 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Underwater Visual Tracking With a Large Scale Dataset and Image Enhancement
Aug 31, 2023
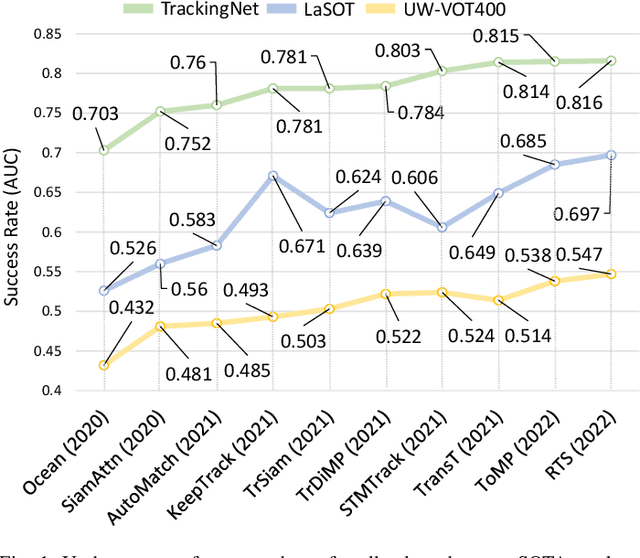
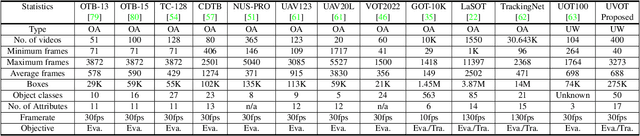


This paper presents a new dataset and general tracker enhancement method for Underwater Visual Object Tracking (UVOT). Despite its significance, underwater tracking has remained unexplored due to data inaccessibility. It poses distinct challenges; the underwater environment exhibits non-uniform lighting conditions, low visibility, lack of sharpness, low contrast, camouflage, and reflections from suspended particles. Performance of traditional tracking methods designed primarily for terrestrial or open-air scenarios drops in such conditions. We address the problem by proposing a novel underwater image enhancement algorithm designed specifically to boost tracking quality. The method has resulted in a significant performance improvement, of up to 5.0% AUC, of state-of-the-art (SOTA) visual trackers. To develop robust and accurate UVOT methods, large-scale datasets are required. To this end, we introduce a large-scale UVOT benchmark dataset consisting of 400 video segments and 275,000 manually annotated frames enabling underwater training and evaluation of deep trackers. The videos are labelled with several underwater-specific tracking attributes including watercolor variation, target distractors, camouflage, target relative size, and low visibility conditions. The UVOT400 dataset, tracking results, and the code are publicly available on: https://github.com/BasitAlawode/UWVOT400.
Anyview: Generalizable Indoor 3D Object Detection with Variable Frames
Oct 09, 2023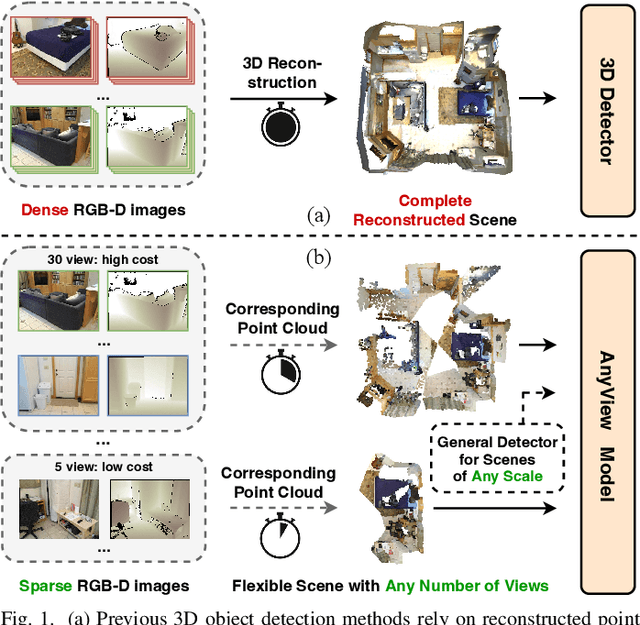
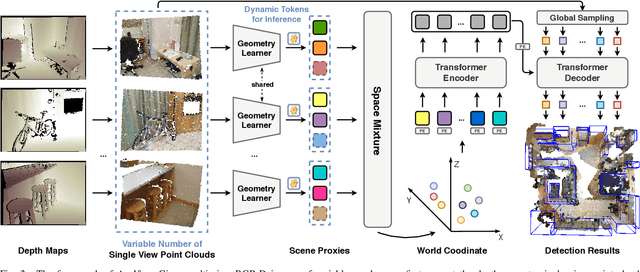

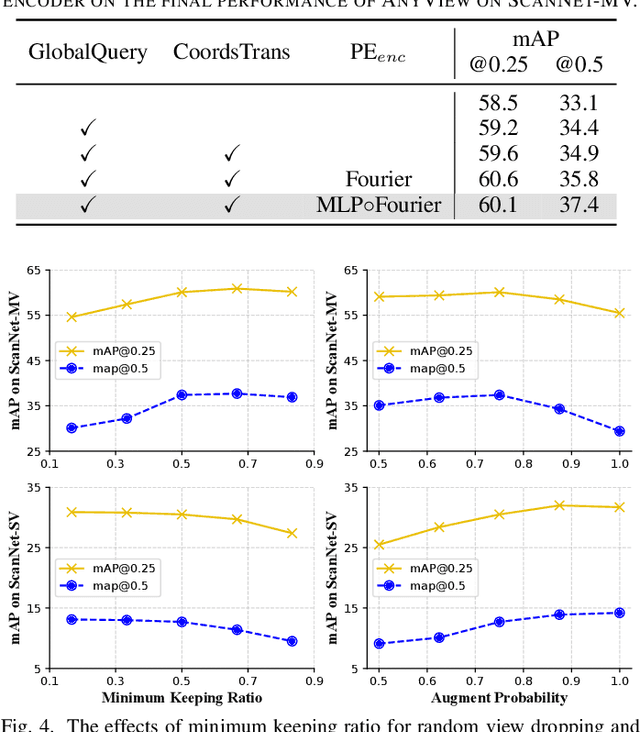
In this paper, we propose a novel network framework for indoor 3D object detection to handle variable input frame numbers in practical scenarios. Existing methods only consider fixed frames of input data for a single detector, such as monocular RGB-D images or point clouds reconstructed from dense multi-view RGB-D images. While in practical application scenes such as robot navigation and manipulation, the raw input to the 3D detectors is the RGB-D images with variable frame numbers instead of the reconstructed scene point cloud. However, the previous approaches can only handle fixed frame input data and have poor performance with variable frame input. In order to facilitate 3D object detection methods suitable for practical tasks, we present a novel 3D detection framework named AnyView for our practical applications, which generalizes well across different numbers of input frames with a single model. To be specific, we propose a geometric learner to mine the local geometric features of each input RGB-D image frame and implement local-global feature interaction through a designed spatial mixture module. Meanwhile, we further utilize a dynamic token strategy to adaptively adjust the number of extracted features for each frame, which ensures consistent global feature density and further enhances the generalization after fusion. Extensive experiments on the ScanNet dataset show our method achieves both great generalizability and high detection accuracy with a simple and clean architecture containing a similar amount of parameters with the baselines.
Fourier PD and PDUNet: Complex-valued networks to speed-up MR Thermometry during Hypterthermia
Oct 02, 2023Hyperthermia (HT) in combination with radio- and/or chemotherapy has become an accepted cancer treatment for distinct solid tumour entities. In HT, tumour tissue is exogenously heated to temperatures of 39 to 43 $\degree$C for 60 minutes. Temperature monitoring can be performed noninvasively using dynamic magnetic resonance imaging (MRI). However, the slow nature of MRI leads to motion artefacts in the images due to the movements of patients during image acquisition time. By discarding parts of the data, the speed of the acquisition can be increased - known as Undersampling. However, due to the invalidation of the Nyquist criterion, the acquired images have lower resolution and can also produce artefacts. The aim of this work was, therefore, to reconstruct highly undersampled MR thermometry acquisitions with better resolution and with less artefacts compared to conventional techniques like compressed sensing. The use of deep learning in the medical field has emerged in recent times, and various studies have shown that deep learning has the potential to solve inverse problems such as MR image reconstruction. However, most of the published work only focusses on the magnitude images, while the phase images are ignored, which are fundamental requirements for MR thermometry. This work, for the first time ever, presents deep learning based solutions for reconstructing undersampled MR thermometry data. Two different deep learning models have been employed here, the Fourier Primal-Dual network and Fourier Primal-Dual UNet, to reconstruct highly undersampled complex images of MR thermometry. It was observed that the method was able to reduce the temperature difference between the undersampled MRIs and the fully sampled MRIs from 1.5 $\degree$C to 0.5 $\degree$C.
BLIP-Adapter: Parameter-Efficient Transfer Learning for Mobile Screenshot Captioning
Sep 26, 2023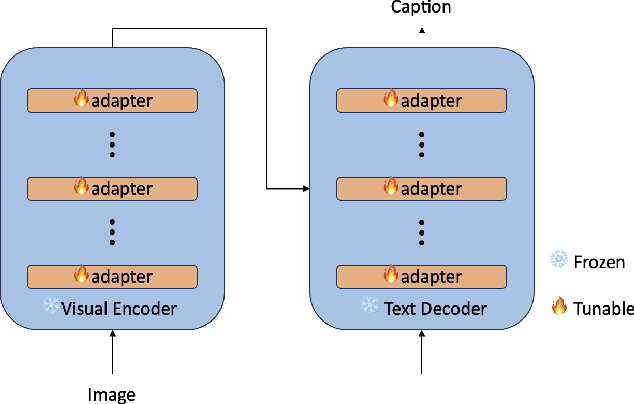
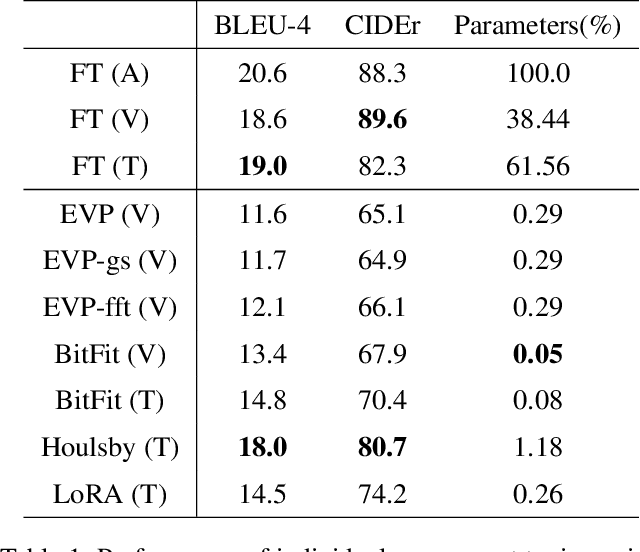
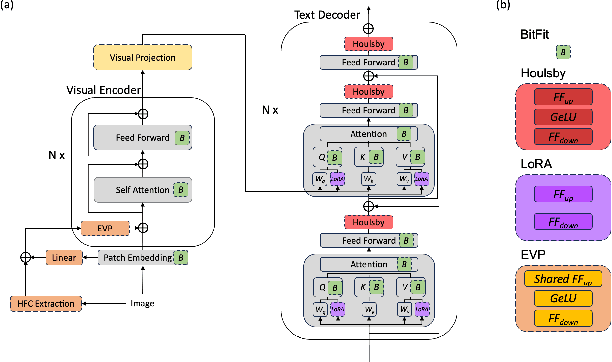
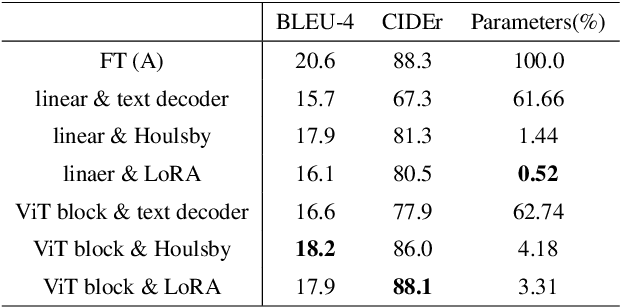
This study aims to explore efficient tuning methods for the screenshot captioning task. Recently, image captioning has seen significant advancements, but research in captioning tasks for mobile screens remains relatively scarce. Current datasets and use cases describing user behaviors within product screenshots are notably limited. Consequently, we sought to fine-tune pre-existing models for the screenshot captioning task. However, fine-tuning large pre-trained models can be resource-intensive, requiring considerable time, computational power, and storage due to the vast number of parameters in image captioning models. To tackle this challenge, this study proposes a combination of adapter methods, which necessitates tuning only the additional modules on the model. These methods are originally designed for vision or language tasks, and our intention is to apply them to address similar challenges in screenshot captioning. By freezing the parameters of the image caption models and training only the weights associated with the methods, performance comparable to fine-tuning the entire model can be achieved, while significantly reducing the number of parameters. This study represents the first comprehensive investigation into the effectiveness of combining adapters within the context of the screenshot captioning task. Through our experiments and analyses, this study aims to provide valuable insights into the application of adapters in vision-language models and contribute to the development of efficient tuning techniques for the screenshot captioning task. Our study is available at https://github.com/RainYuGG/BLIP-Adapter
A novel approach for holographic 3D content generation without depth map
Sep 26, 2023In preparation for observing holographic 3D content, acquiring a set of RGB color and depth map images per scene is necessary to generate computer-generated holograms (CGHs) when using the fast Fourier transform (FFT) algorithm. However, in real-world situations, these paired formats of RGB color and depth map images are not always fully available. We propose a deep learning-based method to synthesize the volumetric digital holograms using only the given RGB image, so that we can overcome environments where RGB color and depth map images are partially provided. The proposed method uses only the input of RGB image to estimate its depth map and then generate its CGH sequentially. Through experiments, we demonstrate that the volumetric hologram generated through our proposed model is more accurate than that of competitive models, under the situation that only RGB color data can be provided.
When to Learn What: Model-Adaptive Data Augmentation Curriculum
Sep 30, 2023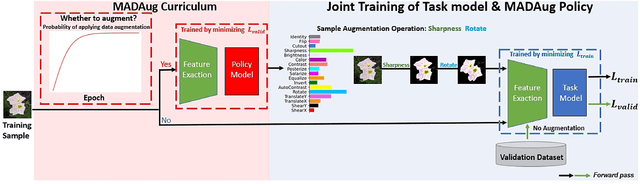
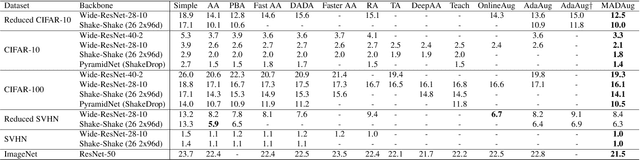
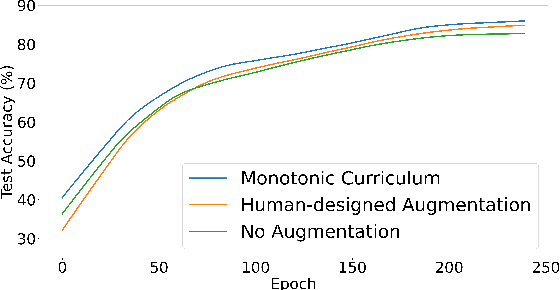

Data augmentation (DA) is widely used to improve the generalization of neural networks by enforcing the invariances and symmetries to pre-defined transformations applied to input data. However, a fixed augmentation policy may have different effects on each sample in different training stages but existing approaches cannot adjust the policy to be adaptive to each sample and the training model. In this paper, we propose Model Adaptive Data Augmentation (MADAug) that jointly trains an augmentation policy network to teach the model when to learn what. Unlike previous work, MADAug selects augmentation operators for each input image by a model-adaptive policy varying between training stages, producing a data augmentation curriculum optimized for better generalization. In MADAug, we train the policy through a bi-level optimization scheme, which aims to minimize a validation-set loss of a model trained using the policy-produced data augmentations. We conduct an extensive evaluation of MADAug on multiple image classification tasks and network architectures with thorough comparisons to existing DA approaches. MADAug outperforms or is on par with other baselines and exhibits better fairness: it brings improvement to all classes and more to the difficult ones. Moreover, MADAug learned policy shows better performance when transferred to fine-grained datasets. In addition, the auto-optimized policy in MADAug gradually introduces increasing perturbations and naturally forms an easy-to-hard curriculum.
Iris Liveness Detection Competition (LivDet-Iris) -- The 2023 Edition
Oct 06, 2023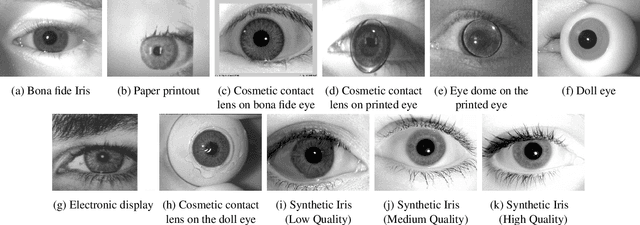
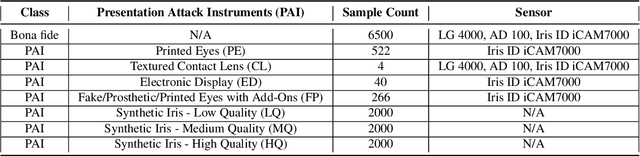
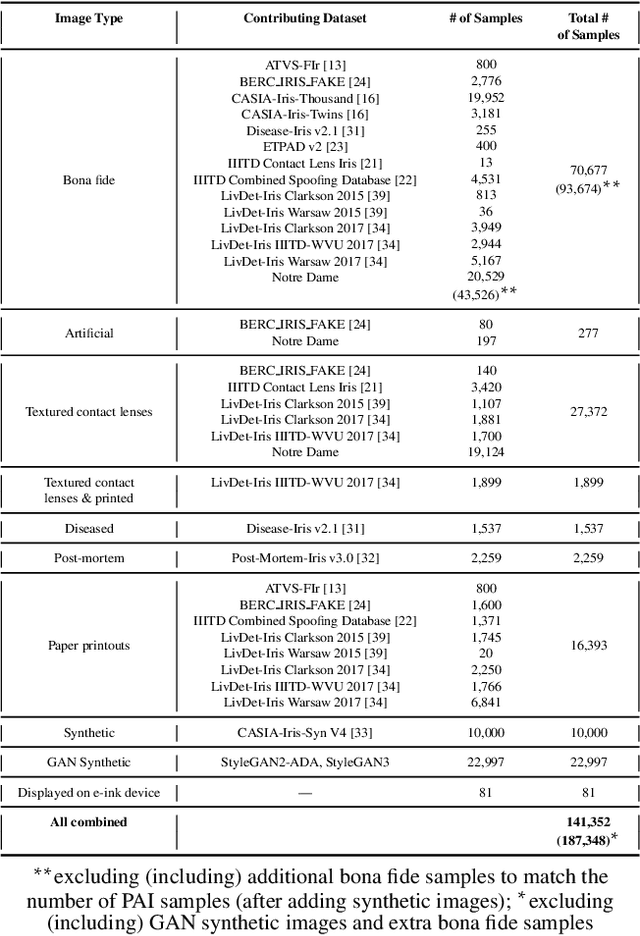
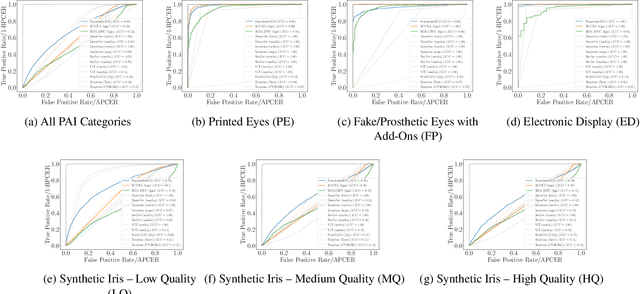
This paper describes the results of the 2023 edition of the ''LivDet'' series of iris presentation attack detection (PAD) competitions. New elements in this fifth competition include (1) GAN-generated iris images as a category of presentation attack instruments (PAI), and (2) an evaluation of human accuracy at detecting PAI as a reference benchmark. Clarkson University and the University of Notre Dame contributed image datasets for the competition, composed of samples representing seven different PAI categories, as well as baseline PAD algorithms. Fraunhofer IGD, Beijing University of Civil Engineering and Architecture, and Hochschule Darmstadt contributed results for a total of eight PAD algorithms to the competition. Accuracy results are analyzed by different PAI types, and compared to human accuracy. Overall, the Fraunhofer IGD algorithm, using an attention-based pixel-wise binary supervision network, showed the best-weighted accuracy results (average classification error rate of 37.31%), while the Beijing University of Civil Engineering and Architecture's algorithm won when equal weights for each PAI were given (average classification rate of 22.15%). These results suggest that iris PAD is still a challenging problem.
Explainable unsupervised multi-modal image registration using deep networks
Aug 03, 2023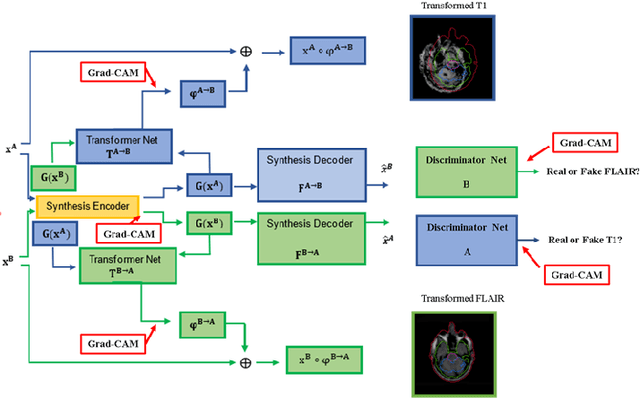
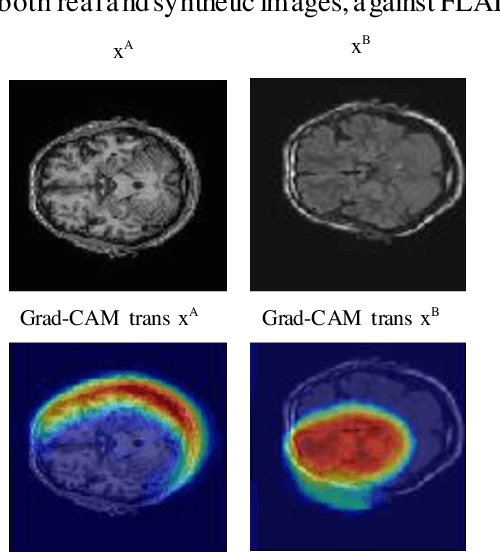

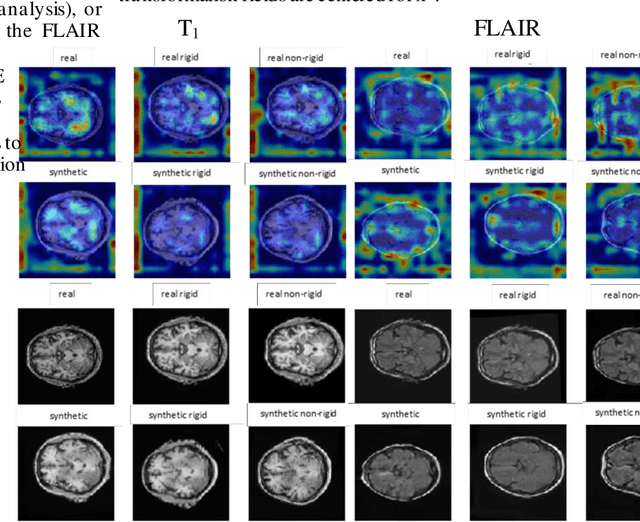
Clinical decision making from magnetic resonance imaging (MRI) combines complementary information from multiple MRI sequences (defined as 'modalities'). MRI image registration aims to geometrically 'pair' diagnoses from different modalities, time points and slices. Both intra- and inter-modality MRI registration are essential components in clinical MRI settings. Further, an MRI image processing pipeline that can address both afine and non-rigid registration is critical, as both types of deformations may be occuring in real MRI data scenarios. Unlike image classification, explainability is not commonly addressed in image registration deep learning (DL) methods, as it is challenging to interpet model-data behaviours against transformation fields. To properly address this, we incorporate Grad-CAM-based explainability frameworks in each major component of our unsupervised multi-modal and multi-organ image registration DL methodology. We previously demonstrated that we were able to reach superior performance (against the current standard Syn method). In this work, we show that our DL model becomes fully explainable, setting the framework to generalise our approach on further medical imaging data.
RLIPv2: Fast Scaling of Relational Language-Image Pre-training
Aug 18, 2023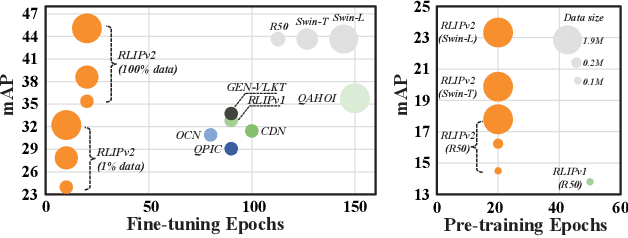
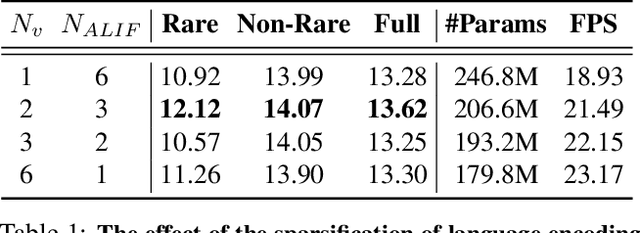
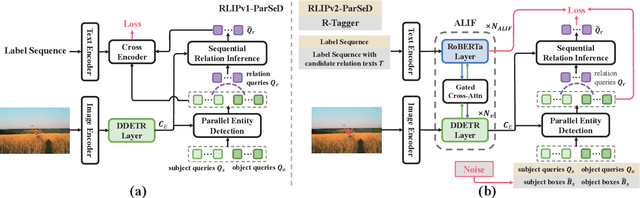
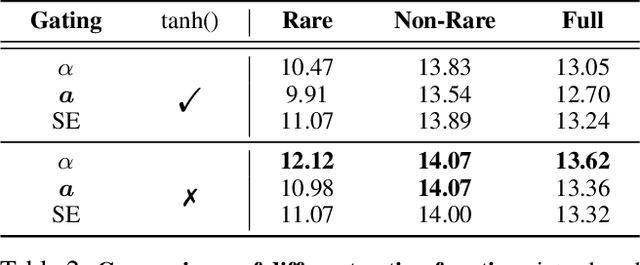
Relational Language-Image Pre-training (RLIP) aims to align vision representations with relational texts, thereby advancing the capability of relational reasoning in computer vision tasks. However, hindered by the slow convergence of RLIPv1 architecture and the limited availability of existing scene graph data, scaling RLIPv1 is challenging. In this paper, we propose RLIPv2, a fast converging model that enables the scaling of relational pre-training to large-scale pseudo-labelled scene graph data. To enable fast scaling, RLIPv2 introduces Asymmetric Language-Image Fusion (ALIF), a mechanism that facilitates earlier and deeper gated cross-modal fusion with sparsified language encoding layers. ALIF leads to comparable or better performance than RLIPv1 in a fraction of the time for pre-training and fine-tuning. To obtain scene graph data at scale, we extend object detection datasets with free-form relation labels by introducing a captioner (e.g., BLIP) and a designed Relation Tagger. The Relation Tagger assigns BLIP-generated relation texts to region pairs, thus enabling larger-scale relational pre-training. Through extensive experiments conducted on Human-Object Interaction Detection and Scene Graph Generation, RLIPv2 shows state-of-the-art performance on three benchmarks under fully-finetuning, few-shot and zero-shot settings. Notably, the largest RLIPv2 achieves 23.29mAP on HICO-DET without any fine-tuning, yields 32.22mAP with just 1% data and yields 45.09mAP with 100% data. Code and models are publicly available at https://github.com/JacobYuan7/RLIPv2.
ChatRadio-Valuer: A Chat Large Language Model for Generalizable Radiology Report Generation Based on Multi-institution and Multi-system Data
Oct 10, 2023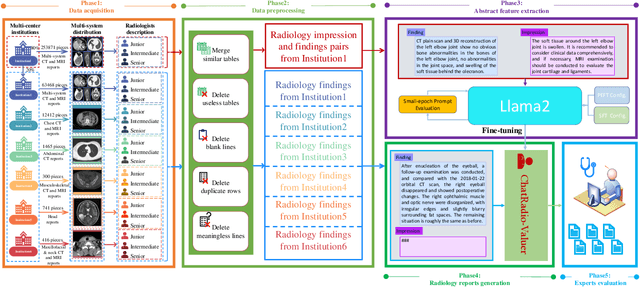
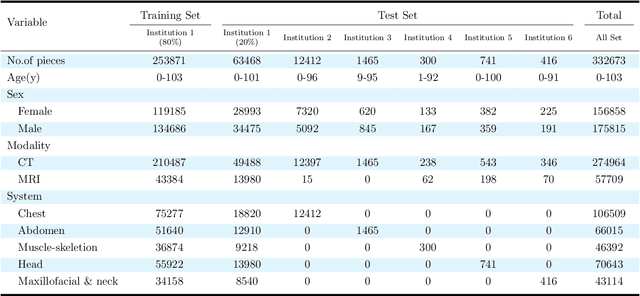
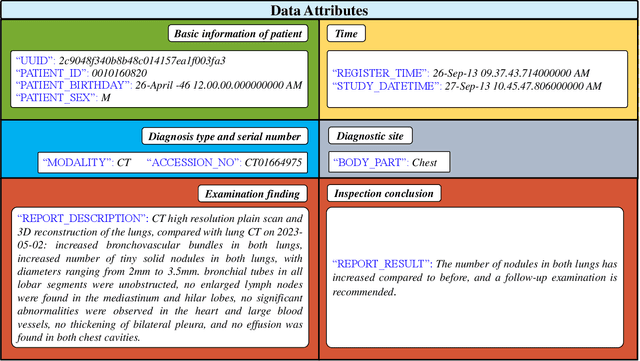
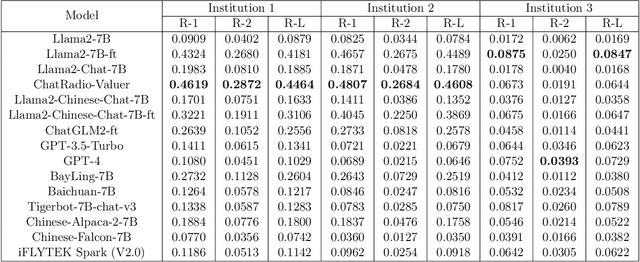
Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge generalizability challenge to the current methods under massive data volume, mainly because the style and normativity of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns generalizable representations and provides a basis pattern for model adaptation in sophisticated analysts' cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and maxillofacial $\&$ neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of \textbf{332,673} observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.