 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning A Coarse-to-Fine Diffusion Transformer for Image Restoration
Aug 17, 2023


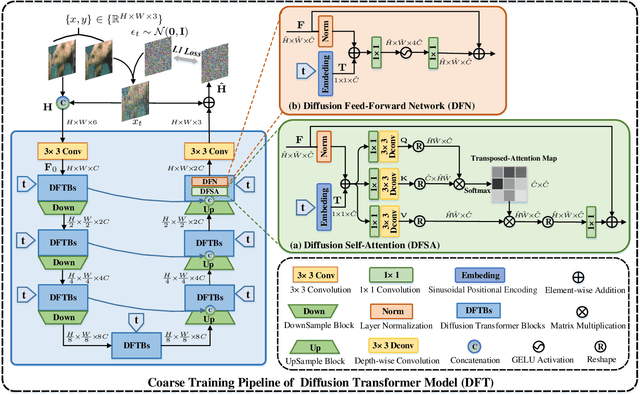
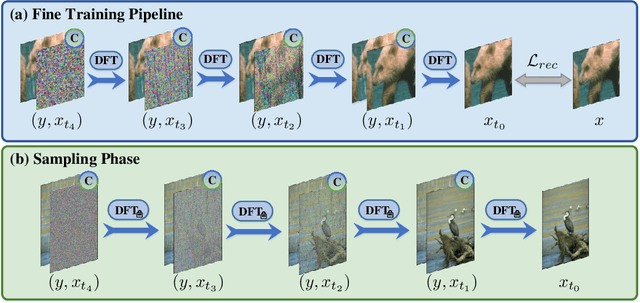
Recent years have witnessed the remarkable performance of diffusion models in various vision tasks. However, for image restoration that aims to recover clear images with sharper details from given degraded observations, diffusion-based methods may fail to recover promising results due to inaccurate noise estimation. Moreover, simple constraining noises cannot effectively learn complex degradation information, which subsequently hinders the model capacity. To solve the above problems, we propose a coarse-to-fine diffusion Transformer (C2F-DFT) for image restoration. Specifically, our C2F-DFT contains diffusion self-attention (DFSA) and diffusion feed-forward network (DFN) within a new coarse-to-fine training scheme. The DFSA and DFN respectively capture the long-range diffusion dependencies and learn hierarchy diffusion representation to facilitate better restoration. In the coarse training stage, our C2F-DFT estimates noises and then generates the final clean image by a sampling algorithm. To further improve the restoration quality, we propose a simple yet effective fine training scheme. It first exploits the coarse-trained diffusion model with fixed steps to generate restoration results, which then would be constrained with corresponding ground-truth ones to optimize the models to remedy the unsatisfactory results affected by inaccurate noise estimation. Extensive experiments show that C2F-DFT significantly outperforms diffusion-based restoration method IR-SDE and achieves competitive performance compared with Transformer-based state-of-the-art methods on $3$ tasks, including deraining, deblurring, and real denoising.
DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
Oct 11, 2023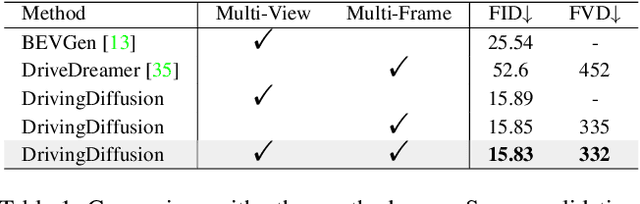
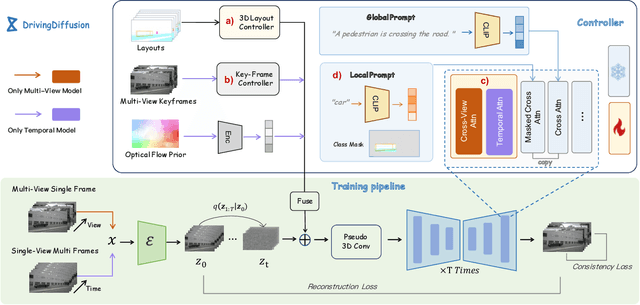
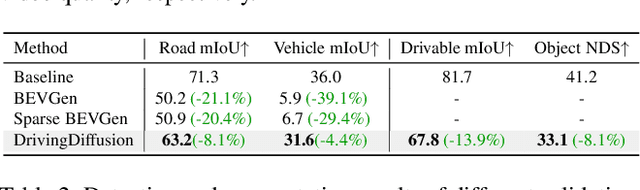
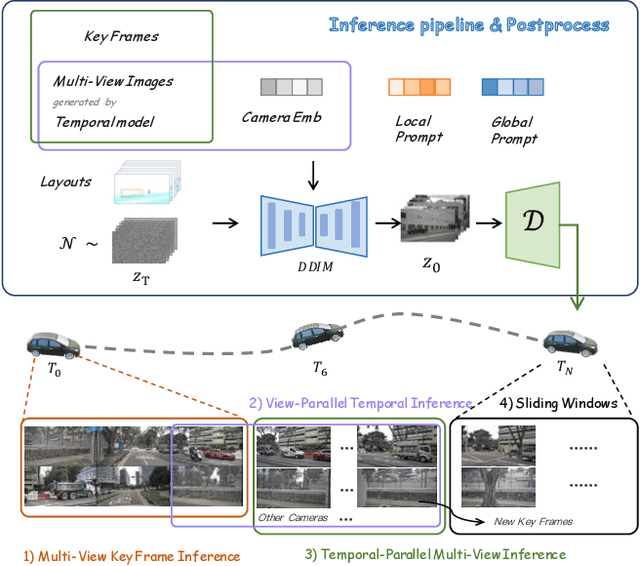
With the increasing popularity of autonomous driving based on the powerful and unified bird's-eye-view (BEV) representation, a demand for high-quality and large-scale multi-view video data with accurate annotation is urgently required. However, such large-scale multi-view data is hard to obtain due to expensive collection and annotation costs. To alleviate the problem, we propose a spatial-temporal consistent diffusion framework DrivingDiffusion, to generate realistic multi-view videos controlled by 3D layout. There are three challenges when synthesizing multi-view videos given a 3D layout: How to keep 1) cross-view consistency and 2) cross-frame consistency? 3) How to guarantee the quality of the generated instances? Our DrivingDiffusion solves the problem by cascading the multi-view single-frame image generation step, the single-view video generation step shared by multiple cameras, and post-processing that can handle long video generation. In the multi-view model, the consistency of multi-view images is ensured by information exchange between adjacent cameras. In the temporal model, we mainly query the information that needs attention in subsequent frame generation from the multi-view images of the first frame. We also introduce the local prompt to effectively improve the quality of generated instances. In post-processing, we further enhance the cross-view consistency of subsequent frames and extend the video length by employing temporal sliding window algorithm. Without any extra cost, our model can generate large-scale realistic multi-camera driving videos in complex urban scenes, fueling the downstream driving tasks. The code will be made publicly available.
Robust Unsupervised Domain Adaptation by Retaining Confident Entropy via Edge Concatenation
Oct 11, 2023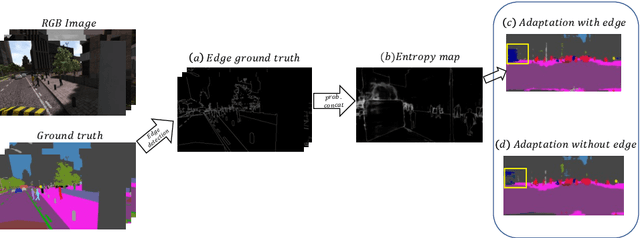
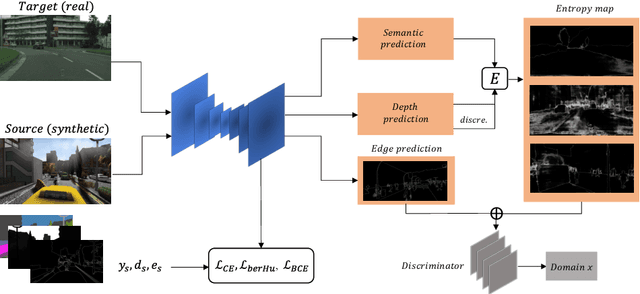
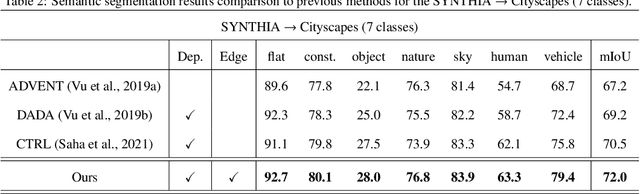

The generalization capability of unsupervised domain adaptation can mitigate the need for extensive pixel-level annotations to train semantic segmentation networks by training models on synthetic data as a source with computer-generated annotations. Entropy-based adversarial networks are proposed to improve source domain prediction; however, they disregard significant external information, such as edges, which have the potential to identify and distinguish various objects within an image accurately. To address this issue, we introduce a novel approach to domain adaptation, leveraging the synergy of internal and external information within entropy-based adversarial networks. In this approach, we enrich the discriminator network with edge-predicted probability values within this innovative framework to enhance the clarity of class boundaries. Furthermore, we devised a probability-sharing network that integrates diverse information for more effective segmentation. Incorporating object edges addresses a pivotal aspect of unsupervised domain adaptation that has frequently been neglected in the past -- the precise delineation of object boundaries. Conventional unsupervised domain adaptation methods usually center around aligning feature distributions and may not explicitly model object boundaries. Our approach effectively bridges this gap by offering clear guidance on object boundaries, thereby elevating the quality of domain adaptation. Our approach undergoes rigorous evaluation on the established unsupervised domain adaptation benchmarks, specifically in adapting SYNTHIA $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Mapillary. Experimental results show that the proposed model attains better performance than state-of-the-art methods. The superior performance across different unsupervised domain adaptation scenarios highlights the versatility and robustness of the proposed method.
Underwater Image Enhancement by Transformer-based Diffusion Model with Non-uniform Sampling for Skip Strategy
Sep 07, 2023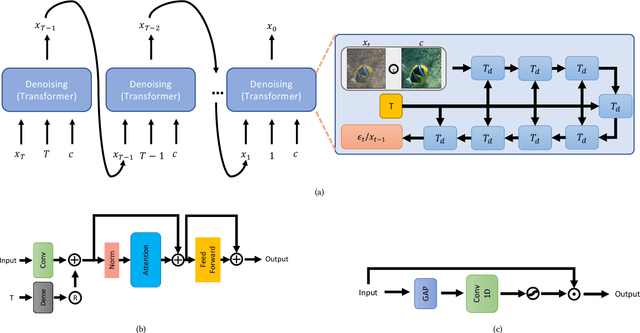
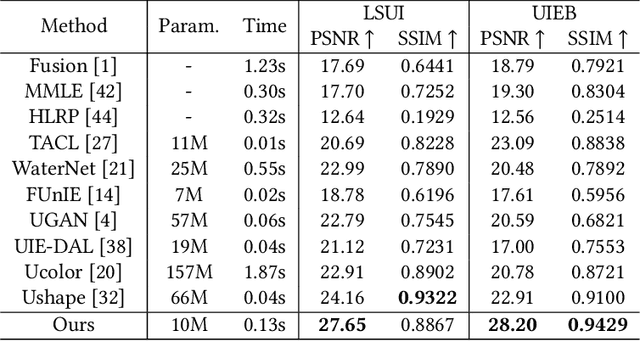
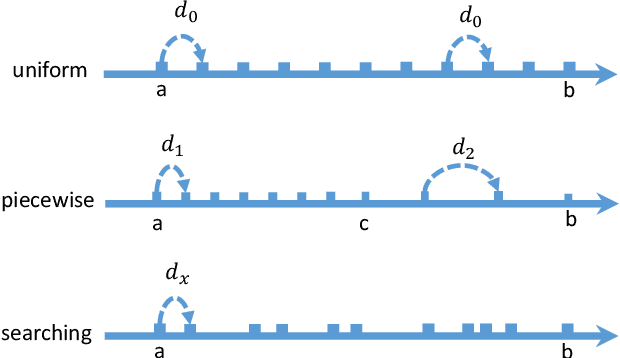
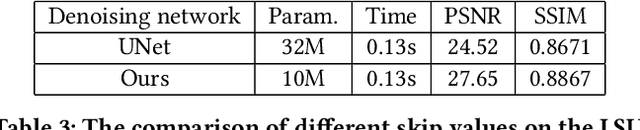
In this paper, we present an approach to image enhancement with diffusion model in underwater scenes. Our method adapts conditional denoising diffusion probabilistic models to generate the corresponding enhanced images by using the underwater images and the Gaussian noise as the inputs. Additionally, in order to improve the efficiency of the reverse process in the diffusion model, we adopt two different ways. We firstly propose a lightweight transformer-based denoising network, which can effectively promote the time of network forward per iteration. On the other hand, we introduce a skip sampling strategy to reduce the number of iterations. Besides, based on the skip sampling strategy, we propose two different non-uniform sampling methods for the sequence of the time step, namely piecewise sampling and searching with the evolutionary algorithm. Both of them are effective and can further improve performance by using the same steps against the previous uniform sampling. In the end, we conduct a relative evaluation of the widely used underwater enhancement datasets between the recent state-of-the-art methods and the proposed approach. The experimental results prove that our approach can achieve both competitive performance and high efficiency. Our code is available at \href{mailto:https://github.com/piggy2009/DM_underwater}{\color{blue}{https://github.com/piggy2009/DM\_underwater}}.
Enabling Neural Radiance Fields (NeRF) for Large-scale Aerial Images -- A Multi-tiling Approaching and the Geometry Assessment of NeRF
Oct 01, 2023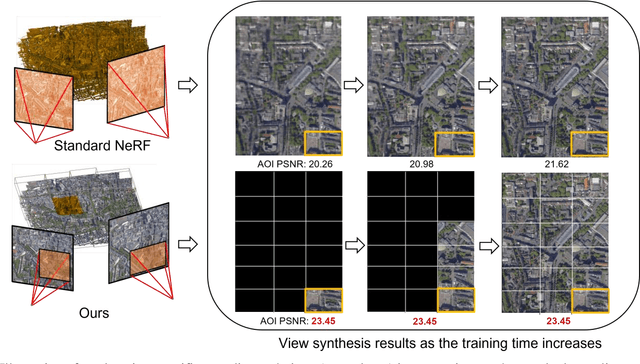

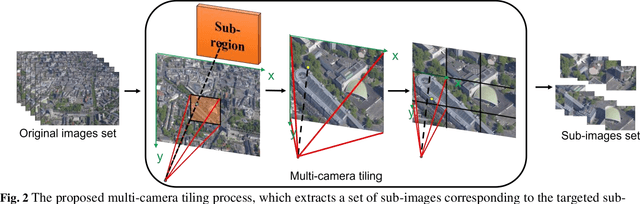

Neural Radiance Fields (NeRF) offer the potential to benefit 3D reconstruction tasks, including aerial photogrammetry. However, the scalability and accuracy of the inferred geometry are not well-documented for large-scale aerial assets,since such datasets usually result in very high memory consumption and slow convergence.. In this paper, we aim to scale the NeRF on large-scael aerial datasets and provide a thorough geometry assessment of NeRF. Specifically, we introduce a location-specific sampling technique as well as a multi-camera tiling (MCT) strategy to reduce memory consumption during image loading for RAM, representation training for GPU memory, and increase the convergence rate within tiles. MCT decomposes a large-frame image into multiple tiled images with different camera models, allowing these small-frame images to be fed into the training process as needed for specific locations without a loss of accuracy. We implement our method on a representative approach, Mip-NeRF, and compare its geometry performance with threephotgrammetric MVS pipelines on two typical aerial datasets against LiDAR reference data. Both qualitative and quantitative results suggest that the proposed NeRF approach produces better completeness and object details than traditional approaches, although as of now, it still falls short in terms of accuracy.
Transformer Fusion with Optimal Transport
Oct 09, 2023
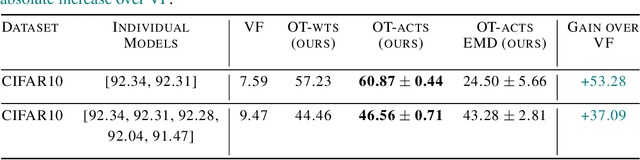
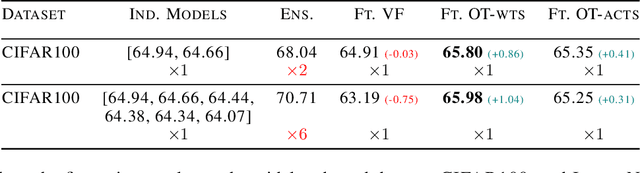
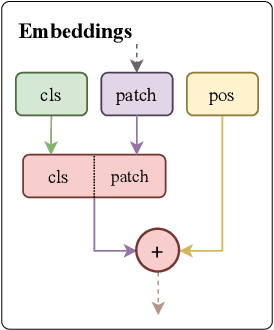
Fusion is a technique for merging multiple independently-trained neural networks in order to combine their capabilities. Past attempts have been restricted to the case of fully-connected, convolutional, and residual networks. In this paper, we present a systematic approach for fusing two or more transformer-based networks exploiting Optimal Transport to (soft-)align the various architectural components. We flesh out an abstraction for layer alignment, that can generalize to arbitrary architectures -- in principle -- and we apply this to the key ingredients of Transformers such as multi-head self-attention, layer-normalization, and residual connections, and we discuss how to handle them via various ablation studies. Furthermore, our method allows the fusion of models of different sizes (heterogeneous fusion), providing a new and efficient way for compression of Transformers. The proposed approach is evaluated on both image classification tasks via Vision Transformer and natural language modeling tasks using BERT. Our approach consistently outperforms vanilla fusion, and, after a surprisingly short finetuning, also outperforms the individual converged parent models. In our analysis, we uncover intriguing insights about the significant role of soft alignment in the case of Transformers. Our results showcase the potential of fusing multiple Transformers, thus compounding their expertise, in the budding paradigm of model fusion and recombination.
FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing
Oct 09, 2023
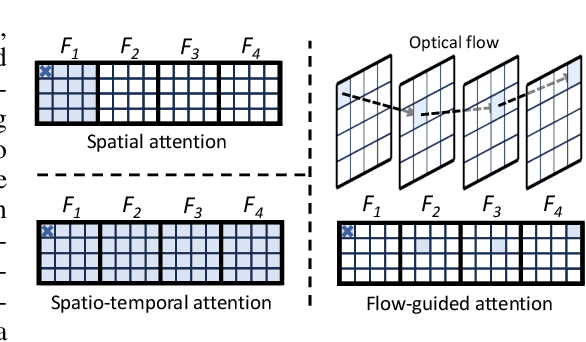


Text-to-video editing aims to edit the visual appearance of a source video conditional on textual prompts. A major challenge in this task is to ensure that all frames in the edited video are visually consistent. Most recent works apply advanced text-to-image diffusion models to this task by inflating 2D spatial attention in the U-Net into spatio-temporal attention. Although temporal context can be added through spatio-temporal attention, it may introduce some irrelevant information for each patch and therefore cause inconsistency in the edited video. In this paper, for the first time, we introduce optical flow into the attention module in the diffusion model's U-Net to address the inconsistency issue for text-to-video editing. Our method, FLATTEN, enforces the patches on the same flow path across different frames to attend to each other in the attention module, thus improving the visual consistency in the edited videos. Additionally, our method is training-free and can be seamlessly integrated into any diffusion-based text-to-video editing methods and improve their visual consistency. Experiment results on existing text-to-video editing benchmarks show that our proposed method achieves the new state-of-the-art performance. In particular, our method excels in maintaining the visual consistency in the edited videos.
Latent Diffusion Model for DNA Sequence Generation
Oct 09, 2023The harnessing of machine learning, especially deep generative models, has opened up promising avenues in the field of synthetic DNA sequence generation. Whilst Generative Adversarial Networks (GANs) have gained traction for this application, they often face issues such as limited sample diversity and mode collapse. On the other hand, Diffusion Models are a promising new class of generative models that are not burdened with these problems, enabling them to reach the state-of-the-art in domains such as image generation. In light of this, we propose a novel latent diffusion model, DiscDiff, tailored for discrete DNA sequence generation. By simply embedding discrete DNA sequences into a continuous latent space using an autoencoder, we are able to leverage the powerful generative abilities of continuous diffusion models for the generation of discrete data. Additionally, we introduce Fr\'echet Reconstruction Distance (FReD) as a new metric to measure the sample quality of DNA sequence generations. Our DiscDiff model demonstrates an ability to generate synthetic DNA sequences that align closely with real DNA in terms of Motif Distribution, Latent Embedding Distribution (FReD), and Chromatin Profiles. Additionally, we contribute a comprehensive cross-species dataset of 150K unique promoter-gene sequences from 15 species, enriching resources for future generative modelling in genomics. We will make our code public upon publication.
Making Scalable Meta Learning Practical
Oct 09, 2023Despite its flexibility to learn diverse inductive biases in machine learning programs, meta learning (i.e., learning to learn) has long been recognized to suffer from poor scalability due to its tremendous compute/memory costs, training instability, and a lack of efficient distributed training support. In this work, we focus on making scalable meta learning practical by introducing SAMA, which combines advances in both implicit differentiation algorithms and systems. Specifically, SAMA is designed to flexibly support a broad range of adaptive optimizers in the base level of meta learning programs, while reducing computational burden by avoiding explicit computation of second-order gradient information, and exploiting efficient distributed training techniques implemented for first-order gradients. Evaluated on multiple large-scale meta learning benchmarks, SAMA showcases up to 1.7/4.8x increase in throughput and 2.0/3.8x decrease in memory consumption respectively on single-/multi-GPU setups compared to other baseline meta learning algorithms. Furthermore, we show that SAMA-based data optimization leads to consistent improvements in text classification accuracy with BERT and RoBERTa large language models, and achieves state-of-the-art results in both small- and large-scale data pruning on image classification tasks, demonstrating the practical applicability of scalable meta learning across language and vision domains.
Attention-Guided Lidar Segmentation and Odometry Using Image-to-Point Cloud Saliency Transfer
Aug 28, 2023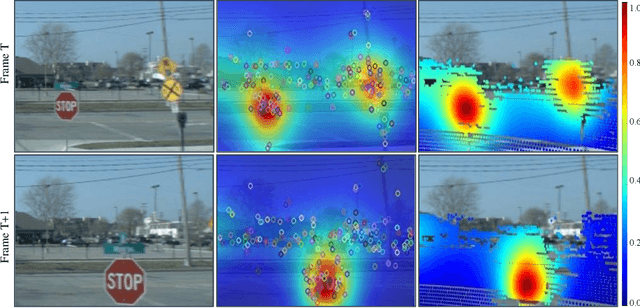

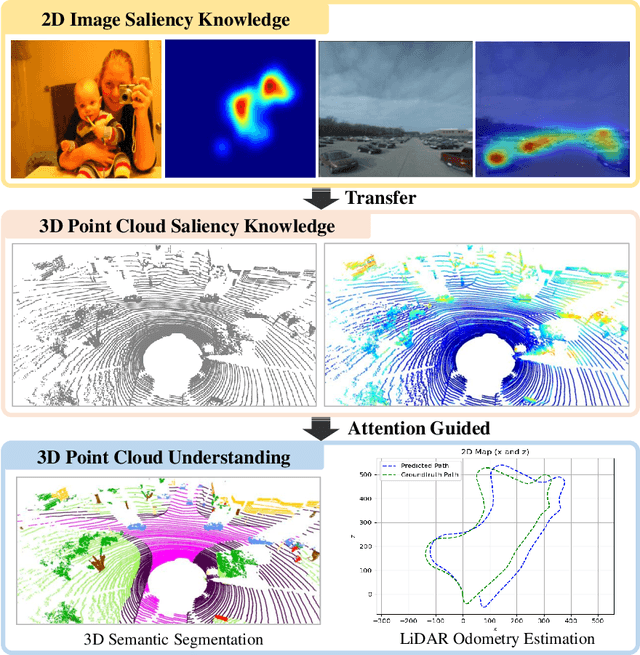
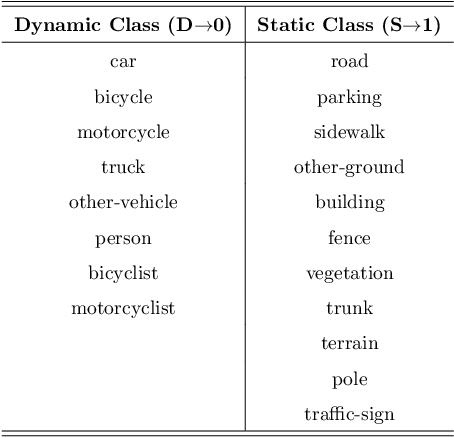
LiDAR odometry estimation and 3D semantic segmentation are crucial for autonomous driving, which has achieved remarkable advances recently. However, these tasks are challenging due to the imbalance of points in different semantic categories for 3D semantic segmentation and the influence of dynamic objects for LiDAR odometry estimation, which increases the importance of using representative/salient landmarks as reference points for robust feature learning. To address these challenges, we propose a saliency-guided approach that leverages attention information to improve the performance of LiDAR odometry estimation and semantic segmentation models. Unlike in the image domain, only a few studies have addressed point cloud saliency information due to the lack of annotated training data. To alleviate this, we first present a universal framework to transfer saliency distribution knowledge from color images to point clouds, and use this to construct a pseudo-saliency dataset (i.e. FordSaliency) for point clouds. Then, we adopt point cloud-based backbones to learn saliency distribution from pseudo-saliency labels, which is followed by our proposed SalLiDAR module. SalLiDAR is a saliency-guided 3D semantic segmentation model that integrates saliency information to improve segmentation performance. Finally, we introduce SalLONet, a self-supervised saliency-guided LiDAR odometry network that uses the semantic and saliency predictions of SalLiDAR to achieve better odometry estimation. Our extensive experiments on benchmark datasets demonstrate that the proposed SalLiDAR and SalLONet models achieve state-of-the-art performance against existing methods, highlighting the effectiveness of image-to-LiDAR saliency knowledge transfer. Source code will be available at https://github.com/nevrez/SalLONet.