 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bridging Semantic Gaps for Language-Supervised Semantic Segmentation
Sep 27, 2023
Vision-Language Pre-training has demonstrated its remarkable zero-shot recognition ability and potential to learn generalizable visual representations from language supervision. Taking a step ahead, language-supervised semantic segmentation enables spatial localization of textual inputs by learning pixel grouping solely from image-text pairs. Nevertheless, the state-of-the-art suffers from clear semantic gaps between visual and textual modality: plenty of visual concepts appeared in images are missing in their paired captions. Such semantic misalignment circulates in pre-training, leading to inferior zero-shot performance in dense predictions due to insufficient visual concepts captured in textual representations. To close such semantic gap, we propose Concept Curation (CoCu), a pipeline that leverages CLIP to compensate for the missing semantics. For each image-text pair, we establish a concept archive that maintains potential visually-matched concepts with our proposed vision-driven expansion and text-to-vision-guided ranking. Relevant concepts can thus be identified via cluster-guided sampling and fed into pre-training, thereby bridging the gap between visual and textual semantics. Extensive experiments over a broad suite of 8 segmentation benchmarks show that CoCu achieves superb zero-shot transfer performance and greatly boosts language-supervised segmentation baseline by a large margin, suggesting the value of bridging semantic gap in pre-training data.
Alice Benchmarks: Connecting Real World Object Re-Identification with the Synthetic
Oct 06, 2023

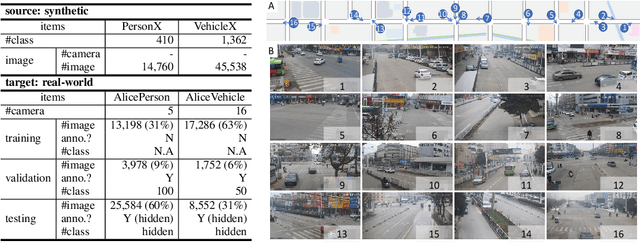
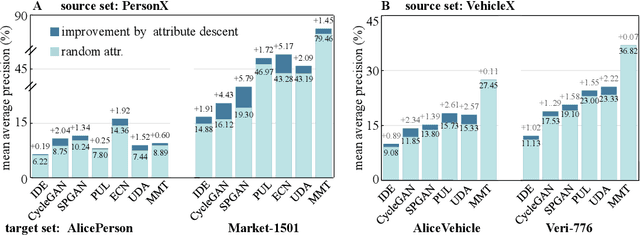
For object re-identification (re-ID), learning from synthetic data has become a promising strategy to cheaply acquire large-scale annotated datasets and effective models, with few privacy concerns. Many interesting research problems arise from this strategy, e.g., how to reduce the domain gap between synthetic source and real-world target. To facilitate developing more new approaches in learning from synthetic data, we introduce the Alice benchmarks, large-scale datasets providing benchmarks as well as evaluation protocols to the research community. Within the Alice benchmarks, two object re-ID tasks are offered: person and vehicle re-ID. We collected and annotated two challenging real-world target datasets: AlicePerson and AliceVehicle, captured under various illuminations, image resolutions, etc. As an important feature of our real target, the clusterability of its training set is not manually guaranteed to make it closer to a real domain adaptation test scenario. Correspondingly, we reuse existing PersonX and VehicleX as synthetic source domains. The primary goal is to train models from synthetic data that can work effectively in the real world. In this paper, we detail the settings of Alice benchmarks, provide an analysis of existing commonly-used domain adaptation methods, and discuss some interesting future directions. An online server will be set up for the community to evaluate methods conveniently and fairly.
A privacy-preserving method using secret key for convolutional neural network-based speech classification
Oct 06, 2023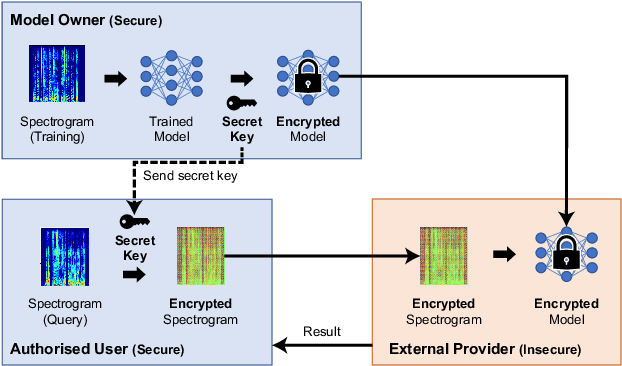
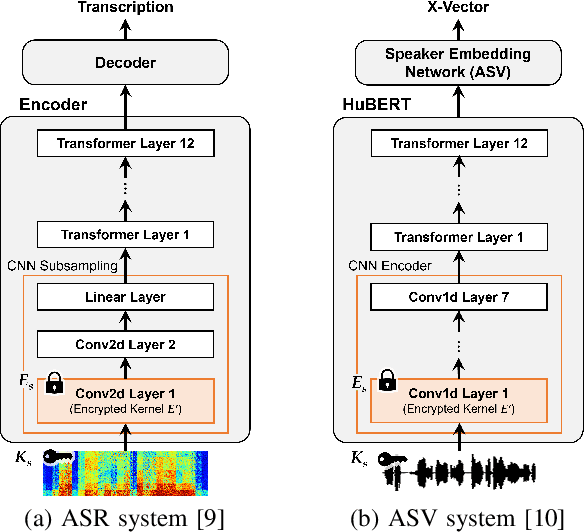
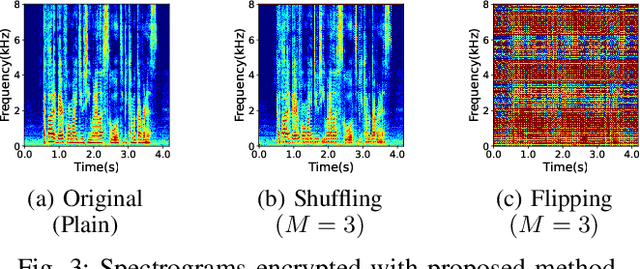
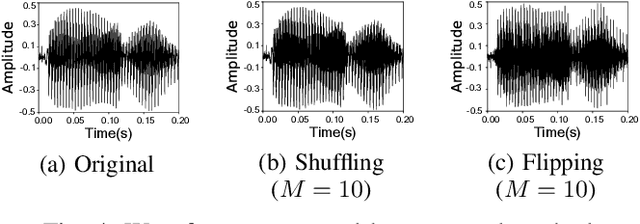
In this paper, we propose a privacy-preserving method with a secret key for convolutional neural network (CNN)-based speech classification tasks. Recently, many methods related to privacy preservation have been developed in image classification research fields. In contrast, in speech classification research fields, little research has considered these risks. To promote research on privacy preservation for speech classification, we provide an encryption method with a secret key in CNN-based speech classification systems. The encryption method is based on a random matrix with an invertible inverse. The encrypted speech data with a correct key can be accepted by a model with an encrypted kernel generated using an inverse matrix of a random matrix. Whereas the encrypted speech data is strongly distorted, the classification tasks can be correctly performed when a correct key is provided. Additionally, in this paper, we evaluate the difficulty of reconstructing the original information from the encrypted spectrograms and waveforms. In our experiments, the proposed encryption methods are performed in automatic speech recognition~(ASR) and automatic speaker verification~(ASV) tasks. The results show that the encrypted data can be used completely the same as the original data when a correct secret key is provided in the transformer-based ASR and x-vector-based ASV with self-supervised front-end systems. The robustness of the encrypted data against reconstruction attacks is also illustrated.
What Learned Representations and Influence Functions Can Tell Us About Adversarial Examples
Sep 19, 2023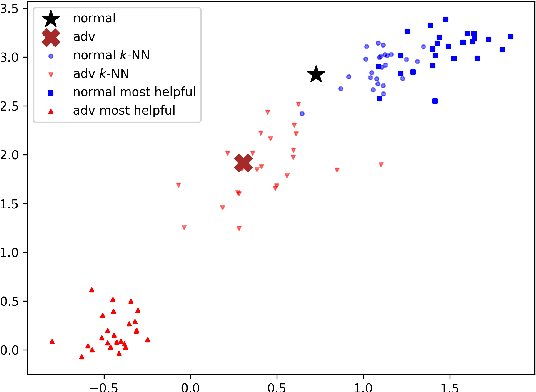

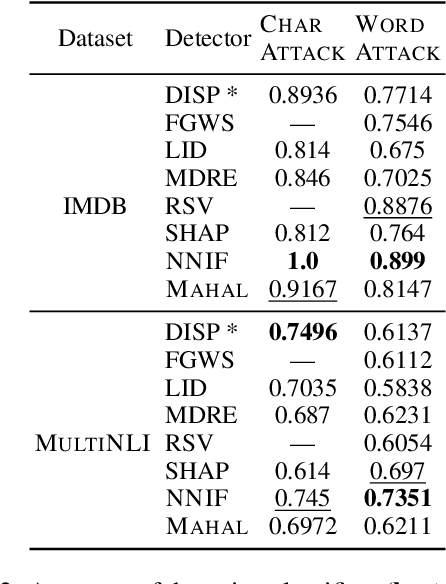
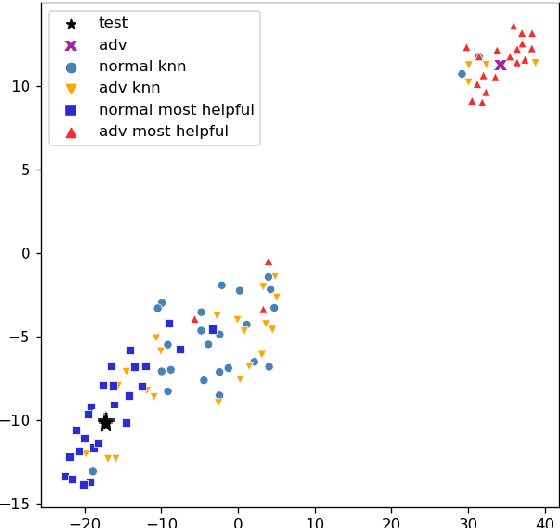
Adversarial examples, deliberately crafted using small perturbations to fool deep neural networks, were first studied in image processing and more recently in NLP. While approaches to detecting adversarial examples in NLP have largely relied on search over input perturbations, image processing has seen a range of techniques that aim to characterise adversarial subspaces over the learned representations. In this paper, we adapt two such approaches to NLP, one based on nearest neighbors and influence functions and one on Mahalanobis distances. The former in particular produces a state-of-the-art detector when compared against several strong baselines; moreover, the novel use of influence functions provides insight into how the nature of adversarial example subspaces in NLP relate to those in image processing, and also how they differ depending on the kind of NLP task.
Occ$^2$Net: Robust Image Matching Based on 3D Occupancy Estimation for Occluded Regions
Aug 14, 2023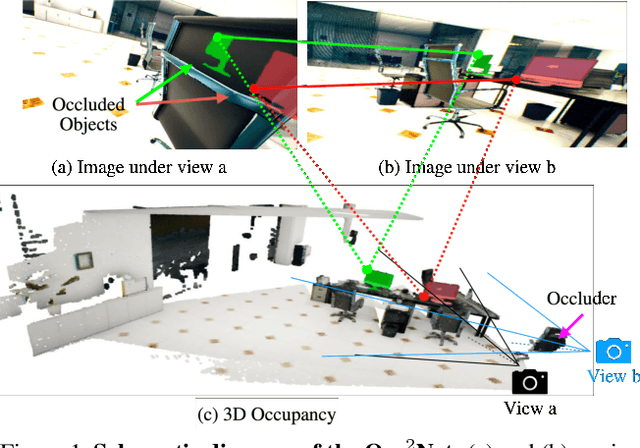
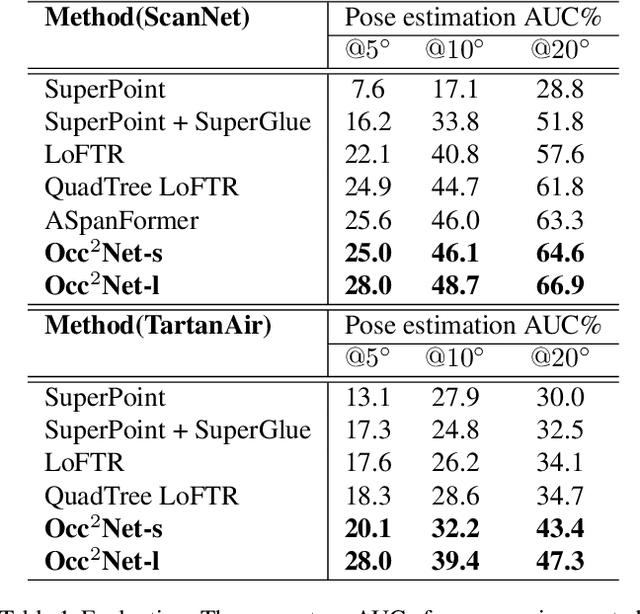
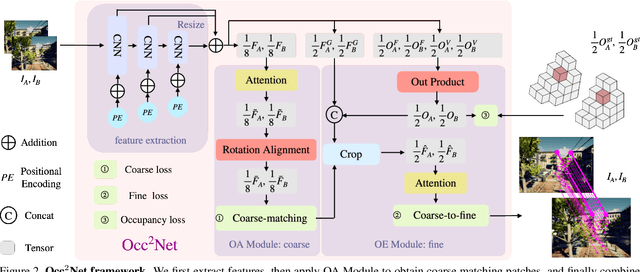
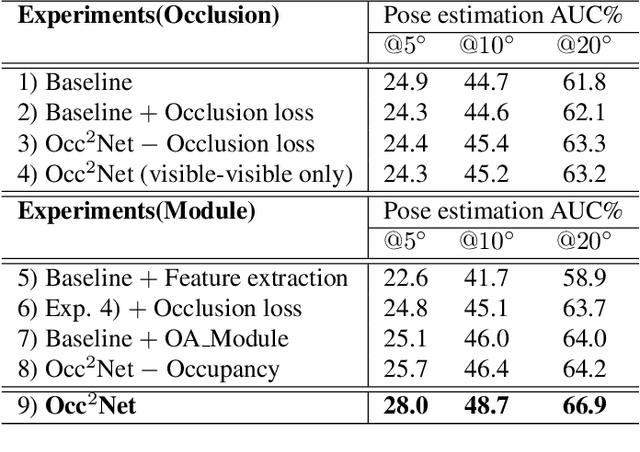
Image matching is a fundamental and critical task in various visual applications, such as Simultaneous Localization and Mapping (SLAM) and image retrieval, which require accurate pose estimation. However, most existing methods ignore the occlusion relations between objects caused by camera motion and scene structure. In this paper, we propose Occ$^2$Net, a novel image matching method that models occlusion relations using 3D occupancy and infers matching points in occluded regions. Thanks to the inductive bias encoded in the Occupancy Estimation (OE) module, it greatly simplifies bootstrapping of a multi-view consistent 3D representation that can then integrate information from multiple views. Together with an Occlusion-Aware (OA) module, it incorporates attention layers and rotation alignment to enable matching between occluded and visible points. We evaluate our method on both real-world and simulated datasets and demonstrate its superior performance over state-of-the-art methods on several metrics, especially in occlusion scenarios.
Dual Aggregation Transformer for Image Super-Resolution
Aug 07, 2023
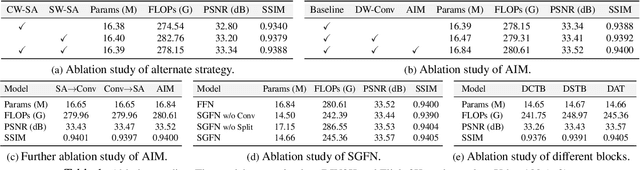
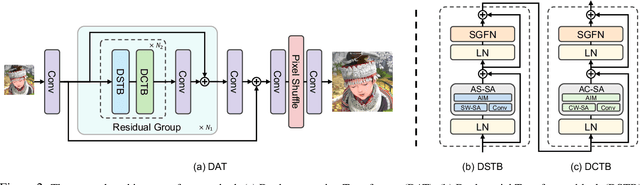
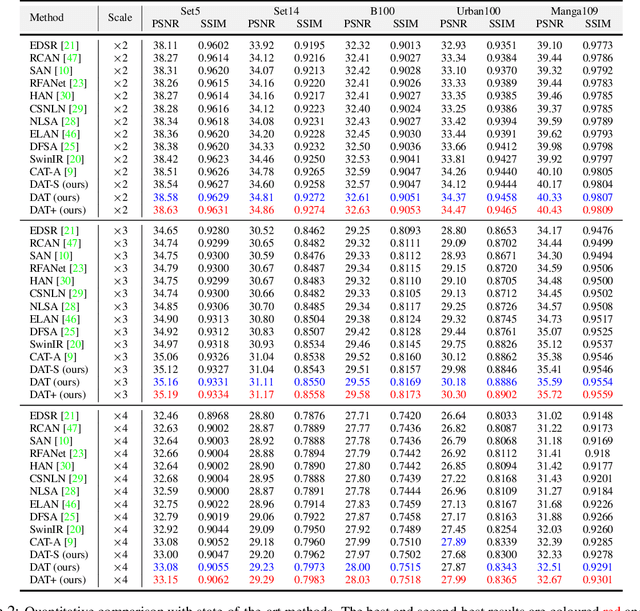
Transformer has recently gained considerable popularity in low-level vision tasks, including image super-resolution (SR). These networks utilize self-attention along different dimensions, spatial or channel, and achieve impressive performance. This inspires us to combine the two dimensions in Transformer for a more powerful representation capability. Based on the above idea, we propose a novel Transformer model, Dual Aggregation Transformer (DAT), for image SR. Our DAT aggregates features across spatial and channel dimensions, in the inter-block and intra-block dual manner. Specifically, we alternately apply spatial and channel self-attention in consecutive Transformer blocks. The alternate strategy enables DAT to capture the global context and realize inter-block feature aggregation. Furthermore, we propose the adaptive interaction module (AIM) and the spatial-gate feed-forward network (SGFN) to achieve intra-block feature aggregation. AIM complements two self-attention mechanisms from corresponding dimensions. Meanwhile, SGFN introduces additional non-linear spatial information in the feed-forward network. Extensive experiments show that our DAT surpasses current methods. Code and models are obtainable at https://github.com/zhengchen1999/DAT.
Prototype Generation: Robust Feature Visualisation for Data Independent Interpretability
Sep 29, 2023We introduce Prototype Generation, a stricter and more robust form of feature visualisation for model-agnostic, data-independent interpretability of image classification models. We demonstrate its ability to generate inputs that result in natural activation paths, countering previous claims that feature visualisation algorithms are untrustworthy due to the unnatural internal activations. We substantiate these claims by quantitatively measuring similarity between the internal activations of our generated prototypes and natural images. We also demonstrate how the interpretation of generated prototypes yields important insights, highlighting spurious correlations and biases learned by models which quantitative methods over test-sets cannot identify.
Privacy Assessment on Reconstructed Images: Are Existing Evaluation Metrics Faithful to Human Perception?
Sep 22, 2023
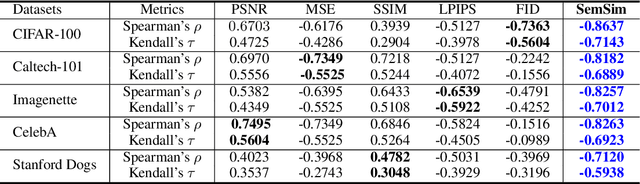
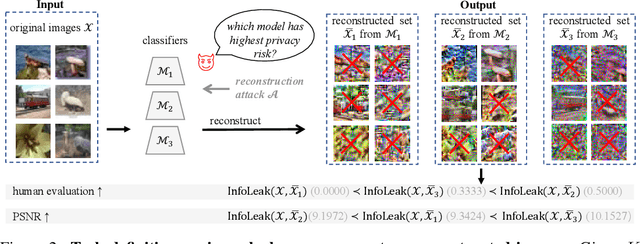
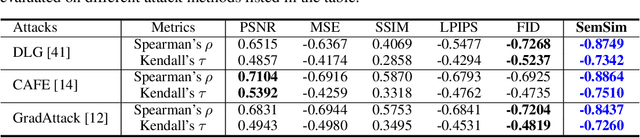
Hand-crafted image quality metrics, such as PSNR and SSIM, are commonly used to evaluate model privacy risk under reconstruction attacks. Under these metrics, reconstructed images that are determined to resemble the original one generally indicate more privacy leakage. Images determined as overall dissimilar, on the other hand, indicate higher robustness against attack. However, there is no guarantee that these metrics well reflect human opinions, which, as a judgement for model privacy leakage, are more trustworthy. In this paper, we comprehensively study the faithfulness of these hand-crafted metrics to human perception of privacy information from the reconstructed images. On 5 datasets ranging from natural images, faces, to fine-grained classes, we use 4 existing attack methods to reconstruct images from many different classification models and, for each reconstructed image, we ask multiple human annotators to assess whether this image is recognizable. Our studies reveal that the hand-crafted metrics only have a weak correlation with the human evaluation of privacy leakage and that even these metrics themselves often contradict each other. These observations suggest risks of current metrics in the community. To address this potential risk, we propose a learning-based measure called SemSim to evaluate the Semantic Similarity between the original and reconstructed images. SemSim is trained with a standard triplet loss, using an original image as an anchor, one of its recognizable reconstructed images as a positive sample, and an unrecognizable one as a negative. By training on human annotations, SemSim exhibits a greater reflection of privacy leakage on the semantic level. We show that SemSim has a significantly higher correlation with human judgment compared with existing metrics. Moreover, this strong correlation generalizes to unseen datasets, models and attack methods.
Single-shot experimental-numerical twin-image removal in lensless digital holographic microscopy
Aug 08, 2023Lensless digital holographic microscopy (LDHM) offers very large field-of-view label-free imaging crucial, e.g., in high-throughput particle tracking and biomedical examination of cells and tissues. Compact layouts promote point-of-case and out-of-laboratory applications. The LDHM, based on the Gabor in-line holographic principle, is inherently spoiled by the twin-image effect, which complicates the quantitative analysis of reconstructed phase and amplitude maps. Popular family of solutions consists of numerical methods, which tend to minimize twin-image upon iterative process based on data redundancy. Additional hologram recordings are needed, and final results heavily depend on the algorithmic parameters, however. In this contribution we present a novel single-shot experimental-numerical twin-image removal technique for LDHM. It leverages two-source off-axis hologram recording deploying simple fiber splitter. Additionally, we introduce a novel phase retrieval numerical algorithm specifically tailored to the acquired holograms, that provides twin-image-free reconstruction without compromising the resolution. We quantitatively and qualitatively verify proposed method employing phase test target and cheek cells biosample. The results demonstrate that the proposed technique enables low-cost, out-of-laboratory LDHM imaging with enhanced precision, achieved through the elimination of twin-image errors. This advancement opens new avenues for more accurate technical and biomedical imaging applications using LDHM, particularly in scenarios where cost-effective and portable imaging solutions are desired.
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023
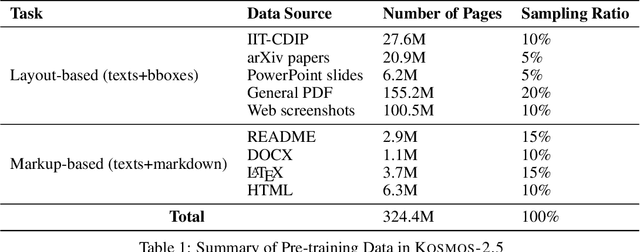
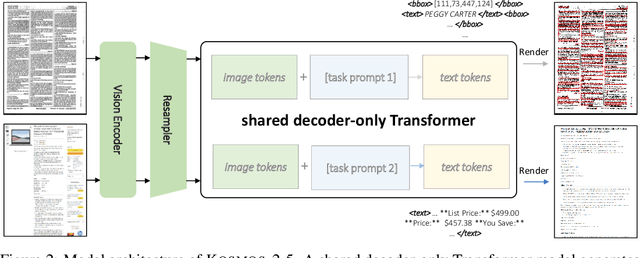

We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.