 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffPrompter: Differentiable Implicit Visual Prompts for Semantic-Segmentation in Adverse Conditions
Oct 06, 2023
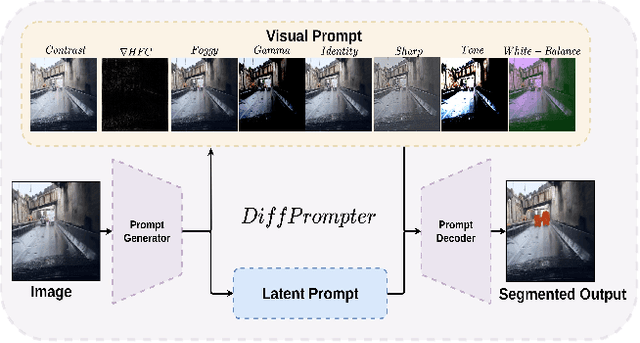
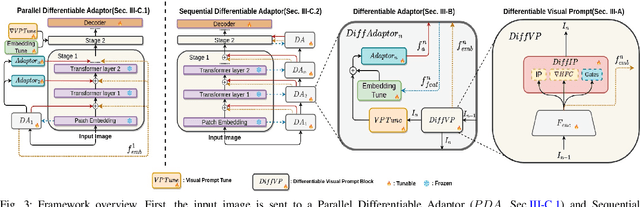
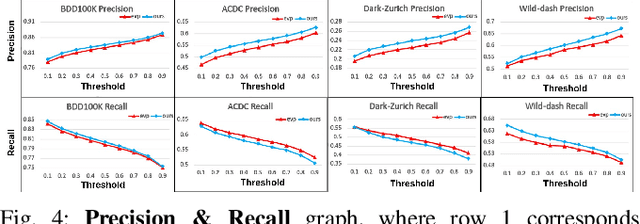

Semantic segmentation in adverse weather scenarios is a critical task for autonomous driving systems. While foundation models have shown promise, the need for specialized adaptors becomes evident for handling more challenging scenarios. We introduce DiffPrompter, a novel differentiable visual and latent prompting mechanism aimed at expanding the learning capabilities of existing adaptors in foundation models. Our proposed $\nabla$HFC image processing block excels particularly in adverse weather conditions, where conventional methods often fall short. Furthermore, we investigate the advantages of jointly training visual and latent prompts, demonstrating that this combined approach significantly enhances performance in out-of-distribution scenarios. Our differentiable visual prompts leverage parallel and series architectures to generate prompts, effectively improving object segmentation tasks in adverse conditions. Through a comprehensive series of experiments and evaluations, we provide empirical evidence to support the efficacy of our approach. Project page at https://diffprompter.github.io.
Learning Dense Flow Field for Highly-accurate Cross-view Camera Localization
Sep 27, 2023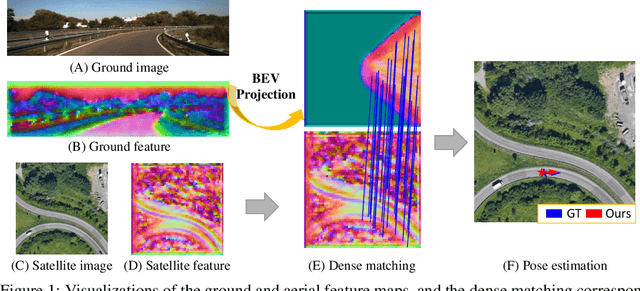
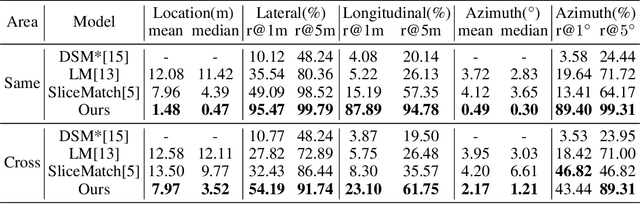
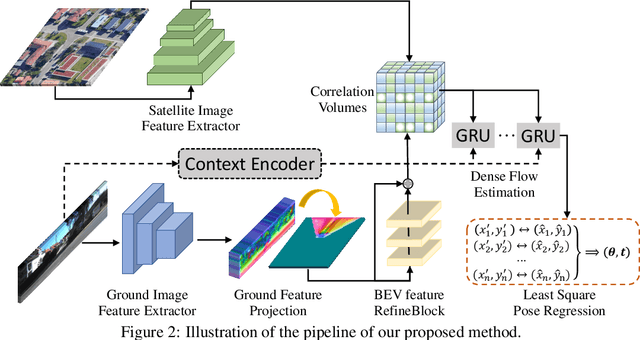
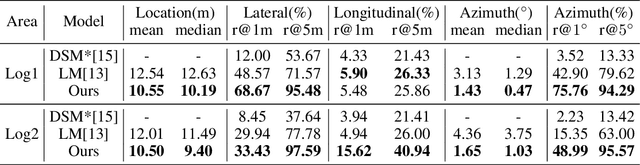
This paper addresses the problem of estimating the 3-DoF camera pose for a ground-level image with respect to a satellite image that encompasses the local surroundings. We propose a novel end-to-end approach that leverages the learning of dense pixel-wise flow fields in pairs of ground and satellite images to calculate the camera pose. Our approach differs from existing methods by constructing the feature metric at the pixel level, enabling full-image supervision for learning distinctive geometric configurations and visual appearances across views. Specifically, our method employs two distinct convolution networks for ground and satellite feature extraction. Then, we project the ground feature map to the bird's eye view (BEV) using a fixed camera height assumption to achieve preliminary geometric alignment. To further establish content association between the BEV and satellite features, we introduce a residual convolution block to refine the projected BEV feature. Optical flow estimation is performed on the refined BEV feature map and the satellite feature map using flow decoder networks based on RAFT. After obtaining dense flow correspondences, we apply the least square method to filter matching inliers and regress the ground camera pose. Extensive experiments demonstrate significant improvements compared to state-of-the-art methods. Notably, our approach reduces the median localization error by 89%, 19%, 80% and 35% on the KITTI, Ford multi-AV, VIGOR and Oxford RobotCar datasets, respectively.
Enabling Neural Radiance Fields (NeRF) for Large-scale Aerial Images -- A Multi-tiling Approaching and the Geometry Assessment of NeRF
Oct 01, 2023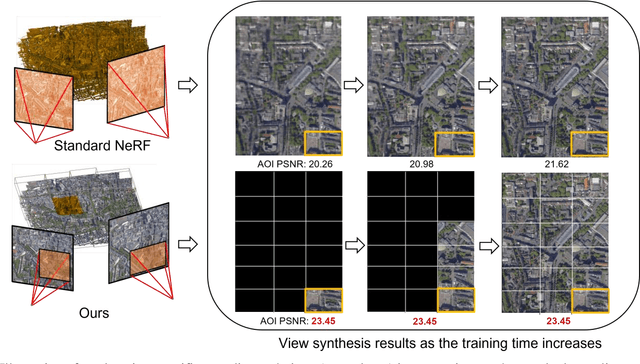

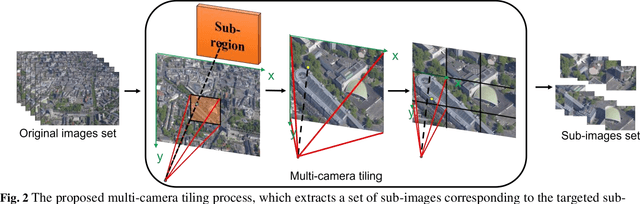

Neural Radiance Fields (NeRF) offer the potential to benefit 3D reconstruction tasks, including aerial photogrammetry. However, the scalability and accuracy of the inferred geometry are not well-documented for large-scale aerial assets,since such datasets usually result in very high memory consumption and slow convergence.. In this paper, we aim to scale the NeRF on large-scael aerial datasets and provide a thorough geometry assessment of NeRF. Specifically, we introduce a location-specific sampling technique as well as a multi-camera tiling (MCT) strategy to reduce memory consumption during image loading for RAM, representation training for GPU memory, and increase the convergence rate within tiles. MCT decomposes a large-frame image into multiple tiled images with different camera models, allowing these small-frame images to be fed into the training process as needed for specific locations without a loss of accuracy. We implement our method on a representative approach, Mip-NeRF, and compare its geometry performance with threephotgrammetric MVS pipelines on two typical aerial datasets against LiDAR reference data. Both qualitative and quantitative results suggest that the proposed NeRF approach produces better completeness and object details than traditional approaches, although as of now, it still falls short in terms of accuracy.
RetSeg: Retention-based Colorectal Polyps Segmentation Network
Oct 10, 2023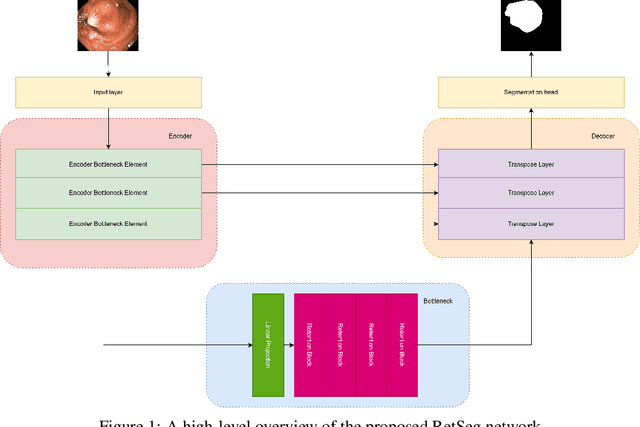
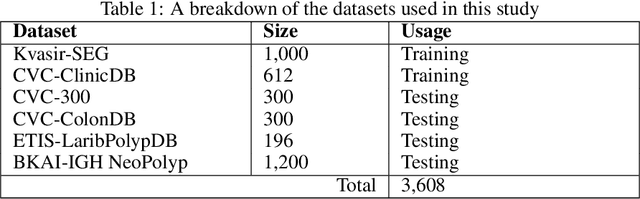
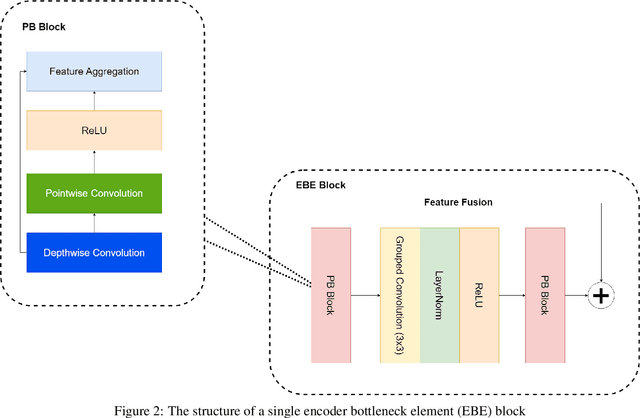
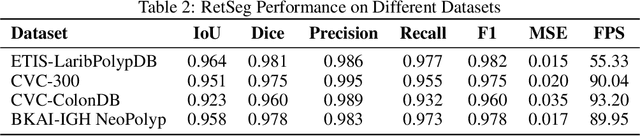
Vision Transformers (ViTs) have revolutionized medical imaging analysis, showcasing superior efficacy compared to conventional Convolutional Neural Networks (CNNs) in vital tasks such as polyp classification, detection, and segmentation. Leveraging attention mechanisms to focus on specific image regions, ViTs exhibit contextual awareness in processing visual data, culminating in robust and precise predictions, even for intricate medical images. Moreover, the inherent self-attention mechanism in Transformers accommodates varying input sizes and resolutions, granting an unprecedented flexibility absent in traditional CNNs. However, Transformers grapple with challenges like excessive memory usage and limited training parallelism due to self-attention, rendering them impractical for real-time disease detection on resource-constrained devices. In this study, we address these hurdles by investigating the integration of the recently introduced retention mechanism into polyp segmentation, introducing RetSeg, an encoder-decoder network featuring multi-head retention blocks. Drawing inspiration from Retentive Networks (RetNet), RetSeg is designed to bridge the gap between precise polyp segmentation and resource utilization, particularly tailored for colonoscopy images. We train and validate RetSeg for polyp segmentation employing two publicly available datasets: Kvasir-SEG and CVC-ClinicDB. Additionally, we showcase RetSeg's promising performance across diverse public datasets, including CVC-ColonDB, ETIS-LaribPolypDB, CVC-300, and BKAI-IGH NeoPolyp. While our work represents an early-stage exploration, further in-depth studies are imperative to advance these promising findings.
Efficient Adaptation of Large Vision Transformer via Adapter Re-Composing
Oct 10, 2023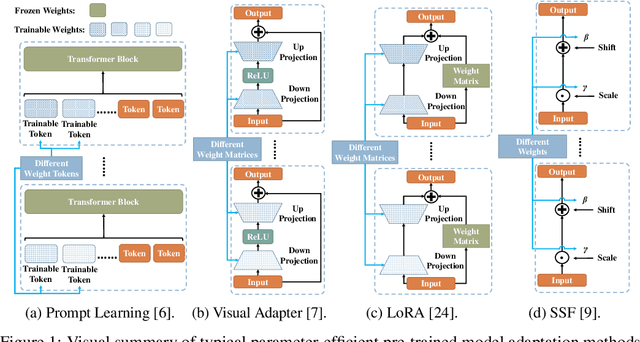
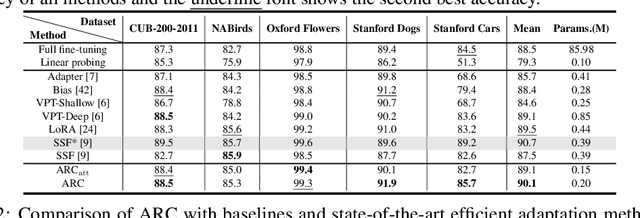
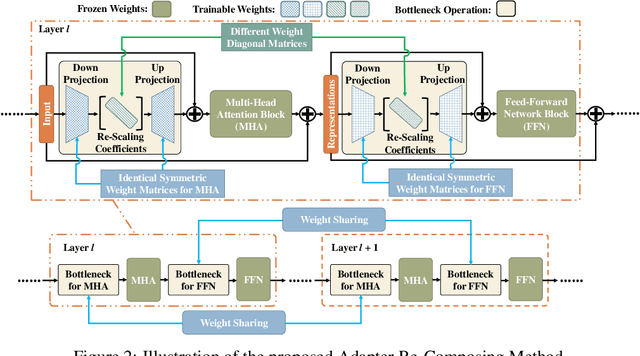
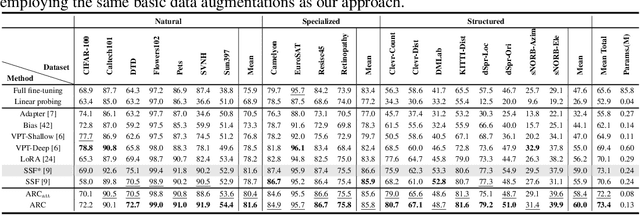
The advent of high-capacity pre-trained models has revolutionized problem-solving in computer vision, shifting the focus from training task-specific models to adapting pre-trained models. Consequently, effectively adapting large pre-trained models to downstream tasks in an efficient manner has become a prominent research area. Existing solutions primarily concentrate on designing lightweight adapters and their interaction with pre-trained models, with the goal of minimizing the number of parameters requiring updates. In this study, we propose a novel Adapter Re-Composing (ARC) strategy that addresses efficient pre-trained model adaptation from a fresh perspective. Our approach considers the reusability of adaptation parameters and introduces a parameter-sharing scheme. Specifically, we leverage symmetric down-/up-projections to construct bottleneck operations, which are shared across layers. By learning low-dimensional re-scaling coefficients, we can effectively re-compose layer-adaptive adapters. This parameter-sharing strategy in adapter design allows us to significantly reduce the number of new parameters while maintaining satisfactory performance, thereby offering a promising approach to compress the adaptation cost. We conduct experiments on 24 downstream image classification tasks using various Vision Transformer variants to evaluate our method. The results demonstrate that our approach achieves compelling transfer learning performance with a reduced parameter count. Our code is available at \href{https://github.com/DavidYanAnDe/ARC}{https://github.com/DavidYanAnDe/ARC}.
Soft Mixture Denoising: Beyond the Expressive Bottleneck of Diffusion Models
Sep 28, 2023Because diffusion models have shown impressive performances in a number of tasks, such as image synthesis, there is a trend in recent works to prove (with certain assumptions) that these models have strong approximation capabilities. In this paper, we show that current diffusion models actually have an expressive bottleneck in backward denoising and some assumption made by existing theoretical guarantees is too strong. Based on this finding, we prove that diffusion models have unbounded errors in both local and global denoising. In light of our theoretical studies, we introduce soft mixture denoising (SMD), an expressive and efficient model for backward denoising. SMD not only permits diffusion models to well approximate any Gaussian mixture distributions in theory, but also is simple and efficient for implementation. Our experiments on multiple image datasets show that SMD significantly improves different types of diffusion models (e.g., DDPM), espeically in the situation of few backward iterations.
Domain-Controlled Prompt Learning
Sep 30, 2023Large pre-trained vision-language models, such as CLIP, have shown remarkable generalization capabilities across various tasks when appropriate text prompts are provided. However, adapting these models to specialized domains, like remote sensing images (RSIs), medical images, etc, remains unexplored and challenging. Existing prompt learning methods often lack domain-awareness or domain-transfer mechanisms, leading to suboptimal performance due to the misinterpretation of specialized images in natural image patterns. To tackle this dilemma, we proposed a Domain-Controlled Prompt Learning for the specialized domains. Specifically, the large-scale specialized domain foundation model (LSDM) is first introduced to provide essential specialized domain knowledge. Using lightweight neural networks, we transfer this knowledge into domain biases, which control both the visual and language branches to obtain domain-adaptive prompts in a directly incorporating manner. Simultaneously, to overcome the existing overfitting challenge, we propose a novel noisy-adding strategy, without extra trainable parameters, to help the model escape the suboptimal solution in a global domain oscillation manner. Experimental results show our method achieves state-of-the-art performance in specialized domain image recognition datasets. Our code is available at https://anonymous.4open.science/r/DCPL-8588.
End-to-End Optimization of JPEG-Based Deep Learning Process for Image Classification
Aug 10, 2023
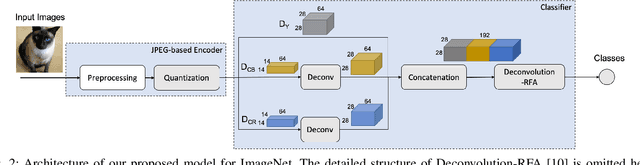
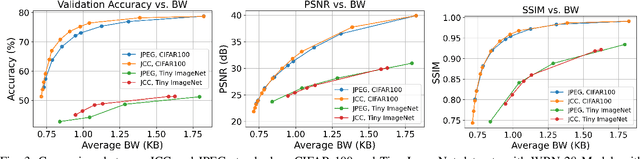
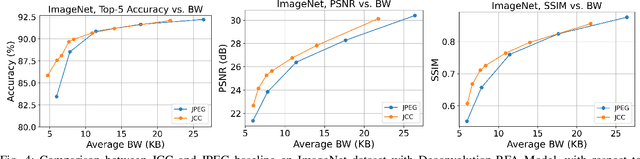
Among major deep learning (DL) applications, distributed learning involving image classification require effective image compression codecs deployed on low-cost sensing devices for efficient transmission and storage. Traditional codecs such as JPEG designed for perceptual quality are not configured for DL tasks. This work introduces an integrative end-to-end trainable model for image compression and classification consisting of a JPEG image codec and a DL-based classifier. We demonstrate how this model can optimize the widely deployed JPEG codec settings to improve classification accuracy in consideration of bandwidth constraint. Our tests on CIFAR-100 and ImageNet also demonstrate improved validation accuracy over preset JPEG configuration.
DLSIA: Deep Learning for Scientific Image Analysis
Aug 02, 2023We introduce DLSIA (Deep Learning for Scientific Image Analysis), a Python-based machine learning library that empowers scientists and researchers across diverse scientific domains with a range of customizable convolutional neural network (CNN) architectures for a wide variety of tasks in image analysis to be used in downstream data processing, or for experiment-in-the-loop computing scenarios. DLSIA features easy-to-use architectures such as autoencoders, tunable U-Nets, and parameter-lean mixed-scale dense networks (MSDNets). Additionally, we introduce sparse mixed-scale networks (SMSNets), generated using random graphs and sparse connections. As experimental data continues to grow in scale and complexity, DLSIA provides accessible CNN construction and abstracts CNN complexities, allowing scientists to tailor their machine learning approaches, accelerate discoveries, foster interdisciplinary collaboration, and advance research in scientific image analysis.
Posterior Sampling Based on Gradient Flows of the MMD with Negative Distance Kernel
Oct 04, 2023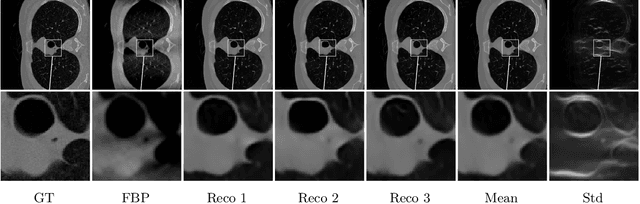



We propose conditional flows of the maximum mean discrepancy (MMD) with the negative distance kernel for posterior sampling and conditional generative modeling. This MMD, which is also known as energy distance, has several advantageous properties like efficient computation via slicing and sorting. We approximate the joint distribution of the ground truth and the observations using discrete Wasserstein gradient flows and establish an error bound for the posterior distributions. Further, we prove that our particle flow is indeed a Wasserstein gradient flow of an appropriate functional. The power of our method is demonstrated by numerical examples including conditional image generation and inverse problems like superresolution, inpainting and computed tomography in low-dose and limited-angle settings.