 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Computational Image Formation
Jul 21, 2023
At the pinnacle of computational imaging is the co-optimization of camera and algorithm. This, however, is not the only form of computational imaging. In problems such as imaging through adverse weather, the bigger challenge is how to accurately simulate the forward degradation process so that we can synthesize data to train reconstruction models and/or integrating the forward model as part of the reconstruction algorithm. This article introduces the concept of computational image formation (CIF). Compared to the standard inverse problems where the goal is to recover the latent image $\mathbf{x}$ from the observation $\mathbf{y} = \mathcal{G}(\mathbf{x})$, CIF shifts the focus to designing an approximate mapping $\mathcal{H}_{\theta}$ such that $\mathcal{H}_{\theta} \approx \mathcal{G}$ while giving a better image reconstruction result. The word ``computational'' highlights the fact that the image formation is now replaced by a numerical simulator. While matching nature remains an important goal, CIF pays even greater attention on strategically choosing an $\mathcal{H}_{\theta}$ so that the reconstruction performance is maximized. The goal of this article is to conceptualize the idea of CIF by elaborating on its meaning and implications. The first part of the article is a discussion on the four attributes of a CIF simulator: accurate enough to mimic $\mathcal{G}$, fast enough to be integrated as part of the reconstruction, providing a well-posed inverse problem when plugged into the reconstruction, and differentiable in the backpropagation sense. The second part of the article is a detailed case study based on imaging through atmospheric turbulence. The third part of the article is a collection of other examples that fall into the category of CIF. Finally, thoughts about the future direction and recommendations to the community are shared.
FLIP: Cross-domain Face Anti-spoofing with Language Guidance
Sep 28, 2023Face anti-spoofing (FAS) or presentation attack detection is an essential component of face recognition systems deployed in security-critical applications. Existing FAS methods have poor generalizability to unseen spoof types, camera sensors, and environmental conditions. Recently, vision transformer (ViT) models have been shown to be effective for the FAS task due to their ability to capture long-range dependencies among image patches. However, adaptive modules or auxiliary loss functions are often required to adapt pre-trained ViT weights learned on large-scale datasets such as ImageNet. In this work, we first show that initializing ViTs with multimodal (e.g., CLIP) pre-trained weights improves generalizability for the FAS task, which is in line with the zero-shot transfer capabilities of vision-language pre-trained (VLP) models. We then propose a novel approach for robust cross-domain FAS by grounding visual representations with the help of natural language. Specifically, we show that aligning the image representation with an ensemble of class descriptions (based on natural language semantics) improves FAS generalizability in low-data regimes. Finally, we propose a multimodal contrastive learning strategy to boost feature generalization further and bridge the gap between source and target domains. Extensive experiments on three standard protocols demonstrate that our method significantly outperforms the state-of-the-art methods, achieving better zero-shot transfer performance than five-shot transfer of adaptive ViTs. Code: https://github.com/koushiksrivats/FLIP
Reversing Deep Face Embeddings with Probable Privacy Protection
Oct 04, 2023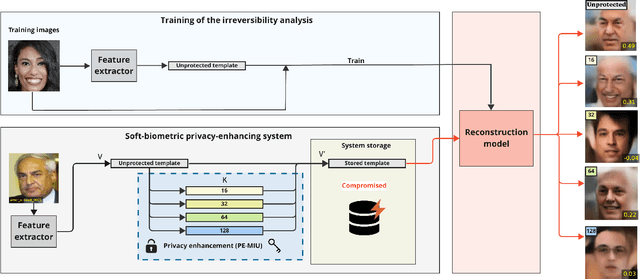
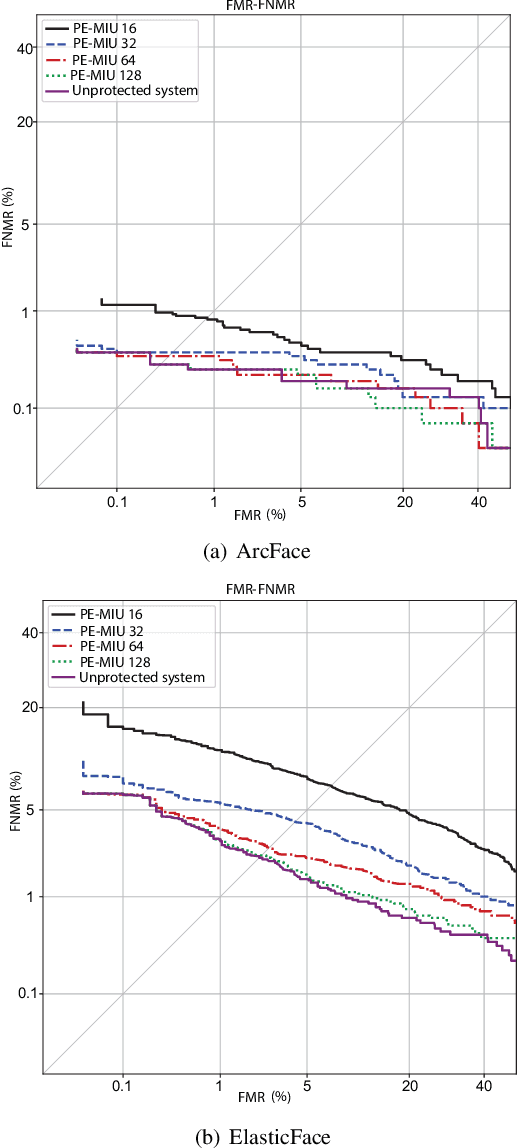

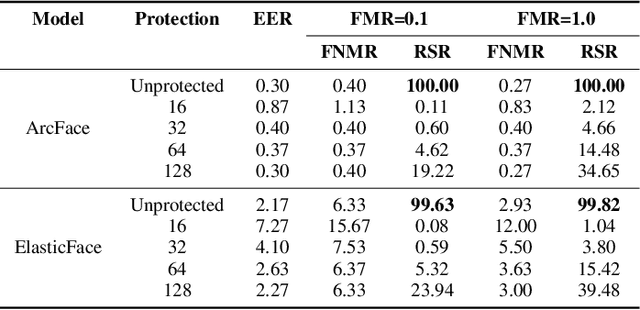
Generally, privacy-enhancing face recognition systems are designed to offer permanent protection of face embeddings. Recently, so-called soft-biometric privacy-enhancement approaches have been introduced with the aim of canceling soft-biometric attributes. These methods limit the amount of soft-biometric information (gender or skin-colour) that can be inferred from face embeddings. Previous work has underlined the need for research into rigorous evaluations and standardised evaluation protocols when assessing privacy protection capabilities. Motivated by this fact, this paper explores to what extent the non-invertibility requirement can be met by methods that claim to provide soft-biometric privacy protection. Additionally, a detailed vulnerability assessment of state-of-the-art face embedding extractors is analysed in terms of the transformation complexity used for privacy protection. In this context, a well-known state-of-the-art face image reconstruction approach has been evaluated on protected face embeddings to break soft biometric privacy protection. Experimental results show that biometric privacy-enhanced face embeddings can be reconstructed with an accuracy of up to approximately 98%, depending on the complexity of the protection algorithm.
Optimizing Key-Selection for Face-based One-Time Biometrics via Morphing
Oct 04, 2023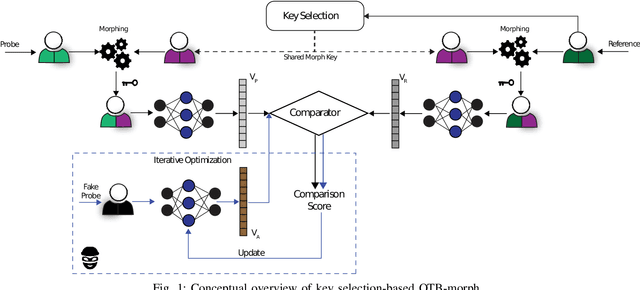

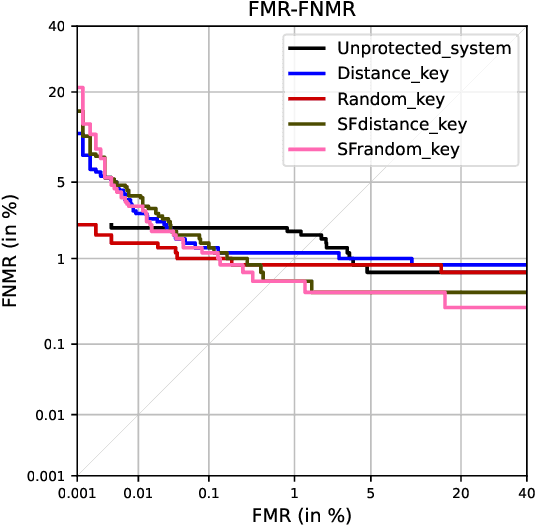
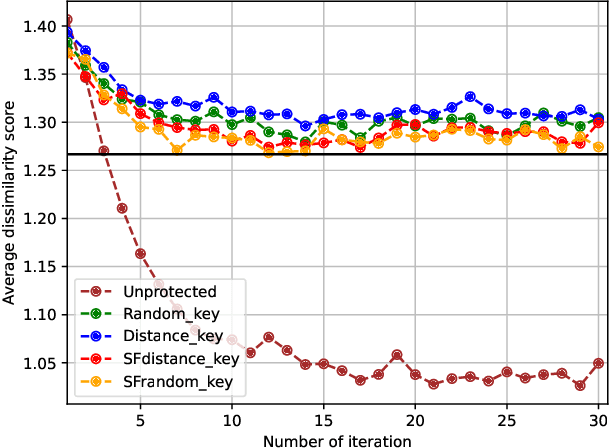
Nowadays, facial recognition systems are still vulnerable to adversarial attacks. These attacks vary from simple perturbations of the input image to modifying the parameters of the recognition model to impersonate an authorised subject. So-called privacy-enhancing facial recognition systems have been mostly developed to provide protection of stored biometric reference data, i.e. templates. In the literature, privacy-enhancing facial recognition approaches have focused solely on conventional security threats at the template level, ignoring the growing concern related to adversarial attacks. Up to now, few works have provided mechanisms to protect face recognition against adversarial attacks while maintaining high security at the template level. In this paper, we propose different key selection strategies to improve the security of a competitive cancelable scheme operating at the signal level. Experimental results show that certain strategies based on signal-level key selection can lead to complete blocking of the adversarial attack based on an iterative optimization for the most secure threshold, while for the most practical threshold, the attack success chance can be decreased to approximately 5.0%.
Self2Self+: Single-Image Denoising with Self-Supervised Learning and Image Quality Assessment Loss
Jul 20, 2023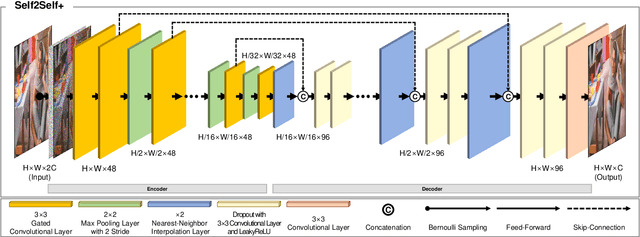
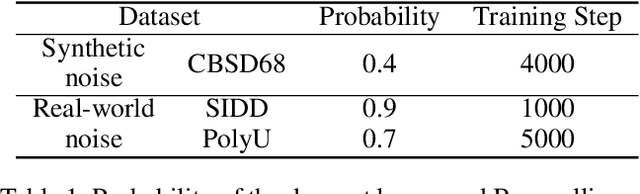

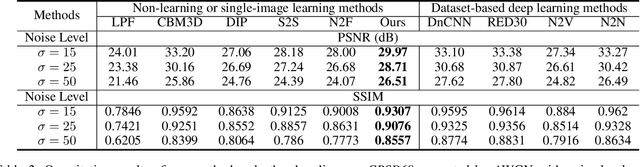
Recently, denoising methods based on supervised learning have exhibited promising performance. However, their reliance on external datasets containing noisy-clean image pairs restricts their applicability. To address this limitation, researchers have focused on training denoising networks using solely a set of noisy inputs. To improve the feasibility of denoising procedures, in this study, we proposed a single-image self-supervised learning method in which only the noisy input image is used for network training. Gated convolution was used for feature extraction and no-reference image quality assessment was used for guiding the training process. Moreover, the proposed method sampled instances from the input image dataset using Bernoulli sampling with a certain dropout rate for training. The corresponding result was produced by averaging the generated predictions from various instances of the trained network with dropouts. The experimental results indicated that the proposed method achieved state-of-the-art denoising performance on both synthetic and real-world datasets. This highlights the effectiveness and practicality of our method as a potential solution for various noise removal tasks.
WSAM: Visual Explanations from Style Augmentation as Adversarial Attacker and Their Influence in Image Classification
Aug 29, 2023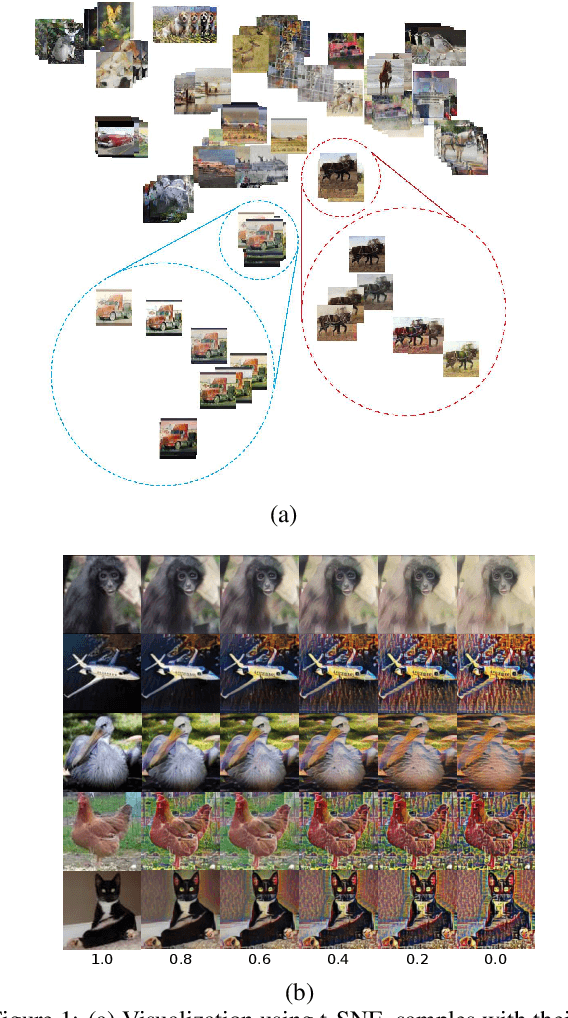

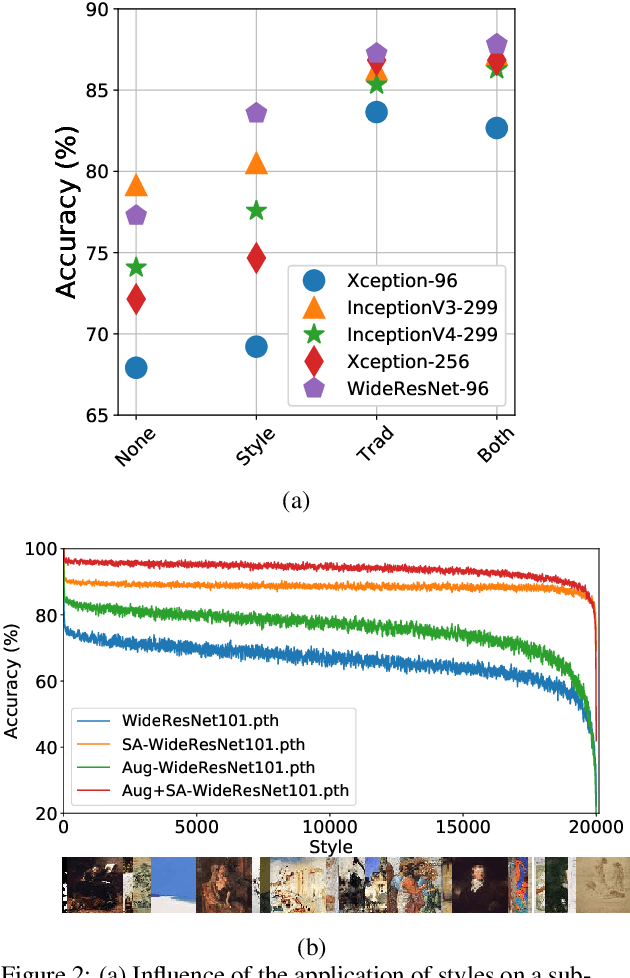
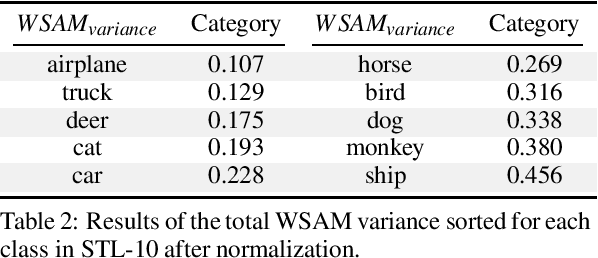
Currently, style augmentation is capturing attention due to convolutional neural networks (CNN) being strongly biased toward recognizing textures rather than shapes. Most existing styling methods either perform a low-fidelity style transfer or a weak style representation in the embedding vector. This paper outlines a style augmentation algorithm using stochastic-based sampling with noise addition to improving randomization on a general linear transformation for style transfer. With our augmentation strategy, all models not only present incredible robustness against image stylizing but also outperform all previous methods and surpass the state-of-the-art performance for the STL-10 dataset. In addition, we present an analysis of the model interpretations under different style variations. At the same time, we compare comprehensive experiments demonstrating the performance when applied to deep neural architectures in training settings.
Retinex-guided Channel-grouping based Patch Swap for Arbitrary Style Transfer
Sep 19, 2023The basic principle of the patch-matching based style transfer is to substitute the patches of the content image feature maps by the closest patches from the style image feature maps. Since the finite features harvested from one single aesthetic style image are inadequate to represent the rich textures of the content natural image, existing techniques treat the full-channel style feature patches as simple signal tensors and create new style feature patches via signal-level fusion, which ignore the implicit diversities existed in style features and thus fail for generating better stylised results. In this paper, we propose a Retinex theory guided, channel-grouping based patch swap technique to solve the above challenges. Channel-grouping strategy groups the style feature maps into surface and texture channels, which prevents the winner-takes-all problem. Retinex theory based decomposition controls a more stable channel code rate generation. In addition, we provide complementary fusion and multi-scale generation strategy to prevent unexpected black area and over-stylised results respectively. Experimental results demonstrate that the proposed method outperforms the existing techniques in providing more style-consistent textures while keeping the content fidelity.
HOD: A Benchmark Dataset for Harmful Object Detection
Oct 08, 2023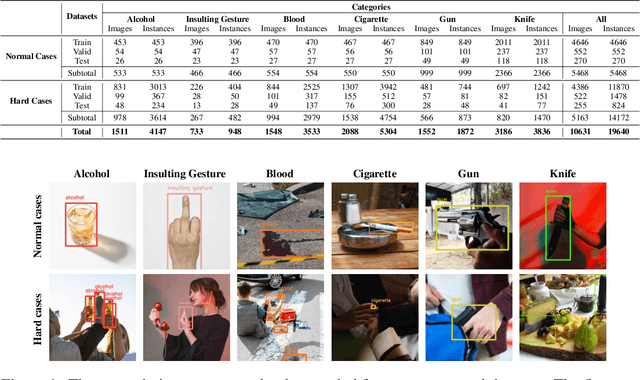
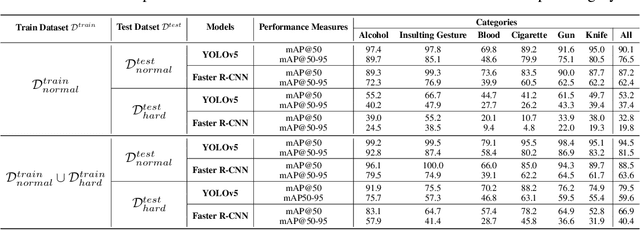

Recent multi-media data such as images and videos have been rapidly spread out on various online services such as social network services (SNS). With the explosive growth of online media services, the number of image content that may harm users is also growing exponentially. Thus, most recent online platforms such as Facebook and Instagram have adopted content filtering systems to prevent the prevalence of harmful content and reduce the possible risk of adverse effects on users. Unfortunately, computer vision research on detecting harmful content has not yet attracted attention enough. Users of each platform still manually click the report button to recognize patterns of harmful content they dislike when exposed to harmful content. However, the problem with manual reporting is that users are already exposed to harmful content. To address these issues, our research goal in this work is to develop automatic harmful object detection systems for online services. We present a new benchmark dataset for harmful object detection. Unlike most related studies focusing on a small subset of object categories, our dataset addresses various categories. Specifically, our proposed dataset contains more than 10,000 images across 6 categories that might be harmful, consisting of not only normal cases but also hard cases that are difficult to detect. Moreover, we have conducted extensive experiments to evaluate the effectiveness of our proposed dataset. We have utilized the recently proposed state-of-the-art (SOTA) object detection architectures and demonstrated our proposed dataset can be greatly useful for the real-time harmful object detection task. The whole source codes and datasets are publicly accessible at https://github.com/poori-nuna/HOD-Benchmark-Dataset.
OSNet & MNetO: Two Types of General Reconstruction Architectures for Linear Computed Tomography in Multi-Scenarios
Sep 25, 2023Recently, linear computed tomography (LCT) systems have actively attracted attention. To weaken projection truncation and image the region of interest (ROI) for LCT, the backprojection filtration (BPF) algorithm is an effective solution. However, in BPF for LCT, it is difficult to achieve stable interior reconstruction, and for differentiated backprojection (DBP) images of LCT, multiple rotation-finite inversion of Hilbert transform (Hilbert filtering)-inverse rotation operations will blur the image. To satisfy multiple reconstruction scenarios for LCT, including interior ROI, complete object, and exterior region beyond field-of-view (FOV), and avoid the rotation operations of Hilbert filtering, we propose two types of reconstruction architectures. The first overlays multiple DBP images to obtain a complete DBP image, then uses a network to learn the overlying Hilbert filtering function, referred to as the Overlay-Single Network (OSNet). The second uses multiple networks to train different directional Hilbert filtering models for DBP images of multiple linear scannings, respectively, and then overlays the reconstructed results, i.e., Multiple Networks Overlaying (MNetO). In two architectures, we introduce a Swin Transformer (ST) block to the generator of pix2pixGAN to extract both local and global features from DBP images at the same time. We investigate two architectures from different networks, FOV sizes, pixel sizes, number of projections, geometric magnification, and processing time. Experimental results show that two architectures can both recover images. OSNet outperforms BPF in various scenarios. For the different networks, ST-pix2pixGAN is superior to pix2pixGAN and CycleGAN. MNetO exhibits a few artifacts due to the differences among the multiple models, but any one of its models is suitable for imaging the exterior edge in a certain direction.
Efficient Object Rearrangement via Multi-view Fusion
Sep 16, 2023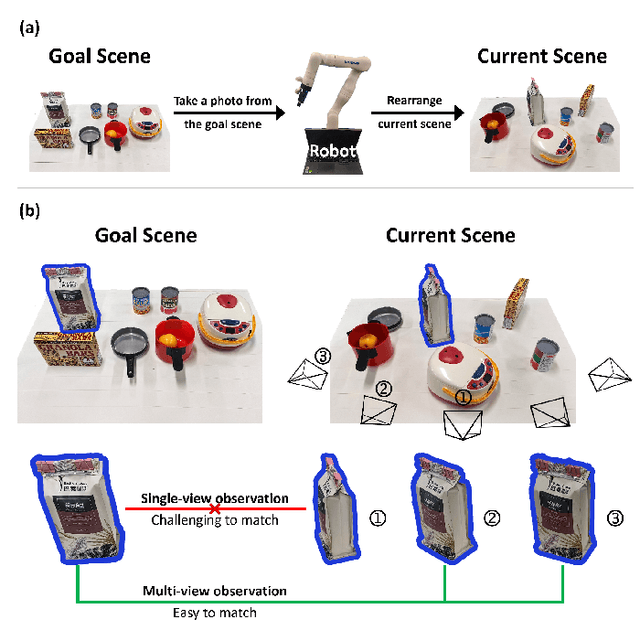
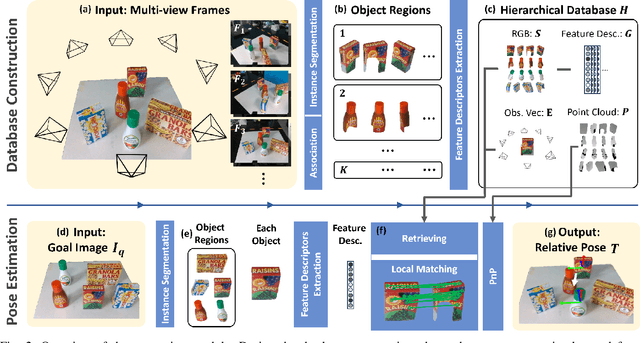
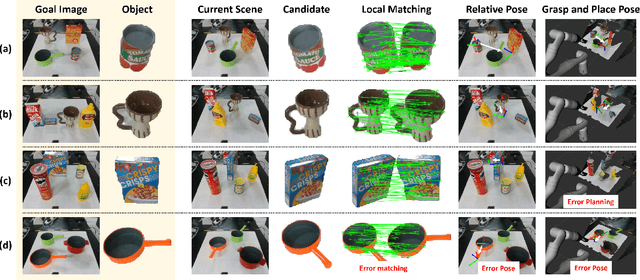
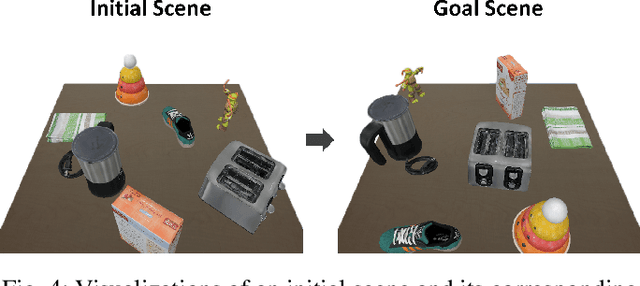
The prospect of assistive robots aiding in object organization has always been compelling. In an image-goal setting, the robot rearranges the current scene to match the single image captured from the goal scene. The key to an image-goal rearrangement system is estimating the desired placement pose of each object based on the single goal image and observations from the current scene. In order to establish sufficient associations for accurate estimation, the system should observe an object from a viewpoint similar to that in the goal image. Existing image-goal rearrangement systems, due to their reliance on a fixed viewpoint for perception, often require redundant manipulations to randomly adjust an object's pose for a better perspective. Addressing this inefficiency, we introduce a novel object rearrangement system that employs multi-view fusion. By observing the current scene from multiple viewpoints before manipulating objects, our approach can estimate a more accurate pose without redundant manipulation times. A standard visual localization pipeline at the object level is developed to capitalize on the advantages of multi-view observations. Simulation results demonstrate that the efficiency of our system outperforms existing single-view systems. The effectiveness of our system is further validated in a physical experiment.