 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Mask-aware CLIP Representations for Zero-Shot Segmentation
Sep 30, 2023

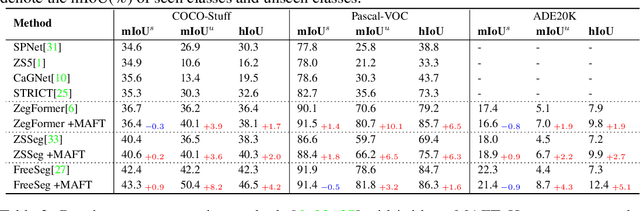
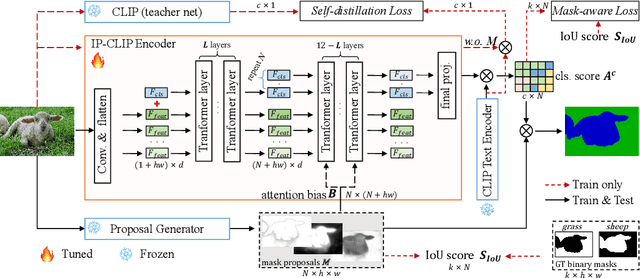
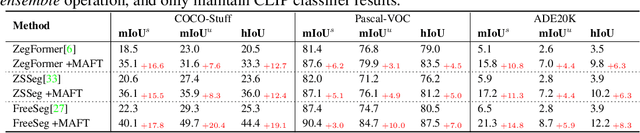
Recently, pre-trained vision-language models have been increasingly used to tackle the challenging zero-shot segmentation task. Typical solutions follow the paradigm of first generating mask proposals and then adopting CLIP to classify them. To maintain the CLIP's zero-shot transferability, previous practices favour to freeze CLIP during training. However, in the paper, we reveal that CLIP is insensitive to different mask proposals and tends to produce similar predictions for various mask proposals of the same image. This insensitivity results in numerous false positives when classifying mask proposals. This issue mainly relates to the fact that CLIP is trained with image-level supervision. To alleviate this issue, we propose a simple yet effective method, named Mask-aware Fine-tuning (MAFT). Specifically, Image-Proposals CLIP Encoder (IP-CLIP Encoder) is proposed to handle arbitrary numbers of image and mask proposals simultaneously. Then, mask-aware loss and self-distillation loss are designed to fine-tune IP-CLIP Encoder, ensuring CLIP is responsive to different mask proposals while not sacrificing transferability. In this way, mask-aware representations can be easily learned to make the true positives stand out. Notably, our solution can seamlessly plug into most existing methods without introducing any new parameters during the fine-tuning process. We conduct extensive experiments on the popular zero-shot benchmarks. With MAFT, the performance of the state-of-the-art methods is promoted by a large margin: 50.4% (+ 8.2%) on COCO, 81.8% (+ 3.2%) on Pascal-VOC, and 8.7% (+4.3%) on ADE20K in terms of mIoU for unseen classes. The code is available at https://github.com/jiaosiyu1999/MAFT.git.
Self-Sampling Meta SAM: Enhancing Few-shot Medical Image Segmentation with Meta-Learning
Aug 31, 2023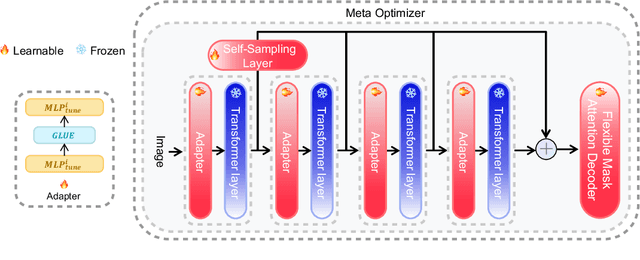
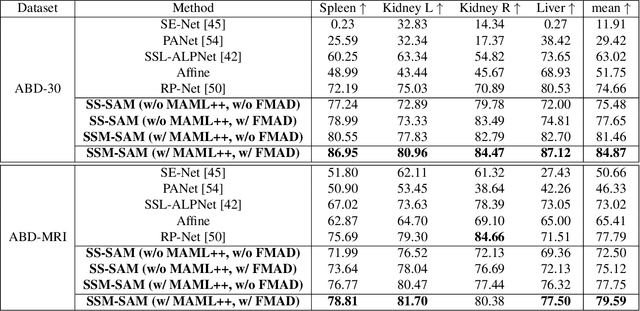
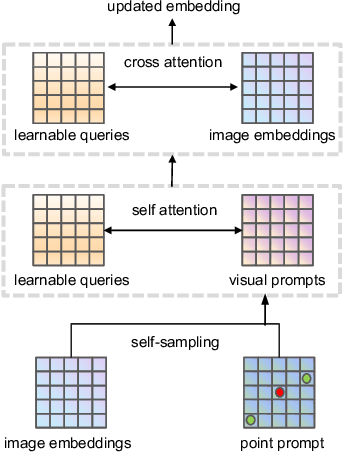
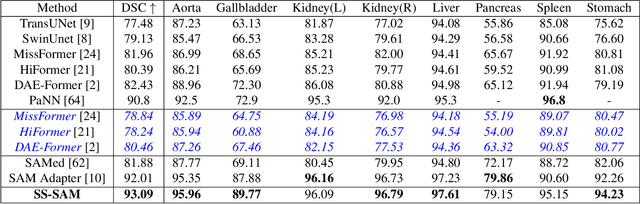
While the Segment Anything Model (SAM) excels in semantic segmentation for general-purpose images, its performance significantly deteriorates when applied to medical images, primarily attributable to insufficient representation of medical images in its training dataset. Nonetheless, gathering comprehensive datasets and training models that are universally applicable is particularly challenging due to the long-tail problem common in medical images. To address this gap, here we present a Self-Sampling Meta SAM (SSM-SAM) framework for few-shot medical image segmentation. Our innovation lies in the design of three key modules: 1) An online fast gradient descent optimizer, further optimized by a meta-learner, which ensures swift and robust adaptation to new tasks. 2) A Self-Sampling module designed to provide well-aligned visual prompts for improved attention allocation; and 3) A robust attention-based decoder specifically designed for medical few-shot learning to capture relationship between different slices. Extensive experiments on a popular abdominal CT dataset and an MRI dataset demonstrate that the proposed method achieves significant improvements over state-of-the-art methods in few-shot segmentation, with an average improvements of 10.21% and 1.80% in terms of DSC, respectively. In conclusion, we present a novel approach for rapid online adaptation in interactive image segmentation, adapting to a new organ in just 0.83 minutes. Code is publicly available on GitHub upon acceptance.
Augmenting Vision-Based Human Pose Estimation with Rotation Matrix
Oct 09, 2023
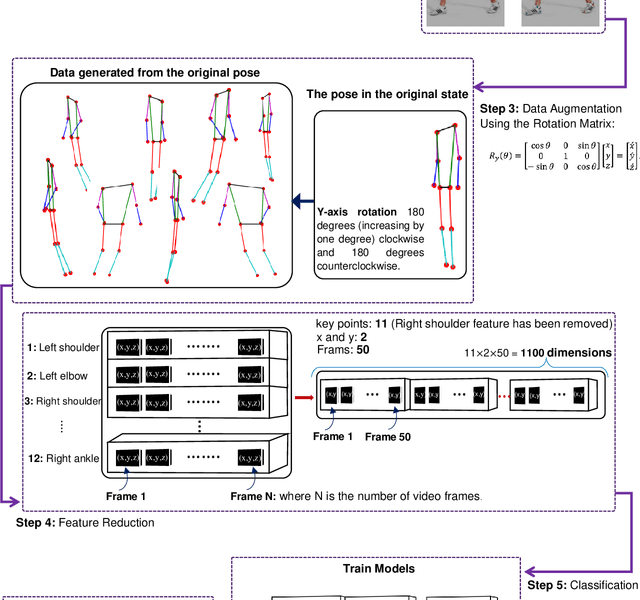

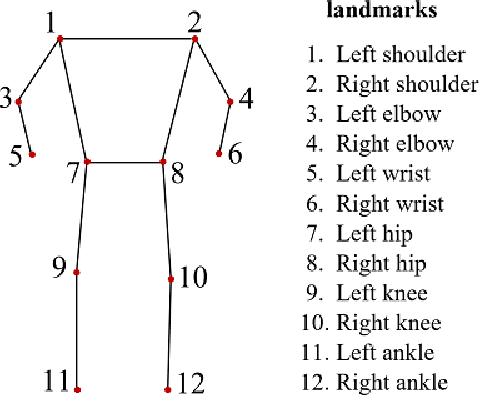
Fitness applications are commonly used to monitor activities within the gym, but they often fail to automatically track indoor activities inside the gym. This study proposes a model that utilizes pose estimation combined with a novel data augmentation method, i.e., rotation matrix. We aim to enhance the classification accuracy of activity recognition based on pose estimation data. Through our experiments, we experiment with different classification algorithms along with image augmentation approaches. Our findings demonstrate that the SVM with SGD optimization, using data augmentation with the Rotation Matrix, yields the most accurate results, achieving a 96% accuracy rate in classifying five physical activities. Conversely, without implementing the data augmentation techniques, the baseline accuracy remains at a modest 64%.
Understanding Transferable Representation Learning and Zero-shot Transfer in CLIP
Oct 02, 2023

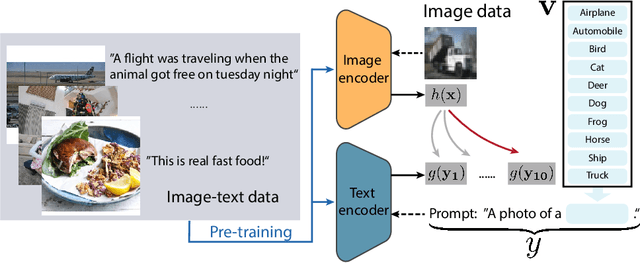

Multi-modal learning has become increasingly popular due to its ability to leverage information from different data sources (e.g., text and images) to improve the model performance. Recently, CLIP has emerged as an effective approach that employs vision-language contrastive pretraining to learn joint image and text representations and exhibits remarkable performance in zero-shot learning and text-guided natural image generation. Despite the huge practical success of CLIP, its theoretical understanding remains elusive. In this paper, we formally study transferrable representation learning underlying CLIP and demonstrate how features from different modalities get aligned. We also analyze its zero-shot transfer performance on the downstream tasks. Inspired by our analysis, we propose a new CLIP-type approach, which achieves better performance than CLIP and other state-of-the-art methods on benchmark datasets.
A Restoration Network as an Implicit Prior
Oct 02, 2023Image denoisers have been shown to be powerful priors for solving inverse problems in imaging. In this work, we introduce a generalization of these methods that allows any image restoration network to be used as an implicit prior. The proposed method uses priors specified by deep neural networks pre-trained as general restoration operators. The method provides a principled approach for adapting state-of-the-art restoration models for other inverse problems. Our theoretical result analyzes its convergence to a stationary point of a global functional associated with the restoration operator. Numerical results show that the method using a super-resolution prior achieves state-of-the-art performance both quantitatively and qualitatively. Overall, this work offers a step forward for solving inverse problems by enabling the use of powerful pre-trained restoration models as priors.
Jurassic World Remake: Bringing Ancient Fossils Back to Life via Zero-Shot Long Image-to-Image Translation
Aug 14, 2023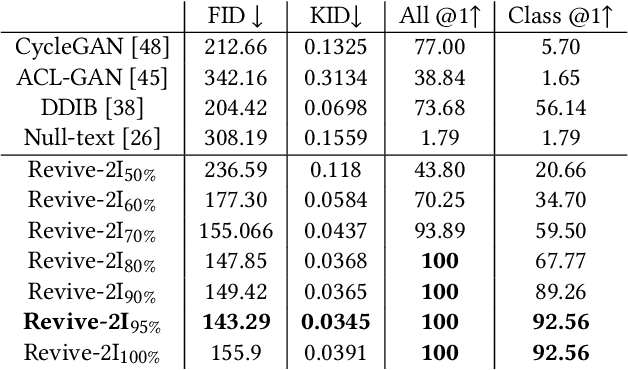
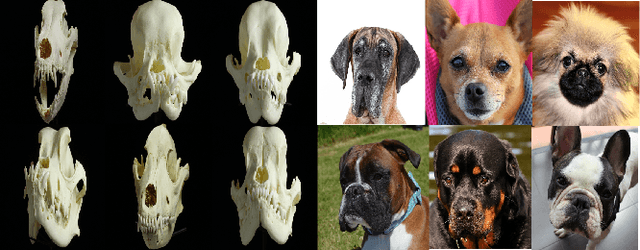
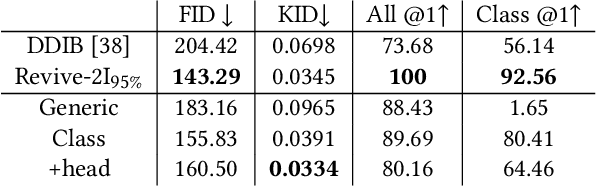
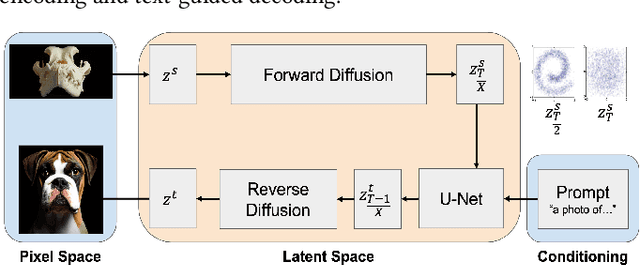
With a strong understanding of the target domain from natural language, we produce promising results in translating across large domain gaps and bringing skeletons back to life. In this work, we use text-guided latent diffusion models for zero-shot image-to-image translation (I2I) across large domain gaps (longI2I), where large amounts of new visual features and new geometry need to be generated to enter the target domain. Being able to perform translations across large domain gaps has a wide variety of real-world applications in criminology, astrology, environmental conservation, and paleontology. In this work, we introduce a new task Skull2Animal for translating between skulls and living animals. On this task, we find that unguided Generative Adversarial Networks (GANs) are not capable of translating across large domain gaps. Instead of these traditional I2I methods, we explore the use of guided diffusion and image editing models and provide a new benchmark model, Revive-2I, capable of performing zero-shot I2I via text-prompting latent diffusion models. We find that guidance is necessary for longI2I because, to bridge the large domain gap, prior knowledge about the target domain is needed. In addition, we find that prompting provides the best and most scalable information about the target domain as classifier-guided diffusion models require retraining for specific use cases and lack stronger constraints on the target domain because of the wide variety of images they are trained on.
CMISR: Circular Medical Image Super-Resolution
Aug 15, 2023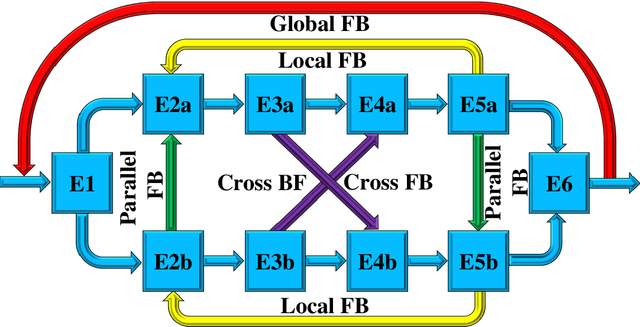
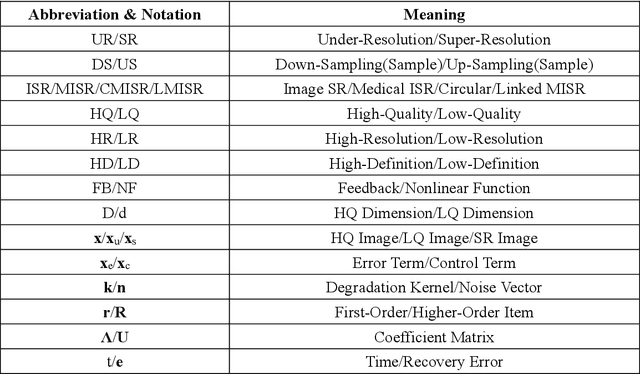
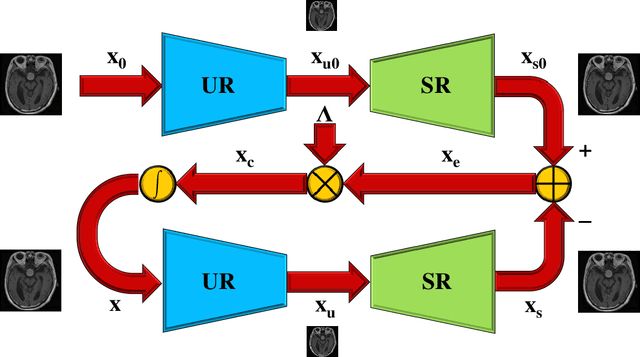
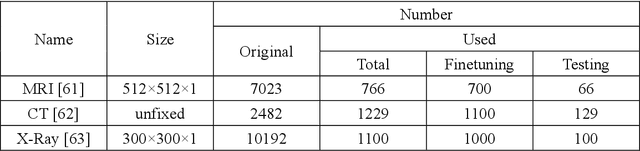
Classical methods of medical image super-resolution (MISR) utilize open-loop architecture with implicit under-resolution (UR) unit and explicit super-resolution (SR) unit. The UR unit can always be given, assumed, or estimated, while the SR unit is elaborately designed according to various SR algorithms. The closed-loop feedback mechanism is widely employed in current MISR approaches and can efficiently improve their performance. The feedback mechanism may be divided into two categories: local and global feedback. Therefore, this paper proposes a global feedback-based closed-cycle framework, circular MISR (CMISR), with unambiguous UR and SR elements. Mathematical model and closed-loop equation of CMISR are built. Mathematical proof with Taylor-series approximation indicates that CMISR has zero recovery error in steady-state. In addition, CMISR holds plug-and-play characteristic which can be established on any existing MISR algorithms. Five CMISR algorithms are respectively proposed based on the state-of-the-art open-loop MISR algorithms. Experimental results with three scale factors and on three open medical image datasets show that CMISR is superior to MISR in reconstruction performance and is particularly suited to medical images with strong edges or intense contrast.
Microscopy Image Segmentation via Point and Shape Regularized Data Synthesis
Aug 18, 2023Current deep learning-based approaches for the segmentation of microscopy images heavily rely on large amount of training data with dense annotation, which is highly costly and laborious in practice. Compared to full annotation where the complete contour of objects is depicted, point annotations, specifically object centroids, are much easier to acquire and still provide crucial information about the objects for subsequent segmentation. In this paper, we assume access to point annotations only during training and develop a unified pipeline for microscopy image segmentation using synthetically generated training data. Our framework includes three stages: (1) it takes point annotations and samples a pseudo dense segmentation mask constrained with shape priors; (2) with an image generative model trained in an unpaired manner, it translates the mask to a realistic microscopy image regularized by object level consistency; (3) the pseudo masks along with the synthetic images then constitute a pairwise dataset for training an ad-hoc segmentation model. On the public MoNuSeg dataset, our synthesis pipeline produces more diverse and realistic images than baseline models while maintaining high coherence between input masks and generated images. When using the identical segmentation backbones, the models trained on our synthetic dataset significantly outperform those trained with pseudo-labels or baseline-generated images. Moreover, our framework achieves comparable results to models trained on authentic microscopy images with dense labels, demonstrating its potential as a reliable and highly efficient alternative to labor-intensive manual pixel-wise annotations in microscopy image segmentation. The code is available.
Argumentative Stance Prediction: An Exploratory Study on Multimodality and Few-Shot Learning
Oct 11, 2023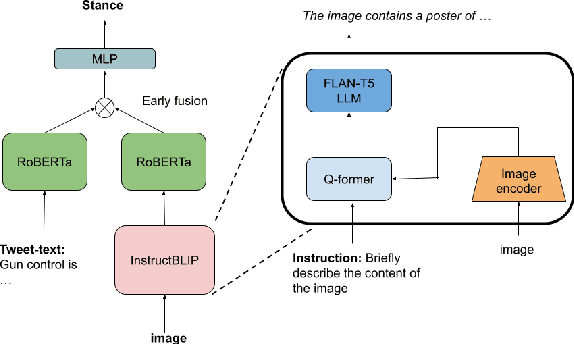
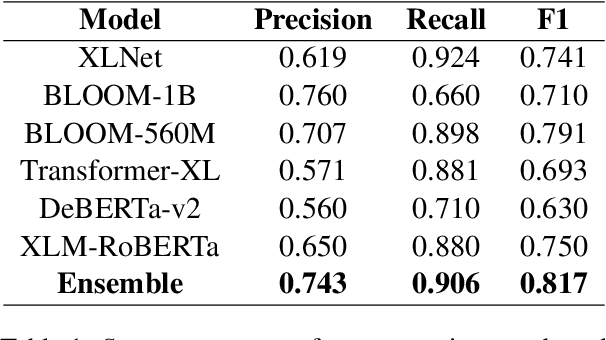
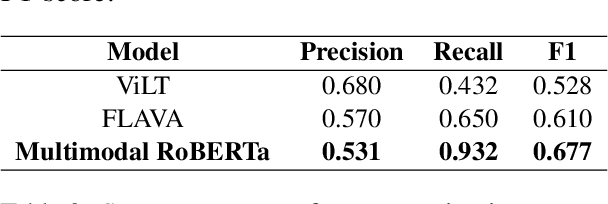

To advance argumentative stance prediction as a multimodal problem, the First Shared Task in Multimodal Argument Mining hosted stance prediction in crucial social topics of gun control and abortion. Our exploratory study attempts to evaluate the necessity of images for stance prediction in tweets and compare out-of-the-box text-based large-language models (LLM) in few-shot settings against fine-tuned unimodal and multimodal models. Our work suggests an ensemble of fine-tuned text-based language models (0.817 F1-score) outperforms both the multimodal (0.677 F1-score) and text-based few-shot prediction using a recent state-of-the-art LLM (0.550 F1-score). In addition to the differences in performance, our findings suggest that the multimodal models tend to perform better when image content is summarized as natural language over their native pixel structure and, using in-context examples improves few-shot performance of LLMs.
Relational Prior Knowledge Graphs for Detection and Instance Segmentation
Oct 11, 2023
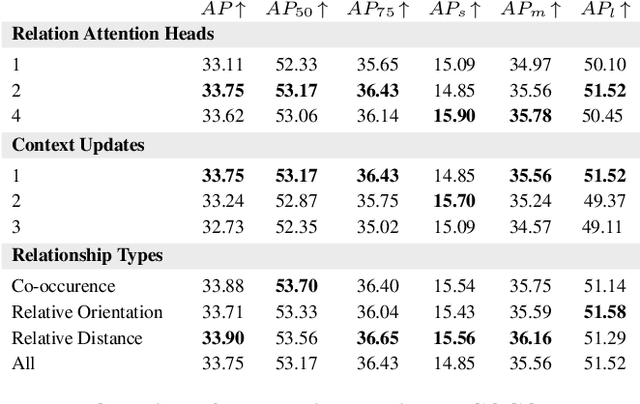
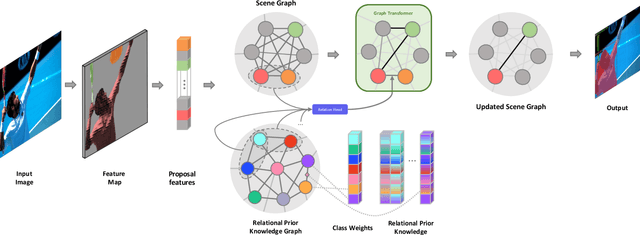
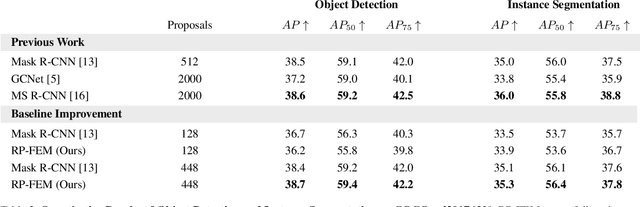
Humans have a remarkable ability to perceive and reason about the world around them by understanding the relationships between objects. In this paper, we investigate the effectiveness of using such relationships for object detection and instance segmentation. To this end, we propose a Relational Prior-based Feature Enhancement Model (RP-FEM), a graph transformer that enhances object proposal features using relational priors. The proposed architecture operates on top of scene graphs obtained from initial proposals and aims to concurrently learn relational context modeling for object detection and instance segmentation. Experimental evaluations on COCO show that the utilization of scene graphs, augmented with relational priors, offer benefits for object detection and instance segmentation. RP-FEM demonstrates its capacity to suppress improbable class predictions within the image while also preventing the model from generating duplicate predictions, leading to improvements over the baseline model on which it is built.