 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Recycling Training Strategy for Medical Image Segmentation with Diffusion Denoising Models
Aug 30, 2023
Denoising diffusion models have found applications in image segmentation by generating segmented masks conditioned on images. Existing studies predominantly focus on adjusting model architecture or improving inference such as test-time sampling strategies. In this work, we focus on training strategy improvements and propose a novel recycling method. During each training step, a segmentation mask is first predicted given an image and a random noise. This predicted mask, replacing the conventional ground truth mask, is used for denoising task during training. This approach can be interpreted as aligning the training strategy with inference by eliminating the dependence on ground truth masks for generating noisy samples. Our proposed method significantly outperforms standard diffusion training, self-conditioning, and existing recycling strategies across multiple medical imaging data sets: muscle ultrasound, abdominal CT, prostate MR, and brain MR. This holds true for two widely adopted sampling strategies: denoising diffusion probabilistic model and denoising diffusion implicit model. Importantly, existing diffusion models often display a declining or unstable performance during inference, whereas our novel recycling consistently enhances or maintains performance. Furthermore, we show for the first time that, under a fair comparison with the same network architectures and computing budget, the proposed recycling-based diffusion models achieved on-par performance with non-diffusion-based supervised training. This paper summarises these quantitative results and discusses their values, with a fully reproducible JAX-based implementation, released at https://github.com/mathpluscode/ImgX-DiffSeg.
In-Domain GAN Inversion for Faithful Reconstruction and Editability
Sep 25, 2023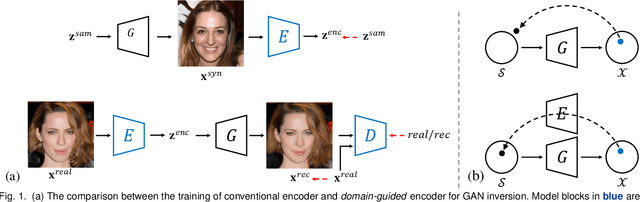
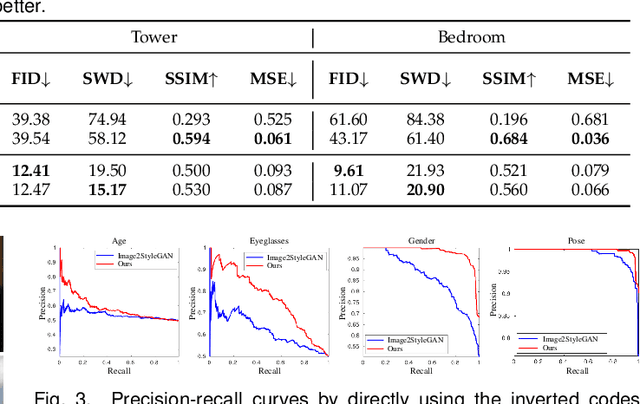
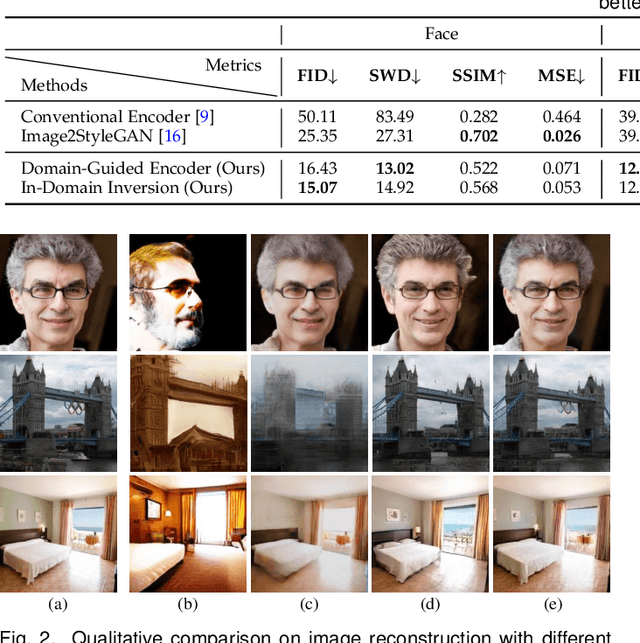
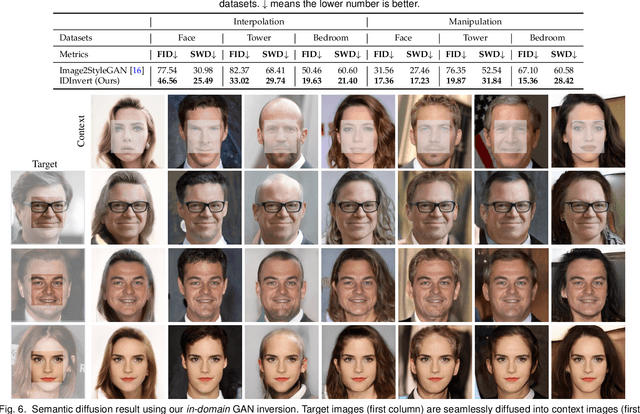
Generative Adversarial Networks (GANs) have significantly advanced image synthesis through mapping randomly sampled latent codes to high-fidelity synthesized images. However, applying well-trained GANs to real image editing remains challenging. A common solution is to find an approximate latent code that can adequately recover the input image to edit, which is also known as GAN inversion. To invert a GAN model, prior works typically focus on reconstructing the target image at the pixel level, yet few studies are conducted on whether the inverted result can well support manipulation at the semantic level. This work fills in this gap by proposing in-domain GAN inversion, which consists of a domain-guided encoder and a domain-regularized optimizer, to regularize the inverted code in the native latent space of the pre-trained GAN model. In this way, we manage to sufficiently reuse the knowledge learned by GANs for image reconstruction, facilitating a wide range of editing applications without any retraining. We further make comprehensive analyses on the effects of the encoder structure, the starting inversion point, as well as the inversion parameter space, and observe the trade-off between the reconstruction quality and the editing property. Such a trade-off sheds light on how a GAN model represents an image with various semantics encoded in the learned latent distribution. Code, models, and demo are available at the project page: https://genforce.github.io/idinvert/.
Foreground Object Search by Distilling Composite Image Feature
Aug 09, 2023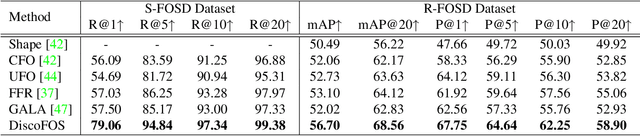
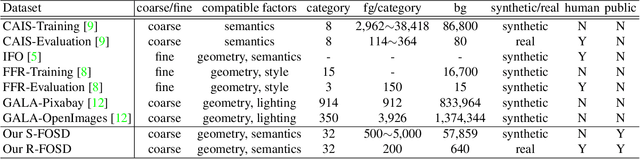
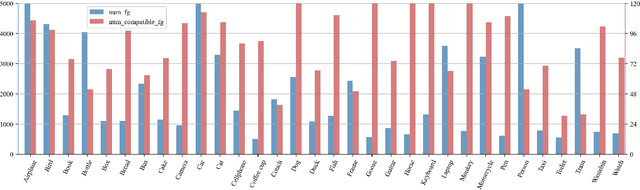
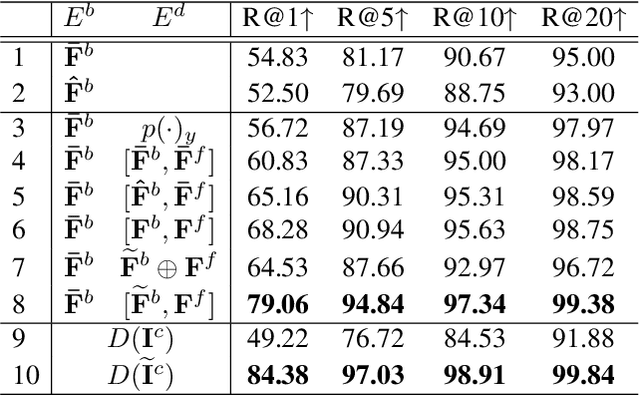
Foreground object search (FOS) aims to find compatible foreground objects for a given background image, producing realistic composite image. We observe that competitive retrieval performance could be achieved by using a discriminator to predict the compatibility of composite image, but this approach has unaffordable time cost. To this end, we propose a novel FOS method via distilling composite feature (DiscoFOS). Specifically, the abovementioned discriminator serves as teacher network. The student network employs two encoders to extract foreground feature and background feature. Their interaction output is enforced to match the composite image feature from the teacher network. Additionally, previous works did not release their datasets, so we contribute two datasets for FOS task: S-FOSD dataset with synthetic composite images and R-FOSD dataset with real composite images. Extensive experiments on our two datasets demonstrate the superiority of the proposed method over previous approaches. The dataset and code are available at https://github.com/bcmi/Foreground-Object-Search-Dataset-FOSD.
Structure Invariant Transformation for better Adversarial Transferability
Sep 26, 2023Given the severe vulnerability of Deep Neural Networks (DNNs) against adversarial examples, there is an urgent need for an effective adversarial attack to identify the deficiencies of DNNs in security-sensitive applications. As one of the prevalent black-box adversarial attacks, the existing transfer-based attacks still cannot achieve comparable performance with the white-box attacks. Among these, input transformation based attacks have shown remarkable effectiveness in boosting transferability. In this work, we find that the existing input transformation based attacks transform the input image globally, resulting in limited diversity of the transformed images. We postulate that the more diverse transformed images result in better transferability. Thus, we investigate how to locally apply various transformations onto the input image to improve such diversity while preserving the structure of image. To this end, we propose a novel input transformation based attack, called Structure Invariant Attack (SIA), which applies a random image transformation onto each image block to craft a set of diverse images for gradient calculation. Extensive experiments on the standard ImageNet dataset demonstrate that SIA exhibits much better transferability than the existing SOTA input transformation based attacks on CNN-based and transformer-based models, showing its generality and superiority in boosting transferability. Code is available at https://github.com/xiaosen-wang/SIT.
GeoCLIP: Clip-Inspired Alignment between Locations and Images for Effective Worldwide Geo-localization
Sep 27, 2023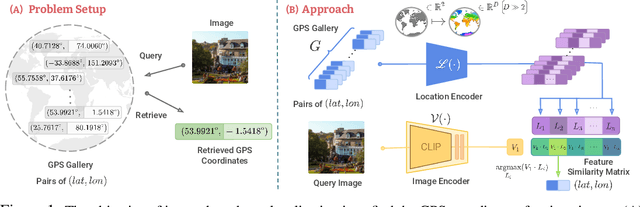
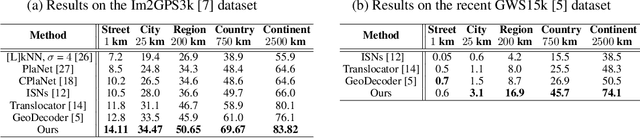
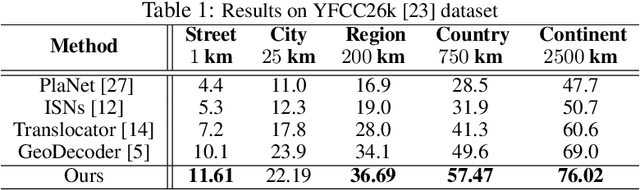
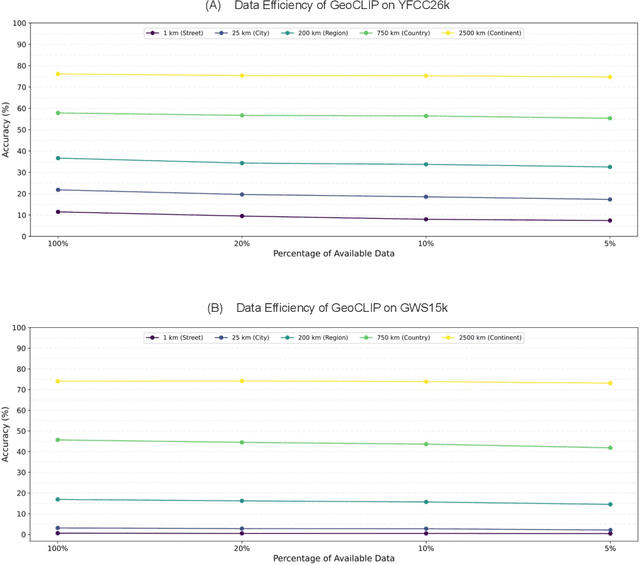
Worldwide Geo-localization aims to pinpoint the precise location of images taken anywhere on Earth. This task has considerable challenges due to immense variation in geographic landscapes. The image-to-image retrieval-based approaches fail to solve this problem on a global scale as it is not feasible to construct a large gallery of images covering the entire world. Instead, existing approaches divide the globe into discrete geographic cells, transforming the problem into a classification task. However, their performance is limited by the predefined classes and often results in inaccurate localizations when an image's location significantly deviates from its class center. To overcome these limitations, we propose GeoCLIP, a novel CLIP-inspired Image-to-GPS retrieval approach that enforces alignment between the image and its corresponding GPS locations. GeoCLIP's location encoder models the Earth as a continuous function by employing positional encoding through random Fourier features and constructing a hierarchical representation that captures information at varying resolutions to yield a semantically rich high-dimensional feature suitable to use even beyond geo-localization. To the best of our knowledge, this is the first work employing GPS encoding for geo-localization. We demonstrate the efficacy of our method via extensive experiments and ablations on benchmark datasets. We achieve competitive performance with just 20% of training data, highlighting its effectiveness even in limited-data settings. Furthermore, we qualitatively demonstrate geo-localization using a text query by leveraging CLIP backbone of our image encoder.
BI-LAVA: Biocuration with Hierarchical Image Labeling through Active Learning and Visual Analysis
Aug 15, 2023In the biomedical domain, taxonomies organize the acquisition modalities of scientific images in hierarchical structures. Such taxonomies leverage large sets of correct image labels and provide essential information about the importance of a scientific publication, which could then be used in biocuration tasks. However, the hierarchical nature of the labels, the overhead of processing images, the absence or incompleteness of labeled data, and the expertise required to label this type of data impede the creation of useful datasets for biocuration. From a multi-year collaboration with biocurators and text-mining researchers, we derive an iterative visual analytics and active learning strategy to address these challenges. We implement this strategy in a system called BI-LAVA Biocuration with Hierarchical Image Labeling through Active Learning and Visual Analysis. BI-LAVA leverages a small set of image labels, a hierarchical set of image classifiers, and active learning to help model builders deal with incomplete ground-truth labels, target a hierarchical taxonomy of image modalities, and classify a large pool of unlabeled images. BI-LAVA's front end uses custom encodings to represent data distributions, taxonomies, image projections, and neighborhoods of image thumbnails, which help model builders explore an unfamiliar image dataset and taxonomy and correct and generate labels. An evaluation with machine learning practitioners shows that our mixed human-machine approach successfully supports domain experts in understanding the characteristics of classes within the taxonomy, as well as validating and improving data quality in labeled and unlabeled collections.
Bi-Modality Medical Image Synthesis Using Semi-Supervised Sequential Generative Adversarial Networks
Aug 29, 2023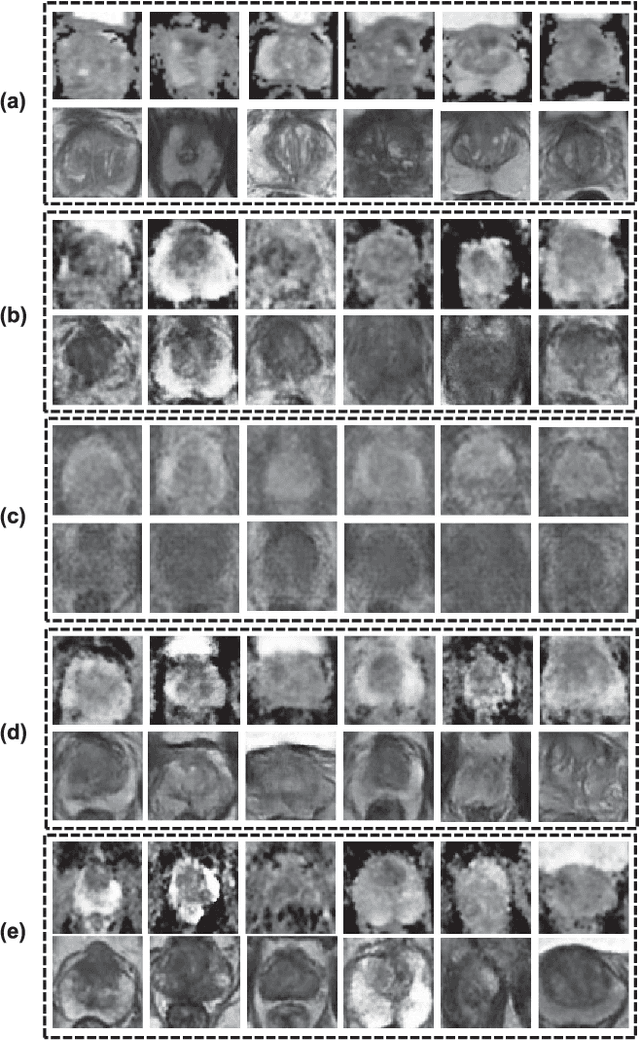
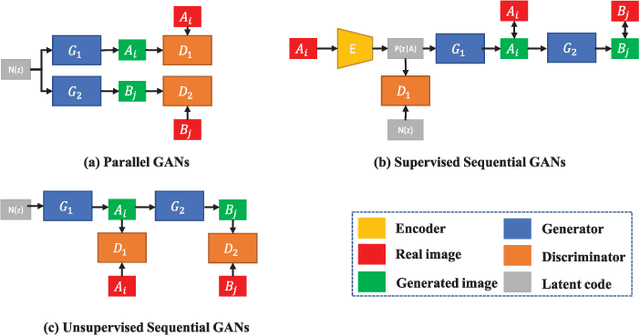
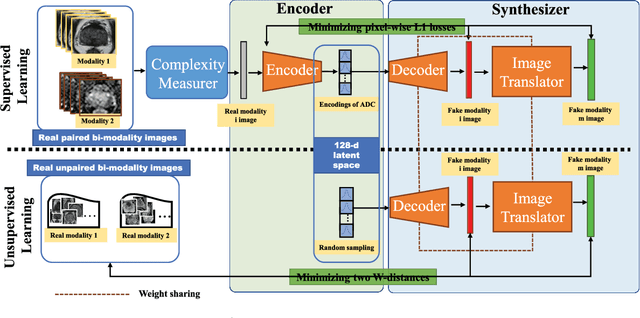
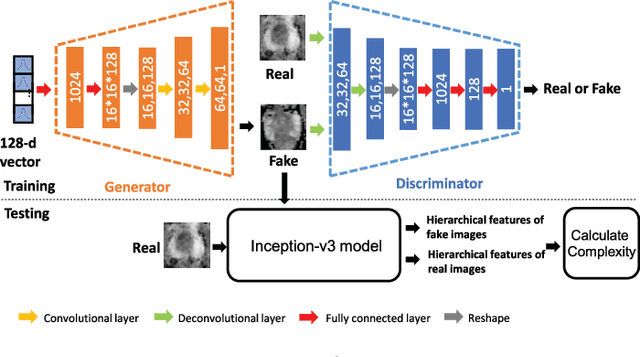
In this paper, we propose a bi-modality medical image synthesis approach based on sequential generative adversarial network (GAN) and semi-supervised learning. Our approach consists of two generative modules that synthesize images of the two modalities in a sequential order. A method for measuring the synthesis complexity is proposed to automatically determine the synthesis order in our sequential GAN. Images of the modality with a lower complexity are synthesized first, and the counterparts with a higher complexity are generated later. Our sequential GAN is trained end-to-end in a semi-supervised manner. In supervised training, the joint distribution of bi-modality images are learned from real paired images of the two modalities by explicitly minimizing the reconstruction losses between the real and synthetic images. To avoid overfitting limited training images, in unsupervised training, the marginal distribution of each modality is learned based on unpaired images by minimizing the Wasserstein distance between the distributions of real and fake images. We comprehensively evaluate the proposed model using two synthesis tasks based on three types of evaluate metrics and user studies. Visual and quantitative results demonstrate the superiority of our method to the state-of-the-art methods, and reasonable visual quality and clinical significance. Code is made publicly available at https://github.com/hustlinyi/Multimodal-Medical-Image-Synthesis.
Neural Diffusion Models
Oct 12, 2023



Diffusion models have shown remarkable performance on many generative tasks. Despite recent success, most diffusion models are restricted in that they only allow linear transformation of the data distribution. In contrast, broader family of transformations can potentially help train generative distributions more efficiently, simplifying the reverse process and closing the gap between the true negative log-likelihood and the variational approximation. In this paper, we present Neural Diffusion Models (NDMs), a generalization of conventional diffusion models that enables defining and learning time-dependent non-linear transformations of data. We show how to optimise NDMs using a variational bound in a simulation-free setting. Moreover, we derive a time-continuous formulation of NDMs, which allows fast and reliable inference using off-the-shelf numerical ODE and SDE solvers. Finally, we demonstrate the utility of NDMs with learnable transformations through experiments on standard image generation benchmarks, including CIFAR-10, downsampled versions of ImageNet and CelebA-HQ. NDMs outperform conventional diffusion models in terms of likelihood and produce high-quality samples.
Self-supervised visual learning for analyzing firearms trafficking activities on the Web
Oct 12, 2023Automated visual firearms classification from RGB images is an important real-world task with applications in public space security, intelligence gathering and law enforcement investigations. When applied to images massively crawled from the World Wide Web (including social media and dark Web sites), it can serve as an important component of systems that attempt to identify criminal firearms trafficking networks, by analyzing Big Data from open-source intelligence. Deep Neural Networks (DNN) are the state-of-the-art methodology for achieving this, with Convolutional Neural Networks (CNN) being typically employed. The common transfer learning approach consists of pretraining on a large-scale, generic annotated dataset for whole-image classification, such as ImageNet-1k, and then finetuning the DNN on a smaller, annotated, task-specific, downstream dataset for visual firearms classification. Neither Visual Transformer (ViT) neural architectures nor Self-Supervised Learning (SSL) approaches have been so far evaluated on this critical task. SSL essentially consists of replacing the traditional supervised pretraining objective with an unsupervised pretext task that does not require ground-truth labels..
Towards Open-World Co-Salient Object Detection with Generative Uncertainty-aware Group Selective Exchange-Masking
Oct 16, 2023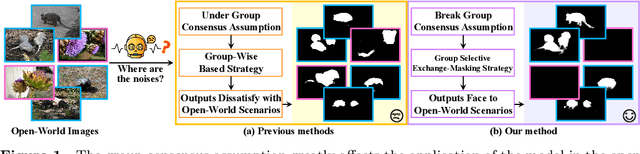
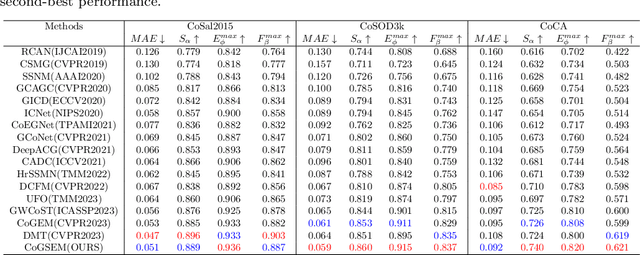
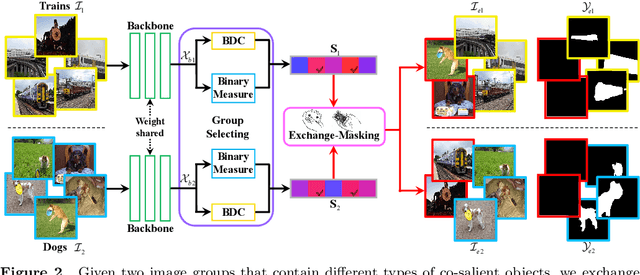
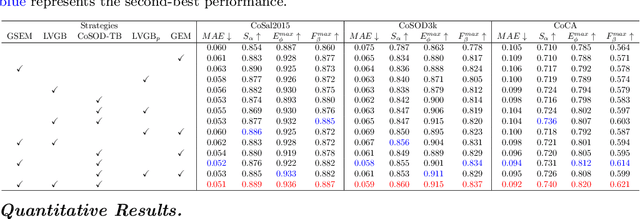
The traditional definition of co-salient object detection (CoSOD) task is to segment the common salient objects in a group of relevant images. This definition is based on an assumption of group consensus consistency that is not always reasonable in the open-world setting, which results in robustness issue in the model when dealing with irrelevant images in the inputting image group under the open-word scenarios. To tackle this problem, we introduce a group selective exchange-masking (GSEM) approach for enhancing the robustness of the CoSOD model. GSEM takes two groups of images as input, each containing different types of salient objects. Based on the mixed metric we designed, GSEM selects a subset of images from each group using a novel learning-based strategy, then the selected images are exchanged. To simultaneously consider the uncertainty introduced by irrelevant images and the consensus features of the remaining relevant images in the group, we designed a latent variable generator branch and CoSOD transformer branch. The former is composed of a vector quantised-variational autoencoder to generate stochastic global variables that model uncertainty. The latter is designed to capture correlation-based local features that include group consensus. Finally, the outputs of the two branches are merged and passed to a transformer-based decoder to generate robust predictions. Taking into account that there are currently no benchmark datasets specifically designed for open-world scenarios, we constructed three open-world benchmark datasets, namely OWCoSal, OWCoSOD, and OWCoCA, based on existing datasets. By breaking the group-consistency assumption, these datasets provide effective simulations of real-world scenarios and can better evaluate the robustness and practicality of models.