 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Open-Set Knowledge-Based Visual Question Answering with Inference Paths
Oct 12, 2023
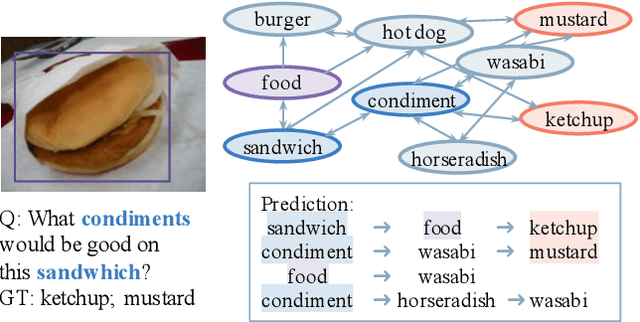
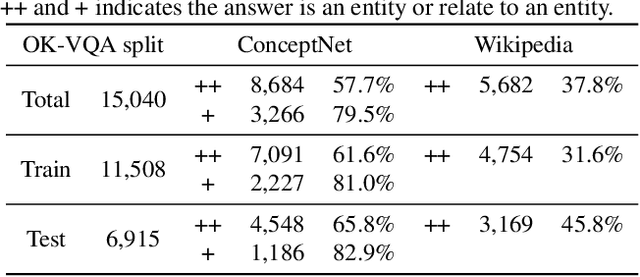
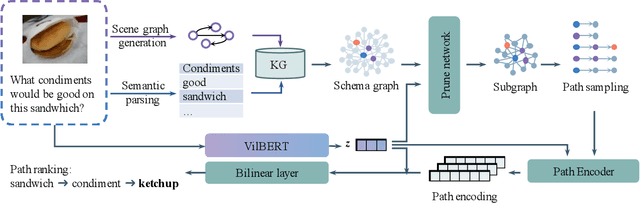
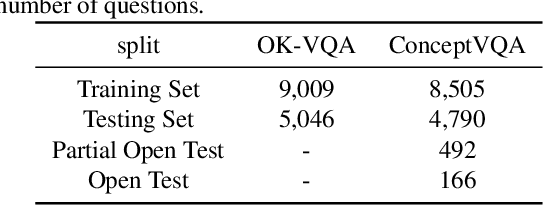
Given an image and an associated textual question, the purpose of Knowledge-Based Visual Question Answering (KB-VQA) is to provide a correct answer to the question with the aid of external knowledge bases. Prior KB-VQA models are usually formulated as a retriever-classifier framework, where a pre-trained retriever extracts textual or visual information from knowledge graphs and then makes a prediction among the candidates. Despite promising progress, there are two drawbacks with existing models. Firstly, modeling question-answering as multi-class classification limits the answer space to a preset corpus and lacks the ability of flexible reasoning. Secondly, the classifier merely consider "what is the answer" without "how to get the answer", which cannot ground the answer to explicit reasoning paths. In this paper, we confront the challenge of \emph{explainable open-set} KB-VQA, where the system is required to answer questions with entities at wild and retain an explainable reasoning path. To resolve the aforementioned issues, we propose a new retriever-ranker paradigm of KB-VQA, Graph pATH rankER (GATHER for brevity). Specifically, it contains graph constructing, pruning, and path-level ranking, which not only retrieves accurate answers but also provides inference paths that explain the reasoning process. To comprehensively evaluate our model, we reformulate the benchmark dataset OK-VQA with manually corrected entity-level annotations and release it as ConceptVQA. Extensive experiments on real-world questions demonstrate that our framework is not only able to perform open-set question answering across the whole knowledge base but provide explicit reasoning path.
Score Priors Guided Deep Variational Inference for Unsupervised Real-World Single Image Denoising
Aug 09, 2023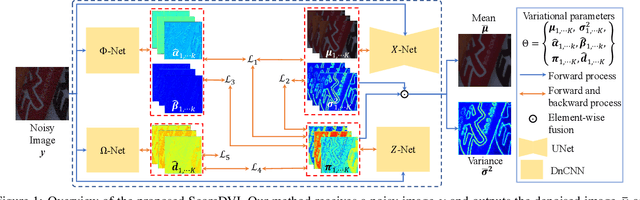
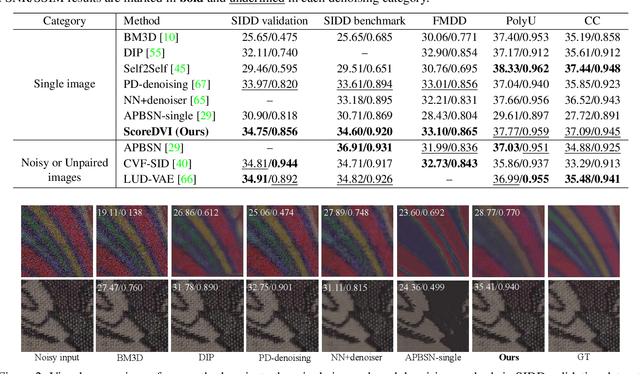


Real-world single image denoising is crucial and practical in computer vision. Bayesian inversions combined with score priors now have proven effective for single image denoising but are limited to white Gaussian noise. Moreover, applying existing score-based methods for real-world denoising requires not only the explicit train of score priors on the target domain but also the careful design of sampling procedures for posterior inference, which is complicated and impractical. To address these limitations, we propose a score priors-guided deep variational inference, namely ScoreDVI, for practical real-world denoising. By considering the deep variational image posterior with a Gaussian form, score priors are extracted based on easily accessible minimum MSE Non-$i.i.d$ Gaussian denoisers and variational samples, which in turn facilitate optimizing the variational image posterior. Such a procedure adaptively applies cheap score priors to denoising. Additionally, we exploit a Non-$i.i.d$ Gaussian mixture model and variational noise posterior to model the real-world noise. This scheme also enables the pixel-wise fusion of multiple image priors and variational image posteriors. Besides, we develop a noise-aware prior assignment strategy that dynamically adjusts the weight of image priors in the optimization. Our method outperforms other single image-based real-world denoising methods and achieves comparable performance to dataset-based unsupervised methods.
EViT: An Eagle Vision Transformer with Bi-Fovea Self-Attention
Oct 10, 2023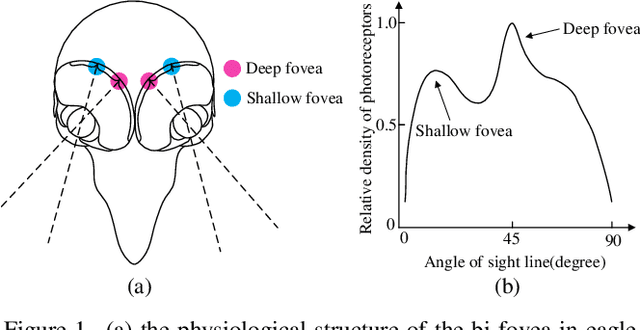
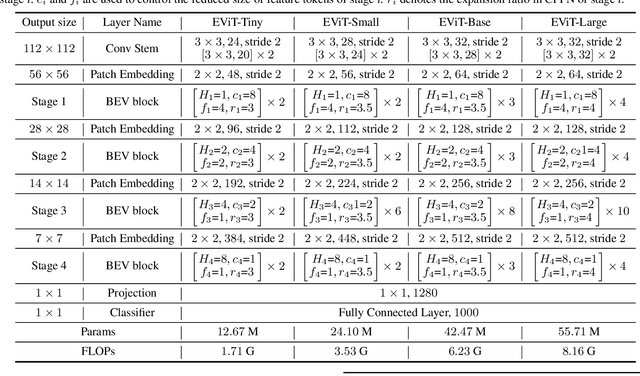
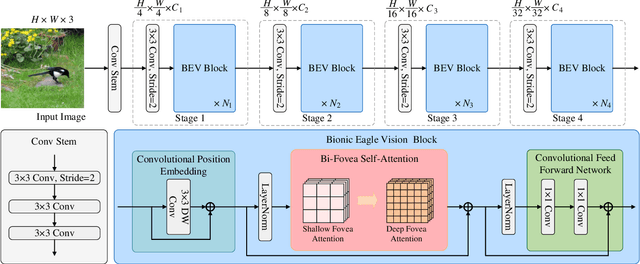
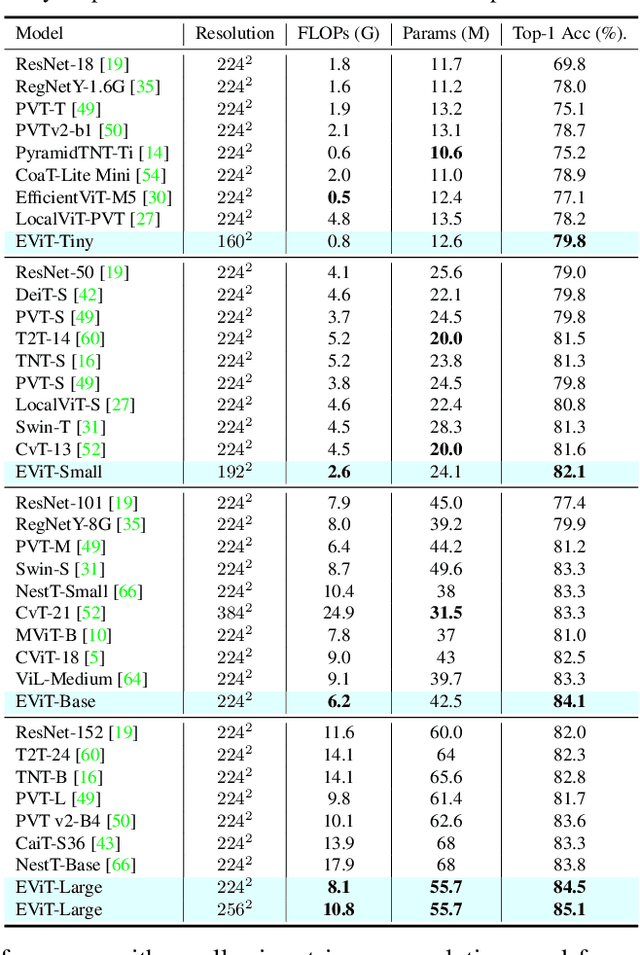
Because of the advancement of deep learning technology, vision transformer has demonstrated competitive performance in various computer vision tasks. Unfortunately, vision transformer still faces some challenges such as high computational complexity and absence of desirable inductive bias. To alleviate these problems, this study proposes a novel Bi-Fovea Self-Attention (BFSA) inspired by the physiological structure and characteristics of bi-fovea vision in eagle eyes. This BFSA can simulate the shallow fovea and deep fovea functions of eagle vision, enabling the network to extract feature representations of targets from coarse to fine, facilitating the interaction of multi-scale feature representations. Additionally, this study designs a Bionic Eagle Vision (BEV) block based on BFSA and CNN. It combines CNN and Vision Transformer, to enhance the network's local and global representation ability for targets. Furthermore, this study develops a unified and efficient general pyramid backbone network family, named Eagle Vision Transformers (EViTs) by stacking the BEV blocks. Experimental results on various computer vision tasks including image classification, object detection, instance segmentation and other transfer learning tasks show that the proposed EViTs perform significantly better than the baselines under similar model sizes, which exhibits faster speed on graphics processing unit compared to other models. Code will be released at https://github.com/nkusyl.
Open-source Pulseq sequences on Philips MRI scanners
Oct 10, 2023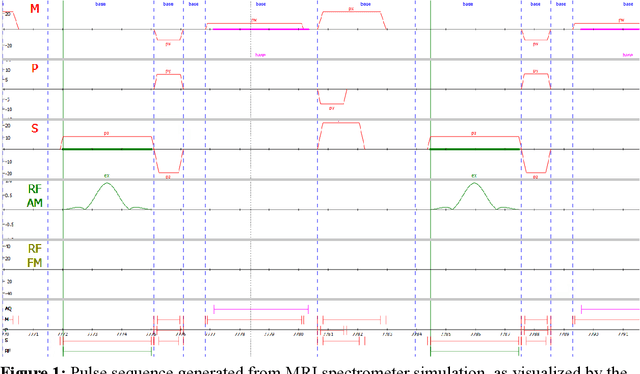

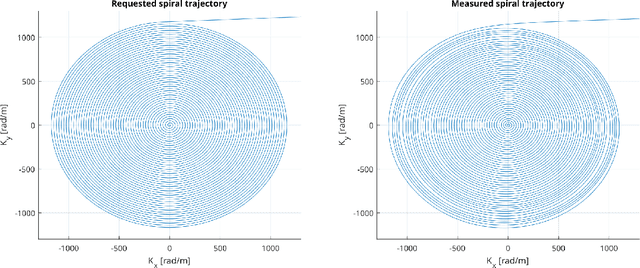
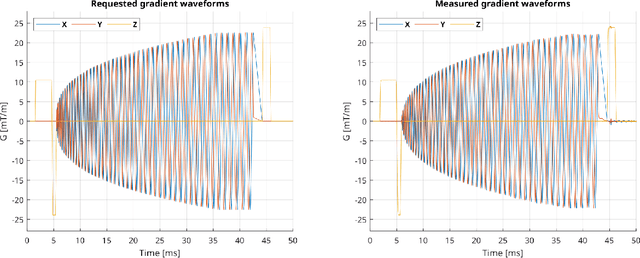
Purpose: This work aims to address the limitations faced by researchers in developing and sharing new MRI sequences by implementing an interpreter for the open-source MRI pulse sequence format, Pulseq, on a Philips MRI scanner. Methods: The implementation involved modifying a few source code files to create a Pulseq interpreter for the Philips MRI system. Validation experiments were conducted using simulations and phantom scans performed on a 7T Achieva MRI system. The observed sequence and waveforms were compared to the intended ones, and the gradient waveforms produced by the scanner were verified using a field camera. Image reconstruction was performed using the raw k-space samples acquired from both the native vendor environment and the Pulseq interpreter. Results: The reconstructed images obtained through the Pulseq implementation were found to be comparable to those obtained through the native implementation. The performance of the Pulseq interpreter was assessed by profiling the CPU utilization of the MRI spectrometer, showing minimal resource utilization for certain sequences. Conclusion: The successful implementation of the Pulseq interpreter on the Philips MRI scanner demonstrates the feasibility of utilizing Pulseq sequences on Philips MRI scanners. This provides an open-source platform for MRI sequence development, facilitating collaboration among researchers and accelerating scientific progress in the field of MRI.
CLIP Is Also a Good Teacher: A New Learning Framework for Inductive Zero-shot Semantic Segmentation
Oct 03, 2023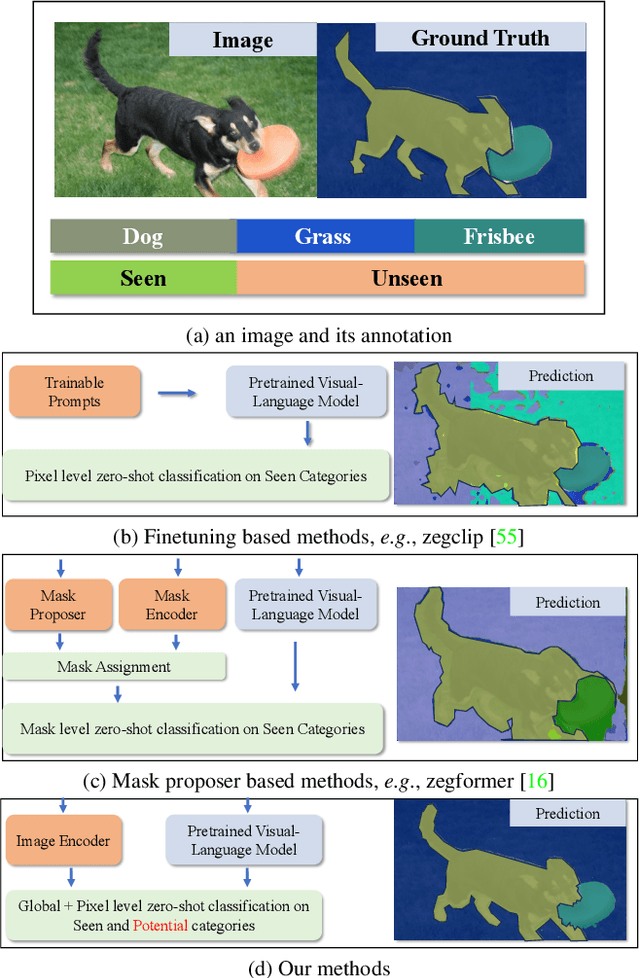
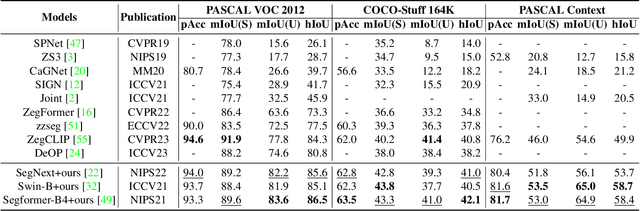
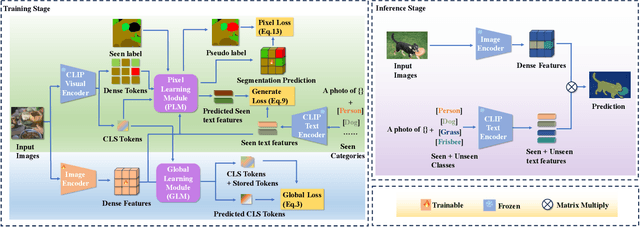
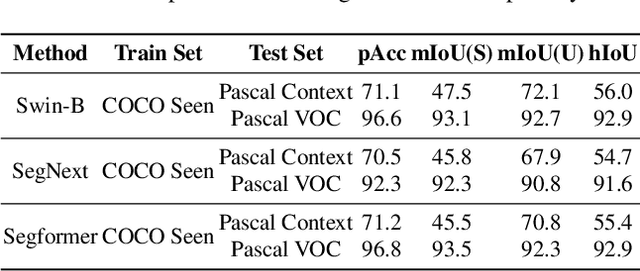
Existing Generalized Zero-shot Semantic Segmentation (GZLSS) methods apply either finetuning the CLIP paradigm or formulating it as a mask classification task, benefiting from the Vision-Language Models (VLMs). However, the fine-tuning methods are restricted with fixed backbone models which are not flexible for segmentation, and mask classification methods heavily rely on additional explicit mask proposers. Meanwhile, prevalent methods utilize only seen categories which is a great waste, i.e., neglecting the area exists but not annotated. To this end, we propose CLIPTeacher, a new learning framework that can be applied to various per-pixel classification segmentation models without introducing any explicit mask proposer or changing the structure of CLIP, and utilize both seen and ignoring areas. Specifically, CLIPTeacher consists of two key modules: Global Learning Module (GLM) and Pixel Learning Module (PLM). Specifically, GLM aligns the dense features from an image encoder with the CLS token, i.e., the only token trained in CLIP, which is a simple but effective way to probe global information from the CLIP models. In contrast, PLM only leverages dense tokens from CLIP to produce high-level pseudo annotations for ignoring areas without introducing any extra mask proposer. Meanwhile, PLM can fully take advantage of the whole image based on the pseudo annotations. Experimental results on three benchmark datasets: PASCAL VOC 2012, COCO-Stuff 164k, and PASCAL Context show large performance gains, i.e., 2.2%, 1.3%, and 8.8%
A Large-Scale 3D Face Mesh Video Dataset via Neural Re-parameterized Optimization
Oct 06, 2023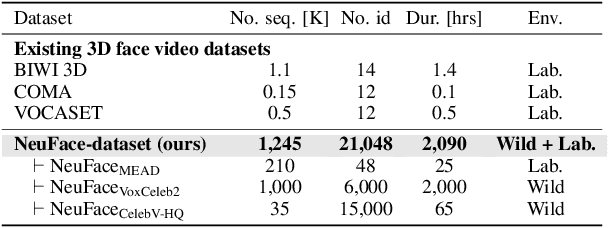
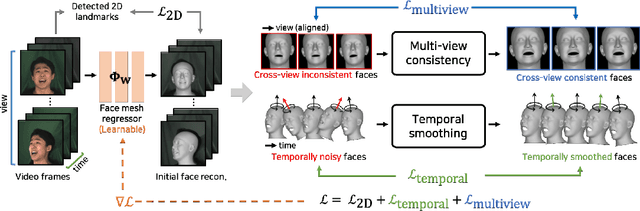
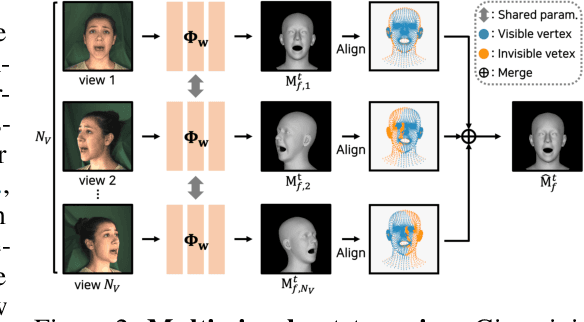
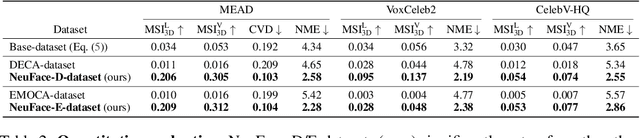
We propose NeuFace, a 3D face mesh pseudo annotation method on videos via neural re-parameterized optimization. Despite the huge progress in 3D face reconstruction methods, generating reliable 3D face labels for in-the-wild dynamic videos remains challenging. Using NeuFace optimization, we annotate the per-view/-frame accurate and consistent face meshes on large-scale face videos, called the NeuFace-dataset. We investigate how neural re-parameterization helps to reconstruct image-aligned facial details on 3D meshes via gradient analysis. By exploiting the naturalness and diversity of 3D faces in our dataset, we demonstrate the usefulness of our dataset for 3D face-related tasks: improving the reconstruction accuracy of an existing 3D face reconstruction model and learning 3D facial motion prior. Code and datasets will be available at https://neuface-dataset.github.io.
ILuvUI: Instruction-tuned LangUage-Vision modeling of UIs from Machine Conversations
Oct 07, 2023Multimodal Vision-Language Models (VLMs) enable powerful applications from their fused understanding of images and language, but many perform poorly on UI tasks due to the lack of UI training data. In this paper, we adapt a recipe for generating paired text-image training data for VLMs to the UI domain by combining existing pixel-based methods with a Large Language Model (LLM). Unlike prior art, our method requires no human-provided annotations, and it can be applied to any dataset of UI screenshots. We generate a dataset of 335K conversational examples paired with UIs that cover Q&A, UI descriptions, and planning, and use it to fine-tune a conversational VLM for UI tasks. To assess the performance of our model, we benchmark it on UI element detection tasks, evaluate response quality, and showcase its applicability to multi-step UI navigation and planning.
High-performance Data Management for Whole Slide Image Analysis in Digital Pathology
Aug 20, 2023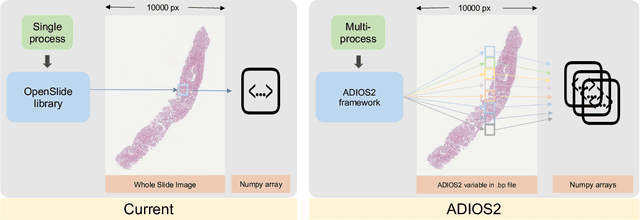

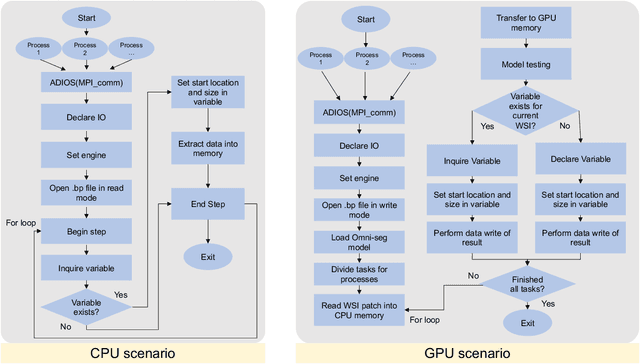

When dealing with giga-pixel digital pathology in whole-slide imaging, a notable proportion of data records holds relevance during each analysis operation. For instance, when deploying an image analysis algorithm on whole-slide images (WSI), the computational bottleneck often lies in the input-output (I/O) system. This is particularly notable as patch-level processing introduces a considerable I/O load onto the computer system. However, this data management process could be further paralleled, given the typical independence of patch-level image processes across different patches. This paper details our endeavors in tackling this data access challenge by implementing the Adaptable IO System version 2 (ADIOS2). Our focus has been constructing and releasing a digital pathology-centric pipeline using ADIOS2, which facilitates streamlined data management across WSIs. Additionally, we've developed strategies aimed at curtailing data retrieval times. The performance evaluation encompasses two key scenarios: (1) a pure CPU-based image analysis scenario ("CPU scenario"), and (2) a GPU-based deep learning framework scenario ("GPU scenario"). Our findings reveal noteworthy outcomes. Under the CPU scenario, ADIOS2 showcases an impressive two-fold speed-up compared to the brute-force approach. In the GPU scenario, its performance stands on par with the cutting-edge GPU I/O acceleration framework, NVIDIA Magnum IO GPU Direct Storage (GDS). From what we know, this appears to be among the initial instances, if any, of utilizing ADIOS2 within the field of digital pathology. The source code has been made publicly available at https://github.com/hrlblab/adios.
GAEI-UNet: Global Attention and Elastic Interaction U-Net for Vessel Image Segmentation
Aug 23, 2023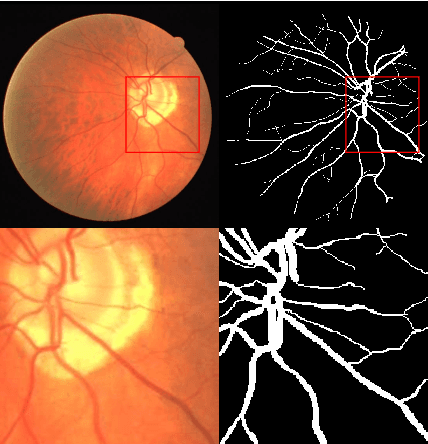
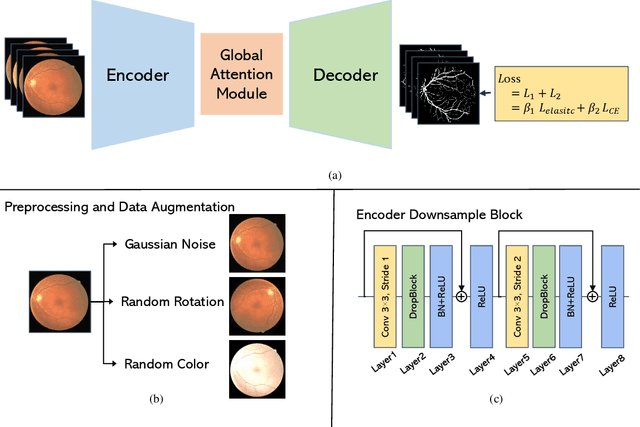
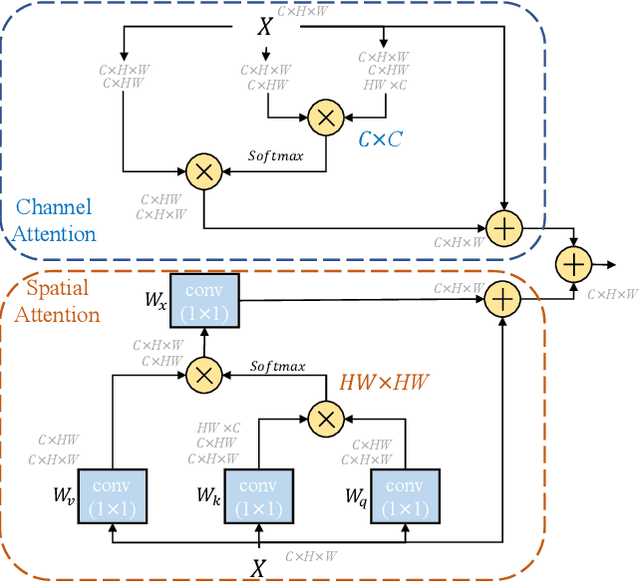
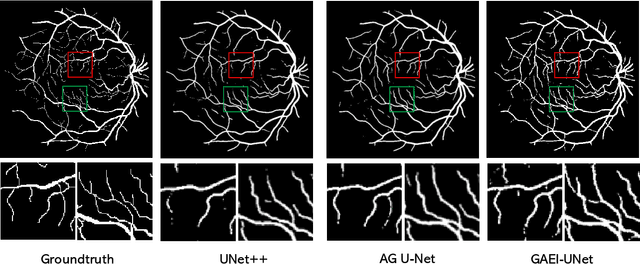
Vessel image segmentation plays a pivotal role in medical diagnostics, aiding in the early detection and treatment of vascular diseases. While segmentation based on deep learning has shown promising results, effectively segmenting small structures and maintaining connectivity between them remains challenging. To address these limitations, we propose GAEI-UNet, a novel model that combines global attention and elastic interaction-based techniques. GAEI-UNet leverages global spatial and channel context information to enhance high-level semantic understanding within the U-Net architecture, enabling precise segmentation of small vessels. Additionally, we adopt an elastic interaction-based loss function to improve connectivity among these fine structures. By capturing the forces generated by misalignment between target and predicted shapes, our model effectively learns to preserve the correct topology of vessel networks. Evaluation on retinal vessel dataset -- DRIVE demonstrates the superior performance of GAEI-UNet in terms of SE and connectivity of small structures, without significantly increasing computational complexity. This research aims to advance the field of vessel image segmentation, providing more accurate and reliable diagnostic tools for the medical community. The implementation code is available on Code.
Unleashing the Power of Self-Supervised Image Denoising: A Comprehensive Review
Aug 09, 2023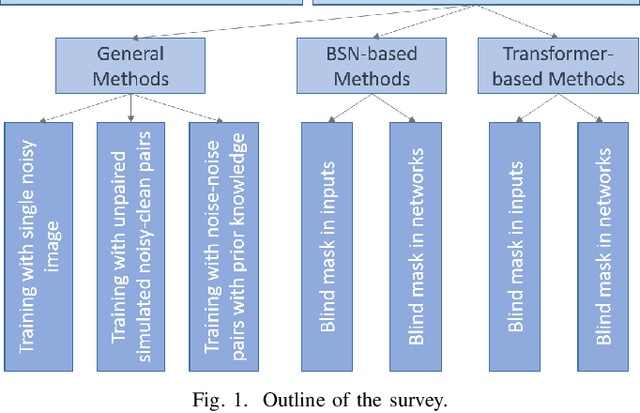

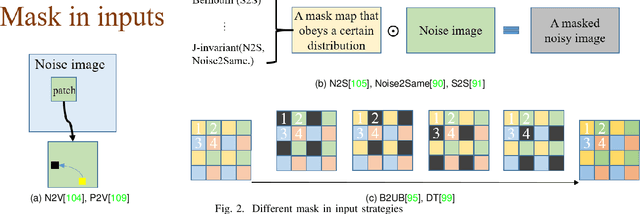
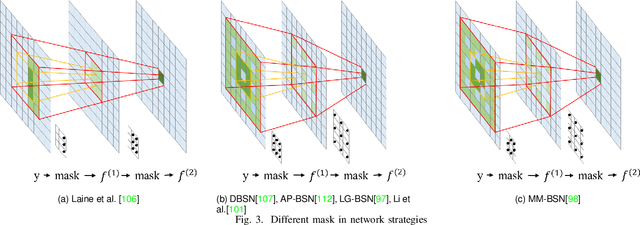
The advent of deep learning has brought a revolutionary transformation to image denoising techniques. However, the persistent challenge of acquiring noise-clean pairs for supervised methods in real-world scenarios remains formidable, necessitating the exploration of more practical self-supervised image denoising. This paper focuses on self-supervised image denoising methods that offer effective solutions to address this challenge. Our comprehensive review thoroughly analyzes the latest advancements in self-supervised image denoising approaches, categorizing them into three distinct classes: General methods, Blind Spot Network (BSN)-based methods, and Transformer-based methods. For each class, we provide a concise theoretical analysis along with their practical applications. To assess the effectiveness of these methods, we present both quantitative and qualitative experimental results on various datasets, utilizing classical algorithms as benchmarks. Additionally, we critically discuss the current limitations of these methods and propose promising directions for future research. By offering a detailed overview of recent developments in self-supervised image denoising, this review serves as an invaluable resource for researchers and practitioners in the field, facilitating a deeper understanding of this emerging domain and inspiring further advancements.