 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023

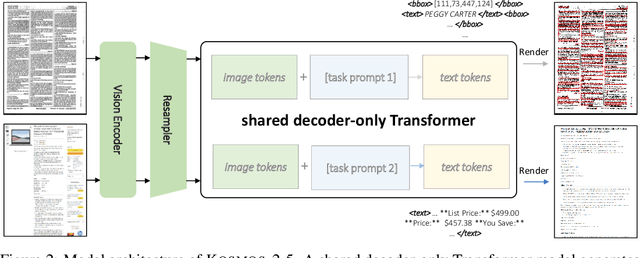

We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
Face Aging via Diffusion-based Editing
Sep 20, 2023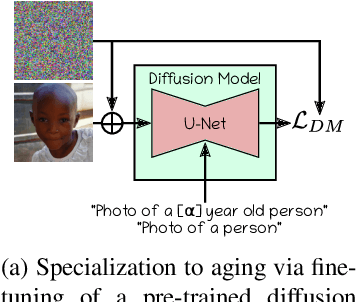
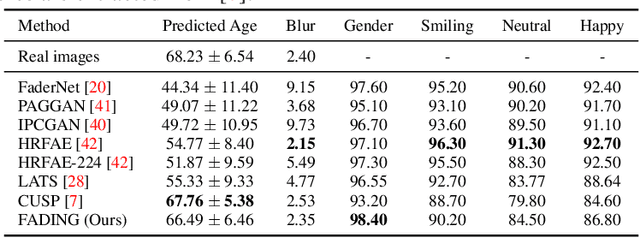


In this paper, we address the problem of face aging: generating past or future facial images by incorporating age-related changes to the given face. Previous aging methods rely solely on human facial image datasets and are thus constrained by their inherent scale and bias. This restricts their application to a limited generatable age range and the inability to handle large age gaps. We propose FADING, a novel approach to address Face Aging via DIffusion-based editiNG. We go beyond existing methods by leveraging the rich prior of large-scale language-image diffusion models. First, we specialize a pre-trained diffusion model for the task of face age editing by using an age-aware fine-tuning scheme. Next, we invert the input image to latent noise and obtain optimized null text embeddings. Finally, we perform text-guided local age editing via attention control. The quantitative and qualitative analyses demonstrate that our method outperforms existing approaches with respect to aging accuracy, attribute preservation, and aging quality.
MindDiffuser: Controlled Image Reconstruction from Human Brain Activity with Semantic and Structural Diffusion
Aug 08, 2023
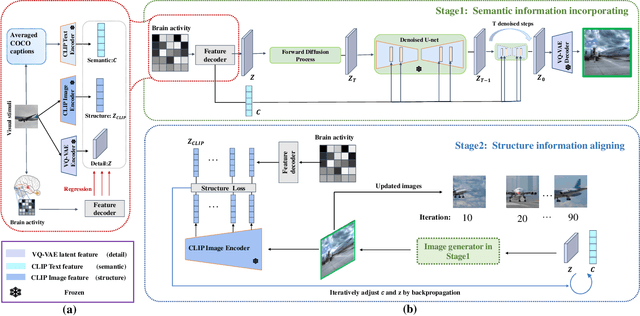
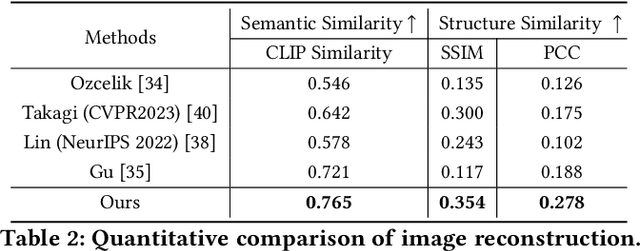
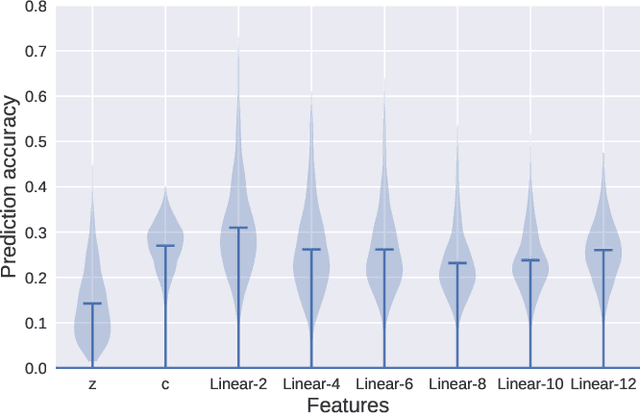
Reconstructing visual stimuli from brain recordings has been a meaningful and challenging task. Especially, the achievement of precise and controllable image reconstruction bears great significance in propelling the progress and utilization of brain-computer interfaces. Despite the advancements in complex image reconstruction techniques, the challenge persists in achieving a cohesive alignment of both semantic (concepts and objects) and structure (position, orientation, and size) with the image stimuli. To address the aforementioned issue, we propose a two-stage image reconstruction model called MindDiffuser. In Stage 1, the VQ-VAE latent representations and the CLIP text embeddings decoded from fMRI are put into Stable Diffusion, which yields a preliminary image that contains semantic information. In Stage 2, we utilize the CLIP visual feature decoded from fMRI as supervisory information, and continually adjust the two feature vectors decoded in Stage 1 through backpropagation to align the structural information. The results of both qualitative and quantitative analyses demonstrate that our model has surpassed the current state-of-the-art models on Natural Scenes Dataset (NSD). The subsequent experimental findings corroborate the neurobiological plausibility of the model, as evidenced by the interpretability of the multimodal feature employed, which align with the corresponding brain responses.
Global-correlated 3D-decoupling Transformer for Clothed Avatar Reconstruction
Sep 26, 2023Reconstructing 3D clothed human avatars from single images is a challenging task, especially when encountering complex poses and loose clothing. Current methods exhibit limitations in performance, largely attributable to their dependence on insufficient 2D image features and inconsistent query methods. Owing to this, we present the Global-correlated 3D-decoupling Transformer for clothed Avatar reconstruction (GTA), a novel transformer-based architecture that reconstructs clothed human avatars from monocular images. Our approach leverages transformer architectures by utilizing a Vision Transformer model as an encoder for capturing global-correlated image features. Subsequently, our innovative 3D-decoupling decoder employs cross-attention to decouple tri-plane features, using learnable embeddings as queries for cross-plane generation. To effectively enhance feature fusion with the tri-plane 3D feature and human body prior, we propose a hybrid prior fusion strategy combining spatial and prior-enhanced queries, leveraging the benefits of spatial localization and human body prior knowledge. Comprehensive experiments on CAPE and THuman2.0 datasets illustrate that our method outperforms state-of-the-art approaches in both geometry and texture reconstruction, exhibiting high robustness to challenging poses and loose clothing, and producing higher-resolution textures. Codes will be available at https://github.com/River-Zhang/GTA.
VPA: Fully Test-Time Visual Prompt Adaptation
Sep 26, 2023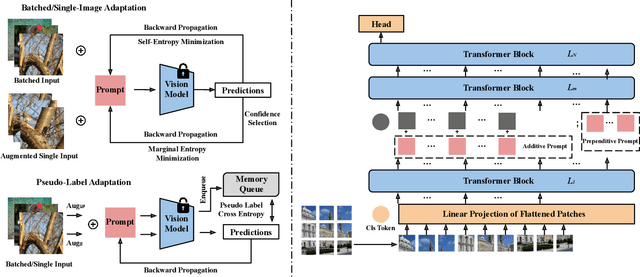
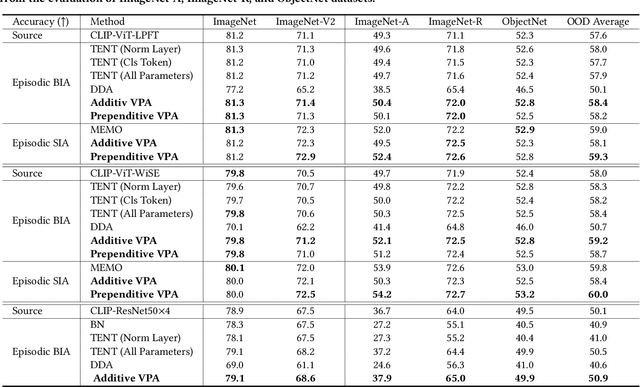
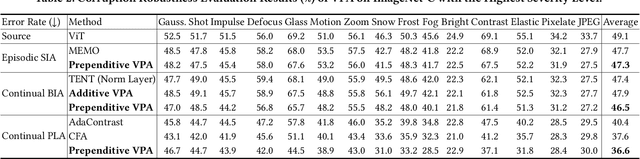
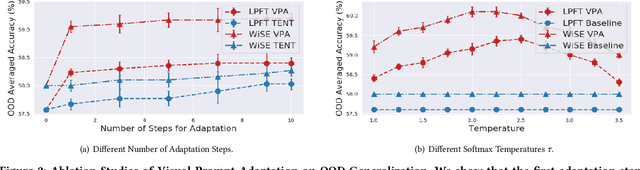
Textual prompt tuning has demonstrated significant performance improvements in adapting natural language processing models to a variety of downstream tasks by treating hand-engineered prompts as trainable parameters. Inspired by the success of textual prompting, several studies have investigated the efficacy of visual prompt tuning. In this work, we present Visual Prompt Adaptation (VPA), the first framework that generalizes visual prompting with test-time adaptation. VPA introduces a small number of learnable tokens, enabling fully test-time and storage-efficient adaptation without necessitating source-domain information. We examine our VPA design under diverse adaptation settings, encompassing single-image, batched-image, and pseudo-label adaptation. We evaluate VPA on multiple tasks, including out-of-distribution (OOD) generalization, corruption robustness, and domain adaptation. Experimental results reveal that VPA effectively enhances OOD generalization by 3.3% across various models, surpassing previous test-time approaches. Furthermore, we show that VPA improves corruption robustness by 6.5% compared to strong baselines. Finally, we demonstrate that VPA also boosts domain adaptation performance by relatively 5.2%. Our VPA also exhibits marked effectiveness in improving the robustness of zero-shot recognition for vision-language models.
CTP-Net: Character Texture Perception Network for Document Image Forgery Localization
Aug 04, 2023
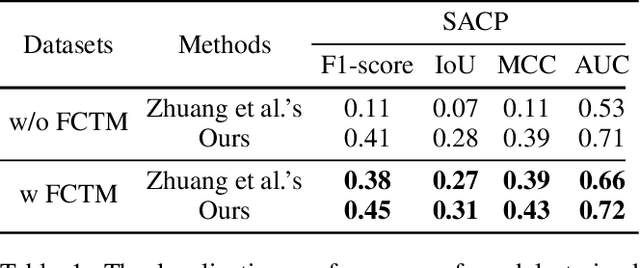
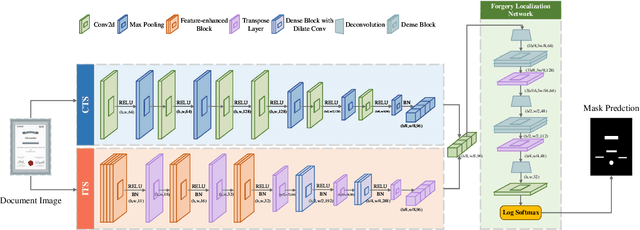
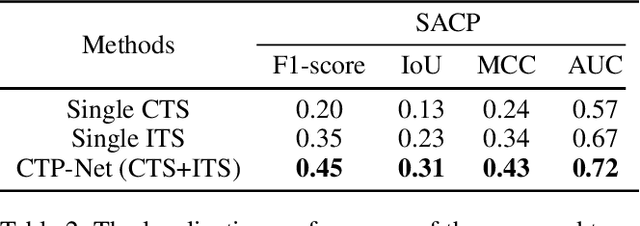
Due to the progression of information technology in recent years, document images have been widely disseminated in social networks. With the help of powerful image editing tools, document images are easily forged without leaving visible manipulation traces, which leads to severe issues if significant information is falsified for malicious use. Therefore, the research of document image forensics is worth further exploring. In a document image, the character with specific semantic information is most vulnerable to tampering, for which capturing the forgery traces of the character is the key to localizing the forged region in document images. Considering both character and image textures, in this paper, we propose a Character Texture Perception Network (CTP-Net) to localize the forgery of document images. Based on optical character recognition, a Character Texture Stream (CTS) is designed to capture features of text areas that are essential components of a document image. Meanwhile, texture features of the whole document image are exploited by an Image Texture Stream (ITS). Combining the features extracted from the CTS and the ITS, the CTP-Net can reveal more subtle forgery traces from document images. To overcome the challenge caused by the lack of fake document images, we design a data generation strategy that is utilized to construct a Fake Chinese Trademark dataset (FCTM). Through a series of experiments, we show that the proposed CTP-Net is able to capture tampering traces in document images, especially in text regions. Experimental results demonstrate that CTP-Net can localize multi-scale forged areas in document images and outperform the state-of-the-art forgery localization methods.
How Does Pruning Impact Long-Tailed Multi-Label Medical Image Classifiers?
Aug 17, 2023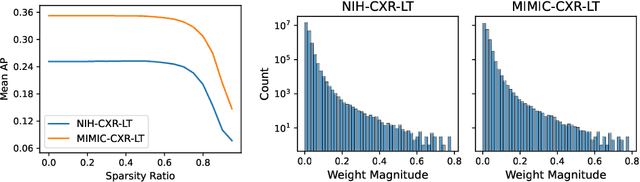

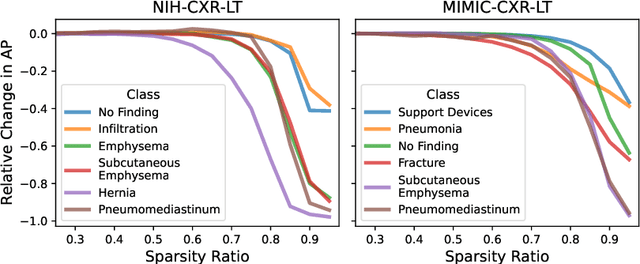
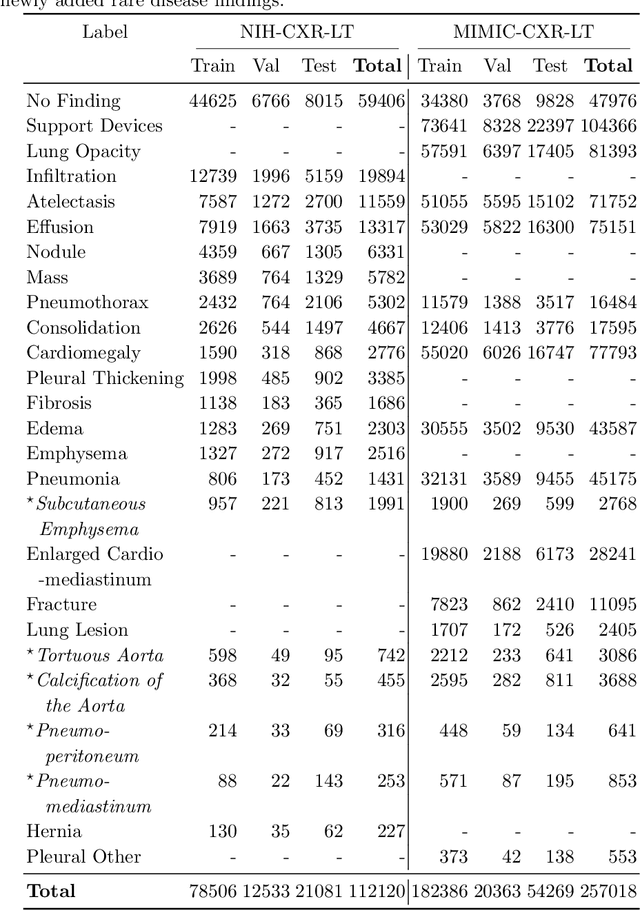
Pruning has emerged as a powerful technique for compressing deep neural networks, reducing memory usage and inference time without significantly affecting overall performance. However, the nuanced ways in which pruning impacts model behavior are not well understood, particularly for long-tailed, multi-label datasets commonly found in clinical settings. This knowledge gap could have dangerous implications when deploying a pruned model for diagnosis, where unexpected model behavior could impact patient well-being. To fill this gap, we perform the first analysis of pruning's effect on neural networks trained to diagnose thorax diseases from chest X-rays (CXRs). On two large CXR datasets, we examine which diseases are most affected by pruning and characterize class "forgettability" based on disease frequency and co-occurrence behavior. Further, we identify individual CXRs where uncompressed and heavily pruned models disagree, known as pruning-identified exemplars (PIEs), and conduct a human reader study to evaluate their unifying qualities. We find that radiologists perceive PIEs as having more label noise, lower image quality, and higher diagnosis difficulty. This work represents a first step toward understanding the impact of pruning on model behavior in deep long-tailed, multi-label medical image classification. All code, model weights, and data access instructions can be found at https://github.com/VITA-Group/PruneCXR.
Text-guided Foundation Model Adaptation for Pathological Image Classification
Jul 27, 2023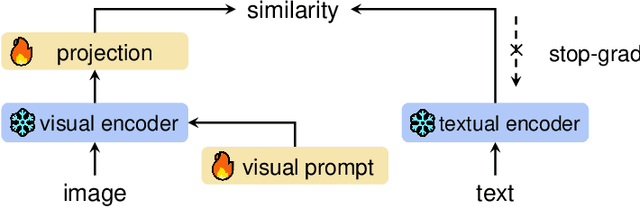

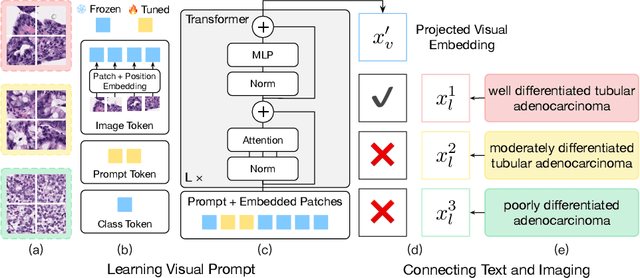
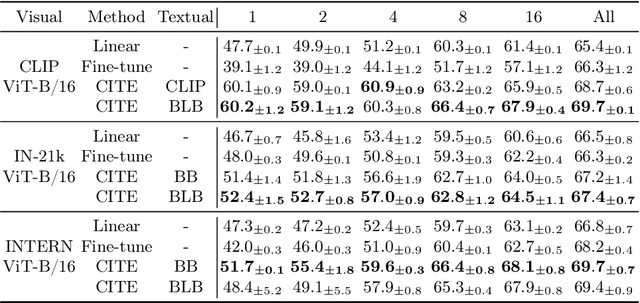
The recent surge of foundation models in computer vision and natural language processing opens up perspectives in utilizing multi-modal clinical data to train large models with strong generalizability. Yet pathological image datasets often lack biomedical text annotation and enrichment. Guiding data-efficient image diagnosis from the use of biomedical text knowledge becomes a substantial interest. In this paper, we propose to Connect Image and Text Embeddings (CITE) to enhance pathological image classification. CITE injects text insights gained from language models pre-trained with a broad range of biomedical texts, leading to adapt foundation models towards pathological image understanding. Through extensive experiments on the PatchGastric stomach tumor pathological image dataset, we demonstrate that CITE achieves leading performance compared with various baselines especially when training data is scarce. CITE offers insights into leveraging in-domain text knowledge to reinforce data-efficient pathological image classification. Code is available at https://github.com/Yunkun-Zhang/CITE.
AG-CRC: Anatomy-Guided Colorectal Cancer Segmentation in CT with Imperfect Anatomical Knowledge
Oct 07, 2023When delineating lesions from medical images, a human expert can always keep in mind the anatomical structure behind the voxels. However, although high-quality (though not perfect) anatomical information can be retrieved from computed tomography (CT) scans with modern deep learning algorithms, it is still an open problem how these automatically generated organ masks can assist in addressing challenging lesion segmentation tasks, such as the segmentation of colorectal cancer (CRC). In this paper, we develop a novel Anatomy-Guided segmentation framework to exploit the auto-generated organ masks to aid CRC segmentation from CT, namely AG-CRC. First, we obtain multi-organ segmentation (MOS) masks with existing MOS models (e.g., TotalSegmentor) and further derive a more robust organ of interest (OOI) mask that may cover most of the colon-rectum and CRC voxels. Then, we propose an anatomy-guided training patch sampling strategy by optimizing a heuristic gain function that considers both the proximity of important regions (e.g., the tumor or organs of interest) and sample diversity. Third, we design a novel self-supervised learning scheme inspired by the topology of tubular organs like the colon to boost the model performance further. Finally, we employ a masked loss scheme to guide the model to focus solely on the essential learning region. We extensively evaluate the proposed method on two CRC segmentation datasets, where substantial performance improvement (5% to 9% in Dice) is achieved over current state-of-the-art medical image segmentation models, and the ablation studies further evidence the efficacy of every proposed component.
Activate and Reject: Towards Safe Domain Generalization under Category Shift
Oct 07, 2023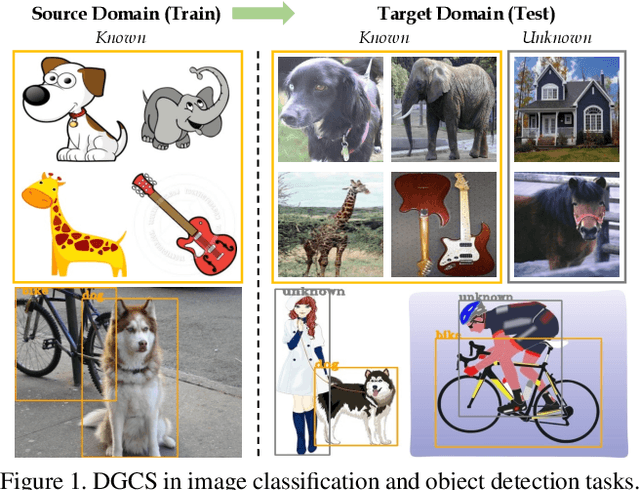

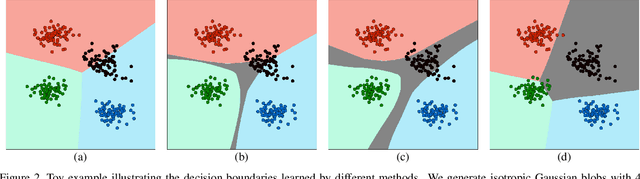
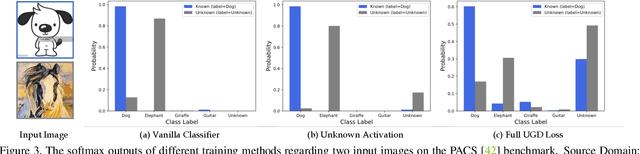
Albeit the notable performance on in-domain test points, it is non-trivial for deep neural networks to attain satisfactory accuracy when deploying in the open world, where novel domains and object classes often occur. In this paper, we study a practical problem of Domain Generalization under Category Shift (DGCS), which aims to simultaneously detect unknown-class samples and classify known-class samples in the target domains. Compared to prior DG works, we face two new challenges: 1) how to learn the concept of ``unknown'' during training with only source known-class samples, and 2) how to adapt the source-trained model to unseen environments for safe model deployment. To this end, we propose a novel Activate and Reject (ART) framework to reshape the model's decision boundary to accommodate unknown classes and conduct post hoc modification to further discriminate known and unknown classes using unlabeled test data. Specifically, during training, we promote the response to the unknown by optimizing the unknown probability and then smoothing the overall output to mitigate the overconfidence issue. At test time, we introduce a step-wise online adaptation method that predicts the label by virtue of the cross-domain nearest neighbor and class prototype information without updating the network's parameters or using threshold-based mechanisms. Experiments reveal that ART consistently improves the generalization capability of deep networks on different vision tasks. For image classification, ART improves the H-score by 6.1% on average compared to the previous best method. For object detection and semantic segmentation, we establish new benchmarks and achieve competitive performance.