 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CCD-3DR: Consistent Conditioning in Diffusion for Single-Image 3D Reconstruction
Aug 15, 2023
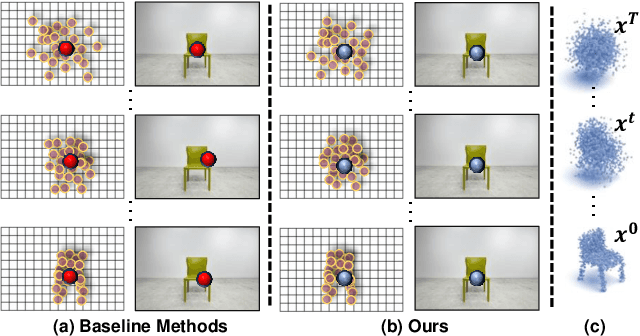
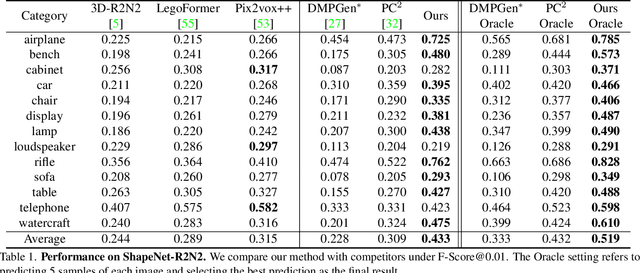
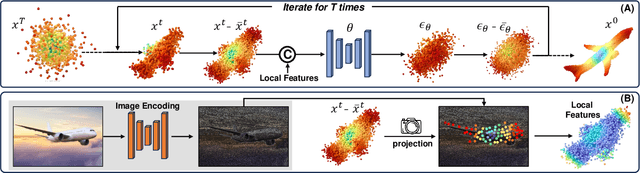
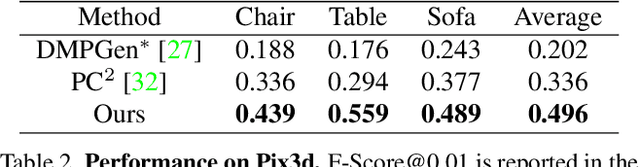
In this paper, we present a novel shape reconstruction method leveraging diffusion model to generate 3D sparse point cloud for the object captured in a single RGB image. Recent methods typically leverage global embedding or local projection-based features as the condition to guide the diffusion model. However, such strategies fail to consistently align the denoised point cloud with the given image, leading to unstable conditioning and inferior performance. In this paper, we present CCD-3DR, which exploits a novel centered diffusion probabilistic model for consistent local feature conditioning. We constrain the noise and sampled point cloud from the diffusion model into a subspace where the point cloud center remains unchanged during the forward diffusion process and reverse process. The stable point cloud center further serves as an anchor to align each point with its corresponding local projection-based features. Extensive experiments on synthetic benchmark ShapeNet-R2N2 demonstrate that CCD-3DR outperforms all competitors by a large margin, with over 40% improvement. We also provide results on real-world dataset Pix3D to thoroughly demonstrate the potential of CCD-3DR in real-world applications. Codes will be released soon
Robust estimation of exposure ratios in multi-exposure image stacks
Aug 12, 2023

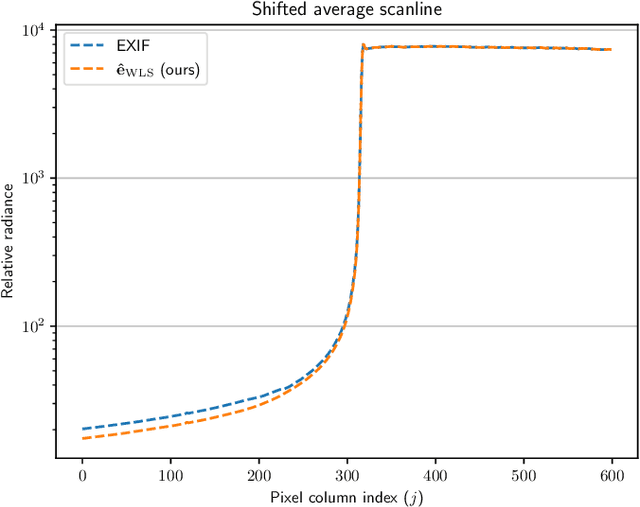
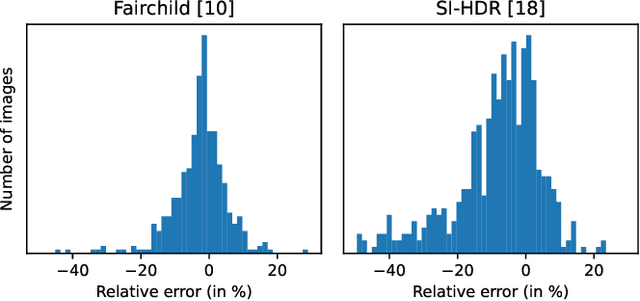
Merging multi-exposure image stacks into a high dynamic range (HDR) image requires knowledge of accurate exposure times. When exposure times are inaccurate, for example, when they are extracted from a camera's EXIF metadata, the reconstructed HDR images reveal banding artifacts at smooth gradients. To remedy this, we propose to estimate exposure ratios directly from the input images. We derive the exposure time estimation as an optimization problem, in which pixels are selected from pairs of exposures to minimize estimation error caused by camera noise. When pixel values are represented in the logarithmic domain, the problem can be solved efficiently using a linear solver. We demonstrate that the estimation can be easily made robust to pixel misalignment caused by camera or object motion by collecting pixels from multiple spatial tiles. The proposed automatic exposure estimation and alignment eliminates banding artifacts in popular datasets and is essential for applications that require physically accurate reconstructions, such as measuring the modulation transfer function of a display. The code for the method is available.
* 11 pages, 11 figures, journal
Deepfake Image Generation for Improved Brain Tumor Segmentation
Jul 26, 2023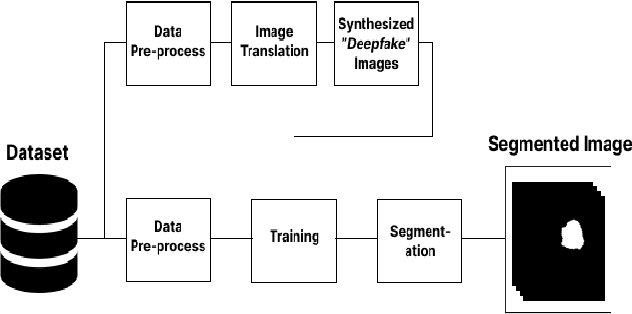

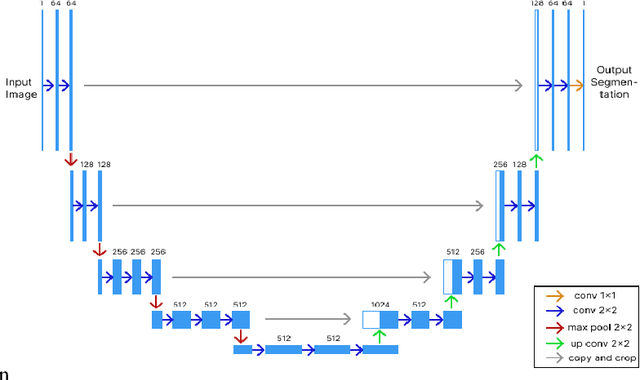
As the world progresses in technology and health, awareness of disease by revealing asymptomatic signs improves. It is important to detect and treat tumors in early stage as it can be life-threatening. Computer-aided technologies are used to overcome lingering limitations facing disease diagnosis, while brain tumor segmentation remains a difficult process, especially when multi-modality data is involved. This is mainly attributed to ineffective training due to lack of data and corresponding labelling. This work investigates the feasibility of employing deep-fake image generation for effective brain tumor segmentation. To this end, a Generative Adversarial Network was used for image-to-image translation for increasing dataset size, followed by image segmentation using a U-Net-based convolutional neural network trained with deepfake images. Performance of the proposed approach is compared with ground truth of four publicly available datasets. Results show improved performance in terms of image segmentation quality metrics, and could potentially assist when training with limited data.
* 6 pages, 8 figures, 2 tables, conference paper
LAVIE: High-Quality Video Generation with Cascaded Latent Diffusion Models
Sep 27, 2023
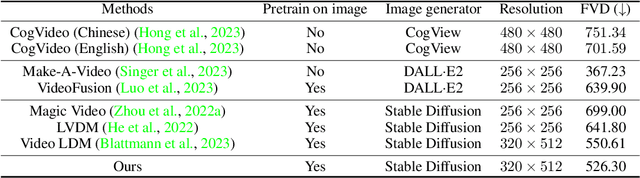

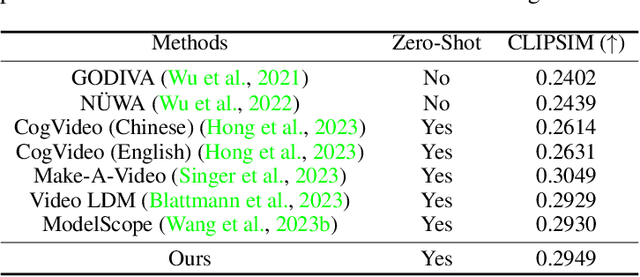
This work aims to learn a high-quality text-to-video (T2V) generative model by leveraging a pre-trained text-to-image (T2I) model as a basis. It is a highly desirable yet challenging task to simultaneously a) accomplish the synthesis of visually realistic and temporally coherent videos while b) preserving the strong creative generation nature of the pre-trained T2I model. To this end, we propose LaVie, an integrated video generation framework that operates on cascaded video latent diffusion models, comprising a base T2V model, a temporal interpolation model, and a video super-resolution model. Our key insights are two-fold: 1) We reveal that the incorporation of simple temporal self-attentions, coupled with rotary positional encoding, adequately captures the temporal correlations inherent in video data. 2) Additionally, we validate that the process of joint image-video fine-tuning plays a pivotal role in producing high-quality and creative outcomes. To enhance the performance of LaVie, we contribute a comprehensive and diverse video dataset named Vimeo25M, consisting of 25 million text-video pairs that prioritize quality, diversity, and aesthetic appeal. Extensive experiments demonstrate that LaVie achieves state-of-the-art performance both quantitatively and qualitatively. Furthermore, we showcase the versatility of pre-trained LaVie models in various long video generation and personalized video synthesis applications.
Dynamic Shuffle: An Efficient Channel Mixture Method
Oct 04, 2023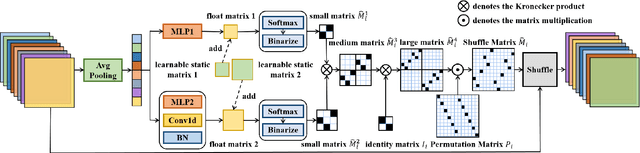
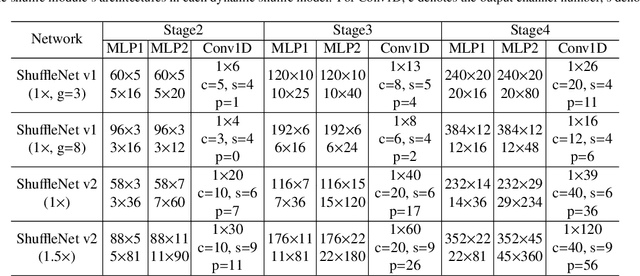
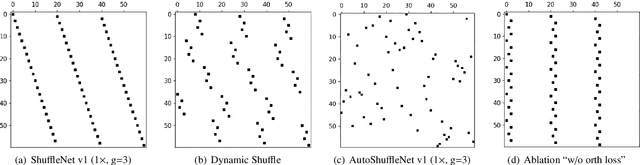
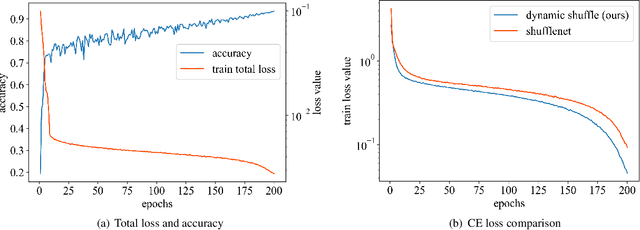
The redundancy of Convolutional neural networks not only depends on weights but also depends on inputs. Shuffling is an efficient operation for mixing channel information but the shuffle order is usually pre-defined. To reduce the data-dependent redundancy, we devise a dynamic shuffle module to generate data-dependent permutation matrices for shuffling. Since the dimension of permutation matrix is proportional to the square of the number of input channels, to make the generation process efficiently, we divide the channels into groups and generate two shared small permutation matrices for each group, and utilize Kronecker product and cross group shuffle to obtain the final permutation matrices. To make the generation process learnable, based on theoretical analysis, softmax, orthogonal regularization, and binarization are employed to asymptotically approximate the permutation matrix. Dynamic shuffle adaptively mixes channel information with negligible extra computation and memory occupancy. Experiment results on image classification benchmark datasets CIFAR-10, CIFAR-100, Tiny ImageNet and ImageNet have shown that our method significantly increases ShuffleNets' performance. Adding dynamic generated matrix with learnable static matrix, we further propose static-dynamic-shuffle and show that it can serve as a lightweight replacement of ordinary pointwise convolution.
Photorealistic and Identity-Preserving Image-Based Emotion Manipulation with Latent Diffusion Models
Aug 06, 2023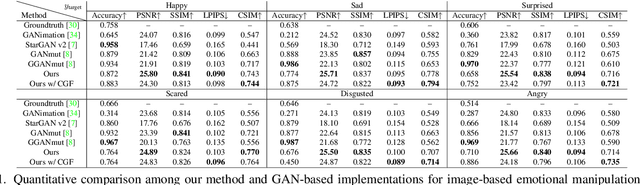


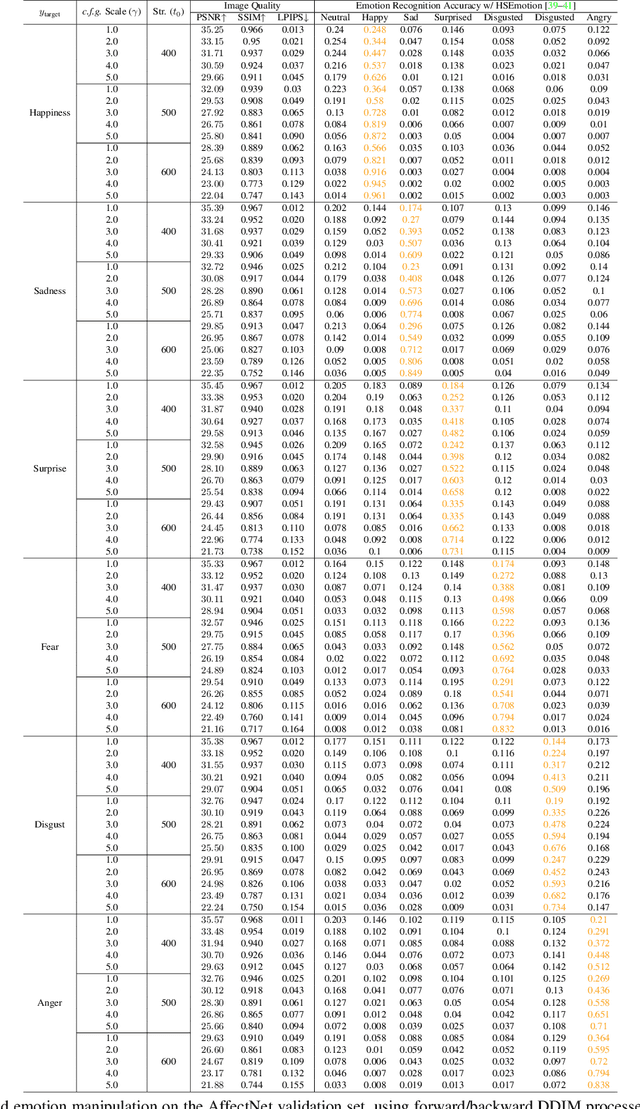
In this paper, we investigate the emotion manipulation capabilities of diffusion models with "in-the-wild" images, a rather unexplored application area relative to the vast and rapidly growing literature for image-to-image translation tasks. Our proposed method encapsulates several pieces of prior work, with the most important being Latent Diffusion models and text-driven manipulation with CLIP latents. We conduct extensive qualitative and quantitative evaluations on AffectNet, demonstrating the superiority of our approach in terms of image quality and realism, while achieving competitive results relative to emotion translation compared to a variety of GAN-based counterparts. Code is released as a publicly available repo.
Information Flow in Self-Supervised Learning
Sep 29, 2023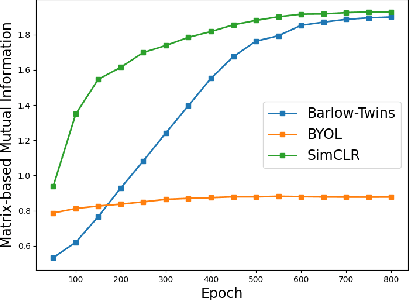
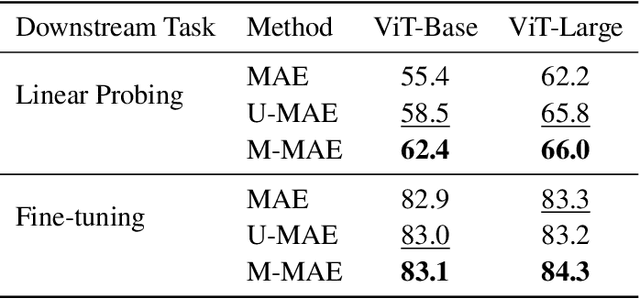


In this paper, we provide a comprehensive toolbox for understanding and enhancing self-supervised learning (SSL) methods through the lens of matrix information theory. Specifically, by leveraging the principles of matrix mutual information and joint entropy, we offer a unified analysis for both contrastive and feature decorrelation based methods. Furthermore, we propose the matrix variational masked auto-encoder (M-MAE) method, grounded in matrix information theory, as an enhancement to masked image modeling. The empirical evaluations underscore the effectiveness of M-MAE compared with the state-of-the-art methods, including a 3.9% improvement in linear probing ViT-Base, and a 1% improvement in fine-tuning ViT-Large, both on ImageNet.
Ano-SuPs: Multi-size anomaly detection for manufactured products by identifying suspected patches
Sep 20, 2023Image-based systems have gained popularity owing to their capacity to provide rich manufacturing status information, low implementation costs and high acquisition rates. However, the complexity of the image background and various anomaly patterns pose new challenges to existing matrix decomposition methods, which are inadequate for modeling requirements. Moreover, the uncertainty of the anomaly can cause anomaly contamination problems, making the designed model and method highly susceptible to external disturbances. To address these challenges, we propose a two-stage strategy anomaly detection method that detects anomalies by identifying suspected patches (Ano-SuPs). Specifically, we propose to detect the patches with anomalies by reconstructing the input image twice: the first step is to obtain a set of normal patches by removing those suspected patches, and the second step is to use those normal patches to refine the identification of the patches with anomalies. To demonstrate its effectiveness, we evaluate the proposed method systematically through simulation experiments and case studies. We further identified the key parameters and designed steps that impact the model's performance and efficiency.
Towards Saner Deep Image Registration
Jul 24, 2023

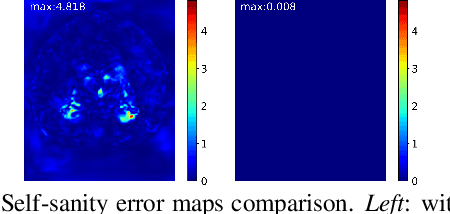
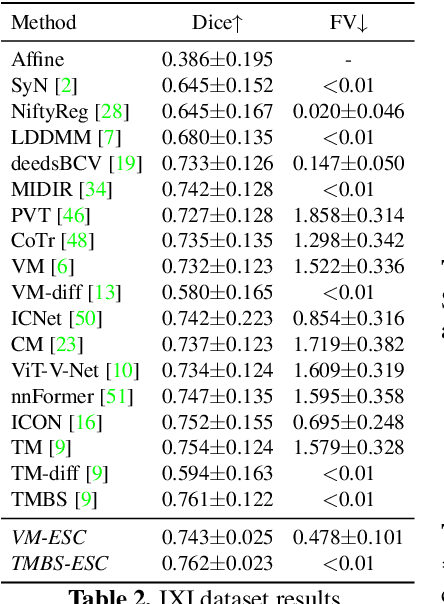
With recent advances in computing hardware and surges of deep-learning architectures, learning-based deep image registration methods have surpassed their traditional counterparts, in terms of metric performance and inference time. However, these methods focus on improving performance measurements such as Dice, resulting in less attention given to model behaviors that are equally desirable for registrations, especially for medical imaging. This paper investigates these behaviors for popular learning-based deep registrations under a sanity-checking microscope. We find that most existing registrations suffer from low inverse consistency and nondiscrimination of identical pairs due to overly optimized image similarities. To rectify these behaviors, we propose a novel regularization-based sanity-enforcer method that imposes two sanity checks on the deep model to reduce its inverse consistency errors and increase its discriminative power simultaneously. Moreover, we derive a set of theoretical guarantees for our sanity-checked image registration method, with experimental results supporting our theoretical findings and their effectiveness in increasing the sanity of models without sacrificing any performance. Our code and models are available at https://github.com/tuffr5/Saner-deep-registration.
Learning Bottleneck Transformer for Event Image-Voxel Feature Fusion based Classification
Aug 23, 2023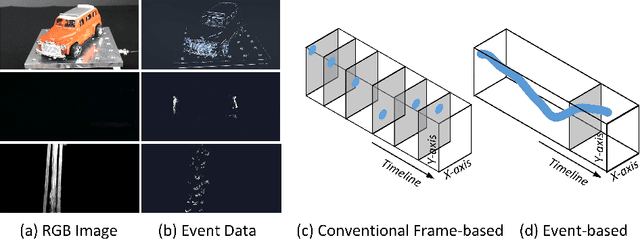

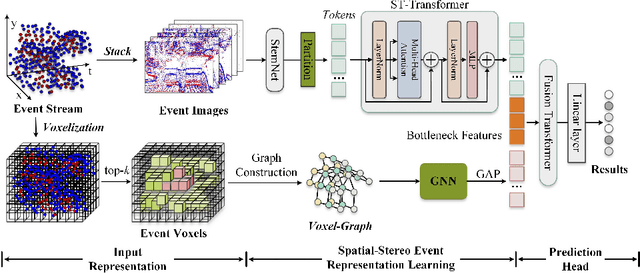

Recognizing target objects using an event-based camera draws more and more attention in recent years. Existing works usually represent the event streams into point-cloud, voxel, image, etc, and learn the feature representations using various deep neural networks. Their final results may be limited by the following factors: monotonous modal expressions and the design of the network structure. To address the aforementioned challenges, this paper proposes a novel dual-stream framework for event representation, extraction, and fusion. This framework simultaneously models two common representations: event images and event voxels. By utilizing Transformer and Structured Graph Neural Network (GNN) architectures, spatial information and three-dimensional stereo information can be learned separately. Additionally, a bottleneck Transformer is introduced to facilitate the fusion of the dual-stream information. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance on two widely used event-based classification datasets. The source code of this work is available at: \url{https://github.com/Event-AHU/EFV_event_classification}