 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Zero-Shot Visual Classification with Guided Cropping
Sep 12, 2023
Pretrained vision-language models, such as CLIP, show promising zero-shot performance across a wide variety of datasets. For closed-set classification tasks, however, there is an inherent limitation: CLIP image encoders are typically designed to extract generic image-level features that summarize superfluous or confounding information for the target tasks. This results in degradation of classification performance, especially when objects of interest cover small areas of input images. In this work, we propose CLIP with Guided Cropping (GC-CLIP), where we use an off-the-shelf zero-shot object detection model in a preprocessing step to increase focus of zero-shot classifier to the object of interest and minimize influence of extraneous image regions. We empirically show that our approach improves zero-shot classification results across architectures and datasets, favorably for small objects.
SAR Target Image Generation Method Using Azimuth-Controllable Generative Adversarial Network
Aug 10, 2023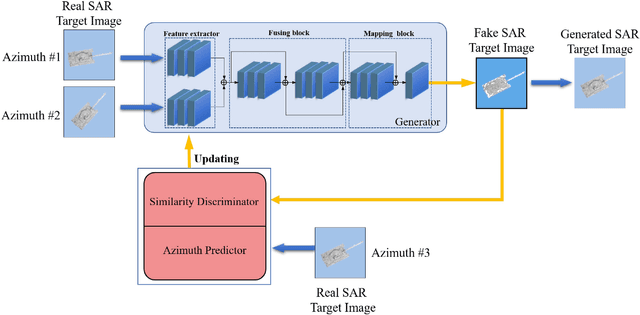
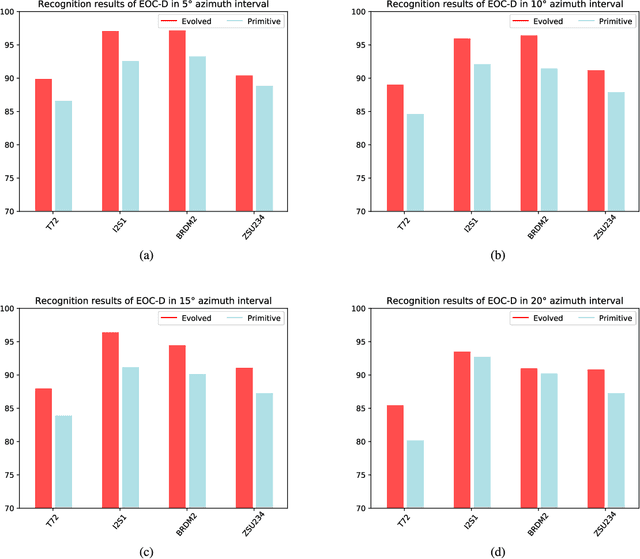
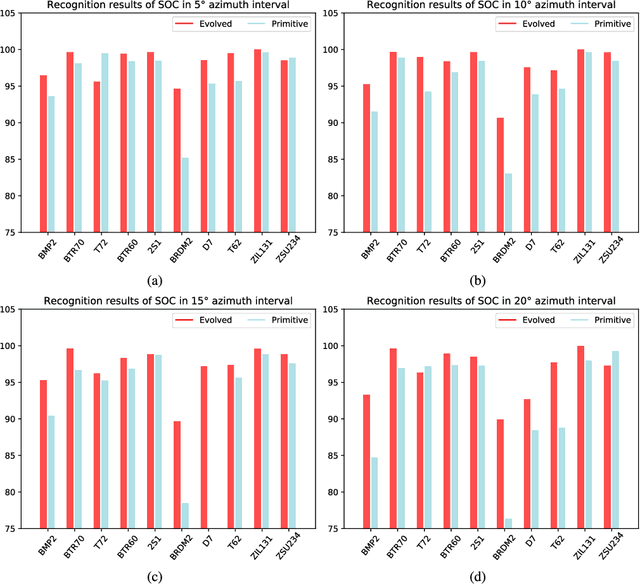
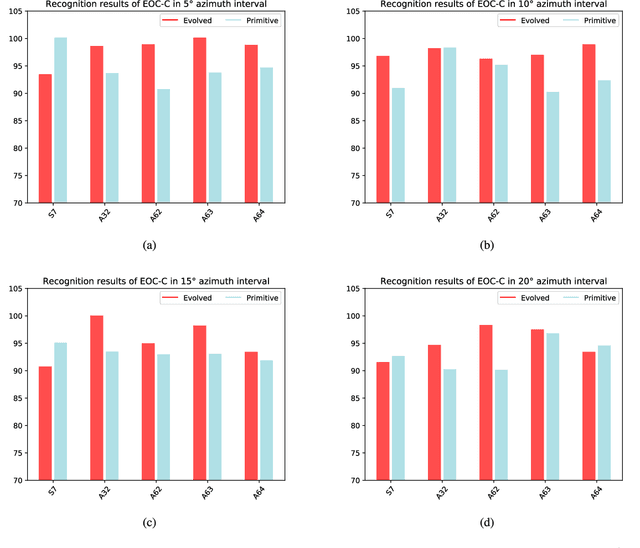
Sufficient synthetic aperture radar (SAR) target images are very important for the development of researches. However, available SAR target images are often limited in practice, which hinders the progress of SAR application. In this paper, we propose an azimuth-controllable generative adversarial network to generate precise SAR target images with an intermediate azimuth between two given SAR images' azimuths. This network mainly contains three parts: generator, discriminator, and predictor. Through the proposed specific network structure, the generator can extract and fuse the optimal target features from two input SAR target images to generate SAR target image. Then a similarity discriminator and an azimuth predictor are designed. The similarity discriminator can differentiate the generated SAR target images from the real SAR images to ensure the accuracy of the generated, while the azimuth predictor measures the difference of azimuth between the generated and the desired to ensure the azimuth controllability of the generated. Therefore, the proposed network can generate precise SAR images, and their azimuths can be controlled well by the inputs of the deep network, which can generate the target images in different azimuths to solve the small sample problem to some degree and benefit the researches of SAR images. Extensive experimental results show the superiority of the proposed method in azimuth controllability and accuracy of SAR target image generation.
Bi-Level Image-Guided Ergodic Exploration with Applications to Planetary Rovers
Jul 31, 2023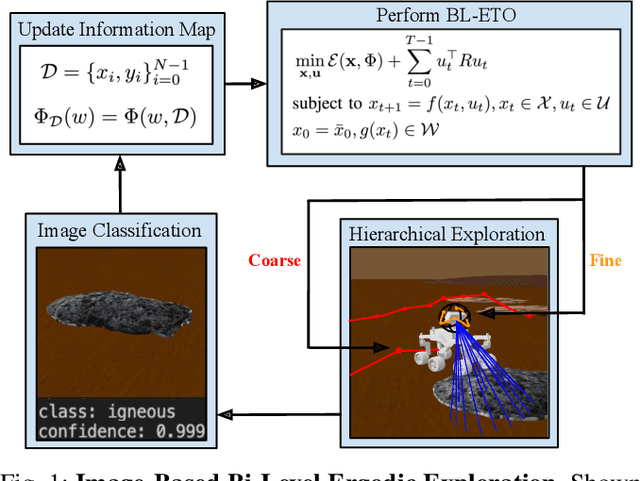
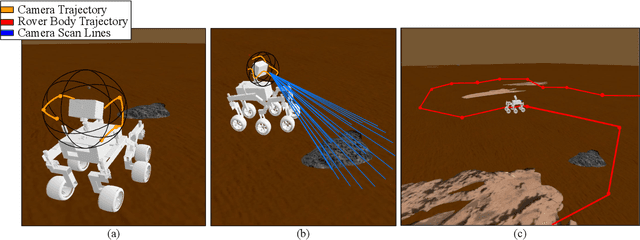

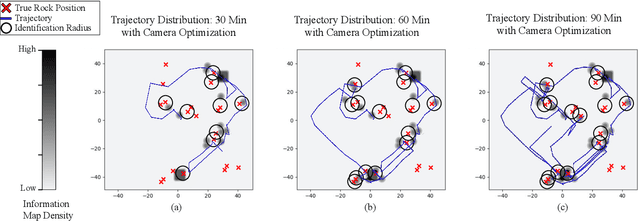
We present a method for image-guided exploration for mobile robotic systems. Our approach extends ergodic exploration methods, a recent exploration approach that prioritizes complete coverage of a space, with the use of a learned image classifier that automatically detects objects and updates an information map to guide further exploration and localization of objects. Additionally, to improve outcomes of the information collected by our robot's visual sensor, we present a decomposition of the ergodic optimization problem as bi-level coarse and fine solvers, which act respectively on the robot's body and the robot's visual sensor. Our approach is applied to geological survey and localization of rock formations for Mars rovers, with real images from Mars rovers used to train the image classifier. Results demonstrate 1) improved localization of rock formations compared to naive approaches while 2) minimizing the path length of the exploration through the bi-level exploration.
Open Compound Domain Adaptation with Object Style Compensation for Semantic Segmentation
Sep 28, 2023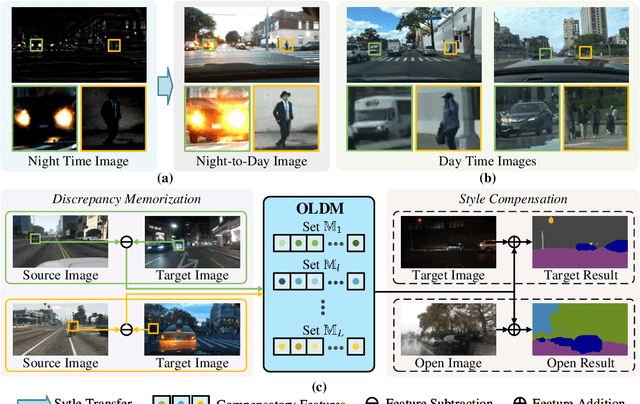
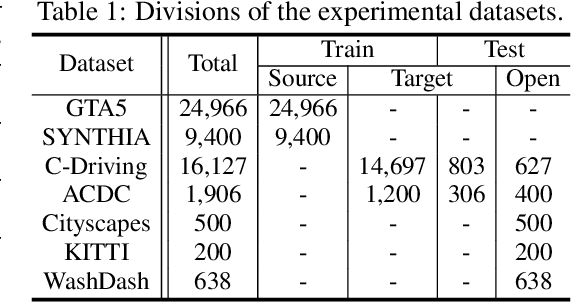
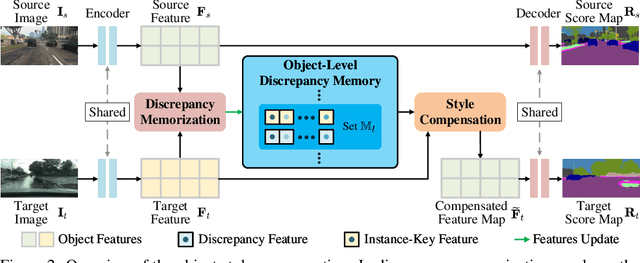
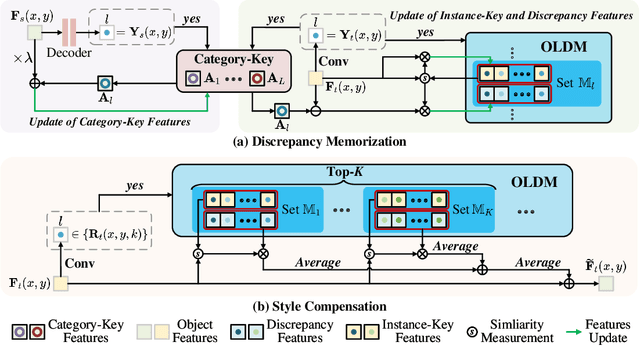
Many methods of semantic image segmentation have borrowed the success of open compound domain adaptation. They minimize the style gap between the images of source and target domains, more easily predicting the accurate pseudo annotations for target domain's images that train segmentation network. The existing methods globally adapt the scene style of the images, whereas the object styles of different categories or instances are adapted improperly. This paper proposes the Object Style Compensation, where we construct the Object-Level Discrepancy Memory with multiple sets of discrepancy features. The discrepancy features in a set capture the style changes of the same category's object instances adapted from target to source domains. We learn the discrepancy features from the images of source and target domains, storing the discrepancy features in memory. With this memory, we select appropriate discrepancy features for compensating the style information of the object instances of various categories, adapting the object styles to a unified style of source domain. Our method enables a more accurate computation of the pseudo annotations for target domain's images, thus yielding state-of-the-art results on different datasets.
Detecting Unknown Attacks in IoT Environments: An Open Set Classifier for Enhanced Network Intrusion Detection
Sep 28, 2023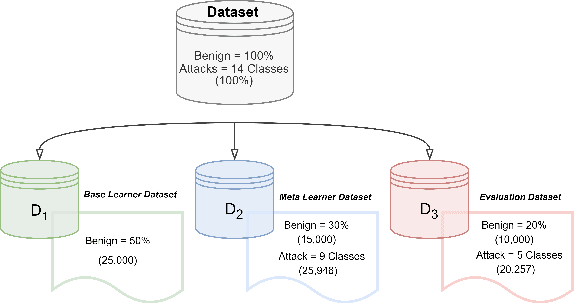
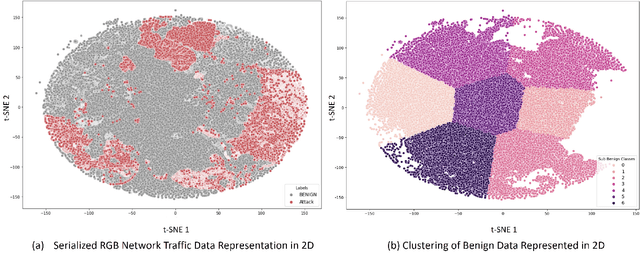
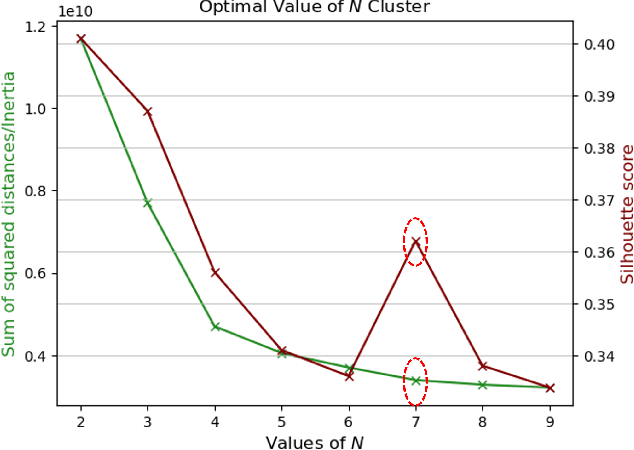
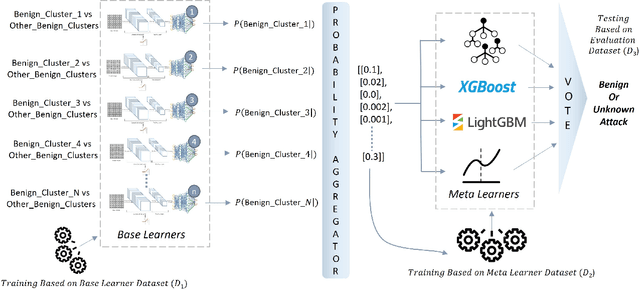
The widespread integration of Internet of Things (IoT) devices across all facets of life has ushered in an era of interconnectedness, creating new avenues for cybersecurity challenges and underscoring the need for robust intrusion detection systems. However, traditional security systems are designed with a closed-world perspective and often face challenges in dealing with the ever-evolving threat landscape, where new and unfamiliar attacks are constantly emerging. In this paper, we introduce a framework aimed at mitigating the open set recognition (OSR) problem in the realm of Network Intrusion Detection Systems (NIDS) tailored for IoT environments. Our framework capitalizes on image-based representations of packet-level data, extracting spatial and temporal patterns from network traffic. Additionally, we integrate stacking and sub-clustering techniques, enabling the identification of unknown attacks by effectively modeling the complex and diverse nature of benign behavior. The empirical results prominently underscore the framework's efficacy, boasting an impressive 88\% detection rate for previously unseen attacks when compared against existing approaches and recent advancements. Future work will perform extensive experimentation across various openness levels and attack scenarios, further strengthening the adaptability and performance of our proposed solution in safeguarding IoT environments.
LEyes: A Lightweight Framework for Deep Learning-Based Eye Tracking using Synthetic Eye Images
Sep 28, 2023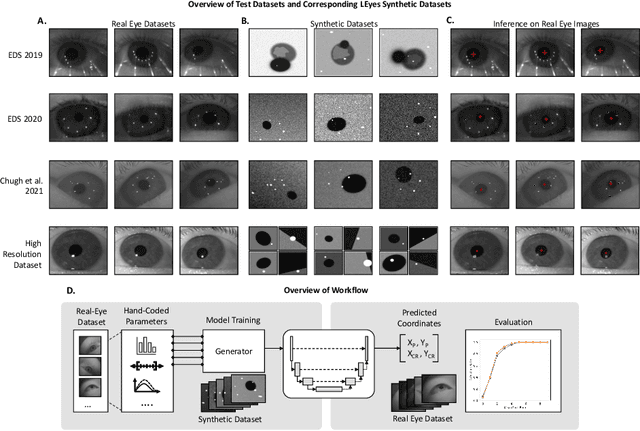
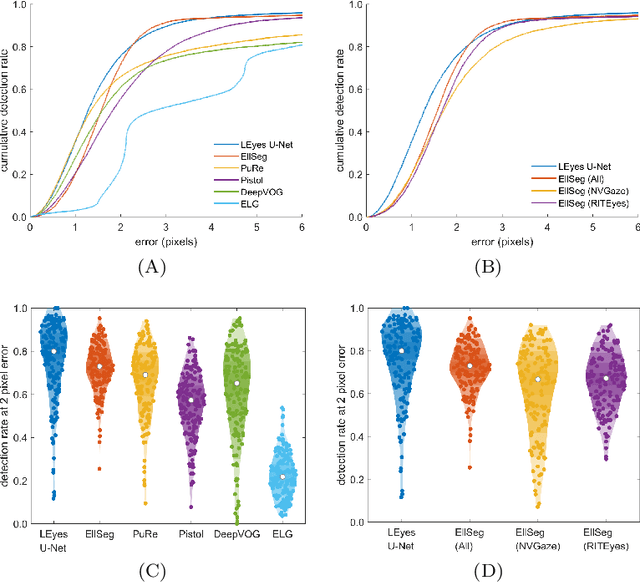
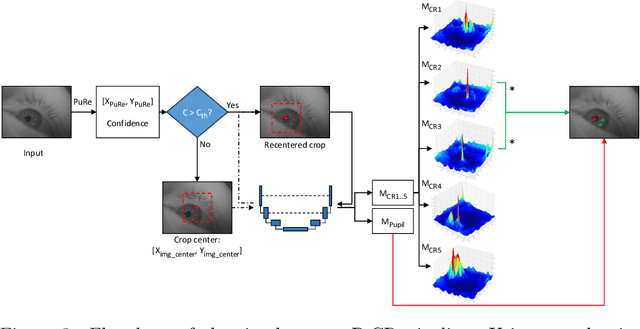
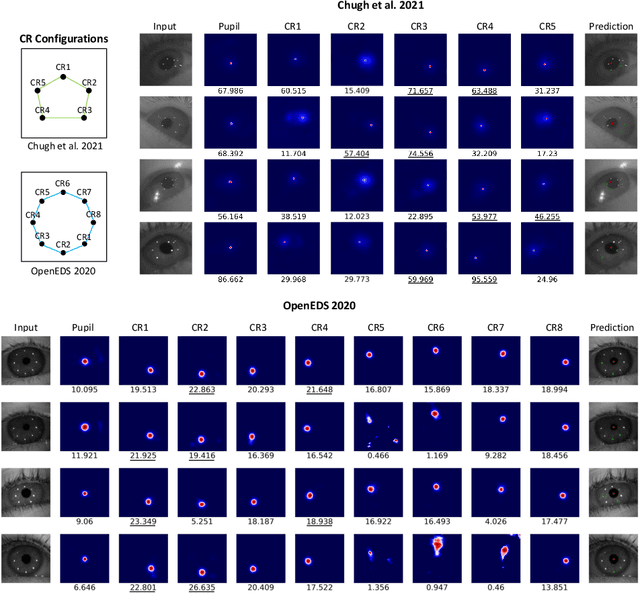
Deep learning has bolstered gaze estimation techniques, but real-world deployment has been impeded by inadequate training datasets. This problem is exacerbated by both hardware-induced variations in eye images and inherent biological differences across the recorded participants, leading to both feature and pixel-level variance that hinders the generalizability of models trained on specific datasets. While synthetic datasets can be a solution, their creation is both time and resource-intensive. To address this problem, we present a framework called Light Eyes or "LEyes" which, unlike conventional photorealistic methods, only models key image features required for video-based eye tracking using simple light distributions. LEyes facilitates easy configuration for training neural networks across diverse gaze-estimation tasks. We demonstrate that models trained using LEyes are consistently on-par or outperform other state-of-the-art algorithms in terms of pupil and CR localization across well-known datasets. In addition, a LEyes trained model outperforms the industry standard eye tracker using significantly more cost-effective hardware. Going forward, we are confident that LEyes will revolutionize synthetic data generation for gaze estimation models, and lead to significant improvements of the next generation video-based eye trackers.
Self-supervised Cross-view Representation Reconstruction for Change Captioning
Sep 28, 2023Change captioning aims to describe the difference between a pair of similar images. Its key challenge is how to learn a stable difference representation under pseudo changes caused by viewpoint change. In this paper, we address this by proposing a self-supervised cross-view representation reconstruction (SCORER) network. Concretely, we first design a multi-head token-wise matching to model relationships between cross-view features from similar/dissimilar images. Then, by maximizing cross-view contrastive alignment of two similar images, SCORER learns two view-invariant image representations in a self-supervised way. Based on these, we reconstruct the representations of unchanged objects by cross-attention, thus learning a stable difference representation for caption generation. Further, we devise a cross-modal backward reasoning to improve the quality of caption. This module reversely models a ``hallucination'' representation with the caption and ``before'' representation. By pushing it closer to the ``after'' representation, we enforce the caption to be informative about the difference in a self-supervised manner. Extensive experiments show our method achieves the state-of-the-art results on four datasets. The code is available at https://github.com/tuyunbin/SCORER.
STIR: Surgical Tattoos in Infrared
Sep 28, 2023Quantifying performance of methods for tracking and mapping tissue in endoscopic environments is essential for enabling image guidance and automation of medical interventions and surgery. Datasets developed so far either use rigid environments, visible markers, or require annotators to label salient points in videos after collection. These are respectively: not general, visible to algorithms, or costly and error-prone. We introduce a novel labeling methodology along with a dataset that uses said methodology, Surgical Tattoos in Infrared (STIR). STIR has labels that are persistent but invisible to visible spectrum algorithms. This is done by labelling tissue points with IR-flourescent dye, indocyanine green (ICG), and then collecting visible light video clips. STIR comprises hundreds of stereo video clips in both in-vivo and ex-vivo scenes with start and end points labelled in the IR spectrum. With over 3,000 labelled points, STIR will help to quantify and enable better analysis of tracking and mapping methods. After introducing STIR, we analyze multiple different frame-based tracking methods on STIR using both 3D and 2D endpoint error and accuracy metrics. STIR is available at https://dx.doi.org/10.21227/w8g4-g548
Distance-Aware eXplanation Based Learning
Sep 11, 2023eXplanation Based Learning (XBL) is an interactive learning approach that provides a transparent method of training deep learning models by interacting with their explanations. XBL augments loss functions to penalize a model based on deviation of its explanations from user annotation of image features. The literature on XBL mostly depends on the intersection of visual model explanations and image feature annotations. We present a method to add a distance-aware explanation loss to categorical losses that trains a learner to focus on important regions of a training dataset. Distance is an appropriate approach for calculating explanation loss since visual model explanations such as Gradient-weighted Class Activation Mapping (Grad-CAMs) are not strictly bounded as annotations and their intersections may not provide complete information on the deviation of a model's focus from relevant image regions. In addition to assessing our model using existing metrics, we propose an interpretability metric for evaluating visual feature-attribution based model explanations that is more informative of the model's performance than existing metrics. We demonstrate performance of our proposed method on three image classification tasks.
Improving Misaligned Multi-modality Image Fusion with One-stage Progressive Dense Registration
Aug 22, 2023


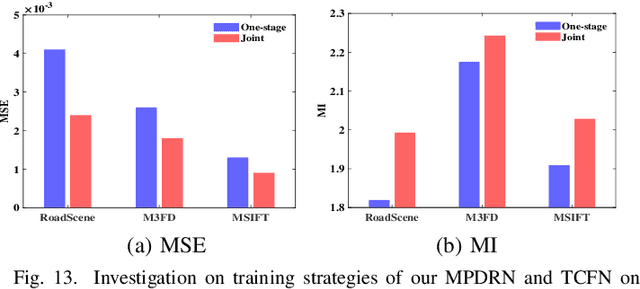
Misalignments between multi-modality images pose challenges in image fusion, manifesting as structural distortions and edge ghosts. Existing efforts commonly resort to registering first and fusing later, typically employing two cascaded stages for registration,i.e., coarse registration and fine registration. Both stages directly estimate the respective target deformation fields. In this paper, we argue that the separated two-stage registration is not compact, and the direct estimation of the target deformation fields is not accurate enough. To address these challenges, we propose a Cross-modality Multi-scale Progressive Dense Registration (C-MPDR) scheme, which accomplishes the coarse-to-fine registration exclusively using a one-stage optimization, thus improving the fusion performance of misaligned multi-modality images. Specifically, two pivotal components are involved, a dense Deformation Field Fusion (DFF) module and a Progressive Feature Fine (PFF) module. The DFF aggregates the predicted multi-scale deformation sub-fields at the current scale, while the PFF progressively refines the remaining misaligned features. Both work together to accurately estimate the final deformation fields. In addition, we develop a Transformer-Conv-based Fusion (TCF) subnetwork that considers local and long-range feature dependencies, allowing us to capture more informative features from the registered infrared and visible images for the generation of high-quality fused images. Extensive experimental analysis demonstrates the superiority of the proposed method in the fusion of misaligned cross-modality images.