 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Escher Meshes
Sep 28, 2023
This paper proposes a fully-automatic, text-guided generative method for producing periodic, repeating, tile-able 2D art, such as the one seen on floors, mosaics, ceramics, and the work of M.C. Escher. In contrast to the standard concept of a seamless texture, i.e., square images that are seamless when tiled, our method generates non-square tilings which comprise solely of repeating copies of the same object. It achieves this by optimizing both geometry and color of a 2D mesh, in order to generate a non-square tile in the shape and appearance of the desired object, with close to no additional background details. We enable geometric optimization of tilings by our key technical contribution: an unconstrained, differentiable parameterization of the space of all possible tileable shapes for a given symmetry group. Namely, we prove that modifying the laplacian used in a 2D mesh-mapping technique - Orbifold Tutte Embedding - can achieve all possible tiling configurations for a chosen planar symmetry group. We thus consider both the mesh's tile-shape and its texture as optimizable parameters, rendering the textured mesh via a differentiable renderer. We leverage a trained image diffusion model to define a loss on the resulting image, thereby updating the mesh's parameters based on its appearance matching the text prompt. We show our method is able to produce plausible, appealing results, with non-trivial tiles, for a variety of different periodic tiling patterns.
Stochastic Digital Twin for Copy Detection Patterns
Sep 28, 2023Copy detection patterns (CDP) present an efficient technique for product protection against counterfeiting. However, the complexity of studying CDP production variability often results in time-consuming and costly procedures, limiting CDP scalability. Recent advancements in computer modelling, notably the concept of a "digital twin" for printing-imaging channels, allow for enhanced scalability and the optimization of authentication systems. Yet, the development of an accurate digital twin is far from trivial. This paper extends previous research which modelled a printing-imaging channel using a machine learning-based digital twin for CDP. This model, built upon an information-theoretic framework known as "Turbo", demonstrated superior performance over traditional generative models such as CycleGAN and pix2pix. However, the emerging field of Denoising Diffusion Probabilistic Models (DDPM) presents a potential advancement in generative models due to its ability to stochastically model the inherent randomness of the printing-imaging process, and its impressive performance in image-to-image translation tasks. This study aims at comparing the capabilities of the Turbo framework and DDPM on the same CDP datasets, with the goal of establishing the real-world benefits of DDPM models for digital twin applications in CDP security. Furthermore, the paper seeks to evaluate the generative potential of the studied models in the context of mobile phone data acquisition. Despite the increased complexity of DDPM methods when compared to traditional approaches, our study highlights their advantages and explores their potential for future applications.
CCD-3DR: Consistent Conditioning in Diffusion for Single-Image 3D Reconstruction
Aug 15, 2023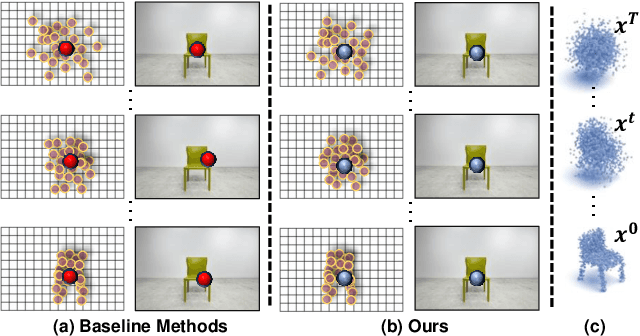
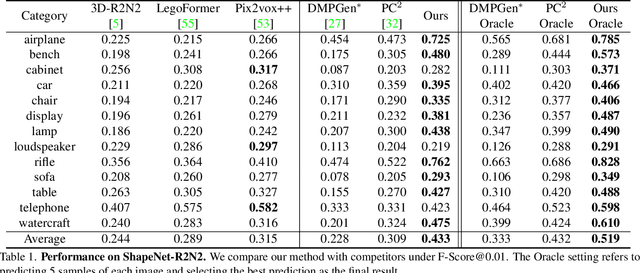
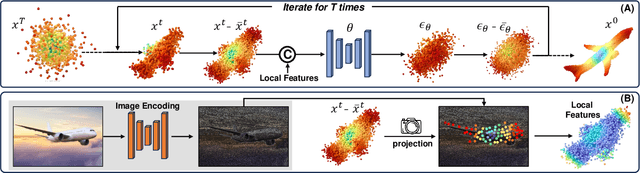
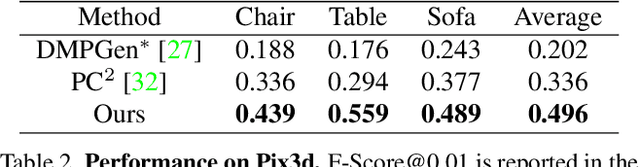
In this paper, we present a novel shape reconstruction method leveraging diffusion model to generate 3D sparse point cloud for the object captured in a single RGB image. Recent methods typically leverage global embedding or local projection-based features as the condition to guide the diffusion model. However, such strategies fail to consistently align the denoised point cloud with the given image, leading to unstable conditioning and inferior performance. In this paper, we present CCD-3DR, which exploits a novel centered diffusion probabilistic model for consistent local feature conditioning. We constrain the noise and sampled point cloud from the diffusion model into a subspace where the point cloud center remains unchanged during the forward diffusion process and reverse process. The stable point cloud center further serves as an anchor to align each point with its corresponding local projection-based features. Extensive experiments on synthetic benchmark ShapeNet-R2N2 demonstrate that CCD-3DR outperforms all competitors by a large margin, with over 40% improvement. We also provide results on real-world dataset Pix3D to thoroughly demonstrate the potential of CCD-3DR in real-world applications. Codes will be released soon
Deepfake Image Generation for Improved Brain Tumor Segmentation
Jul 26, 2023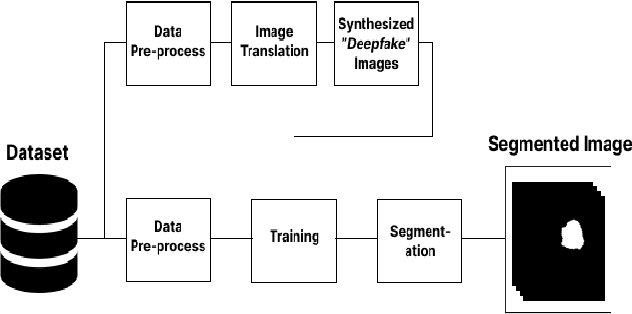

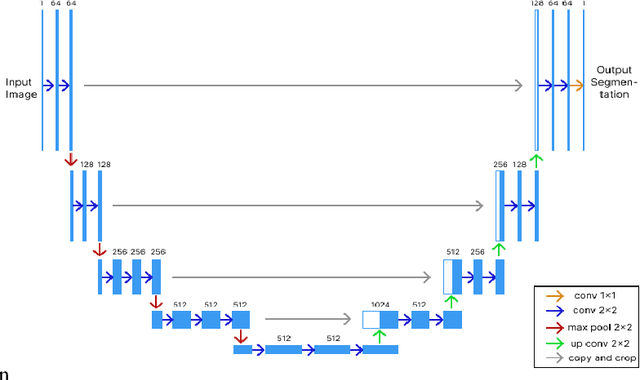
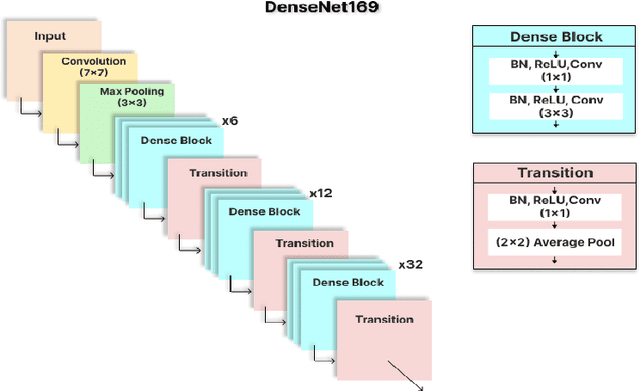
As the world progresses in technology and health, awareness of disease by revealing asymptomatic signs improves. It is important to detect and treat tumors in early stage as it can be life-threatening. Computer-aided technologies are used to overcome lingering limitations facing disease diagnosis, while brain tumor segmentation remains a difficult process, especially when multi-modality data is involved. This is mainly attributed to ineffective training due to lack of data and corresponding labelling. This work investigates the feasibility of employing deep-fake image generation for effective brain tumor segmentation. To this end, a Generative Adversarial Network was used for image-to-image translation for increasing dataset size, followed by image segmentation using a U-Net-based convolutional neural network trained with deepfake images. Performance of the proposed approach is compared with ground truth of four publicly available datasets. Results show improved performance in terms of image segmentation quality metrics, and could potentially assist when training with limited data.
* 6 pages, 8 figures, 2 tables, conference paper
AG-CRC: Anatomy-Guided Colorectal Cancer Segmentation in CT with Imperfect Anatomical Knowledge
Oct 07, 2023When delineating lesions from medical images, a human expert can always keep in mind the anatomical structure behind the voxels. However, although high-quality (though not perfect) anatomical information can be retrieved from computed tomography (CT) scans with modern deep learning algorithms, it is still an open problem how these automatically generated organ masks can assist in addressing challenging lesion segmentation tasks, such as the segmentation of colorectal cancer (CRC). In this paper, we develop a novel Anatomy-Guided segmentation framework to exploit the auto-generated organ masks to aid CRC segmentation from CT, namely AG-CRC. First, we obtain multi-organ segmentation (MOS) masks with existing MOS models (e.g., TotalSegmentor) and further derive a more robust organ of interest (OOI) mask that may cover most of the colon-rectum and CRC voxels. Then, we propose an anatomy-guided training patch sampling strategy by optimizing a heuristic gain function that considers both the proximity of important regions (e.g., the tumor or organs of interest) and sample diversity. Third, we design a novel self-supervised learning scheme inspired by the topology of tubular organs like the colon to boost the model performance further. Finally, we employ a masked loss scheme to guide the model to focus solely on the essential learning region. We extensively evaluate the proposed method on two CRC segmentation datasets, where substantial performance improvement (5% to 9% in Dice) is achieved over current state-of-the-art medical image segmentation models, and the ablation studies further evidence the efficacy of every proposed component.
Activate and Reject: Towards Safe Domain Generalization under Category Shift
Oct 07, 2023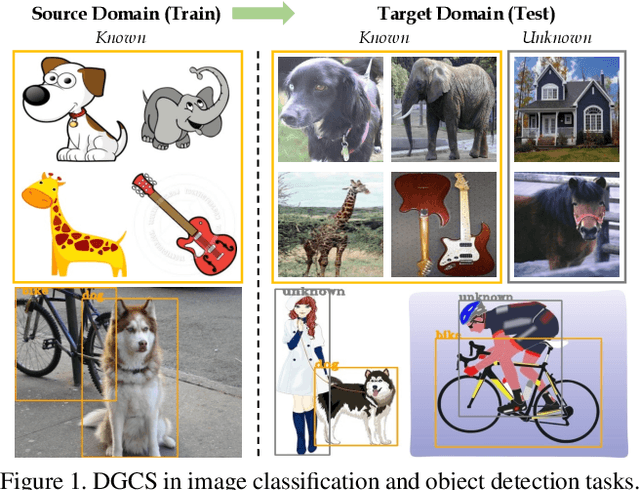

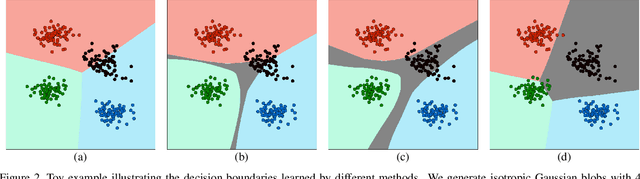
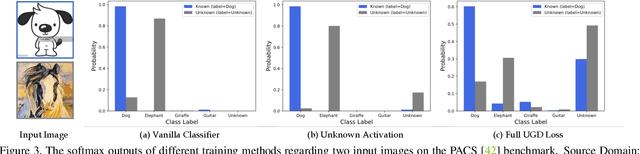
Albeit the notable performance on in-domain test points, it is non-trivial for deep neural networks to attain satisfactory accuracy when deploying in the open world, where novel domains and object classes often occur. In this paper, we study a practical problem of Domain Generalization under Category Shift (DGCS), which aims to simultaneously detect unknown-class samples and classify known-class samples in the target domains. Compared to prior DG works, we face two new challenges: 1) how to learn the concept of ``unknown'' during training with only source known-class samples, and 2) how to adapt the source-trained model to unseen environments for safe model deployment. To this end, we propose a novel Activate and Reject (ART) framework to reshape the model's decision boundary to accommodate unknown classes and conduct post hoc modification to further discriminate known and unknown classes using unlabeled test data. Specifically, during training, we promote the response to the unknown by optimizing the unknown probability and then smoothing the overall output to mitigate the overconfidence issue. At test time, we introduce a step-wise online adaptation method that predicts the label by virtue of the cross-domain nearest neighbor and class prototype information without updating the network's parameters or using threshold-based mechanisms. Experiments reveal that ART consistently improves the generalization capability of deep networks on different vision tasks. For image classification, ART improves the H-score by 6.1% on average compared to the previous best method. For object detection and semantic segmentation, we establish new benchmarks and achieve competitive performance.
Investigating the Limitation of CLIP Models: The Worst-Performing Categories
Oct 05, 2023Contrastive Language-Image Pre-training (CLIP) provides a foundation model by integrating natural language into visual concepts, enabling zero-shot recognition on downstream tasks. It is usually expected that satisfactory overall accuracy can be achieved across numerous domains through well-designed textual prompts. However, we found that their performance in the worst categories is significantly inferior to the overall performance. For example, on ImageNet, there are a total of 10 categories with class-wise accuracy as low as 0\%, even though the overall performance has achieved 64.1\%. This phenomenon reveals the potential risks associated with using CLIP models, particularly in risk-sensitive applications where specific categories hold significant importance. To address this issue, we investigate the alignment between the two modalities in the CLIP model and propose the Class-wise Matching Margin (\cmm) to measure the inference confusion. \cmm\ can effectively identify the worst-performing categories and estimate the potential performance of the candidate prompts. We further query large language models to enrich descriptions of worst-performing categories and build a weighted ensemble to highlight the efficient prompts. Experimental results clearly verify the effectiveness of our proposal, where the accuracy on the worst-10 categories on ImageNet is boosted to 5.2\%, without manual prompt engineering, laborious optimization, or access to labeled validation data.
RUSOpt: Robotic UltraSound Probe Normalization with Bayesian Optimization for In-plane and Out-plane Scanning
Oct 05, 2023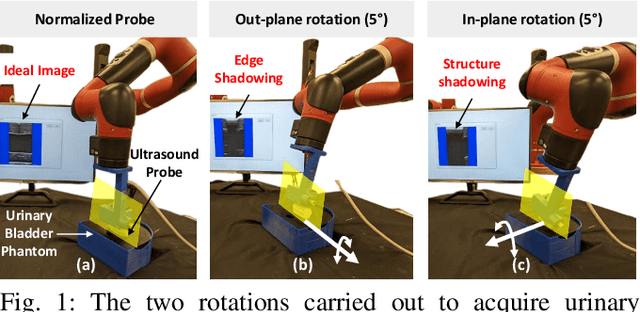

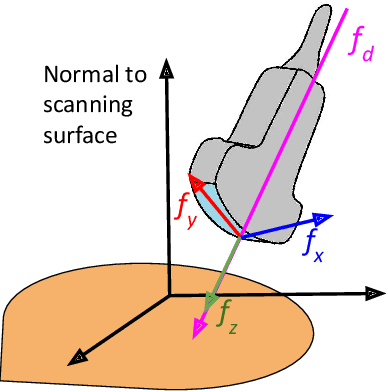
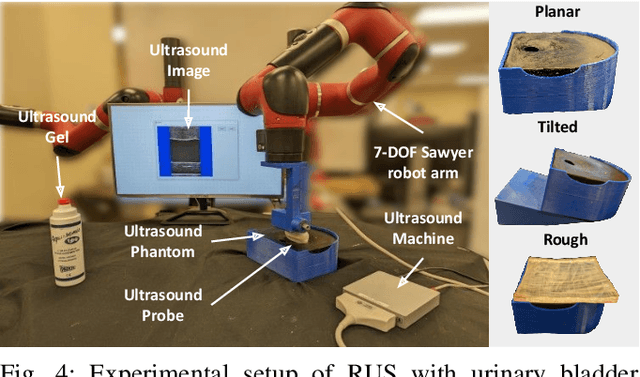
The one of the significant challenges faced by autonomous robotic ultrasound systems is acquiring high-quality images across different patients. The proper orientation of the robotized probe plays a crucial role in governing the quality of ultrasound images. To address this challenge, we propose a sample-efficient method to automatically adjust the orientation of the ultrasound probe normal to the point of contact on the scanning surface, thereby improving the acoustic coupling of the probe and resulting image quality. Our method utilizes Bayesian Optimization (BO) based search on the scanning surface to efficiently search for the normalized probe orientation. We formulate a novel objective function for BO that leverages the contact force measurements and underlying mechanics to identify the normal. We further incorporate a regularization scheme in BO to handle the noisy objective function. The performance of the proposed strategy has been assessed through experiments on urinary bladder phantoms. These phantoms included planar, tilted, and rough surfaces, and were examined using both linear and convex probes with varying search space limits. Further, simulation-based studies have been carried out using 3D human mesh models. The results demonstrate that the mean ($\pm$SD) absolute angular error averaged over all phantoms and 3D models is $\boldsymbol{2.4\pm0.7^\circ}$ and $\boldsymbol{2.1\pm1.3^\circ}$, respectively.
Functional data learning using convolutional neural networks
Oct 05, 2023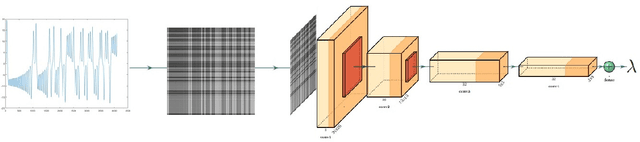

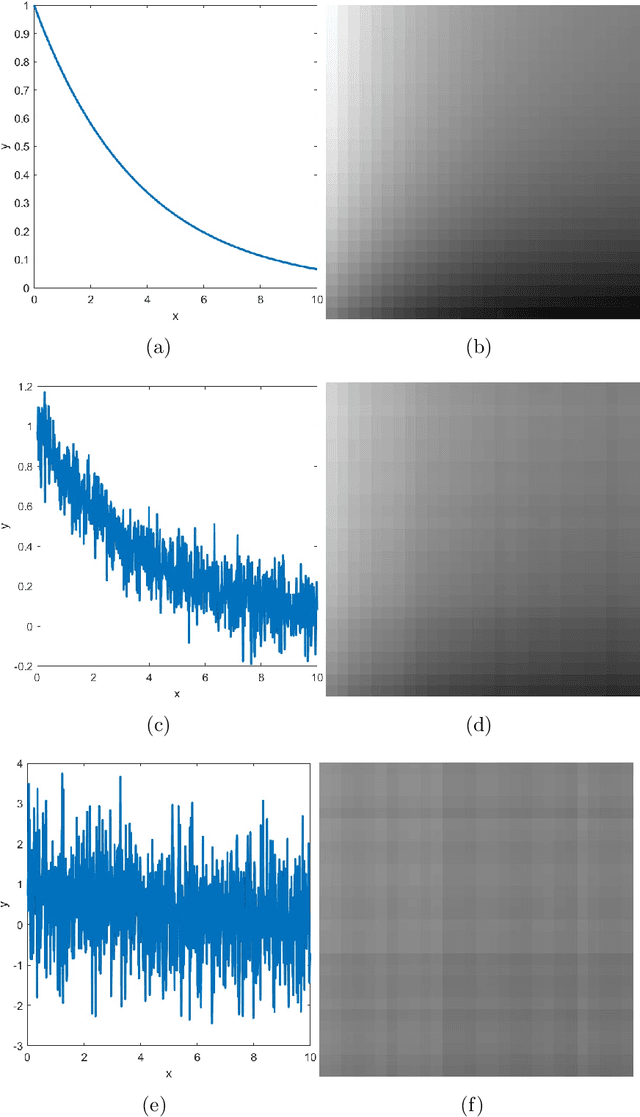

In this paper, we show how convolutional neural networks (CNN) can be used in regression and classification learning problems of noisy and non-noisy functional data. The main idea is to transform the functional data into a 28 by 28 image. We use a specific but typical architecture of a convolutional neural network to perform all the regression exercises of parameter estimation and functional form classification. First, we use some functional case studies of functional data with and without random noise to showcase the strength of the new method. In particular, we use it to estimate exponential growth and decay rates, the bandwidths of sine and cosine functions, and the magnitudes and widths of curve peaks. We also use it to classify the monotonicity and curvatures of functional data, algebraic versus exponential growth, and the number of peaks of functional data. Second, we apply the same convolutional neural networks to Lyapunov exponent estimation in noisy and non-noisy chaotic data, in estimating rates of disease transmission from epidemic curves, and in detecting the similarity of drug dissolution profiles. Finally, we apply the method to real-life data to detect Parkinson's disease patients in a classification problem. The method, although simple, shows high accuracy and is promising for future use in engineering and medical applications.
SimVLG: Simple and Efficient Pretraining of Visual Language Generative Models
Oct 05, 2023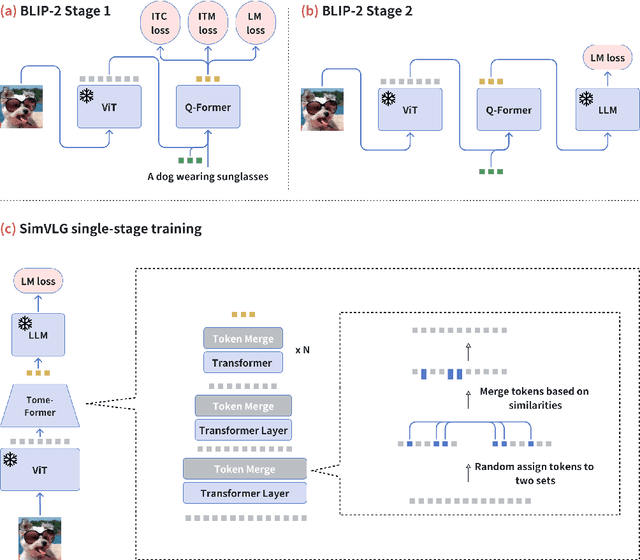
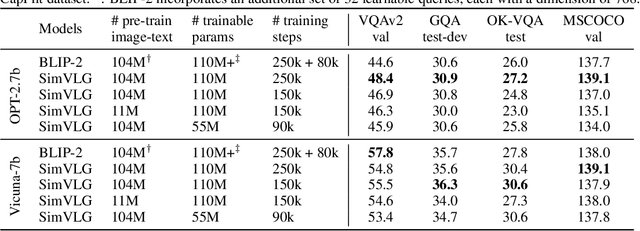
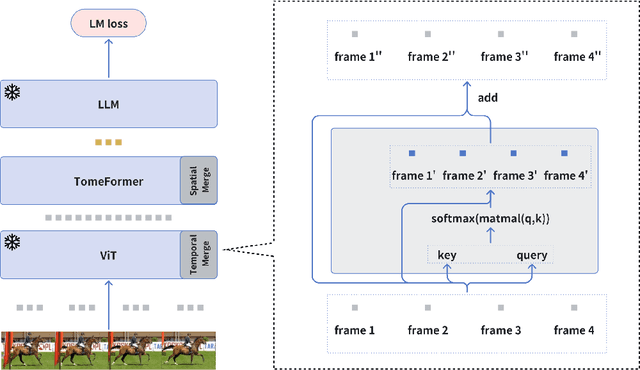

In this paper, we propose ``SimVLG'', a streamlined framework for the pre-training of computationally intensive vision-language generative models, leveraging frozen pre-trained large language models (LLMs). The prevailing paradigm in vision-language pre-training (VLP) typically involves a two-stage optimization process: an initial resource-intensive phase dedicated to general-purpose vision-language representation learning, aimed at extracting and consolidating pertinent visual features, followed by a subsequent phase focusing on end-to-end alignment between visual and linguistic modalities. Our one-stage, single-loss framework circumvents the aforementioned computationally demanding first stage of training by gradually merging similar visual tokens during training. This gradual merging process effectively compacts the visual information while preserving the richness of semantic content, leading to fast convergence without sacrificing performance. Our experiments show that our approach can speed up the training of vision-language models by a factor $\times 5$ without noticeable impact on the overall performance. Additionally, we show that our models can achieve comparable performance to current vision-language models with only $1/10$ of the data. Finally, we demonstrate how our image-text models can be easily adapted to video-language generative tasks through a novel soft attentive temporal token merging modules.