 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Text-guided Foundation Model Adaptation for Pathological Image Classification
Jul 27, 2023
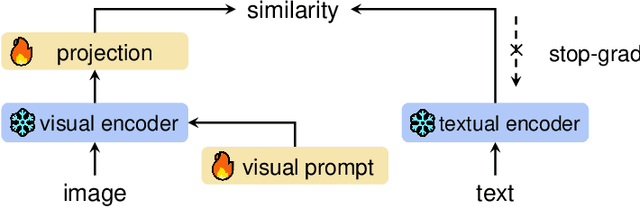

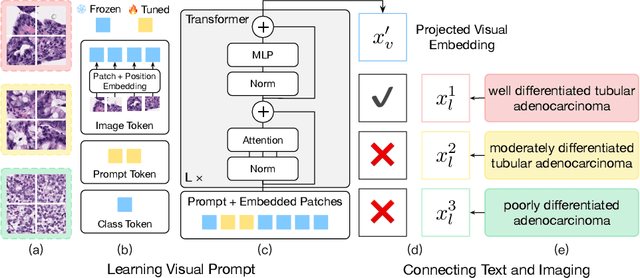
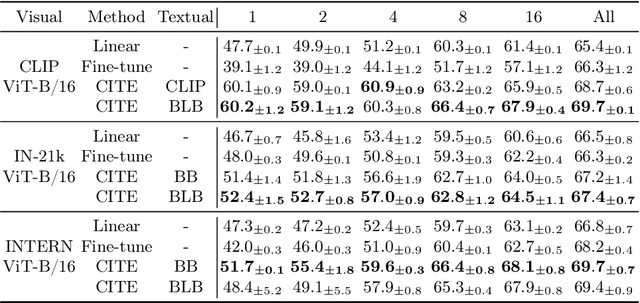
The recent surge of foundation models in computer vision and natural language processing opens up perspectives in utilizing multi-modal clinical data to train large models with strong generalizability. Yet pathological image datasets often lack biomedical text annotation and enrichment. Guiding data-efficient image diagnosis from the use of biomedical text knowledge becomes a substantial interest. In this paper, we propose to Connect Image and Text Embeddings (CITE) to enhance pathological image classification. CITE injects text insights gained from language models pre-trained with a broad range of biomedical texts, leading to adapt foundation models towards pathological image understanding. Through extensive experiments on the PatchGastric stomach tumor pathological image dataset, we demonstrate that CITE achieves leading performance compared with various baselines especially when training data is scarce. CITE offers insights into leveraging in-domain text knowledge to reinforce data-efficient pathological image classification. Code is available at https://github.com/Yunkun-Zhang/CITE.
FGFusion: Fine-Grained Lidar-Camera Fusion for 3D Object Detection
Sep 21, 2023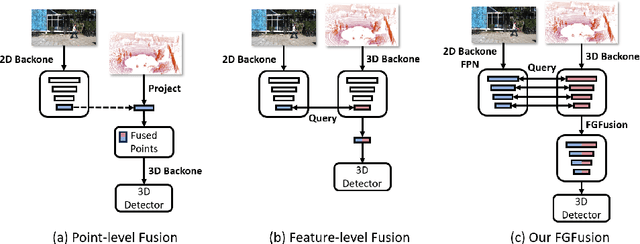
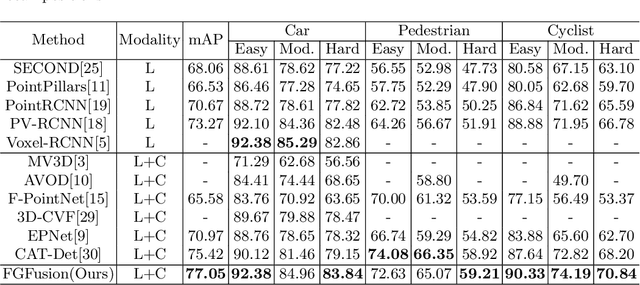
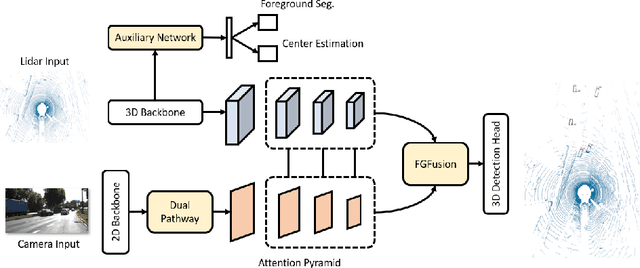
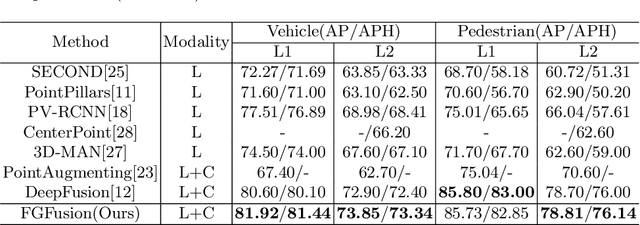
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While most prevalent methods progressively downscale the 3D point clouds and camera images and then fuse the high-level features, the downscaled features inevitably lose low-level detailed information. In this paper, we propose Fine-Grained Lidar-Camera Fusion (FGFusion) that make full use of multi-scale features of image and point cloud and fuse them in a fine-grained way. First, we design a dual pathway hierarchy structure to extract both high-level semantic and low-level detailed features of the image. Second, an auxiliary network is introduced to guide point cloud features to better learn the fine-grained spatial information. Finally, we propose multi-scale fusion (MSF) to fuse the last N feature maps of image and point cloud. Extensive experiments on two popular autonomous driving benchmarks, i.e. KITTI and Waymo, demonstrate the effectiveness of our method.
Learning Expected Appearances for Intraoperative Registration during Neurosurgery
Oct 03, 2023We present a novel method for intraoperative patient-to-image registration by learning Expected Appearances. Our method uses preoperative imaging to synthesize patient-specific expected views through a surgical microscope for a predicted range of transformations. Our method estimates the camera pose by minimizing the dissimilarity between the intraoperative 2D view through the optical microscope and the synthesized expected texture. In contrast to conventional methods, our approach transfers the processing tasks to the preoperative stage, reducing thereby the impact of low-resolution, distorted, and noisy intraoperative images, that often degrade the registration accuracy. We applied our method in the context of neuronavigation during brain surgery. We evaluated our approach on synthetic data and on retrospective data from 6 clinical cases. Our method outperformed state-of-the-art methods and achieved accuracies that met current clinical standards.
CLIP-DIY: CLIP Dense Inference Yields Open-Vocabulary Semantic Segmentation For-Free
Sep 25, 2023

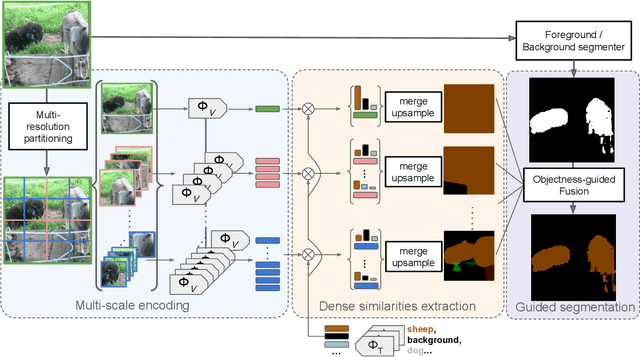
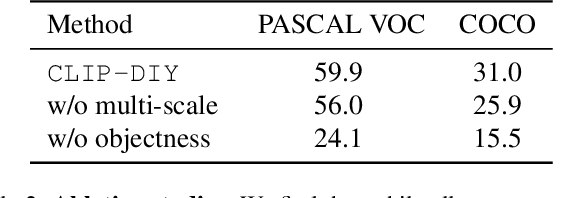
The emergence of CLIP has opened the way for open-world image perception. The zero-shot classification capabilities of the model are impressive but are harder to use for dense tasks such as image segmentation. Several methods have proposed different modifications and learning schemes to produce dense output. Instead, we propose in this work an open-vocabulary semantic segmentation method, dubbed CLIP-DIY, which does not require any additional training or annotations, but instead leverages existing unsupervised object localization approaches. In particular, CLIP-DIY is a multi-scale approach that directly exploits CLIP classification abilities on patches of different sizes and aggregates the decision in a single map. We further guide the segmentation using foreground/background scores obtained using unsupervised object localization methods. With our method, we obtain state-of-the-art zero-shot semantic segmentation results on PASCAL VOC and perform on par with the best methods on COCO.
CTP-Net: Character Texture Perception Network for Document Image Forgery Localization
Aug 04, 2023
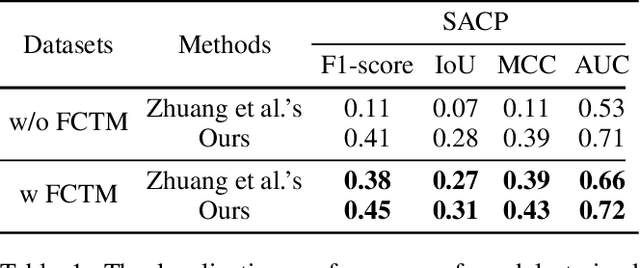
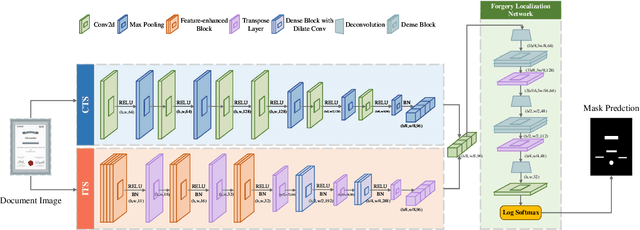
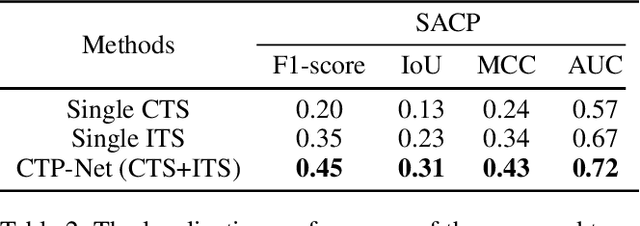
Due to the progression of information technology in recent years, document images have been widely disseminated in social networks. With the help of powerful image editing tools, document images are easily forged without leaving visible manipulation traces, which leads to severe issues if significant information is falsified for malicious use. Therefore, the research of document image forensics is worth further exploring. In a document image, the character with specific semantic information is most vulnerable to tampering, for which capturing the forgery traces of the character is the key to localizing the forged region in document images. Considering both character and image textures, in this paper, we propose a Character Texture Perception Network (CTP-Net) to localize the forgery of document images. Based on optical character recognition, a Character Texture Stream (CTS) is designed to capture features of text areas that are essential components of a document image. Meanwhile, texture features of the whole document image are exploited by an Image Texture Stream (ITS). Combining the features extracted from the CTS and the ITS, the CTP-Net can reveal more subtle forgery traces from document images. To overcome the challenge caused by the lack of fake document images, we design a data generation strategy that is utilized to construct a Fake Chinese Trademark dataset (FCTM). Through a series of experiments, we show that the proposed CTP-Net is able to capture tampering traces in document images, especially in text regions. Experimental results demonstrate that CTP-Net can localize multi-scale forged areas in document images and outperform the state-of-the-art forgery localization methods.
MindDiffuser: Controlled Image Reconstruction from Human Brain Activity with Semantic and Structural Diffusion
Aug 08, 2023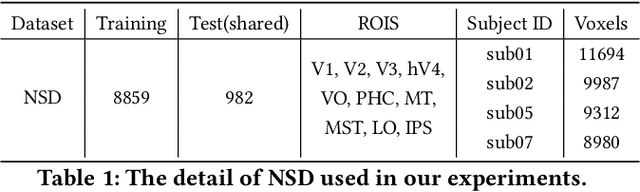
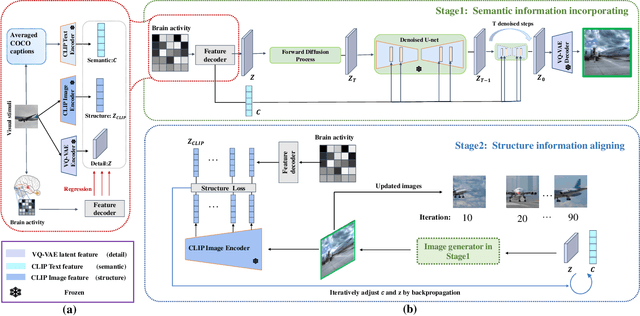
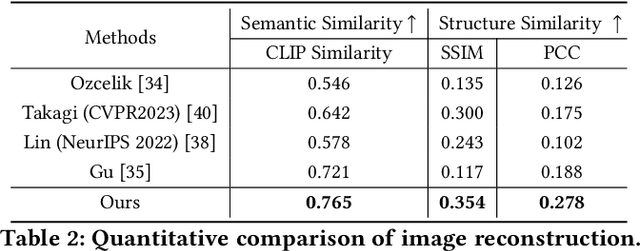
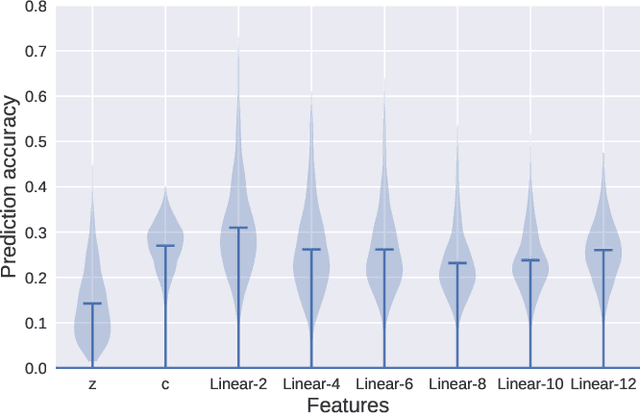
Reconstructing visual stimuli from brain recordings has been a meaningful and challenging task. Especially, the achievement of precise and controllable image reconstruction bears great significance in propelling the progress and utilization of brain-computer interfaces. Despite the advancements in complex image reconstruction techniques, the challenge persists in achieving a cohesive alignment of both semantic (concepts and objects) and structure (position, orientation, and size) with the image stimuli. To address the aforementioned issue, we propose a two-stage image reconstruction model called MindDiffuser. In Stage 1, the VQ-VAE latent representations and the CLIP text embeddings decoded from fMRI are put into Stable Diffusion, which yields a preliminary image that contains semantic information. In Stage 2, we utilize the CLIP visual feature decoded from fMRI as supervisory information, and continually adjust the two feature vectors decoded in Stage 1 through backpropagation to align the structural information. The results of both qualitative and quantitative analyses demonstrate that our model has surpassed the current state-of-the-art models on Natural Scenes Dataset (NSD). The subsequent experimental findings corroborate the neurobiological plausibility of the model, as evidenced by the interpretability of the multimodal feature employed, which align with the corresponding brain responses.
DeepMesh: Mesh-based Cardiac Motion Tracking using Deep Learning
Sep 25, 2023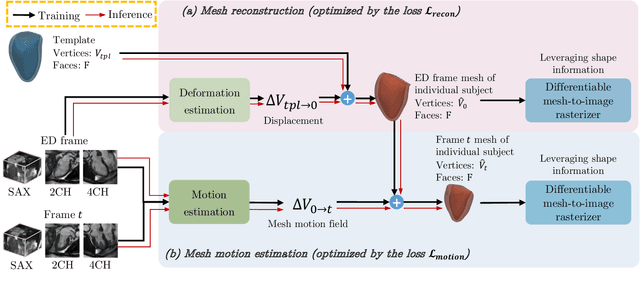
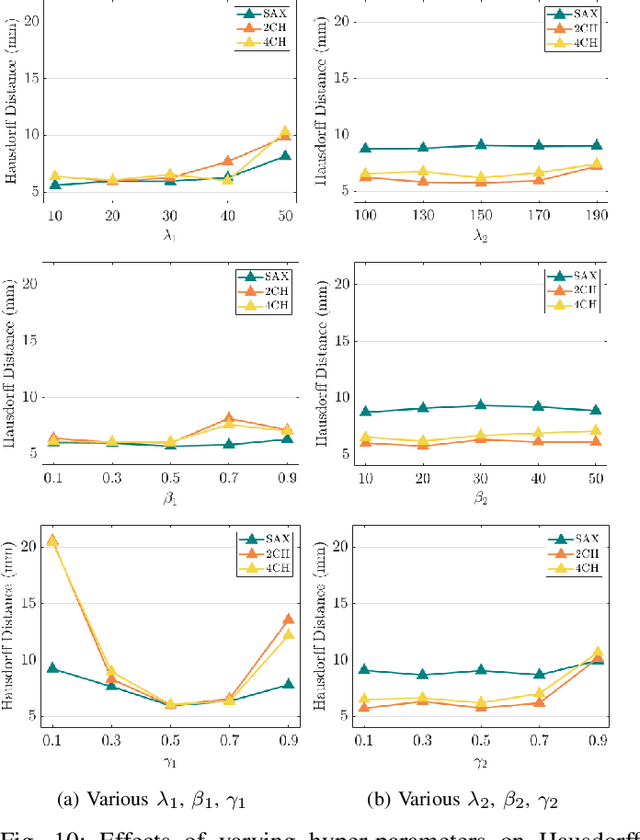
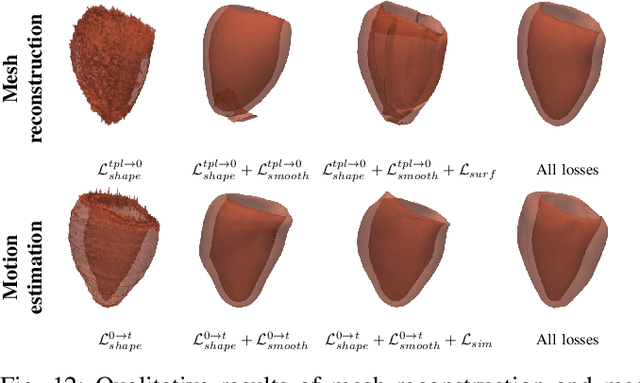
3D motion estimation from cine cardiac magnetic resonance (CMR) images is important for the assessment of cardiac function and the diagnosis of cardiovascular diseases. Current state-of-the art methods focus on estimating dense pixel-/voxel-wise motion fields in image space, which ignores the fact that motion estimation is only relevant and useful within the anatomical objects of interest, e.g., the heart. In this work, we model the heart as a 3D mesh consisting of epi- and endocardial surfaces. We propose a novel learning framework, DeepMesh, which propagates a template heart mesh to a subject space and estimates the 3D motion of the heart mesh from CMR images for individual subjects. In DeepMesh, the heart mesh of the end-diastolic frame of an individual subject is first reconstructed from the template mesh. Mesh-based 3D motion fields with respect to the end-diastolic frame are then estimated from 2D short- and long-axis CMR images. By developing a differentiable mesh-to-image rasterizer, DeepMesh is able to leverage 2D shape information from multiple anatomical views for 3D mesh reconstruction and mesh motion estimation. The proposed method estimates vertex-wise displacement and thus maintains vertex correspondences between time frames, which is important for the quantitative assessment of cardiac function across different subjects and populations. We evaluate DeepMesh on CMR images acquired from the UK Biobank. We focus on 3D motion estimation of the left ventricle in this work. Experimental results show that the proposed method quantitatively and qualitatively outperforms other image-based and mesh-based cardiac motion tracking methods.
Global Features are All You Need for Image Retrieval and Reranking
Aug 19, 2023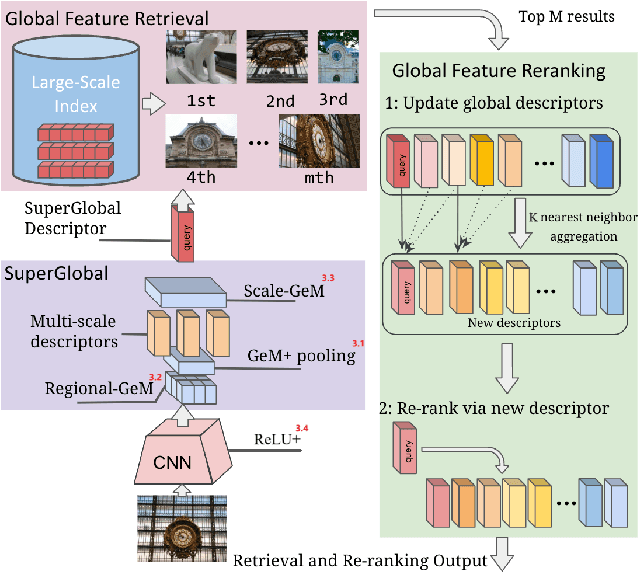
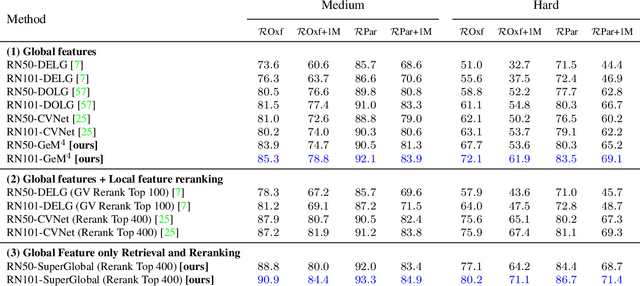
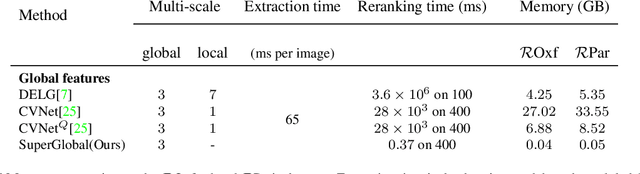
Image retrieval systems conventionally use a two-stage paradigm, leveraging global features for initial retrieval and local features for reranking. However, the scalability of this method is often limited due to the significant storage and computation cost incurred by local feature matching in the reranking stage. In this paper, we present SuperGlobal, a novel approach that exclusively employs global features for both stages, improving efficiency without sacrificing accuracy. SuperGlobal introduces key enhancements to the retrieval system, specifically focusing on the global feature extraction and reranking processes. For extraction, we identify sub-optimal performance when the widely-used ArcFace loss and Generalized Mean (GeM) pooling methods are combined and propose several new modules to improve GeM pooling. In the reranking stage, we introduce a novel method to update the global features of the query and top-ranked images by only considering feature refinement with a small set of images, thus being very compute and memory efficient. Our experiments demonstrate substantial improvements compared to the state of the art in standard benchmarks. Notably, on the Revisited Oxford+1M Hard dataset, our single-stage results improve by 7.1%, while our two-stage gain reaches 3.7% with a strong 64,865x speedup. Our two-stage system surpasses the current single-stage state-of-the-art by 16.3%, offering a scalable, accurate alternative for high-performing image retrieval systems with minimal time overhead. Code: https://github.com/ShihaoShao-GH/SuperGlobal.
Finite Scalar Quantization: VQ-VAE Made Simple
Sep 27, 2023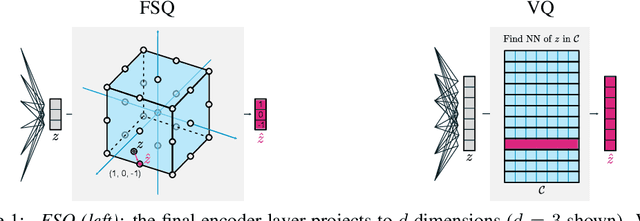


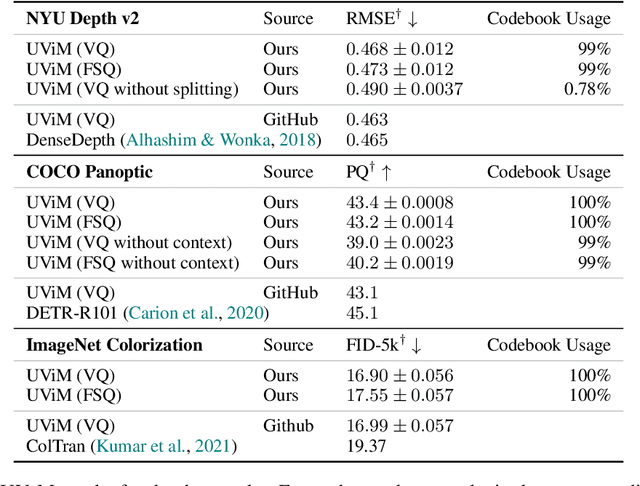
We propose to replace vector quantization (VQ) in the latent representation of VQ-VAEs with a simple scheme termed finite scalar quantization (FSQ), where we project the VAE representation down to a few dimensions (typically less than 10). Each dimension is quantized to a small set of fixed values, leading to an (implicit) codebook given by the product of these sets. By appropriately choosing the number of dimensions and values each dimension can take, we obtain the same codebook size as in VQ. On top of such discrete representations, we can train the same models that have been trained on VQ-VAE representations. For example, autoregressive and masked transformer models for image generation, multimodal generation, and dense prediction computer vision tasks. Concretely, we employ FSQ with MaskGIT for image generation, and with UViM for depth estimation, colorization, and panoptic segmentation. Despite the much simpler design of FSQ, we obtain competitive performance in all these tasks. We emphasize that FSQ does not suffer from codebook collapse and does not need the complex machinery employed in VQ (commitment losses, codebook reseeding, code splitting, entropy penalties, etc.) to learn expressive discrete representations.
Improving Facade Parsing with Vision Transformers and Line Integration
Oct 07, 2023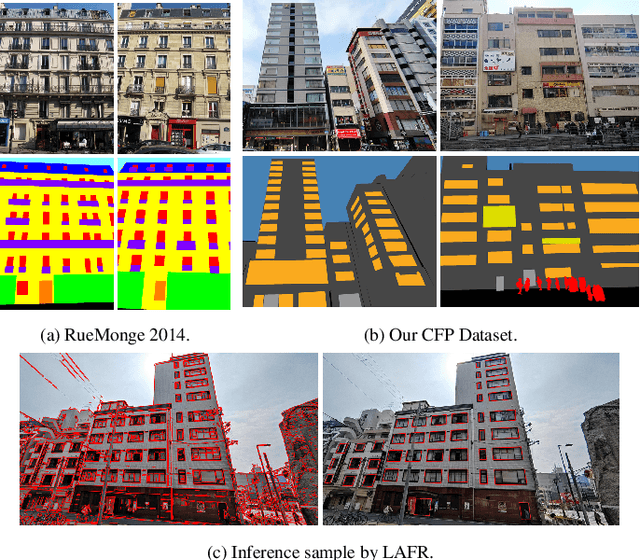
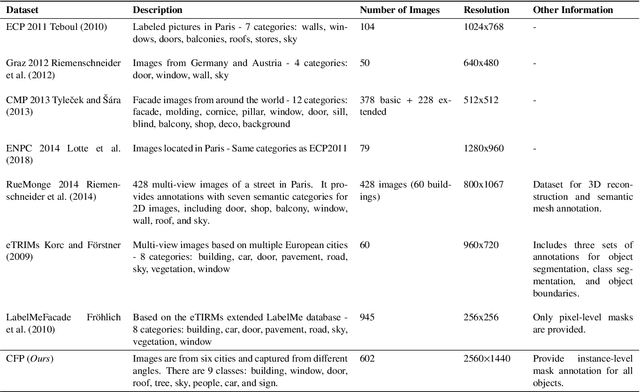

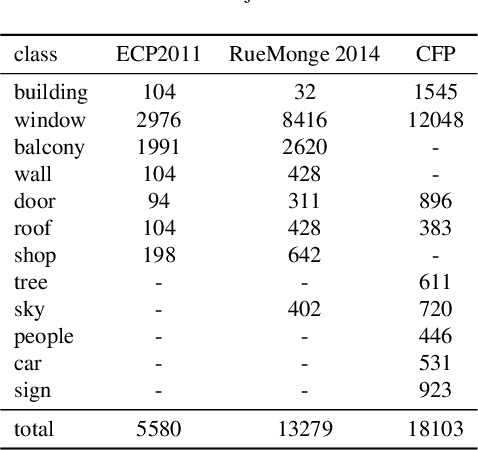
Facade parsing stands as a pivotal computer vision task with far-reaching applications in areas like architecture, urban planning, and energy efficiency. Despite the recent success of deep learning-based methods in yielding impressive results on certain open-source datasets, their viability for real-world applications remains uncertain. Real-world scenarios are considerably more intricate, demanding greater computational efficiency. Existing datasets often fall short in representing these settings, and previous methods frequently rely on extra models to enhance accuracy, which requires much computation cost. In this paper, we introduce Comprehensive Facade Parsing (CFP), a dataset meticulously designed to encompass the intricacies of real-world facade parsing tasks. Comprising a total of 602 high-resolution street-view images, this dataset captures a diverse array of challenging scenarios, including sloping angles and densely clustered buildings, with painstakingly curated annotations for each image. We introduce a new pipeline known as Revision-based Transformer Facade Parsing (RTFP). This marks the pioneering utilization of Vision Transformers (ViT) in facade parsing, and our experimental results definitively substantiate its merit. We also design Line Acquisition, Filtering, and Revision (LAFR), an efficient yet accurate revision algorithm that can improve the segment result solely from simple line detection using prior knowledge of the facade. In ECP 2011, RueMonge 2014, and our CFP, we evaluate the superiority of our method.