 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-performance Data Management for Whole Slide Image Analysis in Digital Pathology
Aug 20, 2023
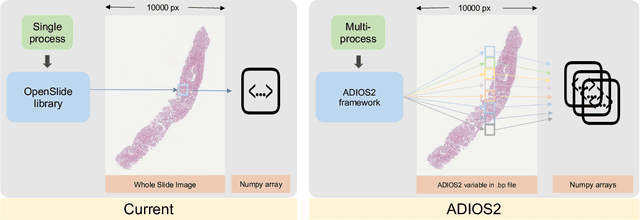

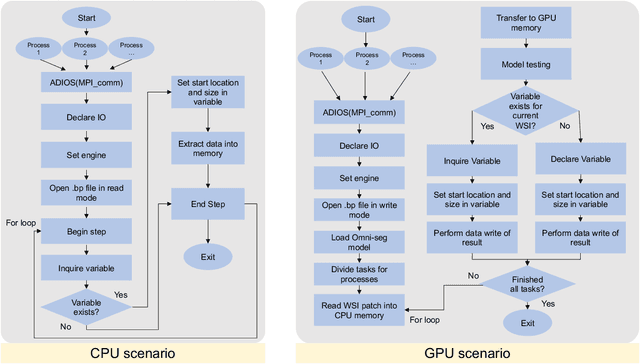

When dealing with giga-pixel digital pathology in whole-slide imaging, a notable proportion of data records holds relevance during each analysis operation. For instance, when deploying an image analysis algorithm on whole-slide images (WSI), the computational bottleneck often lies in the input-output (I/O) system. This is particularly notable as patch-level processing introduces a considerable I/O load onto the computer system. However, this data management process could be further paralleled, given the typical independence of patch-level image processes across different patches. This paper details our endeavors in tackling this data access challenge by implementing the Adaptable IO System version 2 (ADIOS2). Our focus has been constructing and releasing a digital pathology-centric pipeline using ADIOS2, which facilitates streamlined data management across WSIs. Additionally, we've developed strategies aimed at curtailing data retrieval times. The performance evaluation encompasses two key scenarios: (1) a pure CPU-based image analysis scenario ("CPU scenario"), and (2) a GPU-based deep learning framework scenario ("GPU scenario"). Our findings reveal noteworthy outcomes. Under the CPU scenario, ADIOS2 showcases an impressive two-fold speed-up compared to the brute-force approach. In the GPU scenario, its performance stands on par with the cutting-edge GPU I/O acceleration framework, NVIDIA Magnum IO GPU Direct Storage (GDS). From what we know, this appears to be among the initial instances, if any, of utilizing ADIOS2 within the field of digital pathology. The source code has been made publicly available at https://github.com/hrlblab/adios.
HydraViT: Adaptive Multi-Branch Transformer for Multi-Label Disease Classification from Chest X-ray Images
Oct 09, 2023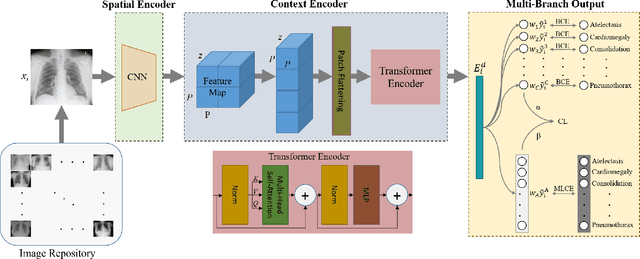
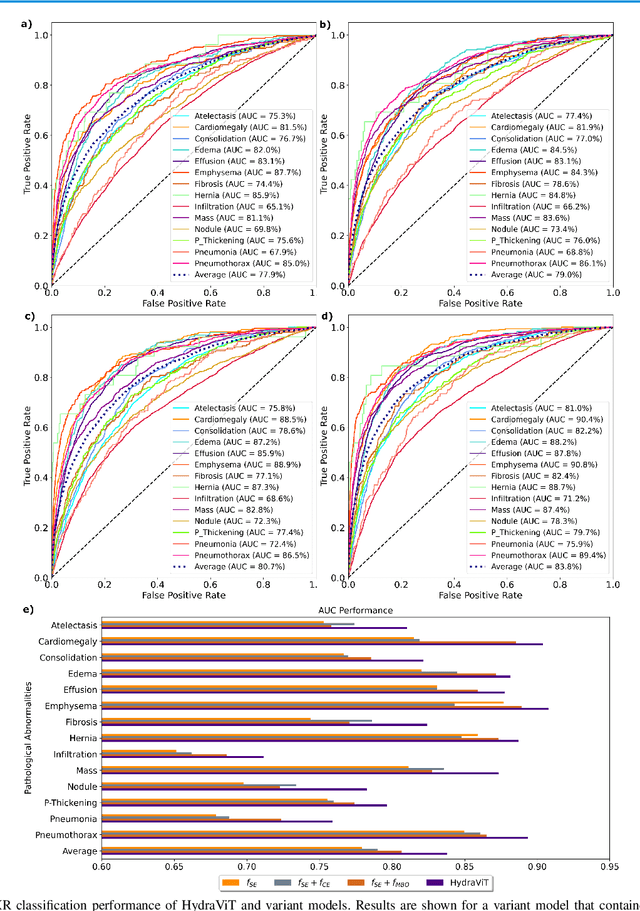
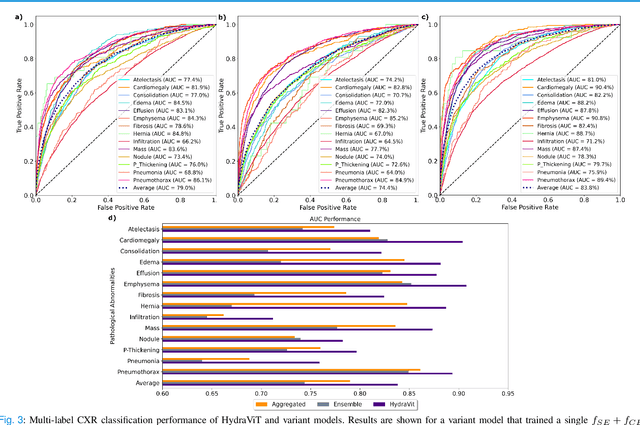
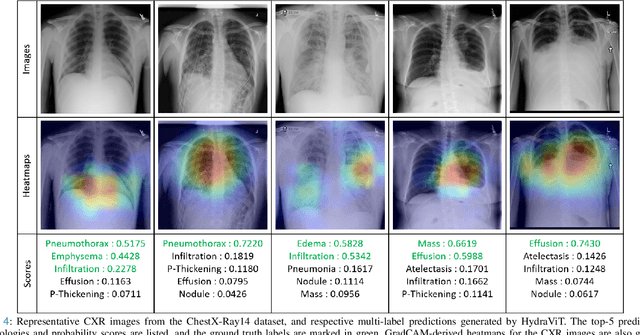
Chest X-ray is an essential diagnostic tool in the identification of chest diseases given its high sensitivity to pathological abnormalities in the lungs. However, image-driven diagnosis is still challenging due to heterogeneity in size and location of pathology, as well as visual similarities and co-occurrence of separate pathology. Since disease-related regions often occupy a relatively small portion of diagnostic images, classification models based on traditional convolutional neural networks (CNNs) are adversely affected given their locality bias. While CNNs were previously augmented with attention maps or spatial masks to guide focus on potentially critical regions, learning localization guidance under heterogeneity in the spatial distribution of pathology is challenging. To improve multi-label classification performance, here we propose a novel method, HydraViT, that synergistically combines a transformer backbone with a multi-branch output module with learned weighting. The transformer backbone enhances sensitivity to long-range context in X-ray images, while using the self-attention mechanism to adaptively focus on task-critical regions. The multi-branch output module dedicates an independent branch to each disease label to attain robust learning across separate disease classes, along with an aggregated branch across labels to maintain sensitivity to co-occurrence relationships among pathology. Experiments demonstrate that, on average, HydraViT outperforms competing attention-guided methods by 1.2%, region-guided methods by 1.4%, and semantic-guided methods by 1.0% in multi-label classification performance.
Automating Customer Service using LangChain: Building custom open-source GPT Chatbot for organizations
Oct 09, 2023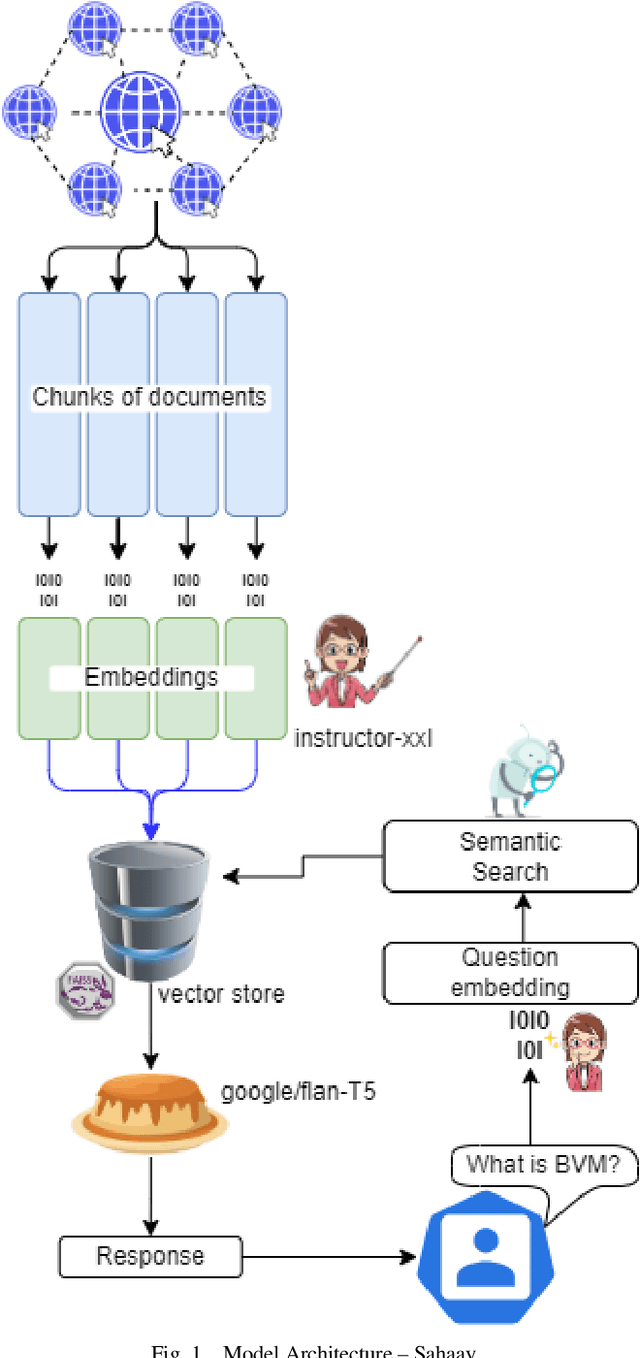



In the digital age, the dynamics of customer service are evolving, driven by technological advancements and the integration of Large Language Models (LLMs). This research paper introduces a groundbreaking approach to automating customer service using LangChain, a custom LLM tailored for organizations. The paper explores the obsolescence of traditional customer support techniques, particularly Frequently Asked Questions (FAQs), and proposes a paradigm shift towards responsive, context-aware, and personalized customer interactions. The heart of this innovation lies in the fusion of open-source methodologies, web scraping, fine-tuning, and the seamless integration of LangChain into customer service platforms. This open-source state-of-the-art framework, presented as "Sahaay," demonstrates the ability to scale across industries and organizations, offering real-time support and query resolution. Key elements of this research encompass data collection via web scraping, the role of embeddings, the utilization of Google's Flan T5 XXL, Base and Small language models for knowledge retrieval, and the integration of the chatbot into customer service platforms. The results section provides insights into their performance and use cases, here particularly within an educational institution. This research heralds a new era in customer service, where technology is harnessed to create efficient, personalized, and responsive interactions. Sahaay, powered by LangChain, redefines the customer-company relationship, elevating customer retention, value extraction, and brand image. As organizations embrace LLMs, customer service becomes a dynamic and customer-centric ecosystem.
Consistency Regularization Improves Placenta Segmentation in Fetal EPI MRI Time Series
Oct 05, 2023The placenta plays a crucial role in fetal development. Automated 3D placenta segmentation from fetal EPI MRI holds promise for advancing prenatal care. This paper proposes an effective semi-supervised learning method for improving placenta segmentation in fetal EPI MRI time series. We employ consistency regularization loss that promotes consistency under spatial transformation of the same image and temporal consistency across nearby images in a time series. The experimental results show that the method improves the overall segmentation accuracy and provides better performance for outliers and hard samples. The evaluation also indicates that our method improves the temporal coherency of the prediction, which could lead to more accurate computation of temporal placental biomarkers. This work contributes to the study of the placenta and prenatal clinical decision-making. Code is available at https://github.com/firstmover/cr-seg.
Coloring Deep CNN Layers with Activation Hue Loss
Oct 05, 2023This paper proposes a novel hue-like angular parameter to model the structure of deep convolutional neural network (CNN) activation space, referred to as the {\em activation hue}, for the purpose of regularizing models for more effective learning. The activation hue generalizes the notion of color hue angle in standard 3-channel RGB intensity space to $N$-channel activation space. A series of observations based on nearest neighbor indexing of activation vectors with pre-trained networks indicate that class-informative activations are concentrated about an angle $\theta$ in both the $(x,y)$ image plane and in multi-channel activation space. A regularization term in the form of hue-like angular $\theta$ labels is proposed to complement standard one-hot loss. Training from scratch using combined one-hot + activation hue loss improves classification performance modestly for a wide variety of classification tasks, including ImageNet.
Transmission and Color-guided Network for Underwater Image Enhancement
Aug 09, 2023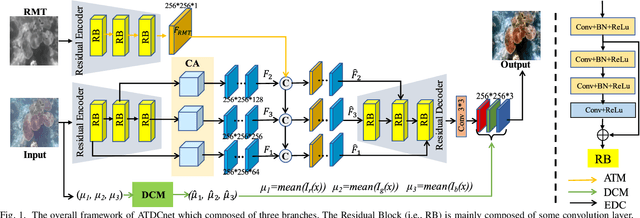

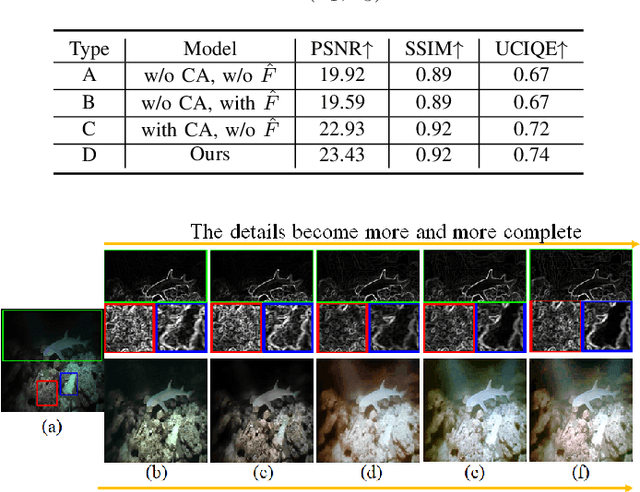
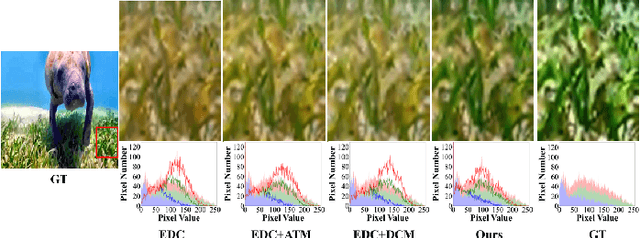
In recent years, with the continuous development of the marine industry, underwater image enhancement has attracted plenty of attention. Unfortunately, the propagation of light in water will be absorbed by water bodies and scattered by suspended particles, resulting in color deviation and low contrast. To solve these two problems, we propose an Adaptive Transmission and Dynamic Color guided network (named ATDCnet) for underwater image enhancement. In particular, to exploit the knowledge of physics, we design an Adaptive Transmission-directed Module (ATM) to better guide the network. To deal with the color deviation problem, we design a Dynamic Color-guided Module (DCM) to post-process the enhanced image color. Further, we design an Encoder-Decoder-based Compensation (EDC) structure with attention and a multi-stage feature fusion mechanism to perform color restoration and contrast enhancement simultaneously. Extensive experiments demonstrate the state-of-the-art performance of the ATDCnet on multiple benchmark datasets.
Open Image Content Disarm And Reconstruction
Jul 26, 2023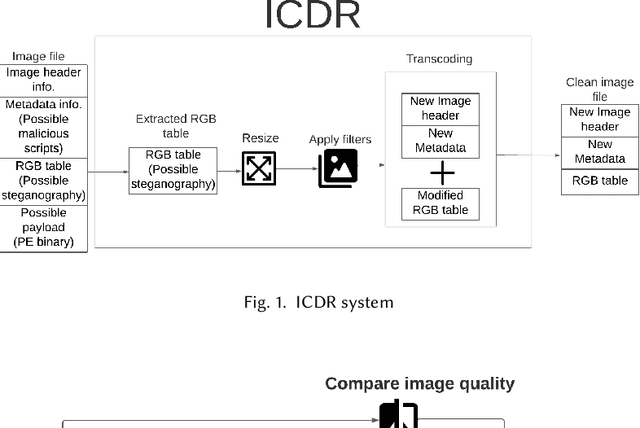
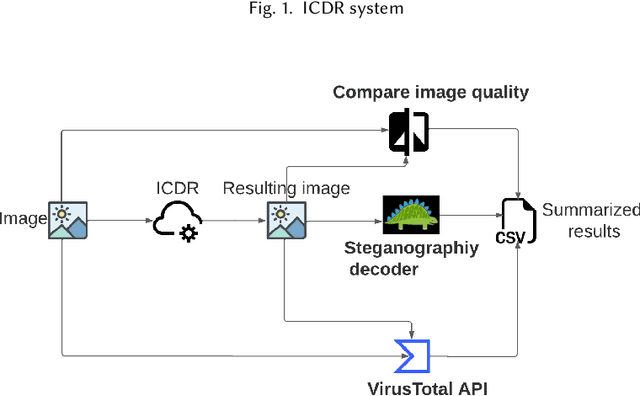
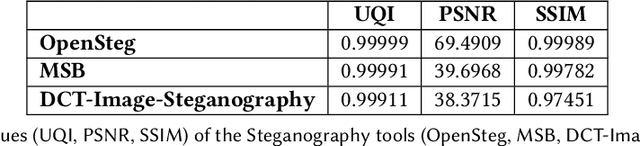
With the advance in malware technology, attackers create new ways to hide their malicious code from antivirus services. One way to obfuscate an attack is to use common files as cover to hide the malicious scripts, so the malware will look like a legitimate file. Although cutting-edge Artificial Intelligence and content signature exist, evasive malware successfully bypasses next-generation malware detection using advanced methods like steganography. Some of the files commonly used to hide malware are image files (e.g., JPEG). In addition, some malware use steganography to hide malicious scripts or sensitive data in images. Steganography in images is difficult to detect even with specialized tools. Image-based attacks try to attack the user's device using malicious payloads or utilize image steganography to hide sensitive data inside legitimate images and leak it outside the user's device. Therefore in this paper, we present a novel Image Content Disarm and Reconstruction (ICDR). Our ICDR system removes potential malware, with a zero trust approach, while maintaining high image quality and file usability. By extracting the image data, removing it from the rest of the file, and manipulating the image pixels, it is possible to disable or remove the hidden malware inside the file.
Score Priors Guided Deep Variational Inference for Unsupervised Real-World Single Image Denoising
Aug 09, 2023
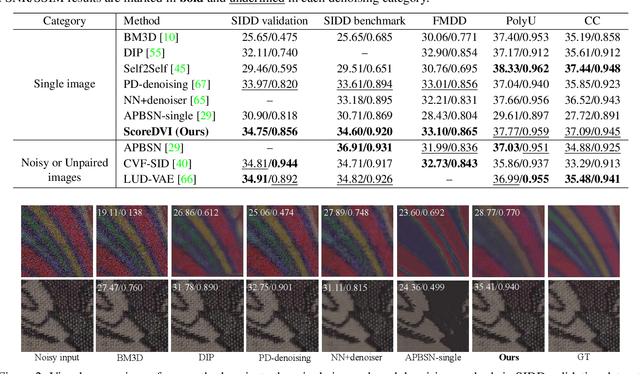


Real-world single image denoising is crucial and practical in computer vision. Bayesian inversions combined with score priors now have proven effective for single image denoising but are limited to white Gaussian noise. Moreover, applying existing score-based methods for real-world denoising requires not only the explicit train of score priors on the target domain but also the careful design of sampling procedures for posterior inference, which is complicated and impractical. To address these limitations, we propose a score priors-guided deep variational inference, namely ScoreDVI, for practical real-world denoising. By considering the deep variational image posterior with a Gaussian form, score priors are extracted based on easily accessible minimum MSE Non-$i.i.d$ Gaussian denoisers and variational samples, which in turn facilitate optimizing the variational image posterior. Such a procedure adaptively applies cheap score priors to denoising. Additionally, we exploit a Non-$i.i.d$ Gaussian mixture model and variational noise posterior to model the real-world noise. This scheme also enables the pixel-wise fusion of multiple image priors and variational image posteriors. Besides, we develop a noise-aware prior assignment strategy that dynamically adjusts the weight of image priors in the optimization. Our method outperforms other single image-based real-world denoising methods and achieves comparable performance to dataset-based unsupervised methods.
Computational Pathology at Health System Scale -- Self-Supervised Foundation Models from Three Billion Images
Oct 10, 2023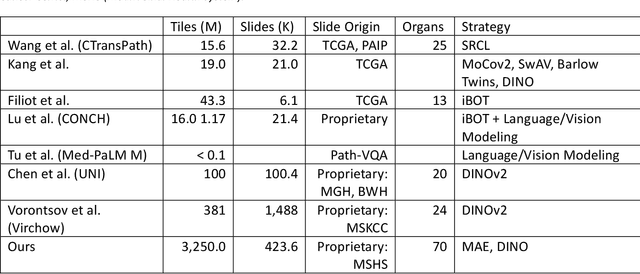
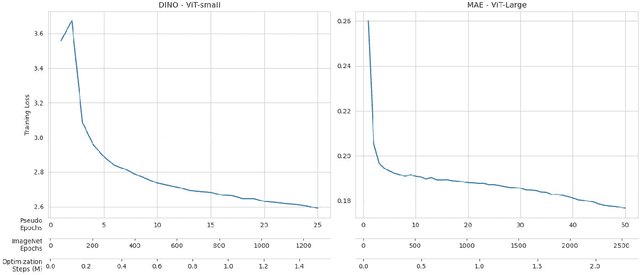
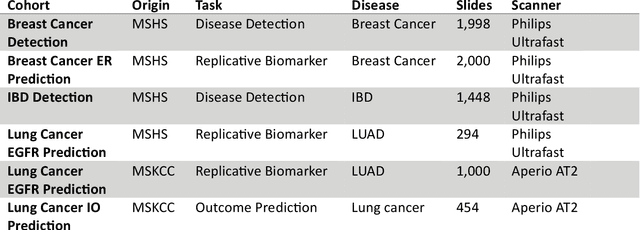
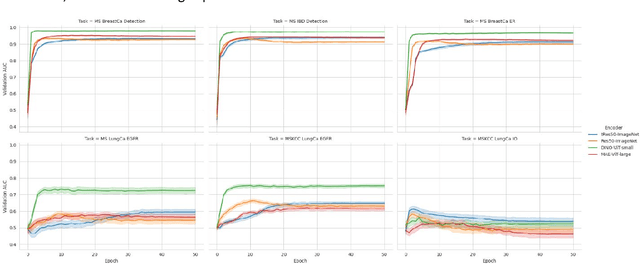
Recent breakthroughs in self-supervised learning have enabled the use of large unlabeled datasets to train visual foundation models that can generalize to a variety of downstream tasks. While this training paradigm is well suited for the medical domain where annotations are scarce, large-scale pre-training in the medical domain, and in particular pathology, has not been extensively studied. Previous work in self-supervised learning in pathology has leveraged smaller datasets for both pre-training and evaluating downstream performance. The aim of this project is to train the largest academic foundation model and benchmark the most prominent self-supervised learning algorithms by pre-training and evaluating downstream performance on large clinical pathology datasets. We collected the largest pathology dataset to date, consisting of over 3 billion images from over 423 thousand microscopy slides. We compared pre-training of visual transformer models using the masked autoencoder (MAE) and DINO algorithms. We evaluated performance on six clinically relevant tasks from three anatomic sites and two institutions: breast cancer detection, inflammatory bowel disease detection, breast cancer estrogen receptor prediction, lung adenocarcinoma EGFR mutation prediction, and lung cancer immunotherapy response prediction. Our results demonstrate that pre-training on pathology data is beneficial for downstream performance compared to pre-training on natural images. Additionally, the DINO algorithm achieved better generalization performance across all tasks tested. The presented results signify a phase change in computational pathology research, paving the way into a new era of more performant models based on large-scale, parallel pre-training at the billion-image scale.
Improved YOLOv8 Detection Algorithm in Security Inspection Image
Aug 15, 2023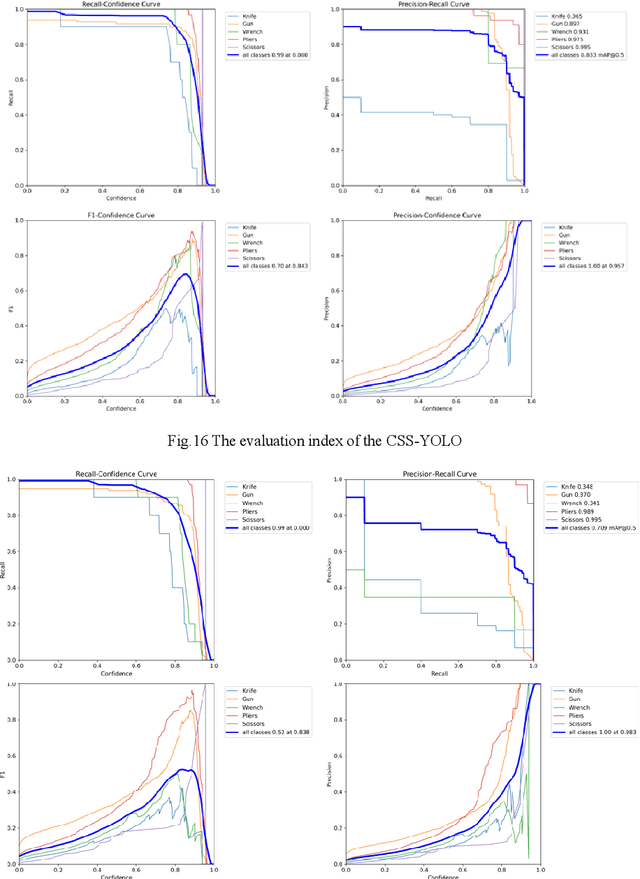


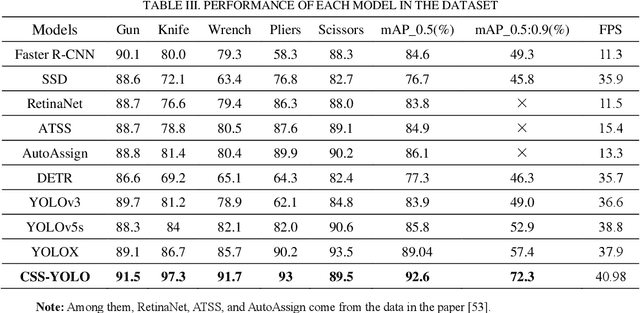
Security inspection is the first line of defense to ensure the safety of people's lives and property, and intelligent security inspection is an inevitable trend in the future development of the security inspection industry. Aiming at the problems of overlapping detection objects, false detection of contraband, and missed detection in the process of X-ray image detection, an improved X-ray contraband detection algorithm CSS-YOLO based on YOLOv8s is proposed.