 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reinforced UI Instruction Grounding: Towards a Generic UI Task Automation API
Oct 07, 2023
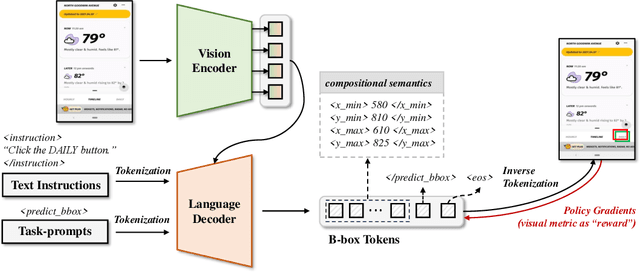


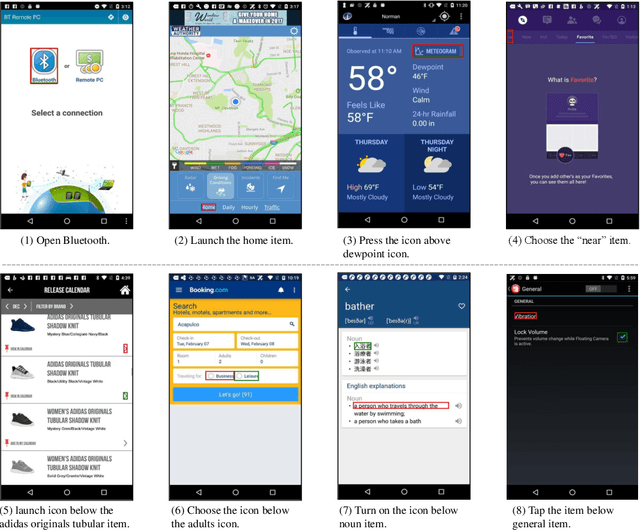
Recent popularity of Large Language Models (LLMs) has opened countless possibilities in automating numerous AI tasks by connecting LLMs to various domain-specific models or APIs, where LLMs serve as dispatchers while domain-specific models or APIs are action executors. Despite the vast numbers of domain-specific models/APIs, they still struggle to comprehensively cover super diverse automation demands in the interaction between human and User Interfaces (UIs). In this work, we build a multimodal model to ground natural language instructions in given UI screenshots as a generic UI task automation executor. This metadata-free grounding model, consisting of a visual encoder and a language decoder, is first pretrained on well studied document understanding tasks and then learns to decode spatial information from UI screenshots in a promptable way. To facilitate the exploitation of image-to-text pretrained knowledge, we follow the pixel-to-sequence paradigm to predict geometric coordinates in a sequence of tokens using a language decoder. We further propose an innovative Reinforcement Learning (RL) based algorithm to supervise the tokens in such sequence jointly with visually semantic metrics, which effectively strengthens the spatial decoding capability of the pixel-to-sequence paradigm. Extensive experiments demonstrate our proposed reinforced UI instruction grounding model outperforms the state-of-the-art methods by a clear margin and shows the potential as a generic UI task automation API.
Federated Self-Supervised Learning of Monocular Depth Estimators for Autonomous Vehicles
Oct 07, 2023Image-based depth estimation has gained significant attention in recent research on computer vision for autonomous vehicles in intelligent transportation systems. This focus stems from its cost-effectiveness and wide range of potential applications. Unlike binocular depth estimation methods that require two fixed cameras, monocular depth estimation methods only rely on a single camera, making them highly versatile. While state-of-the-art approaches for this task leverage self-supervised learning of deep neural networks in conjunction with tasks like pose estimation and semantic segmentation, none of them have explored the combination of federated learning and self-supervision to train models using unlabeled and private data captured by autonomous vehicles. The utilization of federated learning offers notable benefits, including enhanced privacy protection, reduced network consumption, and improved resilience to connectivity issues. To address this gap, we propose FedSCDepth, a novel method that combines federated learning and deep self-supervision to enable the learning of monocular depth estimators with comparable effectiveness and superior efficiency compared to the current state-of-the-art methods. Our evaluation experiments conducted on Eigen's Split of the KITTI dataset demonstrate that our proposed method achieves near state-of-the-art performance, with a test loss below 0.13 and requiring, on average, only 1.5k training steps and up to 0.415 GB of weight data transfer per autonomous vehicle on each round.
Dual Degradation-Inspired Deep Unfolding Network for Low-Light Image Enhancement
Aug 05, 2023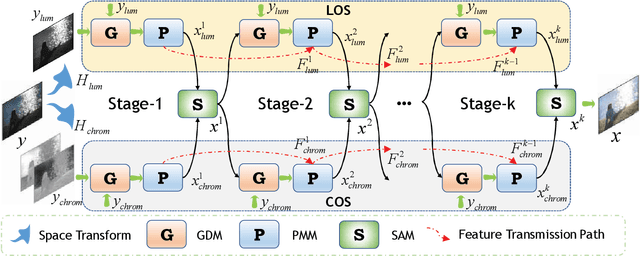
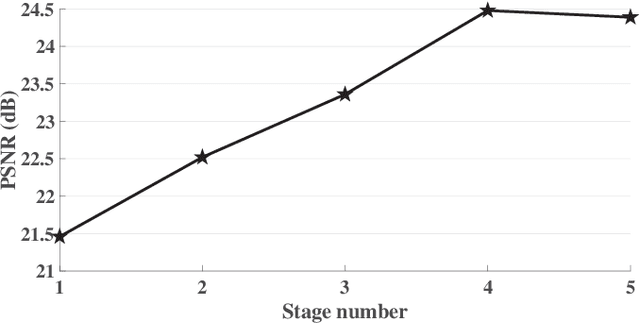


Although low-light image enhancement has achieved great stride based on deep enhancement models, most of them mainly stress on enhancement performance via an elaborated black-box network and rarely explore the physical significance of enhancement models. Towards this issue, we propose a Dual degrAdation-inSpired deep Unfolding network, termed DASUNet, for low-light image enhancement. Specifically, we construct a dual degradation model (DDM) to explicitly simulate the deterioration mechanism of low-light images. It learns two distinct image priors via considering degradation specificity between luminance and chrominance spaces. To make the proposed scheme tractable, we design an alternating optimization solution to solve the proposed DDM. Further, the designed solution is unfolded into a specified deep network, imitating the iteration updating rules, to form DASUNet. Local and long-range information are obtained by prior modeling module (PMM), inheriting the advantages of convolution and Transformer, to enhance the representation capability of dual degradation priors. Additionally, a space aggregation module (SAM) is presented to boost the interaction of two degradation models. Extensive experiments on multiple popular low-light image datasets validate the effectiveness of DASUNet compared to canonical state-of-the-art low-light image enhancement methods. Our source code and pretrained model will be publicly available.
TextDiff: Mask-Guided Residual Diffusion Models for Scene Text Image Super-Resolution
Aug 13, 2023
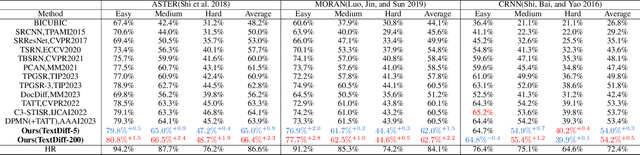


The goal of scene text image super-resolution is to reconstruct high-resolution text-line images from unrecognizable low-resolution inputs. The existing methods relying on the optimization of pixel-level loss tend to yield text edges that exhibit a notable degree of blurring, thereby exerting a substantial impact on both the readability and recognizability of the text. To address these issues, we propose TextDiff, the first diffusion-based framework tailored for scene text image super-resolution. It contains two modules: the Text Enhancement Module (TEM) and the Mask-Guided Residual Diffusion Module (MRD). The TEM generates an initial deblurred text image and a mask that encodes the spatial location of the text. The MRD is responsible for effectively sharpening the text edge by modeling the residuals between the ground-truth images and the initial deblurred images. Extensive experiments demonstrate that our TextDiff achieves state-of-the-art (SOTA) performance on public benchmark datasets and can improve the readability of scene text images. Moreover, our proposed MRD module is plug-and-play that effectively sharpens the text edges produced by SOTA methods. This enhancement not only improves the readability and recognizability of the results generated by SOTA methods but also does not require any additional joint training. Available Codes:https://github.com/Lenubolim/TextDiff.
Brighten-and-Colorize: A Decoupled Network for Customized Low-Light Image Enhancement
Aug 06, 2023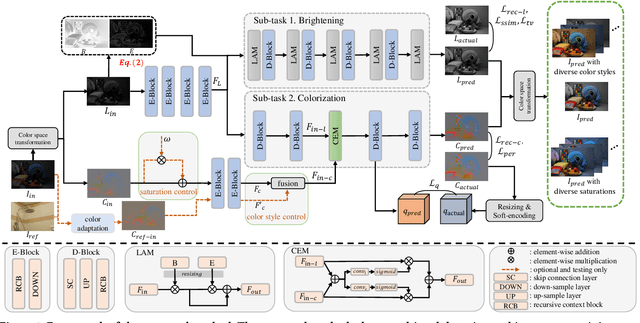

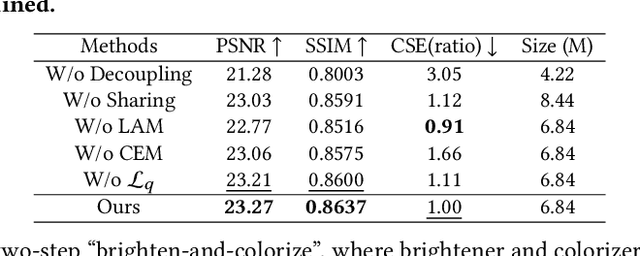
Low-Light Image Enhancement (LLIE) aims to improve the perceptual quality of an image captured in low-light conditions. Generally, a low-light image can be divided into lightness and chrominance components. Recent advances in this area mainly focus on the refinement of the lightness, while ignoring the role of chrominance. It easily leads to chromatic aberration and, to some extent, limits the diverse applications of chrominance in customized LLIE. In this work, a ``brighten-and-colorize'' network (called BCNet), which introduces image colorization to LLIE, is proposed to address the above issues. BCNet can accomplish LLIE with accurate color and simultaneously enables customized enhancement with varying saturations and color styles based on user preferences. Specifically, BCNet regards LLIE as a multi-task learning problem: brightening and colorization. The brightening sub-task aligns with other conventional LLIE methods to get a well-lit lightness. The colorization sub-task is accomplished by regarding the chrominance of the low-light image as color guidance like the user-guide image colorization. Upon completion of model training, the color guidance (i.e., input low-light chrominance) can be simply manipulated by users to acquire customized results. This customized process is optional and, due to its decoupled nature, does not compromise the structural and detailed information of lightness. Extensive experiments on the commonly used LLIE datasets show that the proposed method achieves both State-Of-The-Art (SOTA) performance and user-friendly customization.
How Does Pruning Impact Long-Tailed Multi-Label Medical Image Classifiers?
Aug 17, 2023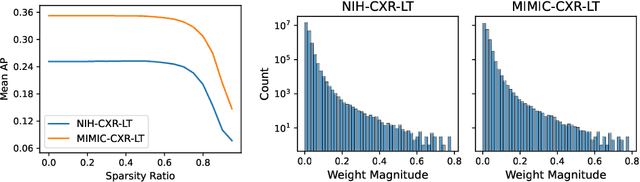

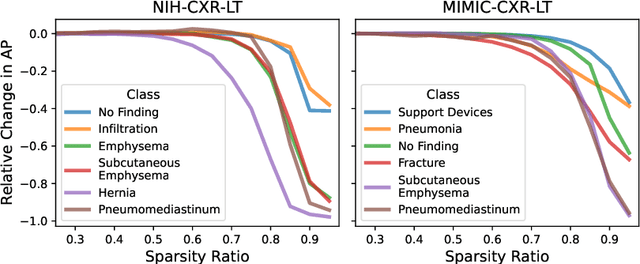
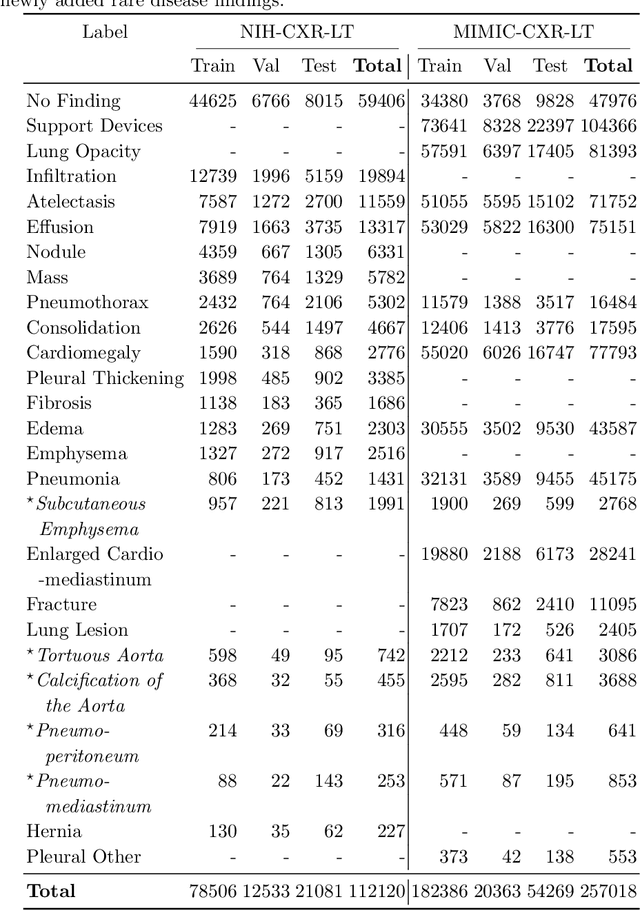
Pruning has emerged as a powerful technique for compressing deep neural networks, reducing memory usage and inference time without significantly affecting overall performance. However, the nuanced ways in which pruning impacts model behavior are not well understood, particularly for long-tailed, multi-label datasets commonly found in clinical settings. This knowledge gap could have dangerous implications when deploying a pruned model for diagnosis, where unexpected model behavior could impact patient well-being. To fill this gap, we perform the first analysis of pruning's effect on neural networks trained to diagnose thorax diseases from chest X-rays (CXRs). On two large CXR datasets, we examine which diseases are most affected by pruning and characterize class "forgettability" based on disease frequency and co-occurrence behavior. Further, we identify individual CXRs where uncompressed and heavily pruned models disagree, known as pruning-identified exemplars (PIEs), and conduct a human reader study to evaluate their unifying qualities. We find that radiologists perceive PIEs as having more label noise, lower image quality, and higher diagnosis difficulty. This work represents a first step toward understanding the impact of pruning on model behavior in deep long-tailed, multi-label medical image classification. All code, model weights, and data access instructions can be found at https://github.com/VITA-Group/PruneCXR.
Denoising Diffusion Probabilistic Model for Retinal Image Generation and Segmentation
Aug 16, 2023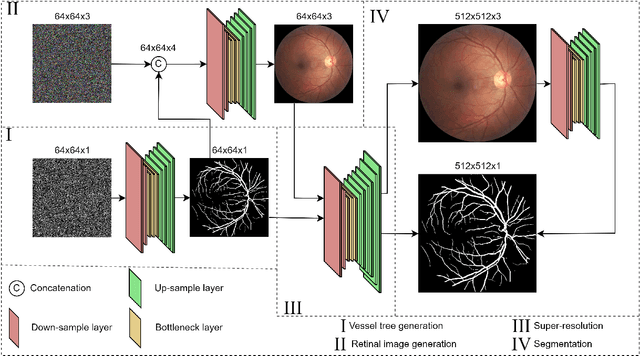
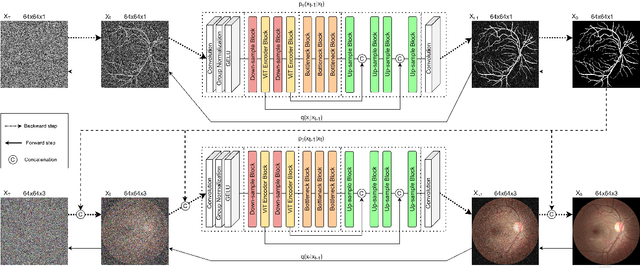

Experts use retinal images and vessel trees to detect and diagnose various eye, blood circulation, and brain-related diseases. However, manual segmentation of retinal images is a time-consuming process that requires high expertise and is difficult due to privacy issues. Many methods have been proposed to segment images, but the need for large retinal image datasets limits the performance of these methods. Several methods synthesize deep learning models based on Generative Adversarial Networks (GAN) to generate limited sample varieties. This paper proposes a novel Denoising Diffusion Probabilistic Model (DDPM) that outperformed GANs in image synthesis. We developed a Retinal Trees (ReTree) dataset consisting of retinal images, corresponding vessel trees, and a segmentation network based on DDPM trained with images from the ReTree dataset. In the first stage, we develop a two-stage DDPM that generates vessel trees from random numbers belonging to a standard normal distribution. Later, the model is guided to generate fundus images from given vessel trees and random distribution. The proposed dataset has been evaluated quantitatively and qualitatively. Quantitative evaluation metrics include Frechet Inception Distance (FID) score, Jaccard similarity coefficient, Cohen's kappa, Matthew's Correlation Coefficient (MCC), precision, recall, F1-score, and accuracy. We trained the vessel segmentation model with synthetic data to validate our dataset's efficiency and tested it on authentic data. Our developed dataset and source code is available at https://github.com/AAleka/retree.
Depolarized Holography with Polarization-multiplexing Metasurface
Sep 26, 2023The evolution of computer-generated holography (CGH) algorithms has prompted significant improvements in the performances of holographic displays. Nonetheless, they start to encounter a limited degree of freedom in CGH optimization and physical constraints stemming from the coherent nature of holograms. To surpass the physical limitations, we consider polarization as a new degree of freedom by utilizing a novel optical platform called metasurface. Polarization-multiplexing metasurfaces enable incoherent-like behavior in holographic displays due to the mutual incoherence of orthogonal polarization states. We leverage this unique characteristic of a metasurface by integrating it into a holographic display and exploiting polarization diversity to bring an additional degree of freedom for CGH algorithms. To minimize the speckle noise while maximizing the image quality, we devise a fully differentiable optimization pipeline by taking into account the metasurface proxy model, thereby jointly optimizing spatial light modulator phase patterns and geometric parameters of metasurface nanostructures. We evaluate the metasurface-enabled depolarized holography through simulations and experiments, demonstrating its ability to reduce speckle noise and enhance image quality.
PEACE: Prompt Engineering Automation for CLIPSeg Enhancement in Aerial Robotics
Sep 29, 2023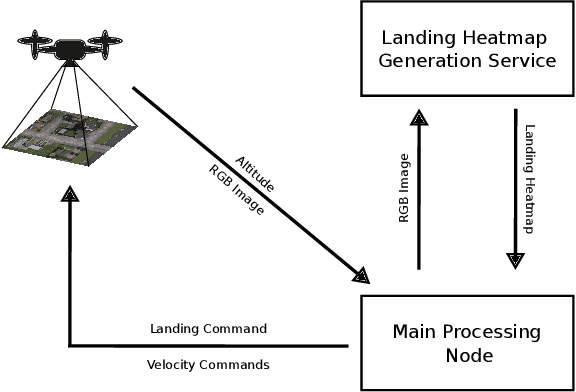
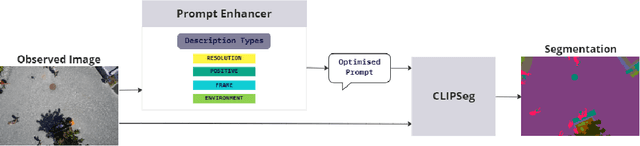
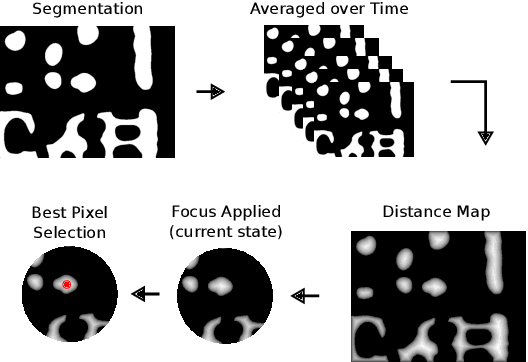
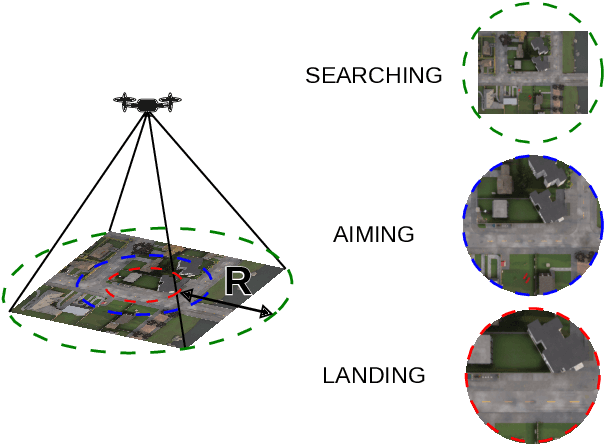
From industrial to space robotics, safe landing is an essential component for flight operations. With the growing interest in artificial intelligence, we direct our attention to learning based safe landing approaches. This paper extends our previous work, DOVESEI, which focused on a reactive UAV system by harnessing the capabilities of open vocabulary image segmentation. Prompt-based safe landing zone segmentation using an open vocabulary based model is no more just an idea, but proven to be feasible by the work of DOVESEI. However, a heuristic selection of words for prompt is not a reliable solution since it cannot take the changing environment into consideration and detrimental consequences can occur if the observed environment is not well represented by the given prompt. Therefore, we introduce PEACE (Prompt Engineering Automation for CLIPSeg Enhancement), powering DOVESEI to automate the prompt generation and engineering to adapt to data distribution shifts. Our system is capable of performing safe landing operations with collision avoidance at altitudes as low as 20 meters using only monocular cameras and image segmentation. We take advantage of DOVESEI's dynamic focus to circumvent abrupt fluctuations in the terrain segmentation between frames in a video stream. PEACE shows promising improvements in prompt generation and engineering for aerial images compared to the standard prompt used for CLIP and CLIPSeg. Combining DOVESEI and PEACE, our system was able improve successful safe landing zone selections by 58.62% compared to using only DOVESEI. All the source code is open source and available online.
IOSG: Image-driven Object Searching and Grasping
Aug 10, 2023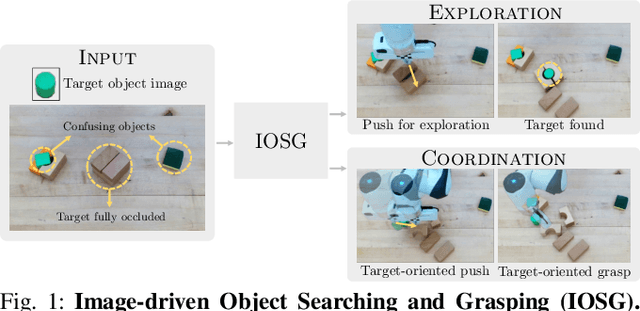
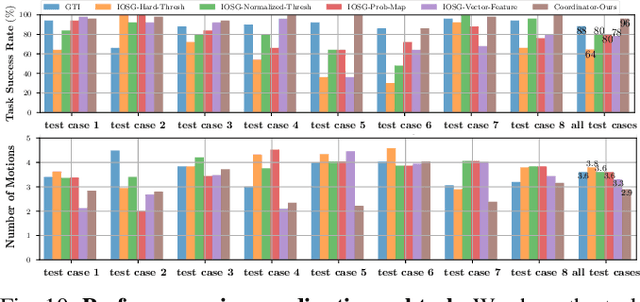

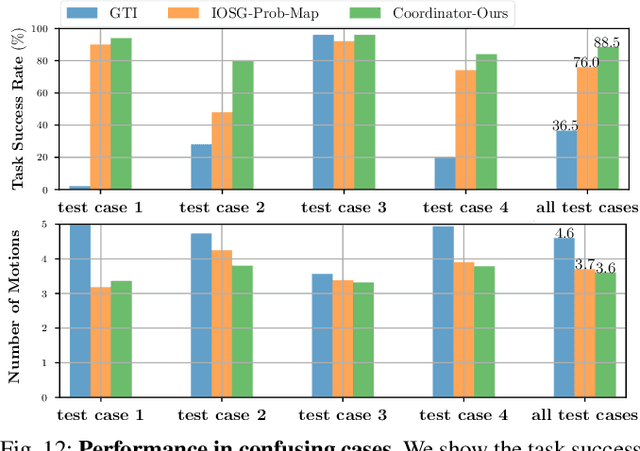
When robots retrieve specific objects from cluttered scenes, such as home and warehouse environments, the target objects are often partially occluded or completely hidden. Robots are thus required to search, identify a target object, and successfully grasp it. Preceding works have relied on pre-trained object recognition or segmentation models to find the target object. However, such methods require laborious manual annotations to train the models and even fail to find novel target objects. In this paper, we propose an Image-driven Object Searching and Grasping (IOSG) approach where a robot is provided with the reference image of a novel target object and tasked to find and retrieve it. We design a Target Similarity Network that generates a probability map to infer the location of the novel target. IOSG learns a hierarchical policy; the high-level policy predicts the subtask type, whereas the low-level policies, explorer and coordinator, generate effective push and grasp actions. The explorer is responsible for searching the target object when it is hidden or occluded by other objects. Once the target object is found, the coordinator conducts target-oriented pushing and grasping to retrieve the target from the clutter. The proposed pipeline is trained with full self-supervision in simulation and applied to a real environment. Our model achieves a 96.0% and 94.5% task success rate on coordination and exploration tasks in simulation respectively, and 85.0% success rate on a real robot for the search-and-grasp task.