 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Painterly Image Harmonization using Diffusion Model
Aug 04, 2023
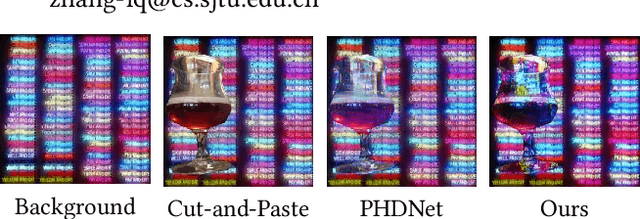

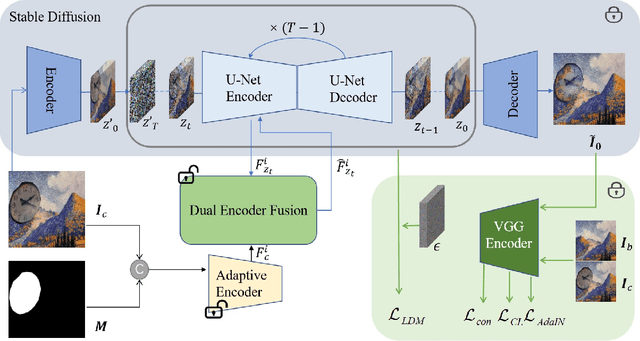
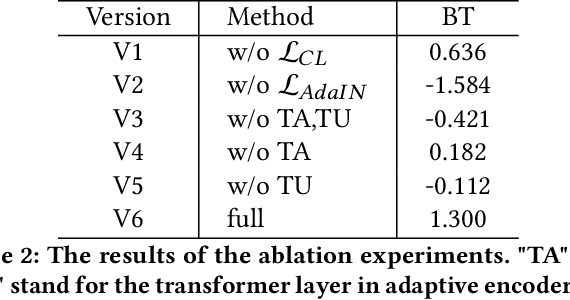
Painterly image harmonization aims to insert photographic objects into paintings and obtain artistically coherent composite images. Previous methods for this task mainly rely on inference optimization or generative adversarial network, but they are either very time-consuming or struggling at fine control of the foreground objects (e.g., texture and content details). To address these issues, we propose a novel Painterly Harmonization stable Diffusion model (PHDiffusion), which includes a lightweight adaptive encoder and a Dual Encoder Fusion (DEF) module. Specifically, the adaptive encoder and the DEF module first stylize foreground features within each encoder. Then, the stylized foreground features from both encoders are combined to guide the harmonization process. During training, besides the noise loss in diffusion model, we additionally employ content loss and two style losses, i.e., AdaIN style loss and contrastive style loss, aiming to balance the trade-off between style migration and content preservation. Compared with the state-of-the-art models from related fields, our PHDiffusion can stylize the foreground more sufficiently and simultaneously retain finer content. Our code and model are available at https://github.com/bcmi/PHDiffusion-Painterly-Image-Harmonization.
PAIF: Perception-Aware Infrared-Visible Image Fusion for Attack-Tolerant Semantic Segmentation
Aug 08, 2023
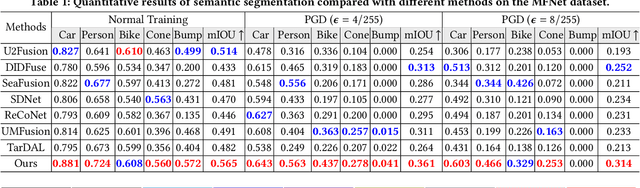
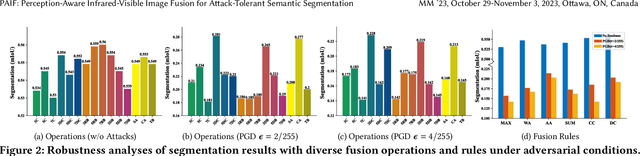
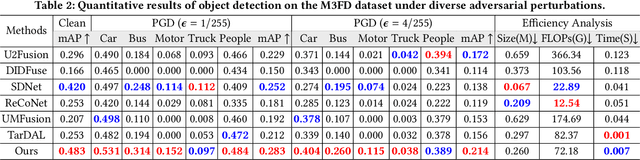
Infrared and visible image fusion is a powerful technique that combines complementary information from different modalities for downstream semantic perception tasks. Existing learning-based methods show remarkable performance, but are suffering from the inherent vulnerability of adversarial attacks, causing a significant decrease in accuracy. In this work, a perception-aware fusion framework is proposed to promote segmentation robustness in adversarial scenes. We first conduct systematic analyses about the components of image fusion, investigating the correlation with segmentation robustness under adversarial perturbations. Based on these analyses, we propose a harmonized architecture search with a decomposition-based structure to balance standard accuracy and robustness. We also propose an adaptive learning strategy to improve the parameter robustness of image fusion, which can learn effective feature extraction under diverse adversarial perturbations. Thus, the goals of image fusion (\textit{i.e.,} extracting complementary features from source modalities and defending attack) can be realized from the perspectives of architectural and learning strategies. Extensive experimental results demonstrate that our scheme substantially enhances the robustness, with gains of 15.3% mIOU of segmentation in the adversarial scene, compared with advanced competitors. The source codes are available at https://github.com/LiuZhu-CV/PAIF.
A Comprehensive Review on Tree Detection Methods Using Point Cloud and Aerial Imagery from Unmanned Aerial Vehicles
Oct 07, 2023Unmanned Aerial Vehicles (UAVs) are considered cutting-edge technology with highly cost-effective and flexible usage scenarios. Although many papers have reviewed the application of UAVs in agriculture, the review of the application for tree detection is still insufficient. This paper focuses on tree detection methods applied to UAV data collected by UAVs. There are two kinds of data, the point cloud and the images, which are acquired by the Light Detection and Ranging (LiDAR) sensor and camera, respectively. Among the detection methods using point-cloud data, this paper mainly classifies these methods according to LiDAR and Digital Aerial Photography (DAP). For the detection methods using images directly, this paper reviews these methods by whether or not to use the Deep Learning (DL) method. Our review concludes and analyses the comparison and combination between the application of LiDAR-based and DAP-based point cloud data. The performance, relative merits, and application fields of the methods are also introduced. Meanwhile, this review counts the number of tree detection studies using different methods in recent years. From our statics, the detection task using DL methods on the image has become a mainstream trend as the number of DL-based detection researches increases to 45% of the total number of tree detection studies up to 2022. As a result, this review could help and guide researchers who want to carry out tree detection on specific forests and for farmers to use UAVs in managing agriculture production.
Memory-Constrained Semantic Segmentation for Ultra-High Resolution UAV Imagery
Oct 07, 2023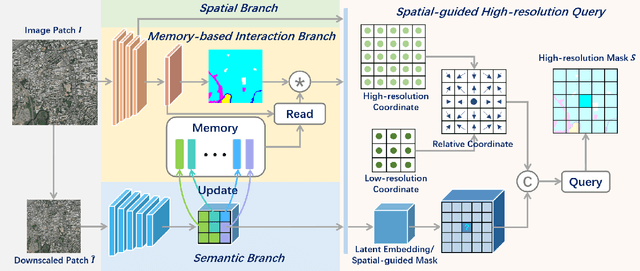
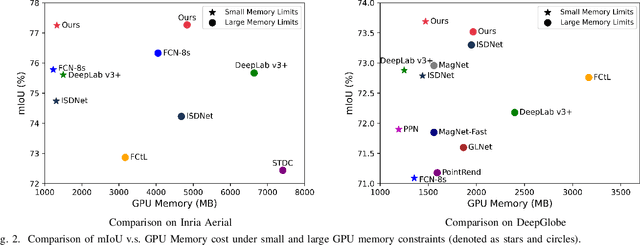
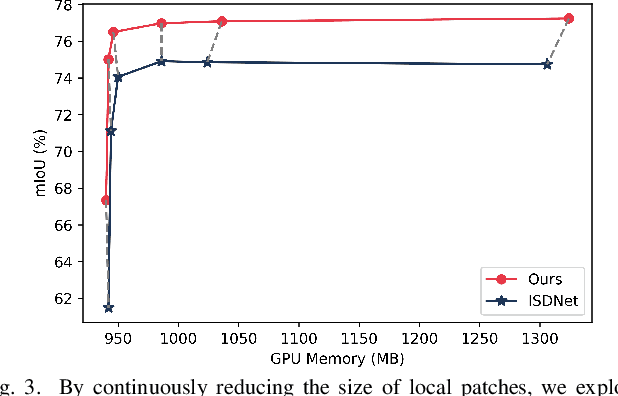

Amidst the swift advancements in photography and sensor technologies, high-definition cameras have become commonplace in the deployment of Unmanned Aerial Vehicles (UAVs) for diverse operational purposes. Within the domain of UAV imagery analysis, the segmentation of ultra-high resolution images emerges as a substantial and intricate challenge, especially when grappling with the constraints imposed by GPU memory-restricted computational devices. This paper delves into the intricate problem of achieving efficient and effective segmentation of ultra-high resolution UAV imagery, while operating under stringent GPU memory limitation. The strategy of existing approaches is to downscale the images to achieve computationally efficient segmentation. However, this strategy tends to overlook smaller, thinner, and curvilinear regions. To address this problem, we propose a GPU memory-efficient and effective framework for local inference without accessing the context beyond local patches. In particular, we introduce a novel spatial-guided high-resolution query module, which predicts pixel-wise segmentation results with high quality only by querying nearest latent embeddings with the guidance of high-resolution information. Additionally, we present an efficient memory-based interaction scheme to correct potential semantic bias of the underlying high-resolution information by associating cross-image contextual semantics. For evaluation of our approach, we perform comprehensive experiments over public benchmarks and achieve superior performance under both conditions of small and large GPU memory usage limitations. We will release the model and codes in the future.
Automatic and Efficient Customization of Neural Networks for ML Applications
Oct 07, 2023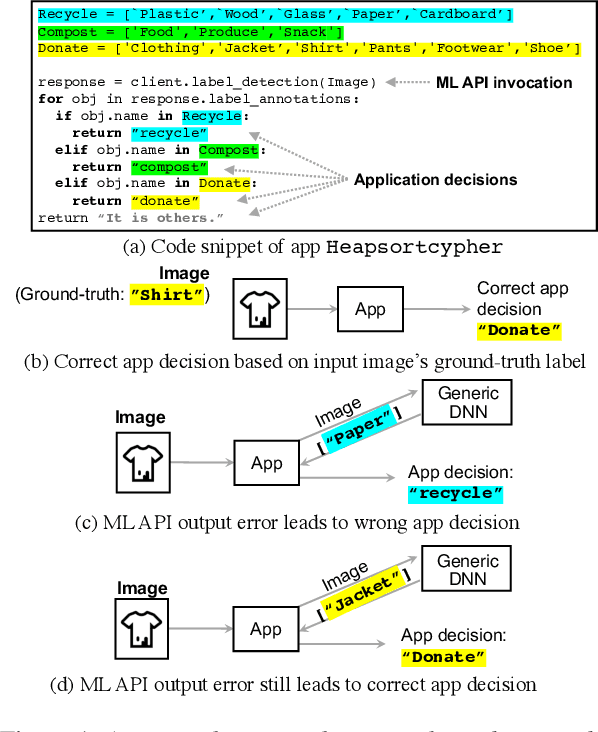



ML APIs have greatly relieved application developers of the burden to design and train their own neural network models -- classifying objects in an image can now be as simple as one line of Python code to call an API. However, these APIs offer the same pre-trained models regardless of how their output is used by different applications. This can be suboptimal as not all ML inference errors can cause application failures, and the distinction between inference errors that can or cannot cause failures varies greatly across applications. To tackle this problem, we first study 77 real-world applications, which collectively use six ML APIs from two providers, to reveal common patterns of how ML API output affects applications' decision processes. Inspired by the findings, we propose ChameleonAPI, an optimization framework for ML APIs, which takes effect without changing the application source code. ChameleonAPI provides application developers with a parser that automatically analyzes the application to produce an abstract of its decision process, which is then used to devise an application-specific loss function that only penalizes API output errors critical to the application. ChameleonAPI uses the loss function to efficiently train a neural network model customized for each application and deploys it to serve API invocations from the respective application via existing interface. Compared to a baseline that selects the best-of-all commercial ML API, we show that ChameleonAPI reduces incorrect application decisions by 43%.
Reversing Deep Face Embeddings with Probable Privacy Protection
Oct 04, 2023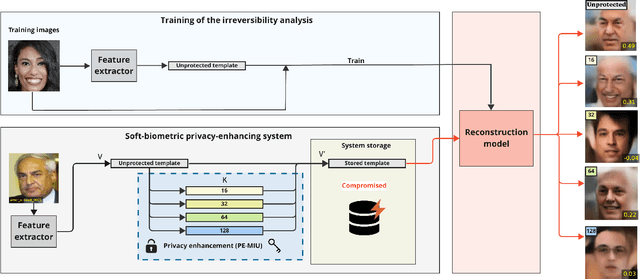
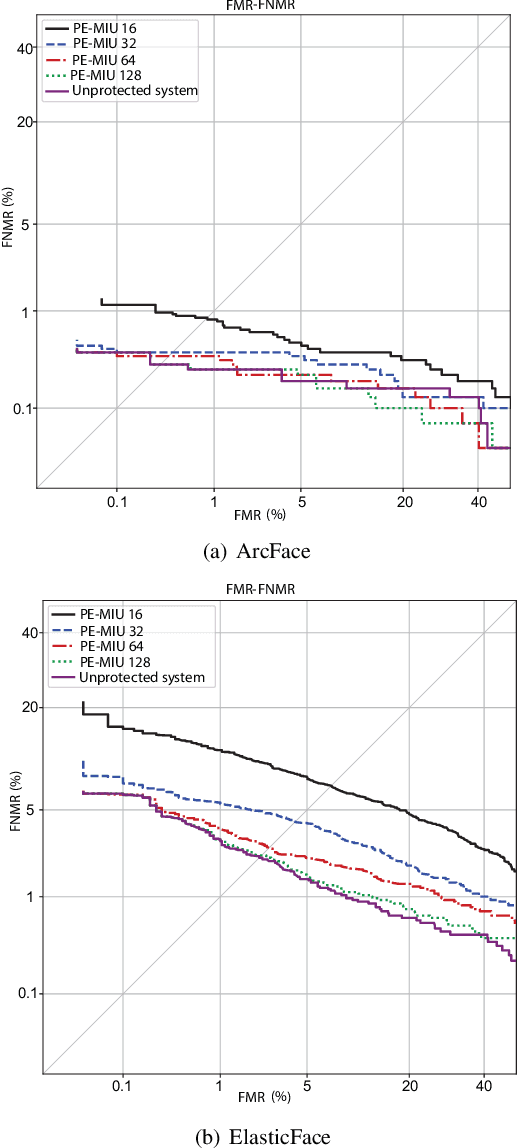

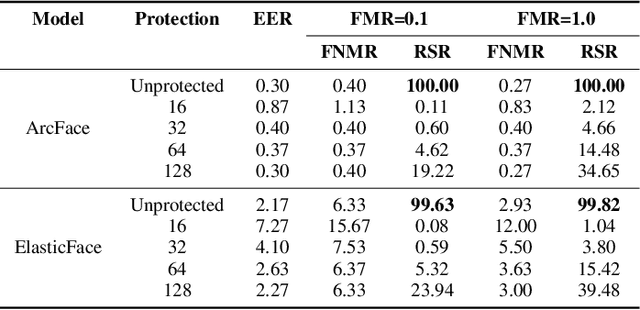
Generally, privacy-enhancing face recognition systems are designed to offer permanent protection of face embeddings. Recently, so-called soft-biometric privacy-enhancement approaches have been introduced with the aim of canceling soft-biometric attributes. These methods limit the amount of soft-biometric information (gender or skin-colour) that can be inferred from face embeddings. Previous work has underlined the need for research into rigorous evaluations and standardised evaluation protocols when assessing privacy protection capabilities. Motivated by this fact, this paper explores to what extent the non-invertibility requirement can be met by methods that claim to provide soft-biometric privacy protection. Additionally, a detailed vulnerability assessment of state-of-the-art face embedding extractors is analysed in terms of the transformation complexity used for privacy protection. In this context, a well-known state-of-the-art face image reconstruction approach has been evaluated on protected face embeddings to break soft biometric privacy protection. Experimental results show that biometric privacy-enhanced face embeddings can be reconstructed with an accuracy of up to approximately 98%, depending on the complexity of the protection algorithm.
Optimizing Key-Selection for Face-based One-Time Biometrics via Morphing
Oct 04, 2023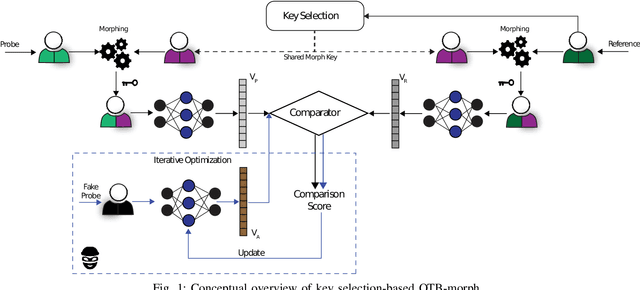

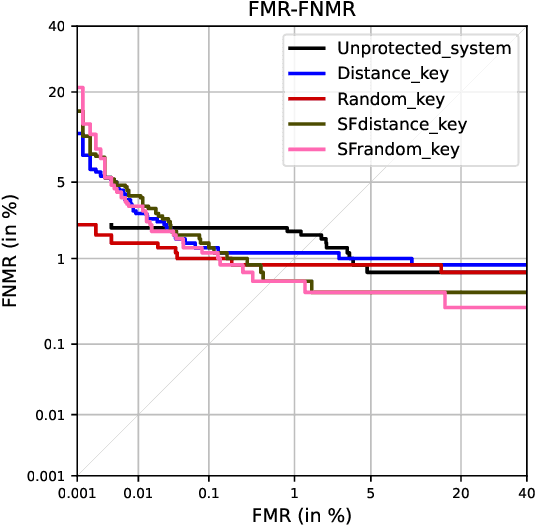
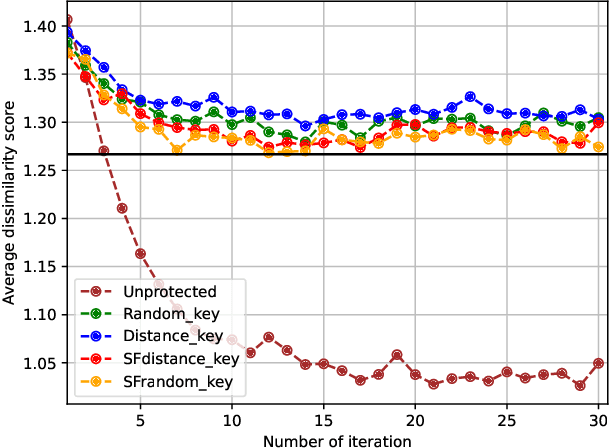
Nowadays, facial recognition systems are still vulnerable to adversarial attacks. These attacks vary from simple perturbations of the input image to modifying the parameters of the recognition model to impersonate an authorised subject. So-called privacy-enhancing facial recognition systems have been mostly developed to provide protection of stored biometric reference data, i.e. templates. In the literature, privacy-enhancing facial recognition approaches have focused solely on conventional security threats at the template level, ignoring the growing concern related to adversarial attacks. Up to now, few works have provided mechanisms to protect face recognition against adversarial attacks while maintaining high security at the template level. In this paper, we propose different key selection strategies to improve the security of a competitive cancelable scheme operating at the signal level. Experimental results show that certain strategies based on signal-level key selection can lead to complete blocking of the adversarial attack based on an iterative optimization for the most secure threshold, while for the most practical threshold, the attack success chance can be decreased to approximately 5.0%.
WaterFlow: Heuristic Normalizing Flow for Underwater Image Enhancement and Beyond
Aug 02, 2023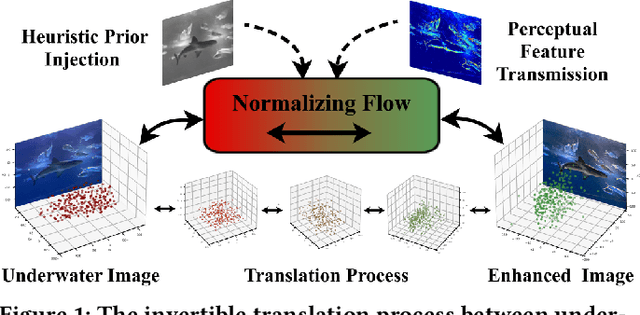
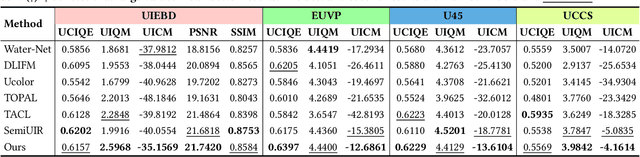
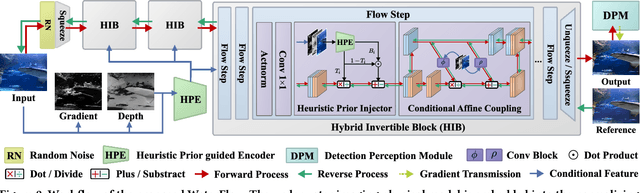
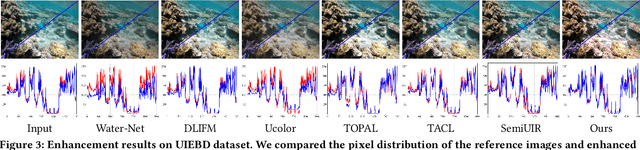
Underwater images suffer from light refraction and absorption, which impairs visibility and interferes the subsequent applications. Existing underwater image enhancement methods mainly focus on image quality improvement, ignoring the effect on practice. To balance the visual quality and application, we propose a heuristic normalizing flow for detection-driven underwater image enhancement, dubbed WaterFlow. Specifically, we first develop an invertible mapping to achieve the translation between the degraded image and its clear counterpart. Considering the differentiability and interpretability, we incorporate the heuristic prior into the data-driven mapping procedure, where the ambient light and medium transmission coefficient benefit credible generation. Furthermore, we introduce a detection perception module to transmit the implicit semantic guidance into the enhancement procedure, where the enhanced images hold more detection-favorable features and are able to promote the detection performance. Extensive experiments prove the superiority of our WaterFlow, against state-of-the-art methods quantitatively and qualitatively.
Logical Bias Learning for Object Relation Prediction
Oct 01, 2023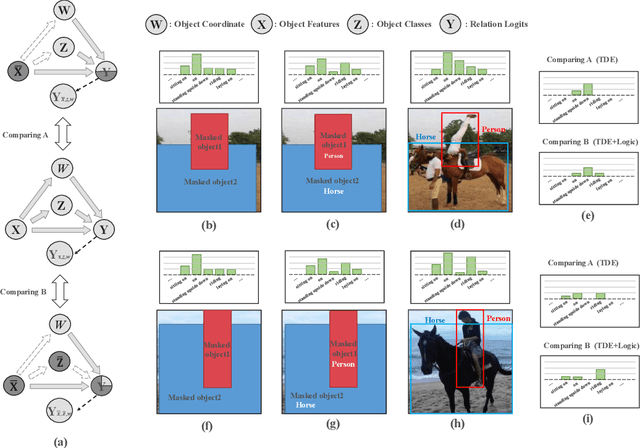
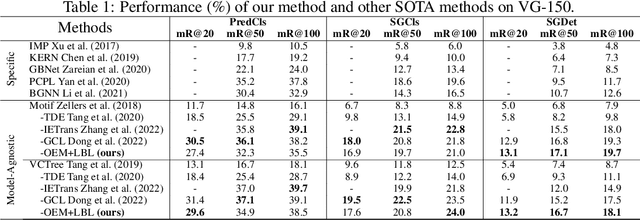
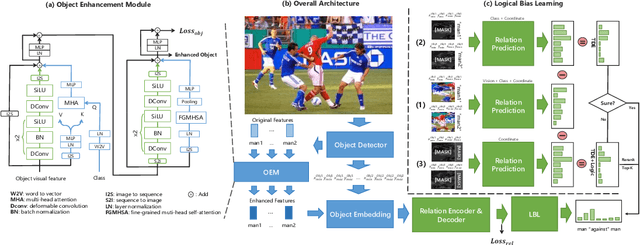
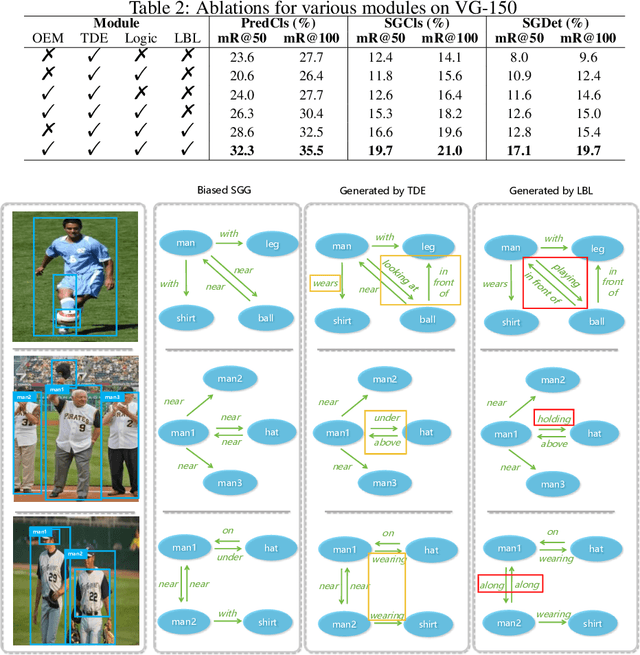
Scene graph generation (SGG) aims to automatically map an image into a semantic structural graph for better scene understanding. It has attracted significant attention for its ability to provide object and relation information, enabling graph reasoning for downstream tasks. However, it faces severe limitations in practice due to the biased data and training method. In this paper, we present a more rational and effective strategy based on causal inference for object relation prediction. To further evaluate the superiority of our strategy, we propose an object enhancement module to conduct ablation studies. Experimental results on the Visual Gnome 150 (VG-150) dataset demonstrate the effectiveness of our proposed method. These contributions can provide great potential for foundation models for decision-making.
Bridging Semantic Gaps for Language-Supervised Semantic Segmentation
Sep 27, 2023Vision-Language Pre-training has demonstrated its remarkable zero-shot recognition ability and potential to learn generalizable visual representations from language supervision. Taking a step ahead, language-supervised semantic segmentation enables spatial localization of textual inputs by learning pixel grouping solely from image-text pairs. Nevertheless, the state-of-the-art suffers from clear semantic gaps between visual and textual modality: plenty of visual concepts appeared in images are missing in their paired captions. Such semantic misalignment circulates in pre-training, leading to inferior zero-shot performance in dense predictions due to insufficient visual concepts captured in textual representations. To close such semantic gap, we propose Concept Curation (CoCu), a pipeline that leverages CLIP to compensate for the missing semantics. For each image-text pair, we establish a concept archive that maintains potential visually-matched concepts with our proposed vision-driven expansion and text-to-vision-guided ranking. Relevant concepts can thus be identified via cluster-guided sampling and fed into pre-training, thereby bridging the gap between visual and textual semantics. Extensive experiments over a broad suite of 8 segmentation benchmarks show that CoCu achieves superb zero-shot transfer performance and greatly boosts language-supervised segmentation baseline by a large margin, suggesting the value of bridging semantic gap in pre-training data.