 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transformer Fusion with Optimal Transport
Oct 09, 2023
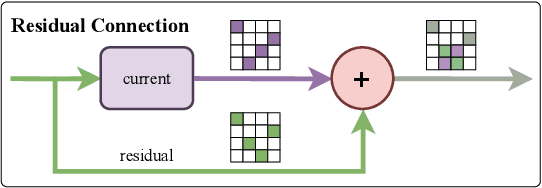
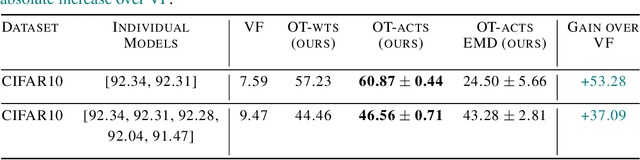
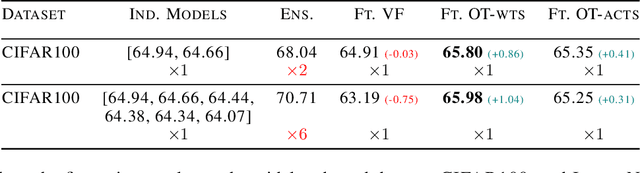
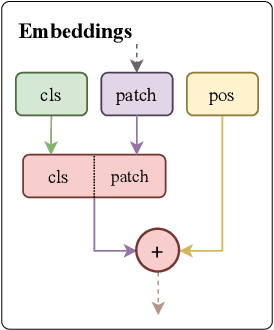
Fusion is a technique for merging multiple independently-trained neural networks in order to combine their capabilities. Past attempts have been restricted to the case of fully-connected, convolutional, and residual networks. In this paper, we present a systematic approach for fusing two or more transformer-based networks exploiting Optimal Transport to (soft-)align the various architectural components. We flesh out an abstraction for layer alignment, that can generalize to arbitrary architectures -- in principle -- and we apply this to the key ingredients of Transformers such as multi-head self-attention, layer-normalization, and residual connections, and we discuss how to handle them via various ablation studies. Furthermore, our method allows the fusion of models of different sizes (heterogeneous fusion), providing a new and efficient way for compression of Transformers. The proposed approach is evaluated on both image classification tasks via Vision Transformer and natural language modeling tasks using BERT. Our approach consistently outperforms vanilla fusion, and, after a surprisingly short finetuning, also outperforms the individual converged parent models. In our analysis, we uncover intriguing insights about the significant role of soft alignment in the case of Transformers. Our results showcase the potential of fusing multiple Transformers, thus compounding their expertise, in the budding paradigm of model fusion and recombination.
HumanNorm: Learning Normal Diffusion Model for High-quality and Realistic 3D Human Generation
Oct 02, 2023
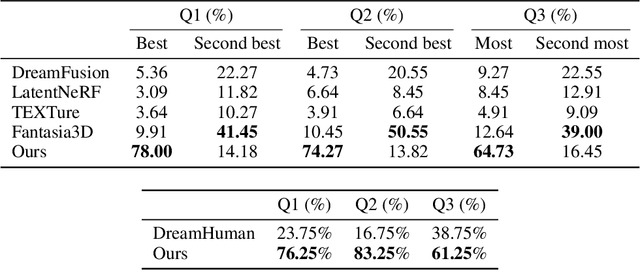

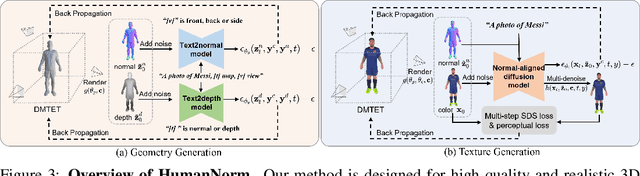
Recent text-to-3D methods employing diffusion models have made significant advancements in 3D human generation. However, these approaches face challenges due to the limitations of the text-to-image diffusion model, which lacks an understanding of 3D structures. Consequently, these methods struggle to achieve high-quality human generation, resulting in smooth geometry and cartoon-like appearances. In this paper, we observed that fine-tuning text-to-image diffusion models with normal maps enables their adaptation into text-to-normal diffusion models, which enhances the 2D perception of 3D geometry while preserving the priors learned from large-scale datasets. Therefore, we propose HumanNorm, a novel approach for high-quality and realistic 3D human generation by learning the normal diffusion model including a normal-adapted diffusion model and a normal-aligned diffusion model. The normal-adapted diffusion model can generate high-fidelity normal maps corresponding to prompts with view-dependent text. The normal-aligned diffusion model learns to generate color images aligned with the normal maps, thereby transforming physical geometry details into realistic appearance. Leveraging the proposed normal diffusion model, we devise a progressive geometry generation strategy and coarse-to-fine texture generation strategy to enhance the efficiency and robustness of 3D human generation. Comprehensive experiments substantiate our method's ability to generate 3D humans with intricate geometry and realistic appearances, significantly outperforming existing text-to-3D methods in both geometry and texture quality. The project page of HumanNorm is https://humannorm.github.io/.
Dataset Diffusion: Diffusion-based Synthetic Dataset Generation for Pixel-Level Semantic Segmentation
Sep 29, 2023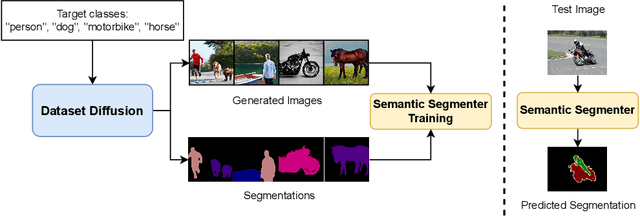
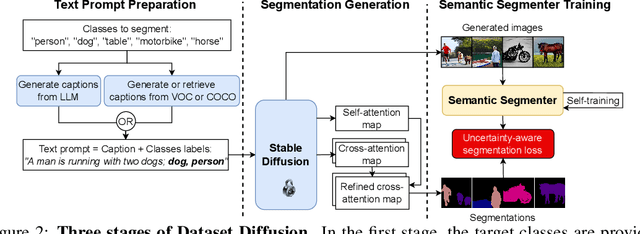
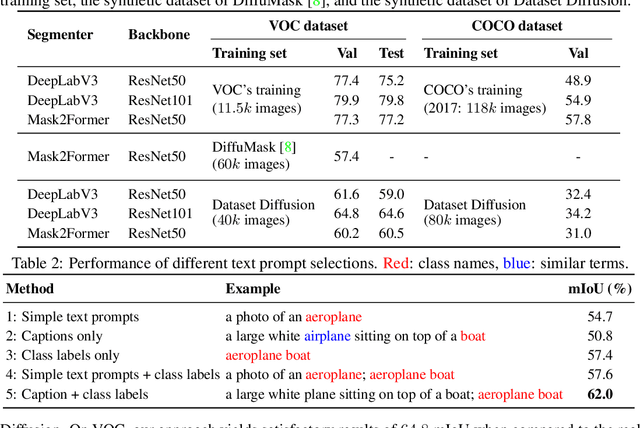

Preparing training data for deep vision models is a labor-intensive task. To address this, generative models have emerged as an effective solution for generating synthetic data. While current generative models produce image-level category labels, we propose a novel method for generating pixel-level semantic segmentation labels using the text-to-image generative model Stable Diffusion (SD). By utilizing the text prompts, cross-attention, and self-attention of SD, we introduce three new techniques: class-prompt appending, class-prompt cross-attention, and self-attention exponentiation. These techniques enable us to generate segmentation maps corresponding to synthetic images. These maps serve as pseudo-labels for training semantic segmenters, eliminating the need for labor-intensive pixel-wise annotation. To account for the imperfections in our pseudo-labels, we incorporate uncertainty regions into the segmentation, allowing us to disregard loss from those regions. We conduct evaluations on two datasets, PASCAL VOC and MSCOCO, and our approach significantly outperforms concurrent work. Our benchmarks and code will be released at https://github.com/VinAIResearch/Dataset-Diffusion
HAvatar: High-fidelity Head Avatar via Facial Model Conditioned Neural Radiance Field
Sep 29, 2023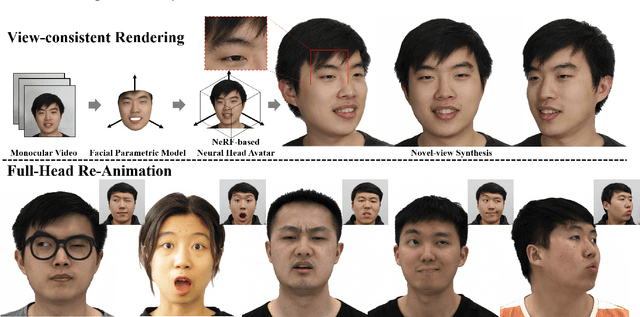
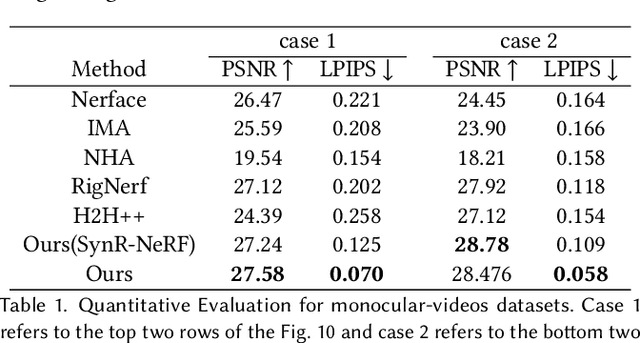
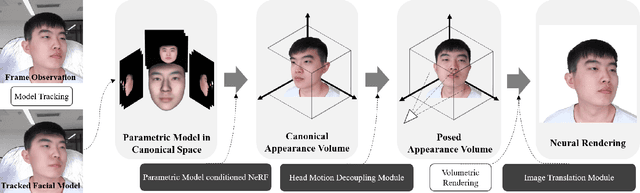
The problem of modeling an animatable 3D human head avatar under light-weight setups is of significant importance but has not been well solved. Existing 3D representations either perform well in the realism of portrait images synthesis or the accuracy of expression control, but not both. To address the problem, we introduce a novel hybrid explicit-implicit 3D representation, Facial Model Conditioned Neural Radiance Field, which integrates the expressiveness of NeRF and the prior information from the parametric template. At the core of our representation, a synthetic-renderings-based condition method is proposed to fuse the prior information from the parametric model into the implicit field without constraining its topological flexibility. Besides, based on the hybrid representation, we properly overcome the inconsistent shape issue presented in existing methods and improve the animation stability. Moreover, by adopting an overall GAN-based architecture using an image-to-image translation network, we achieve high-resolution, realistic and view-consistent synthesis of dynamic head appearance. Experiments demonstrate that our method can achieve state-of-the-art performance for 3D head avatar animation compared with previous methods.
A Foundation Model for General Moving Object Segmentation in Medical Images
Sep 29, 2023
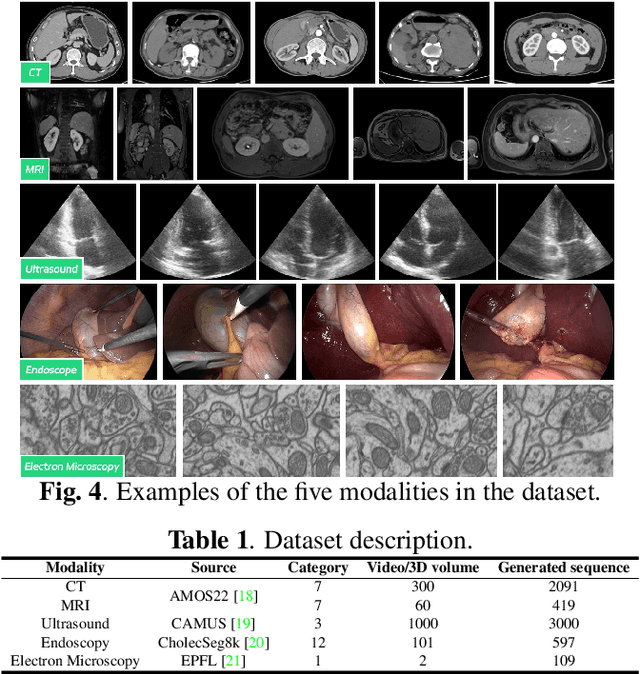
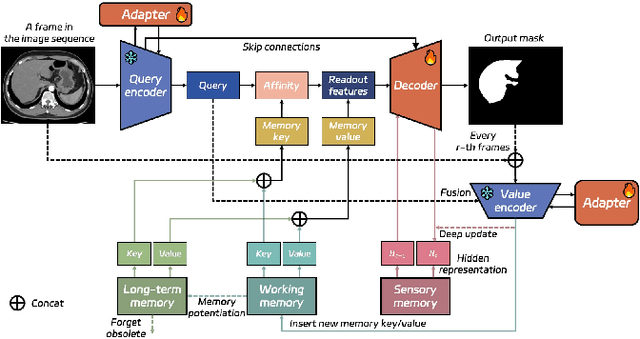
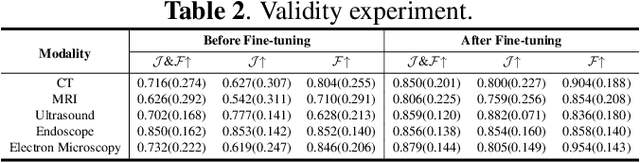
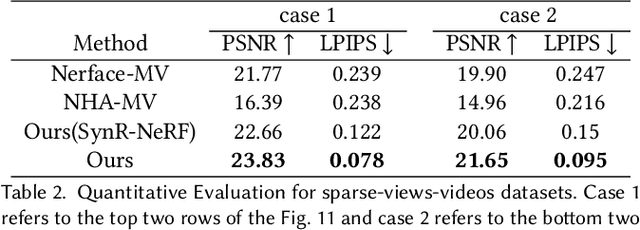
Medical image segmentation aims to delineate the anatomical or pathological structures of interest, playing a crucial role in clinical diagnosis. A substantial amount of high-quality annotated data is crucial for constructing high-precision deep segmentation models. However, medical annotation is highly cumbersome and time-consuming, especially for medical videos or 3D volumes, due to the huge labeling space and poor inter-frame consistency. Recently, a fundamental task named Moving Object Segmentation (MOS) has made significant advancements in natural images. Its objective is to delineate moving objects from the background within image sequences, requiring only minimal annotations. In this paper, we propose the first foundation model, named iMOS, for MOS in medical images. Extensive experiments on a large multi-modal medical dataset validate the effectiveness of the proposed iMOS. Specifically, with the annotation of only a small number of images in the sequence, iMOS can achieve satisfactory tracking and segmentation performance of moving objects throughout the entire sequence in bi-directions. We hope that the proposed iMOS can help accelerate the annotation speed of experts, and boost the development of medical foundation models.
3D Reconstruction with Generalizable Neural Fields using Scene Priors
Sep 29, 2023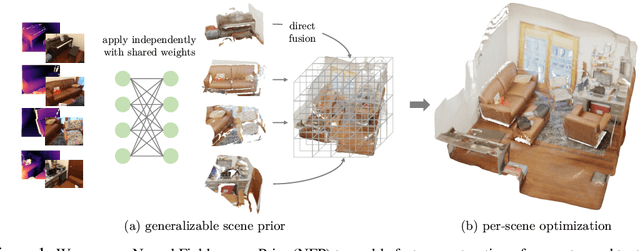
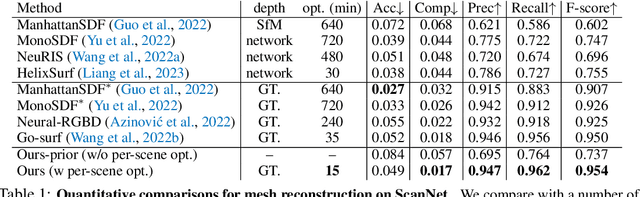
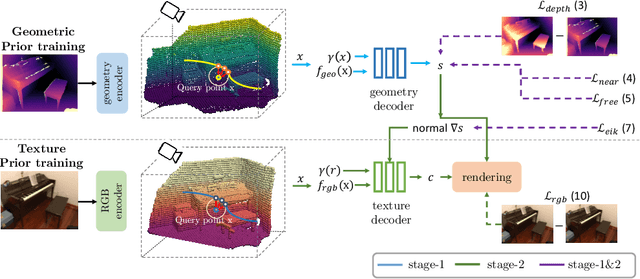
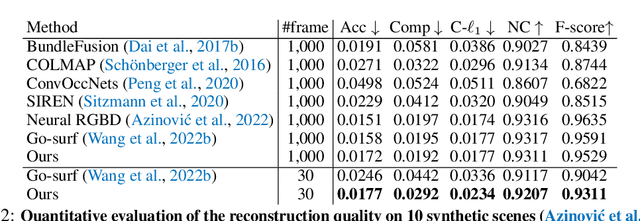
High-fidelity 3D scene reconstruction has been substantially advanced by recent progress in neural fields. However, most existing methods train a separate network from scratch for each individual scene. This is not scalable, inefficient, and unable to yield good results given limited views. While learning-based multi-view stereo methods alleviate this issue to some extent, their multi-view setting makes it less flexible to scale up and to broad applications. Instead, we introduce training generalizable Neural Fields incorporating scene Priors (NFPs). The NFP network maps any single-view RGB-D image into signed distance and radiance values. A complete scene can be reconstructed by merging individual frames in the volumetric space WITHOUT a fusion module, which provides better flexibility. The scene priors can be trained on large-scale datasets, allowing for fast adaptation to the reconstruction of a new scene with fewer views. NFP not only demonstrates SOTA scene reconstruction performance and efficiency, but it also supports single-image novel-view synthesis, which is underexplored in neural fields. More qualitative results are available at: https://oasisyang.github.io/neural-prior
End-to-End Optimization of JPEG-Based Deep Learning Process for Image Classification
Aug 10, 2023
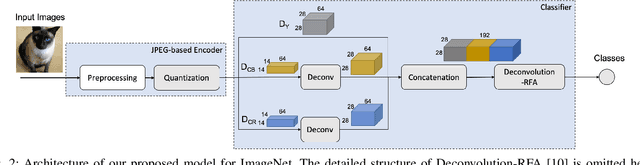
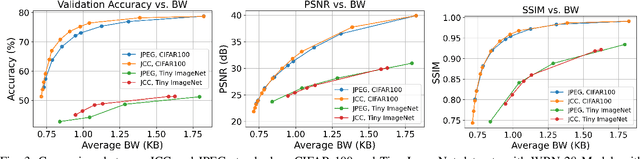
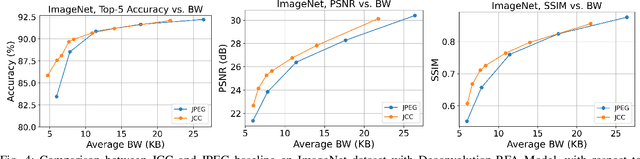
Among major deep learning (DL) applications, distributed learning involving image classification require effective image compression codecs deployed on low-cost sensing devices for efficient transmission and storage. Traditional codecs such as JPEG designed for perceptual quality are not configured for DL tasks. This work introduces an integrative end-to-end trainable model for image compression and classification consisting of a JPEG image codec and a DL-based classifier. We demonstrate how this model can optimize the widely deployed JPEG codec settings to improve classification accuracy in consideration of bandwidth constraint. Our tests on CIFAR-100 and ImageNet also demonstrate improved validation accuracy over preset JPEG configuration.
Compositional Servoing by Recombining Demonstrations
Oct 06, 2023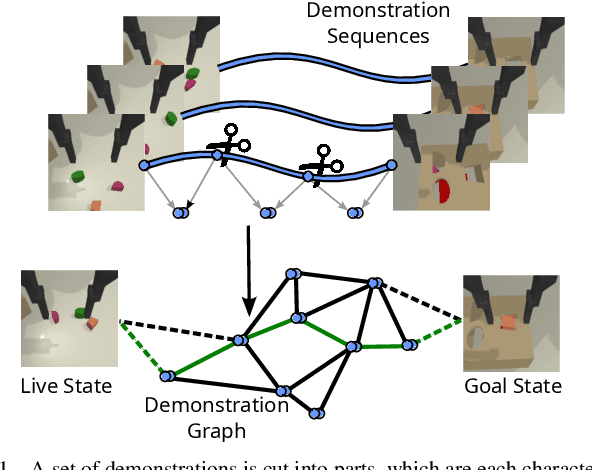
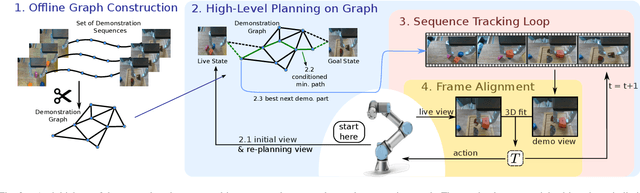
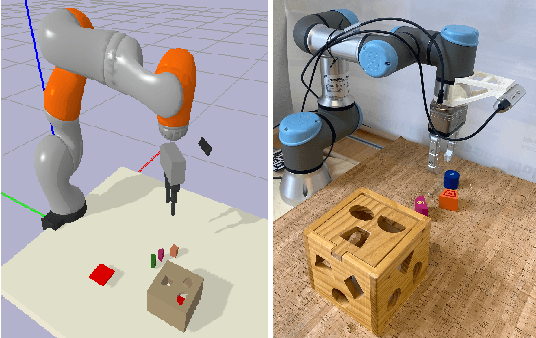
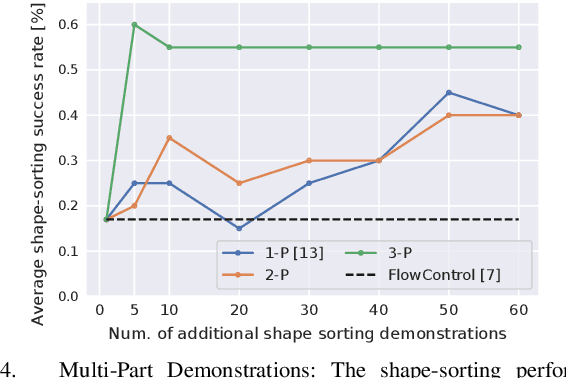
Learning-based manipulation policies from image inputs often show weak task transfer capabilities. In contrast, visual servoing methods allow efficient task transfer in high-precision scenarios while requiring only a few demonstrations. In this work, we present a framework that formulates the visual servoing task as graph traversal. Our method not only extends the robustness of visual servoing, but also enables multitask capability based on a few task-specific demonstrations. We construct demonstration graphs by splitting existing demonstrations and recombining them. In order to traverse the demonstration graph in the inference case, we utilize a similarity function that helps select the best demonstration for a specific task. This enables us to compute the shortest path through the graph. Ultimately, we show that recombining demonstrations leads to higher task-respective success. We present extensive simulation and real-world experimental results that demonstrate the efficacy of our approach.
Envisioning Narrative Intelligence: A Creative Visual Storytelling Anthology
Oct 06, 2023In this paper, we collect an anthology of 100 visual stories from authors who participated in our systematic creative process of improvised story-building based on image sequences. Following close reading and thematic analysis of our anthology, we present five themes that characterize the variations found in this creative visual storytelling process: (1) Narrating What is in Vision vs. Envisioning; (2) Dynamically Characterizing Entities/Objects; (3) Sensing Experiential Information About the Scenery; (4) Modulating the Mood; (5) Encoding Narrative Biases. In understanding the varied ways that people derive stories from images, we offer considerations for collecting story-driven training data to inform automatic story generation. In correspondence with each theme, we envision narrative intelligence criteria for computational visual storytelling as: creative, reliable, expressive, grounded, and responsible. From these criteria, we discuss how to foreground creative expression, account for biases, and operate in the bounds of visual storyworlds.
* 21 pages, 11 figures
DLSIA: Deep Learning for Scientific Image Analysis
Aug 02, 2023We introduce DLSIA (Deep Learning for Scientific Image Analysis), a Python-based machine learning library that empowers scientists and researchers across diverse scientific domains with a range of customizable convolutional neural network (CNN) architectures for a wide variety of tasks in image analysis to be used in downstream data processing, or for experiment-in-the-loop computing scenarios. DLSIA features easy-to-use architectures such as autoencoders, tunable U-Nets, and parameter-lean mixed-scale dense networks (MSDNets). Additionally, we introduce sparse mixed-scale networks (SMSNets), generated using random graphs and sparse connections. As experimental data continues to grow in scale and complexity, DLSIA provides accessible CNN construction and abstracts CNN complexities, allowing scientists to tailor their machine learning approaches, accelerate discoveries, foster interdisciplinary collaboration, and advance research in scientific image analysis.