 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MoreStyle: Relax Low-frequency Constraint of Fourier-based Image Reconstruction in Generalizable Medical Image Segmentation
Mar 19, 2024
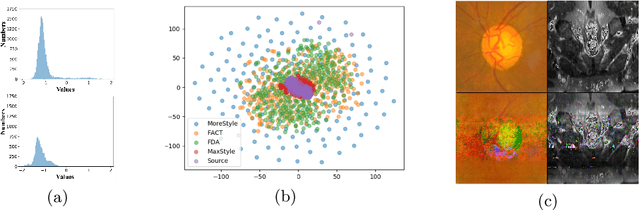
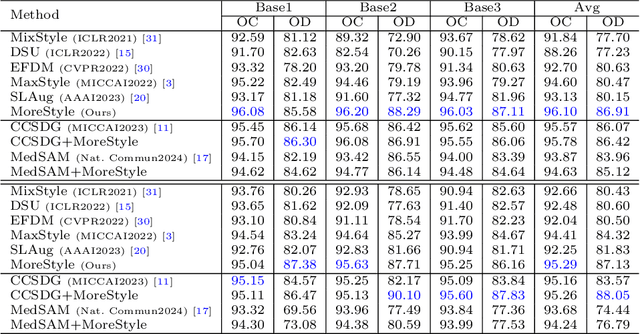
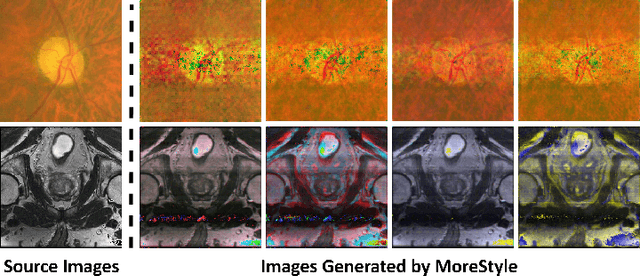
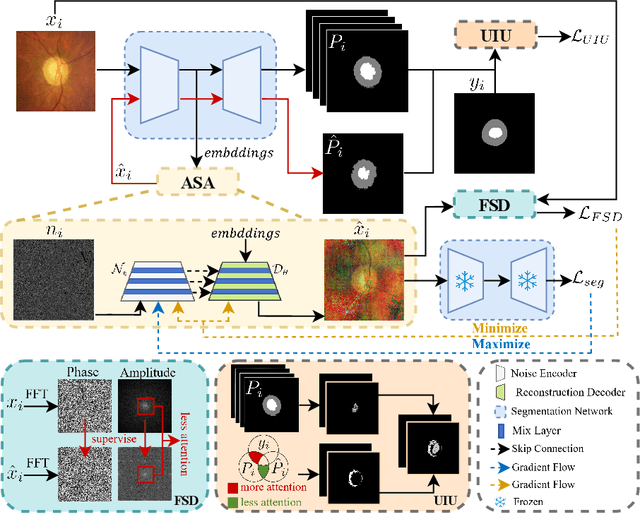
The task of single-source domain generalization (SDG) in medical image segmentation is crucial due to frequent domain shifts in clinical image datasets. To address the challenge of poor generalization across different domains, we introduce a Plug-and-Play module for data augmentation called MoreStyle. MoreStyle diversifies image styles by relaxing low-frequency constraints in Fourier space, guiding the image reconstruction network. With the help of adversarial learning, MoreStyle further expands the style range and pinpoints the most intricate style combinations within latent features. To handle significant style variations, we introduce an uncertainty-weighted loss. This loss emphasizes hard-to-classify pixels resulting only from style shifts while mitigating true hard-to-classify pixels in both MoreStyle-generated and original images. Extensive experiments on two widely used benchmarks demonstrate that the proposed MoreStyle effectively helps to achieve good domain generalization ability, and has the potential to further boost the performance of some state-of-the-art SDG methods.
ViTamin: Designing Scalable Vision Models in the Vision-Language Era
Apr 03, 2024Recent breakthroughs in vision-language models (VLMs) start a new page in the vision community. The VLMs provide stronger and more generalizable feature embeddings compared to those from ImageNet-pretrained models, thanks to the training on the large-scale Internet image-text pairs. However, despite the amazing achievement from the VLMs, vanilla Vision Transformers (ViTs) remain the default choice for the image encoder. Although pure transformer proves its effectiveness in the text encoding area, it remains questionable whether it is also the case for image encoding, especially considering that various types of networks are proposed on the ImageNet benchmark, which, unfortunately, are rarely studied in VLMs. Due to small data/model scale, the original conclusions of model design on ImageNet can be limited and biased. In this paper, we aim at building an evaluation protocol of vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework. We provide a comprehensive way to benchmark different vision models, covering their zero-shot performance and scalability in both model and training data sizes. To this end, we introduce ViTamin, a new vision models tailored for VLMs. ViTamin-L significantly outperforms ViT-L by 2.0% ImageNet zero-shot accuracy, when using the same publicly available DataComp-1B dataset and the same OpenCLIP training scheme. ViTamin-L presents promising results on 60 diverse benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal models. When further scaling up the model size, our ViTamin-XL with only 436M parameters attains 82.9% ImageNet zero-shot accuracy, surpassing 82.0% achieved by EVA-E that has ten times more parameters (4.4B).
Generalizable 3D Scene Reconstruction via Divide and Conquer from a Single View
Apr 04, 2024Single-view 3D reconstruction is currently approached from two dominant perspectives: reconstruction of scenes with limited diversity using 3D data supervision or reconstruction of diverse singular objects using large image priors. However, real-world scenarios are far more complex and exceed the capabilities of these methods. We therefore propose a hybrid method following a divide-and-conquer strategy. We first process the scene holistically, extracting depth and semantic information, and then leverage a single-shot object-level method for the detailed reconstruction of individual components. By following a compositional processing approach, the overall framework achieves full reconstruction of complex 3D scenes from a single image. We purposely design our pipeline to be highly modular by carefully integrating specific procedures for each processing step, without requiring an end-to-end training of the whole system. This enables the pipeline to naturally improve as future methods can replace the individual modules. We demonstrate the reconstruction performance of our approach on both synthetic and real-world scenes, comparing favorable against prior works. Project page: https://andreeadogaru.github.io/Gen3DSR.
Cognitive resilience: Unraveling the proficiency of image-captioning models to interpret masked visual content
Mar 23, 2024This study explores the ability of Image Captioning (IC) models to decode masked visual content sourced from diverse datasets. Our findings reveal the IC model's capability to generate captions from masked images, closely resembling the original content. Notably, even in the presence of masks, the model adeptly crafts descriptive textual information that goes beyond what is observable in the original image-generated captions. While the decoding performance of the IC model experiences a decline with an increase in the masked region's area, the model still performs well when important regions of the image are not masked at high coverage.
Clustering Propagation for Universal Medical Image Segmentation
Mar 25, 2024Prominent solutions for medical image segmentation are typically tailored for automatic or interactive setups, posing challenges in facilitating progress achieved in one task to another.$_{\!}$ This$_{\!}$ also$_{\!}$ necessitates$_{\!}$ separate$_{\!}$ models for each task, duplicating both training time and parameters.$_{\!}$ To$_{\!}$ address$_{\!}$ above$_{\!}$ issues,$_{\!}$ we$_{\!}$ introduce$_{\!}$ S2VNet,$_{\!}$ a$_{\!}$ universal$_{\!}$ framework$_{\!}$ that$_{\!}$ leverages$_{\!}$ Slice-to-Volume$_{\!}$ propagation$_{\!}$ to$_{\!}$ unify automatic/interactive segmentation within a single model and one training session. Inspired by clustering-based segmentation techniques, S2VNet makes full use of the slice-wise structure of volumetric data by initializing cluster centers from the cluster$_{\!}$ results$_{\!}$ of$_{\!}$ previous$_{\!}$ slice.$_{\!}$ This enables knowledge acquired from prior slices to assist in the segmentation of the current slice, further efficiently bridging the communication between remote slices using mere 2D networks. Moreover, such a framework readily accommodates interactive segmentation with no architectural change, simply by initializing centroids from user inputs. S2VNet distinguishes itself by swift inference speeds and reduced memory consumption compared to prevailing 3D solutions. It can also handle multi-class interactions with each of them serving to initialize different centroids. Experiments on three benchmarks demonstrate S2VNet surpasses task-specified solutions on both automatic/interactive setups.
Grounding and Enhancing Grid-based Models for Neural Fields
Apr 06, 2024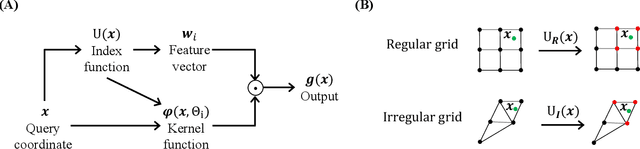
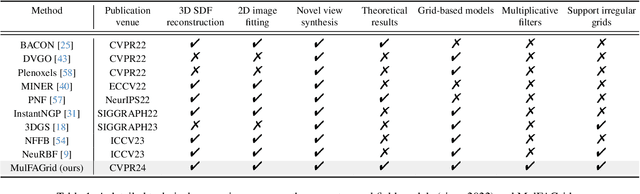
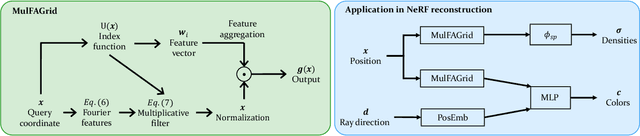
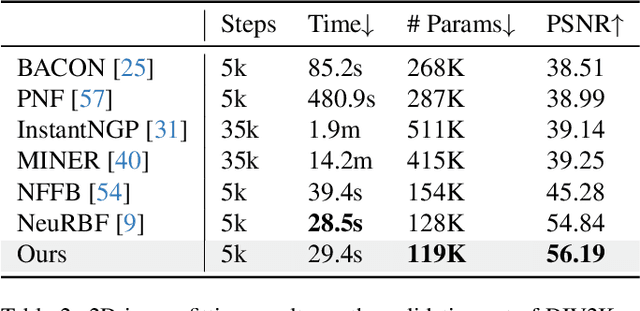
Many contemporary studies utilize grid-based models for neural field representation, but a systematic analysis of grid-based models is still missing, hindering the improvement of those models. Therefore, this paper introduces a theoretical framework for grid-based models. This framework points out that these models' approximation and generalization behaviors are determined by grid tangent kernels (GTK), which are intrinsic properties of grid-based models. The proposed framework facilitates a consistent and systematic analysis of diverse grid-based models. Furthermore, the introduced framework motivates the development of a novel grid-based model named the Multiplicative Fourier Adaptive Grid (MulFAGrid). The numerical analysis demonstrates that MulFAGrid exhibits a lower generalization bound than its predecessors, indicating its robust generalization performance. Empirical studies reveal that MulFAGrid achieves state-of-the-art performance in various tasks, including 2D image fitting, 3D signed distance field (SDF) reconstruction, and novel view synthesis, demonstrating superior representation ability. The project website is available at https://sites.google.com/view/cvpr24-2034-submission/home.
Real, fake and synthetic faces -- does the coin have three sides?
Apr 02, 2024With the ever-growing power of generative artificial intelligence, deepfake and artificially generated (synthetic) media have continued to spread online, which creates various ethical and moral concerns regarding their usage. To tackle this, we thus present a novel exploration of the trends and patterns observed in real, deepfake and synthetic facial images. The proposed analysis is done in two parts: firstly, we incorporate eight deep learning models and analyze their performances in distinguishing between the three classes of images. Next, we look to further delve into the similarities and differences between these three sets of images by investigating their image properties both in the context of the entire image as well as in the context of specific regions within the image. ANOVA test was also performed and provided further clarity amongst the patterns associated between the images of the three classes. From our findings, we observe that the investigated deeplearning models found it easier to detect synthetic facial images, with the ViT Patch-16 model performing best on this task with a class-averaged sensitivity, specificity, precision, and accuracy of 97.37%, 98.69%, 97.48%, and 98.25%, respectively. This observation was supported by further analysis of various image properties. We saw noticeable differences across the three category of images. This analysis can help us build better algorithms for facial image generation, and also shows that synthetic, deepfake and real face images are indeed three different classes.
FGAIF: Aligning Large Vision-Language Models with Fine-grained AI Feedback
Apr 07, 2024Large Vision-Language Models (LVLMs) have demonstrated proficiency in tackling a variety of visual-language tasks. However, current LVLMs suffer from misalignment between text and image modalities which causes three kinds of hallucination problems, i.e., object existence, object attribute, and object relationship. To tackle this issue, existing methods mainly utilize Reinforcement Learning (RL) to align modalities in LVLMs. However, they still suffer from three main limitations: (1) General feedback can not indicate the hallucination type contained in the response; (2) Sparse rewards only give the sequence-level reward for the whole response; and (3)Annotation cost is time-consuming and labor-intensive. To handle these limitations, we propose an innovative method to align modalities in LVLMs through Fine-Grained Artificial Intelligence Feedback (FGAIF), which mainly consists of three steps: AI-based Feedback Collection, Fine-grained Reward Model Training, and Reinforcement Learning with Fine-grained Reward. Specifically, We first utilize AI tools to predict the types of hallucination for each segment in the response and obtain a collection of fine-grained feedback. Then, based on the collected reward data, three specialized reward models are trained to produce dense rewards. Finally, a novel fine-grained feedback module is integrated into the Proximal Policy Optimization (PPO) algorithm. Extensive experiments are conducted on hallucination and general benchmarks, demonstrating the superior performance of our proposed method. Notably, compared with previous models trained with the RL-based aligning method, our proposed method is effective even with fewer parameters.
Advancing Geometric Problem Solving: A Comprehensive Benchmark for Multimodal Model Evaluation
Apr 07, 2024In this work, we present the MM-MATH dataset, a novel benchmark developed to rigorously evaluate the performance of advanced large language and multimodal models - including but not limited to GPT-4, GPT-4V, and Claude - within the domain of geometric computation. This dataset comprises 5,929 meticulously crafted geometric problems, each paired with a corresponding image, aimed at mirroring the complexity and requirements typical of ninth-grade mathematics. The motivation behind MM-MATH stems from the burgeoning interest and significant strides in multimodal technology, which necessitates a paradigm shift in assessment methodologies from mere outcome analysis to a more holistic evaluation encompassing reasoning and procedural correctness. Despite impressive gains in various benchmark performances, our analysis uncovers a persistent and notable deficiency in these models' ability to parse and interpret geometric information accurately from images, accounting for over 60% of observed errors. By deploying a dual-focused evaluation approach, examining both the end results and the underlying problem-solving processes, we unearthed a marked discrepancy between the capabilities of current multimodal models and human-level proficiency. The introduction of MM-MATH represents a tripartite contribution to the field: it not only serves as a comprehensive and challenging benchmark for assessing geometric problem-solving prowess but also illuminates critical gaps in textual and visual comprehension that current models exhibit. Through this endeavor, we aspire to catalyze further research and development aimed at bridging these gaps, thereby advancing the state of multimodal model capabilities to new heights.
CAPE: CAM as a Probabilistic Ensemble for Enhanced DNN Interpretation
Apr 04, 2024Deep Neural Networks (DNNs) are widely used for visual classification tasks, but their complex computation process and black-box nature hinder decision transparency and interpretability. Class activation maps (CAMs) and recent variants provide ways to visually explain the DNN decision-making process by displaying 'attention' heatmaps of the DNNs. Nevertheless, the CAM explanation only offers relative attention information, that is, on an attention heatmap, we can interpret which image region is more or less important than the others. However, these regions cannot be meaningfully compared across classes, and the contribution of each region to the model's class prediction is not revealed. To address these challenges that ultimately lead to better DNN Interpretation, in this paper, we propose CAPE, a novel reformulation of CAM that provides a unified and probabilistically meaningful assessment of the contributions of image regions. We quantitatively and qualitatively compare CAPE with state-of-the-art CAM methods on CUB and ImageNet benchmark datasets to demonstrate enhanced interpretability. We also test on a cytology imaging dataset depicting a challenging Chronic Myelomonocytic Leukemia (CMML) diagnosis problem. Code is available at: https://github.com/AIML-MED/CAPE.