 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Coding-Modulation for Digital Semantic Communications via Variational Autoencoder
Oct 10, 2023
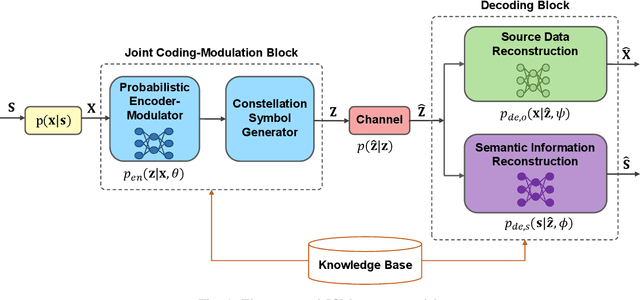
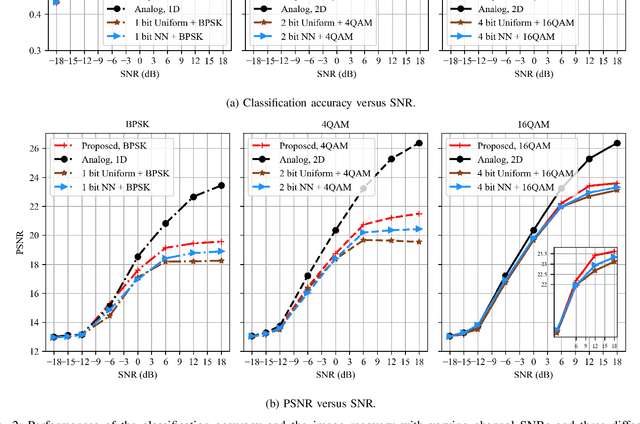

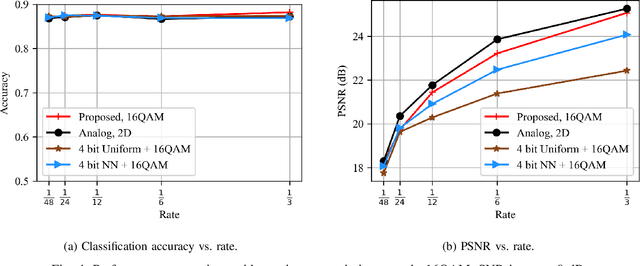
Semantic communications have emerged as a new paradigm for improving communication efficiency by transmitting the semantic information of a source message that is most relevant to a desired task at the receiver. Most existing approaches typically utilize neural networks (NNs) to design end-to-end semantic communication systems, where NN-based semantic encoders output continuously distributed signals to be sent directly to the channel in an analog communication fashion. In this work, we propose a joint coding-modulation framework for digital semantic communications by using variational autoencoder (VAE). Our approach learns the transition probability from source data to discrete constellation symbols, thereby avoiding the non-differentiability problem of digital modulation. Meanwhile, by jointly designing the coding and modulation process together, we can match the obtained modulation strategy with the operating channel condition. We also derive a matching loss function with information-theoretic meaning for end-to-end training. Experiments conducted on image semantic communication validate that our proposed joint coding-modulation framework outperforms separate design of semantic coding and modulation under various channel conditions, transmission rates, and modulation orders. Furthermore, its performance gap to analog semantic communication reduces as the modulation order increases while enjoying the hardware implementation convenience.
Time Does Tell: Self-Supervised Time-Tuning of Dense Image Representations
Aug 22, 2023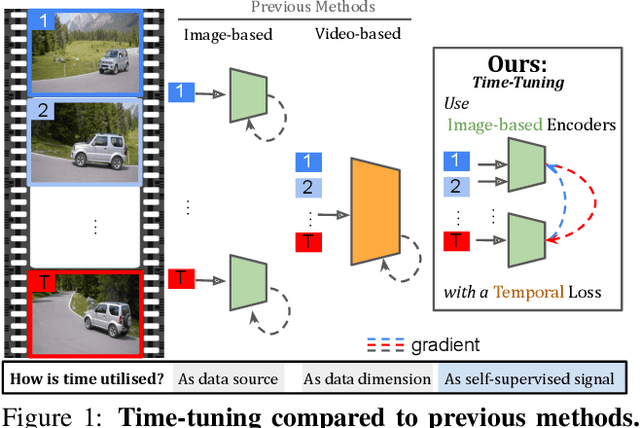

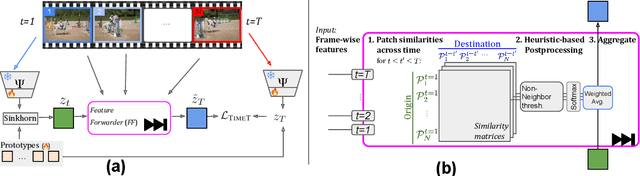
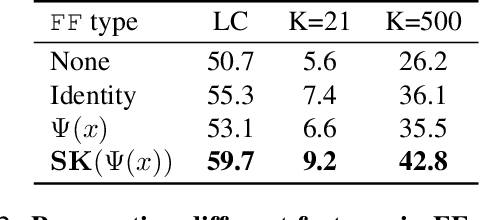
Spatially dense self-supervised learning is a rapidly growing problem domain with promising applications for unsupervised segmentation and pretraining for dense downstream tasks. Despite the abundance of temporal data in the form of videos, this information-rich source has been largely overlooked. Our paper aims to address this gap by proposing a novel approach that incorporates temporal consistency in dense self-supervised learning. While methods designed solely for images face difficulties in achieving even the same performance on videos, our method improves not only the representation quality for videos-but also images. Our approach, which we call time-tuning, starts from image-pretrained models and fine-tunes them with a novel self-supervised temporal-alignment clustering loss on unlabeled videos. This effectively facilitates the transfer of high-level information from videos to image representations. Time-tuning improves the state-of-the-art by 8-10% for unsupervised semantic segmentation on videos and matches it for images. We believe this method paves the way for further self-supervised scaling by leveraging the abundant availability of videos. The implementation can be found here : https://github.com/SMSD75/Timetuning
Diffusion Posterior Illumination for Ambiguity-aware Inverse Rendering
Sep 30, 2023Inverse rendering, the process of inferring scene properties from images, is a challenging inverse problem. The task is ill-posed, as many different scene configurations can give rise to the same image. Most existing solutions incorporate priors into the inverse-rendering pipeline to encourage plausible solutions, but they do not consider the inherent ambiguities and the multi-modal distribution of possible decompositions. In this work, we propose a novel scheme that integrates a denoising diffusion probabilistic model pre-trained on natural illumination maps into an optimization framework involving a differentiable path tracer. The proposed method allows sampling from combinations of illumination and spatially-varying surface materials that are, both, natural and explain the image observations. We further conduct an extensive comparative study of different priors on illumination used in previous work on inverse rendering. Our method excels in recovering materials and producing highly realistic and diverse environment map samples that faithfully explain the illumination of the input images.
Prior Mismatch and Adaptation in PnP-ADMM with a Nonconvex Convergence Analysis
Sep 29, 2023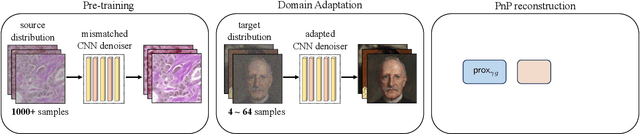
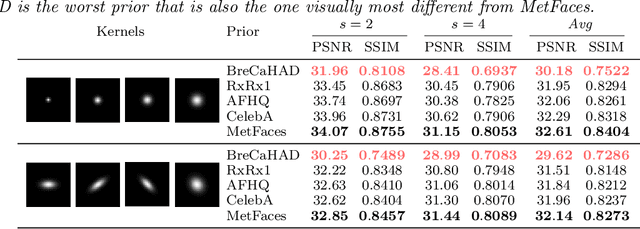

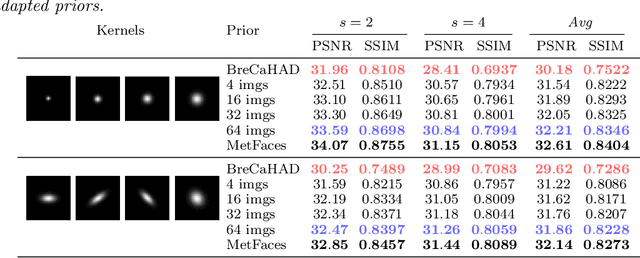
Plug-and-Play (PnP) priors is a widely-used family of methods for solving imaging inverse problems by integrating physical measurement models with image priors specified using image denoisers. PnP methods have been shown to achieve state-of-the-art performance when the prior is obtained using powerful deep denoisers. Despite extensive work on PnP, the topic of distribution mismatch between the training and testing data has often been overlooked in the PnP literature. This paper presents a set of new theoretical and numerical results on the topic of prior distribution mismatch and domain adaptation for alternating direction method of multipliers (ADMM) variant of PnP. Our theoretical result provides an explicit error bound for PnP-ADMM due to the mismatch between the desired denoiser and the one used for inference. Our analysis contributes to the work in the area by considering the mismatch under nonconvex data-fidelity terms and expansive denoisers. Our first set of numerical results quantifies the impact of the prior distribution mismatch on the performance of PnP-ADMM on the problem of image super-resolution. Our second set of numerical results considers a simple and effective domain adaption strategy that closes the performance gap due to the use of mismatched denoisers. Our results suggest the relative robustness of PnP-ADMM to prior distribution mismatch, while also showing that the performance gap can be significantly reduced with few training samples from the desired distribution.
Towards Design and Development of an ArUco Markers-Based Quantitative Surface Tactile Sensor
Oct 12, 2023

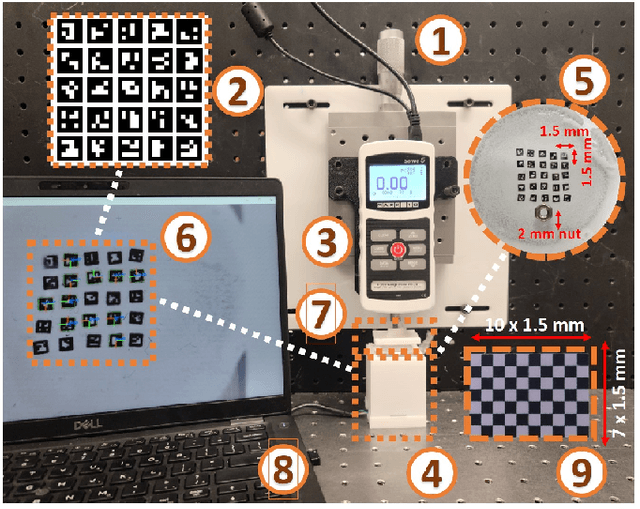
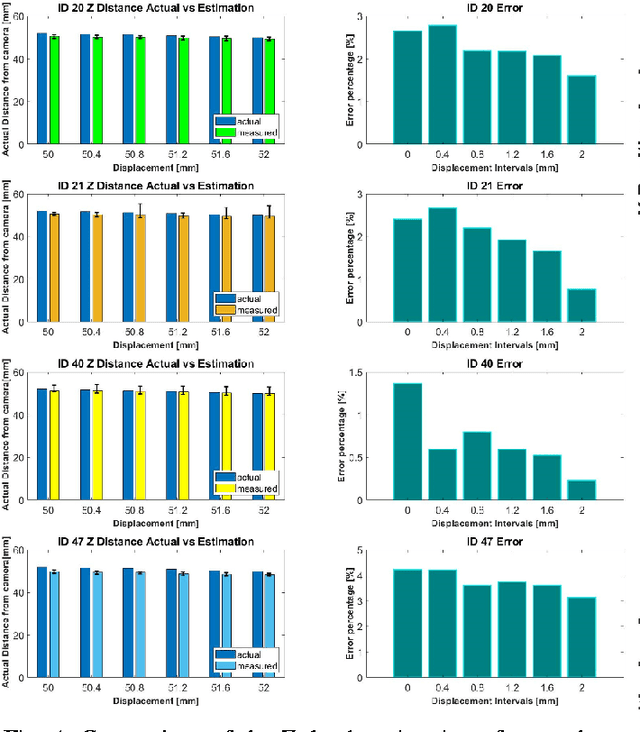
In this paper, with the goal of quantifying the qualitative image outputs of a Vision-based Tactile Sensor (VTS), we present the design, fabrication, and characterization of a novel Quantitative Surface Tactile Sensor (called QS-TS). QS-TS directly estimates the sensor's gel layer deformation in real-time enabling safe and autonomous tactile manipulation and servoing of delicate objects using robotic manipulators. The core of the proposed sensor is the utilization of miniature 1.5 mm x 1.5 mm synthetic square markers with inner binary patterns and a broad black border, called ArUco Markers. Each ArUco marker can provide real-time camera pose estimation that, in our design, is used as a quantitative measure for obtaining deformation of the QS-TS gel layer. Moreover, thanks to the use of ArUco markers, we propose a unique fabrication procedure that mitigates various challenges associated with the fabrication of the existing marker-based VTSs and offers an intuitive and less-arduous method for the construction of the VTS. Remarkably, the proposed fabrication facilitates the integration and adherence of markers with the gel layer to robustly and reliably obtain a quantitative measure of deformation in real-time regardless of the orientation of ArUco Markers. The performance and efficacy of the proposed QS-TS in estimating the deformation of the sensor's gel layer were experimentally evaluated and verified. Results demonstrate the phenomenal performance of the QS-TS in estimating the deformation of the gel layer with a relative error of <5%.
MotionDirector: Motion Customization of Text-to-Video Diffusion Models
Oct 12, 2023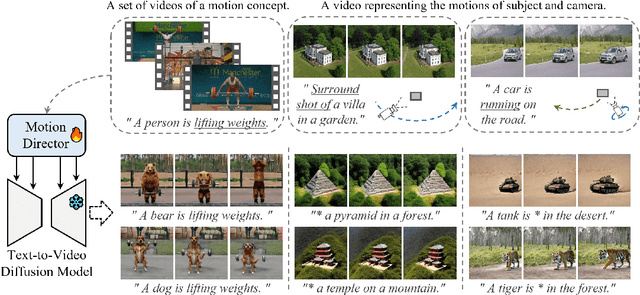
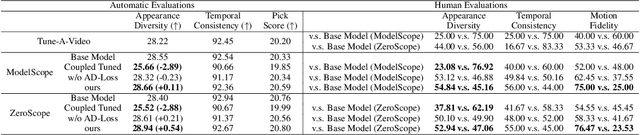


Large-scale pre-trained diffusion models have exhibited remarkable capabilities in diverse video generations. Given a set of video clips of the same motion concept, the task of Motion Customization is to adapt existing text-to-video diffusion models to generate videos with this motion. For example, generating a video with a car moving in a prescribed manner under specific camera movements to make a movie, or a video illustrating how a bear would lift weights to inspire creators. Adaptation methods have been developed for customizing appearance like subject or style, yet unexplored for motion. It is straightforward to extend mainstream adaption methods for motion customization, including full model tuning, parameter-efficient tuning of additional layers, and Low-Rank Adaptions (LoRAs). However, the motion concept learned by these methods is often coupled with the limited appearances in the training videos, making it difficult to generalize the customized motion to other appearances. To overcome this challenge, we propose MotionDirector, with a dual-path LoRAs architecture to decouple the learning of appearance and motion. Further, we design a novel appearance-debiased temporal loss to mitigate the influence of appearance on the temporal training objective. Experimental results show the proposed method can generate videos of diverse appearances for the customized motions. Our method also supports various downstream applications, such as the mixing of different videos with their appearance and motion respectively, and animating a single image with customized motions. Our code and model weights will be released.
Hard View Selection for Contrastive Learning
Oct 05, 2023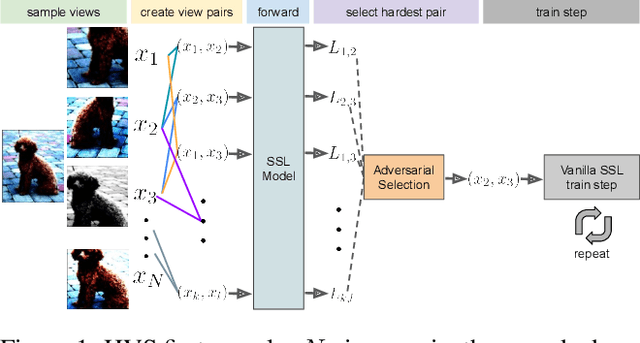
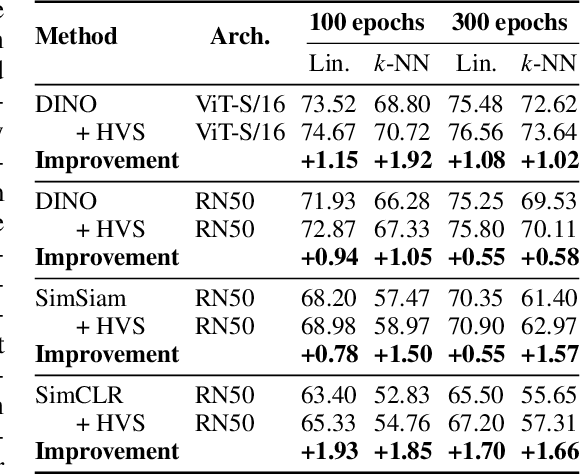
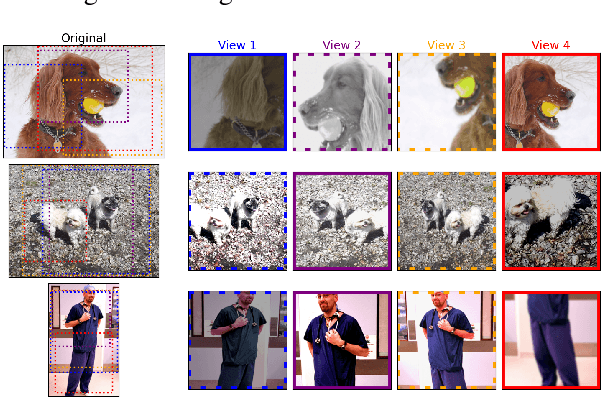
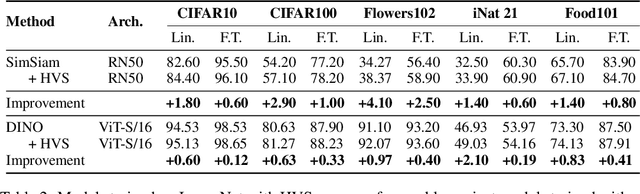
Many Contrastive Learning (CL) methods train their models to be invariant to different "views" of an image input for which a good data augmentation pipeline is crucial. While considerable efforts were directed towards improving pre-text tasks, architectures, or robustness (e.g., Siamese networks or teacher-softmax centering), the majority of these methods remain strongly reliant on the random sampling of operations within the image augmentation pipeline, such as the random resized crop or color distortion operation. In this paper, we argue that the role of the view generation and its effect on performance has so far received insufficient attention. To address this, we propose an easy, learning-free, yet powerful Hard View Selection (HVS) strategy designed to extend the random view generation to expose the pretrained model to harder samples during CL training. It encompasses the following iterative steps: 1) randomly sample multiple views and create pairs of two views, 2) run forward passes for each view pair on the currently trained model, 3) adversarially select the pair yielding the worst loss, and 4) run the backward pass with the selected pair. In our empirical analysis we show that under the hood, HVS increases task difficulty by controlling the Intersection over Union of views during pretraining. With only 300-epoch pretraining, HVS is able to closely rival the 800-epoch DINO baseline which remains very favorable even when factoring in the slowdown induced by the additional forwards of HVS. Additionally, HVS consistently achieves accuracy improvements on ImageNet between 0.55% and 1.9% on linear evaluation and similar improvements on transfer tasks across multiple CL methods, such as DINO, SimSiam, and SimCLR.
Channel Vision Transformers: An Image Is Worth C x 16 x 16 Words
Sep 28, 2023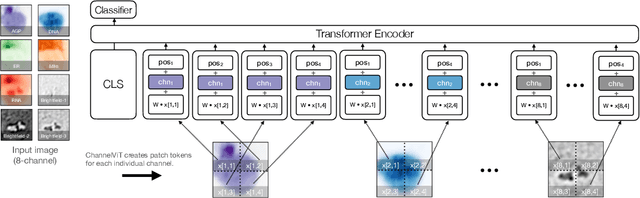
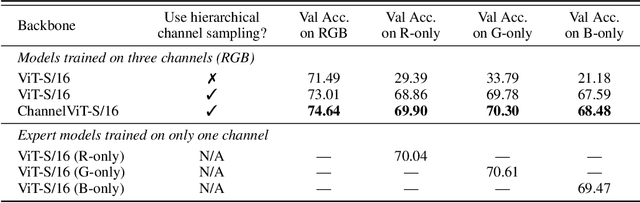
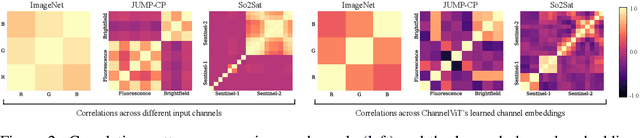
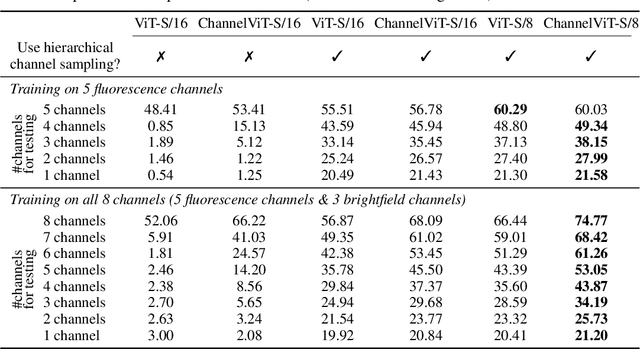
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors.
Uncertainty Quantification for Eosinophil Segmentation
Sep 28, 2023Eosinophilic Esophagitis (EoE) is an allergic condition increasing in prevalence. To diagnose EoE, pathologists must find 15 or more eosinophils within a single high-power field (400X magnification). Determining whether or not a patient has EoE can be an arduous process and any medical imaging approaches used to assist diagnosis must consider both efficiency and precision. We propose an improvement of Adorno et al's approach for quantifying eosinphils using deep image segmentation. Our new approach leverages Monte Carlo Dropout, a common approach in deep learning to reduce overfitting, to provide uncertainty quantification on current deep learning models. The uncertainty can be visualized in an output image to evaluate model performance, provide insight to how deep learning algorithms function, and assist pathologists in identifying eosinophils.
Logarithm-transform aided Gaussian Sampling for Few-Shot Learning
Sep 28, 2023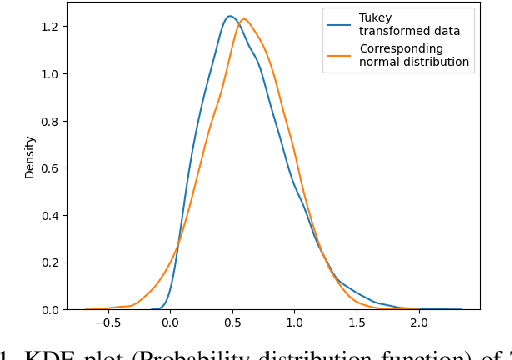
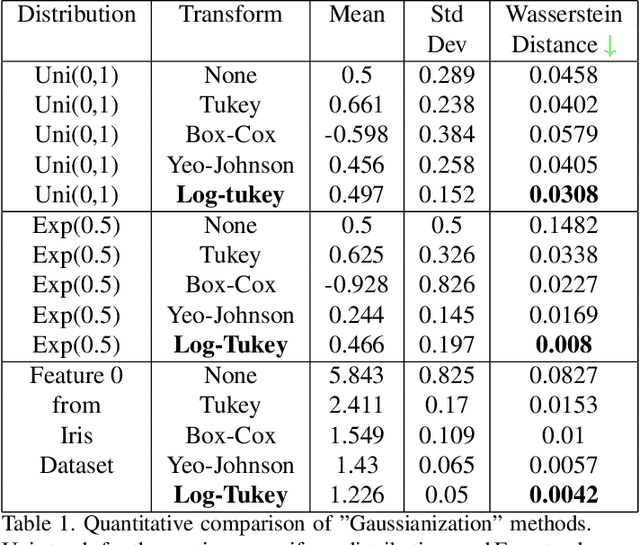
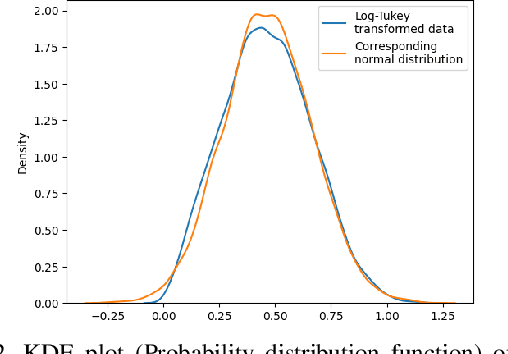
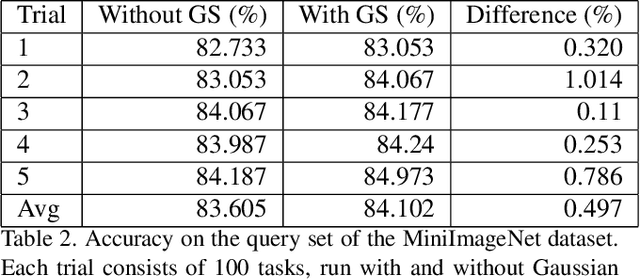
Few-shot image classification has recently witnessed the rise of representation learning being utilised for models to adapt to new classes using only a few training examples. Therefore, the properties of the representations, such as their underlying probability distributions, assume vital importance. Representations sampled from Gaussian distributions have been used in recent works, [19] to train classifiers for few-shot classification. These methods rely on transforming the distributions of experimental data to approximate Gaussian distributions for their functioning. In this paper, I propose a novel Gaussian transform, that outperforms existing methods on transforming experimental data into Gaussian-like distributions. I then utilise this novel transformation for few-shot image classification and show significant gains in performance, while sampling lesser data.