 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GeRA: Label-Efficient Geometrically Regularized Alignment
Oct 07, 2023
Pretrained unimodal encoders incorporate rich semantic information into embedding space structures. To be similarly informative, multi-modal encoders typically require massive amounts of paired data for alignment and training. We introduce a semi-supervised Geometrically Regularized Alignment (GeRA) method to align the embedding spaces of pretrained unimodal encoders in a label-efficient way. Our method leverages the manifold geometry of unpaired (unlabeled) data to improve alignment performance. To prevent distortions to local geometry during the alignment process, potentially disrupting semantic neighborhood structures and causing misalignment of unobserved pairs, we introduce a geometric loss term. This term is built upon a diffusion operator that captures the local manifold geometry of the unimodal pretrained encoders. GeRA is modality-agnostic and thus can be used to align pretrained encoders from any data modalities. We provide empirical evidence to the effectiveness of our method in the domains of speech-text and image-text alignment. Our experiments demonstrate significant improvement in alignment quality compared to a variaty of leading baselines, especially with a small amount of paired data, using our proposed geometric regularization.
Explainable unsupervised multi-modal image registration using deep networks
Aug 03, 2023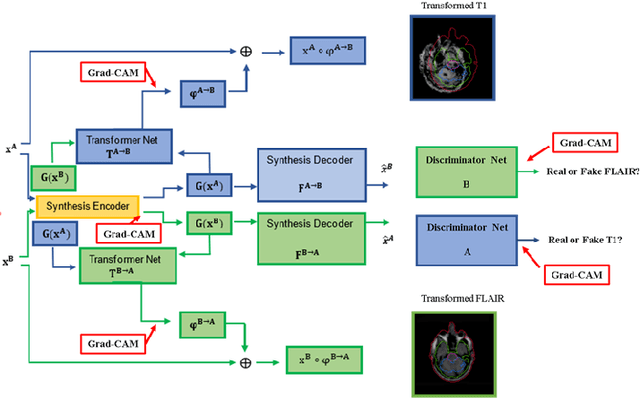
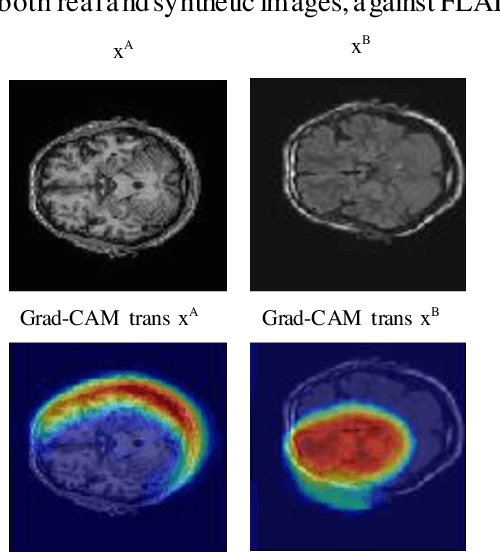

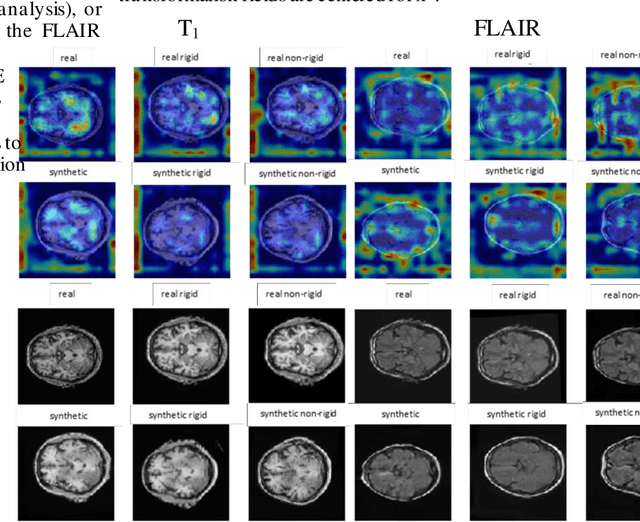
Clinical decision making from magnetic resonance imaging (MRI) combines complementary information from multiple MRI sequences (defined as 'modalities'). MRI image registration aims to geometrically 'pair' diagnoses from different modalities, time points and slices. Both intra- and inter-modality MRI registration are essential components in clinical MRI settings. Further, an MRI image processing pipeline that can address both afine and non-rigid registration is critical, as both types of deformations may be occuring in real MRI data scenarios. Unlike image classification, explainability is not commonly addressed in image registration deep learning (DL) methods, as it is challenging to interpet model-data behaviours against transformation fields. To properly address this, we incorporate Grad-CAM-based explainability frameworks in each major component of our unsupervised multi-modal and multi-organ image registration DL methodology. We previously demonstrated that we were able to reach superior performance (against the current standard Syn method). In this work, we show that our DL model becomes fully explainable, setting the framework to generalise our approach on further medical imaging data.
Distributed Deep Joint Source-Channel Coding with Decoder-Only Side Information
Oct 06, 2023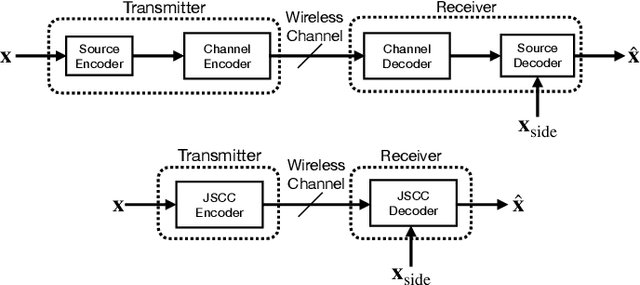
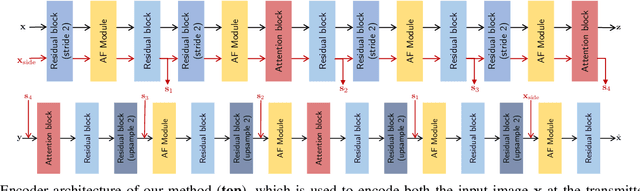

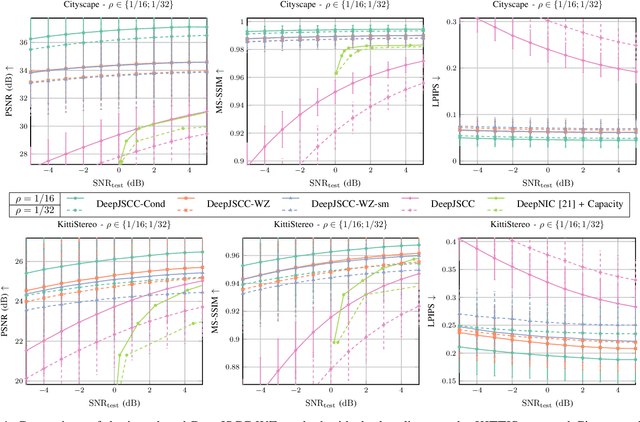
We consider low-latency image transmission over a noisy wireless channel when correlated side information is present only at the receiver side (the Wyner-Ziv scenario). In particular, we are interested in developing practical schemes using a data-driven joint source-channel coding (JSCC) approach, which has been previously shown to outperform conventional separation-based approaches in the practical finite blocklength regimes, and to provide graceful degradation with channel quality. We propose a novel neural network architecture that incorporates the decoder-only side information at multiple stages at the receiver side. Our results demonstrate that the proposed method succeeds in integrating the side information, yielding improved performance at all channel noise levels in terms of the various distortion criteria considered here, especially at low channel signal-to-noise ratios (SNRs) and small bandwidth ratios (BRs). We also provide the source code of the proposed method to enable further research and reproducibility of the results.
Generating Less Certain Adversarial Examples Improves Robust Generalization
Oct 06, 2023
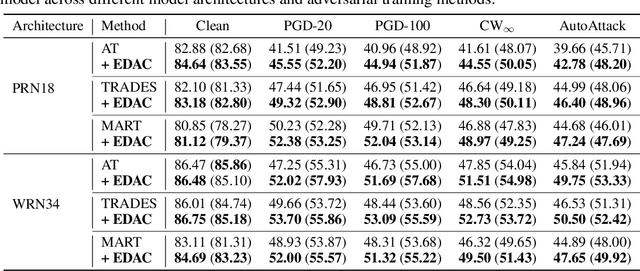
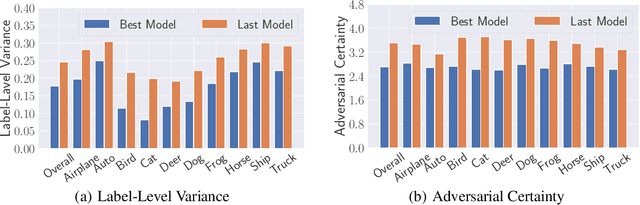
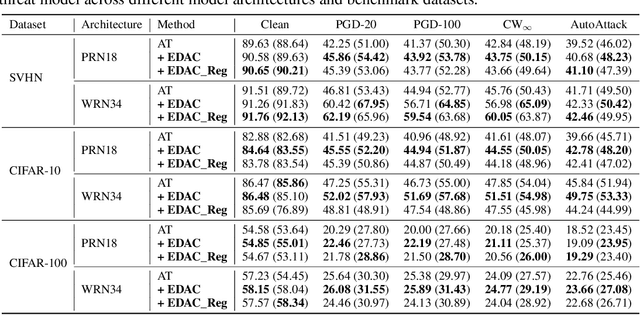
Recent studies have shown that deep neural networks are vulnerable to adversarial examples. Numerous defenses have been proposed to improve model robustness, among which adversarial training is most successful. In this work, we revisit the robust overfitting phenomenon. In particular, we argue that overconfident models produced during adversarial training could be a potential cause, supported by the empirical observation that the predicted labels of adversarial examples generated by models with better robust generalization ability tend to have significantly more even distributions. Based on the proposed definition of adversarial certainty, we incorporate an extragradient step in the adversarial training framework to search for models that can generate adversarially perturbed inputs with lower certainty, further improving robust generalization. Our approach is general and can be easily combined with other variants of adversarial training methods. Extensive experiments on image benchmarks demonstrate that our method effectively alleviates robust overfitting and is able to produce models with consistently improved robustness.
MeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance
Sep 01, 2023
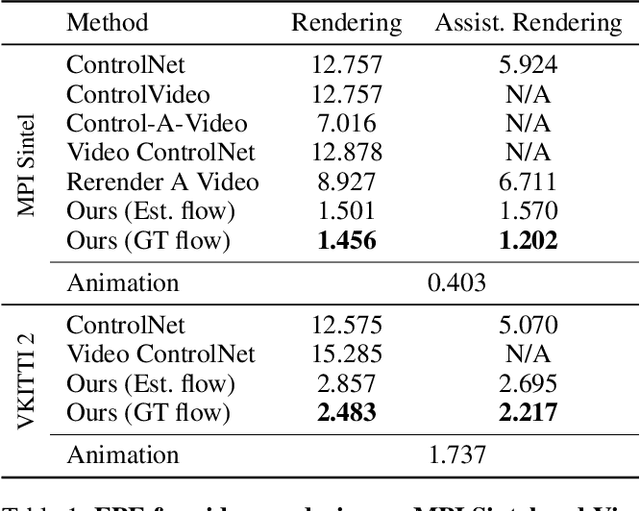
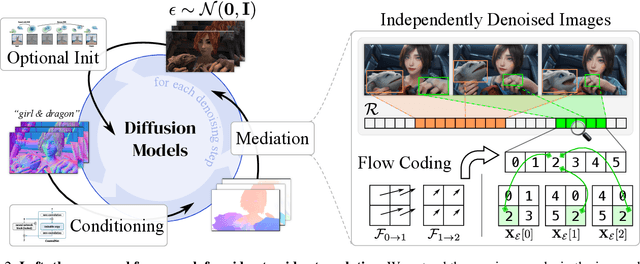
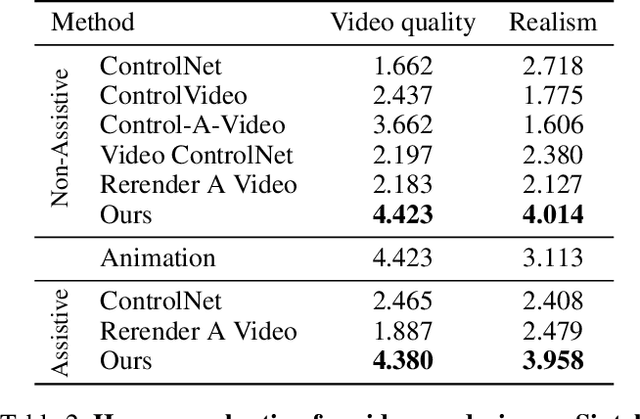
This study introduces an efficient and effective method, MeDM, that utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models. Through extensive qualitative, quantitative, and subjective experiments on various benchmarks, the study demonstrates the effectiveness and superiority of the proposed approach. Project page can be found at https://medm2023.github.io
Consistency Regularization Improves Placenta Segmentation in Fetal EPI MRI Time Series
Oct 05, 2023The placenta plays a crucial role in fetal development. Automated 3D placenta segmentation from fetal EPI MRI holds promise for advancing prenatal care. This paper proposes an effective semi-supervised learning method for improving placenta segmentation in fetal EPI MRI time series. We employ consistency regularization loss that promotes consistency under spatial transformation of the same image and temporal consistency across nearby images in a time series. The experimental results show that the method improves the overall segmentation accuracy and provides better performance for outliers and hard samples. The evaluation also indicates that our method improves the temporal coherency of the prediction, which could lead to more accurate computation of temporal placental biomarkers. This work contributes to the study of the placenta and prenatal clinical decision-making. Code is available at https://github.com/firstmover/cr-seg.
Coloring Deep CNN Layers with Activation Hue Loss
Oct 05, 2023This paper proposes a novel hue-like angular parameter to model the structure of deep convolutional neural network (CNN) activation space, referred to as the {\em activation hue}, for the purpose of regularizing models for more effective learning. The activation hue generalizes the notion of color hue angle in standard 3-channel RGB intensity space to $N$-channel activation space. A series of observations based on nearest neighbor indexing of activation vectors with pre-trained networks indicate that class-informative activations are concentrated about an angle $\theta$ in both the $(x,y)$ image plane and in multi-channel activation space. A regularization term in the form of hue-like angular $\theta$ labels is proposed to complement standard one-hot loss. Training from scratch using combined one-hot + activation hue loss improves classification performance modestly for a wide variety of classification tasks, including ImageNet.
ADU-Depth: Attention-based Distillation with Uncertainty Modeling for Depth Estimation
Sep 26, 2023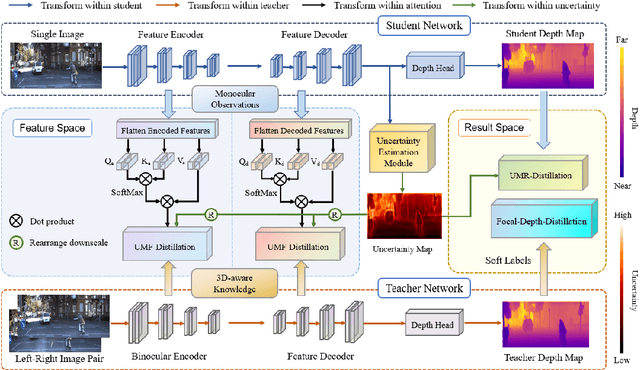
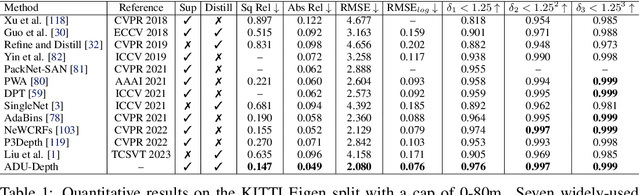
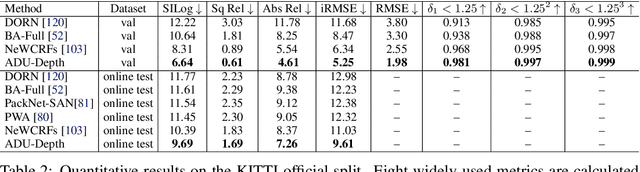

Monocular depth estimation is challenging due to its inherent ambiguity and ill-posed nature, yet it is quite important to many applications. While recent works achieve limited accuracy by designing increasingly complicated networks to extract features with limited spatial geometric cues from a single RGB image, we intend to introduce spatial cues by training a teacher network that leverages left-right image pairs as inputs and transferring the learned 3D geometry-aware knowledge to the monocular student network. Specifically, we present a novel knowledge distillation framework, named ADU-Depth, with the goal of leveraging the well-trained teacher network to guide the learning of the student network, thus boosting the precise depth estimation with the help of extra spatial scene information. To enable domain adaptation and ensure effective and smooth knowledge transfer from teacher to student, we apply both attention-adapted feature distillation and focal-depth-adapted response distillation in the training stage. In addition, we explicitly model the uncertainty of depth estimation to guide distillation in both feature space and result space to better produce 3D-aware knowledge from monocular observations and thus enhance the learning for hard-to-predict image regions. Our extensive experiments on the real depth estimation datasets KITTI and DrivingStereo demonstrate the effectiveness of the proposed method, which ranked 1st on the challenging KITTI online benchmark.
RLIPv2: Fast Scaling of Relational Language-Image Pre-training
Aug 18, 2023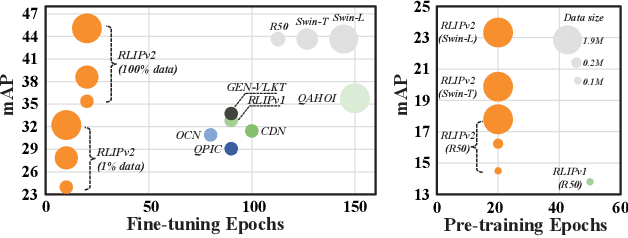
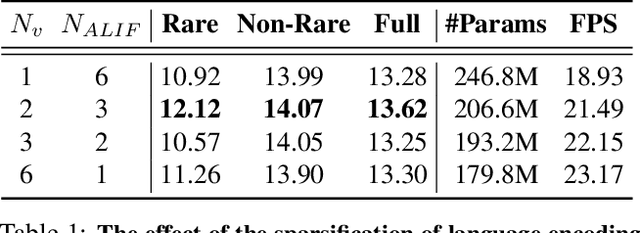
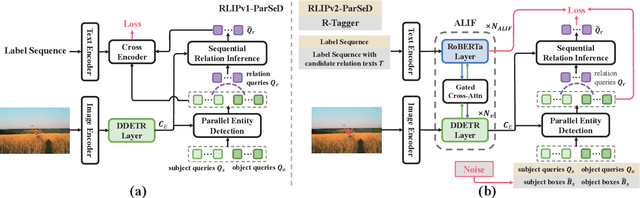
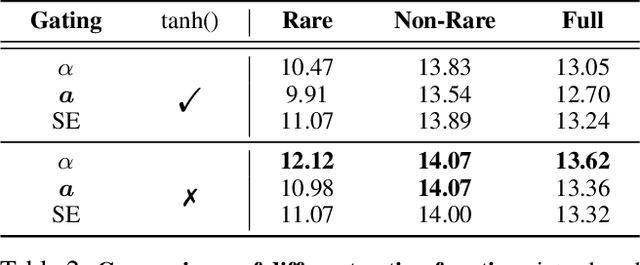
Relational Language-Image Pre-training (RLIP) aims to align vision representations with relational texts, thereby advancing the capability of relational reasoning in computer vision tasks. However, hindered by the slow convergence of RLIPv1 architecture and the limited availability of existing scene graph data, scaling RLIPv1 is challenging. In this paper, we propose RLIPv2, a fast converging model that enables the scaling of relational pre-training to large-scale pseudo-labelled scene graph data. To enable fast scaling, RLIPv2 introduces Asymmetric Language-Image Fusion (ALIF), a mechanism that facilitates earlier and deeper gated cross-modal fusion with sparsified language encoding layers. ALIF leads to comparable or better performance than RLIPv1 in a fraction of the time for pre-training and fine-tuning. To obtain scene graph data at scale, we extend object detection datasets with free-form relation labels by introducing a captioner (e.g., BLIP) and a designed Relation Tagger. The Relation Tagger assigns BLIP-generated relation texts to region pairs, thus enabling larger-scale relational pre-training. Through extensive experiments conducted on Human-Object Interaction Detection and Scene Graph Generation, RLIPv2 shows state-of-the-art performance on three benchmarks under fully-finetuning, few-shot and zero-shot settings. Notably, the largest RLIPv2 achieves 23.29mAP on HICO-DET without any fine-tuning, yields 32.22mAP with just 1% data and yields 45.09mAP with 100% data. Code and models are publicly available at https://github.com/JacobYuan7/RLIPv2.
Improving Underwater Visual Tracking With a Large Scale Dataset and Image Enhancement
Aug 31, 2023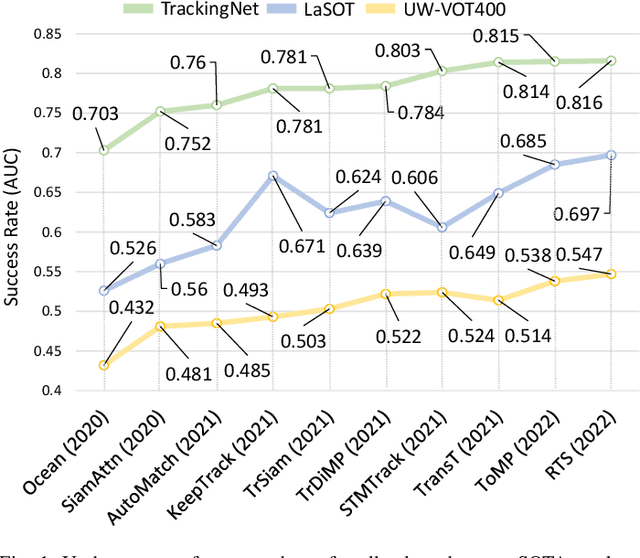
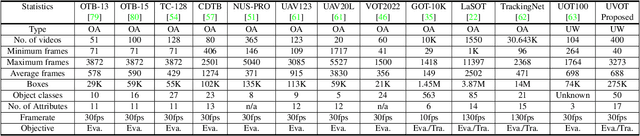


This paper presents a new dataset and general tracker enhancement method for Underwater Visual Object Tracking (UVOT). Despite its significance, underwater tracking has remained unexplored due to data inaccessibility. It poses distinct challenges; the underwater environment exhibits non-uniform lighting conditions, low visibility, lack of sharpness, low contrast, camouflage, and reflections from suspended particles. Performance of traditional tracking methods designed primarily for terrestrial or open-air scenarios drops in such conditions. We address the problem by proposing a novel underwater image enhancement algorithm designed specifically to boost tracking quality. The method has resulted in a significant performance improvement, of up to 5.0% AUC, of state-of-the-art (SOTA) visual trackers. To develop robust and accurate UVOT methods, large-scale datasets are required. To this end, we introduce a large-scale UVOT benchmark dataset consisting of 400 video segments and 275,000 manually annotated frames enabling underwater training and evaluation of deep trackers. The videos are labelled with several underwater-specific tracking attributes including watercolor variation, target distractors, camouflage, target relative size, and low visibility conditions. The UVOT400 dataset, tracking results, and the code are publicly available on: https://github.com/BasitAlawode/UWVOT400.