 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
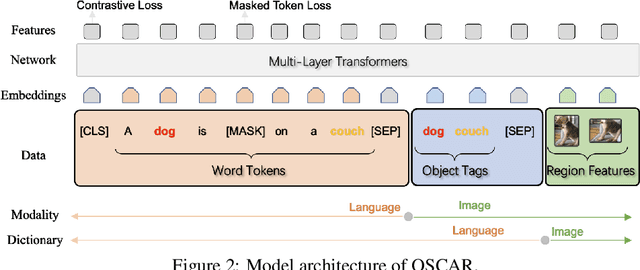
DOMINO: A Dual-System for Multi-step Visual Language Reasoning
Oct 04, 2023
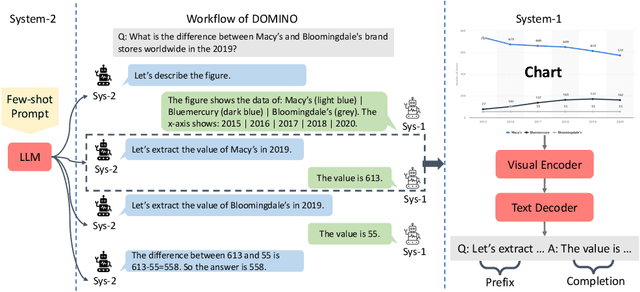
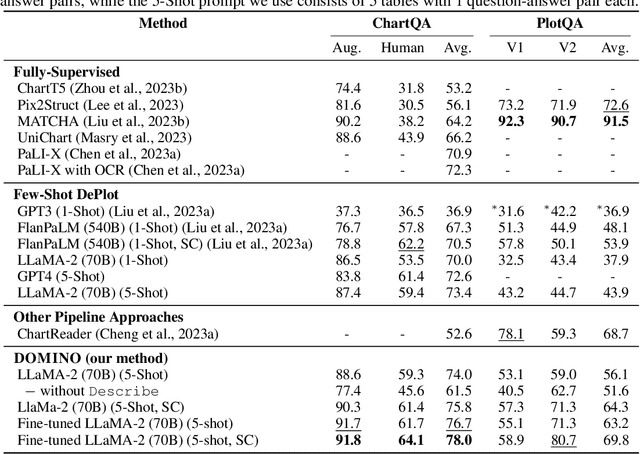
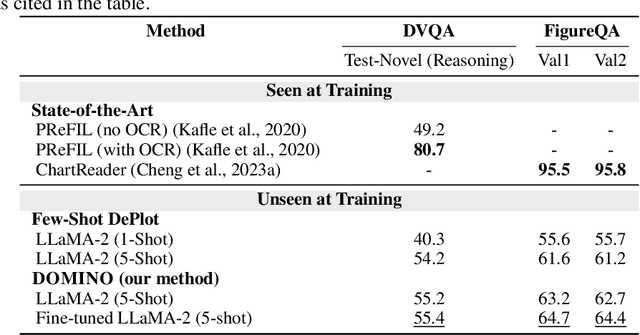
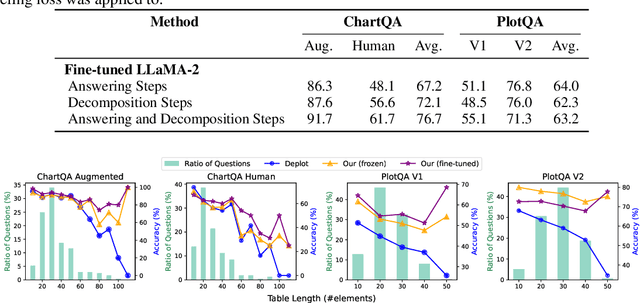
Visual language reasoning requires a system to extract text or numbers from information-dense images like charts or plots and perform logical or arithmetic reasoning to arrive at an answer. To tackle this task, existing work relies on either (1) an end-to-end vision-language model trained on a large amount of data, or (2) a two-stage pipeline where a captioning model converts the image into text that is further read by another large language model to deduce the answer. However, the former approach forces the model to answer a complex question with one single step, and the latter approach is prone to inaccurate or distracting information in the converted text that can confuse the language model. In this work, we propose a dual-system for multi-step multimodal reasoning, which consists of a "System-1" step for visual information extraction and a "System-2" step for deliberate reasoning. Given an input, System-2 breaks down the question into atomic sub-steps, each guiding System-1 to extract the information required for reasoning from the image. Experiments on chart and plot datasets show that our method with a pre-trained System-2 module performs competitively compared to prior work on in- and out-of-distribution data. By fine-tuning the System-2 module (LLaMA-2 70B) on only a small amount of data on multi-step reasoning, the accuracy of our method is further improved and surpasses the best fully-supervised end-to-end approach by 5.7% and a pipeline approach with FlanPaLM (540B) by 7.5% on a challenging dataset with human-authored questions.
Learning A Coarse-to-Fine Diffusion Transformer for Image Restoration
Aug 17, 2023

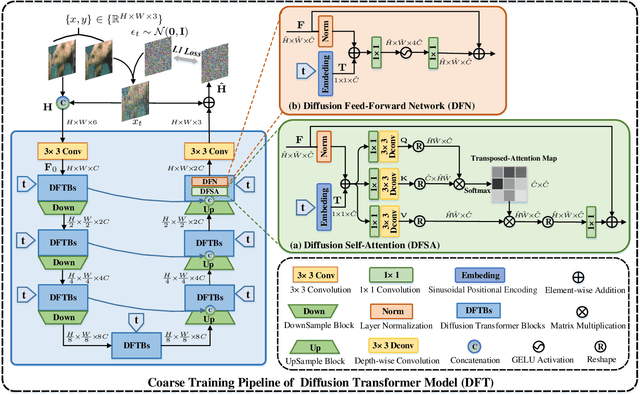
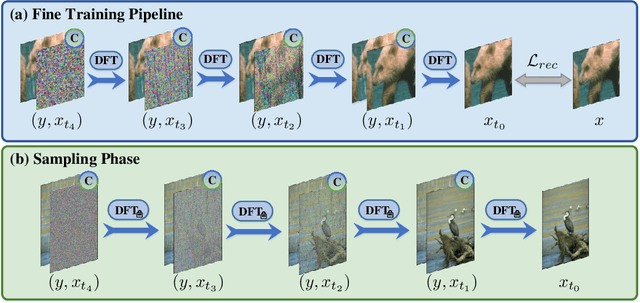
Recent years have witnessed the remarkable performance of diffusion models in various vision tasks. However, for image restoration that aims to recover clear images with sharper details from given degraded observations, diffusion-based methods may fail to recover promising results due to inaccurate noise estimation. Moreover, simple constraining noises cannot effectively learn complex degradation information, which subsequently hinders the model capacity. To solve the above problems, we propose a coarse-to-fine diffusion Transformer (C2F-DFT) for image restoration. Specifically, our C2F-DFT contains diffusion self-attention (DFSA) and diffusion feed-forward network (DFN) within a new coarse-to-fine training scheme. The DFSA and DFN respectively capture the long-range diffusion dependencies and learn hierarchy diffusion representation to facilitate better restoration. In the coarse training stage, our C2F-DFT estimates noises and then generates the final clean image by a sampling algorithm. To further improve the restoration quality, we propose a simple yet effective fine training scheme. It first exploits the coarse-trained diffusion model with fixed steps to generate restoration results, which then would be constrained with corresponding ground-truth ones to optimize the models to remedy the unsatisfactory results affected by inaccurate noise estimation. Extensive experiments show that C2F-DFT significantly outperforms diffusion-based restoration method IR-SDE and achieves competitive performance compared with Transformer-based state-of-the-art methods on $3$ tasks, including deraining, deblurring, and real denoising.
On the Cognition of Visual Question Answering Models and Human Intelligence: A Comparative Study
Oct 04, 2023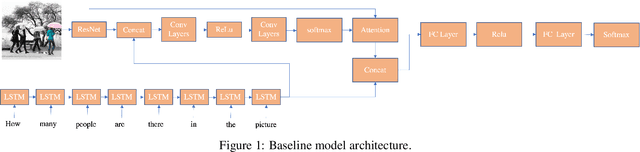
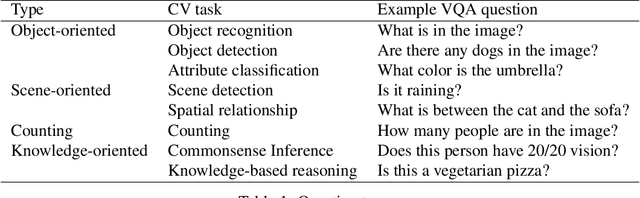

Visual Question Answering (VQA) is a challenging task that requires cross-modal understanding and reasoning of visual image and natural language question. To inspect the association of VQA models to human cognition, we designed a survey to record human thinking process and analyzed VQA models by comparing the outputs and attention maps with those of humans. We found that although the VQA models resemble human cognition in architecture and performs similarly with human on the recognition-level, they still struggle with cognitive inferences. The analysis of human thinking procedure serves to direct future research and introduce more cognitive capacity into modeling features and architectures.
Self-supervised Domain-agnostic Domain Adaptation for Satellite Images
Sep 20, 2023
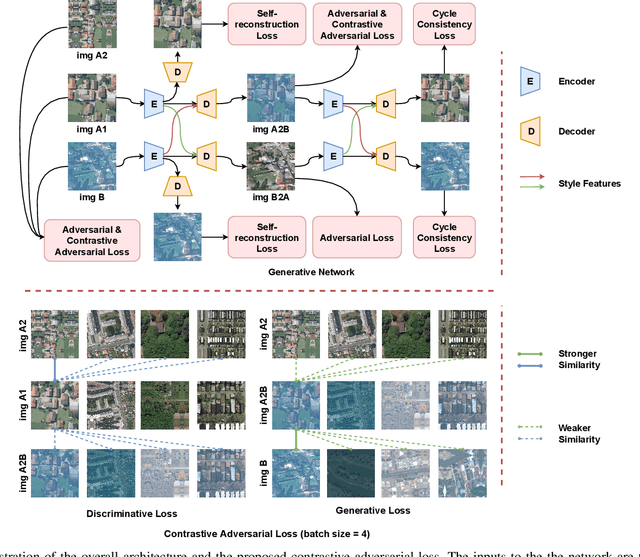

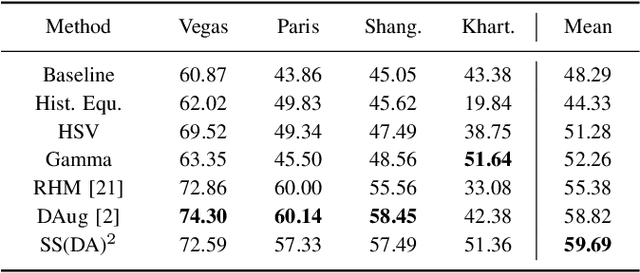
Domain shift caused by, e.g., different geographical regions or acquisition conditions is a common issue in machine learning for global scale satellite image processing. A promising method to address this problem is domain adaptation, where the training and the testing datasets are split into two or multiple domains according to their distributions, and an adaptation method is applied to improve the generalizability of the model on the testing dataset. However, defining the domain to which each satellite image belongs is not trivial, especially under large-scale multi-temporal and multi-sensory scenarios, where a single image mosaic could be generated from multiple data sources. In this paper, we propose an self-supervised domain-agnostic domain adaptation (SS(DA)2) method to perform domain adaptation without such a domain definition. To achieve this, we first design a contrastive generative adversarial loss to train a generative network to perform image-to-image translation between any two satellite image patches. Then, we improve the generalizability of the downstream models by augmenting the training data with different testing spectral characteristics. The experimental results on public benchmarks verify the effectiveness of SS(DA)2.
LIPEx -- Locally Interpretable Probabilistic Explanations -- To Look Beyond The True Class
Oct 07, 2023In this work, we instantiate a novel perturbation-based multi-class explanation framework, LIPEx (Locally Interpretable Probabilistic Explanation). We demonstrate that LIPEx not only locally replicates the probability distributions output by the widely used complex classification models but also provides insight into how every feature deemed to be important affects the prediction probability for each of the possible classes. We achieve this by defining the explanation as a matrix obtained via regression with respect to the Hellinger distance in the space of probability distributions. Ablation tests on text and image data, show that LIPEx-guided removal of important features from the data causes more change in predictions for the underlying model than similar tests on other saliency-based or feature importance-based XAI methods. It is also shown that compared to LIME, LIPEx is much more data efficient in terms of the number of perturbations needed for reliable evaluation of the explanation.
RetSeg: Retention-based Colorectal Polyps Segmentation Network
Oct 10, 2023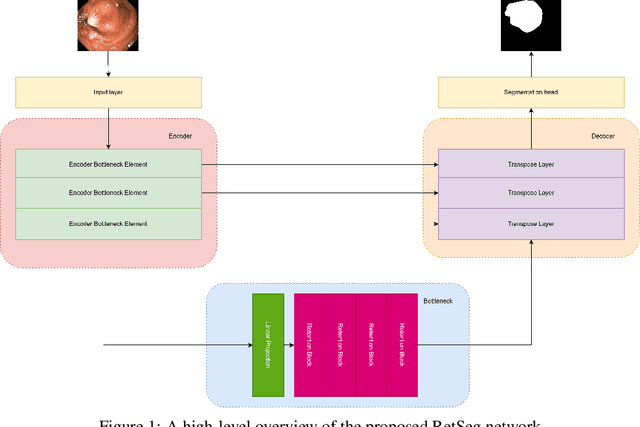
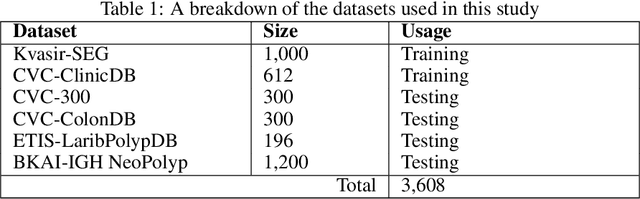
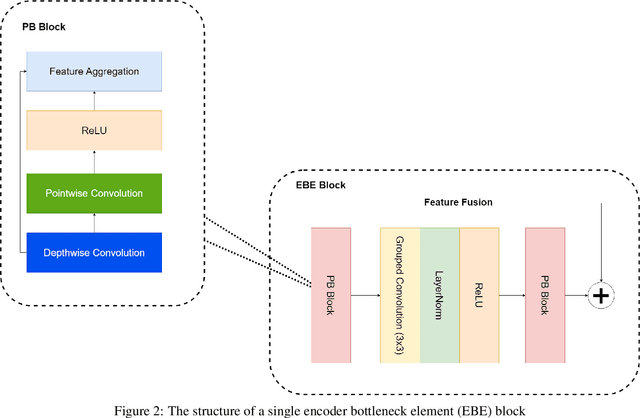
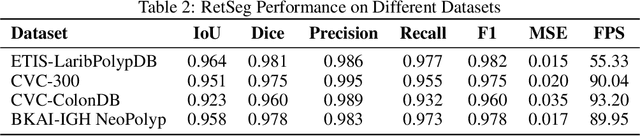
Vision Transformers (ViTs) have revolutionized medical imaging analysis, showcasing superior efficacy compared to conventional Convolutional Neural Networks (CNNs) in vital tasks such as polyp classification, detection, and segmentation. Leveraging attention mechanisms to focus on specific image regions, ViTs exhibit contextual awareness in processing visual data, culminating in robust and precise predictions, even for intricate medical images. Moreover, the inherent self-attention mechanism in Transformers accommodates varying input sizes and resolutions, granting an unprecedented flexibility absent in traditional CNNs. However, Transformers grapple with challenges like excessive memory usage and limited training parallelism due to self-attention, rendering them impractical for real-time disease detection on resource-constrained devices. In this study, we address these hurdles by investigating the integration of the recently introduced retention mechanism into polyp segmentation, introducing RetSeg, an encoder-decoder network featuring multi-head retention blocks. Drawing inspiration from Retentive Networks (RetNet), RetSeg is designed to bridge the gap between precise polyp segmentation and resource utilization, particularly tailored for colonoscopy images. We train and validate RetSeg for polyp segmentation employing two publicly available datasets: Kvasir-SEG and CVC-ClinicDB. Additionally, we showcase RetSeg's promising performance across diverse public datasets, including CVC-ColonDB, ETIS-LaribPolypDB, CVC-300, and BKAI-IGH NeoPolyp. While our work represents an early-stage exploration, further in-depth studies are imperative to advance these promising findings.
Efficient Adaptation of Large Vision Transformer via Adapter Re-Composing
Oct 10, 2023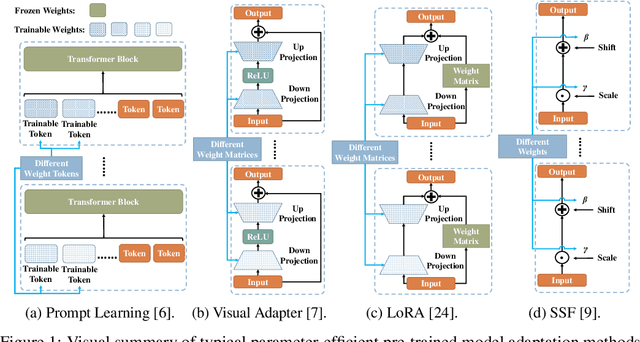
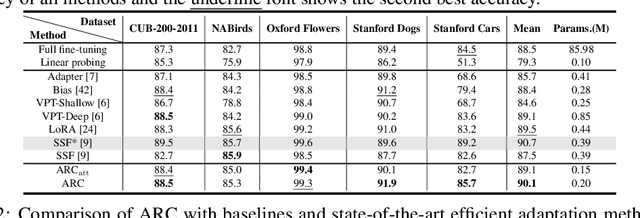
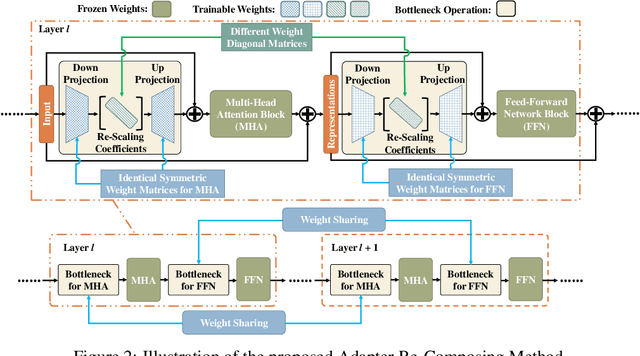
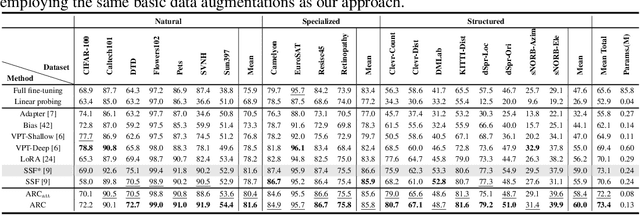
The advent of high-capacity pre-trained models has revolutionized problem-solving in computer vision, shifting the focus from training task-specific models to adapting pre-trained models. Consequently, effectively adapting large pre-trained models to downstream tasks in an efficient manner has become a prominent research area. Existing solutions primarily concentrate on designing lightweight adapters and their interaction with pre-trained models, with the goal of minimizing the number of parameters requiring updates. In this study, we propose a novel Adapter Re-Composing (ARC) strategy that addresses efficient pre-trained model adaptation from a fresh perspective. Our approach considers the reusability of adaptation parameters and introduces a parameter-sharing scheme. Specifically, we leverage symmetric down-/up-projections to construct bottleneck operations, which are shared across layers. By learning low-dimensional re-scaling coefficients, we can effectively re-compose layer-adaptive adapters. This parameter-sharing strategy in adapter design allows us to significantly reduce the number of new parameters while maintaining satisfactory performance, thereby offering a promising approach to compress the adaptation cost. We conduct experiments on 24 downstream image classification tasks using various Vision Transformer variants to evaluate our method. The results demonstrate that our approach achieves compelling transfer learning performance with a reduced parameter count. Our code is available at \href{https://github.com/DavidYanAnDe/ARC}{https://github.com/DavidYanAnDe/ARC}.
Multispectral Imaging with Fresnel Lens
Oct 05, 2023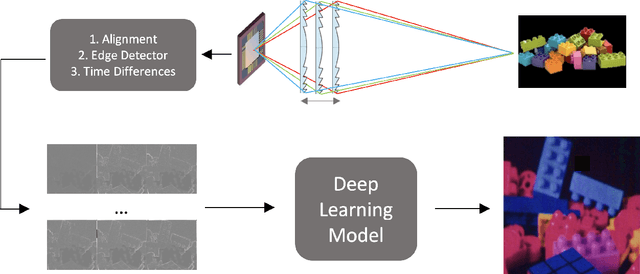

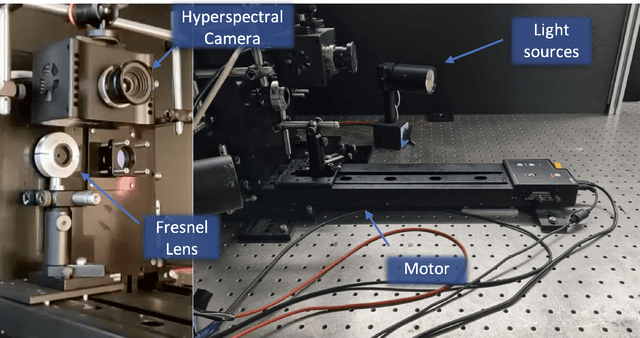

This paper presents a Multispectral imaging (MSI) approach that combines the use of a diffractive optical element, and a deep learning algorithm for spectral reconstruction. Traditional MSI techniques often face challenges such as high costs, compromised spatial or spectral resolution, or prolonged acquisition times. In contrast, our methodology uses a single diffractive lens, a grayscale sensor, and an optical motor to capture the Multispectral image without sacrificing spatial resolution, however with some temporal domain redundancy. Through an experimental demonstration, we show how we can reconstruct up to 50 spectral channel images using diffraction physical theory and a UNet-based deep learning algorithm. This approach holds promise for a cost-effective, compact MSI camera that could be feasibly integrated into mobile devices.
Efficient Anatomical Labeling of Pulmonary Tree Structures via Implicit Point-Graph Networks
Oct 05, 2023Pulmonary diseases rank prominently among the principal causes of death worldwide. Curing them will require, among other things, a better understanding of the many complex 3D tree-shaped structures within the pulmonary system, such as airways, arteries, and veins. In theory, they can be modeled using high-resolution image stacks. Unfortunately, standard CNN approaches operating on dense voxel grids are prohibitively expensive. To remedy this, we introduce a point-based approach that preserves graph connectivity of tree skeleton and incorporates an implicit surface representation. It delivers SOTA accuracy at a low computational cost and the resulting models have usable surfaces. Due to the scarcity of publicly accessible data, we have also curated an extensive dataset to evaluate our approach and will make it public.
DiffPrompter: Differentiable Implicit Visual Prompts for Semantic-Segmentation in Adverse Conditions
Oct 06, 2023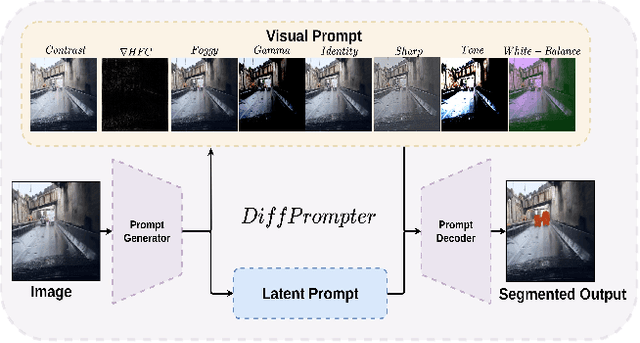
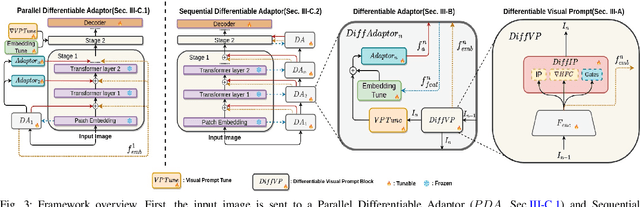
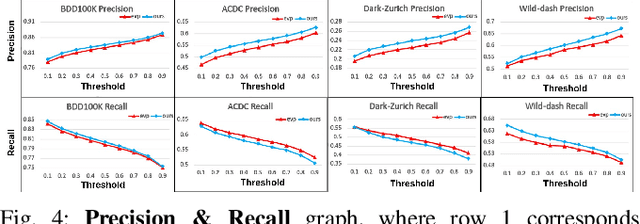

Semantic segmentation in adverse weather scenarios is a critical task for autonomous driving systems. While foundation models have shown promise, the need for specialized adaptors becomes evident for handling more challenging scenarios. We introduce DiffPrompter, a novel differentiable visual and latent prompting mechanism aimed at expanding the learning capabilities of existing adaptors in foundation models. Our proposed $\nabla$HFC image processing block excels particularly in adverse weather conditions, where conventional methods often fall short. Furthermore, we investigate the advantages of jointly training visual and latent prompts, demonstrating that this combined approach significantly enhances performance in out-of-distribution scenarios. Our differentiable visual prompts leverage parallel and series architectures to generate prompts, effectively improving object segmentation tasks in adverse conditions. Through a comprehensive series of experiments and evaluations, we provide empirical evidence to support the efficacy of our approach. Project page at https://diffprompter.github.io.