 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Neuro-Mimetic Realization of the Common Model of Cognition via Hebbian Learning and Free Energy Minimization
Oct 14, 2023
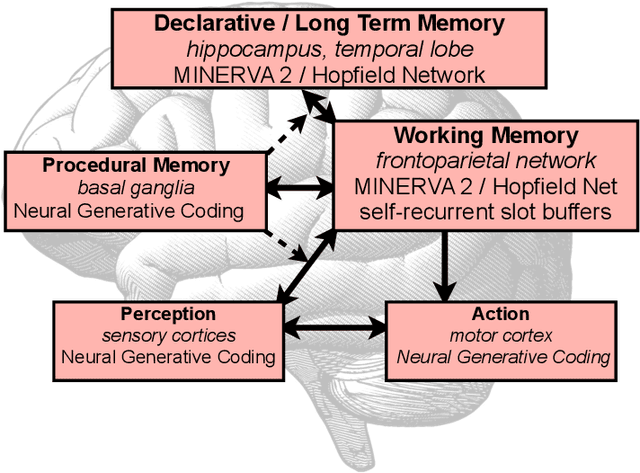
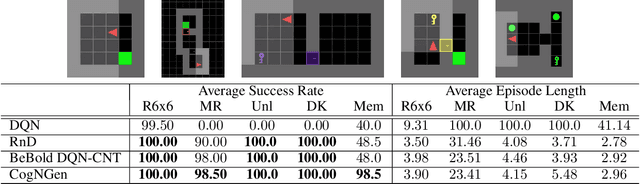
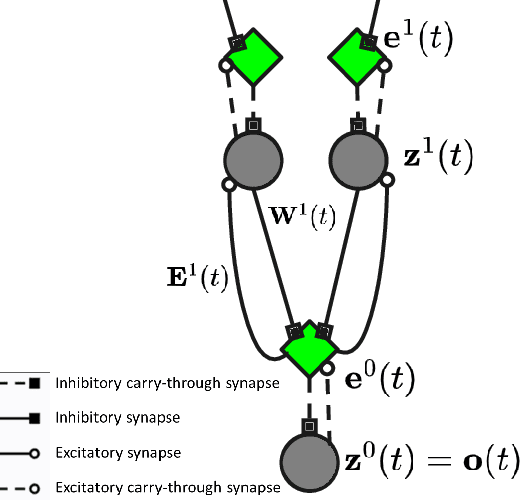
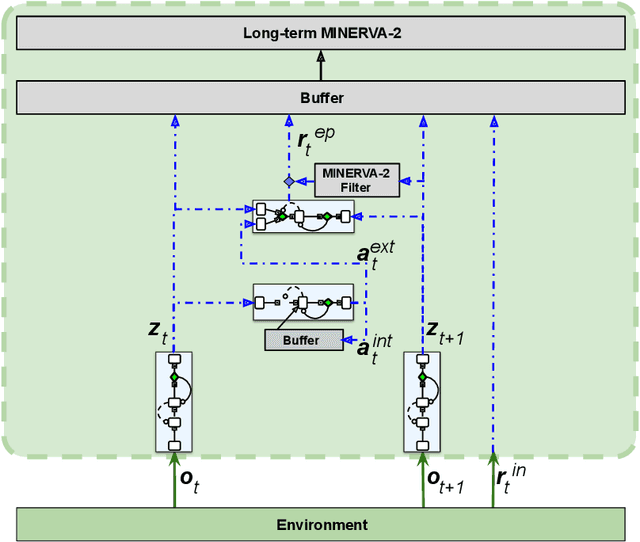
Over the last few years, large neural generative models, capable of synthesizing intricate sequences of words or producing complex image patterns, have recently emerged as a popular representation of what has come to be known as "generative artificial intelligence" (generative AI). Beyond opening the door to new opportunities as well as challenges for the domain of statistical machine learning, the rising popularity of generative AI brings with it interesting questions for Cognitive Science, which seeks to discover the nature of the processes that underpin minds and brains as well as to understand how such functionality might be acquired and instantiated in biological (or artificial) substrate. With this goal in mind, we argue that a promising long-term pathway lies in the crafting of cognitive architectures, a long-standing tradition of the field, cast fundamentally in terms of neuro-mimetic generative building blocks. Concretely, we discuss the COGnitive Neural GENerative system, which is an architecture that casts the Common Model of Cognition in terms of Hebbian adaptation operating in service of optimizing a variational free energy functional.
RL-based Stateful Neural Adaptive Sampling and Denoising for Real-Time Path Tracing
Oct 05, 2023Monte-Carlo path tracing is a powerful technique for realistic image synthesis but suffers from high levels of noise at low sample counts, limiting its use in real-time applications. To address this, we propose a framework with end-to-end training of a sampling importance network, a latent space encoder network, and a denoiser network. Our approach uses reinforcement learning to optimize the sampling importance network, thus avoiding explicit numerically approximated gradients. Our method does not aggregate the sampled values per pixel by averaging but keeps all sampled values which are then fed into the latent space encoder. The encoder replaces handcrafted spatiotemporal heuristics by learned representations in a latent space. Finally, a neural denoiser is trained to refine the output image. Our approach increases visual quality on several challenging datasets and reduces rendering times for equal quality by a factor of 1.6x compared to the previous state-of-the-art, making it a promising solution for real-time applications.
Local Distortion Aware Efficient Transformer Adaptation for Image Quality Assessment
Aug 23, 2023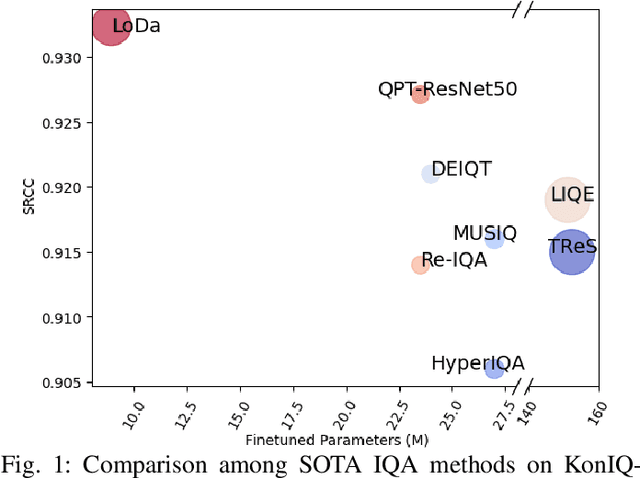
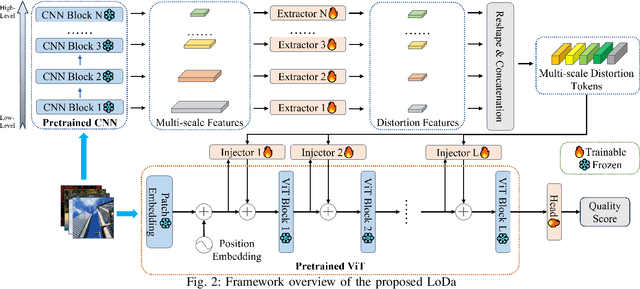
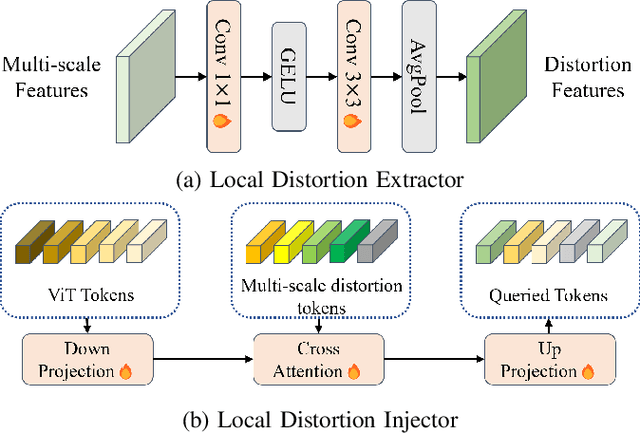
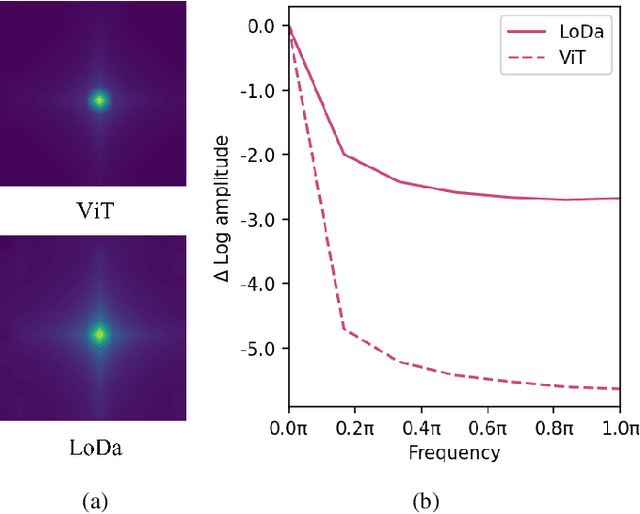
Image Quality Assessment (IQA) constitutes a fundamental task within the field of computer vision, yet it remains an unresolved challenge, owing to the intricate distortion conditions, diverse image contents, and limited availability of data. Recently, the community has witnessed the emergence of numerous large-scale pretrained foundation models, which greatly benefit from dramatically increased data and parameter capacities. However, it remains an open problem whether the scaling law in high-level tasks is also applicable to IQA task which is closely related to low-level clues. In this paper, we demonstrate that with proper injection of local distortion features, a larger pretrained and fixed foundation model performs better in IQA tasks. Specifically, for the lack of local distortion structure and inductive bias of vision transformer (ViT), alongside the large-scale pretrained ViT, we use another pretrained convolution neural network (CNN), which is well known for capturing the local structure, to extract multi-scale image features. Further, we propose a local distortion extractor to obtain local distortion features from the pretrained CNN and a local distortion injector to inject the local distortion features into ViT. By only training the extractor and injector, our method can benefit from the rich knowledge in the powerful foundation models and achieve state-of-the-art performance on popular IQA datasets, indicating that IQA is not only a low-level problem but also benefits from stronger high-level features drawn from large-scale pretrained models.
LocoNeRF: A NeRF-based Approach for Local Structure from Motion for Precise Localization
Oct 08, 2023


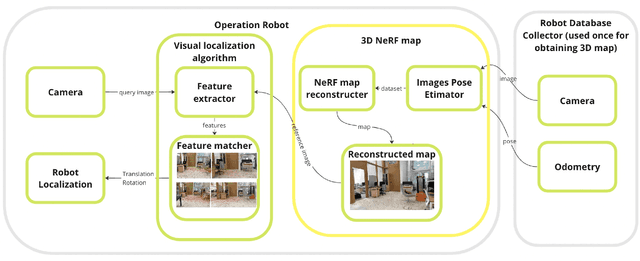
Visual localization is a critical task in mobile robotics, and researchers are continuously developing new approaches to enhance its efficiency. In this article, we propose a novel approach to improve the accuracy of visual localization using Structure from Motion (SfM) techniques. We highlight the limitations of global SfM, which suffers from high latency, and the challenges of local SfM, which requires large image databases for accurate reconstruction. To address these issues, we propose utilizing Neural Radiance Fields (NeRF), as opposed to image databases, to cut down on the space required for storage. We suggest that sampling reference images around the prior query position can lead to further improvements. We evaluate the accuracy of our proposed method against ground truth obtained using LIDAR and Advanced Lidar Odometry and Mapping in Real-time (A-LOAM), and compare its storage usage against local SfM with COLMAP in the conducted experiments. Our proposed method achieves an accuracy of 0.068 meters compared to the ground truth, which is slightly lower than the most advanced method COLMAP, which has an accuracy of 0.022 meters. However, the size of the database required for COLMAP is 400 megabytes, whereas the size of our NeRF model is only 160 megabytes. Finally, we perform an ablation study to assess the impact of using reference images from the NeRF reconstruction.
Safe and Robust Watermark Injection with a Single OoD Image
Sep 04, 2023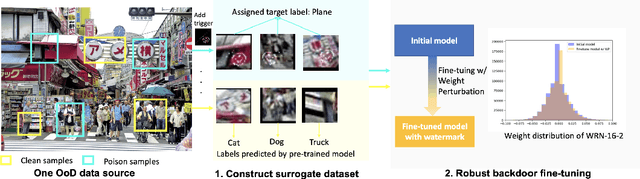

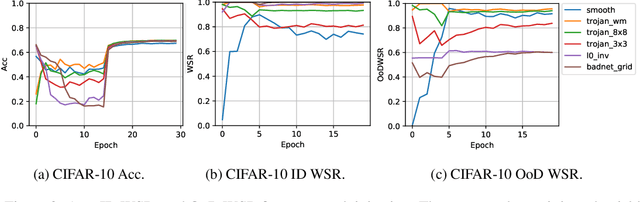
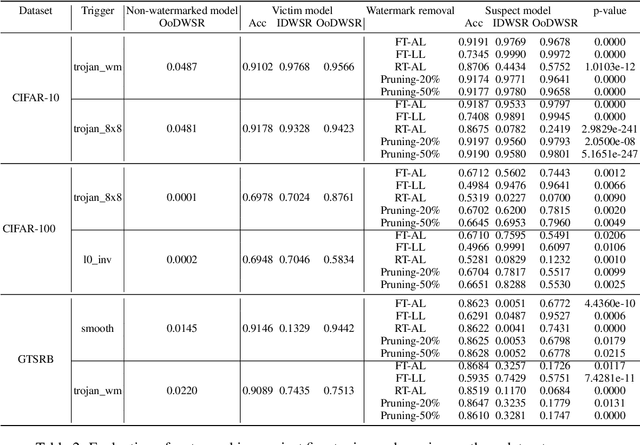
Training a high-performance deep neural network requires large amounts of data and computational resources. Protecting the intellectual property (IP) and commercial ownership of a deep model is challenging yet increasingly crucial. A major stream of watermarking strategies implants verifiable backdoor triggers by poisoning training samples, but these are often unrealistic due to data privacy and safety concerns and are vulnerable to minor model changes such as fine-tuning. To overcome these challenges, we propose a safe and robust backdoor-based watermark injection technique that leverages the diverse knowledge from a single out-of-distribution (OoD) image, which serves as a secret key for IP verification. The independence of training data makes it agnostic to third-party promises of IP security. We induce robustness via random perturbation of model parameters during watermark injection to defend against common watermark removal attacks, including fine-tuning, pruning, and model extraction. Our experimental results demonstrate that the proposed watermarking approach is not only time- and sample-efficient without training data, but also robust against the watermark removal attacks above.
Fast and High-Performance Learned Image Compression With Improved Checkerboard Context Model, Deformable Residual Module, and Knowledge Distillation
Sep 05, 2023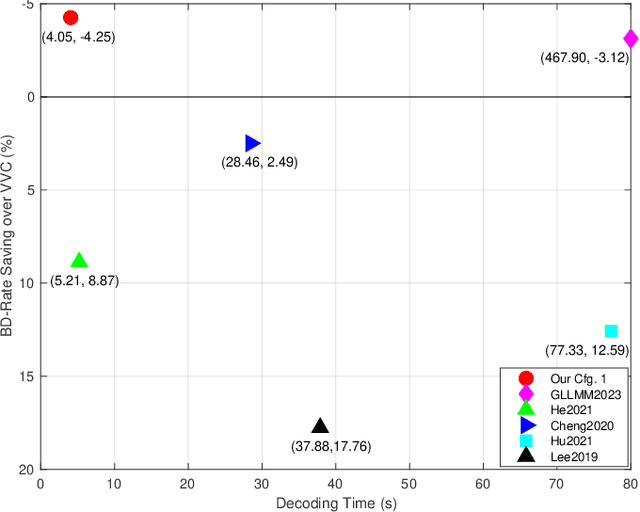
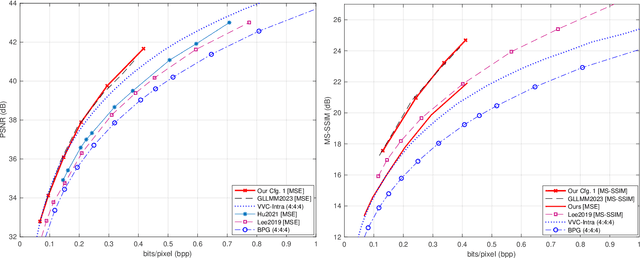
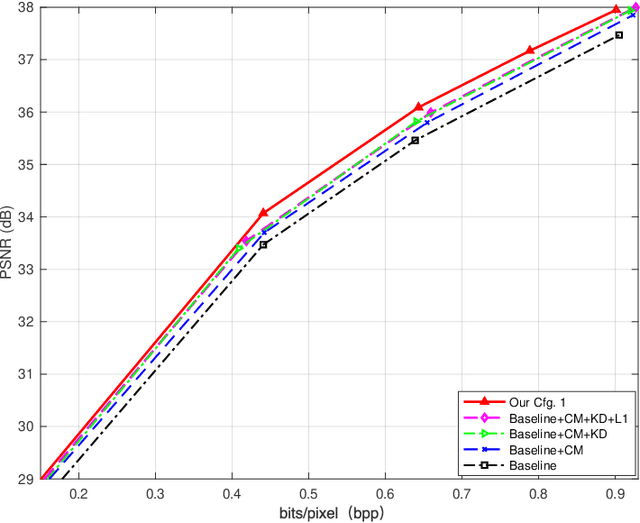
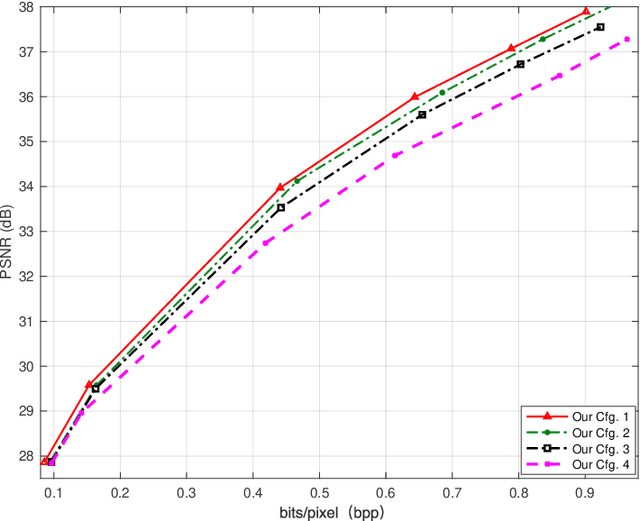
Deep learning-based image compression has made great progresses recently. However, many leading schemes use serial context-adaptive entropy model to improve the rate-distortion (R-D) performance, which is very slow. In addition, the complexities of the encoding and decoding networks are quite high and not suitable for many practical applications. In this paper, we introduce four techniques to balance the trade-off between the complexity and performance. We are the first to introduce deformable convolutional module in compression framework, which can remove more redundancies in the input image, thereby enhancing compression performance. Second, we design a checkerboard context model with two separate distribution parameter estimation networks and different probability models, which enables parallel decoding without sacrificing the performance compared to the sequential context-adaptive model. Third, we develop an improved three-step knowledge distillation and training scheme to achieve different trade-offs between the complexity and the performance of the decoder network, which transfers both the final and intermediate results of the teacher network to the student network to help its training. Fourth, we introduce $L_{1}$ regularization to make the numerical values of the latent representation more sparse. Then we only encode non-zero channels in the encoding and decoding process, which can greatly reduce the encoding and decoding time. Experiments show that compared to the state-of-the-art learned image coding scheme, our method can be about 20 times faster in encoding and 70-90 times faster in decoding, and our R-D performance is also $2.3 \%$ higher. Our method outperforms the traditional approach in H.266/VVC-intra (4:4:4) and some leading learned schemes in terms of PSNR and MS-SSIM metrics when testing on Kodak and Tecnick-40 datasets.
An automated approach for improving the inference latency and energy efficiency of pretrained CNNs by removing irrelevant pixels with focused convolutions
Oct 11, 2023Computer vision often uses highly accurate Convolutional Neural Networks (CNNs), but these deep learning models are associated with ever-increasing energy and computation requirements. Producing more energy-efficient CNNs often requires model training which can be cost-prohibitive. We propose a novel, automated method to make a pretrained CNN more energy-efficient without re-training. Given a pretrained CNN, we insert a threshold layer that filters activations from the preceding layers to identify regions of the image that are irrelevant, i.e. can be ignored by the following layers while maintaining accuracy. Our modified focused convolution operation saves inference latency (by up to 25%) and energy costs (by up to 22%) on various popular pretrained CNNs, with little to no loss in accuracy.
Chinese Text Recognition with A Pre-Trained CLIP-Like Model Through Image-IDS Aligning
Sep 03, 2023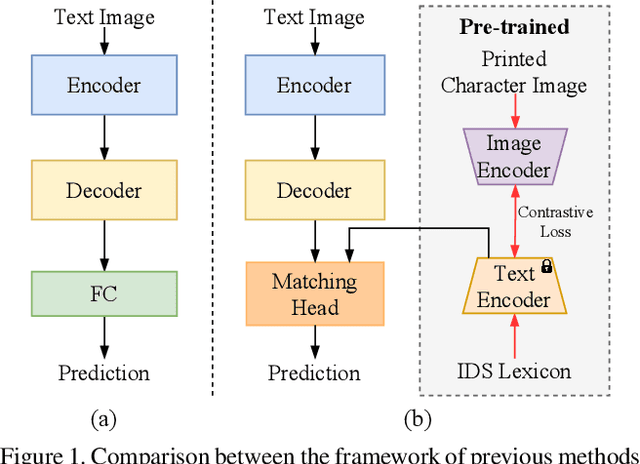
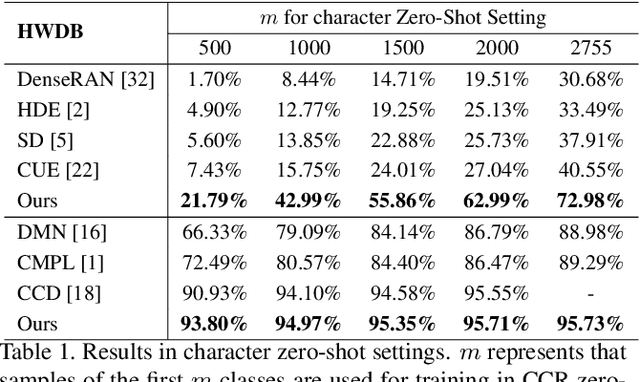

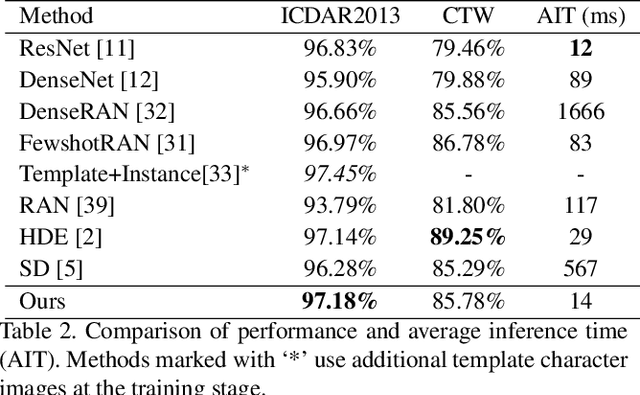
Scene text recognition has been studied for decades due to its broad applications. However, despite Chinese characters possessing different characteristics from Latin characters, such as complex inner structures and large categories, few methods have been proposed for Chinese Text Recognition (CTR). Particularly, the characteristic of large categories poses challenges in dealing with zero-shot and few-shot Chinese characters. In this paper, inspired by the way humans recognize Chinese texts, we propose a two-stage framework for CTR. Firstly, we pre-train a CLIP-like model through aligning printed character images and Ideographic Description Sequences (IDS). This pre-training stage simulates humans recognizing Chinese characters and obtains the canonical representation of each character. Subsequently, the learned representations are employed to supervise the CTR model, such that traditional single-character recognition can be improved to text-line recognition through image-IDS matching. To evaluate the effectiveness of the proposed method, we conduct extensive experiments on both Chinese character recognition (CCR) and CTR. The experimental results demonstrate that the proposed method performs best in CCR and outperforms previous methods in most scenarios of the CTR benchmark. It is worth noting that the proposed method can recognize zero-shot Chinese characters in text images without fine-tuning, whereas previous methods require fine-tuning when new classes appear. The code is available at https://github.com/FudanVI/FudanOCR/tree/main/image-ids-CTR.
Mapping Memes to Words for Multimodal Hateful Meme Classification
Oct 12, 2023Multimodal image-text memes are prevalent on the internet, serving as a unique form of communication that combines visual and textual elements to convey humor, ideas, or emotions. However, some memes take a malicious turn, promoting hateful content and perpetuating discrimination. Detecting hateful memes within this multimodal context is a challenging task that requires understanding the intertwined meaning of text and images. In this work, we address this issue by proposing a novel approach named ISSUES for multimodal hateful meme classification. ISSUES leverages a pre-trained CLIP vision-language model and the textual inversion technique to effectively capture the multimodal semantic content of the memes. The experiments show that our method achieves state-of-the-art results on the Hateful Memes Challenge and HarMeme datasets. The code and the pre-trained models are publicly available at https://github.com/miccunifi/ISSUES.
HairCLIPv2: Unifying Hair Editing via Proxy Feature Blending
Oct 16, 2023Hair editing has made tremendous progress in recent years. Early hair editing methods use well-drawn sketches or masks to specify the editing conditions. Even though they can enable very fine-grained local control, such interaction modes are inefficient for the editing conditions that can be easily specified by language descriptions or reference images. Thanks to the recent breakthrough of cross-modal models (e.g., CLIP), HairCLIP is the first work that enables hair editing based on text descriptions or reference images. However, such text-driven and reference-driven interaction modes make HairCLIP unable to support fine-grained controls specified by sketch or mask. In this paper, we propose HairCLIPv2, aiming to support all the aforementioned interactions with one unified framework. Simultaneously, it improves upon HairCLIP with better irrelevant attributes (e.g., identity, background) preservation and unseen text descriptions support. The key idea is to convert all the hair editing tasks into hair transfer tasks, with editing conditions converted into different proxies accordingly. The editing effects are added upon the input image by blending the corresponding proxy features within the hairstyle or hair color feature spaces. Besides the unprecedented user interaction mode support, quantitative and qualitative experiments demonstrate the superiority of HairCLIPv2 in terms of editing effects, irrelevant attribute preservation and visual naturalness. Our code is available at \url{https://github.com/wty-ustc/HairCLIPv2}.