 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Communication-Efficient Framework for Distributed Image Semantic Wireless Transmission
Aug 08, 2023
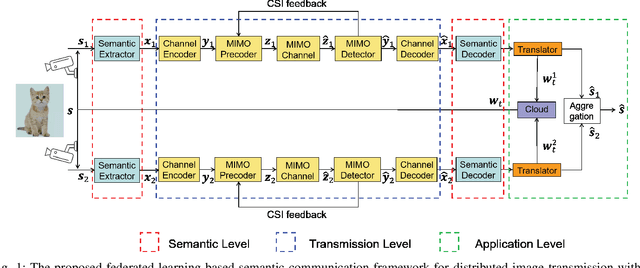
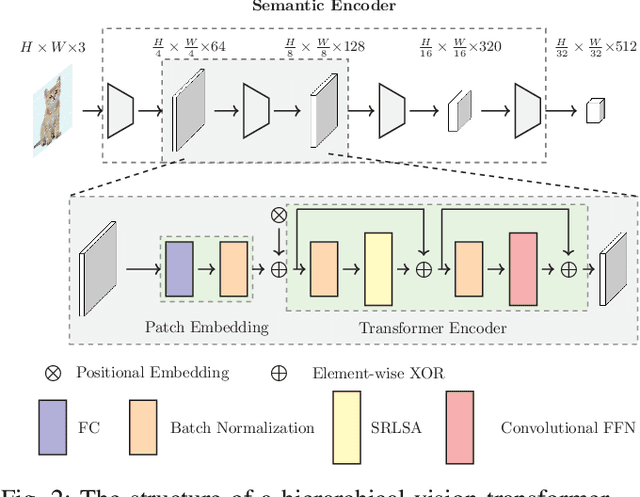
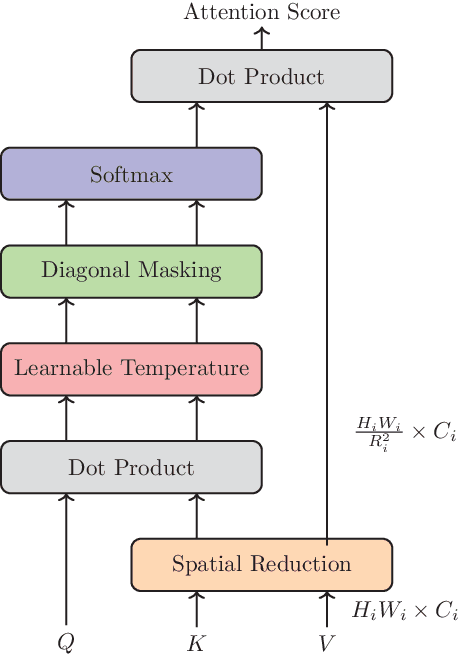
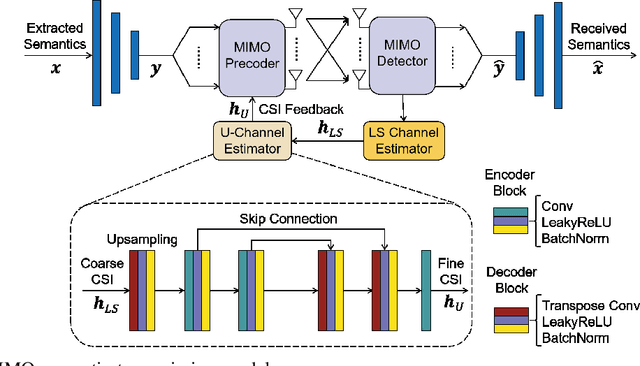
Multi-node communication, which refers to the interaction among multiple devices, has attracted lots of attention in many Internet-of-Things (IoT) scenarios. However, its huge amounts of data flows and inflexibility for task extension have triggered the urgent requirement of communication-efficient distributed data transmission frameworks. In this paper, inspired by the great superiorities on bandwidth reduction and task adaptation of semantic communications, we propose a federated learning-based semantic communication (FLSC) framework for multi-task distributed image transmission with IoT devices. Federated learning enables the design of independent semantic communication link of each user while further improves the semantic extraction and task performance through global aggregation. Each link in FLSC is composed of a hierarchical vision transformer (HVT)-based extractor and a task-adaptive translator for coarse-to-fine semantic extraction and meaning translation according to specific tasks. In order to extend the FLSC into more realistic conditions, we design a channel state information-based multiple-input multiple-output transmission module to combat channel fading and noise. Simulation results show that the coarse semantic information can deal with a range of image-level tasks. Moreover, especially in low signal-to-noise ratio and channel bandwidth ratio regimes, FLSC evidently outperforms the traditional scheme, e.g. about 10 peak signal-to-noise ratio gain in the 3 dB channel condition.
Co-Salient Object Detection with Semantic-Level Consensus Extraction and Dispersion
Sep 14, 2023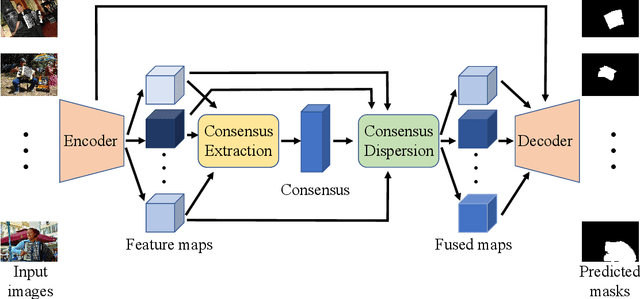
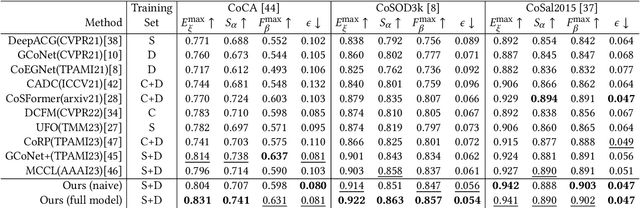

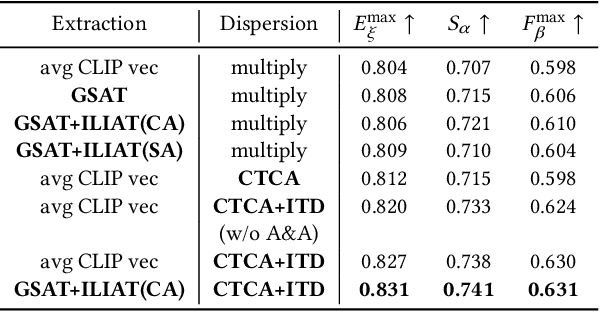
Given a group of images, co-salient object detection (CoSOD) aims to highlight the common salient object in each image. There are two factors closely related to the success of this task, namely consensus extraction, and the dispersion of consensus to each image. Most previous works represent the group consensus using local features, while we instead utilize a hierarchical Transformer module for extracting semantic-level consensus. Therefore, it can obtain a more comprehensive representation of the common object category, and exclude interference from other objects that share local similarities with the target object. In addition, we propose a Transformer-based dispersion module that takes into account the variation of the co-salient object in different scenes. It distributes the consensus to the image feature maps in an image-specific way while making full use of interactions within the group. These two modules are integrated with a ViT encoder and an FPN-like decoder to form an end-to-end trainable network, without additional branch and auxiliary loss. The proposed method is evaluated on three commonly used CoSOD datasets and achieves state-of-the-art performance.
High Dynamic Range Image Reconstruction via Deep Explicit Polynomial Curve Estimation
Jul 31, 2023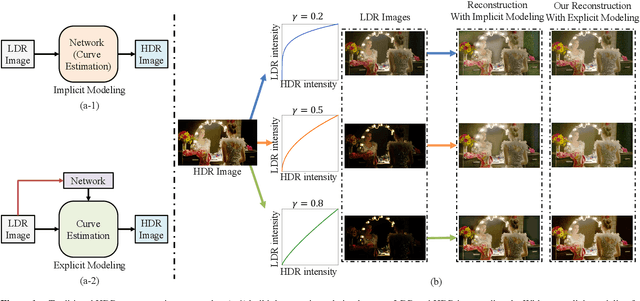
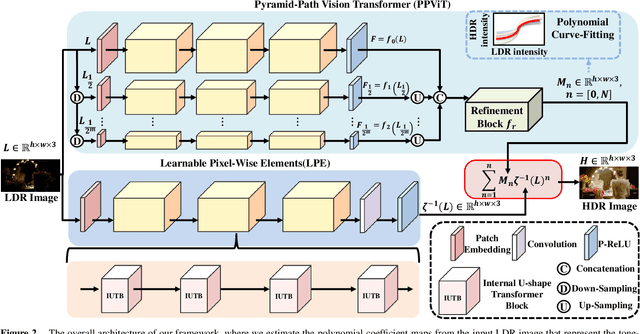
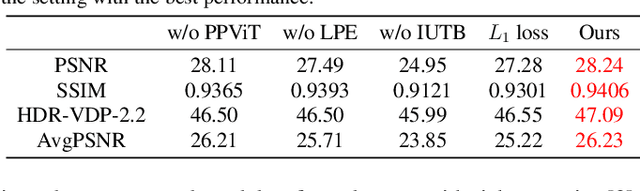
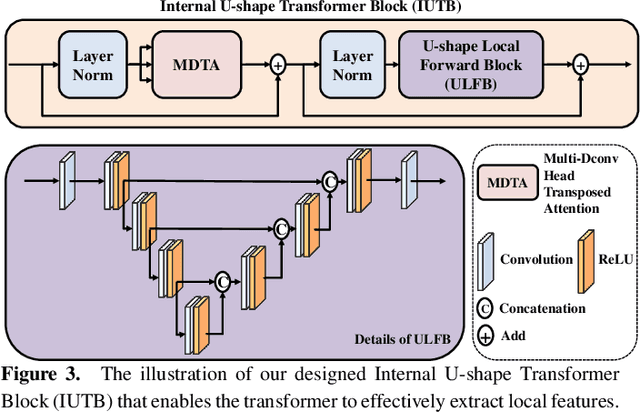
Due to limited camera capacities, digital images usually have a narrower dynamic illumination range than real-world scene radiance. To resolve this problem, High Dynamic Range (HDR) reconstruction is proposed to recover the dynamic range to better represent real-world scenes. However, due to different physical imaging parameters, the tone-mapping functions between images and real radiance are highly diverse, which makes HDR reconstruction extremely challenging. Existing solutions can not explicitly clarify a corresponding relationship between the tone-mapping function and the generated HDR image, but this relationship is vital when guiding the reconstruction of HDR images. To address this problem, we propose a method to explicitly estimate the tone mapping function and its corresponding HDR image in one network. Firstly, based on the characteristics of the tone mapping function, we construct a model by a polynomial to describe the trend of the tone curve. To fit this curve, we use a learnable network to estimate the coefficients of the polynomial. This curve will be automatically adjusted according to the tone space of the Low Dynamic Range (LDR) image, and reconstruct the real HDR image. Besides, since all current datasets do not provide the corresponding relationship between the tone mapping function and the LDR image, we construct a new dataset with both synthetic and real images. Extensive experiments show that our method generalizes well under different tone-mapping functions and achieves SOTA performance.
Improving Facade Parsing with Vision Transformers and Line Integration
Oct 02, 2023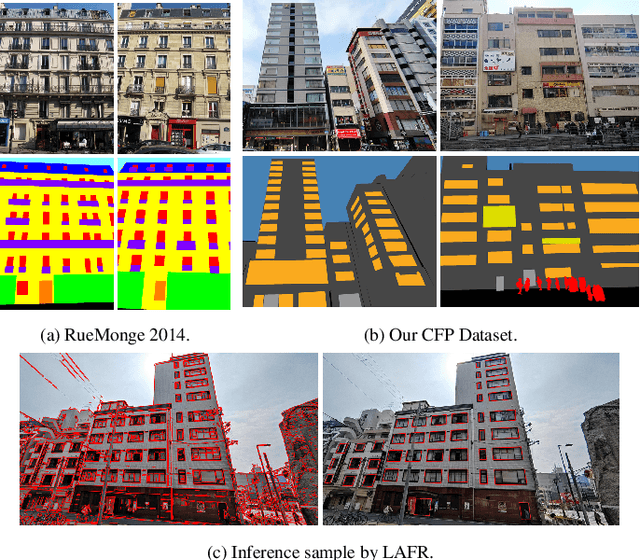
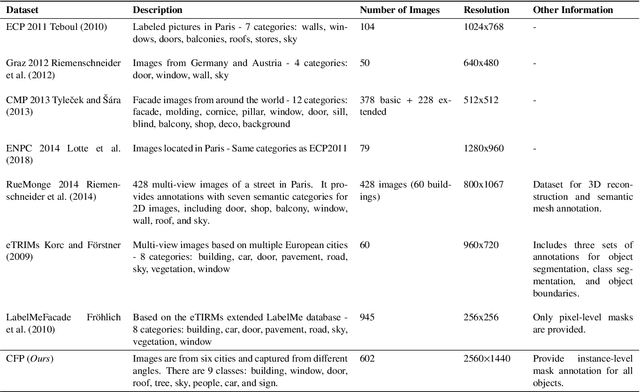

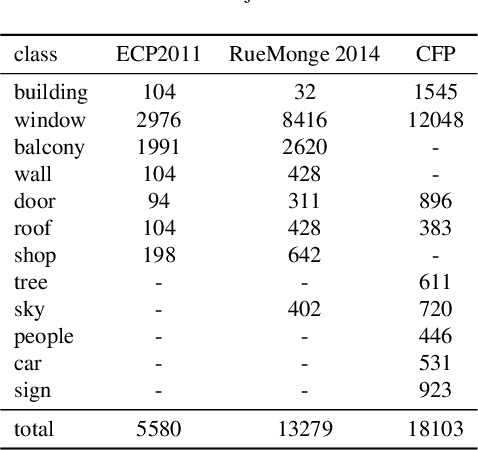
Facade parsing stands as a pivotal computer vision task with far-reaching applications in areas like architecture, urban planning, and energy efficiency. Despite the recent success of deep learning-based methods in yielding impressive results on certain open-source datasets, their viability for real-world applications remains uncertain. Real-world scenarios are considerably more intricate, demanding greater computational efficiency. Existing datasets often fall short in representing these settings, and previous methods frequently rely on extra models to enhance accuracy, which requires much computation cost. In this paper, we introduce Comprehensive Facade Parsing (CFP), a dataset meticulously designed to encompass the intricacies of real-world facade parsing tasks. Comprising a total of 602 high-resolution street-view images, this dataset captures a diverse array of challenging scenarios, including sloping angles and densely clustered buildings, with painstakingly curated annotations for each image. We introduce a new pipeline known as Revision-based Transformer Facade Parsing (RTFP). This marks the pioneering utilization of Vision Transformers (ViT) in facade parsing, and our experimental results definitively substantiate its merit. We also design Line Acquisition, Filtering, and Revision (LAFR), an efficient yet accurate revision algorithm that can improve the segment result solely from simple line detection using prior knowledge of the facade. In ECP 2011, RueMonge 2014, and our CFP, we evaluate the superiority of our method. The dataset and code are available at https://github.com/wbw520/RTFP.
LEAP: Liberate Sparse-view 3D Modeling from Camera Poses
Oct 02, 2023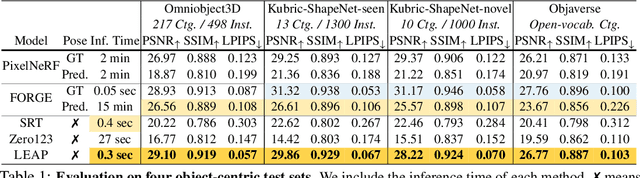
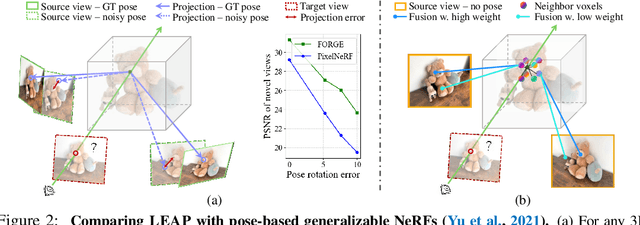
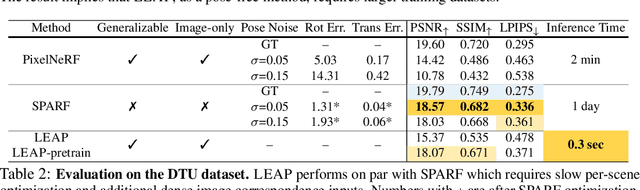
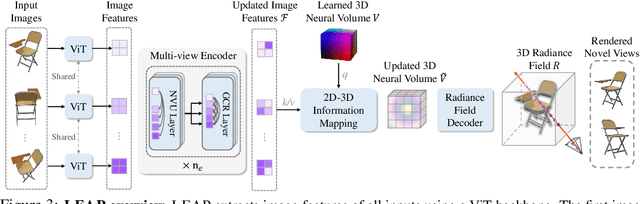
Are camera poses necessary for multi-view 3D modeling? Existing approaches predominantly assume access to accurate camera poses. While this assumption might hold for dense views, accurately estimating camera poses for sparse views is often elusive. Our analysis reveals that noisy estimated poses lead to degraded performance for existing sparse-view 3D modeling methods. To address this issue, we present LEAP, a novel pose-free approach, therefore challenging the prevailing notion that camera poses are indispensable. LEAP discards pose-based operations and learns geometric knowledge from data. LEAP is equipped with a neural volume, which is shared across scenes and is parameterized to encode geometry and texture priors. For each incoming scene, we update the neural volume by aggregating 2D image features in a feature-similarity-driven manner. The updated neural volume is decoded into the radiance field, enabling novel view synthesis from any viewpoint. On both object-centric and scene-level datasets, we show that LEAP significantly outperforms prior methods when they employ predicted poses from state-of-the-art pose estimators. Notably, LEAP performs on par with prior approaches that use ground-truth poses while running $400\times$ faster than PixelNeRF. We show LEAP generalizes to novel object categories and scenes, and learns knowledge closely resembles epipolar geometry. Project page: https://hwjiang1510.github.io/LEAP/
Towards reporting bias in visual-language datasets: bimodal augmentation by decoupling object-attribute association
Oct 02, 2023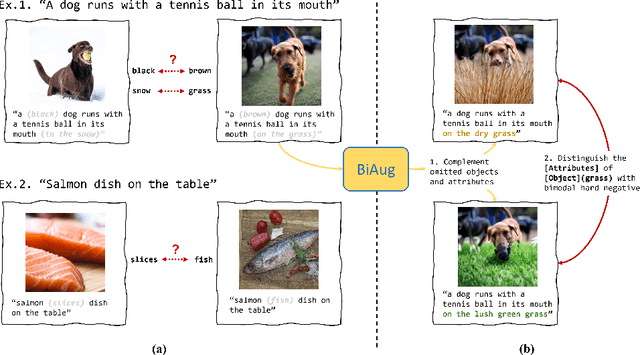
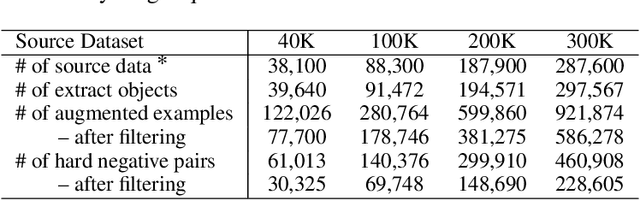
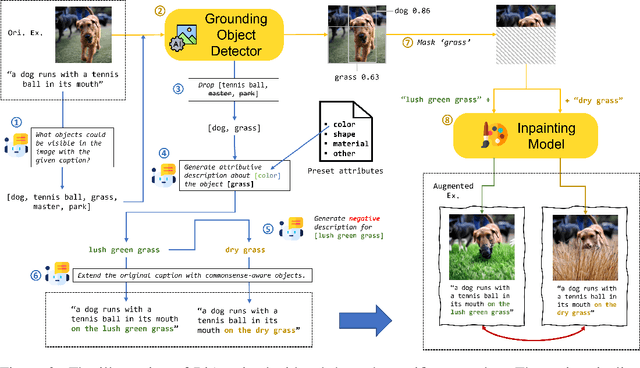
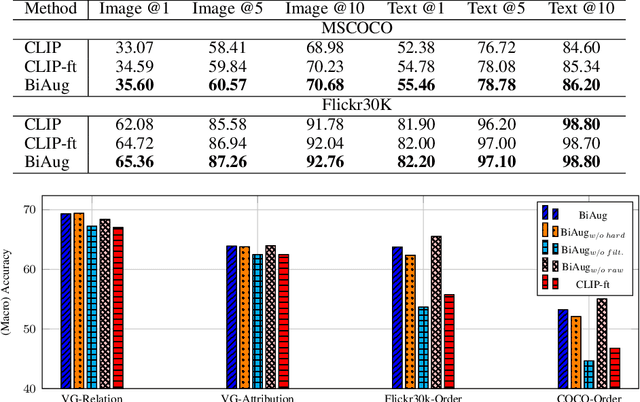
Reporting bias arises when people assume that some knowledge is universally understood and hence, do not necessitate explicit elaboration. In this paper, we focus on the wide existence of reporting bias in visual-language datasets, embodied as the object-attribute association, which can subsequentially degrade models trained on them. To mitigate this bias, we propose a bimodal augmentation (BiAug) approach through object-attribute decoupling to flexibly synthesize visual-language examples with a rich array of object-attribute pairing and construct cross-modal hard negatives. We employ large language models (LLMs) in conjunction with a grounding object detector to extract target objects. Subsequently, the LLM generates a detailed attribute description for each object and produces a corresponding hard negative counterpart. An inpainting model is then used to create images based on these detailed object descriptions. By doing so, the synthesized examples explicitly complement omitted objects and attributes to learn, and the hard negative pairs steer the model to distinguish object attributes. Our experiments demonstrated that BiAug is superior in object-attribute understanding. In addition, BiAug also improves the performance on zero-shot retrieval tasks on general benchmarks like MSCOCO and Flickr30K. BiAug refines the way of collecting text-image datasets. Mitigating the reporting bias helps models achieve a deeper understanding of visual-language phenomena, expanding beyond mere frequent patterns to encompass the richness and diversity of real-world scenarios.
RRR-Net: Reusing, Reducing, and Recycling a Deep Backbone Network
Oct 02, 2023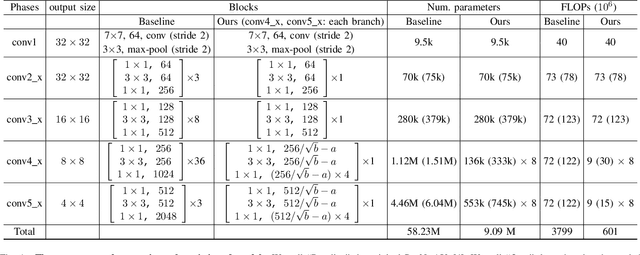
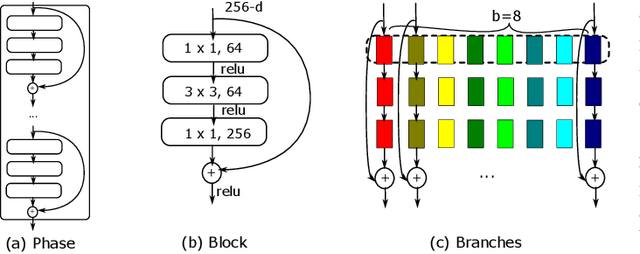
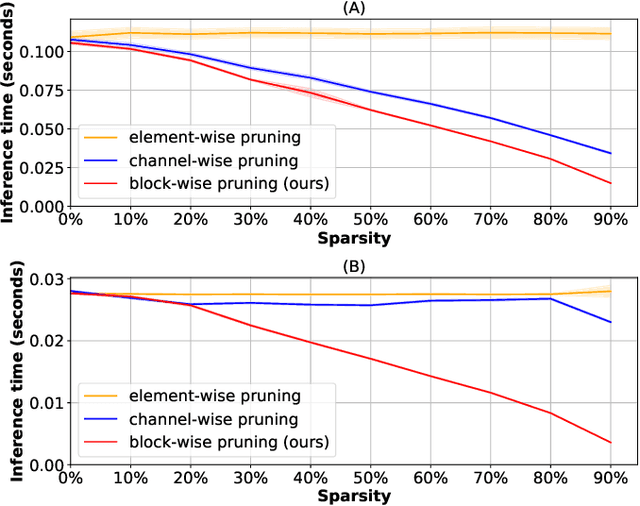
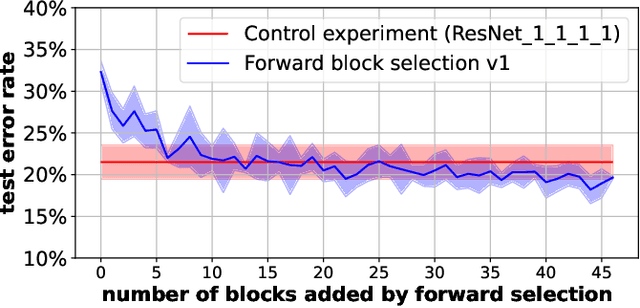
It has become mainstream in computer vision and other machine learning domains to reuse backbone networks pre-trained on large datasets as preprocessors. Typically, the last layer is replaced by a shallow learning machine of sorts; the newly-added classification head and (optionally) deeper layers are fine-tuned on a new task. Due to its strong performance and simplicity, a common pre-trained backbone network is ResNet152.However, ResNet152 is relatively large and induces inference latency. In many cases, a compact and efficient backbone with similar performance would be preferable over a larger, slower one. This paper investigates techniques to reuse a pre-trained backbone with the objective of creating a smaller and faster model. Starting from a large ResNet152 backbone pre-trained on ImageNet, we first reduce it from 51 blocks to 5 blocks, reducing its number of parameters and FLOPs by more than 6 times, without significant performance degradation. Then, we split the model after 3 blocks into several branches, while preserving the same number of parameters and FLOPs, to create an ensemble of sub-networks to improve performance. Our experiments on a large benchmark of $40$ image classification datasets from various domains suggest that our techniques match the performance (if not better) of ``classical backbone fine-tuning'' while achieving a smaller model size and faster inference speed.
VisionKG: Unleashing the Power of Visual Datasets via Knowledge Graph
Sep 24, 2023The availability of vast amounts of visual data with heterogeneous features is a key factor for developing, testing, and benchmarking of new computer vision (CV) algorithms and architectures. Most visual datasets are created and curated for specific tasks or with limited image data distribution for very specific situations, and there is no unified approach to manage and access them across diverse sources, tasks, and taxonomies. This not only creates unnecessary overheads when building robust visual recognition systems, but also introduces biases into learning systems and limits the capabilities of data-centric AI. To address these problems, we propose the Vision Knowledge Graph (VisionKG), a novel resource that interlinks, organizes and manages visual datasets via knowledge graphs and Semantic Web technologies. It can serve as a unified framework facilitating simple access and querying of state-of-the-art visual datasets, regardless of their heterogeneous formats and taxonomies. One of the key differences between our approach and existing methods is that ours is knowledge-based rather than metadatabased. It enhances the enrichment of the semantics at both image and instance levels and offers various data retrieval and exploratory services via SPARQL. VisionKG currently contains 519 million RDF triples that describe approximately 40 million entities, and are accessible at https://vision.semkg.org and through APIs. With the integration of 30 datasets and four popular CV tasks, we demonstrate its usefulness across various scenarios when working with CV pipelines.
Changes-Aware Transformer: Learning Generalized Changes Representation
Sep 24, 2023
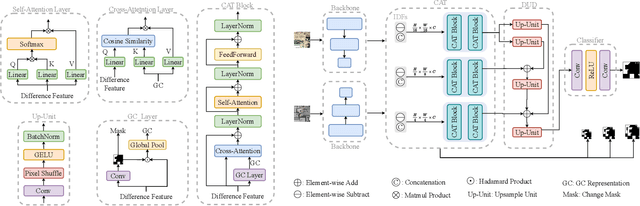


Difference features obtained by comparing the images of two periods play an indispensable role in the change detection (CD) task. However, a pair of bi-temporal images can exhibit diverse changes, which may cause various difference features. Identifying changed pixels with differ difference features to be the same category is thus a challenge for CD. Most nowadays' methods acquire distinctive difference features in implicit ways like enhancing image representation or supervision information. Nevertheless, informative image features only guarantee object semantics are modeled and can not guarantee that changed pixels have similar semantics in the difference feature space and are distinct from those unchanged ones. In this work, the generalized representation of various changes is learned straightforwardly in the difference feature space, and a novel Changes-Aware Transformer (CAT) for refining difference features is proposed. This generalized representation can perceive which pixels are changed and which are unchanged and further guide the update of pixels' difference features. CAT effectively accomplishes this refinement process through the stacked cosine cross-attention layer and self-attention layer. After refinement, the changed pixels in the difference feature space are closer to each other, which facilitates change detection. In addition, CAT is compatible with various backbone networks and existing CD methods. Experiments on remote sensing CD data set and street scene CD data set show that our method achieves state-of-the-art performance and has excellent generalization.
Assessing the capacity of a denoising diffusion probabilistic model to reproduce spatial context
Sep 19, 2023
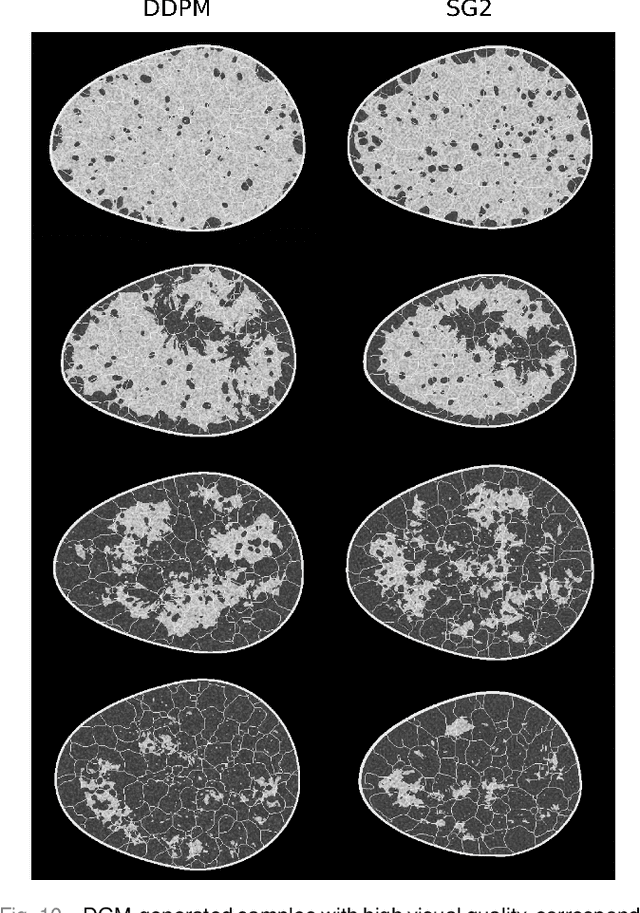
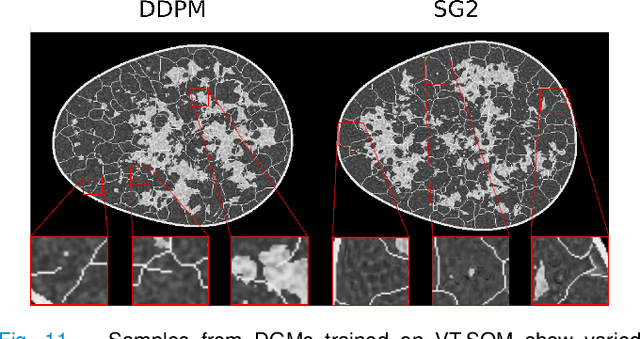

Diffusion models have emerged as a popular family of deep generative models (DGMs). In the literature, it has been claimed that one class of diffusion models -- denoising diffusion probabilistic models (DDPMs) -- demonstrate superior image synthesis performance as compared to generative adversarial networks (GANs). To date, these claims have been evaluated using either ensemble-based methods designed for natural images, or conventional measures of image quality such as structural similarity. However, there remains an important need to understand the extent to which DDPMs can reliably learn medical imaging domain-relevant information, which is referred to as `spatial context' in this work. To address this, a systematic assessment of the ability of DDPMs to learn spatial context relevant to medical imaging applications is reported for the first time. A key aspect of the studies is the use of stochastic context models (SCMs) to produce training data. In this way, the ability of the DDPMs to reliably reproduce spatial context can be quantitatively assessed by use of post-hoc image analyses. Error-rates in DDPM-generated ensembles are reported, and compared to those corresponding to a modern GAN. The studies reveal new and important insights regarding the capacity of DDPMs to learn spatial context. Notably, the results demonstrate that DDPMs hold significant capacity for generating contextually correct images that are `interpolated' between training samples, which may benefit data-augmentation tasks in ways that GANs cannot.