 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FGFusion: Fine-Grained Lidar-Camera Fusion for 3D Object Detection
Sep 21, 2023
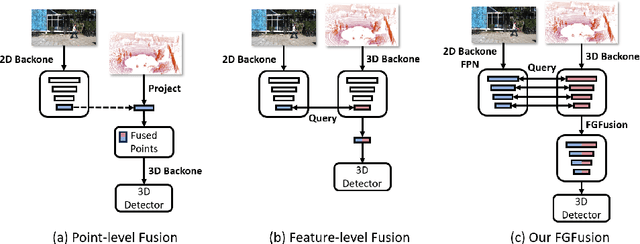
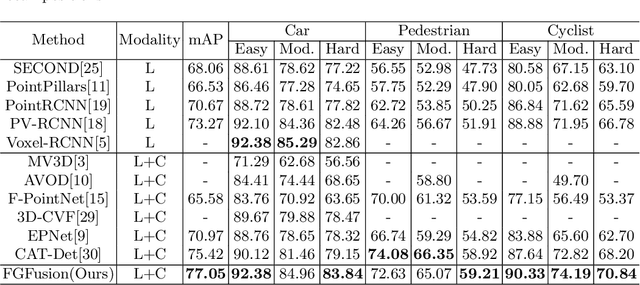
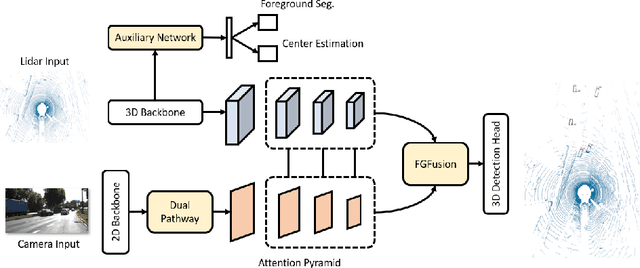
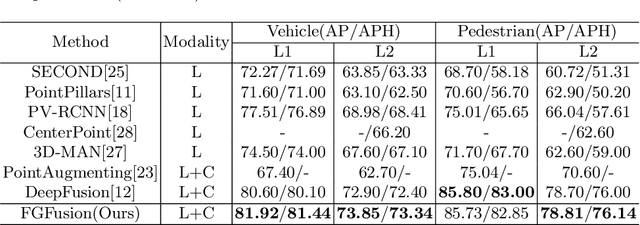
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While most prevalent methods progressively downscale the 3D point clouds and camera images and then fuse the high-level features, the downscaled features inevitably lose low-level detailed information. In this paper, we propose Fine-Grained Lidar-Camera Fusion (FGFusion) that make full use of multi-scale features of image and point cloud and fuse them in a fine-grained way. First, we design a dual pathway hierarchy structure to extract both high-level semantic and low-level detailed features of the image. Second, an auxiliary network is introduced to guide point cloud features to better learn the fine-grained spatial information. Finally, we propose multi-scale fusion (MSF) to fuse the last N feature maps of image and point cloud. Extensive experiments on two popular autonomous driving benchmarks, i.e. KITTI and Waymo, demonstrate the effectiveness of our method.
DeepMesh: Mesh-based Cardiac Motion Tracking using Deep Learning
Sep 25, 2023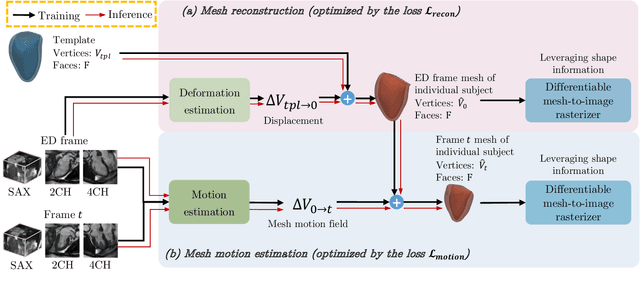
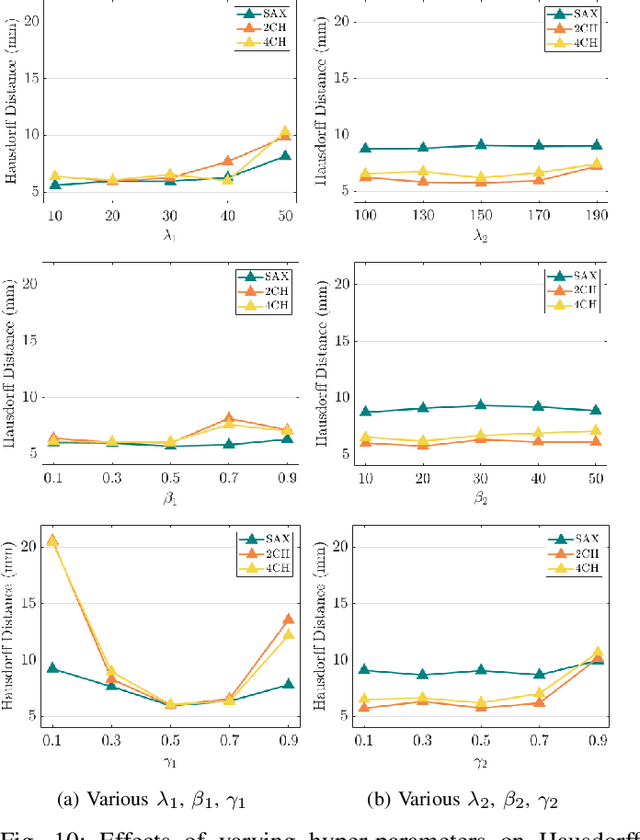
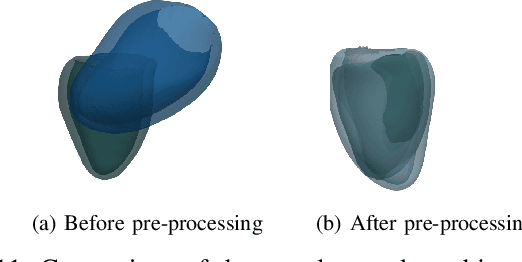
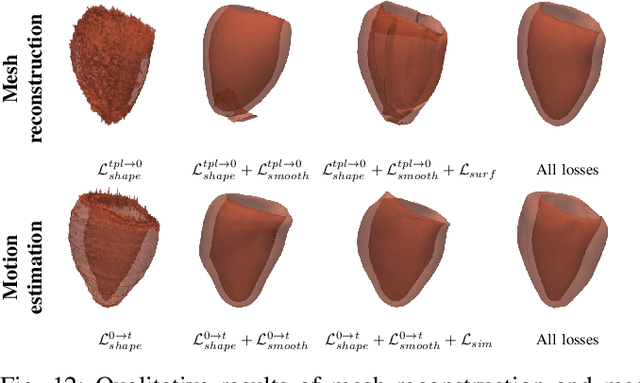
3D motion estimation from cine cardiac magnetic resonance (CMR) images is important for the assessment of cardiac function and the diagnosis of cardiovascular diseases. Current state-of-the art methods focus on estimating dense pixel-/voxel-wise motion fields in image space, which ignores the fact that motion estimation is only relevant and useful within the anatomical objects of interest, e.g., the heart. In this work, we model the heart as a 3D mesh consisting of epi- and endocardial surfaces. We propose a novel learning framework, DeepMesh, which propagates a template heart mesh to a subject space and estimates the 3D motion of the heart mesh from CMR images for individual subjects. In DeepMesh, the heart mesh of the end-diastolic frame of an individual subject is first reconstructed from the template mesh. Mesh-based 3D motion fields with respect to the end-diastolic frame are then estimated from 2D short- and long-axis CMR images. By developing a differentiable mesh-to-image rasterizer, DeepMesh is able to leverage 2D shape information from multiple anatomical views for 3D mesh reconstruction and mesh motion estimation. The proposed method estimates vertex-wise displacement and thus maintains vertex correspondences between time frames, which is important for the quantitative assessment of cardiac function across different subjects and populations. We evaluate DeepMesh on CMR images acquired from the UK Biobank. We focus on 3D motion estimation of the left ventricle in this work. Experimental results show that the proposed method quantitatively and qualitatively outperforms other image-based and mesh-based cardiac motion tracking methods.
Towards A Robust Group-level Emotion Recognition via Uncertainty-Aware Learning
Oct 06, 2023
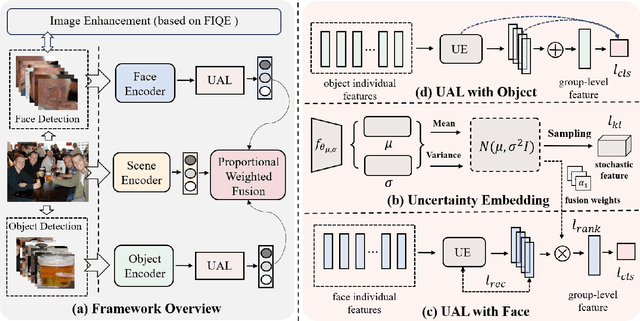
Group-level emotion recognition (GER) is an inseparable part of human behavior analysis, aiming to recognize an overall emotion in a multi-person scene. However, the existing methods are devoted to combing diverse emotion cues while ignoring the inherent uncertainties under unconstrained environments, such as congestion and occlusion occurring within a group. Additionally, since only group-level labels are available, inconsistent emotion predictions among individuals in one group can confuse the network. In this paper, we propose an uncertainty-aware learning (UAL) method to extract more robust representations for GER. By explicitly modeling the uncertainty of each individual, we utilize stochastic embedding drawn from a Gaussian distribution instead of deterministic point embedding. This representation captures the probabilities of different emotions and generates diverse predictions through this stochasticity during the inference stage. Furthermore, uncertainty-sensitive scores are adaptively assigned as the fusion weights of individuals' face within each group. Moreover, we develop an image enhancement module to enhance the model's robustness against severe noise. The overall three-branch model, encompassing face, object, and scene component, is guided by a proportional-weighted fusion strategy and integrates the proposed uncertainty-aware method to produce the final group-level output. Experimental results demonstrate the effectiveness and generalization ability of our method across three widely used databases.
BrainSCUBA: Fine-Grained Natural Language Captions of Visual Cortex Selectivity
Oct 06, 2023Understanding the functional organization of higher visual cortex is a central focus in neuroscience. Past studies have primarily mapped the visual and semantic selectivity of neural populations using hand-selected stimuli, which may potentially bias results towards pre-existing hypotheses of visual cortex functionality. Moving beyond conventional approaches, we introduce a data-driven method that generates natural language descriptions for images predicted to maximally activate individual voxels of interest. Our method -- Semantic Captioning Using Brain Alignments ("BrainSCUBA") -- builds upon the rich embedding space learned by a contrastive vision-language model and utilizes a pre-trained large language model to generate interpretable captions. We validate our method through fine-grained voxel-level captioning across higher-order visual regions. We further perform text-conditioned image synthesis with the captions, and show that our images are semantically coherent and yield high predicted activations. Finally, to demonstrate how our method enables scientific discovery, we perform exploratory investigations on the distribution of "person" representations in the brain, and discover fine-grained semantic selectivity in body-selective areas. Unlike earlier studies that decode text, our method derives voxel-wise captions of semantic selectivity. Our results show that BrainSCUBA is a promising means for understanding functional preferences in the brain, and provides motivation for further hypothesis-driven investigation of visual cortex.
Module-wise Adaptive Distillation for Multimodality Foundation Models
Oct 06, 2023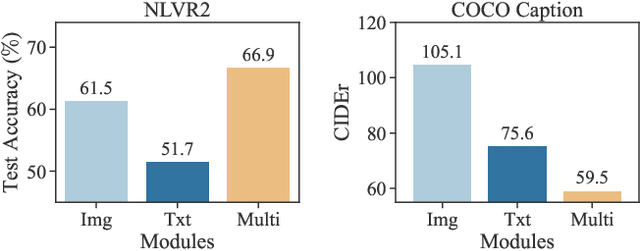
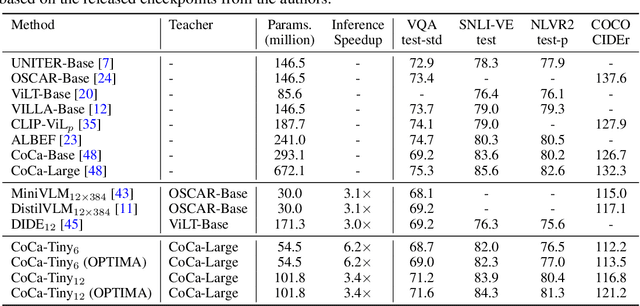
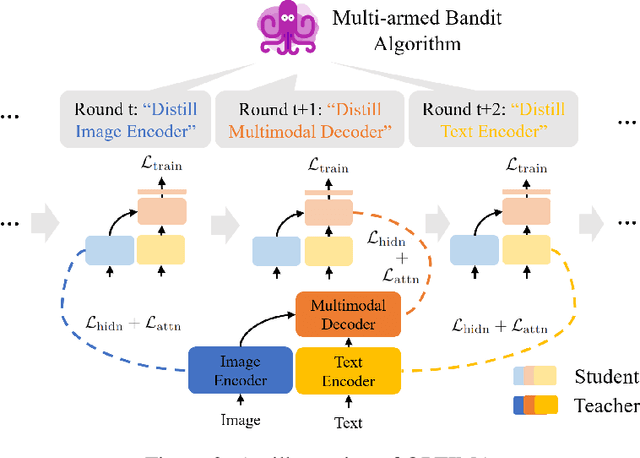
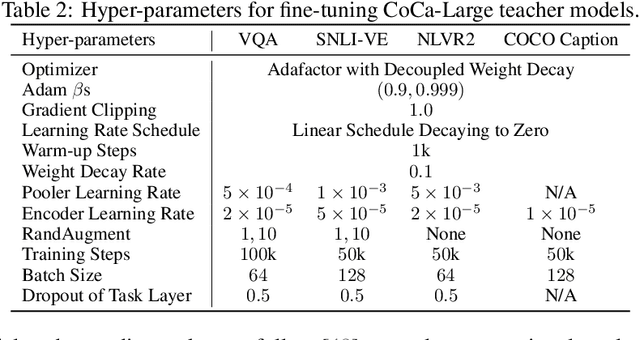
Pre-trained multimodal foundation models have demonstrated remarkable generalizability but pose challenges for deployment due to their large sizes. One effective approach to reducing their sizes is layerwise distillation, wherein small student models are trained to match the hidden representations of large teacher models at each layer. Motivated by our observation that certain architecture components, referred to as modules, contribute more significantly to the student's performance than others, we propose to track the contributions of individual modules by recording the loss decrement after distillation each module and choose the module with a greater contribution to distill more frequently. Such an approach can be naturally formulated as a multi-armed bandit (MAB) problem, where modules and loss decrements are considered as arms and rewards, respectively. We then develop a modified-Thompson sampling algorithm named OPTIMA to address the nonstationarity of module contributions resulting from model updating. Specifically, we leverage the observed contributions in recent history to estimate the changing contribution of each module and select modules based on these estimations to maximize the cumulative contribution. We evaluate the effectiveness of OPTIMA through distillation experiments on various multimodal understanding and image captioning tasks, using the CoCa-Large model (Yu et al., 2022) as the teacher model.
SPADE: Sparsity-Guided Debugging for Deep Neural Networks
Oct 06, 2023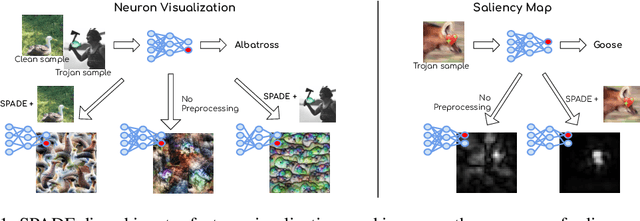
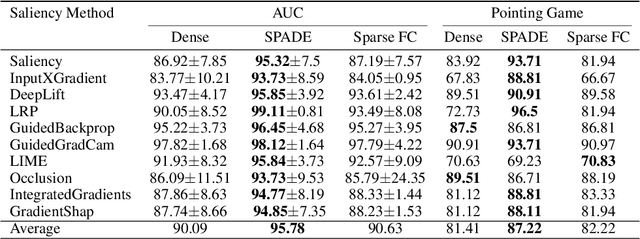

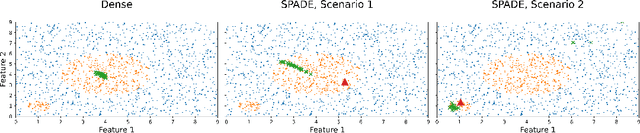
Interpretability, broadly defined as mechanisms for understanding why and how machine learning models reach their decisions, is one of the key open goals at the intersection of deep learning theory and practice. Towards this goal, multiple tools have been proposed to aid a human examiner in reasoning about a network's behavior in general or on a set of instances. However, the outputs of these tools-such as input saliency maps or neuron visualizations-are frequently difficult for a human to interpret, or even misleading, due, in particular, to the fact that neurons can be multifaceted, i.e., a single neuron can be associated with multiple distinct feature combinations. In this paper, we present a new general approach to address this problem, called SPADE, which, given a trained model and a target sample, uses sample-targeted pruning to provide a "trace" of the network's execution on the sample, reducing the network to the connections that are most relevant to the specific prediction. We demonstrate that preprocessing with SPADE significantly increases both the accuracy of image saliency maps across several interpretability methods and the usefulness of neuron visualizations, aiding humans in reasoning about network behavior. Our findings show that sample-specific pruning of connections can disentangle multifaceted neurons, leading to consistently improved interpretability.
Rethinking Cross-Domain Pedestrian Detection: A Background-Focused Distribution Alignment Framework for Instance-Free One-Stage Detectors
Sep 15, 2023
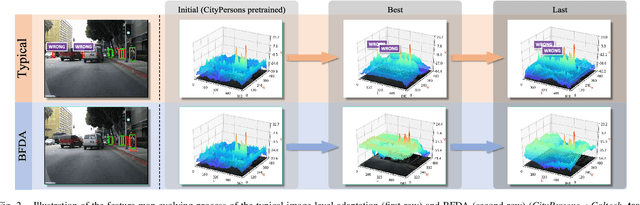


Cross-domain pedestrian detection aims to generalize pedestrian detectors from one label-rich domain to another label-scarce domain, which is crucial for various real-world applications. Most recent works focus on domain alignment to train domain-adaptive detectors either at the instance level or image level. From a practical point of view, one-stage detectors are faster. Therefore, we concentrate on designing a cross-domain algorithm for rapid one-stage detectors that lacks instance-level proposals and can only perform image-level feature alignment. However, pure image-level feature alignment causes the foreground-background misalignment issue to arise, i.e., the foreground features in the source domain image are falsely aligned with background features in the target domain image. To address this issue, we systematically analyze the importance of foreground and background in image-level cross-domain alignment, and learn that background plays a more critical role in image-level cross-domain alignment. Therefore, we focus on cross-domain background feature alignment while minimizing the influence of foreground features on the cross-domain alignment stage. This paper proposes a novel framework, namely, background-focused distribution alignment (BFDA), to train domain adaptive onestage pedestrian detectors. Specifically, BFDA first decouples the background features from the whole image feature maps and then aligns them via a novel long-short-range discriminator.
* This paper published on IEEE Transactions on Image Processing on August 2023.See https://ieeexplore.ieee.org/document/10231122
Rephrase, Augment, Reason: Visual Grounding of Questions for Vision-Language Models
Oct 09, 2023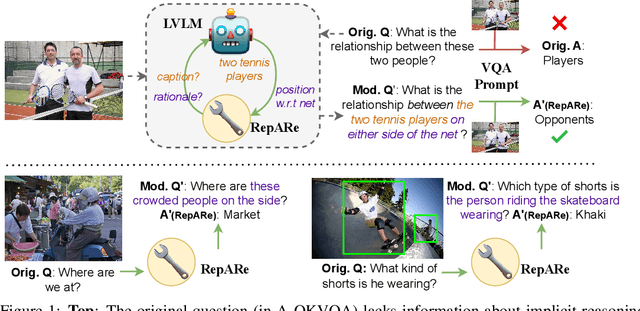
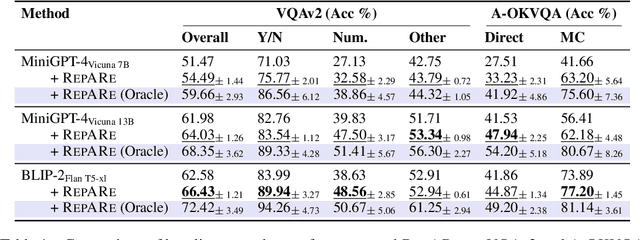
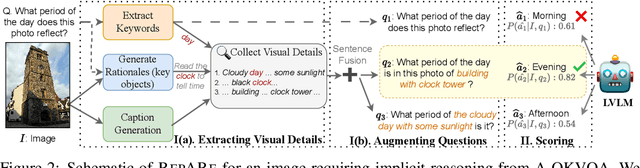
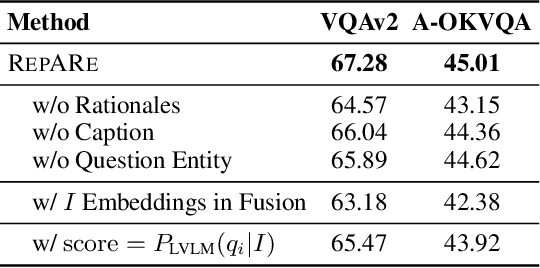
An increasing number of vision-language tasks can be handled with little to no training, i.e., in a zero and few-shot manner, by marrying large language models (LLMs) to vision encoders, resulting in large vision-language models (LVLMs). While this has huge upsides, such as not requiring training data or custom architectures, how an input is presented to a LVLM can have a major impact on zero-shot model performance. In particular, inputs phrased in an underspecified way can result in incorrect answers due to factors like missing visual information, complex implicit reasoning, or linguistic ambiguity. Therefore, adding visually grounded information to the input as a preemptive clarification should improve model performance by reducing underspecification, e.g., by localizing objects and disambiguating references. Similarly, in the VQA setting, changing the way questions are framed can make them easier for models to answer. To this end, we present Rephrase, Augment and Reason (RepARe), a gradient-free framework that extracts salient details about the image using the underlying LVLM as a captioner and reasoner, in order to propose modifications to the original question. We then use the LVLM's confidence over a generated answer as an unsupervised scoring function to select the rephrased question most likely to improve zero-shot performance. Focusing on two visual question answering tasks, we show that RepARe can result in a 3.85% (absolute) increase in zero-shot performance on VQAv2 and a 6.41% point increase on A-OKVQA. Additionally, we find that using gold answers for oracle question candidate selection achieves a substantial gain in VQA accuracy by up to 14.41%. Through extensive analysis, we demonstrate that outputs from RepARe increase syntactic complexity, and effectively utilize vision-language interaction and the frozen language model in LVLMs.
INR-LDDMM: Fluid-based Medical Image Registration Integrating Implicit Neural Representation and Large Deformation Diffeomorphic Metric Mapping
Aug 21, 2023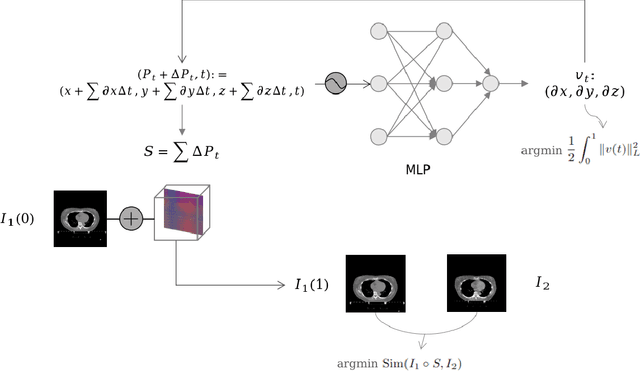
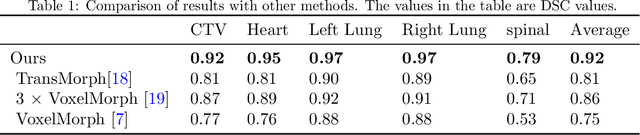
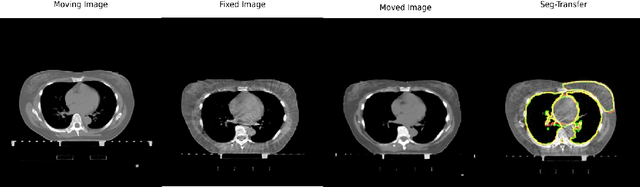
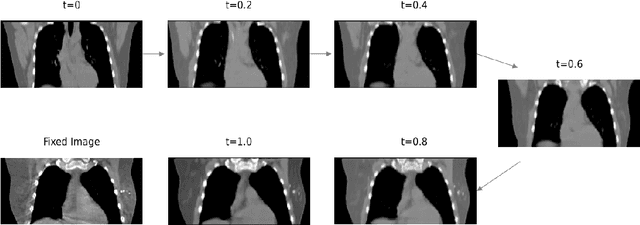
We propose a flow-based registration framework of medical images based on implicit neural representation. By integrating implicit neural representation and Large Deformable Diffeomorphic Metric Mapping (LDDMM), we employ a Multilayer Perceptron (MLP) as a velocity generator while optimizing velocity and image similarity. Moreover, we adopt a coarse-to-fine approach to address the challenge of deformable-based registration methods dropping into local optimal solutions, thus aiding the management of significant deformations in medical image registration. Our algorithm has been validated on a paired CT-CBCT dataset of 50 patients,taking the dice coefficient of transferred annotations as an evaluation metric. Compared to existing methods, our approach achieves the state-of-the-art performance.
PEACE: Prompt Engineering Automation for CLIPSeg Enhancement in Aerial Robotics
Sep 29, 2023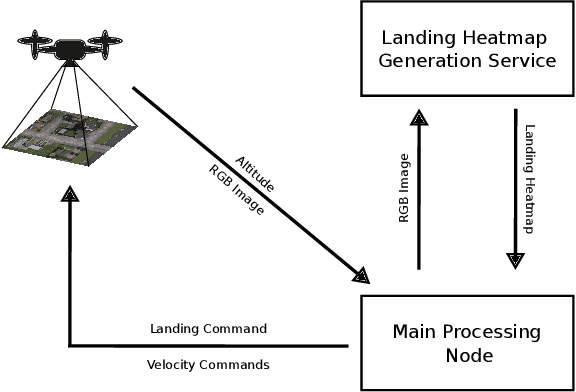
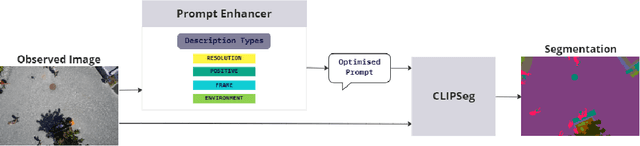
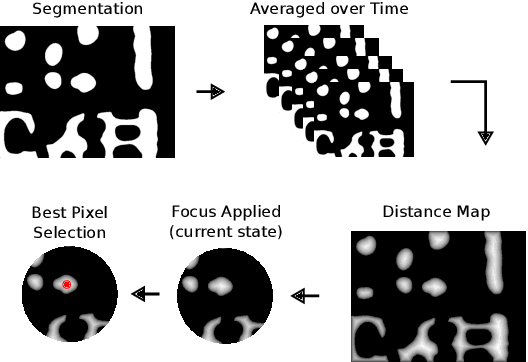
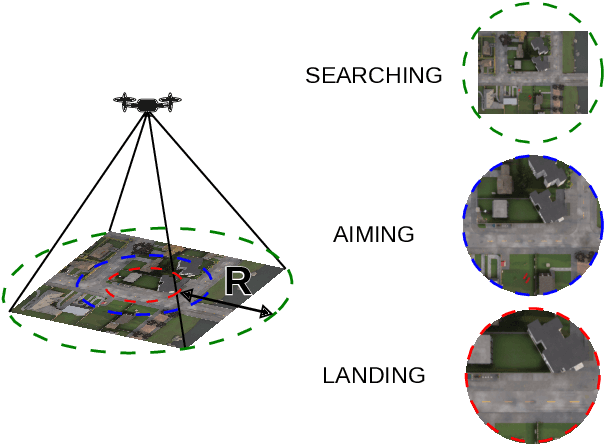
From industrial to space robotics, safe landing is an essential component for flight operations. With the growing interest in artificial intelligence, we direct our attention to learning based safe landing approaches. This paper extends our previous work, DOVESEI, which focused on a reactive UAV system by harnessing the capabilities of open vocabulary image segmentation. Prompt-based safe landing zone segmentation using an open vocabulary based model is no more just an idea, but proven to be feasible by the work of DOVESEI. However, a heuristic selection of words for prompt is not a reliable solution since it cannot take the changing environment into consideration and detrimental consequences can occur if the observed environment is not well represented by the given prompt. Therefore, we introduce PEACE (Prompt Engineering Automation for CLIPSeg Enhancement), powering DOVESEI to automate the prompt generation and engineering to adapt to data distribution shifts. Our system is capable of performing safe landing operations with collision avoidance at altitudes as low as 20 meters using only monocular cameras and image segmentation. We take advantage of DOVESEI's dynamic focus to circumvent abrupt fluctuations in the terrain segmentation between frames in a video stream. PEACE shows promising improvements in prompt generation and engineering for aerial images compared to the standard prompt used for CLIP and CLIPSeg. Combining DOVESEI and PEACE, our system was able improve successful safe landing zone selections by 58.62% compared to using only DOVESEI. All the source code is open source and available online.