 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Risk Controlled Image Retrieval
Jul 14, 2023
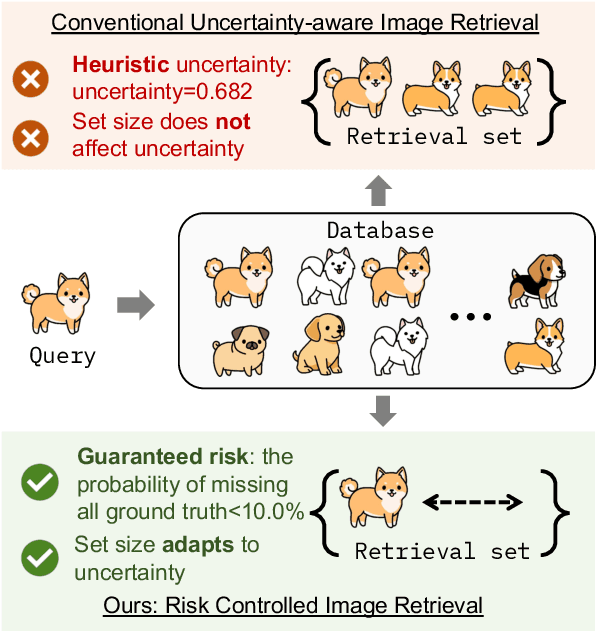
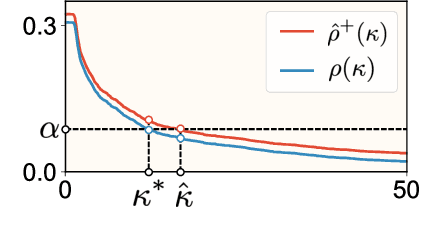
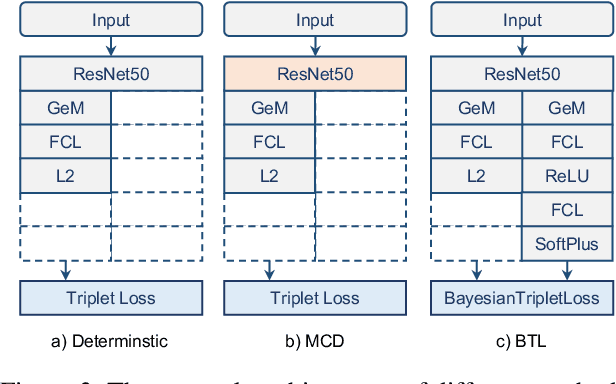
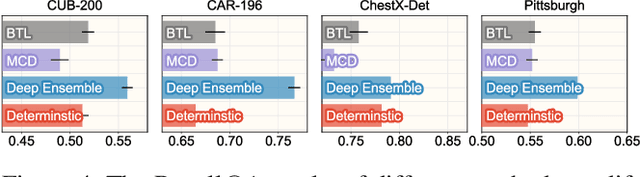
Most image retrieval research focuses on improving predictive performance, but they may fall short in scenarios where the reliability of the prediction is crucial. Though uncertainty quantification can help by assessing uncertainty for query and database images, this method can provide only a heuristic estimate rather than an guarantee. To address these limitations, we present Risk Controlled Image Retrieval (RCIR), which generates retrieval sets that are guaranteed to contain the ground truth samples with a predefined probability. RCIR can be easily plugged into any image retrieval method, agnostic to data distribution and model selection. To the best of our knowledge, this is the first work that provides coverage guarantees for image retrieval. The validity and efficiency of RCIR is demonstrated on four real-world image retrieval datasets, including the Stanford CAR-196 (Krause et al. 2013), CUB-200 (Wah et al. 2011), the Pittsburgh dataset (Torii et al. 2013) and the ChestX-Det dataset (Lian et al. 2021).
Deep Neural Networks Fused with Textures for Image Classification
Aug 03, 2023Fine-grained image classification (FGIC) is a challenging task in computer vision for due to small visual differences among inter-subcategories, but, large intra-class variations. Deep learning methods have achieved remarkable success in solving FGIC. In this paper, we propose a fusion approach to address FGIC by combining global texture with local patch-based information. The first pipeline extracts deep features from various fixed-size non-overlapping patches and encodes features by sequential modelling using the long short-term memory (LSTM). Another path computes image-level textures at multiple scales using the local binary patterns (LBP). The advantages of both streams are integrated to represent an efficient feature vector for image classification. The method is tested on eight datasets representing the human faces, skin lesions, food dishes, marine lives, etc. using four standard backbone CNNs. Our method has attained better classification accuracy over existing methods with notable margins.
* 14 pages, 6 figures, 4 tables, conference
ZRIGF: An Innovative Multimodal Framework for Zero-Resource Image-Grounded Dialogue Generation
Aug 02, 2023
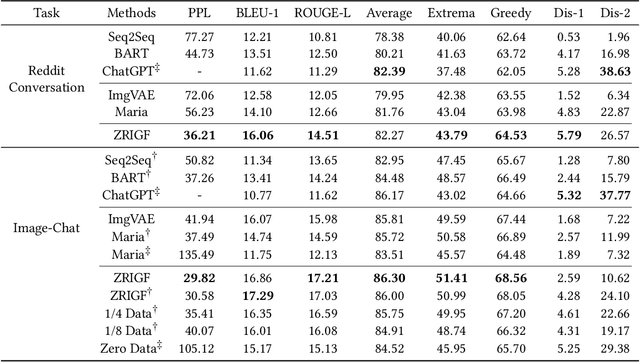
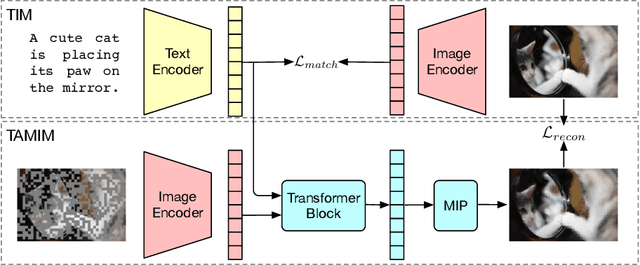

Image-grounded dialogue systems benefit greatly from integrating visual information, resulting in high-quality response generation. However, current models struggle to effectively utilize such information in zero-resource scenarios, mainly due to the disparity between image and text modalities. To overcome this challenge, we propose an innovative multimodal framework, called ZRIGF, which assimilates image-grounded information for dialogue generation in zero-resource situations. ZRIGF implements a two-stage learning strategy, comprising contrastive pre-training and generative pre-training. Contrastive pre-training includes a text-image matching module that maps images and texts into a unified encoded vector space, along with a text-assisted masked image modeling module that preserves pre-training visual features and fosters further multimodal feature alignment. Generative pre-training employs a multimodal fusion module and an information transfer module to produce insightful responses based on harmonized multimodal representations. Comprehensive experiments conducted on both text-based and image-grounded dialogue datasets demonstrate ZRIGF's efficacy in generating contextually pertinent and informative responses. Furthermore, we adopt a fully zero-resource scenario in the image-grounded dialogue dataset to demonstrate our framework's robust generalization capabilities in novel domains. The code is available at https://github.com/zhangbo-nlp/ZRIGF.
MedSyn: Text-guided Anatomy-aware Synthesis of High-Fidelity 3D CT Images
Oct 06, 2023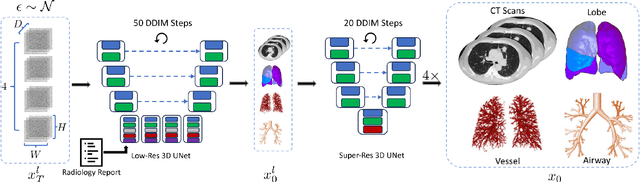
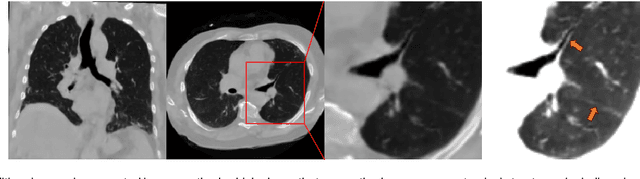
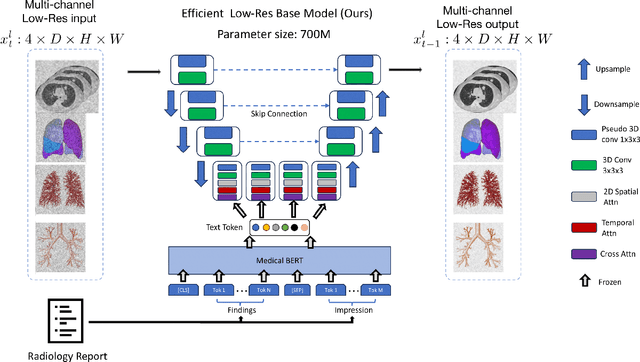
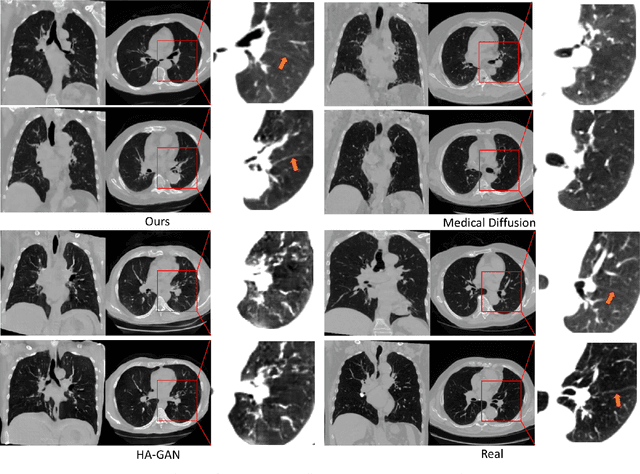
This paper introduces an innovative methodology for producing high-quality 3D lung CT images guided by textual information. While diffusion-based generative models are increasingly used in medical imaging, current state-of-the-art approaches are limited to low-resolution outputs and underutilize radiology reports' abundant information. The radiology reports can enhance the generation process by providing additional guidance and offering fine-grained control over the synthesis of images. Nevertheless, expanding text-guided generation to high-resolution 3D images poses significant memory and anatomical detail-preserving challenges. Addressing the memory issue, we introduce a hierarchical scheme that uses a modified UNet architecture. We start by synthesizing low-resolution images conditioned on the text, serving as a foundation for subsequent generators for complete volumetric data. To ensure the anatomical plausibility of the generated samples, we provide further guidance by generating vascular, airway, and lobular segmentation masks in conjunction with the CT images. The model demonstrates the capability to use textual input and segmentation tasks to generate synthesized images. The results of comparative assessments indicate that our approach exhibits superior performance compared to the most advanced models based on GAN and diffusion techniques, especially in accurately retaining crucial anatomical features such as fissure lines, airways, and vascular structures. This innovation introduces novel possibilities. This study focuses on two main objectives: (1) the development of a method for creating images based on textual prompts and anatomical components, and (2) the capability to generate new images conditioning on anatomical elements. The advancements in image generation can be applied to enhance numerous downstream tasks.
CUPre: Cross-domain Unsupervised Pre-training for Few-Shot Cell Segmentation
Oct 06, 2023While pre-training on object detection tasks, such as Common Objects in Contexts (COCO) [1], could significantly boost the performance of cell segmentation, it still consumes on massive fine-annotated cell images [2] with bounding boxes, masks, and cell types for every cell in every image, to fine-tune the pre-trained model. To lower the cost of annotation, this work considers the problem of pre-training DNN models for few-shot cell segmentation, where massive unlabeled cell images are available but only a small proportion is annotated. Hereby, we propose Cross-domain Unsupervised Pre-training, namely CUPre, transferring the capability of object detection and instance segmentation for common visual objects (learned from COCO) to the visual domain of cells using unlabeled images. Given a standard COCO pre-trained network with backbone, neck, and head modules, CUPre adopts an alternate multi-task pre-training (AMT2) procedure with two sub-tasks -- in every iteration of pre-training, AMT2 first trains the backbone with cell images from multiple cell datasets via unsupervised momentum contrastive learning (MoCo) [3], and then trains the whole model with vanilla COCO datasets via instance segmentation. After pre-training, CUPre fine-tunes the whole model on the cell segmentation task using a few annotated images. We carry out extensive experiments to evaluate CUPre using LIVECell [2] and BBBC038 [4] datasets in few-shot instance segmentation settings. The experiment shows that CUPre can outperform existing pre-training methods, achieving the highest average precision (AP) for few-shot cell segmentation and detection.
An Algorithm to Train Unrestricted Sequential Discrete Morphological Neural Networks
Oct 06, 2023With the advent of deep learning, there have been attempts to insert mathematical morphology (MM) operators into convolutional neural networks (CNN), and the most successful endeavor to date has been the morphological neural networks (MNN). Although MNN have performed better than CNN in solving some problems, they inherit their black-box nature. Furthermore, in the case of binary images, they are approximations, which loose the Boolean lattice structure of MM operators and, thus, it is not possible to represent a specific class of W-operators with desired properties. In a recent work, we proposed the Discrete Morphological Neural Networks (DMNN) for binary image transformation to represent specific classes of W-operators and estimate them via machine learning. We also proposed a stochastic lattice gradient descent algorithm (SLGDA) to learn the parameters of Canonical Discrete Morphological Neural Networks (CDMNN), whose architecture is composed only of operators that can be decomposed as the supremum, infimum, and complement of erosions and dilations. In this paper, we propose an algorithm to learn unrestricted sequential DMNN (USDMNN), whose architecture is given by the composition of general W-operators. We consider the representation of a W-operator by its characteristic Boolean function, and then learn it via a SLGDA in the Boolean lattice of functions. Although both the CDMNN and USDMNN have the Boolean lattice structure, USDMNN are not as dependent on prior information about the problem at hand, and may be more suitable in instances in which the practitioner does not have strong domain knowledge. We illustrate the algorithm in a practical example.
SITTA: A Semantic Image-Text Alignment for Image Captioning
Jul 10, 2023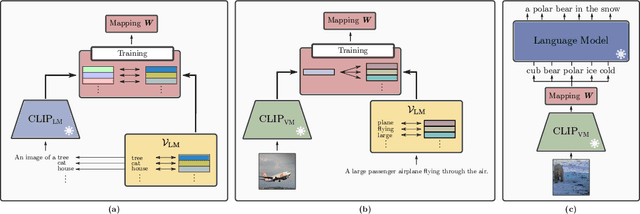
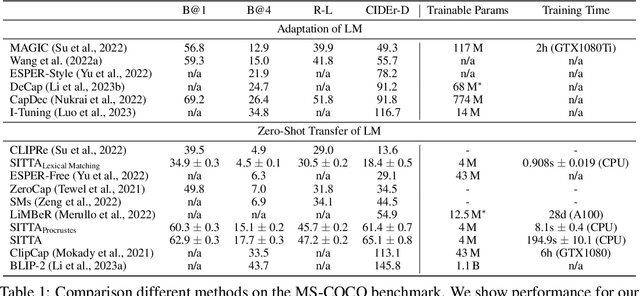

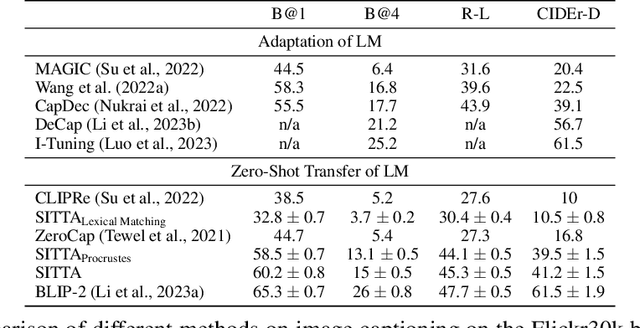
Textual and semantic comprehension of images is essential for generating proper captions. The comprehension requires detection of objects, modeling of relations between them, an assessment of the semantics of the scene and, finally, representing the extracted knowledge in a language space. To achieve rich language capabilities while ensuring good image-language mappings, pretrained language models (LMs) were conditioned on pretrained multi-modal (image-text) models that allow for image inputs. This requires an alignment of the image representation of the multi-modal model with the language representations of a generative LM. However, it is not clear how to best transfer semantics detected by the vision encoder of the multi-modal model to the LM. We introduce two novel ways of constructing a linear mapping that successfully transfers semantics between the embedding spaces of the two pretrained models. The first aligns the embedding space of the multi-modal language encoder with the embedding space of the pretrained LM via token correspondences. The latter leverages additional data that consists of image-text pairs to construct the mapping directly from vision to language space. Using our semantic mappings, we unlock image captioning for LMs without access to gradient information. By using different sources of data we achieve strong captioning performance on MS-COCO and Flickr30k datasets. Even in the face of limited data, our method partly exceeds the performance of other zero-shot and even finetuned competitors. Our ablation studies show that even LMs at a scale of merely 250M parameters can generate decent captions employing our semantic mappings. Our approach makes image captioning more accessible for institutions with restricted computational resources.
Learning Bottleneck Transformer for Event Image-Voxel Feature Fusion based Classification
Aug 23, 2023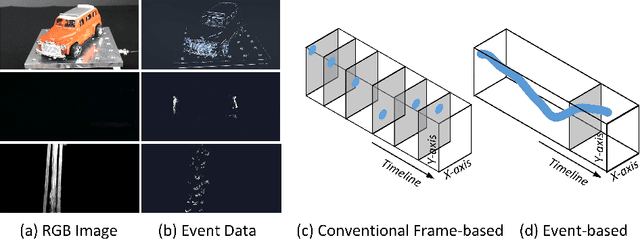

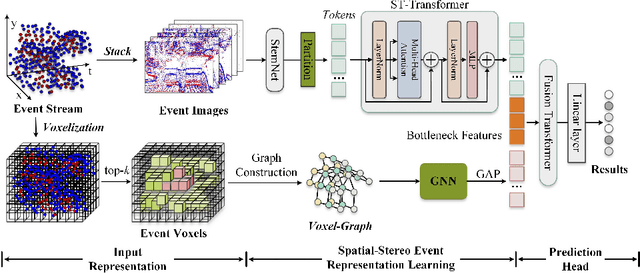

Recognizing target objects using an event-based camera draws more and more attention in recent years. Existing works usually represent the event streams into point-cloud, voxel, image, etc, and learn the feature representations using various deep neural networks. Their final results may be limited by the following factors: monotonous modal expressions and the design of the network structure. To address the aforementioned challenges, this paper proposes a novel dual-stream framework for event representation, extraction, and fusion. This framework simultaneously models two common representations: event images and event voxels. By utilizing Transformer and Structured Graph Neural Network (GNN) architectures, spatial information and three-dimensional stereo information can be learned separately. Additionally, a bottleneck Transformer is introduced to facilitate the fusion of the dual-stream information. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance on two widely used event-based classification datasets. The source code of this work is available at: \url{https://github.com/Event-AHU/EFV_event_classification}
Robust estimation of exposure ratios in multi-exposure image stacks
Aug 12, 2023

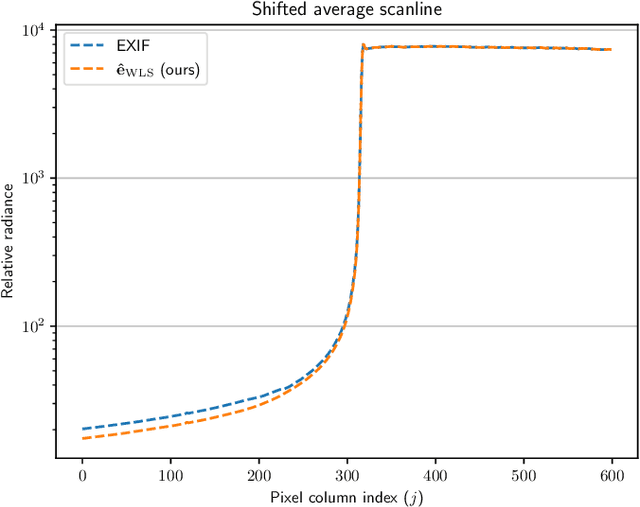
Merging multi-exposure image stacks into a high dynamic range (HDR) image requires knowledge of accurate exposure times. When exposure times are inaccurate, for example, when they are extracted from a camera's EXIF metadata, the reconstructed HDR images reveal banding artifacts at smooth gradients. To remedy this, we propose to estimate exposure ratios directly from the input images. We derive the exposure time estimation as an optimization problem, in which pixels are selected from pairs of exposures to minimize estimation error caused by camera noise. When pixel values are represented in the logarithmic domain, the problem can be solved efficiently using a linear solver. We demonstrate that the estimation can be easily made robust to pixel misalignment caused by camera or object motion by collecting pixels from multiple spatial tiles. The proposed automatic exposure estimation and alignment eliminates banding artifacts in popular datasets and is essential for applications that require physically accurate reconstructions, such as measuring the modulation transfer function of a display. The code for the method is available.
* 11 pages, 11 figures, journal
FashionFlow: Leveraging Diffusion Models for Dynamic Fashion Video Synthesis from Static Imagery
Sep 29, 2023Our study introduces a new image-to-video generator called FashionFlow. By utilising a diffusion model, we are able to create short videos from still images. Our approach involves developing and connecting relevant components with the diffusion model, which sets our work apart. The components include the use of pseudo-3D convolutional layers to generate videos efficiently. VAE and CLIP encoders capture vital characteristics from still images to influence the diffusion model. Our research demonstrates a successful synthesis of fashion videos featuring models posing from various angles, showcasing the fit and appearance of the garment. Our findings hold great promise for improving and enhancing the shopping experience for the online fashion industry.