 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual-Camera Joint Deblurring-Denoising
Sep 16, 2023
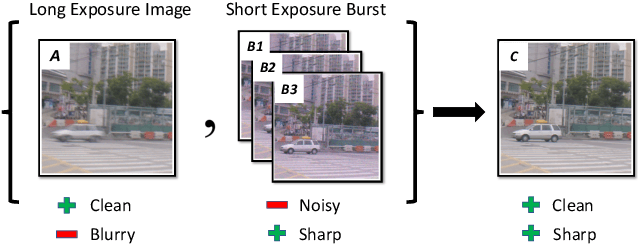
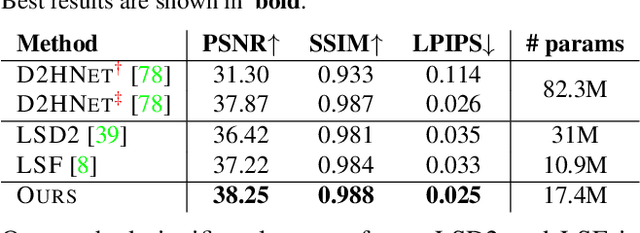
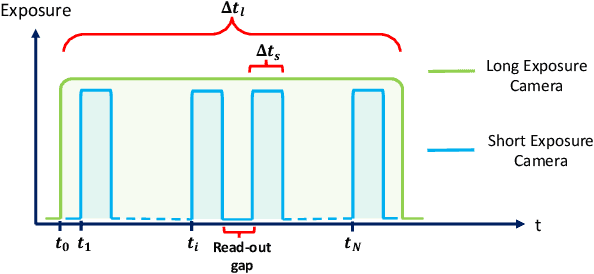
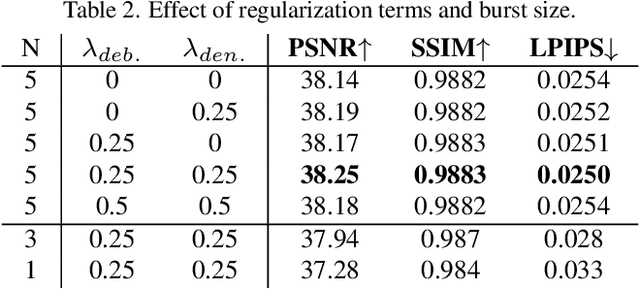
Recent image enhancement methods have shown the advantages of using a pair of long and short-exposure images for low-light photography. These image modalities offer complementary strengths and weaknesses. The former yields an image that is clean but blurry due to camera or object motion, whereas the latter is sharp but noisy due to low photon count. Motivated by the fact that modern smartphones come equipped with multiple rear-facing camera sensors, we propose a novel dual-camera method for obtaining a high-quality image. Our method uses a synchronized burst of short exposure images captured by one camera and a long exposure image simultaneously captured by another. Having a synchronized short exposure burst alongside the long exposure image enables us to (i) obtain better denoising by using a burst instead of a single image, (ii) recover motion from the burst and use it for motion-aware deblurring of the long exposure image, and (iii) fuse the two results to further enhance quality. Our method is able to achieve state-of-the-art results on synthetic dual-camera images from the GoPro dataset with five times fewer training parameters compared to the next best method. We also show that our method qualitatively outperforms competing approaches on real synchronized dual-camera captures.
BLIP-Adapter: Parameter-Efficient Transfer Learning for Mobile Screenshot Captioning
Sep 26, 2023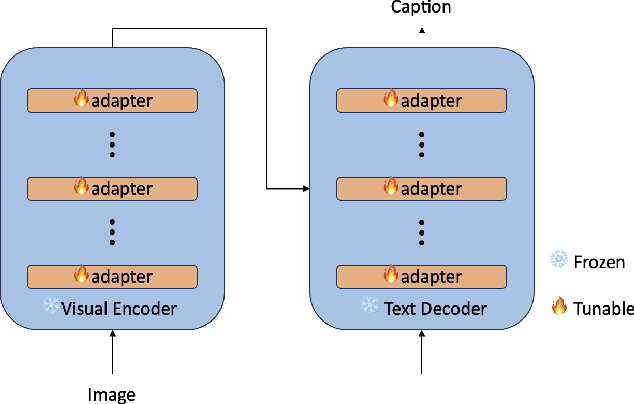
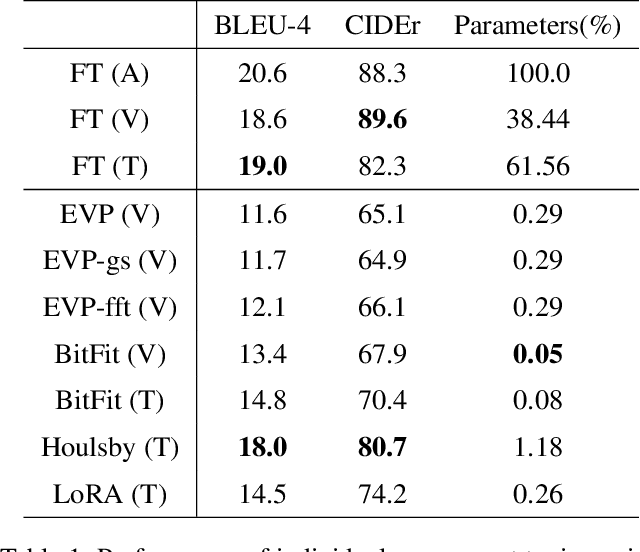
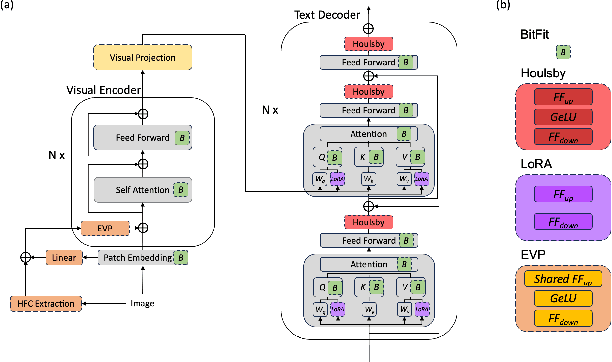
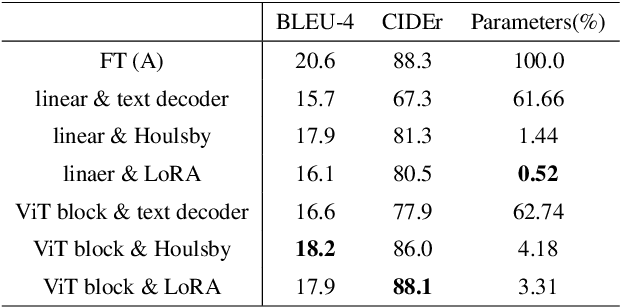
This study aims to explore efficient tuning methods for the screenshot captioning task. Recently, image captioning has seen significant advancements, but research in captioning tasks for mobile screens remains relatively scarce. Current datasets and use cases describing user behaviors within product screenshots are notably limited. Consequently, we sought to fine-tune pre-existing models for the screenshot captioning task. However, fine-tuning large pre-trained models can be resource-intensive, requiring considerable time, computational power, and storage due to the vast number of parameters in image captioning models. To tackle this challenge, this study proposes a combination of adapter methods, which necessitates tuning only the additional modules on the model. These methods are originally designed for vision or language tasks, and our intention is to apply them to address similar challenges in screenshot captioning. By freezing the parameters of the image caption models and training only the weights associated with the methods, performance comparable to fine-tuning the entire model can be achieved, while significantly reducing the number of parameters. This study represents the first comprehensive investigation into the effectiveness of combining adapters within the context of the screenshot captioning task. Through our experiments and analyses, this study aims to provide valuable insights into the application of adapters in vision-language models and contribute to the development of efficient tuning techniques for the screenshot captioning task. Our study is available at https://github.com/RainYuGG/BLIP-Adapter
A novel approach for holographic 3D content generation without depth map
Sep 26, 2023In preparation for observing holographic 3D content, acquiring a set of RGB color and depth map images per scene is necessary to generate computer-generated holograms (CGHs) when using the fast Fourier transform (FFT) algorithm. However, in real-world situations, these paired formats of RGB color and depth map images are not always fully available. We propose a deep learning-based method to synthesize the volumetric digital holograms using only the given RGB image, so that we can overcome environments where RGB color and depth map images are partially provided. The proposed method uses only the input of RGB image to estimate its depth map and then generate its CGH sequentially. Through experiments, we demonstrate that the volumetric hologram generated through our proposed model is more accurate than that of competitive models, under the situation that only RGB color data can be provided.
Text-Guided Vector Graphics Customization
Sep 21, 2023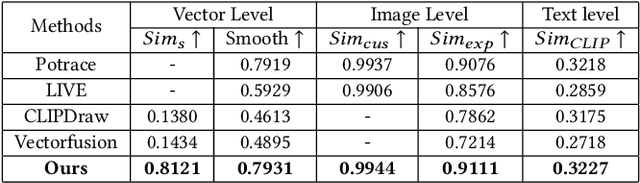
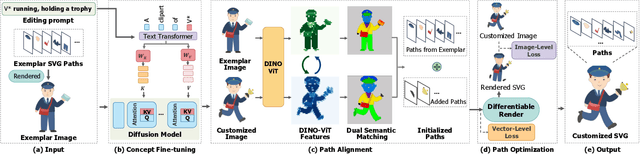
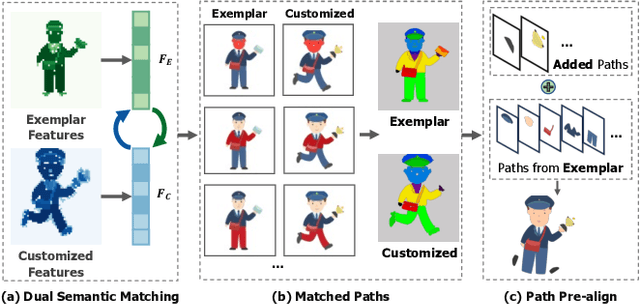
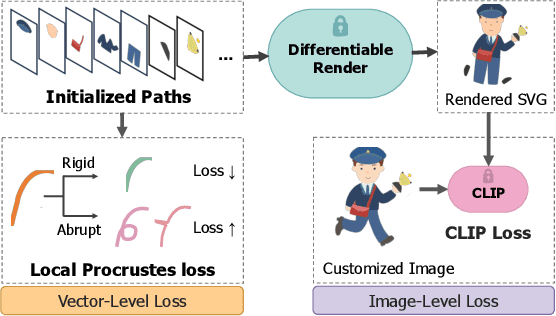
Vector graphics are widely used in digital art and valued by designers for their scalability and layer-wise topological properties. However, the creation and editing of vector graphics necessitate creativity and design expertise, leading to a time-consuming process. In this paper, we propose a novel pipeline that generates high-quality customized vector graphics based on textual prompts while preserving the properties and layer-wise information of a given exemplar SVG. Our method harnesses the capabilities of large pre-trained text-to-image models. By fine-tuning the cross-attention layers of the model, we generate customized raster images guided by textual prompts. To initialize the SVG, we introduce a semantic-based path alignment method that preserves and transforms crucial paths from the exemplar SVG. Additionally, we optimize path parameters using both image-level and vector-level losses, ensuring smooth shape deformation while aligning with the customized raster image. We extensively evaluate our method using multiple metrics from vector-level, image-level, and text-level perspectives. The evaluation results demonstrate the effectiveness of our pipeline in generating diverse customizations of vector graphics with exceptional quality. The project page is https://intchous.github.io/SVGCustomization.
DIG In: Evaluating Disparities in Image Generations with Indicators for Geographic Diversity
Aug 15, 2023
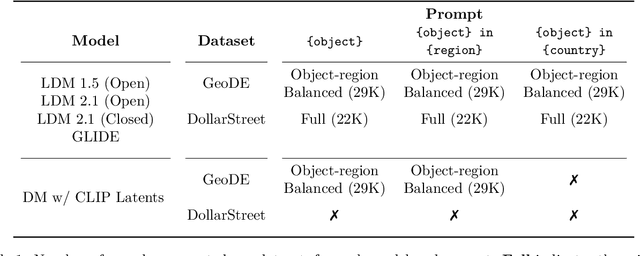


The unprecedented photorealistic results achieved by recent text-to-image generative systems and their increasing use as plug-and-play content creation solutions make it crucial to understand their potential biases. In this work, we introduce three indicators to evaluate the realism, diversity and prompt-generation consistency of text-to-image generative systems when prompted to generate objects from across the world. Our indicators complement qualitative analysis of the broader impact of such systems by enabling automatic and efficient benchmarking of geographic disparities, an important step towards building responsible visual content creation systems. We use our proposed indicators to analyze potential geographic biases in state-of-the-art visual content creation systems and find that: (1) models have less realism and diversity of generations when prompting for Africa and West Asia than Europe, (2) prompting with geographic information comes at a cost to prompt-consistency and diversity of generated images, and (3) models exhibit more region-level disparities for some objects than others. Perhaps most interestingly, our indicators suggest that progress in image generation quality has come at the cost of real-world geographic representation. Our comprehensive evaluation constitutes a crucial step towards ensuring a positive experience of visual content creation for everyone.
Privacy-Preserving Medical Image Classification through Deep Learning and Matrix Decomposition
Aug 31, 2023Deep learning (DL)-based solutions have been extensively researched in the medical domain in recent years, enhancing the efficacy of diagnosis, planning, and treatment. Since the usage of health-related data is strictly regulated, processing medical records outside the hospital environment for developing and using DL models demands robust data protection measures. At the same time, it can be challenging to guarantee that a DL solution delivers a minimum level of performance when being trained on secured data, without being specifically designed for the given task. Our approach uses singular value decomposition (SVD) and principal component analysis (PCA) to obfuscate the medical images before employing them in the DL analysis. The capability of DL algorithms to extract relevant information from secured data is assessed on a task of angiographic view classification based on obfuscated frames. The security level is probed by simulated artificial intelligence (AI)-based reconstruction attacks, considering two threat actors with different prior knowledge of the targeted data. The degree of privacy is quantitatively measured using similarity indices. Although a trade-off between privacy and accuracy should be considered, the proposed technique allows for training the angiographic view classifier exclusively on secured data with satisfactory performance and with no computational overhead, model adaptation, or hyperparameter tuning. While the obfuscated medical image content is well protected against human perception, the hypothetical reconstruction attack proved that it is also difficult to recover the complete information of the original frames.
* 6 pages, 9 figures, Published in: 2023 31st Mediterranean Conference on Control and Automation (MED)
Hierarchical Unsupervised Topological SLAM
Oct 07, 2023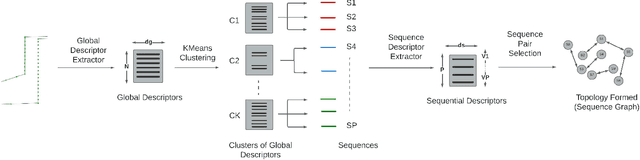
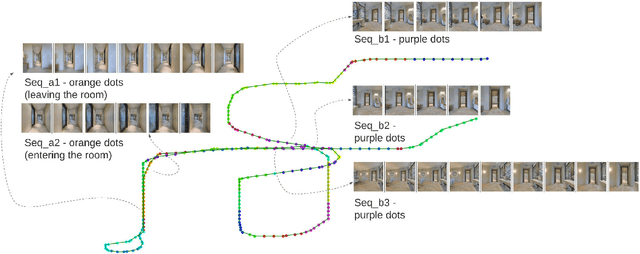
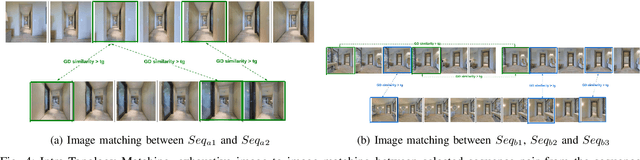

In this paper we present a novel framework for unsupervised topological clustering resulting in improved loop. In this paper we present a novel framework for unsupervised topological clustering resulting in improved loop detection and closure for SLAM. A navigating mobile robot clusters its traversal into visually similar topologies where each cluster (topology) contains a set of similar looking images typically observed from spatially adjacent locations. Each such set of spatially adjacent and visually similar grouping of images constitutes a topology obtained without any supervision. We formulate a hierarchical loop discovery strategy that first detects loops at the level of topologies and subsequently at the level of images between the looped topologies. We show over a number of traversals across different Habitat environments that such a hierarchical pipeline significantly improves SOTA image based loop detection and closure methods. Further, as a consequence of improved loop detection, we enhance the loop closure and backend SLAM performance. Such a rendering of a traversal into topological segments is beneficial for downstream tasks such as navigation that can now build a topological graph where spatially adjacent topological clusters are connected by an edge and navigate over such topological graphs.
Fourier PD and PDUNet: Complex-valued networks to speed-up MR Thermometry during Hypterthermia
Oct 02, 2023Hyperthermia (HT) in combination with radio- and/or chemotherapy has become an accepted cancer treatment for distinct solid tumour entities. In HT, tumour tissue is exogenously heated to temperatures of 39 to 43 $\degree$C for 60 minutes. Temperature monitoring can be performed noninvasively using dynamic magnetic resonance imaging (MRI). However, the slow nature of MRI leads to motion artefacts in the images due to the movements of patients during image acquisition time. By discarding parts of the data, the speed of the acquisition can be increased - known as Undersampling. However, due to the invalidation of the Nyquist criterion, the acquired images have lower resolution and can also produce artefacts. The aim of this work was, therefore, to reconstruct highly undersampled MR thermometry acquisitions with better resolution and with less artefacts compared to conventional techniques like compressed sensing. The use of deep learning in the medical field has emerged in recent times, and various studies have shown that deep learning has the potential to solve inverse problems such as MR image reconstruction. However, most of the published work only focusses on the magnitude images, while the phase images are ignored, which are fundamental requirements for MR thermometry. This work, for the first time ever, presents deep learning based solutions for reconstructing undersampled MR thermometry data. Two different deep learning models have been employed here, the Fourier Primal-Dual network and Fourier Primal-Dual UNet, to reconstruct highly undersampled complex images of MR thermometry. It was observed that the method was able to reduce the temperature difference between the undersampled MRIs and the fully sampled MRIs from 1.5 $\degree$C to 0.5 $\degree$C.
When to Learn What: Model-Adaptive Data Augmentation Curriculum
Sep 30, 2023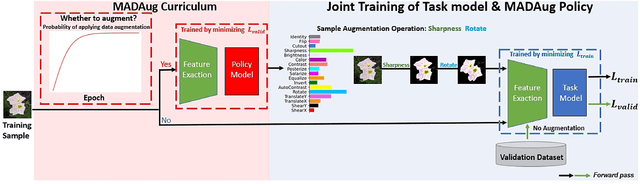
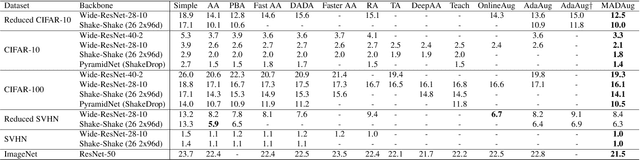
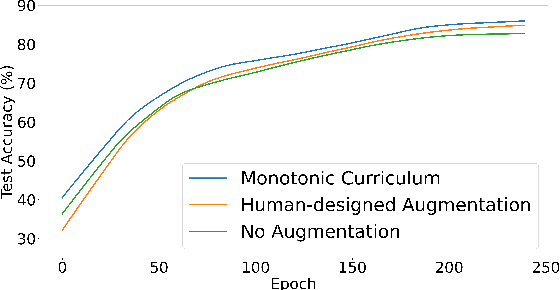

Data augmentation (DA) is widely used to improve the generalization of neural networks by enforcing the invariances and symmetries to pre-defined transformations applied to input data. However, a fixed augmentation policy may have different effects on each sample in different training stages but existing approaches cannot adjust the policy to be adaptive to each sample and the training model. In this paper, we propose Model Adaptive Data Augmentation (MADAug) that jointly trains an augmentation policy network to teach the model when to learn what. Unlike previous work, MADAug selects augmentation operators for each input image by a model-adaptive policy varying between training stages, producing a data augmentation curriculum optimized for better generalization. In MADAug, we train the policy through a bi-level optimization scheme, which aims to minimize a validation-set loss of a model trained using the policy-produced data augmentations. We conduct an extensive evaluation of MADAug on multiple image classification tasks and network architectures with thorough comparisons to existing DA approaches. MADAug outperforms or is on par with other baselines and exhibits better fairness: it brings improvement to all classes and more to the difficult ones. Moreover, MADAug learned policy shows better performance when transferred to fine-grained datasets. In addition, the auto-optimized policy in MADAug gradually introduces increasing perturbations and naturally forms an easy-to-hard curriculum.
An Anchor-Point Based Image-Model for Room Impulse Response Simulation with Directional Source Radiation and Sensor Directivity Patterns
Aug 21, 2023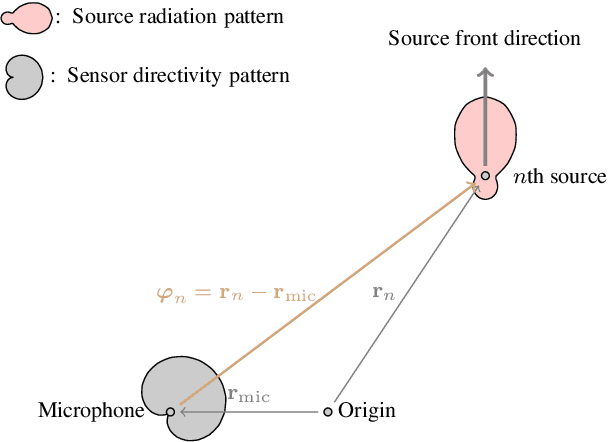

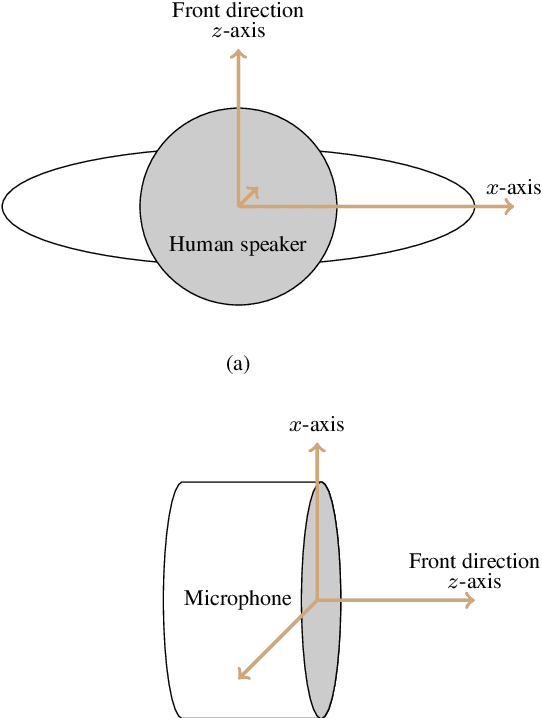
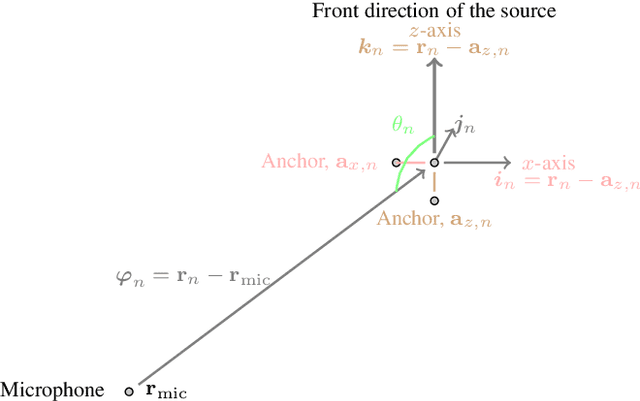
The image model method has been widely used to simulate room impulse responses and the endeavor to adapt this method to different applications has also piqued great interest over the last few decades. This paper attempts to extend the image model method and develops an anchor-point-image-model (APIM) approach as a solution for simulating impulse responses by including both the source radiation and sensor directivity patterns. To determine the orientations of all the virtual sources, anchor points are introduced to real sources, which subsequently lead to the determination of the orientations of the virtual sources. An algorithm is developed to generate room impulse responses with APIM by taking into account the directional pattern functions, factional time delays, as well as the computational complexity. The developed model and algorithms can be used in various acoustic problems to simulate room acoustics and improve and evaluate processing algorithms.