scenarios susceptible to intermittent vision failures. The dataset can be downloaded via https://github.com/unmannedlab/UWB_Dataset.
RAWIW: RAW Image Watermarking Robust to ISP Pipeline
Jul 28, 2023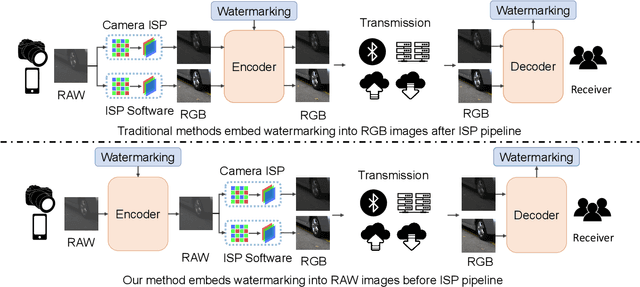
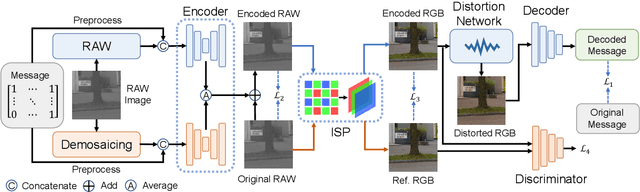


Invisible image watermarking is essential for image copyright protection. Compared to RGB images, RAW format images use a higher dynamic range to capture the radiometric characteristics of the camera sensor, providing greater flexibility in post-processing and retouching. Similar to the master recording in the music industry, RAW images are considered the original format for distribution and image production, thus requiring copyright protection. Existing watermarking methods typically target RGB images, leaving a gap for RAW images. To address this issue, we propose the first deep learning-based RAW Image Watermarking (RAWIW) framework for copyright protection. Unlike RGB image watermarking, our method achieves cross-domain copyright protection. We directly embed copyright information into RAW images, which can be later extracted from the corresponding RGB images generated by different post-processing methods. To achieve end-to-end training of the framework, we integrate a neural network that simulates the ISP pipeline to handle the RAW-to-RGB conversion process. To further validate the generalization of our framework to traditional ISP pipelines and its robustness to transmission distortion, we adopt a distortion network. This network simulates various types of noises introduced during the traditional ISP pipeline and transmission. Furthermore, we employ a three-stage training strategy to strike a balance between robustness and concealment of watermarking. Our extensive experiments demonstrate that RAWIW successfully achieves cross-domain copyright protection for RAW images while maintaining their visual quality and robustness to ISP pipeline distortions.
Cine cardiac MRI reconstruction using a convolutional recurrent network with refinement
Sep 23, 2023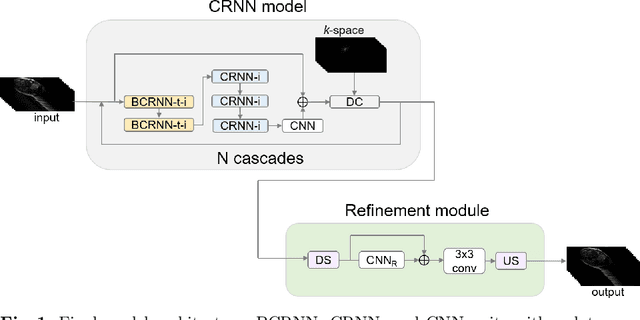
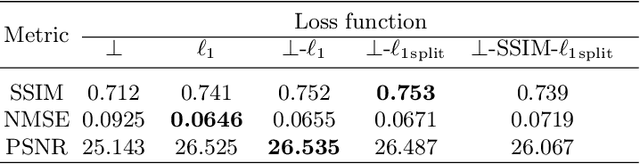
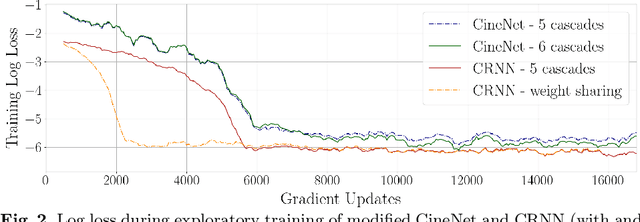
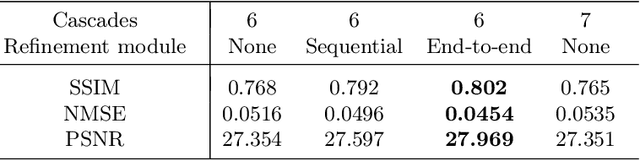
Cine Magnetic Resonance Imaging (MRI) allows for understanding of the heart's function and condition in a non-invasive manner. Undersampling of the $k$-space is employed to reduce the scan duration, thus increasing patient comfort and reducing the risk of motion artefacts, at the cost of reduced image quality. In this challenge paper, we investigate the use of a convolutional recurrent neural network (CRNN) architecture to exploit temporal correlations in supervised cine cardiac MRI reconstruction. This is combined with a single-image super-resolution refinement module to improve single coil reconstruction by 4.4\% in structural similarity and 3.9\% in normalised mean square error compared to a plain CRNN implementation. We deploy a high-pass filter to our $\ell_1$ loss to allow greater emphasis on high-frequency details which are missing in the original data. The proposed model demonstrates considerable enhancements compared to the baseline case and holds promising potential for further improving cardiac MRI reconstruction.
Multi-modal Domain Adaptation for REG via Relation Transfer
Sep 23, 2023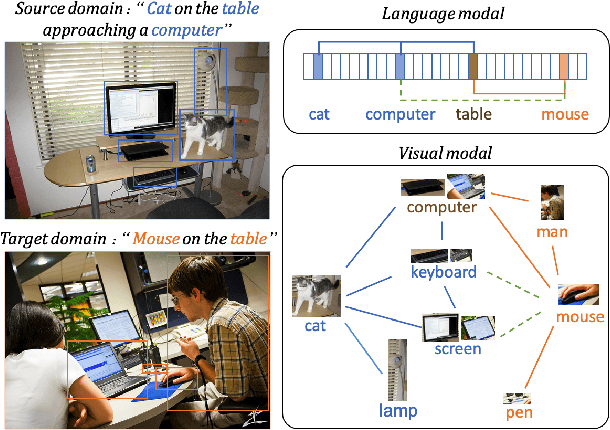

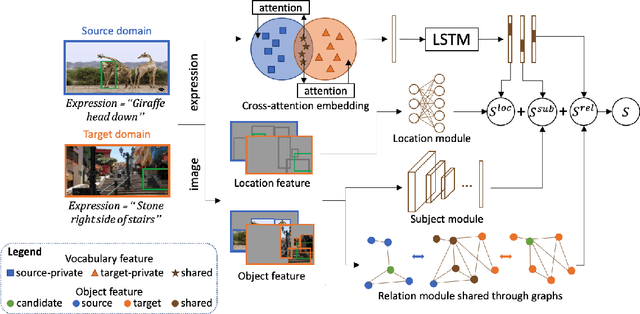
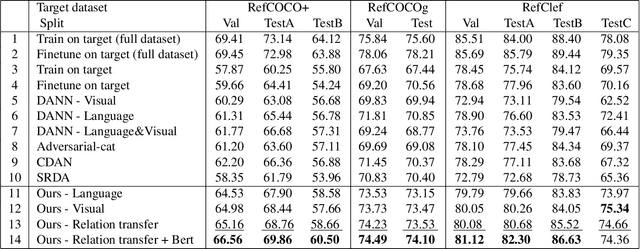
Domain adaptation, which aims to transfer knowledge between domains, has been well studied in many areas such as image classification and object detection. However, for multi-modal tasks, conventional approaches rely on large-scale pre-training. But due to the difficulty of acquiring multi-modal data, large-scale pre-training is often impractical. Therefore, domain adaptation, which can efficiently utilize the knowledge from different datasets (domains), is crucial for multi-modal tasks. In this paper, we focus on the Referring Expression Grounding (REG) task, which is to localize an image region described by a natural language expression. Specifically, we propose a novel approach to effectively transfer multi-modal knowledge through a specially relation-tailored approach for the REG problem. Our approach tackles the multi-modal domain adaptation problem by simultaneously enriching inter-domain relations and transferring relations between domains. Experiments show that our proposed approach significantly improves the transferability of multi-modal domains and enhances adaptation performance in the REG problem.
NeRF-Enhanced Outpainting for Faithful Field-of-View Extrapolation
Sep 23, 2023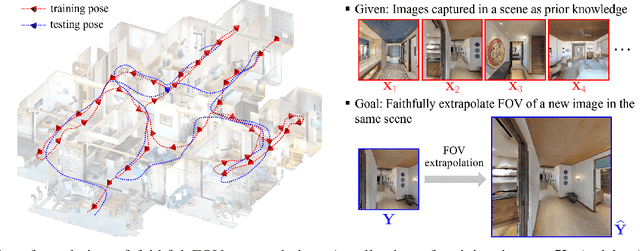



In various applications, such as robotic navigation and remote visual assistance, expanding the field of view (FOV) of the camera proves beneficial for enhancing environmental perception. Unlike image outpainting techniques aimed solely at generating aesthetically pleasing visuals, these applications demand an extended view that faithfully represents the scene. To achieve this, we formulate a new problem of faithful FOV extrapolation that utilizes a set of pre-captured images as prior knowledge of the scene. To address this problem, we present a simple yet effective solution called NeRF-Enhanced Outpainting (NEO) that uses extended-FOV images generated through NeRF to train a scene-specific image outpainting model. To assess the performance of NEO, we conduct comprehensive evaluations on three photorealistic datasets and one real-world dataset. Extensive experiments on the benchmark datasets showcase the robustness and potential of our method in addressing this challenge. We believe our work lays a strong foundation for future exploration within the research community.
Enabling Quartile-based Estimated-Mean Gradient Aggregation As Baseline for Federated Image Classifications
Sep 21, 2023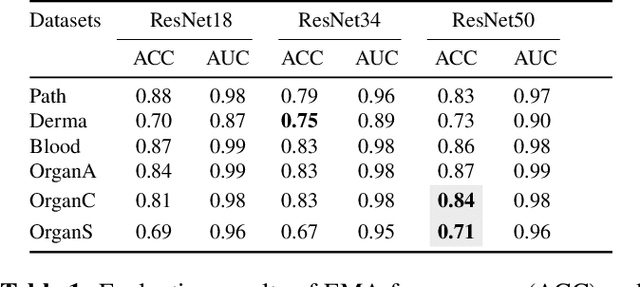
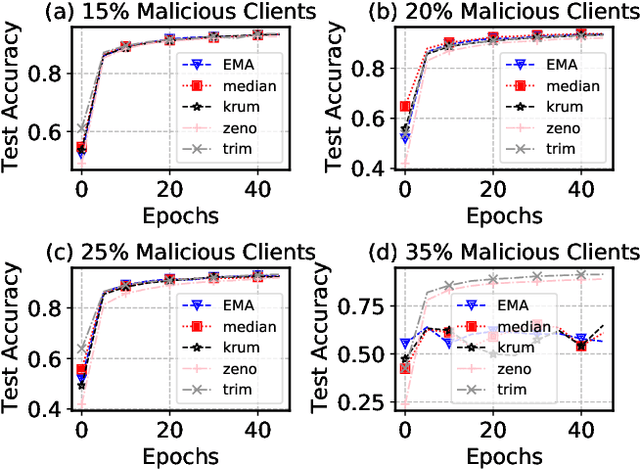
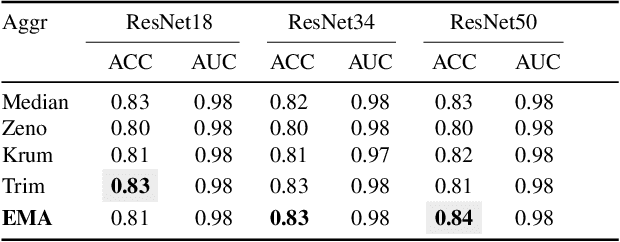
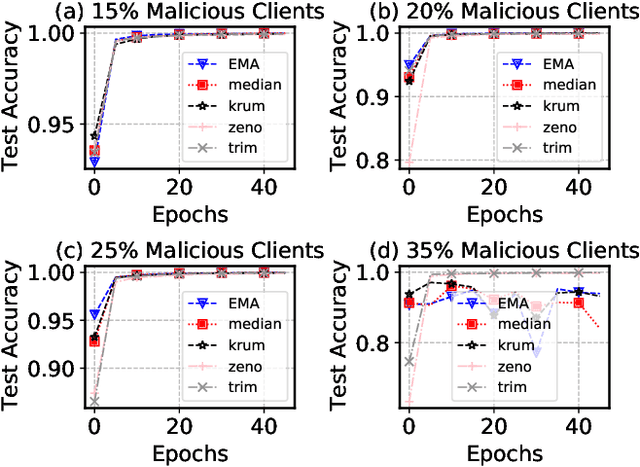
Federated Learning (FL) has revolutionized how we train deep neural networks by enabling decentralized collaboration while safeguarding sensitive data and improving model performance. However, FL faces two crucial challenges: the diverse nature of data held by individual clients and the vulnerability of the FL system to security breaches. This paper introduces an innovative solution named Estimated Mean Aggregation (EMA) that not only addresses these challenges but also provides a fundamental reference point as a $\mathsf{baseline}$ for advanced aggregation techniques in FL systems. EMA's significance lies in its dual role: enhancing model security by effectively handling malicious outliers through trimmed means and uncovering data heterogeneity to ensure that trained models are adaptable across various client datasets. Through a wealth of experiments, EMA consistently demonstrates high accuracy and area under the curve (AUC) compared to alternative methods, establishing itself as a robust baseline for evaluating the effectiveness and security of FL aggregation methods. EMA's contributions thus offer a crucial step forward in advancing the efficiency, security, and versatility of decentralized deep learning in the context of FL.
FP-PET: Large Model, Multiple Loss And Focused Practice
Sep 22, 2023This study presents FP-PET, a comprehensive approach to medical image segmentation with a focus on CT and PET images. Utilizing a dataset from the AutoPet2023 Challenge, the research employs a variety of machine learning models, including STUNet-large, SwinUNETR, and VNet, to achieve state-of-the-art segmentation performance. The paper introduces an aggregated score that combines multiple evaluation metrics such as Dice score, false positive volume (FPV), and false negative volume (FNV) to provide a holistic measure of model effectiveness. The study also discusses the computational challenges and solutions related to model training, which was conducted on high-performance GPUs. Preprocessing and postprocessing techniques, including gaussian weighting schemes and morphological operations, are explored to further refine the segmentation output. The research offers valuable insights into the challenges and solutions for advanced medical image segmentation.