 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Locality-Aware Generalizable Implicit Neural Representation}
Oct 09, 2023
Generalizable implicit neural representation (INR) enables a single continuous function, i.e., a coordinate-based neural network, to represent multiple data instances by modulating its weights or intermediate features using latent codes. However, the expressive power of the state-of-the-art modulation is limited due to its inability to localize and capture fine-grained details of data entities such as specific pixels and rays. To address this issue, we propose a novel framework for generalizable INR that combines a transformer encoder with a locality-aware INR decoder. The transformer encoder predicts a set of latent tokens from a data instance to encode local information into each latent token. The locality-aware INR decoder extracts a modulation vector by selectively aggregating the latent tokens via cross-attention for a coordinate input and then predicts the output by progressively decoding with coarse-to-fine modulation through multiple frequency bandwidths. The selective token aggregation and the multi-band feature modulation enable us to learn locality-aware representation in spatial and spectral aspects, respectively. Our framework significantly outperforms previous generalizable INRs and validates the usefulness of the locality-aware latents for downstream tasks such as image generation.
Longitudinal Volumetric Study for the Progression of Alzheimer's Disease from Structural MR Images
Oct 09, 2023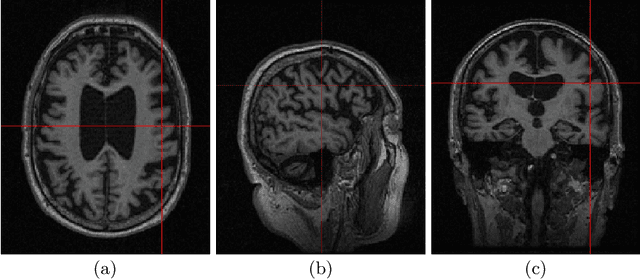

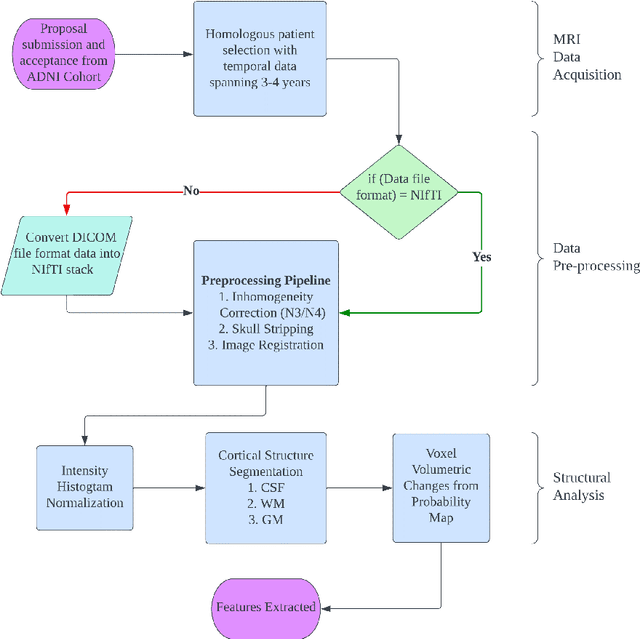
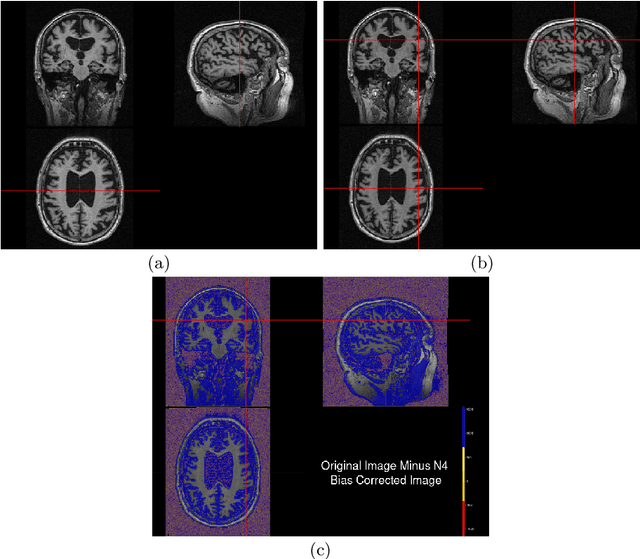
Alzheimer's Disease (AD) is primarily an irreversible neurodegenerative disorder affecting millions of individuals today. The prognosis of the disease solely depends on treating symptoms as they arise and proper caregiving, as there are no current medical preventative treatments. For this purpose, early detection of the disease at its most premature state is of paramount importance. This work aims to survey imaging biomarkers corresponding to the progression of Alzheimer's Disease (AD). A longitudinal study of structural MR images was performed for given temporal test subjects selected randomly from the Alzheimer's Disease Neuroimaging Initiative (ADNI) database. The pipeline implemented includes modern pre-processing techniques such as spatial image registration, skull stripping, and inhomogeneity correction. The temporal data across multiple visits spanning several years helped identify the structural change in the form of volumes of cerebrospinal fluid (CSF), grey matter (GM), and white matter (WM) as the patients progressed further into the disease. Tissue classes are segmented using an unsupervised learning approach using intensity histogram information. The segmented features thus extracted provide insights such as atrophy, increase or intolerable shifting of GM, WM and CSF and should help in future research for automated analysis of Alzheimer's detection with clinical domain explainability.
Unleashing the Power of Self-Supervised Image Denoising: A Comprehensive Review
Aug 09, 2023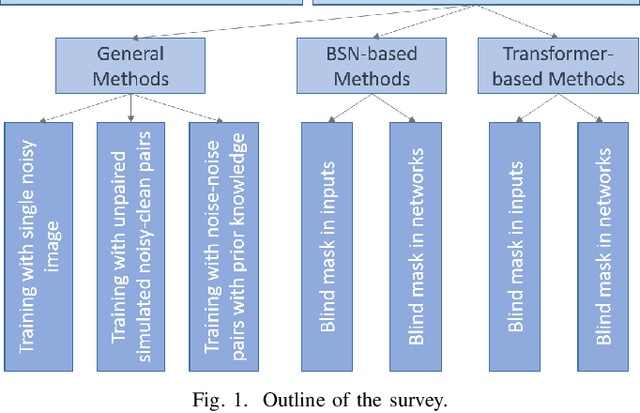

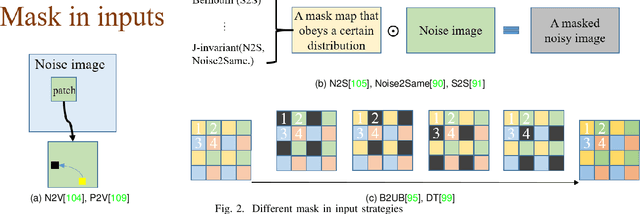
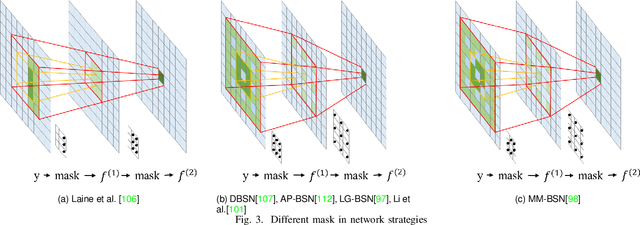
The advent of deep learning has brought a revolutionary transformation to image denoising techniques. However, the persistent challenge of acquiring noise-clean pairs for supervised methods in real-world scenarios remains formidable, necessitating the exploration of more practical self-supervised image denoising. This paper focuses on self-supervised image denoising methods that offer effective solutions to address this challenge. Our comprehensive review thoroughly analyzes the latest advancements in self-supervised image denoising approaches, categorizing them into three distinct classes: General methods, Blind Spot Network (BSN)-based methods, and Transformer-based methods. For each class, we provide a concise theoretical analysis along with their practical applications. To assess the effectiveness of these methods, we present both quantitative and qualitative experimental results on various datasets, utilizing classical algorithms as benchmarks. Additionally, we critically discuss the current limitations of these methods and propose promising directions for future research. By offering a detailed overview of recent developments in self-supervised image denoising, this review serves as an invaluable resource for researchers and practitioners in the field, facilitating a deeper understanding of this emerging domain and inspiring further advancements.
Dual Aggregation Transformer for Image Super-Resolution
Aug 11, 2023
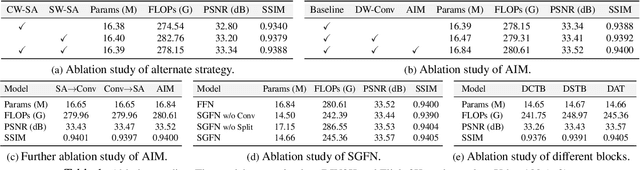
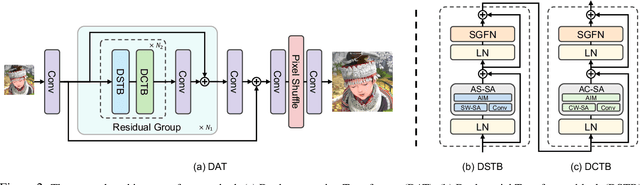
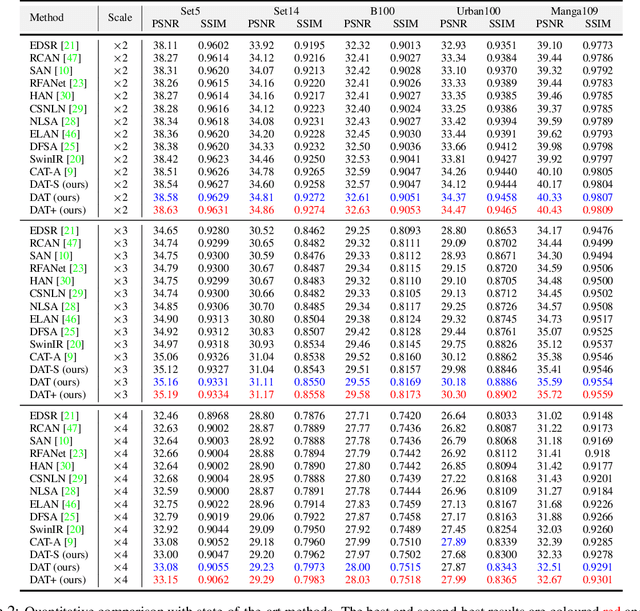
Transformer has recently gained considerable popularity in low-level vision tasks, including image super-resolution (SR). These networks utilize self-attention along different dimensions, spatial or channel, and achieve impressive performance. This inspires us to combine the two dimensions in Transformer for a more powerful representation capability. Based on the above idea, we propose a novel Transformer model, Dual Aggregation Transformer (DAT), for image SR. Our DAT aggregates features across spatial and channel dimensions, in the inter-block and intra-block dual manner. Specifically, we alternately apply spatial and channel self-attention in consecutive Transformer blocks. The alternate strategy enables DAT to capture the global context and realize inter-block feature aggregation. Furthermore, we propose the adaptive interaction module (AIM) and the spatial-gate feed-forward network (SGFN) to achieve intra-block feature aggregation. AIM complements two self-attention mechanisms from corresponding dimensions. Meanwhile, SGFN introduces additional non-linear spatial information in the feed-forward network. Extensive experiments show that our DAT surpasses current methods. Code and models are obtainable at https://github.com/zhengchen1999/DAT.
DOMINO: A Dual-System for Multi-step Visual Language Reasoning
Oct 04, 2023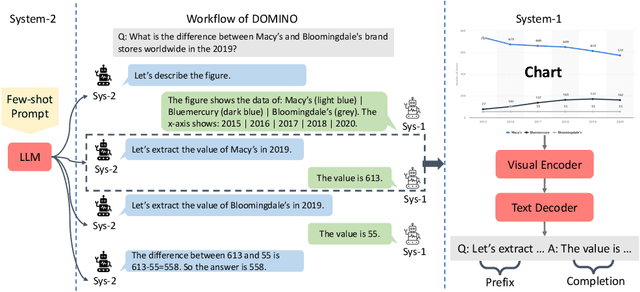
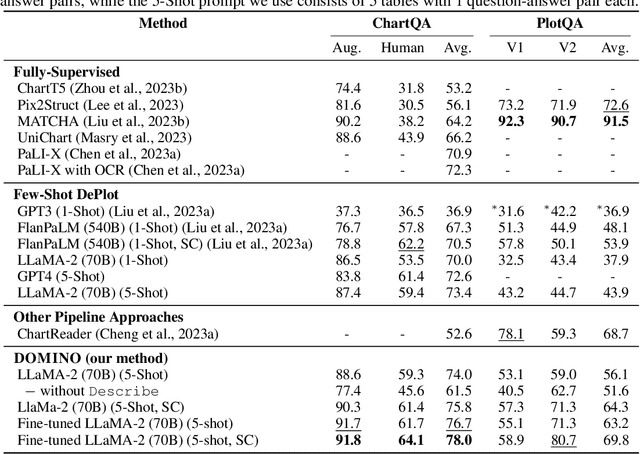
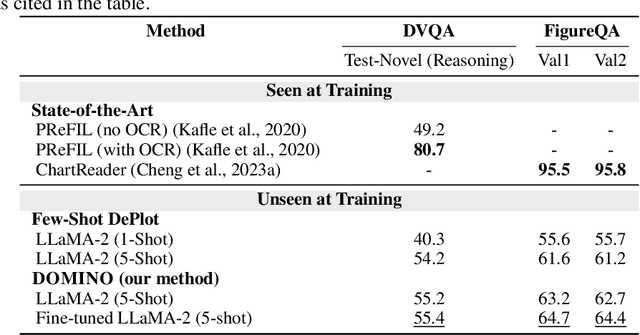
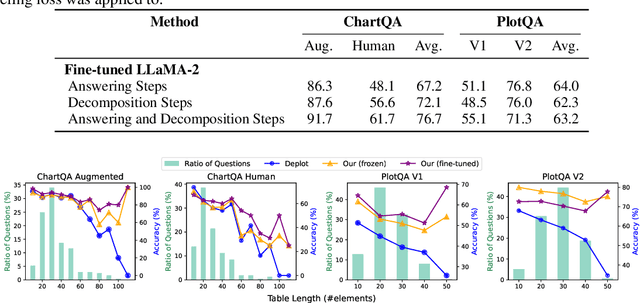
Visual language reasoning requires a system to extract text or numbers from information-dense images like charts or plots and perform logical or arithmetic reasoning to arrive at an answer. To tackle this task, existing work relies on either (1) an end-to-end vision-language model trained on a large amount of data, or (2) a two-stage pipeline where a captioning model converts the image into text that is further read by another large language model to deduce the answer. However, the former approach forces the model to answer a complex question with one single step, and the latter approach is prone to inaccurate or distracting information in the converted text that can confuse the language model. In this work, we propose a dual-system for multi-step multimodal reasoning, which consists of a "System-1" step for visual information extraction and a "System-2" step for deliberate reasoning. Given an input, System-2 breaks down the question into atomic sub-steps, each guiding System-1 to extract the information required for reasoning from the image. Experiments on chart and plot datasets show that our method with a pre-trained System-2 module performs competitively compared to prior work on in- and out-of-distribution data. By fine-tuning the System-2 module (LLaMA-2 70B) on only a small amount of data on multi-step reasoning, the accuracy of our method is further improved and surpasses the best fully-supervised end-to-end approach by 5.7% and a pipeline approach with FlanPaLM (540B) by 7.5% on a challenging dataset with human-authored questions.
Land-cover change detection using paired OpenStreetMap data and optical high-resolution imagery via object-guided Transformer
Oct 04, 2023
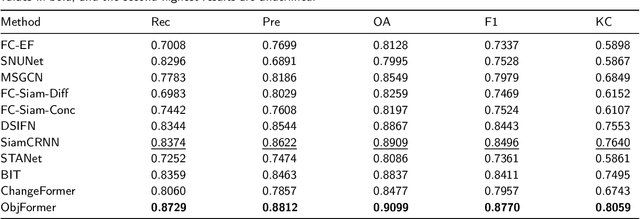
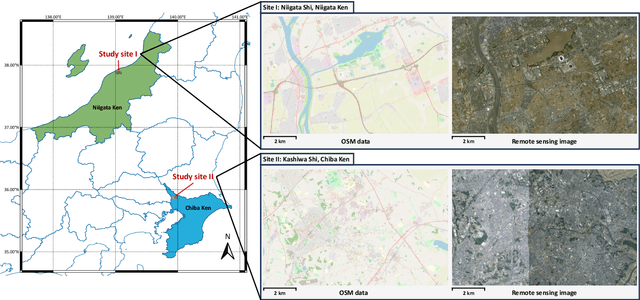
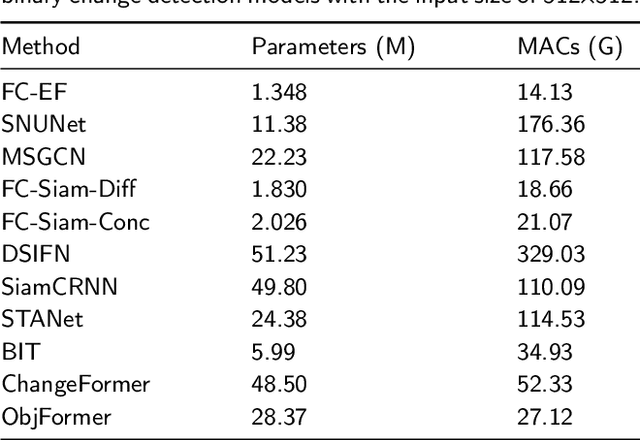
Optical high-resolution imagery and OpenStreetMap (OSM) data are two important data sources for land-cover change detection. Previous studies in these two data sources focus on utilizing the information in OSM data to aid the change detection on multi-temporal optical high-resolution images. This paper pioneers the direct detection of land-cover changes utilizing paired OSM data and optical imagery, thereby broadening the horizons of change detection tasks to encompass more dynamic earth observations. To this end, we propose an object-guided Transformer (ObjFormer) architecture by naturally combining the prevalent object-based image analysis (OBIA) technique with the advanced vision Transformer architecture. The introduction of OBIA can significantly reduce the computational overhead and memory burden in the self-attention module. Specifically, the proposed ObjFormer has a hierarchical pseudo-siamese encoder consisting of object-guided self-attention modules that extract representative features of different levels from OSM data and optical images; a decoder consisting of object-guided cross-attention modules can progressively recover the land-cover changes from the extracted heterogeneous features. In addition to the basic supervised binary change detection task, this paper raises a new semi-supervised semantic change detection task that does not require any manually annotated land-cover labels of optical images to train semantic change detectors. Two lightweight semantic decoders are added to ObjFormer to accomplish this task efficiently. A converse cross-entropy loss is designed to fully utilize the negative samples, thereby contributing to the great performance improvement in this task. The first large-scale benchmark dataset containing 1,287 map-image pairs (1024$\times$ 1024 pixels for each sample) covering 40 regions on six continents ...(see the manuscript for the full abstract)
Gradpaint: Gradient-Guided Inpainting with Diffusion Models
Sep 18, 2023Denoising Diffusion Probabilistic Models (DDPMs) have recently achieved remarkable results in conditional and unconditional image generation. The pre-trained models can be adapted without further training to different downstream tasks, by guiding their iterative denoising process at inference time to satisfy additional constraints. For the specific task of image inpainting, the current guiding mechanism relies on copying-and-pasting the known regions from the input image at each denoising step. However, diffusion models are strongly conditioned by the initial random noise, and therefore struggle to harmonize predictions inside the inpainting mask with the real parts of the input image, often producing results with unnatural artifacts. Our method, dubbed GradPaint, steers the generation towards a globally coherent image. At each step in the denoising process, we leverage the model's "denoised image estimation" by calculating a custom loss measuring its coherence with the masked input image. Our guiding mechanism uses the gradient obtained from backpropagating this loss through the diffusion model itself. GradPaint generalizes well to diffusion models trained on various datasets, improving upon current state-of-the-art supervised and unsupervised methods.
Improved YOLOv8 Detection Algorithm in Security Inspection Image
Aug 15, 2023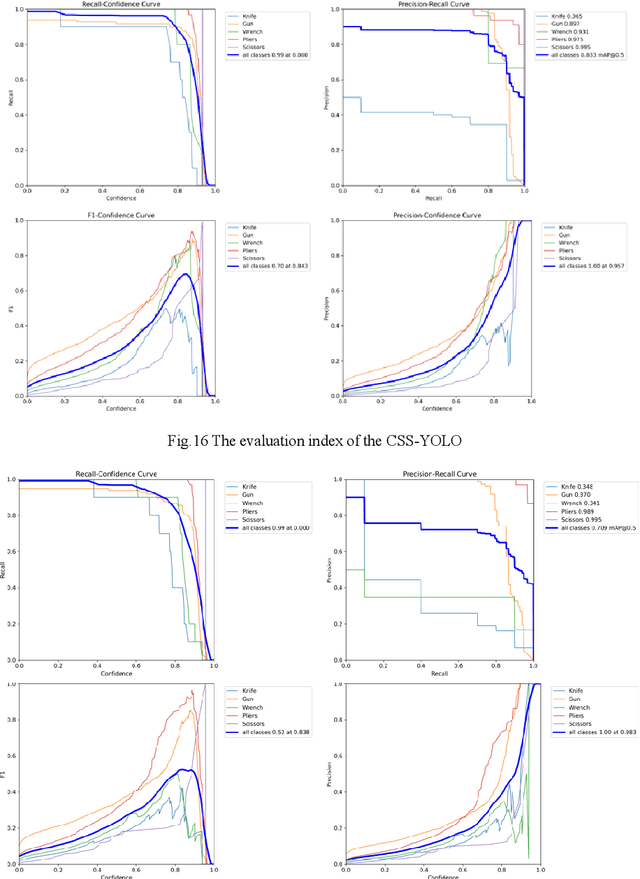


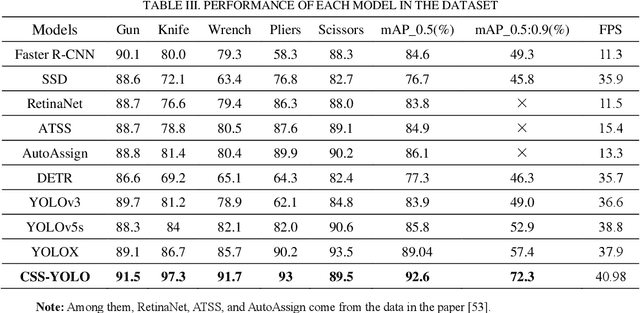
Security inspection is the first line of defense to ensure the safety of people's lives and property, and intelligent security inspection is an inevitable trend in the future development of the security inspection industry. Aiming at the problems of overlapping detection objects, false detection of contraband, and missed detection in the process of X-ray image detection, an improved X-ray contraband detection algorithm CSS-YOLO based on YOLOv8s is proposed.
Diagnosing Bipolar Disorder from 3-D Structural Magnetic Resonance Images Using a Hybrid GAN-CNN Method
Oct 11, 2023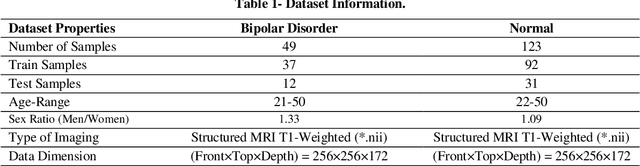
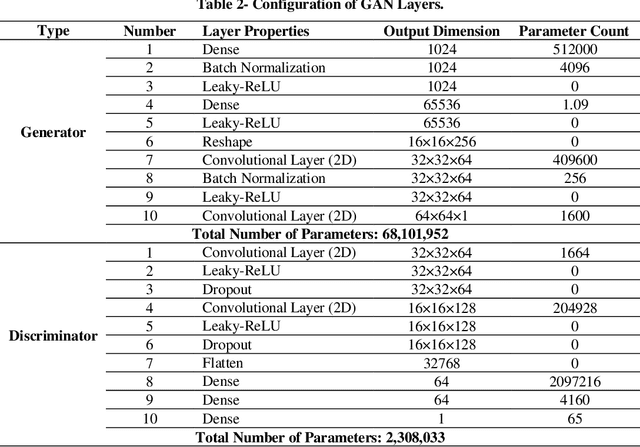
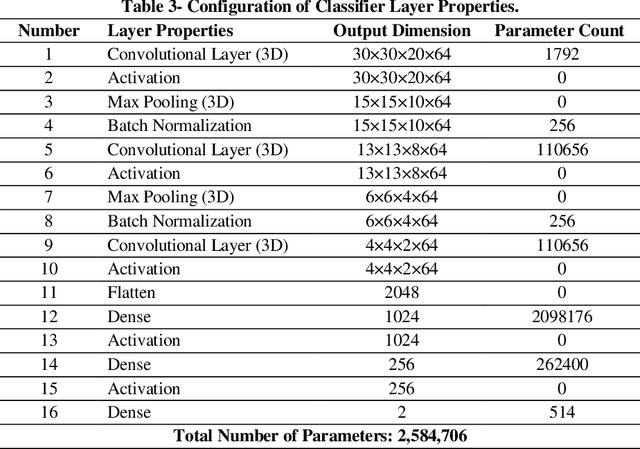

Bipolar Disorder (BD) is a psychiatric condition diagnosed by repetitive cycles of hypomania and depression. Since diagnosing BD relies on subjective behavioral assessments over a long period, a solid diagnosis based on objective criteria is not straightforward. The current study responded to the described obstacle by proposing a hybrid GAN-CNN model to diagnose BD from 3-D structural MRI Images (sMRI). The novelty of this study stems from diagnosing BD from sMRI samples rather than conventional datasets such as functional MRI (fMRI), electroencephalography (EEG), and behavioral symptoms while removing the data insufficiency usually encountered when dealing with sMRI samples. The impact of various augmentation ratios is also tested using 5-fold cross-validation. Based on the results, this study obtains an accuracy rate of 75.8%, a sensitivity of 60.3%, and a specificity of 82.5%, which are 3-5% higher than prior work while utilizing less than 6% sample counts. Next, it is demonstrated that a 2- D layer-based GAN generator can effectively reproduce complex 3D brain samples, a more straightforward technique than manual image processing. Lastly, the optimum augmentation threshold for the current study using 172 sMRI samples is 50%, showing the applicability of the described method for larger sMRI datasets. In conclusion, it is established that data augmentation using GAN improves the accuracy of the CNN classifier using sMRI samples, thus developing more reliable decision support systems to assist practitioners in identifying BD patients more reliably and in a shorter period
A Self-supervised SAR Image Despeckling Strategy Based on Parameter-sharing Convolutional Neural Networks
Aug 11, 2023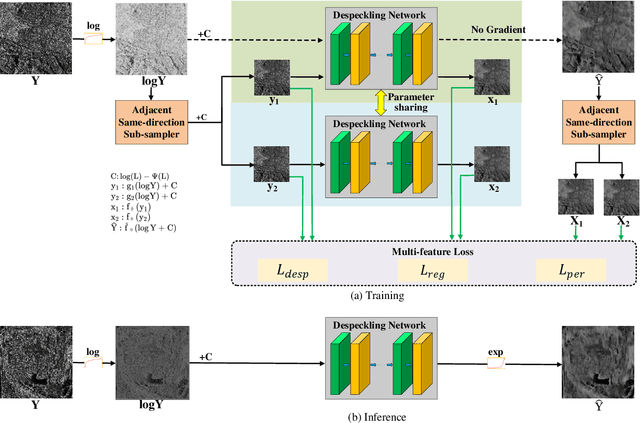
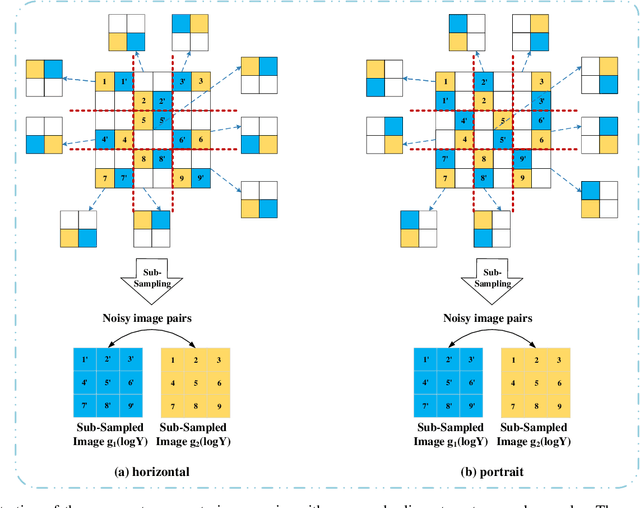
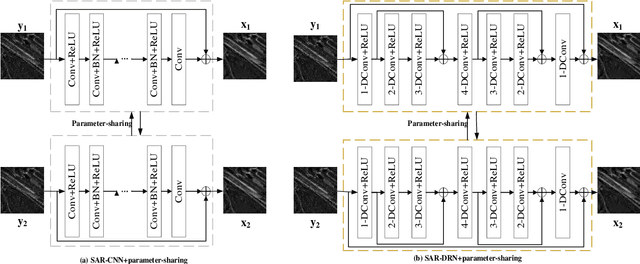
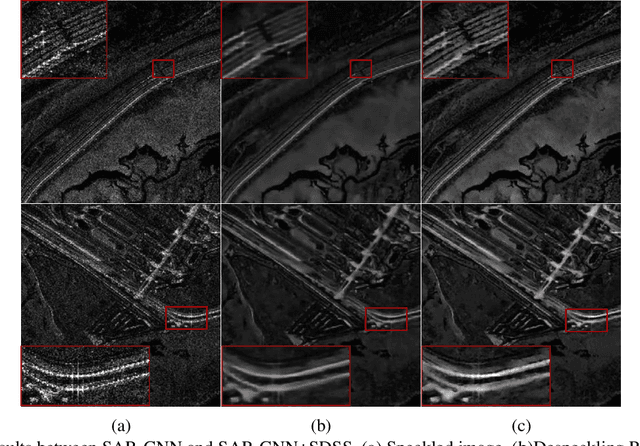
Speckle noise is generated due to the SAR imaging mechanism, which brings difficulties in SAR image interpretation. Hence, despeckling is a helpful step in SAR pre-processing. Nowadays, deep learning has been proved to be a progressive method for SAR image despeckling. Most deep learning methods for despeckling are based on supervised learning, which needs original SAR images and speckle-free SAR images to train the network. However, the speckle-free SAR images are generally not available. So, this issue was tackled by adding multiplicative noise to optical images synthetically for simulating speckled image. Therefore, there are following challenges in SAR image despeckling: (1) lack of speckle-free SAR image; (2) difficulty in keeping details such as edges and textures in heterogeneous areas. To address these issues, we propose a self-supervised SAR despeckling strategy that can be trained without speckle-free images. Firstly, the feasibility of SAR image despeckling without speckle-free images is proved theoretically. Then, the sub-sampler based on the adjacent-syntropy criteria is proposed. The training image pairs are generated by the sub-sampler from real-word SAR image to estimate the noise distribution. Furthermore, to make full use of training pairs, the parameter sharing convolutional neural networks are adopted. Finally, according to the characteristics of SAR images, a multi-feature loss function is proposed. The proposed loss function is composed of despeckling term, regular term and perception term, to constrain the gap between the generated paired images. The ability of edge and texture feature preserving is improved simultaneously. Finally, qualitative and quantitative experiments are validated on real-world SAR images, showing better performances than several advanced SAR image despeckling methods.