 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Can We Reliably Improve the Robustness to Image Acquisition of Remote Sensing of PV Systems?
Sep 21, 2023


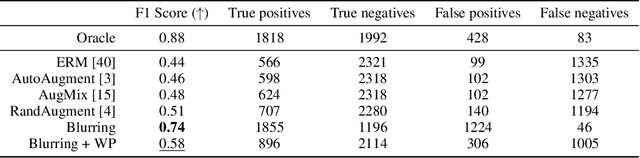

Photovoltaic (PV) energy is crucial for the decarbonization of energy systems. Due to the lack of centralized data, remote sensing of rooftop PV installations is the best option to monitor the evolution of the rooftop PV installed fleet at a regional scale. However, current techniques lack reliability and are notably sensitive to shifts in the acquisition conditions. To overcome this, we leverage the wavelet scale attribution method (WCAM), which decomposes a model's prediction in the space-scale domain. The WCAM enables us to assess on which scales the representation of a PV model rests and provides insights to derive methods that improve the robustness to acquisition conditions, thus increasing trust in deep learning systems to encourage their use for the safe integration of clean energy in electric systems.
SAM-OCTA: A Fine-Tuning Strategy for Applying Foundation Model to OCTA Image Segmentation Tasks
Sep 21, 2023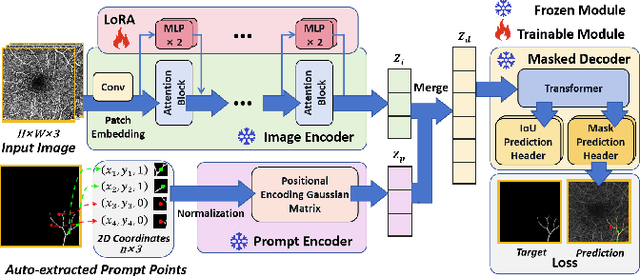
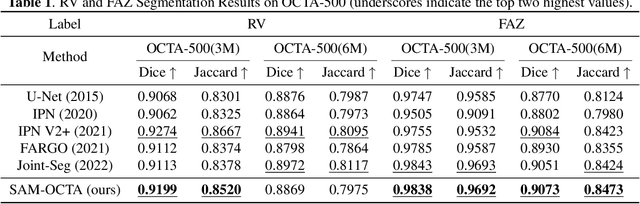
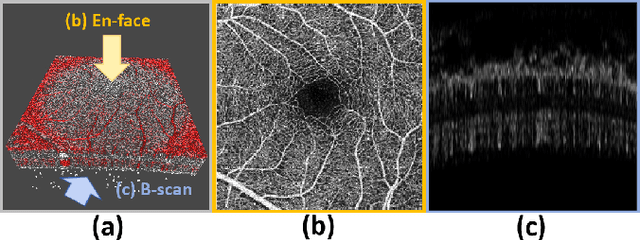
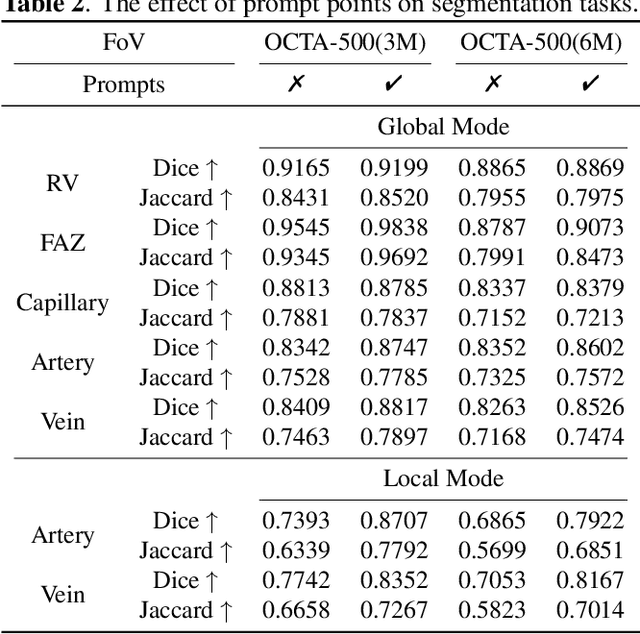
In the analysis of optical coherence tomography angiography (OCTA) images, the operation of segmenting specific targets is necessary. Existing methods typically train on supervised datasets with limited samples (approximately a few hundred), which can lead to overfitting. To address this, the low-rank adaptation technique is adopted for foundation model fine-tuning and proposed corresponding prompt point generation strategies to process various segmentation tasks on OCTA datasets. This method is named SAM-OCTA and has been experimented on the publicly available OCTA-500 dataset. While achieving state-of-the-art performance metrics, this method accomplishes local vessel segmentation as well as effective artery-vein segmentation, which was not well-solved in previous works. The code is available at: https://github.com/ShellRedia/SAM-OCTA.
TFNet: Exploiting Temporal Cues for Fast and Accurate LiDAR Semantic Segmentation
Sep 17, 2023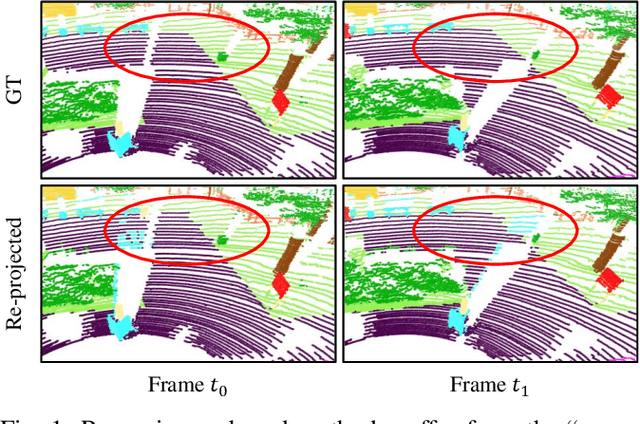
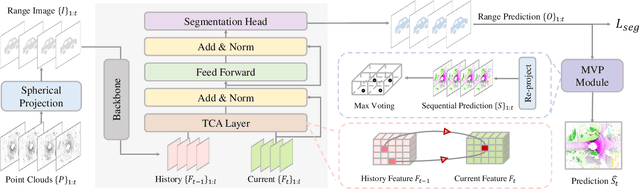
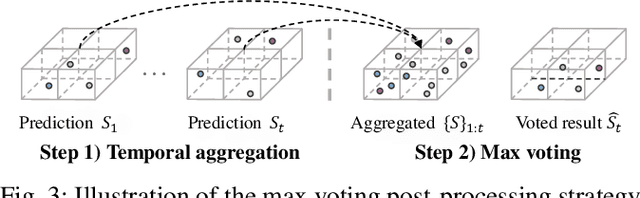
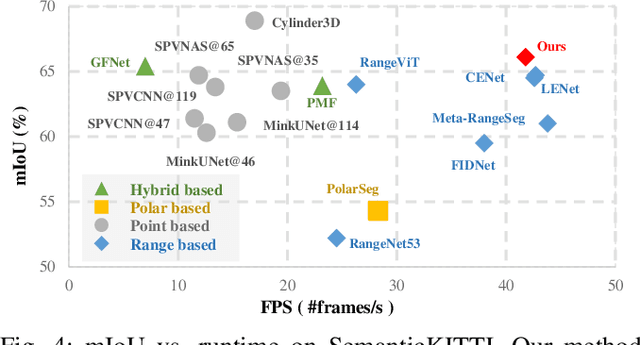
LiDAR semantic segmentation plays a crucial role in enabling autonomous driving and robots to understand their surroundings accurately and robustly. There are different types of methods, such as point-based, range-image-based, polar-based, and hybrid methods. Among these, range-image-based methods are widely used due to their efficiency. However, they face a significant challenge known as the ``many-to-one'' problem caused by the range image's limited horizontal and vertical angular resolution. As a result, around 20\% of the 3D points can be occluded. In this paper, we present TFNet, a range-image-based LiDAR semantic segmentation method that utilizes temporal information to address this issue. Specifically, we incorporate a temporal fusion layer to extract useful information from previous scans and integrate it with the current scan. We then design a max-voting-based post-processing technique to correct false predictions, particularly those caused by the ``many-to-one'' issue. We evaluated the approach on two benchmarks and demonstrate that the post-processing technique is generic and can be applied to various networks. We will release our code and models.
Light Field Diffusion for Single-View Novel View Synthesis
Sep 23, 2023Single-view novel view synthesis, the task of generating images from new viewpoints based on a single reference image, is an important but challenging task in computer vision. Recently, Denoising Diffusion Probabilistic Model (DDPM) has become popular in this area due to its strong ability to generate high-fidelity images. However, current diffusion-based methods directly rely on camera pose matrices as viewing conditions, globally and implicitly introducing 3D constraints. These methods may suffer from inconsistency among generated images from different perspectives, especially in regions with intricate textures and structures. In this work, we present Light Field Diffusion (LFD), a conditional diffusion-based model for single-view novel view synthesis. Unlike previous methods that employ camera pose matrices, LFD transforms the camera view information into light field encoding and combines it with the reference image. This design introduces local pixel-wise constraints within the diffusion models, thereby encouraging better multi-view consistency. Experiments on several datasets show that our LFD can efficiently generate high-fidelity images and maintain better 3D consistency even in intricate regions. Our method can generate images with higher quality than NeRF-based models, and we obtain sample quality similar to other diffusion-based models but with only one-third of the model size.
Class Attendance System in Education with Deep Learning Method
Sep 23, 2023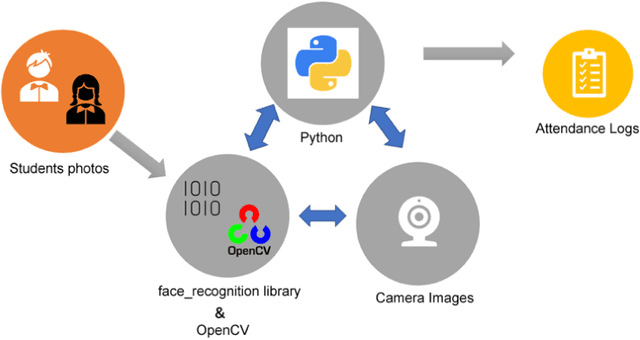
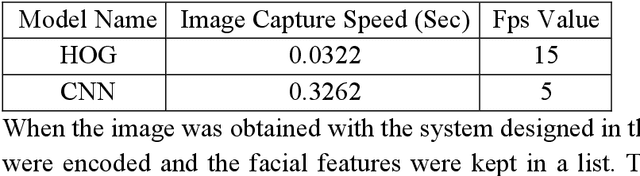

With the advancing technology, the hardware gain of computers and the increase in the processing capacity of processors have facilitated the processing of instantaneous and real-time images. Face recognition processes are also studies in the field of image processing. Facial recognition processes are frequently used in security applications and commercial applications. Especially in the last 20 years, the high performances of artificial intelligence (AI) studies have contributed to the spread of these studies in many different fields. Education is one of them. The potential and advantages of using AI in education; can be grouped under three headings: student, teacher, and institution. One of the institutional studies may be the security of educational environments and the contribution of automation to education and training processes. From this point of view, deep learning methods, one of the sub-branches of AI, were used in this study. For object detection from images, a pioneering study has been designed and successfully implemented to keep records of students' entrance to the educational institution and to perform class attendance with images taken from the camera using image processing algorithms. The application of the study to real-life problems will be carried out in a school determined in the 2022-2023 academic year.
* International LET-IN 2022 Conference Proceedings Book, October 06-08, 2022, Ankara, T\"urkiye. ISBN: 978-605-71971-1-5
Survey on Controlable Image Synthesis with Deep Learning
Jul 18, 2023Image synthesis has attracted emerging research interests in academic and industry communities. Deep learning technologies especially the generative models greatly inspired controllable image synthesis approaches and applications, which aim to generate particular visual contents with latent prompts. In order to further investigate low-level controllable image synthesis problem which is crucial for fine image rendering and editing tasks, we present a survey of some recent works on 3D controllable image synthesis using deep learning. We first introduce the datasets and evaluation indicators for 3D controllable image synthesis. Then, we review the state-of-the-art research for geometrically controllable image synthesis in two aspects: 1) Viewpoint/pose-controllable image synthesis; 2) Structure/shape-controllable image synthesis. Furthermore, the photometrically controllable image synthesis approaches are also reviewed for 3D re-lighting researches. While the emphasis is on 3D controllable image synthesis algorithms, the related applications, products and resources are also briefly summarized for practitioners.
Improving Facade Parsing with Vision Transformers and Line Integration
Oct 02, 2023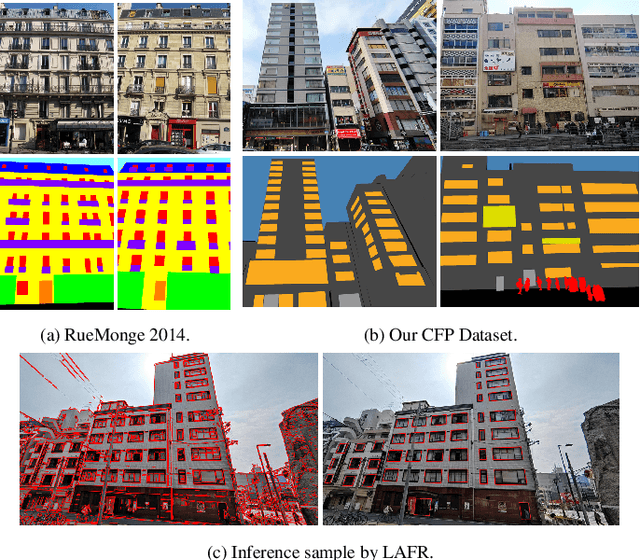
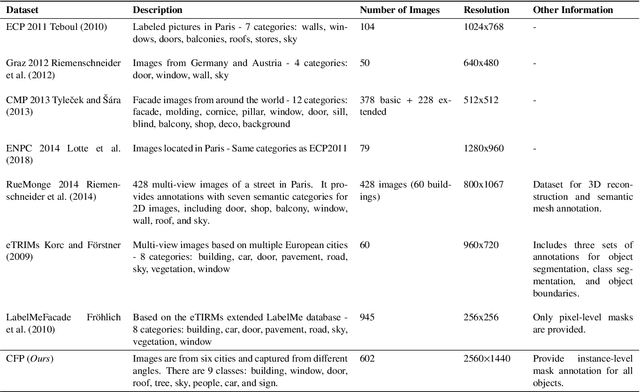

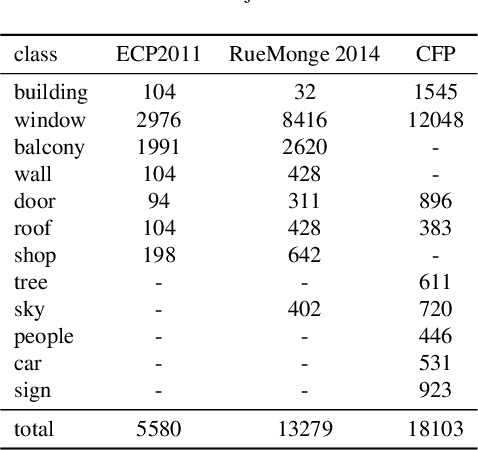
Facade parsing stands as a pivotal computer vision task with far-reaching applications in areas like architecture, urban planning, and energy efficiency. Despite the recent success of deep learning-based methods in yielding impressive results on certain open-source datasets, their viability for real-world applications remains uncertain. Real-world scenarios are considerably more intricate, demanding greater computational efficiency. Existing datasets often fall short in representing these settings, and previous methods frequently rely on extra models to enhance accuracy, which requires much computation cost. In this paper, we introduce Comprehensive Facade Parsing (CFP), a dataset meticulously designed to encompass the intricacies of real-world facade parsing tasks. Comprising a total of 602 high-resolution street-view images, this dataset captures a diverse array of challenging scenarios, including sloping angles and densely clustered buildings, with painstakingly curated annotations for each image. We introduce a new pipeline known as Revision-based Transformer Facade Parsing (RTFP). This marks the pioneering utilization of Vision Transformers (ViT) in facade parsing, and our experimental results definitively substantiate its merit. We also design Line Acquisition, Filtering, and Revision (LAFR), an efficient yet accurate revision algorithm that can improve the segment result solely from simple line detection using prior knowledge of the facade. In ECP 2011, RueMonge 2014, and our CFP, we evaluate the superiority of our method. The dataset and code are available at https://github.com/wbw520/RTFP.
RRR-Net: Reusing, Reducing, and Recycling a Deep Backbone Network
Oct 02, 2023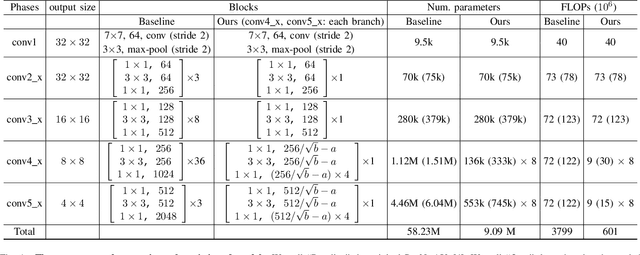
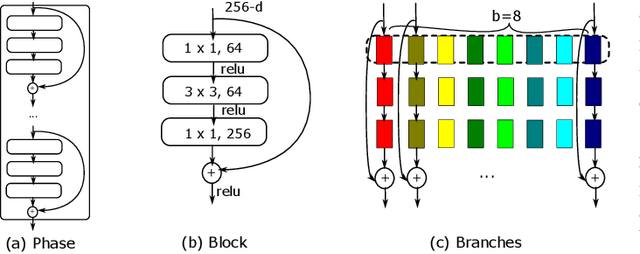
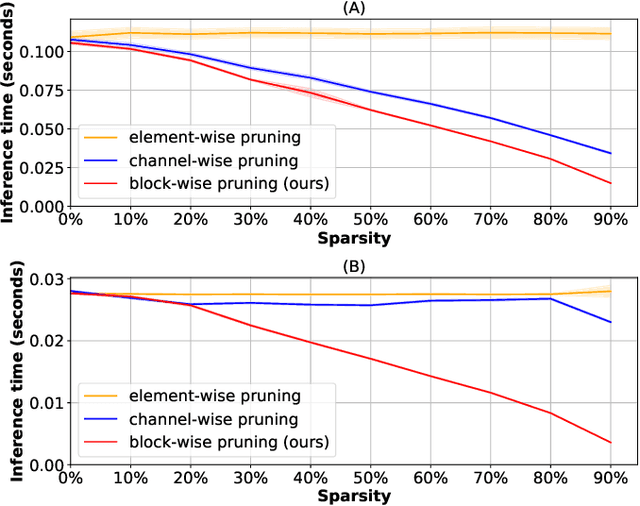
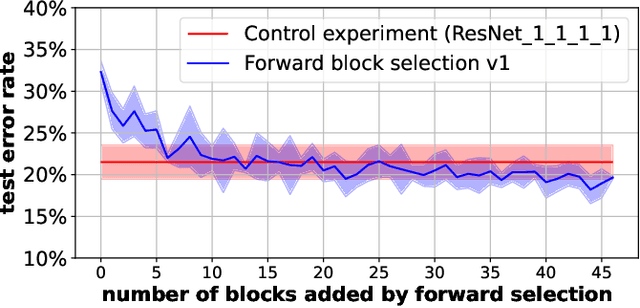
It has become mainstream in computer vision and other machine learning domains to reuse backbone networks pre-trained on large datasets as preprocessors. Typically, the last layer is replaced by a shallow learning machine of sorts; the newly-added classification head and (optionally) deeper layers are fine-tuned on a new task. Due to its strong performance and simplicity, a common pre-trained backbone network is ResNet152.However, ResNet152 is relatively large and induces inference latency. In many cases, a compact and efficient backbone with similar performance would be preferable over a larger, slower one. This paper investigates techniques to reuse a pre-trained backbone with the objective of creating a smaller and faster model. Starting from a large ResNet152 backbone pre-trained on ImageNet, we first reduce it from 51 blocks to 5 blocks, reducing its number of parameters and FLOPs by more than 6 times, without significant performance degradation. Then, we split the model after 3 blocks into several branches, while preserving the same number of parameters and FLOPs, to create an ensemble of sub-networks to improve performance. Our experiments on a large benchmark of $40$ image classification datasets from various domains suggest that our techniques match the performance (if not better) of ``classical backbone fine-tuning'' while achieving a smaller model size and faster inference speed.
LEAP: Liberate Sparse-view 3D Modeling from Camera Poses
Oct 02, 2023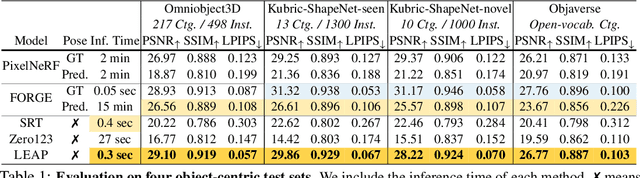
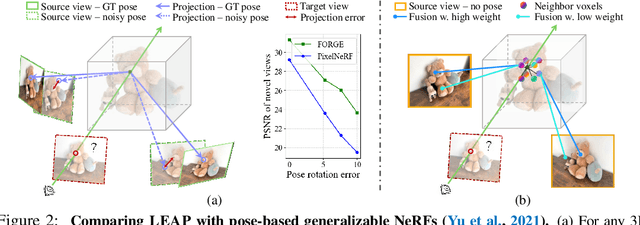
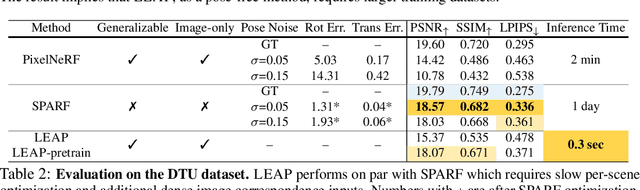
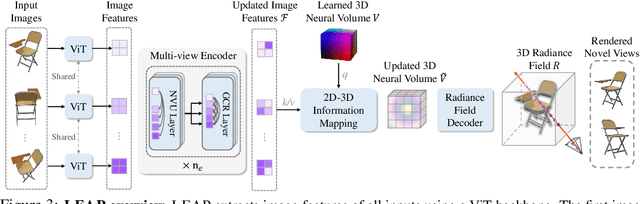
Are camera poses necessary for multi-view 3D modeling? Existing approaches predominantly assume access to accurate camera poses. While this assumption might hold for dense views, accurately estimating camera poses for sparse views is often elusive. Our analysis reveals that noisy estimated poses lead to degraded performance for existing sparse-view 3D modeling methods. To address this issue, we present LEAP, a novel pose-free approach, therefore challenging the prevailing notion that camera poses are indispensable. LEAP discards pose-based operations and learns geometric knowledge from data. LEAP is equipped with a neural volume, which is shared across scenes and is parameterized to encode geometry and texture priors. For each incoming scene, we update the neural volume by aggregating 2D image features in a feature-similarity-driven manner. The updated neural volume is decoded into the radiance field, enabling novel view synthesis from any viewpoint. On both object-centric and scene-level datasets, we show that LEAP significantly outperforms prior methods when they employ predicted poses from state-of-the-art pose estimators. Notably, LEAP performs on par with prior approaches that use ground-truth poses while running $400\times$ faster than PixelNeRF. We show LEAP generalizes to novel object categories and scenes, and learns knowledge closely resembles epipolar geometry. Project page: https://hwjiang1510.github.io/LEAP/
Towards reporting bias in visual-language datasets: bimodal augmentation by decoupling object-attribute association
Oct 02, 2023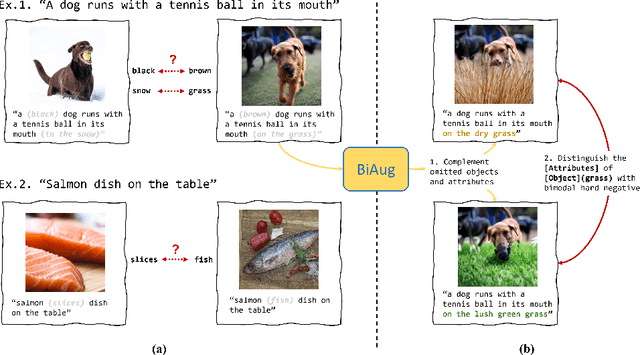
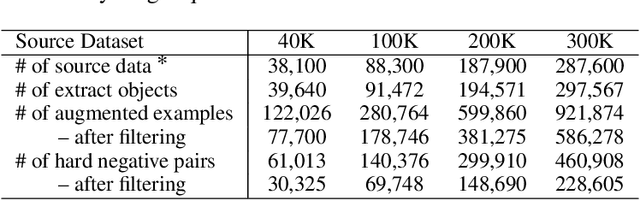
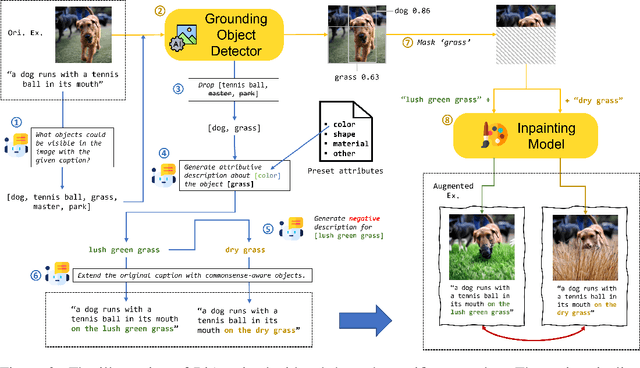
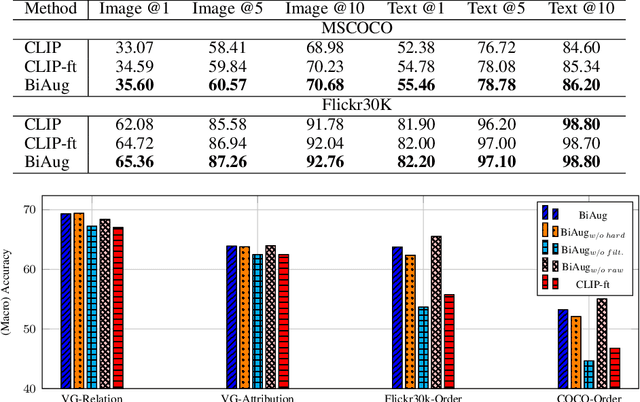
Reporting bias arises when people assume that some knowledge is universally understood and hence, do not necessitate explicit elaboration. In this paper, we focus on the wide existence of reporting bias in visual-language datasets, embodied as the object-attribute association, which can subsequentially degrade models trained on them. To mitigate this bias, we propose a bimodal augmentation (BiAug) approach through object-attribute decoupling to flexibly synthesize visual-language examples with a rich array of object-attribute pairing and construct cross-modal hard negatives. We employ large language models (LLMs) in conjunction with a grounding object detector to extract target objects. Subsequently, the LLM generates a detailed attribute description for each object and produces a corresponding hard negative counterpart. An inpainting model is then used to create images based on these detailed object descriptions. By doing so, the synthesized examples explicitly complement omitted objects and attributes to learn, and the hard negative pairs steer the model to distinguish object attributes. Our experiments demonstrated that BiAug is superior in object-attribute understanding. In addition, BiAug also improves the performance on zero-shot retrieval tasks on general benchmarks like MSCOCO and Flickr30K. BiAug refines the way of collecting text-image datasets. Mitigating the reporting bias helps models achieve a deeper understanding of visual-language phenomena, expanding beyond mere frequent patterns to encompass the richness and diversity of real-world scenarios.