 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Jointly Training Large Autoregressive Multimodal Models
Sep 28, 2023
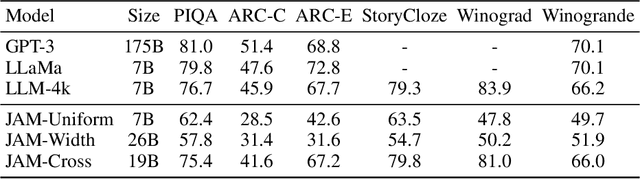
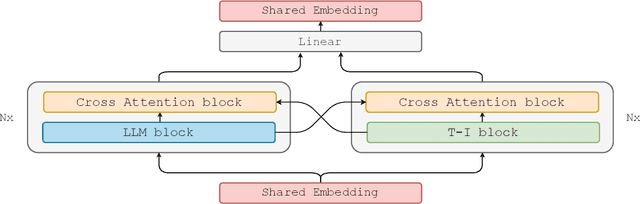
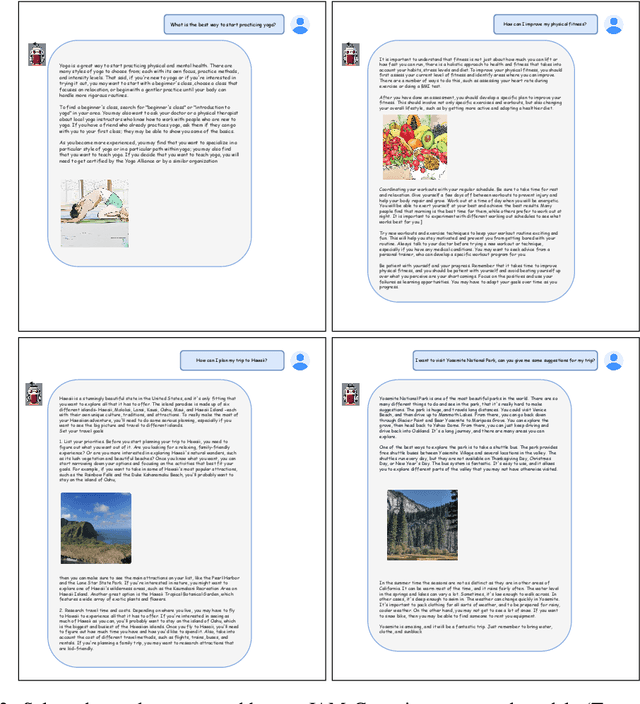
In recent years, advances in the large-scale pretraining of language and text-to-image models have revolutionized the field of machine learning. Yet, integrating these two modalities into a single, robust model capable of generating seamless multimodal outputs remains a significant challenge. To address this gap, we present the Joint Autoregressive Mixture (JAM) framework, a modular approach that systematically fuses existing text and image generation models. We also introduce a specialized, data-efficient instruction-tuning strategy, tailored for mixed-modal generation tasks. Our final instruct-tuned model demonstrates unparalleled performance in generating high-quality multimodal outputs and represents the first model explicitly designed for this purpose.
Evaluating Explanation Methods for Vision-and-Language Navigation
Oct 10, 2023The ability to navigate robots with natural language instructions in an unknown environment is a crucial step for achieving embodied artificial intelligence (AI). With the improving performance of deep neural models proposed in the field of vision-and-language navigation (VLN), it is equally interesting to know what information the models utilize for their decision-making in the navigation tasks. To understand the inner workings of deep neural models, various explanation methods have been developed for promoting explainable AI (XAI). But they are mostly applied to deep neural models for image or text classification tasks and little work has been done in explaining deep neural models for VLN tasks. In this paper, we address these problems by building quantitative benchmarks to evaluate explanation methods for VLN models in terms of faithfulness. We propose a new erasure-based evaluation pipeline to measure the step-wise textual explanation in the sequential decision-making setting. We evaluate several explanation methods for two representative VLN models on two popular VLN datasets and reveal valuable findings through our experiments.
Blind Dates: Examining the Expression of Temporality in Historical Photographs
Oct 10, 2023This paper explores the capacity of computer vision models to discern temporal information in visual content, focusing specifically on historical photographs. We investigate the dating of images using OpenCLIP, an open-source implementation of CLIP, a multi-modal language and vision model. Our experiment consists of three steps: zero-shot classification, fine-tuning, and analysis of visual content. We use the \textit{De Boer Scene Detection} dataset, containing 39,866 gray-scale historical press photographs from 1950 to 1999. The results show that zero-shot classification is relatively ineffective for image dating, with a bias towards predicting dates in the past. Fine-tuning OpenCLIP with a logistic classifier improves performance and eliminates the bias. Additionally, our analysis reveals that images featuring buses, cars, cats, dogs, and people are more accurately dated, suggesting the presence of temporal markers. The study highlights the potential of machine learning models like OpenCLIP in dating images and emphasizes the importance of fine-tuning for accurate temporal analysis. Future research should explore the application of these findings to color photographs and diverse datasets.
Hierarchical Mask2Former: Panoptic Segmentation of Crops, Weeds and Leaves
Oct 10, 2023
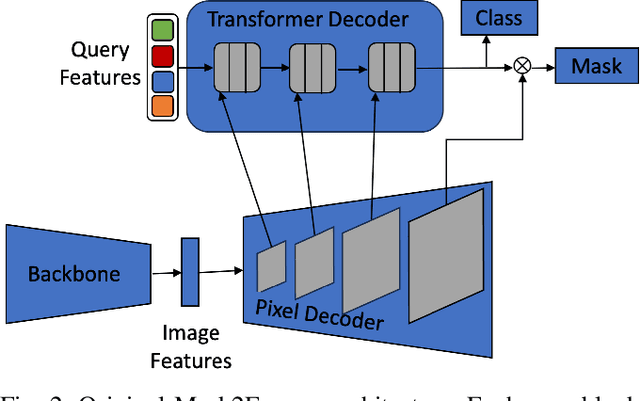
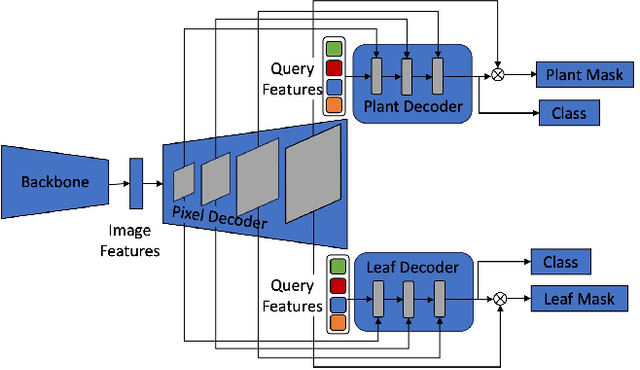
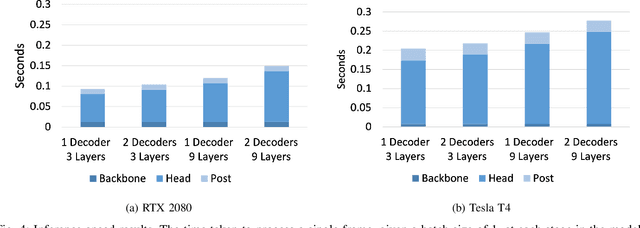
Advancements in machine vision that enable detailed inferences to be made from images have the potential to transform many sectors including agriculture. Precision agriculture, where data analysis enables interventions to be precisely targeted, has many possible applications. Precision spraying, for example, can limit the application of herbicide only to weeds, or limit the application of fertiliser only to undernourished crops, instead of spraying the entire field. The approach promises to maximise yields, whilst minimising resource use and harms to the surrounding environment. To this end, we propose a hierarchical panoptic segmentation method to simultaneously identify indicators of plant growth and locate weeds within an image. We adapt Mask2Former, a state-of-the-art architecture for panoptic segmentation, to predict crop, weed and leaf masks. We achieve a PQ{\dag} of 75.99. Additionally, we explore approaches to make the architecture more compact and therefore more suitable for time and compute constrained applications. With our more compact architecture, inference is up to 60% faster and the reduction in PQ{\dag} is less than 1%.
Compression Ratio Learning and Semantic Communications for Video Imaging
Oct 10, 2023
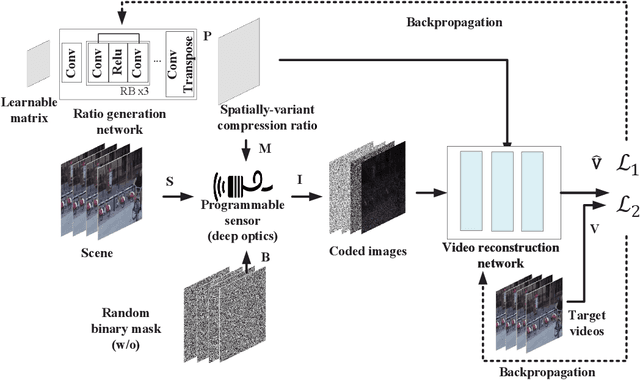
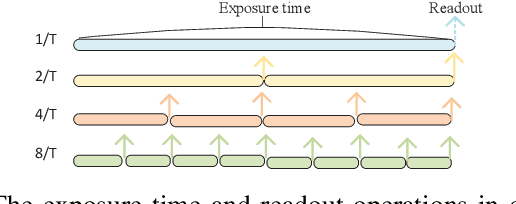
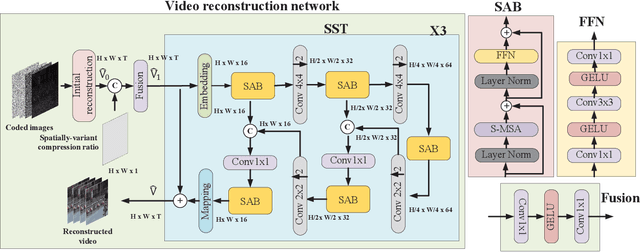
Camera sensors have been widely used in intelligent robotic systems. Developing camera sensors with high sensing efficiency has always been important to reduce the power, memory, and other related resources. Inspired by recent success on programmable sensors and deep optic methods, we design a novel video compressed sensing system with spatially-variant compression ratios, which achieves higher imaging quality than the existing snapshot compressed imaging methods with the same sensing costs. In this article, we also investigate the data transmission methods for programmable sensors, where the performance of communication systems is evaluated by the reconstructed images or videos rather than the transmission of sensor data itself. Usually, different reconstruction algorithms are designed for applications in high dynamic range imaging, video compressive sensing, or motion debluring. This task-aware property inspires a semantic communication framework for programmable sensors. In this work, a policy-gradient based reinforcement learning method is introduced to achieve the explicit trade-off between the compression (or transmission) rate and the image distortion. Numerical results show the superiority of the proposed methods over existing baselines.
Domain Expansion via Network Adaptation for Solving Inverse Problems
Oct 10, 2023Deep learning-based methods deliver state-of-the-art performance for solving inverse problems that arise in computational imaging. These methods can be broadly divided into two groups: (1) learn a network to map measurements to the signal estimate, which is known to be fragile; (2) learn a prior for the signal to use in an optimization-based recovery. Despite the impressive results from the latter approach, many of these methods also lack robustness to shifts in data distribution, measurements, and noise levels. Such domain shifts result in a performance gap and in some cases introduce undesired artifacts in the estimated signal. In this paper, we explore the qualitative and quantitative effects of various domain shifts and propose a flexible and parameter efficient framework that adapt pretrained networks to such shifts. We demonstrate the effectiveness of our method for a number of natural image, MRI, and CT reconstructions tasks under domain, measurement model, and noise-level shifts. Our experiments demonstrate that our method provides significantly better performance and parameter efficiency compared to existing domain adaptation techniques.
Persis: A Persian Font Recognition Pipeline Using Convolutional Neural Networks
Oct 10, 2023



What happens if we encounter a suitable font for our design work but do not know its name? Visual Font Recognition (VFR) systems are used to identify the font typeface in an image. These systems can assist graphic designers in identifying fonts used in images. A VFR system also aids in improving the speed and accuracy of Optical Character Recognition (OCR) systems. In this paper, we introduce the first publicly available datasets in the field of Persian font recognition and employ Convolutional Neural Networks (CNN) to address this problem. The results show that the proposed pipeline obtained 78.0% top-1 accuracy on our new datasets, 89.1% on the IDPL-PFOD dataset, and 94.5% on the KAFD dataset. Furthermore, the average time spent in the entire pipeline for one sample of our proposed datasets is 0.54 and 0.017 seconds for CPU and GPU, respectively. We conclude that CNN methods can be used to recognize Persian fonts without the need for additional pre-processing steps such as feature extraction, binarization, normalization, etc.
Geometry-Guided Ray Augmentation for Neural Surface Reconstruction with Sparse Views
Oct 09, 2023
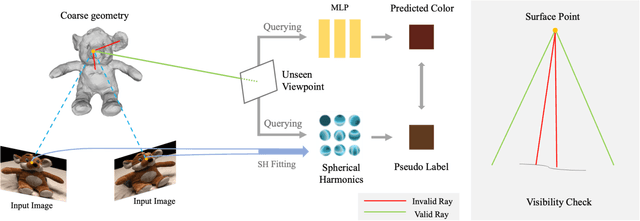
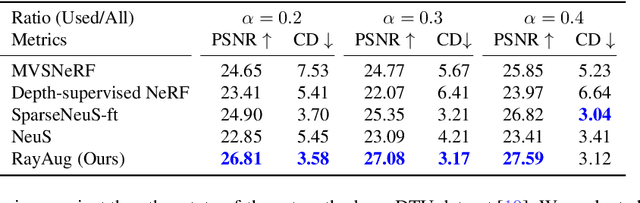

In this paper, we propose a novel method for 3D scene and object reconstruction from sparse multi-view images. Different from previous methods that leverage extra information such as depth or generalizable features across scenes, our approach leverages the scene properties embedded in the multi-view inputs to create precise pseudo-labels for optimization without any prior training. Specifically, we introduce a geometry-guided approach that improves surface reconstruction accuracy from sparse views by leveraging spherical harmonics to predict the novel radiance while holistically considering all color observations for a point in the scene. Also, our pipeline exploits proxy geometry and correctly handles the occlusion in generating the pseudo-labels of radiance, which previous image-warping methods fail to avoid. Our method, dubbed Ray Augmentation (RayAug), achieves superior results on DTU and Blender datasets without requiring prior training, demonstrating its effectiveness in addressing the problem of sparse view reconstruction. Our pipeline is flexible and can be integrated into other implicit neural reconstruction methods for sparse views.
Learning Layer-wise Equivariances Automatically using Gradients
Oct 09, 2023

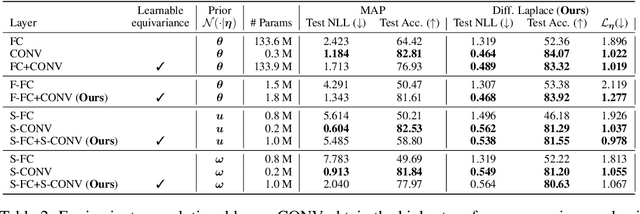

Convolutions encode equivariance symmetries into neural networks leading to better generalisation performance. However, symmetries provide fixed hard constraints on the functions a network can represent, need to be specified in advance, and can not be adapted. Our goal is to allow flexible symmetry constraints that can automatically be learned from data using gradients. Learning symmetry and associated weight connectivity structures from scratch is difficult for two reasons. First, it requires efficient and flexible parameterisations of layer-wise equivariances. Secondly, symmetries act as constraints and are therefore not encouraged by training losses measuring data fit. To overcome these challenges, we improve parameterisations of soft equivariance and learn the amount of equivariance in layers by optimising the marginal likelihood, estimated using differentiable Laplace approximations. The objective balances data fit and model complexity enabling layer-wise symmetry discovery in deep networks. We demonstrate the ability to automatically learn layer-wise equivariances on image classification tasks, achieving equivalent or improved performance over baselines with hard-coded symmetry.
BATINet: Background-Aware Text to Image Synthesis and Manipulation Network
Aug 11, 2023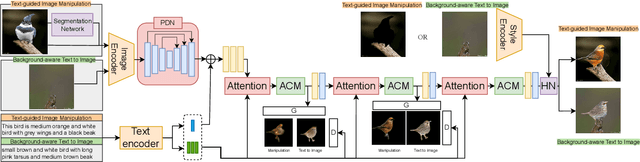

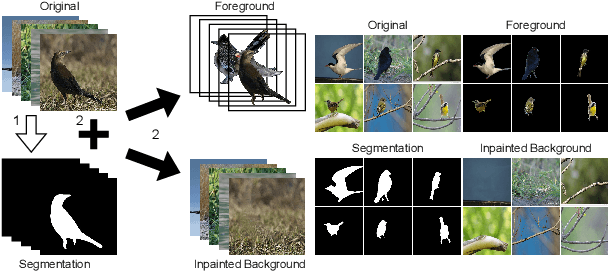

Background-Induced Text2Image (BIT2I) aims to generate foreground content according to the text on the given background image. Most studies focus on generating high-quality foreground content, although they ignore the relationship between the two contents. In this study, we analyzed a novel Background-Aware Text2Image (BAT2I) task in which the generated content matches the input background. We proposed a Background-Aware Text to Image synthesis and manipulation Network (BATINet), which contains two key components: Position Detect Network (PDN) and Harmonize Network (HN). The PDN detects the most plausible position of the text-relevant object in the background image. The HN harmonizes the generated content referring to background style information. Finally, we reconstructed the generation network, which consists of the multi-GAN and attention module to match more user preferences. Moreover, we can apply BATINet to text-guided image manipulation. It solves the most challenging task of manipulating the shape of an object. We demonstrated through qualitative and quantitative evaluations on the CUB dataset that the proposed model outperforms other state-of-the-art methods.