 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Single Models vs. Ensembles: Insights for a Fast Deployment of Parking Monitoring Systems
Sep 28, 2023
Searching for available parking spots in high-density urban centers is a stressful task for drivers that can be mitigated by systems that know in advance the nearest parking space available. To this end, image-based systems offer cost advantages over other sensor-based alternatives (e.g., ultrasonic sensors), requiring less physical infrastructure for installation and maintenance. Despite recent deep learning advances, deploying intelligent parking monitoring is still a challenge since most approaches involve collecting and labeling large amounts of data, which is laborious and time-consuming. Our study aims to uncover the challenges in creating a global framework, trained using publicly available labeled parking lot images, that performs accurately across diverse scenarios, enabling the parking space monitoring as a ready-to-use system to deploy in a new environment. Through exhaustive experiments involving different datasets and deep learning architectures, including fusion strategies and ensemble methods, we found that models trained on diverse datasets can achieve 95\% accuracy without the burden of data annotation and model training on the target parking lot
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Sep 28, 2023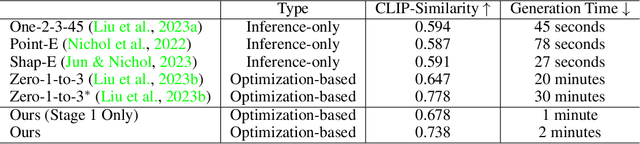
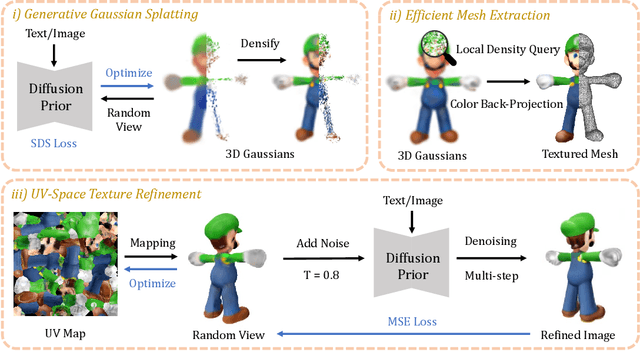


Recent advances in 3D content creation mostly leverage optimization-based 3D generation via score distillation sampling (SDS). Though promising results have been exhibited, these methods often suffer from slow per-sample optimization, limiting their practical usage. In this paper, we propose DreamGaussian, a novel 3D content generation framework that achieves both efficiency and quality simultaneously. Our key insight is to design a generative 3D Gaussian Splatting model with companioned mesh extraction and texture refinement in UV space. In contrast to the occupancy pruning used in Neural Radiance Fields, we demonstrate that the progressive densification of 3D Gaussians converges significantly faster for 3D generative tasks. To further enhance the texture quality and facilitate downstream applications, we introduce an efficient algorithm to convert 3D Gaussians into textured meshes and apply a fine-tuning stage to refine the details. Extensive experiments demonstrate the superior efficiency and competitive generation quality of our proposed approach. Notably, DreamGaussian produces high-quality textured meshes in just 2 minutes from a single-view image, achieving approximately 10 times acceleration compared to existing methods.
On the Contractivity of Plug-and-Play Operators
Sep 28, 2023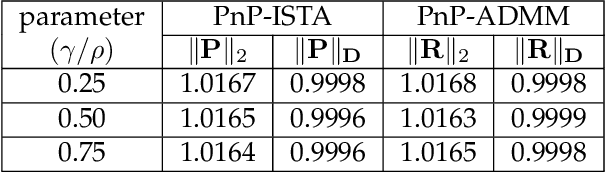

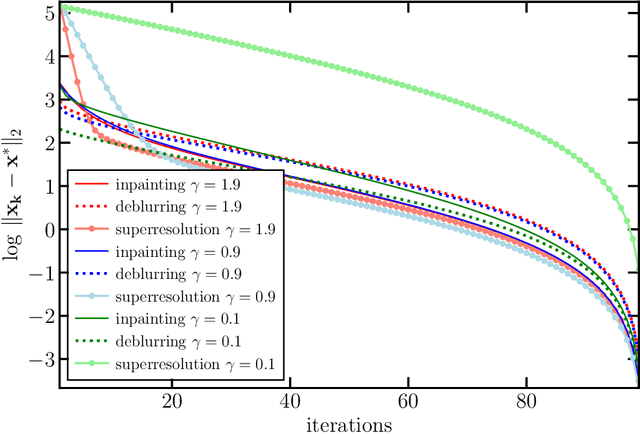

In plug-and-play (PnP) regularization, the proximal operator in algorithms such as ISTA and ADMM is replaced by a powerful denoiser. This formal substitution works surprisingly well in practice. In fact, PnP has been shown to give state-of-the-art results for various imaging applications. The empirical success of PnP has motivated researchers to understand its theoretical underpinnings and, in particular, its convergence. It was shown in prior work that for kernel denoisers such as the nonlocal means, PnP-ISTA provably converges under some strong assumptions on the forward model. The present work is motivated by the following questions: Can we relax the assumptions on the forward model? Can the convergence analysis be extended to PnP-ADMM? Can we estimate the convergence rate? In this letter, we resolve these questions using the contraction mapping theorem: (i) for symmetric denoisers, we show that (under mild conditions) PnP-ISTA and PnP-ADMM exhibit linear convergence; and (ii) for kernel denoisers, we show that PnP-ISTA and PnP-ADMM converge linearly for image inpainting. We validate our theoretical findings using reconstruction experiments.
Soft-IntroVAE for Continuous Latent space Image Super-Resolution
Jul 18, 2023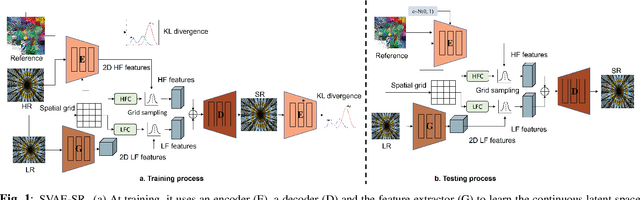
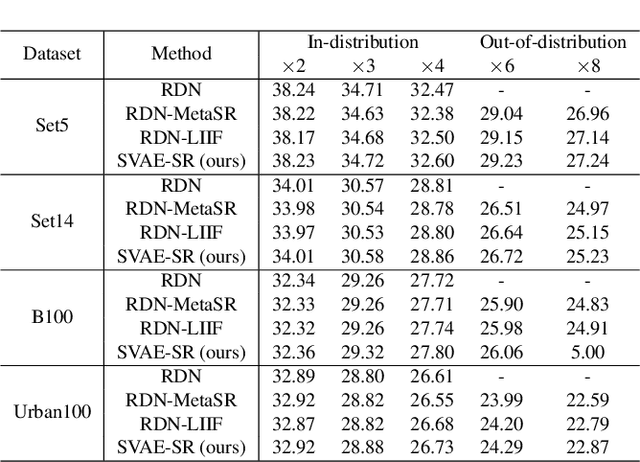
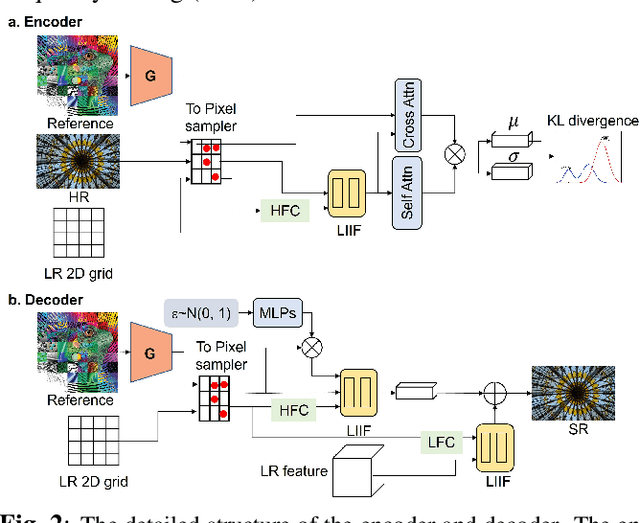
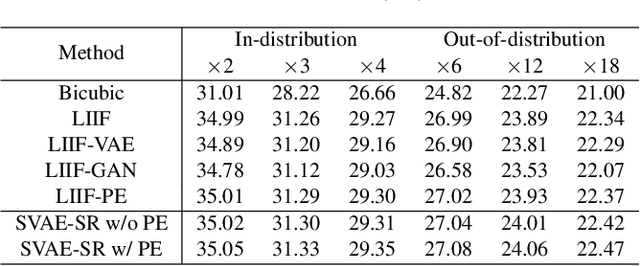
Continuous image super-resolution (SR) recently receives a lot of attention from researchers, for its practical and flexible image scaling for various displays. Local implicit image representation is one of the methods that can map the coordinates and 2D features for latent space interpolation. Inspired by Variational AutoEncoder, we propose a Soft-introVAE for continuous latent space image super-resolution (SVAE-SR). A novel latent space adversarial training is achieved for photo-realistic image restoration. To further improve the quality, a positional encoding scheme is used to extend the original pixel coordinates by aggregating frequency information over the pixel areas. We show the effectiveness of the proposed SVAE-SR through quantitative and qualitative comparisons, and further, illustrate its generalization in denoising and real-image super-resolution.
* 5 pages, 4 figures
AutoDiffusion: Training-Free Optimization of Time Steps and Architectures for Automated Diffusion Model Acceleration
Sep 23, 2023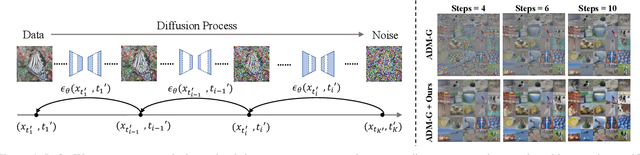

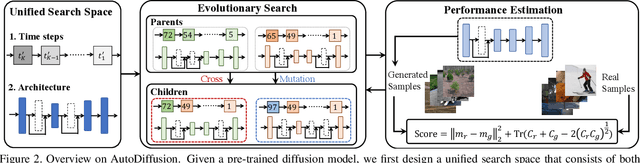
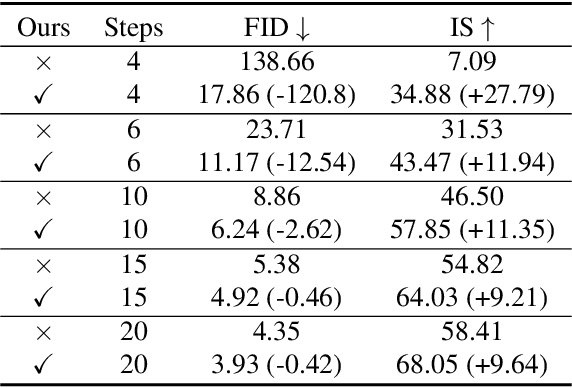
Diffusion models are emerging expressive generative models, in which a large number of time steps (inference steps) are required for a single image generation. To accelerate such tedious process, reducing steps uniformly is considered as an undisputed principle of diffusion models. We consider that such a uniform assumption is not the optimal solution in practice; i.e., we can find different optimal time steps for different models. Therefore, we propose to search the optimal time steps sequence and compressed model architecture in a unified framework to achieve effective image generation for diffusion models without any further training. Specifically, we first design a unified search space that consists of all possible time steps and various architectures. Then, a two stage evolutionary algorithm is introduced to find the optimal solution in the designed search space. To further accelerate the search process, we employ FID score between generated and real samples to estimate the performance of the sampled examples. As a result, the proposed method is (i).training-free, obtaining the optimal time steps and model architecture without any training process; (ii). orthogonal to most advanced diffusion samplers and can be integrated to gain better sample quality. (iii). generalized, where the searched time steps and architectures can be directly applied on different diffusion models with the same guidance scale. Experimental results show that our method achieves excellent performance by using only a few time steps, e.g. 17.86 FID score on ImageNet 64 $\times$ 64 with only four steps, compared to 138.66 with DDIM. The code is available at https://github.com/lilijiangg/AutoDiffusion.
Rethinking Amodal Video Segmentation from Learning Supervised Signals with Object-centric Representation
Sep 23, 2023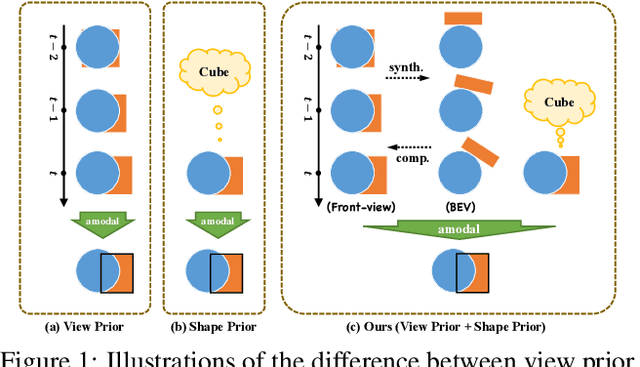
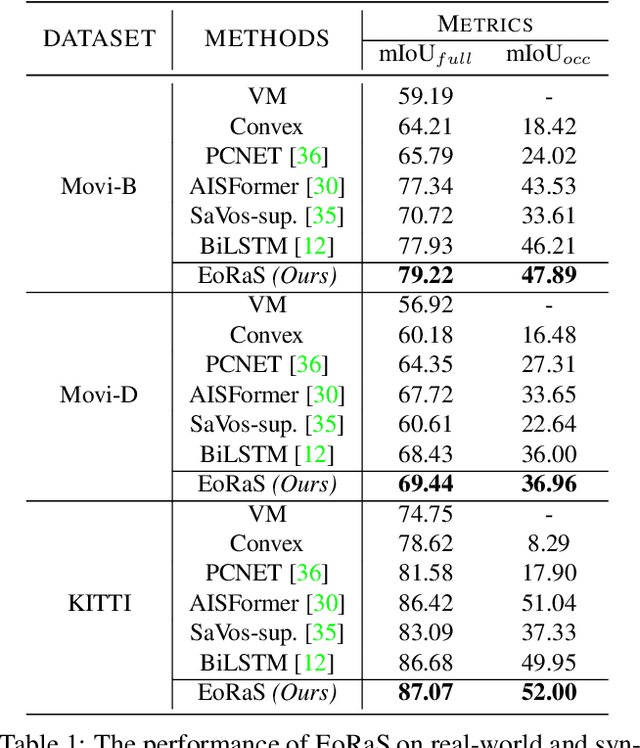
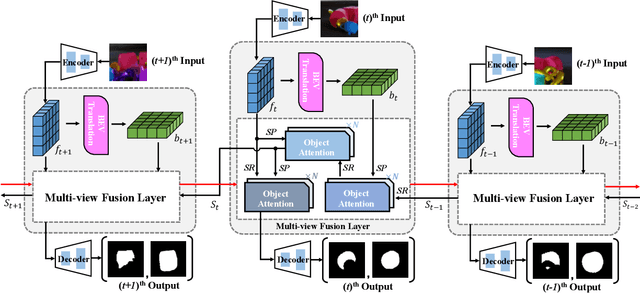

Video amodal segmentation is a particularly challenging task in computer vision, which requires to deduce the full shape of an object from the visible parts of it. Recently, some studies have achieved promising performance by using motion flow to integrate information across frames under a self-supervised setting. However, motion flow has a clear limitation by the two factors of moving cameras and object deformation. This paper presents a rethinking to previous works. We particularly leverage the supervised signals with object-centric representation in \textit{real-world scenarios}. The underlying idea is the supervision signal of the specific object and the features from different views can mutually benefit the deduction of the full mask in any specific frame. We thus propose an Efficient object-centric Representation amodal Segmentation (EoRaS). Specially, beyond solely relying on supervision signals, we design a translation module to project image features into the Bird's-Eye View (BEV), which introduces 3D information to improve current feature quality. Furthermore, we propose a multi-view fusion layer based temporal module which is equipped with a set of object slots and interacts with features from different views by attention mechanism to fulfill sufficient object representation completion. As a result, the full mask of the object can be decoded from image features updated by object slots. Extensive experiments on both real-world and synthetic benchmarks demonstrate the superiority of our proposed method, achieving state-of-the-art performance. Our code will be released at \url{https://github.com/kfan21/EoRaS}.
Reformulating Vision-Language Foundation Models and Datasets Towards Universal Multimodal Assistants
Oct 01, 2023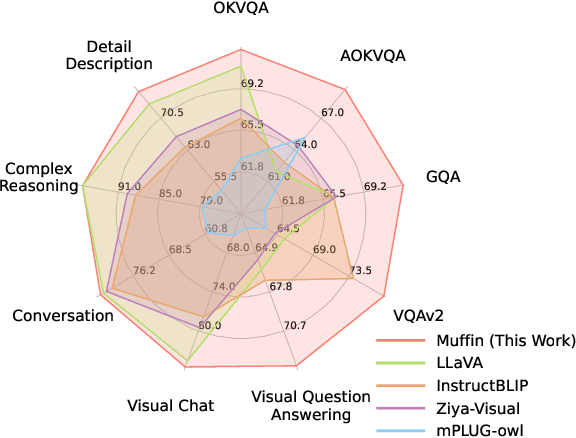
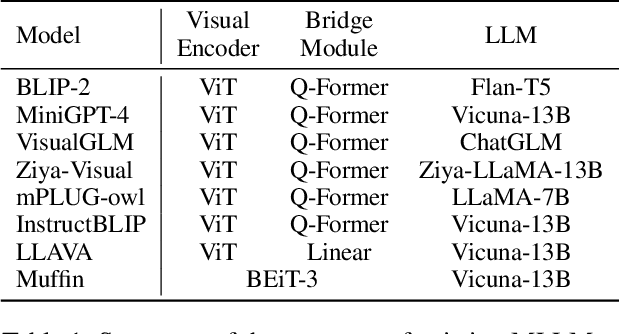
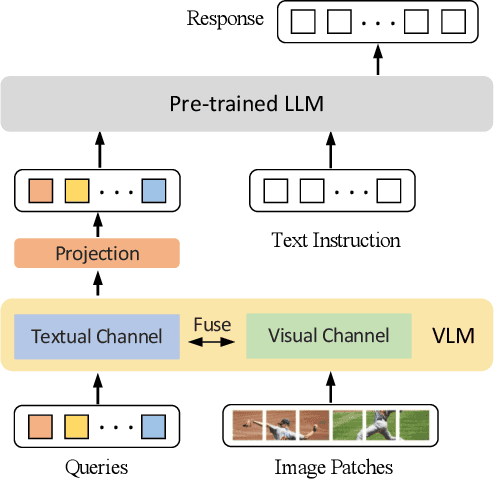
Recent Multimodal Large Language Models (MLLMs) exhibit impressive abilities to perceive images and follow open-ended instructions. The capabilities of MLLMs depend on two crucial factors: the model architecture to facilitate the feature alignment of visual modules and large language models; the multimodal instruction tuning datasets for human instruction following. (i) For the model architecture, most existing models introduce an external bridge module to connect vision encoders with language models, which needs an additional feature-alignment pre-training. In this work, we discover that compact pre-trained vision language models can inherently serve as ``out-of-the-box'' bridges between vision and language. Based on this, we propose Muffin framework, which directly employs pre-trained vision-language models to act as providers of visual signals. (ii) For the multimodal instruction tuning datasets, existing methods omit the complementary relationship between different datasets and simply mix datasets from different tasks. Instead, we propose UniMM-Chat dataset which explores the complementarities of datasets to generate 1.1M high-quality and diverse multimodal instructions. We merge information describing the same image from diverse datasets and transforms it into more knowledge-intensive conversation data. Experimental results demonstrate the effectiveness of the Muffin framework and UniMM-Chat dataset. Muffin achieves state-of-the-art performance on a wide range of vision-language tasks, significantly surpassing state-of-the-art models like LLaVA and InstructBLIP. Our model and dataset are all accessible at https://github.com/thunlp/muffin.
Blind Image Quality Assessment Using Multi-Stream Architecture with Spatial and Channel Attention
Jul 31, 2023
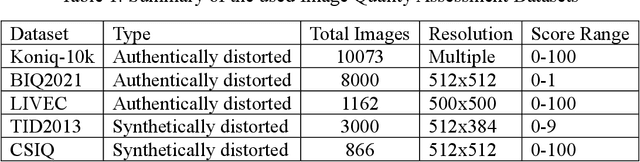
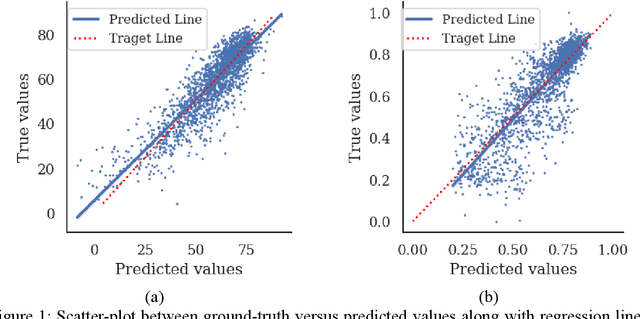
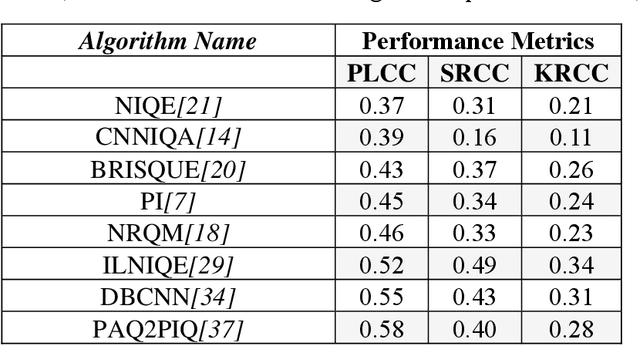
BIQA (Blind Image Quality Assessment) is an important field of study that evaluates images automatically. Although significant progress has been made, blind image quality assessment remains a difficult task since images vary in content and distortions. Most algorithms generate quality without emphasizing the important region of interest. In order to solve this, a multi-stream spatial and channel attention-based algorithm is being proposed. This algorithm generates more accurate predictions with a high correlation to human perceptual assessment by combining hybrid features from two different backbones, followed by spatial and channel attention to provide high weights to the region of interest. Four legacy image quality assessment datasets are used to validate the effectiveness of our proposed approach. Authentic and synthetic distortion image databases are used to demonstrate the effectiveness of the proposed method, and we show that it has excellent generalization properties with a particular focus on the perceptual foreground information.
Linear Progressive Coding for Semantic Communication using Deep Neural Networks
Sep 27, 2023We propose a general method for semantic representation of images and other data using progressive coding. Semantic coding allows for specific pieces of information to be selectively encoded into a set of measurements that can be highly compressed compared to the size of the original raw data. We consider a hierarchical method of coding where a partial amount of semantic information is first encoded a into a coarse representation of the data, which is then refined by additional encodings that add additional semantic information. Such hierarchical coding is especially well-suited for semantic communication i.e. transferring semantic information over noisy channels. Our proposed method can be considered as a generalization of both progressive image compression and source coding for semantic communication. We present results from experiments on the MNIST and CIFAR-10 datasets that show that progressive semantic coding can provide timely previews of semantic information with a small number of initial measurements while achieving overall accuracy and efficiency comparable to non-progressive methods.
Subjective Face Transform using Human First Impressions
Sep 27, 2023
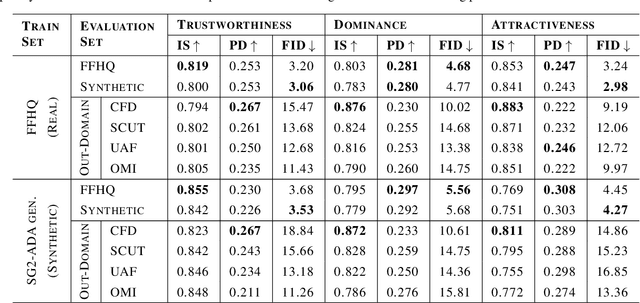
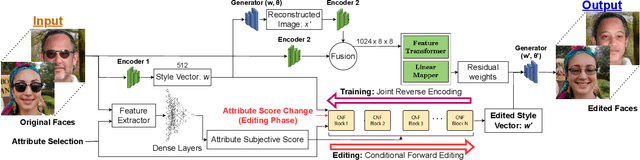
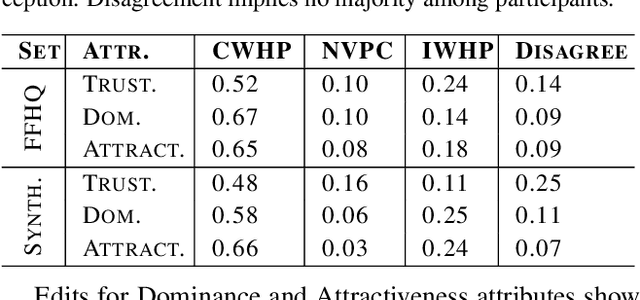
Humans tend to form quick subjective first impressions of non-physical attributes when seeing someone's face, such as perceived trustworthiness or attractiveness. To understand what variations in a face lead to different subjective impressions, this work uses generative models to find semantically meaningful edits to a face image that change perceived attributes. Unlike prior work that relied on statistical manipulation in feature space, our end-to-end framework considers trade-offs between preserving identity and changing perceptual attributes. It maps identity-preserving latent space directions to changes in attribute scores, enabling transformation of any input face along an attribute axis according to a target change. We train on real and synthetic faces, evaluate for in-domain and out-of-domain images using predictive models and human ratings, demonstrating the generalizability of our approach. Ultimately, such a framework can be used to understand and explain biases in subjective interpretation of faces that are not dependent on the identity.