 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Resolving References in Visually-Grounded Dialogue via Text Generation
Sep 23, 2023
Vision-language models (VLMs) have shown to be effective at image retrieval based on simple text queries, but text-image retrieval based on conversational input remains a challenge. Consequently, if we want to use VLMs for reference resolution in visually-grounded dialogue, the discourse processing capabilities of these models need to be augmented. To address this issue, we propose fine-tuning a causal large language model (LLM) to generate definite descriptions that summarize coreferential information found in the linguistic context of references. We then use a pretrained VLM to identify referents based on the generated descriptions, zero-shot. We evaluate our approach on a manually annotated dataset of visually-grounded dialogues and achieve results that, on average, exceed the performance of the baselines we compare against. Furthermore, we find that using referent descriptions based on larger context windows has the potential to yield higher returns.
STARS: Zero-shot Sim-to-Real Transfer for Segmentation of Shipwrecks in Sonar Imagery
Oct 02, 2023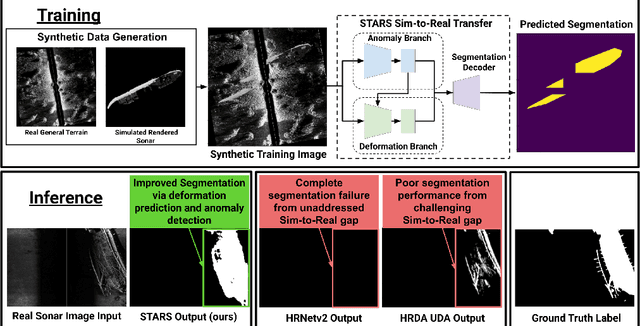
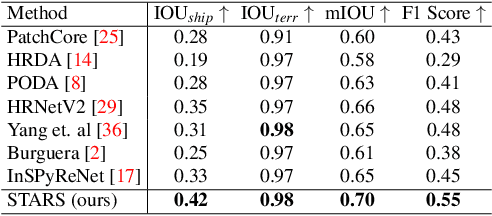

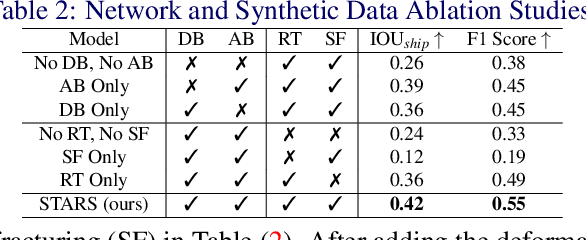
In this paper, we address the problem of sim-to-real transfer for object segmentation when there is no access to real examples of an object of interest during training, i.e. zero-shot sim-to-real transfer for segmentation. We focus on the application of shipwreck segmentation in side scan sonar imagery. Our novel segmentation network, STARS, addresses this challenge by fusing a predicted deformation field and anomaly volume, allowing it to generalize better to real sonar images and achieve more effective zero-shot sim-to-real transfer for image segmentation. We evaluate the sim-to-real transfer capabilities of our method on a real, expert-labeled side scan sonar dataset of shipwrecks collected from field work surveys with an autonomous underwater vehicle (AUV). STARS is trained entirely in simulation and performs zero-shot shipwreck segmentation with no additional fine-tuning on real data. Our method provides a significant 20% increase in segmentation performance for the targeted shipwreck class compared to the best baseline.
Completing Visual Objects via Bridging Generation and Segmentation
Oct 01, 2023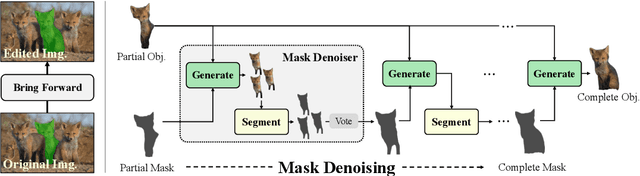
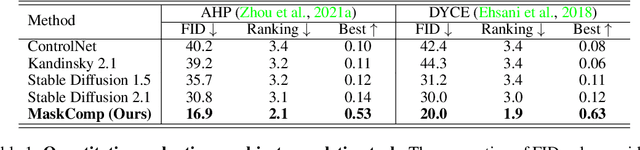


This paper presents a novel approach to object completion, with the primary goal of reconstructing a complete object from its partially visible components. Our method, named MaskComp, delineates the completion process through iterative stages of generation and segmentation. In each iteration, the object mask is provided as an additional condition to boost image generation, and, in return, the generated images can lead to a more accurate mask by fusing the segmentation of images. We demonstrate that the combination of one generation and one segmentation stage effectively functions as a mask denoiser. Through alternation between the generation and segmentation stages, the partial object mask is progressively refined, providing precise shape guidance and yielding superior object completion results. Our experiments demonstrate the superiority of MaskComp over existing approaches, e.g., ControlNet and Stable Diffusion, establishing it as an effective solution for object completion.
Target-aware Bi-Transformer for Few-shot Segmentation
Sep 18, 2023Traditional semantic segmentation tasks require a large number of labels and are difficult to identify unlearned categories. Few-shot semantic segmentation (FSS) aims to use limited labeled support images to identify the segmentation of new classes of objects, which is very practical in the real world. Previous researches were primarily based on prototypes or correlations. Due to colors, textures, and styles are similar in the same image, we argue that the query image can be regarded as its own support image. In this paper, we proposed the Target-aware Bi-Transformer Network (TBTNet) to equivalent treat of support images and query image. A vigorous Target-aware Transformer Layer (TTL) also be designed to distill correlations and force the model to focus on foreground information. It treats the hypercorrelation as a feature, resulting a significant reduction in the number of feature channels. Benefit from this characteristic, our model is the lightest up to now with only 0.4M learnable parameters. Futhermore, TBTNet converges in only 10% to 25% of the training epochs compared to traditional methods. The excellent performance on standard FSS benchmarks of PASCAL-5i and COCO-20i proves the efficiency of our method. Extensive ablation studies were also carried out to evaluate the effectiveness of Bi-Transformer architecture and TTL.
Securing Fixed Neural Network Steganography
Sep 18, 2023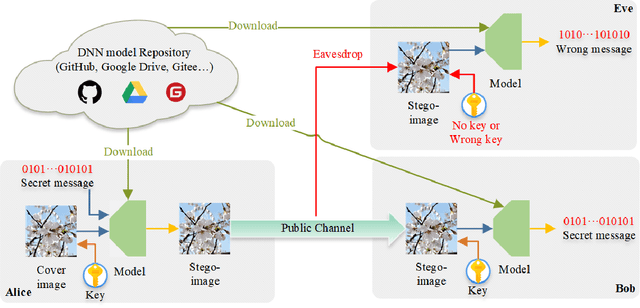

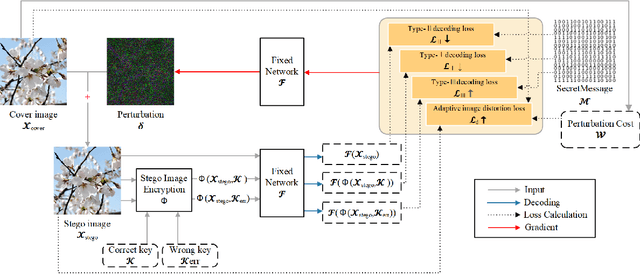
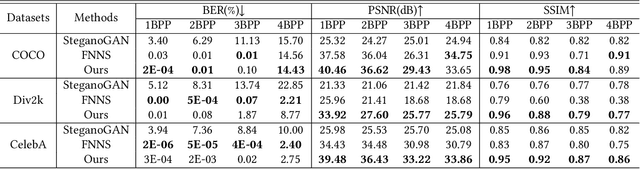
Image steganography is the art of concealing secret information in images in a way that is imperceptible to unauthorized parties. Recent advances show that is possible to use a fixed neural network (FNN) for secret embedding and extraction. Such fixed neural network steganography (FNNS) achieves high steganographic performance without training the networks, which could be more useful in real-world applications. However, the existing FNNS schemes are vulnerable in the sense that anyone can extract the secret from the stego-image. To deal with this issue, we propose a key-based FNNS scheme to improve the security of the FNNS, where we generate key-controlled perturbations from the FNN for data embedding. As such, only the receiver who possesses the key is able to correctly extract the secret from the stego-image using the FNN. In order to improve the visual quality and undetectability of the stego-image, we further propose an adaptive perturbation optimization strategy by taking the perturbation cost into account. Experimental results show that our proposed scheme is capable of preventing unauthorized secret extraction from the stego-images. Furthermore, our scheme is able to generate stego-images with higher visual quality than the state-of-the-art FNNS scheme, especially when the FNN is a neural network for ordinary learning tasks.
SDLFormer: A Sparse and Dense Locality-enhanced Transformer for Accelerated MR Image Reconstruction
Aug 08, 2023Transformers have emerged as viable alternatives to convolutional neural networks owing to their ability to learn non-local region relationships in the spatial domain. The self-attention mechanism of the transformer enables transformers to capture long-range dependencies in the images, which might be desirable for accelerated MRI image reconstruction as the effect of undersampling is non-local in the image domain. Despite its computational efficiency, the window-based transformers suffer from restricted receptive fields as the dependencies are limited to within the scope of the image windows. We propose a window-based transformer network that integrates dilated attention mechanism and convolution for accelerated MRI image reconstruction. The proposed network consists of dilated and dense neighborhood attention transformers to enhance the distant neighborhood pixel relationship and introduce depth-wise convolutions within the transformer module to learn low-level translation invariant features for accelerated MRI image reconstruction. The proposed model is trained in a self-supervised manner. We perform extensive experiments for multi-coil MRI acceleration for coronal PD, coronal PDFS and axial T2 contrasts with 4x and 5x under-sampling in self-supervised learning based on k-space splitting. We compare our method against other reconstruction architectures and the parallel domain self-supervised learning baseline. Results show that the proposed model exhibits improvement margins of (i) around 1.40 dB in PSNR and around 0.028 in SSIM on average over other architectures (ii) around 1.44 dB in PSNR and around 0.029 in SSIM over parallel domain self-supervised learning. The code is available at https://github.com/rahul-gs-16/sdlformer.git
R-C-P Method: An Autonomous Volume Calculation Method Using Image Processing and Machine Vision
Aug 19, 2023
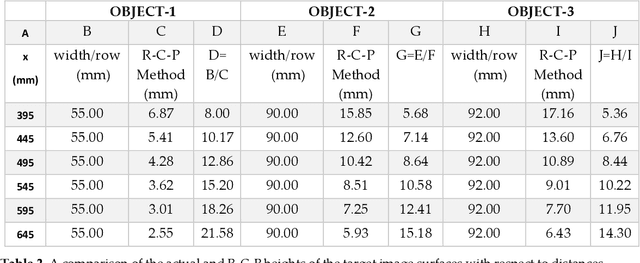

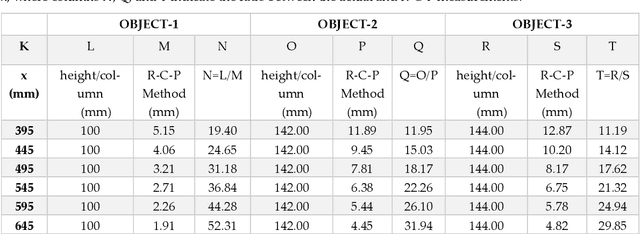
Machine vision and image processing are often used with sensors for situation awareness in autonomous systems, from industrial robots to self-driving cars. The 3D depth sensors, such as LiDAR (Light Detection and Ranging), Radar, are great invention for autonomous systems. Due to the complexity of the setup, LiDAR may not be suitable for some operational environments, for example, a space environment. This study was motivated by a desire to get real-time volumetric and change information with multiple 2D cameras instead of a depth camera. Two cameras were used to measure the dimensions of a rectangular object in real-time. The R-C-P (row-column-pixel) method is developed using image processing and edge detection. In addition to the surface areas, the R-C-P method also detects discontinuous edges or volumes. Lastly, experimental work is presented for illustration of the R-C-P method, which provides the equations for calculating surface area dimensions. Using the equations with given distance information between the object and the camera, the vision system provides the dimensions of actual objects.
Pixel-Grounded Prototypical Part Networks
Sep 25, 2023Prototypical part neural networks (ProtoPartNNs), namely PROTOPNET and its derivatives, are an intrinsically interpretable approach to machine learning. Their prototype learning scheme enables intuitive explanations of the form, this (prototype) looks like that (testing image patch). But, does this actually look like that? In this work, we delve into why object part localization and associated heat maps in past work are misleading. Rather than localizing to object parts, existing ProtoPartNNs localize to the entire image, contrary to generated explanatory visualizations. We argue that detraction from these underlying issues is due to the alluring nature of visualizations and an over-reliance on intuition. To alleviate these issues, we devise new receptive field-based architectural constraints for meaningful localization and a principled pixel space mapping for ProtoPartNNs. To improve interpretability, we propose additional architectural improvements, including a simplified classification head. We also make additional corrections to PROTOPNET and its derivatives, such as the use of a validation set, rather than a test set, to evaluate generalization during training. Our approach, PIXPNET (Pixel-grounded Prototypical part Network), is the only ProtoPartNN that truly learns and localizes to prototypical object parts. We demonstrate that PIXPNET achieves quantifiably improved interpretability without sacrificing accuracy.
Grounded Image Text Matching with Mismatched Relation Reasoning
Aug 04, 2023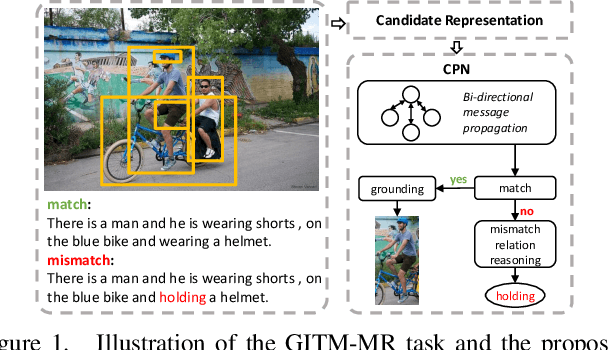

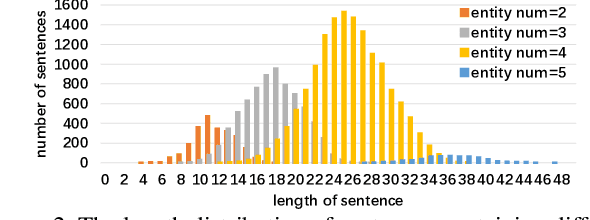
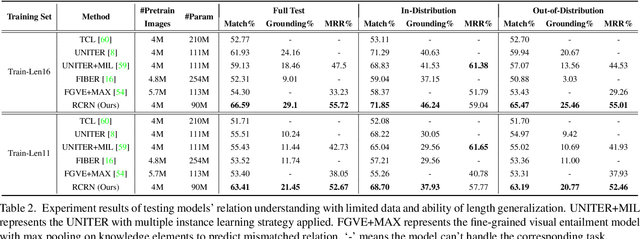
This paper introduces Grounded Image Text Matching with Mismatched Relation (GITM-MR), a novel visual-linguistic joint task that evaluates the relation understanding capabilities of transformer-based pre-trained models. GITM-MR requires a model to first determine if an expression describes an image, then localize referred objects or ground the mismatched parts of the text. We provide a benchmark for evaluating pre-trained models on this task, with a focus on the challenging settings of limited data and out-of-distribution sentence lengths. Our evaluation demonstrates that pre-trained models lack data efficiency and length generalization ability. To address this, we propose the Relation-sensitive Correspondence Reasoning Network (RCRN), which incorporates relation-aware reasoning via bi-directional message propagation guided by language structure. RCRN can be interpreted as a modular program and delivers strong performance in both length generalization and data efficiency.
GAEI-UNet: Global Attention and Elastic Interaction U-Net for Vessel Image Segmentation
Aug 16, 2023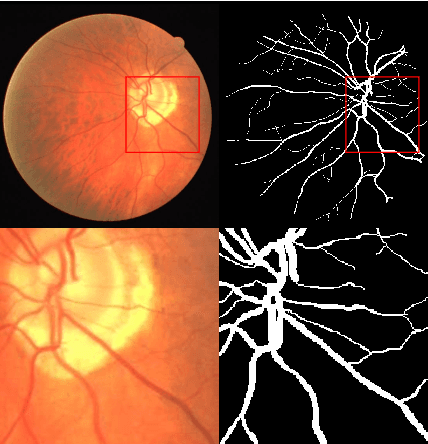
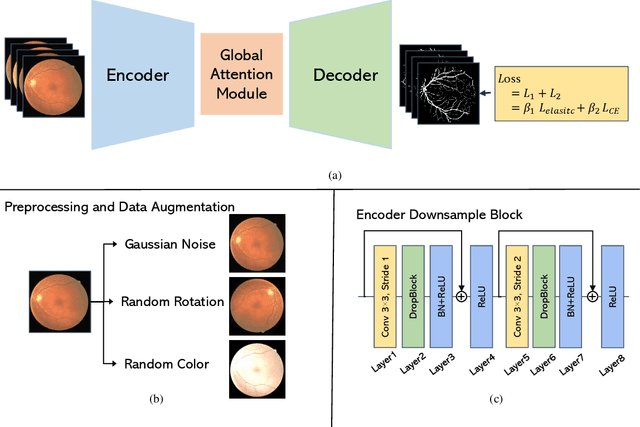
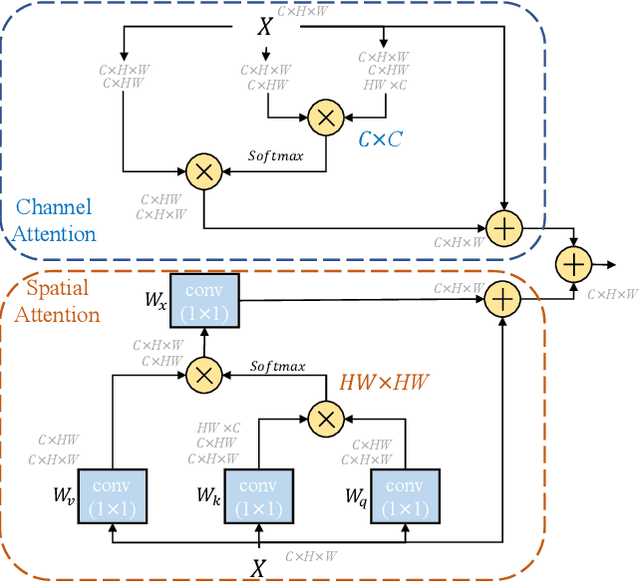
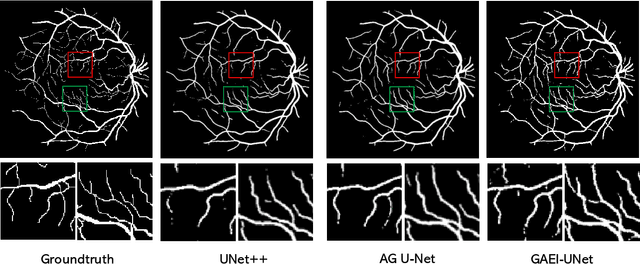
Vessel image segmentation plays a pivotal role in medical diagnostics, aiding in the early detection and treatment of vascular diseases. While segmentation based on deep learning has shown promising results, effectively segmenting small structures and maintaining connectivity between them remains challenging. To address these limitations, we propose GAEI-UNet, a novel model that combines global attention and elastic interaction-based techniques. GAEI-UNet leverages global spatial and channel context information to enhance high-level semantic understanding within the U-Net architecture, enabling precise segmentation of small vessels. Additionally, we adopt an elastic interaction-based loss function to improve connectivity among these fine structures. By capturing the forces generated by misalignment between target and predicted shapes, our model effectively learns to preserve the correct topology of vessel networks. Evaluation on retinal vessel dataset -- DRIVE demonstrates the superior performance of GAEI-UNet in terms of SE and connectivity of small structures, without significantly increasing computational complexity. This research aims to advance the field of vessel image segmentation, providing more accurate and reliable diagnostic tools for the medical community. The implementation code is available on Code.