 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Foreground Object Search by Distilling Composite Image Feature
Aug 09, 2023
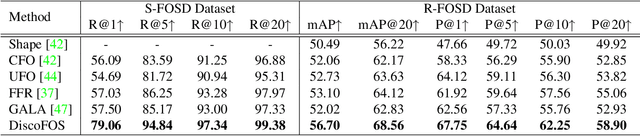
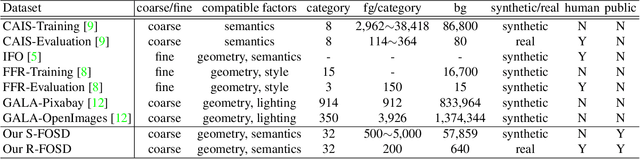
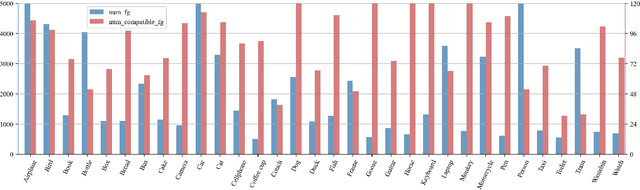
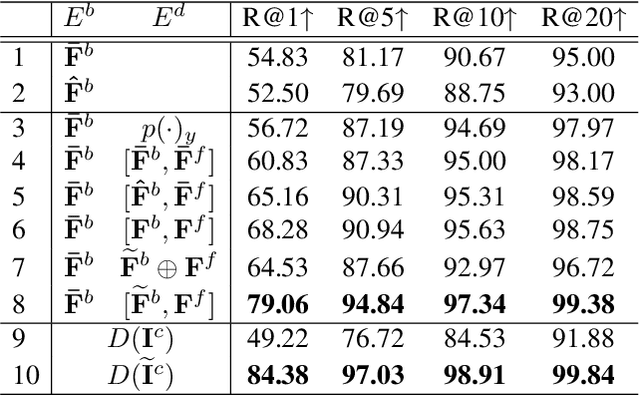
Foreground object search (FOS) aims to find compatible foreground objects for a given background image, producing realistic composite image. We observe that competitive retrieval performance could be achieved by using a discriminator to predict the compatibility of composite image, but this approach has unaffordable time cost. To this end, we propose a novel FOS method via distilling composite feature (DiscoFOS). Specifically, the abovementioned discriminator serves as teacher network. The student network employs two encoders to extract foreground feature and background feature. Their interaction output is enforced to match the composite image feature from the teacher network. Additionally, previous works did not release their datasets, so we contribute two datasets for FOS task: S-FOSD dataset with synthetic composite images and R-FOSD dataset with real composite images. Extensive experiments on our two datasets demonstrate the superiority of the proposed method over previous approaches. The dataset and code are available at https://github.com/bcmi/Foreground-Object-Search-Dataset-FOSD.
Argumentative Stance Prediction: An Exploratory Study on Multimodality and Few-Shot Learning
Oct 11, 2023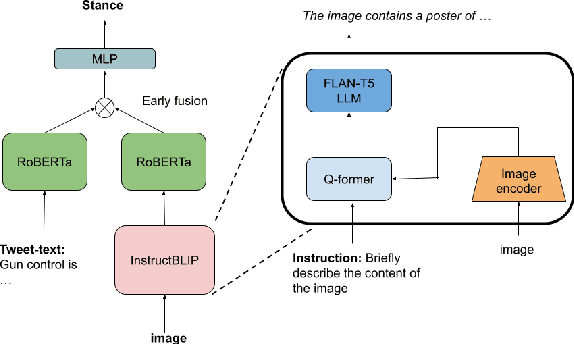
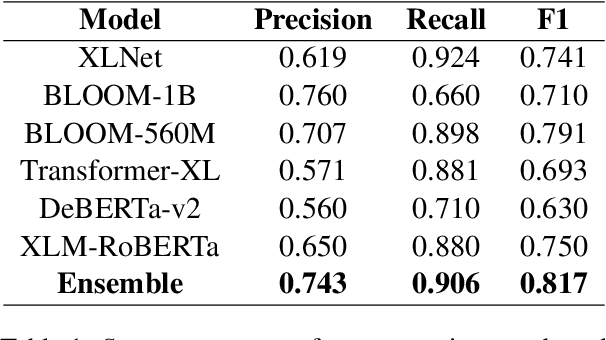
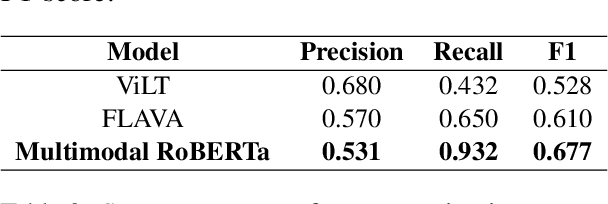

To advance argumentative stance prediction as a multimodal problem, the First Shared Task in Multimodal Argument Mining hosted stance prediction in crucial social topics of gun control and abortion. Our exploratory study attempts to evaluate the necessity of images for stance prediction in tweets and compare out-of-the-box text-based large-language models (LLM) in few-shot settings against fine-tuned unimodal and multimodal models. Our work suggests an ensemble of fine-tuned text-based language models (0.817 F1-score) outperforms both the multimodal (0.677 F1-score) and text-based few-shot prediction using a recent state-of-the-art LLM (0.550 F1-score). In addition to the differences in performance, our findings suggest that the multimodal models tend to perform better when image content is summarized as natural language over their native pixel structure and, using in-context examples improves few-shot performance of LLMs.
Relational Prior Knowledge Graphs for Detection and Instance Segmentation
Oct 11, 2023
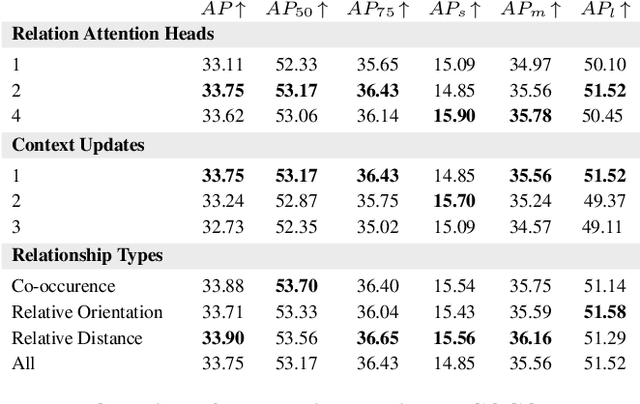
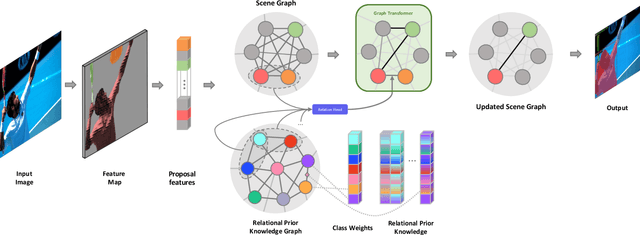
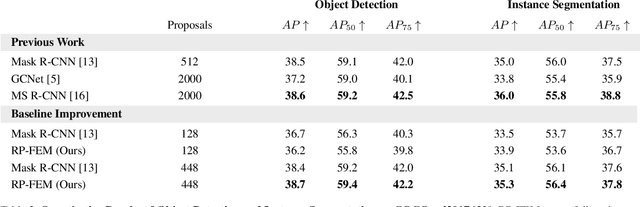
Humans have a remarkable ability to perceive and reason about the world around them by understanding the relationships between objects. In this paper, we investigate the effectiveness of using such relationships for object detection and instance segmentation. To this end, we propose a Relational Prior-based Feature Enhancement Model (RP-FEM), a graph transformer that enhances object proposal features using relational priors. The proposed architecture operates on top of scene graphs obtained from initial proposals and aims to concurrently learn relational context modeling for object detection and instance segmentation. Experimental evaluations on COCO show that the utilization of scene graphs, augmented with relational priors, offer benefits for object detection and instance segmentation. RP-FEM demonstrates its capacity to suppress improbable class predictions within the image while also preventing the model from generating duplicate predictions, leading to improvements over the baseline model on which it is built.
On the Interpretability of Part-Prototype Based Classifiers: A Human Centric Analysis
Oct 10, 2023

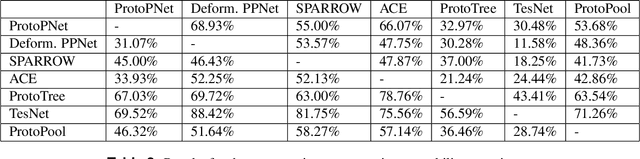

Part-prototype networks have recently become methods of interest as an interpretable alternative to many of the current black-box image classifiers. However, the interpretability of these methods from the perspective of human users has not been sufficiently explored. In this work, we have devised a framework for evaluating the interpretability of part-prototype-based models from a human perspective. The proposed framework consists of three actionable metrics and experiments. To demonstrate the usefulness of our framework, we performed an extensive set of experiments using Amazon Mechanical Turk. They not only show the capability of our framework in assessing the interpretability of various part-prototype-based models, but they also are, to the best of our knowledge, the most comprehensive work on evaluating such methods in a unified framework.
Affine-Transformation-Invariant Image Classification by Differentiable Arithmetic Distribution Module
Sep 01, 2023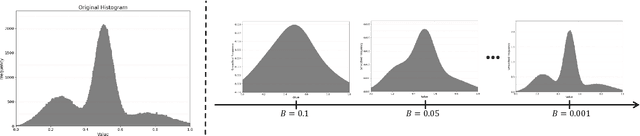
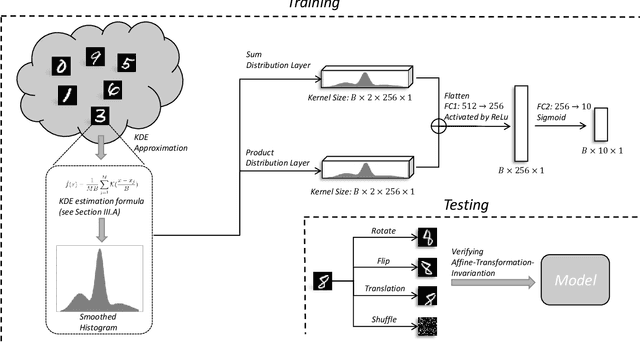
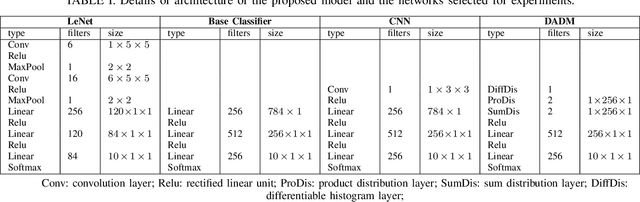

Although Convolutional Neural Networks (CNNs) have achieved promising results in image classification, they still are vulnerable to affine transformations including rotation, translation, flip and shuffle. The drawback motivates us to design a module which can alleviate the impact from different affine transformations. Thus, in this work, we introduce a more robust substitute by incorporating distribution learning techniques, focusing particularly on learning the spatial distribution information of pixels in images. To rectify the issue of non-differentiability of prior distribution learning methods that rely on traditional histograms, we adopt the Kernel Density Estimation (KDE) to formulate differentiable histograms. On this foundation, we present a novel Differentiable Arithmetic Distribution Module (DADM), which is designed to extract the intrinsic probability distributions from images. The proposed approach is able to enhance the model's robustness to affine transformations without sacrificing its feature extraction capabilities, thus bridging the gap between traditional CNNs and distribution-based learning. We validate the effectiveness of the proposed approach through ablation study and comparative experiments with LeNet.
A Recycling Training Strategy for Medical Image Segmentation with Diffusion Denoising Models
Aug 30, 2023Denoising diffusion models have found applications in image segmentation by generating segmented masks conditioned on images. Existing studies predominantly focus on adjusting model architecture or improving inference such as test-time sampling strategies. In this work, we focus on training strategy improvements and propose a novel recycling method. During each training step, a segmentation mask is first predicted given an image and a random noise. This predicted mask, replacing the conventional ground truth mask, is used for denoising task during training. This approach can be interpreted as aligning the training strategy with inference by eliminating the dependence on ground truth masks for generating noisy samples. Our proposed method significantly outperforms standard diffusion training, self-conditioning, and existing recycling strategies across multiple medical imaging data sets: muscle ultrasound, abdominal CT, prostate MR, and brain MR. This holds true for two widely adopted sampling strategies: denoising diffusion probabilistic model and denoising diffusion implicit model. Importantly, existing diffusion models often display a declining or unstable performance during inference, whereas our novel recycling consistently enhances or maintains performance. Furthermore, we show for the first time that, under a fair comparison with the same network architectures and computing budget, the proposed recycling-based diffusion models achieved on-par performance with non-diffusion-based supervised training. This paper summarises these quantitative results and discusses their values, with a fully reproducible JAX-based implementation, released at https://github.com/mathpluscode/ImgX-DiffSeg.
Soft Convex Quantization: Revisiting Vector Quantization with Convex Optimization
Oct 04, 2023
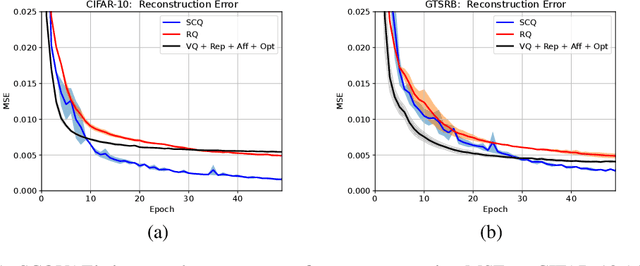

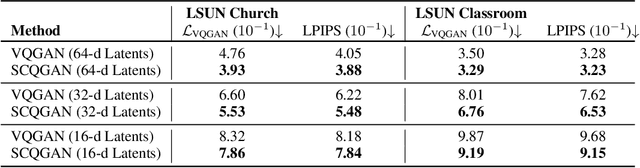
Vector Quantization (VQ) is a well-known technique in deep learning for extracting informative discrete latent representations. VQ-embedded models have shown impressive results in a range of applications including image and speech generation. VQ operates as a parametric K-means algorithm that quantizes inputs using a single codebook vector in the forward pass. While powerful, this technique faces practical challenges including codebook collapse, non-differentiability and lossy compression. To mitigate the aforementioned issues, we propose Soft Convex Quantization (SCQ) as a direct substitute for VQ. SCQ works like a differentiable convex optimization (DCO) layer: in the forward pass, we solve for the optimal convex combination of codebook vectors that quantize the inputs. In the backward pass, we leverage differentiability through the optimality conditions of the forward solution. We then introduce a scalable relaxation of the SCQ optimization and demonstrate its efficacy on the CIFAR-10, GTSRB and LSUN datasets. We train powerful SCQ autoencoder models that significantly outperform matched VQ-based architectures, observing an order of magnitude better image reconstruction and codebook usage with comparable quantization runtime.
On the Performance of Multimodal Language Models
Oct 04, 2023Instruction-tuned large language models (LLMs) have demonstrated promising zero-shot generalization capabilities across various downstream tasks. Recent research has introduced multimodal capabilities to LLMs by integrating independently pretrained vision encoders through model grafting. These multimodal variants undergo instruction tuning, similar to LLMs, enabling effective zero-shot generalization for multimodal tasks. This study conducts a comparative analysis of different multimodal instruction tuning approaches and evaluates their performance across a range of tasks, including complex reasoning, conversation, image captioning, multiple-choice questions (MCQs), and binary classification. Through rigorous benchmarking and ablation experiments, we reveal key insights for guiding architectural choices when incorporating multimodal capabilities into LLMs. However, current approaches have limitations; they do not sufficiently address the need for a diverse multimodal instruction dataset, which is crucial for enhancing task generalization. Additionally, they overlook issues related to truthfulness and factuality when generating responses. These findings illuminate current methodological constraints in adapting language models for image comprehension and provide valuable guidance for researchers and practitioners seeking to harness multimodal versions of LLMs.
SlowFormer: Universal Adversarial Patch for Attack on Compute and Energy Efficiency of Inference Efficient Vision Transformers
Oct 04, 2023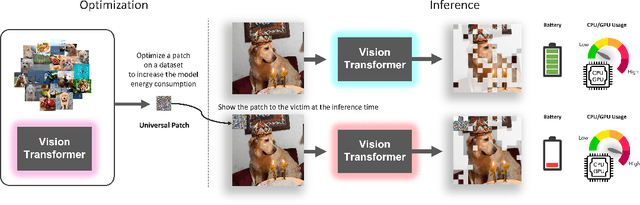
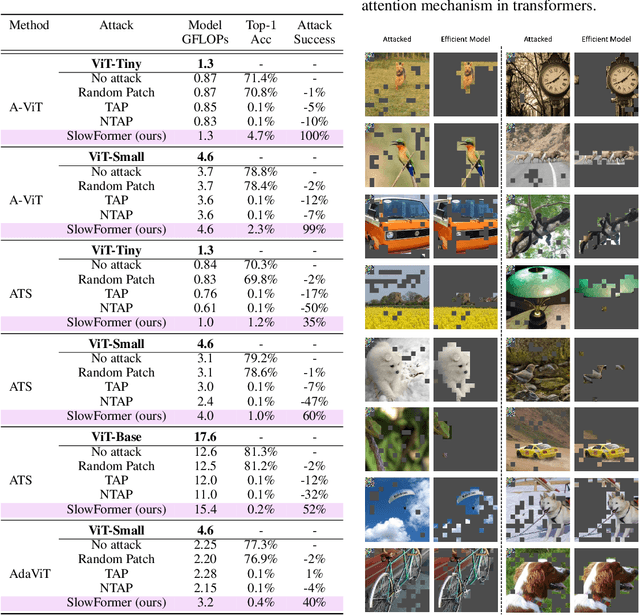

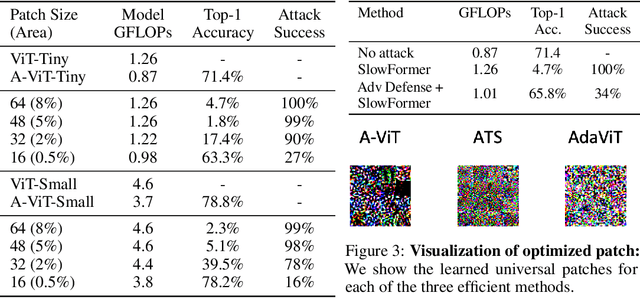
Recently, there has been a lot of progress in reducing the computation of deep models at inference time. These methods can reduce both the computational needs and power usage of deep models. Some of these approaches adaptively scale the compute based on the input instance. We show that such models can be vulnerable to a universal adversarial patch attack, where the attacker optimizes for a patch that when pasted on any image, can increase the compute and power consumption of the model. We run experiments with three different efficient vision transformer methods showing that in some cases, the attacker can increase the computation to the maximum possible level by simply pasting a patch that occupies only 8\% of the image area. We also show that a standard adversarial training defense method can reduce some of the attack's success. We believe adaptive efficient methods will be necessary for the future to lower the power usage of deep models, so we hope our paper encourages the community to study the robustness of these methods and develop better defense methods for the proposed attack.
A Foundation Model for General Moving Object Segmentation in Medical Images
Oct 04, 2023
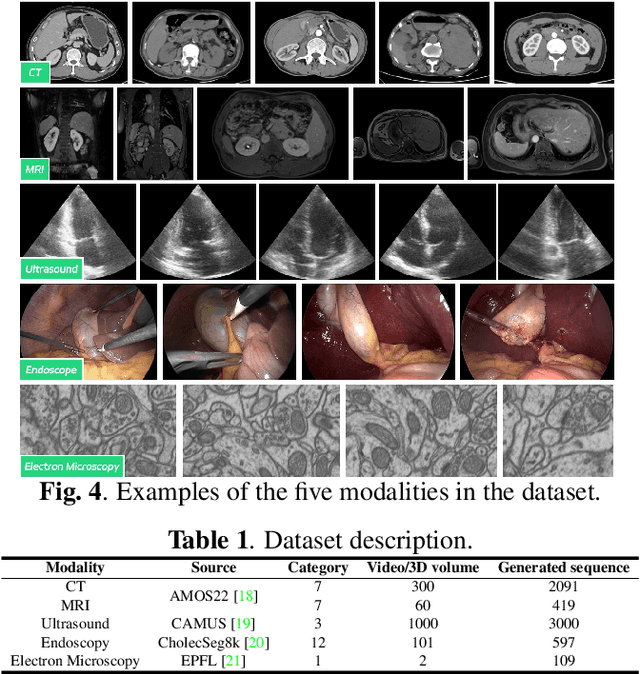
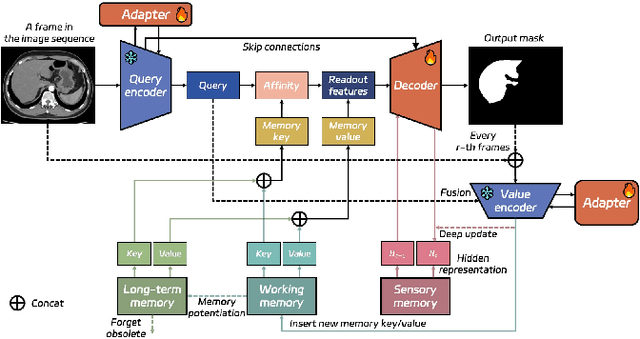
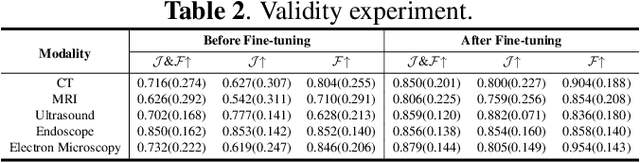
Medical image segmentation aims to delineate the anatomical or pathological structures of interest, playing a crucial role in clinical diagnosis. A substantial amount of high-quality annotated data is crucial for constructing high-precision deep segmentation models. However, medical annotation is highly cumbersome and time-consuming, especially for medical videos or 3D volumes, due to the huge labeling space and poor inter-frame consistency. Recently, a fundamental task named Moving Object Segmentation (MOS) has made significant advancements in natural images. Its objective is to delineate moving objects from the background within image sequences, requiring only minimal annotations. In this paper, we propose the first foundation model, named iMOS, for MOS in medical images. Extensive experiments on a large multi-modal medical dataset validate the effectiveness of the proposed iMOS. Specifically, with the annotation of only a small number of images in the sequence, iMOS can achieve satisfactory tracking and segmentation performance of moving objects throughout the entire sequence in bi-directions. We hope that the proposed iMOS can help accelerate the annotation speed of experts, and boost the development of medical foundation models.