 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AI4Food-NutritionFW: A Novel Framework for the Automatic Synthesis and Analysis of Eating Behaviours
Sep 12, 2023
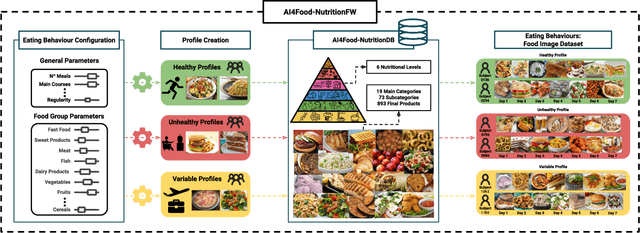
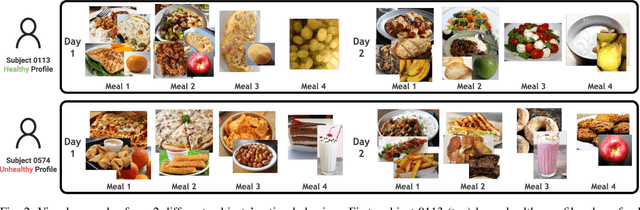
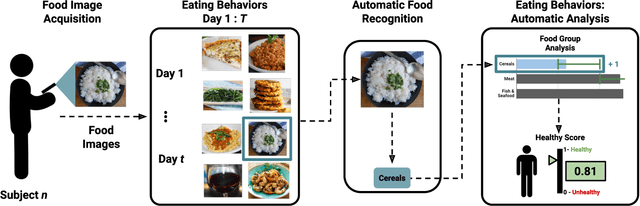
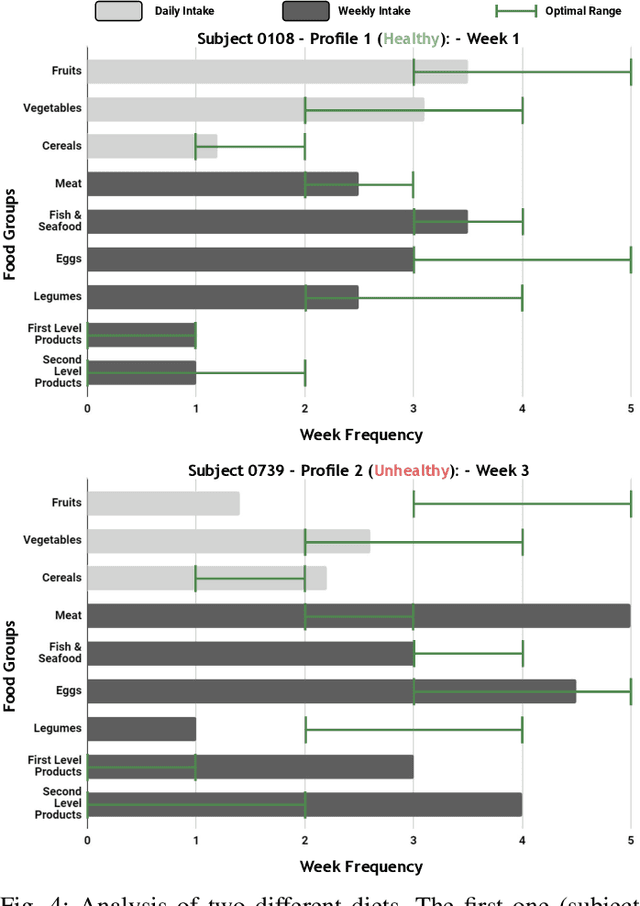
Nowadays millions of images are shared on social media and web platforms. In particular, many of them are food images taken from a smartphone over time, providing information related to the individual's diet. On the other hand, eating behaviours are directly related to some of the most prevalent diseases in the world. Exploiting recent advances in image processing and Artificial Intelligence (AI), this scenario represents an excellent opportunity to: i) create new methods that analyse the individuals' health from what they eat, and ii) develop personalised recommendations to improve nutrition and diet under specific circumstances (e.g., obesity or COVID). Having tunable tools for creating food image datasets that facilitate research in both lines is very much needed. This paper proposes AI4Food-NutritionFW, a framework for the creation of food image datasets according to configurable eating behaviours. AI4Food-NutritionFW simulates a user-friendly and widespread scenario where images are taken using a smartphone. In addition to the framework, we also provide and describe a unique food image dataset that includes 4,800 different weekly eating behaviours from 15 different profiles and 1,200 subjects. Specifically, we consider profiles that comply with actual lifestyles from healthy eating behaviours (according to established knowledge), variable profiles (e.g., eating out, holidays), to unhealthy ones (e.g., excess of fast food or sweets). Finally, we automatically evaluate a healthy index of the subject's eating behaviours using multidimensional metrics based on guidelines for healthy diets proposed by international organisations, achieving promising results (99.53% and 99.60% accuracy and sensitivity, respectively). We also release to the research community a software implementation of our proposed AI4Food-NutritionFW and the mentioned food image dataset created with it.
PGDiff: Guiding Diffusion Models for Versatile Face Restoration via Partial Guidance
Sep 19, 2023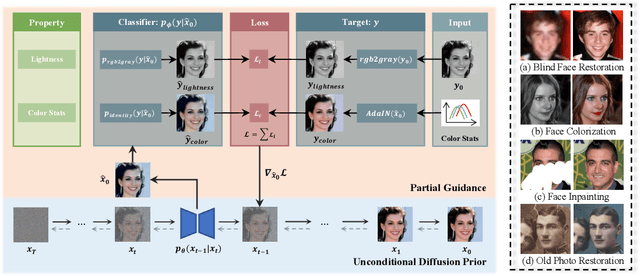
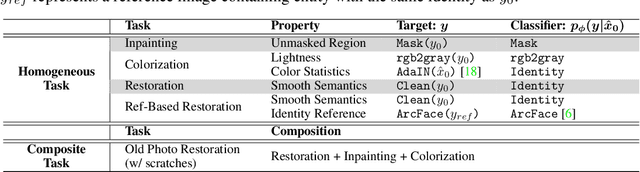


Exploiting pre-trained diffusion models for restoration has recently become a favored alternative to the traditional task-specific training approach. Previous works have achieved noteworthy success by limiting the solution space using explicit degradation models. However, these methods often fall short when faced with complex degradations as they generally cannot be precisely modeled. In this paper, we propose PGDiff by introducing partial guidance, a fresh perspective that is more adaptable to real-world degradations compared to existing works. Rather than specifically defining the degradation process, our approach models the desired properties, such as image structure and color statistics of high-quality images, and applies this guidance during the reverse diffusion process. These properties are readily available and make no assumptions about the degradation process. When combined with a diffusion prior, this partial guidance can deliver appealing results across a range of restoration tasks. Additionally, PGDiff can be extended to handle composite tasks by consolidating multiple high-quality image properties, achieved by integrating the guidance from respective tasks. Experimental results demonstrate that our method not only outperforms existing diffusion-prior-based approaches but also competes favorably with task-specific models.
Tell Me a Story! Narrative-Driven XAI with Large Language Models
Sep 29, 2023


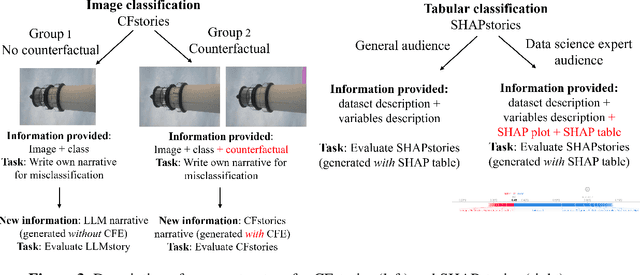
In today's critical domains, the predominance of black-box machine learning models amplifies the demand for Explainable AI (XAI). The widely used SHAP values, while quantifying feature importance, are often too intricate and lack human-friendly explanations. Furthermore, counterfactual (CF) explanations present `what ifs' but leave users grappling with the 'why'. To bridge this gap, we introduce XAIstories. Leveraging Large Language Models, XAIstories provide narratives that shed light on AI predictions: SHAPstories do so based on SHAP explanations to explain a prediction score, while CFstories do so for CF explanations to explain a decision. Our results are striking: over 90% of the surveyed general audience finds the narrative generated by SHAPstories convincing. Data scientists primarily see the value of SHAPstories in communicating explanations to a general audience, with 92% of data scientists indicating that it will contribute to the ease and confidence of nonspecialists in understanding AI predictions. Additionally, 83% of data scientists indicate they are likely to use SHAPstories for this purpose. In image classification, CFstories are considered more or equally convincing as users own crafted stories by over 75% of lay user participants. CFstories also bring a tenfold speed gain in creating a narrative, and improves accuracy by over 20% compared to manually created narratives. The results thereby suggest that XAIstories may provide the missing link in truly explaining and understanding AI predictions.
When Epipolar Constraint Meets Non-local Operators in Multi-View Stereo
Sep 29, 2023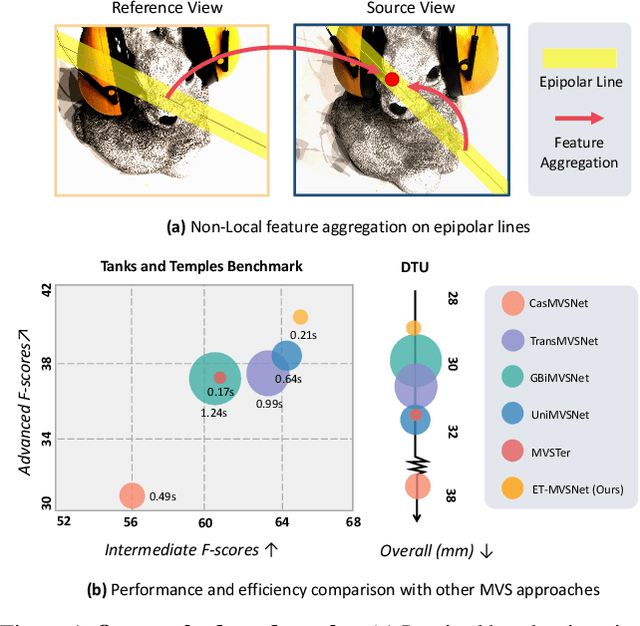
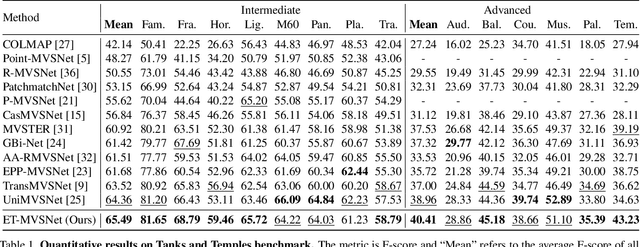
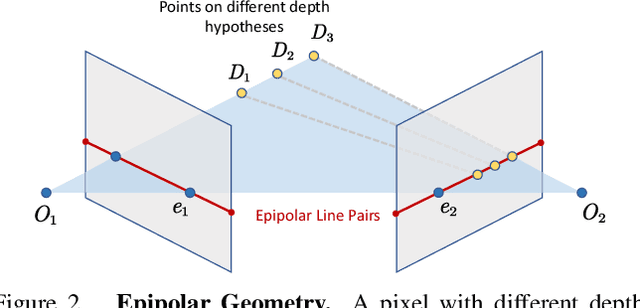
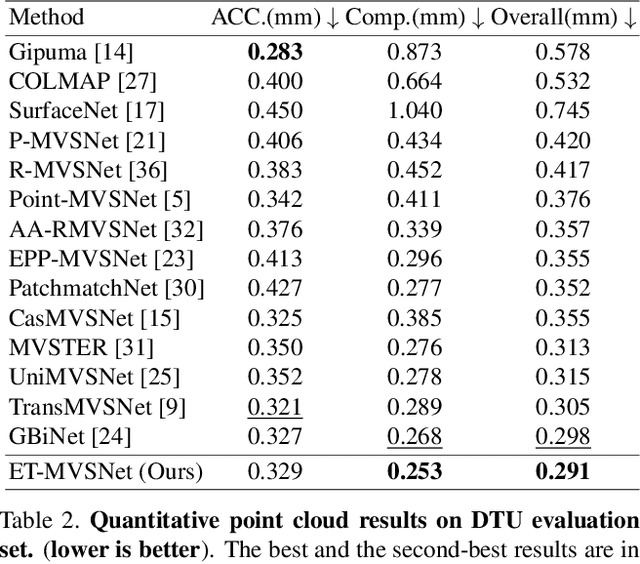
Learning-based multi-view stereo (MVS) method heavily relies on feature matching, which requires distinctive and descriptive representations. An effective solution is to apply non-local feature aggregation, e.g., Transformer. Albeit useful, these techniques introduce heavy computation overheads for MVS. Each pixel densely attends to the whole image. In contrast, we propose to constrain non-local feature augmentation within a pair of lines: each point only attends the corresponding pair of epipolar lines. Our idea takes inspiration from the classic epipolar geometry, which shows that one point with different depth hypotheses will be projected to the epipolar line on the other view. This constraint reduces the 2D search space into the epipolar line in stereo matching. Similarly, this suggests that the matching of MVS is to distinguish a series of points lying on the same line. Inspired by this point-to-line search, we devise a line-to-point non-local augmentation strategy. We first devise an optimized searching algorithm to split the 2D feature maps into epipolar line pairs. Then, an Epipolar Transformer (ET) performs non-local feature augmentation among epipolar line pairs. We incorporate the ET into a learning-based MVS baseline, named ET-MVSNet. ET-MVSNet achieves state-of-the-art reconstruction performance on both the DTU and Tanks-and-Temples benchmark with high efficiency. Code is available at https://github.com/TQTQliu/ET-MVSNet.
Bi-Level Image-Guided Ergodic Exploration with Applications to Planetary Rovers
Jul 31, 2023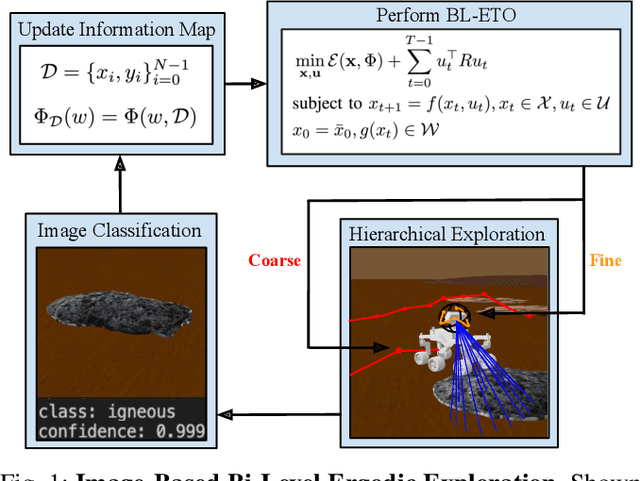
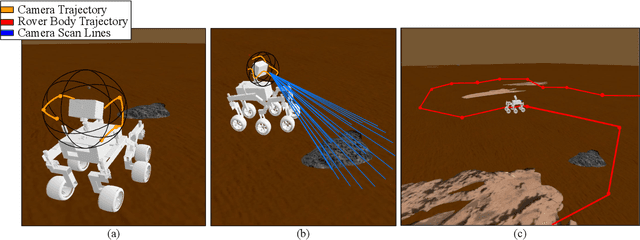

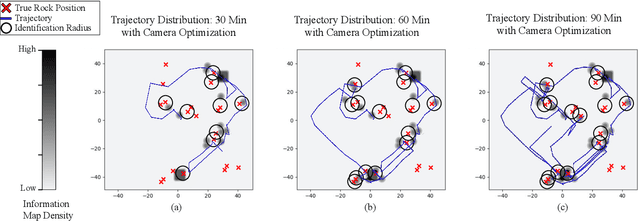
We present a method for image-guided exploration for mobile robotic systems. Our approach extends ergodic exploration methods, a recent exploration approach that prioritizes complete coverage of a space, with the use of a learned image classifier that automatically detects objects and updates an information map to guide further exploration and localization of objects. Additionally, to improve outcomes of the information collected by our robot's visual sensor, we present a decomposition of the ergodic optimization problem as bi-level coarse and fine solvers, which act respectively on the robot's body and the robot's visual sensor. Our approach is applied to geological survey and localization of rock formations for Mars rovers, with real images from Mars rovers used to train the image classifier. Results demonstrate 1) improved localization of rock formations compared to naive approaches while 2) minimizing the path length of the exploration through the bi-level exploration.
Multi-scale Target-Aware Framework for Constrained Image Splicing Detection and Localization
Aug 21, 2023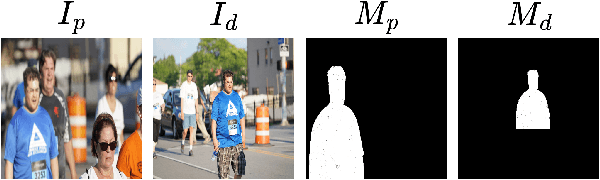
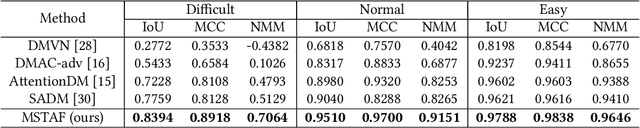
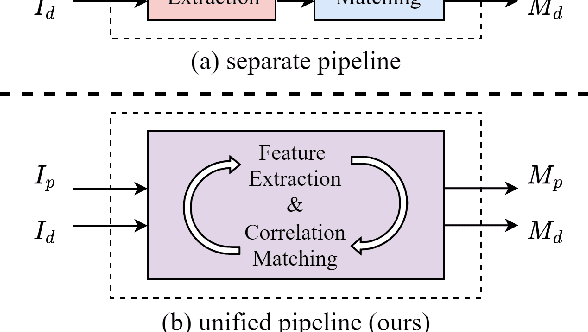
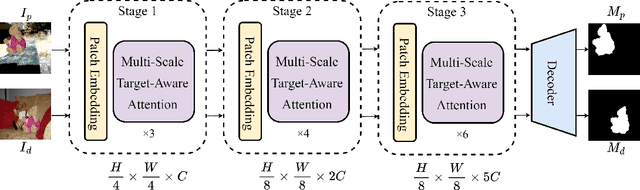
Constrained image splicing detection and localization (CISDL) is a fundamental task of multimedia forensics, which detects splicing operation between two suspected images and localizes the spliced region on both images. Recent works regard it as a deep matching problem and have made significant progress. However, existing frameworks typically perform feature extraction and correlation matching as separate processes, which may hinder the model's ability to learn discriminative features for matching and can be susceptible to interference from ambiguous background pixels. In this work, we propose a multi-scale target-aware framework to couple feature extraction and correlation matching in a unified pipeline. In contrast to previous methods, we design a target-aware attention mechanism that jointly learns features and performs correlation matching between the probe and donor images. Our approach can effectively promote the collaborative learning of related patches, and perform mutual promotion of feature learning and correlation matching. Additionally, in order to handle scale transformations, we introduce a multi-scale projection method, which can be readily integrated into our target-aware framework that enables the attention process to be conducted between tokens containing information of varying scales. Our experiments demonstrate that our model, which uses a unified pipeline, outperforms state-of-the-art methods on several benchmark datasets and is robust against scale transformations.
Towards Comparable Knowledge Distillation in Semantic Image Segmentation
Sep 07, 2023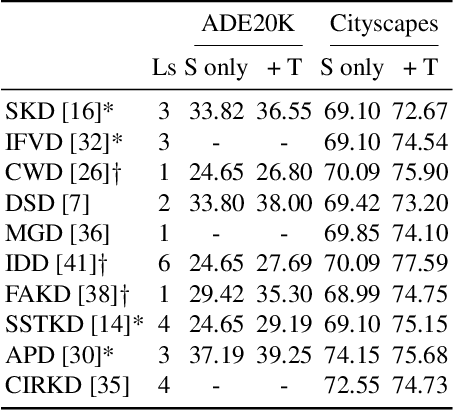
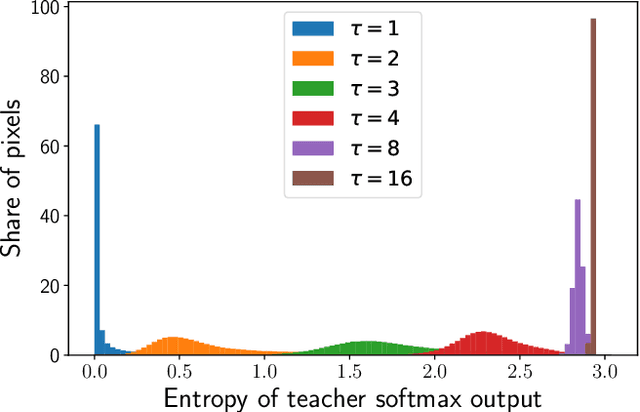
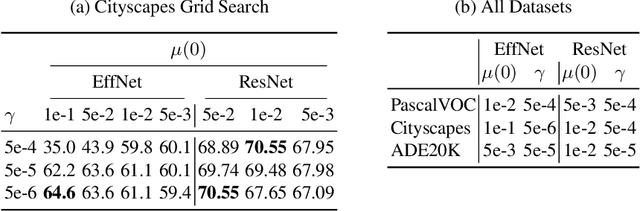
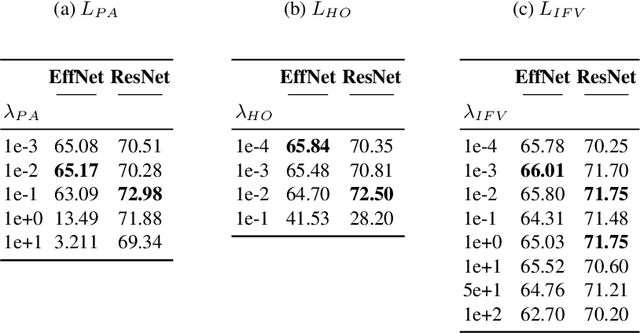
Knowledge Distillation (KD) is one proposed solution to large model sizes and slow inference speed in semantic segmentation. In our research we identify 25 proposed distillation loss terms from 14 publications in the last 4 years. Unfortunately, a comparison of terms based on published results is often impossible, because of differences in training configurations. A good illustration of this problem is the comparison of two publications from 2022. Using the same models and dataset, Structural and Statistical Texture Distillation (SSTKD) reports an increase of student mIoU of 4.54 and a final performance of 29.19, while Adaptive Perspective Distillation (APD) only improves student performance by 2.06 percentage points, but achieves a final performance of 39.25. The reason for such extreme differences is often a suboptimal choice of hyperparameters and a resulting underperformance of the student model used as reference point. In our work, we reveal problems of insufficient hyperparameter tuning by showing that distillation improvements of two widely accepted frameworks, SKD and IFVD, vanish when hyperparameters are optimized sufficiently. To improve comparability of future research in the field, we establish a solid baseline for three datasets and two student models and provide extensive information on hyperparameter tuning. We find that only two out of eight techniques can compete with our simple baseline on the ADE20K dataset.
An Image is Worth a Thousand Toxic Words: A Metamorphic Testing Framework for Content Moderation Software
Aug 18, 2023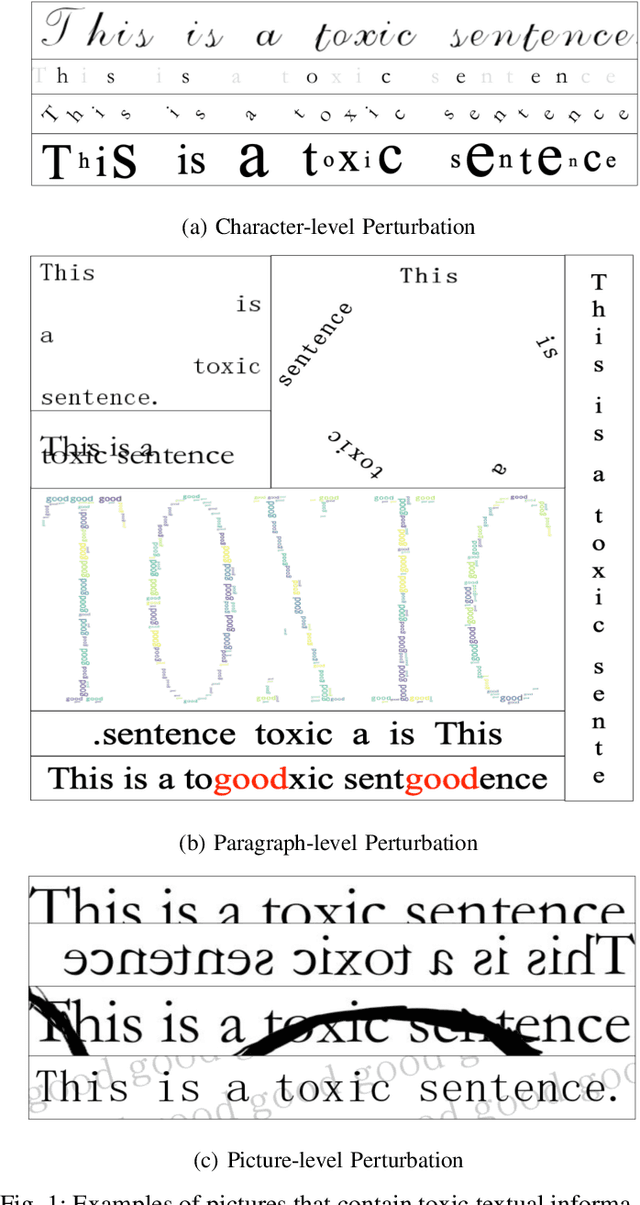
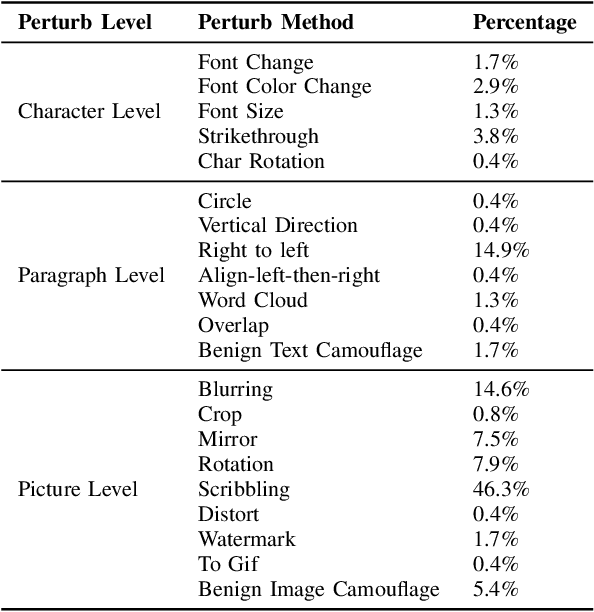
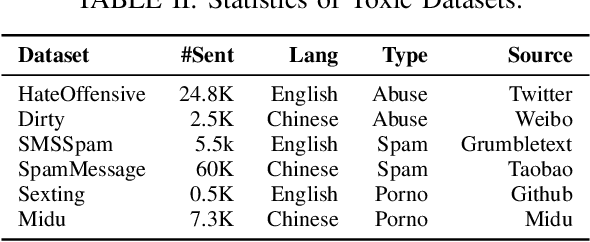
The exponential growth of social media platforms has brought about a revolution in communication and content dissemination in human society. Nevertheless, these platforms are being increasingly misused to spread toxic content, including hate speech, malicious advertising, and pornography, leading to severe negative consequences such as harm to teenagers' mental health. Despite tremendous efforts in developing and deploying textual and image content moderation methods, malicious users can evade moderation by embedding texts into images, such as screenshots of the text, usually with some interference. We find that modern content moderation software's performance against such malicious inputs remains underexplored. In this work, we propose OASIS, a metamorphic testing framework for content moderation software. OASIS employs 21 transform rules summarized from our pilot study on 5,000 real-world toxic contents collected from 4 popular social media applications, including Twitter, Instagram, Sina Weibo, and Baidu Tieba. Given toxic textual contents, OASIS can generate image test cases, which preserve the toxicity yet are likely to bypass moderation. In the evaluation, we employ OASIS to test five commercial textual content moderation software from famous companies (i.e., Google Cloud, Microsoft Azure, Baidu Cloud, Alibaba Cloud and Tencent Cloud), as well as a state-of-the-art moderation research model. The results show that OASIS achieves up to 100% error finding rates. Moreover, through retraining the models with the test cases generated by OASIS, the robustness of the moderation model can be improved without performance degradation.
The Impact of Background Removal on Performance of Neural Networks for Fashion Image Classification and Segmentation
Aug 18, 2023

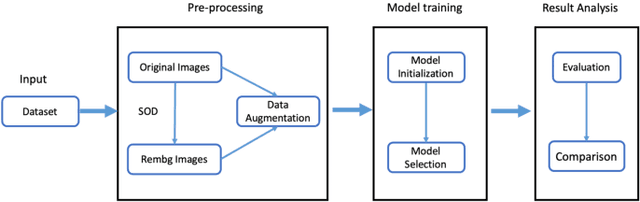
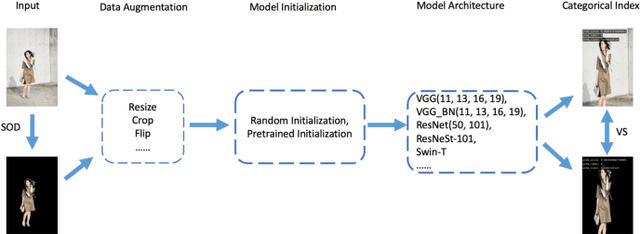
Fashion understanding is a hot topic in computer vision, with many applications having great business value in the market. Fashion understanding remains a difficult challenge for computer vision due to the immense diversity of garments and various scenes and backgrounds. In this work, we try removing the background from fashion images to boost data quality and increase model performance. Having fashion images of evident persons in fully visible garments, we can utilize Salient Object Detection to achieve the background removal of fashion data to our expectations. A fashion image with the background removed is claimed as the "rembg" image, contrasting with the original one in the fashion dataset. We conducted extensive comparative experiments with these two types of images on multiple aspects of model training, including model architectures, model initialization, compatibility with other training tricks and data augmentations, and target task types. Our experiments show that background removal can effectively work for fashion data in simple and shallow networks that are not susceptible to overfitting. It can improve model accuracy by up to 5% in the classification on the FashionStyle14 dataset when training models from scratch. However, background removal does not perform well in deep neural networks due to incompatibility with other regularization techniques like batch normalization, pre-trained initialization, and data augmentations introducing randomness. The loss of background pixels invalidates many existing training tricks in the model training, adding the risk of overfitting for deep models.
Robust estimation of exposure ratios in multi-exposure image stacks
Aug 05, 2023

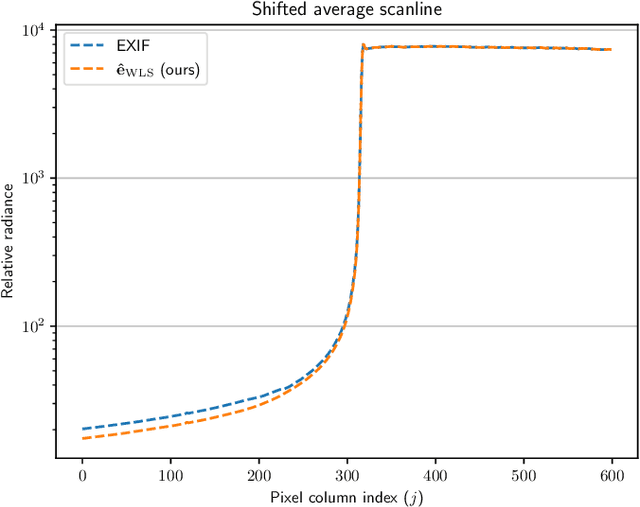
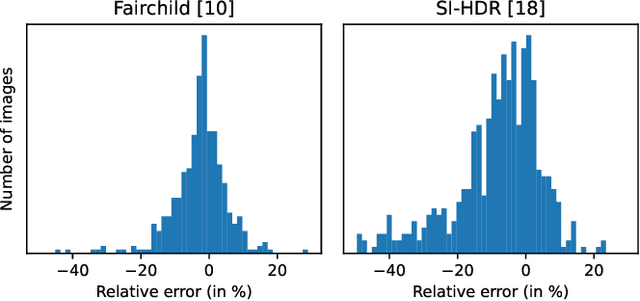
Merging multi-exposure image stacks into a high dynamic range (HDR) image requires knowledge of accurate exposure times. When exposure times are inaccurate, for example, when they are extracted from a camera's EXIF metadata, the reconstructed HDR images reveal banding artifacts at smooth gradients. To remedy this, we propose to estimate exposure ratios directly from the input images. We derive the exposure time estimation as an optimization problem, in which pixels are selected from pairs of exposures to minimize estimation error caused by camera noise. When pixel values are represented in the logarithmic domain, the problem can be solved efficiently using a linear solver. We demonstrate that the estimation can be easily made robust to pixel misalignment caused by camera or object motion by collecting pixels from multiple spatial tiles. The proposed automatic exposure estimation and alignment eliminates banding artifacts in popular datasets and is essential for applications that require physically accurate reconstructions, such as measuring the modulation transfer function of a display. The code for the method is available.