 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Drag View: Generalizable Novel View Synthesis with Unposed Imagery
Oct 05, 2023


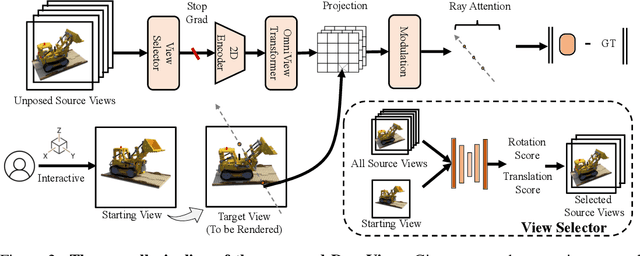
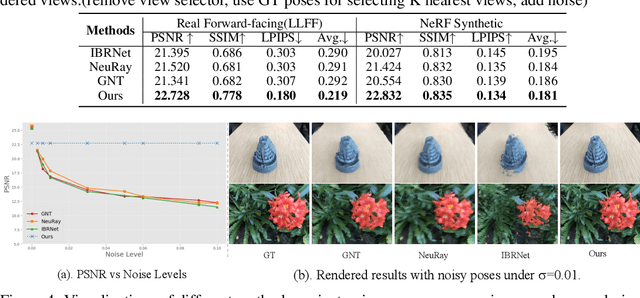
We introduce DragView, a novel and interactive framework for generating novel views of unseen scenes. DragView initializes the new view from a single source image, and the rendering is supported by a sparse set of unposed multi-view images, all seamlessly executed within a single feed-forward pass. Our approach begins with users dragging a source view through a local relative coordinate system. Pixel-aligned features are obtained by projecting the sampled 3D points along the target ray onto the source view. We then incorporate a view-dependent modulation layer to effectively handle occlusion during the projection. Additionally, we broaden the epipolar attention mechanism to encompass all source pixels, facilitating the aggregation of initialized coordinate-aligned point features from other unposed views. Finally, we employ another transformer to decode ray features into final pixel intensities. Crucially, our framework does not rely on either 2D prior models or the explicit estimation of camera poses. During testing, DragView showcases the capability to generalize to new scenes unseen during training, also utilizing only unposed support images, enabling the generation of photo-realistic new views characterized by flexible camera trajectories. In our experiments, we conduct a comprehensive comparison of the performance of DragView with recent scene representation networks operating under pose-free conditions, as well as with generalizable NeRFs subject to noisy test camera poses. DragView consistently demonstrates its superior performance in view synthesis quality, while also being more user-friendly. Project page: https://zhiwenfan.github.io/DragView/.
Deepfake Image Generation for Improved Brain Tumor Segmentation
Jul 26, 2023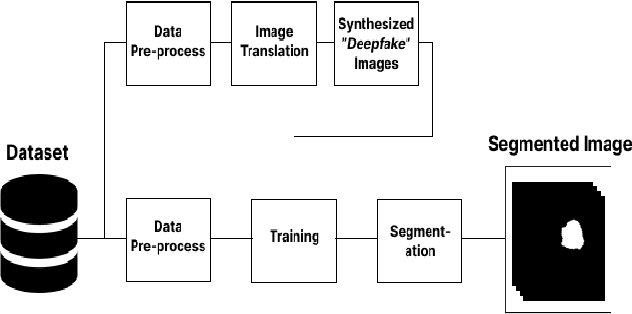

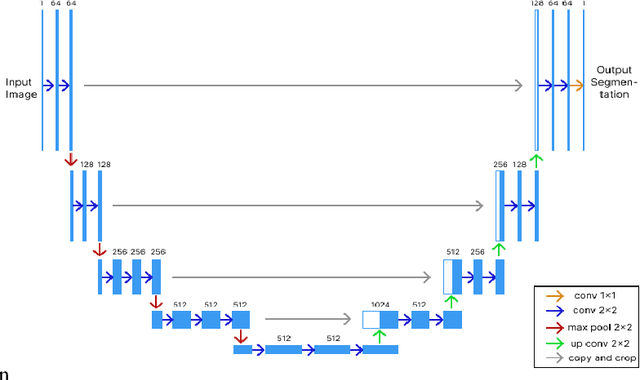
As the world progresses in technology and health, awareness of disease by revealing asymptomatic signs improves. It is important to detect and treat tumors in early stage as it can be life-threatening. Computer-aided technologies are used to overcome lingering limitations facing disease diagnosis, while brain tumor segmentation remains a difficult process, especially when multi-modality data is involved. This is mainly attributed to ineffective training due to lack of data and corresponding labelling. This work investigates the feasibility of employing deep-fake image generation for effective brain tumor segmentation. To this end, a Generative Adversarial Network was used for image-to-image translation for increasing dataset size, followed by image segmentation using a U-Net-based convolutional neural network trained with deepfake images. Performance of the proposed approach is compared with ground truth of four publicly available datasets. Results show improved performance in terms of image segmentation quality metrics, and could potentially assist when training with limited data.
* 6 pages, 8 figures, 2 tables, conference paper
Advancing Intra-operative Precision: Dynamic Data-Driven Non-Rigid Registration for Enhanced Brain Tumor Resection in Image-Guided Neurosurgery
Aug 18, 2023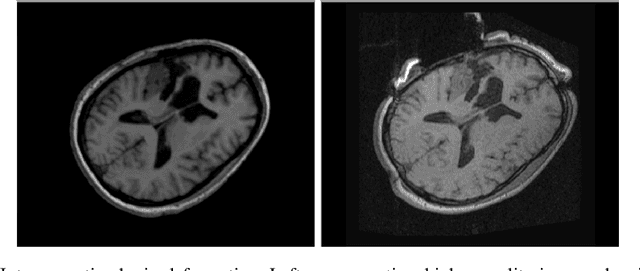

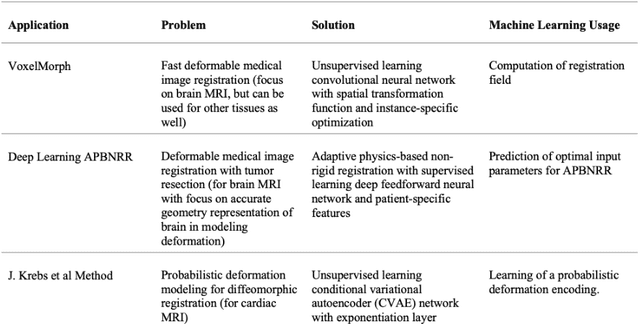
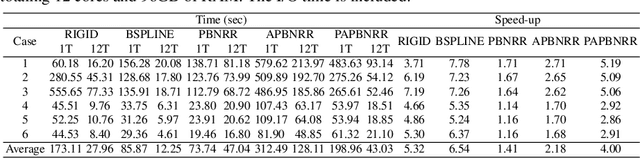
During neurosurgery, medical images of the brain are used to locate tumors and critical structures, but brain tissue shifts make pre-operative images unreliable for accurate removal of tumors. Intra-operative imaging can track these deformations but is not a substitute for pre-operative data. To address this, we use Dynamic Data-Driven Non-Rigid Registration (NRR), a complex and time-consuming image processing operation that adjusts the pre-operative image data to account for intra-operative brain shift. Our review explores a specific NRR method for registering brain MRI during image-guided neurosurgery and examines various strategies for improving the accuracy and speed of the NRR method. We demonstrate that our implementation enables NRR results to be delivered within clinical time constraints while leveraging Distributed Computing and Machine Learning to enhance registration accuracy by identifying optimal parameters for the NRR method. Additionally, we highlight challenges associated with its use in the operating room.
A Benchmark for Chinese-English Scene Text Image Super-resolution
Aug 07, 2023
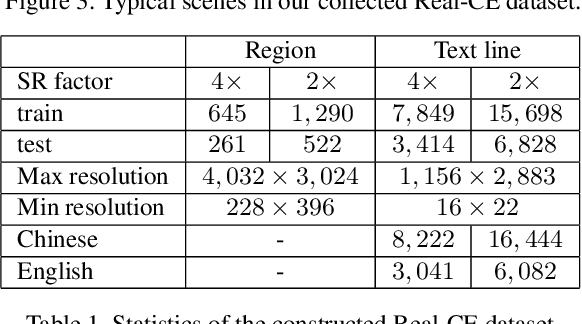
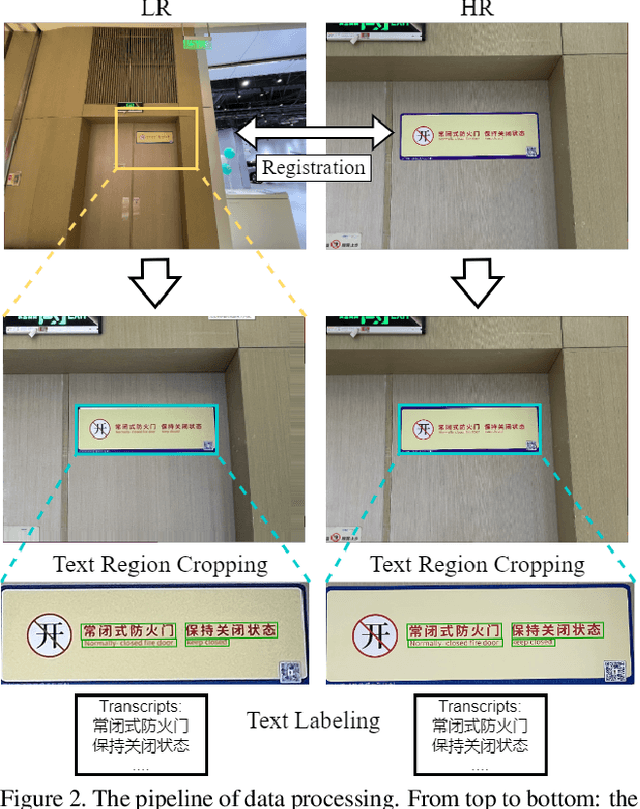
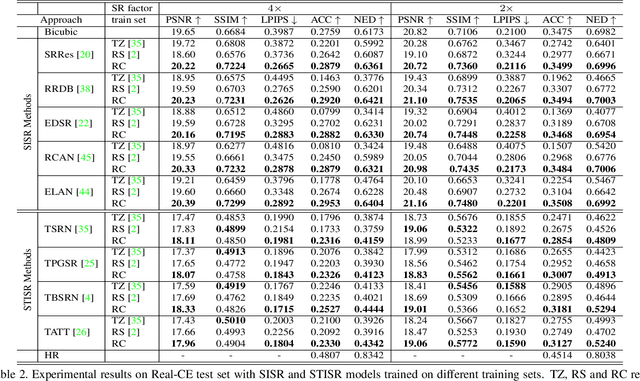
Scene Text Image Super-resolution (STISR) aims to recover high-resolution (HR) scene text images with visually pleasant and readable text content from the given low-resolution (LR) input. Most existing works focus on recovering English texts, which have relatively simple character structures, while little work has been done on the more challenging Chinese texts with diverse and complex character structures. In this paper, we propose a real-world Chinese-English benchmark dataset, namely Real-CE, for the task of STISR with the emphasis on restoring structurally complex Chinese characters. The benchmark provides 1,935/783 real-world LR-HR text image pairs~(contains 33,789 text lines in total) for training/testing in 2$\times$ and 4$\times$ zooming modes, complemented by detailed annotations, including detection boxes and text transcripts. Moreover, we design an edge-aware learning method, which provides structural supervision in image and feature domains, to effectively reconstruct the dense structures of Chinese characters. We conduct experiments on the proposed Real-CE benchmark and evaluate the existing STISR models with and without our edge-aware loss. The benchmark, including data and source code, is available at https://github.com/mjq11302010044/Real-CE.
Improving Robustness of Deep Convolutional Neural Networks via Multiresolution Learning
Sep 28, 2023The current learning process of deep learning, regardless of any deep neural network (DNN) architecture and/or learning algorithm used, is essentially a single resolution training. We explore multiresolution learning and show that multiresolution learning can significantly improve robustness of DNN models for both 1D signal and 2D signal (image) prediction problems. We demonstrate this improvement in terms of both noise and adversarial robustness as well as with small training dataset size. Our results also suggest that it may not be necessary to trade standard accuracy for robustness with multiresolution learning, which is, interestingly, contrary to the observation obtained from the traditional single resolution learning setting.
All-in-one Multi-degradation Image Restoration Network via Hierarchical Degradation Representation
Aug 06, 2023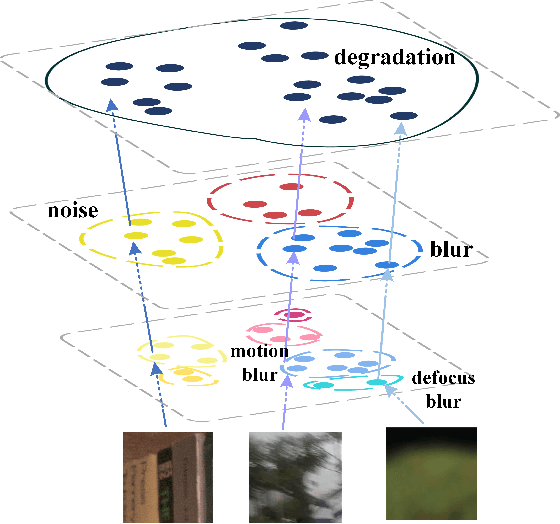

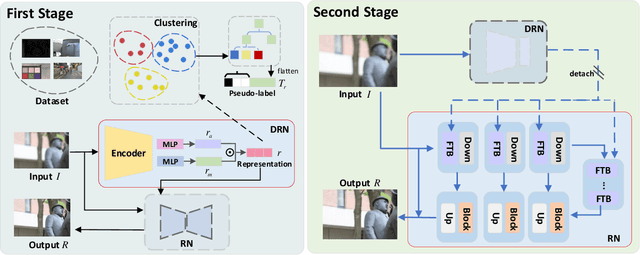
The aim of image restoration is to recover high-quality images from distorted ones. However, current methods usually focus on a single task (\emph{e.g.}, denoising, deblurring or super-resolution) which cannot address the needs of real-world multi-task processing, especially on mobile devices. Thus, developing an all-in-one method that can restore images from various unknown distortions is a significant challenge. Previous works have employed contrastive learning to learn the degradation representation from observed images, but this often leads to representation drift caused by deficient positive and negative pairs. To address this issue, we propose a novel All-in-one Multi-degradation Image Restoration Network (AMIRNet) that can effectively capture and utilize accurate degradation representation for image restoration. AMIRNet learns a degradation representation for unknown degraded images by progressively constructing a tree structure through clustering, without any prior knowledge of degradation information. This tree-structured representation explicitly reflects the consistency and discrepancy of various distortions, providing a specific clue for image restoration. To further enhance the performance of the image restoration network and overcome domain gaps caused by unknown distortions, we design a feature transform block (FTB) that aligns domains and refines features with the guidance of the degradation representation. We conduct extensive experiments on multiple distorted datasets, demonstrating the effectiveness of our method and its advantages over state-of-the-art restoration methods both qualitatively and quantitatively.
Pixel Adaptive Deep Unfolding Transformer for Hyperspectral Image Reconstruction
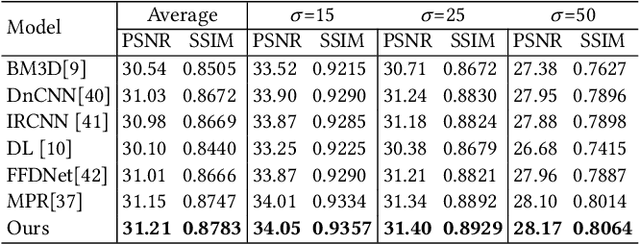
Aug 21, 2023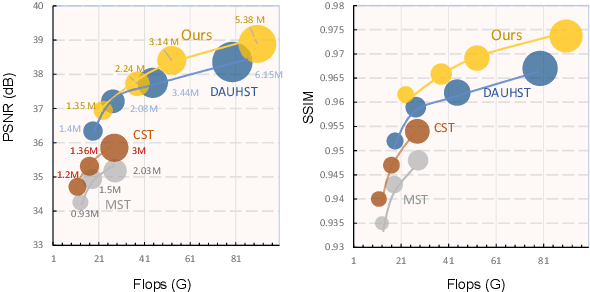
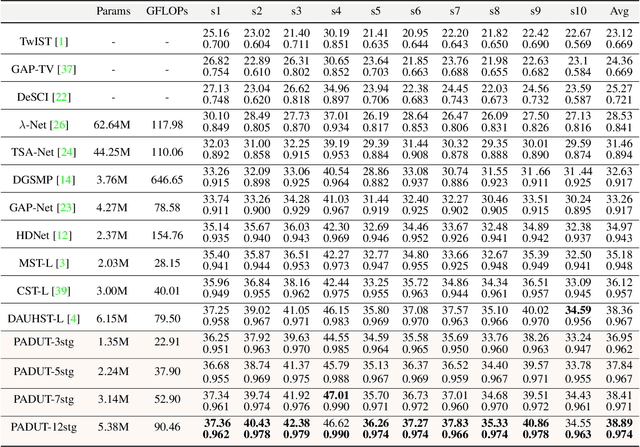
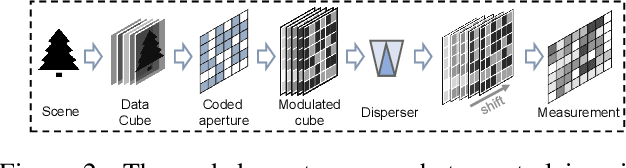
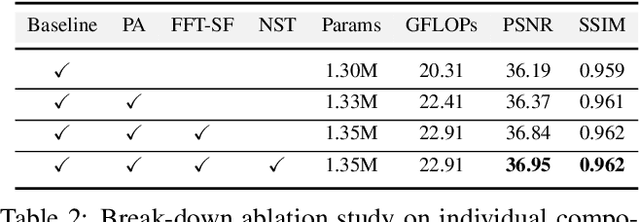
Hyperspectral Image (HSI) reconstruction has made gratifying progress with the deep unfolding framework by formulating the problem into a data module and a prior module. Nevertheless, existing methods still face the problem of insufficient matching with HSI data. The issues lie in three aspects: 1) fixed gradient descent step in the data module while the degradation of HSI is agnostic in the pixel-level. 2) inadequate prior module for 3D HSI cube. 3) stage interaction ignoring the differences in features at different stages. To address these issues, in this work, we propose a Pixel Adaptive Deep Unfolding Transformer (PADUT) for HSI reconstruction. In the data module, a pixel adaptive descent step is employed to focus on pixel-level agnostic degradation. In the prior module, we introduce the Non-local Spectral Transformer (NST) to emphasize the 3D characteristics of HSI for recovering. Moreover, inspired by the diverse expression of features in different stages and depths, the stage interaction is improved by the Fast Fourier Transform (FFT). Experimental results on both simulated and real scenes exhibit the superior performance of our method compared to state-of-the-art HSI reconstruction methods. The code is released at: https://github.com/MyuLi/PADUT.
A Framework for Interpretability in Machine Learning for Medical Imaging
Oct 02, 2023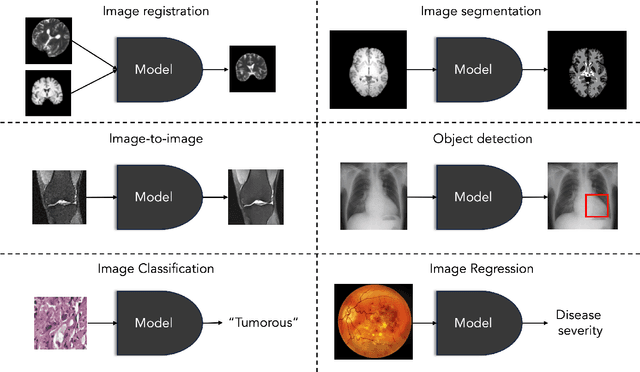
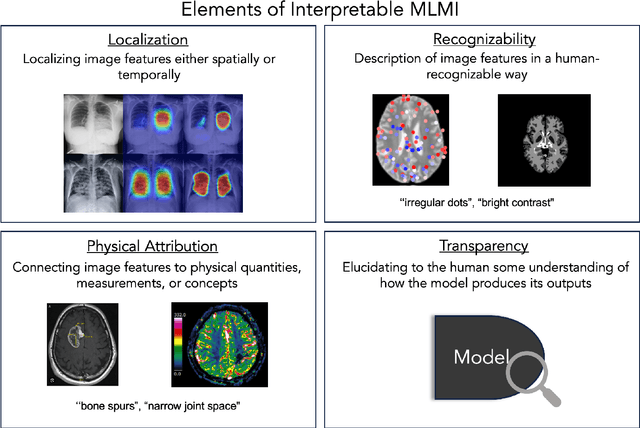
Interpretability for machine learning models in medical imaging (MLMI) is an important direction of research. However, there is a general sense of murkiness in what interpretability means. Why does the need for interpretability in MLMI arise? What goals does one actually seek to address when interpretability is needed? To answer these questions, we identify a need to formalize the goals and elements of interpretability in MLMI. By reasoning about real-world tasks and goals common in both medical image analysis and its intersection with machine learning, we identify four core elements of interpretability: localization, visual recognizability, physical attribution, and transparency. Overall, this paper formalizes interpretability needs in the context of medical imaging, and our applied perspective clarifies concrete MLMI-specific goals and considerations in order to guide method design and improve real-world usage. Our goal is to provide practical and didactic information for model designers and practitioners, inspire developers of models in the medical imaging field to reason more deeply about what interpretability is achieving, and suggest future directions of interpretability research.
Sequential Data Generation with Groupwise Diffusion Process
Oct 02, 2023We present the Groupwise Diffusion Model (GDM), which divides data into multiple groups and diffuses one group at one time interval in the forward diffusion process. GDM generates data sequentially from one group at one time interval, leading to several interesting properties. First, as an extension of diffusion models, GDM generalizes certain forms of autoregressive models and cascaded diffusion models. As a unified framework, GDM allows us to investigate design choices that have been overlooked in previous works, such as data-grouping strategy and order of generation. Furthermore, since one group of the initial noise affects only a certain group of the generated data, latent space now possesses group-wise interpretable meaning. We can further extend GDM to the frequency domain where the forward process sequentially diffuses each group of frequency components. Dividing the frequency bands of the data as groups allows the latent variables to become a hierarchical representation where individual groups encode data at different levels of abstraction. We demonstrate several applications of such representation including disentanglement of semantic attributes, image editing, and generating variations.
A New Real-World Video Dataset for the Comparison of Defogging Algorithms
Oct 02, 2023Video restoration for noise removal, deblurring or super-resolution is attracting more and more attention in the fields of image processing and computer vision. Works on video restoration with data-driven approaches for fog removal are rare however, due to the lack of datasets containing videos in both clear and foggy conditions which are required for deep learning and benchmarking. A new dataset, called REVIDE, was recently proposed for just that purpose. In this paper, we implement the same approach by proposing a new REal-world VIdeo dataset for the comparison of Defogging Algorithms (VIREDA), with various fog densities and ground truths without fog. This small database can serve as a test base for defogging algorithms. A video defogging algorithm is also mentioned (still under development), with the key idea of using temporal redundancy to minimize artefacts and exposure variations between frames. Inspired by the success of Transformers architecture in deep learning for various applications, we select this kind of architecture in a neural network to show the relevance of the proposed dataset.