 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CWCL: Cross-Modal Transfer with Continuously Weighted Contrastive Loss
Sep 26, 2023
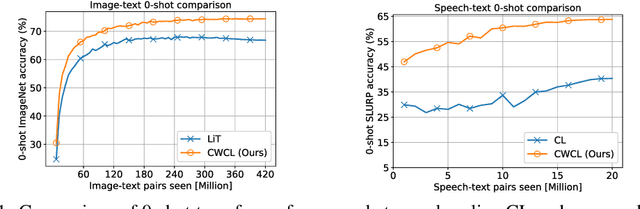
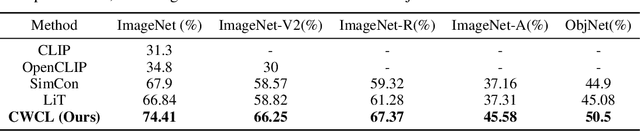
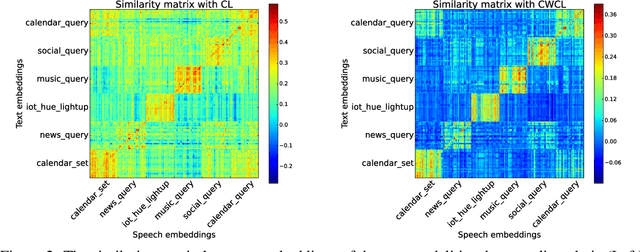

This paper considers contrastive training for cross-modal 0-shot transfer wherein a pre-trained model in one modality is used for representation learning in another domain using pairwise data. The learnt models in the latter domain can then be used for a diverse set of tasks in a zero-shot way, similar to ``Contrastive Language-Image Pre-training (CLIP)'' and ``Locked-image Tuning (LiT)'' that have recently gained considerable attention. Most existing works for cross-modal representation alignment (including CLIP and LiT) use the standard contrastive training objective, which employs sets of positive and negative examples to align similar and repel dissimilar training data samples. However, similarity amongst training examples has a more continuous nature, thus calling for a more `non-binary' treatment. To address this, we propose a novel loss function called Continuously Weighted Contrastive Loss (CWCL) that employs a continuous measure of similarity. With CWCL, we seek to align the embedding space of one modality with another. Owing to the continuous nature of similarity in the proposed loss function, these models outperform existing methods for 0-shot transfer across multiple models, datasets and modalities. Particularly, we consider the modality pairs of image-text and speech-text and our models achieve 5-8% (absolute) improvement over previous state-of-the-art methods in 0-shot image classification and 20-30% (absolute) improvement in 0-shot speech-to-intent classification and keyword classification.
PriViT: Vision Transformers for Fast Private Inference
Oct 06, 2023The Vision Transformer (ViT) architecture has emerged as the backbone of choice for state-of-the-art deep models for computer vision applications. However, ViTs are ill-suited for private inference using secure multi-party computation (MPC) protocols, due to the large number of non-polynomial operations (self-attention, feed-forward rectifiers, layer normalization). We propose PriViT, a gradient based algorithm to selectively "Taylorize" nonlinearities in ViTs while maintaining their prediction accuracy. Our algorithm is conceptually simple, easy to implement, and achieves improved performance over existing approaches for designing MPC-friendly transformer architectures in terms of achieving the Pareto frontier in latency-accuracy. We confirm these improvements via experiments on several standard image classification tasks. Public code is available at https://github.com/NYU-DICE-Lab/privit.
Tight Certified Robustness via Min-Max Representations of ReLU Neural Networks
Oct 07, 2023The reliable deployment of neural networks in control systems requires rigorous robustness guarantees. In this paper, we obtain tight robustness certificates over convex attack sets for min-max representations of ReLU neural networks by developing a convex reformulation of the nonconvex certification problem. This is done by "lifting" the problem to an infinite-dimensional optimization over probability measures, leveraging recent results in distributionally robust optimization to solve for an optimal discrete distribution, and proving that solutions of the original nonconvex problem are generated by the discrete distribution under mild boundedness, nonredundancy, and Slater conditions. As a consequence, optimal (worst-case) attacks against the model may be solved for exactly. This contrasts prior state-of-the-art that either requires expensive branch-and-bound schemes or loose relaxation techniques. Experiments on robust control and MNIST image classification examples highlight the benefits of our approach.
Uncertainty Quantification for Eosinophil Segmentation
Sep 28, 2023Eosinophilic Esophagitis (EoE) is an allergic condition increasing in prevalence. To diagnose EoE, pathologists must find 15 or more eosinophils within a single high-power field (400X magnification). Determining whether or not a patient has EoE can be an arduous process and any medical imaging approaches used to assist diagnosis must consider both efficiency and precision. We propose an improvement of Adorno et al's approach for quantifying eosinphils using deep image segmentation. Our new approach leverages Monte Carlo Dropout, a common approach in deep learning to reduce overfitting, to provide uncertainty quantification on current deep learning models. The uncertainty can be visualized in an output image to evaluate model performance, provide insight to how deep learning algorithms function, and assist pathologists in identifying eosinophils.
Logarithm-transform aided Gaussian Sampling for Few-Shot Learning
Sep 28, 2023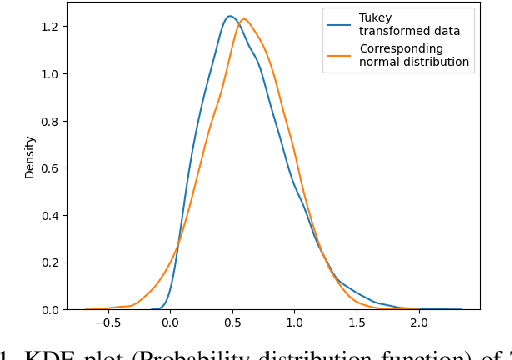
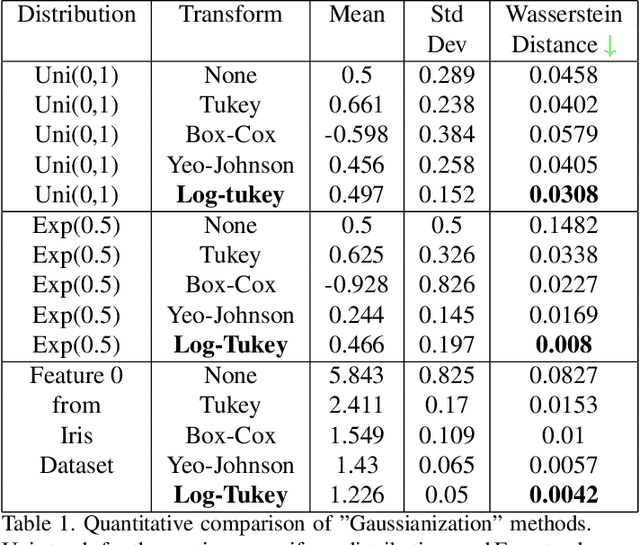
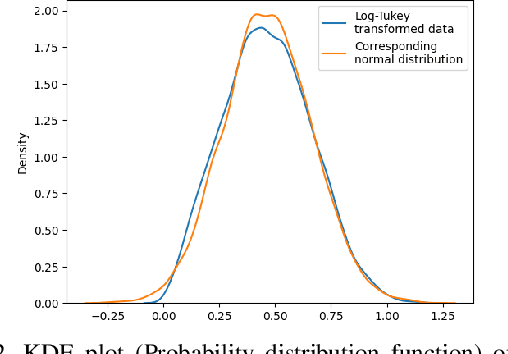
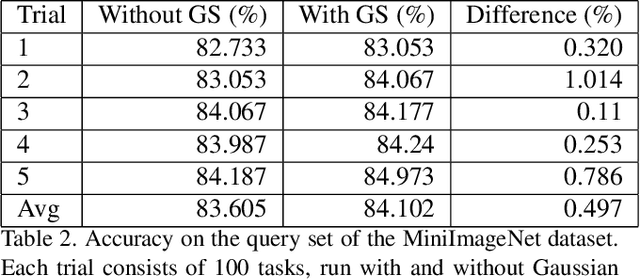
Few-shot image classification has recently witnessed the rise of representation learning being utilised for models to adapt to new classes using only a few training examples. Therefore, the properties of the representations, such as their underlying probability distributions, assume vital importance. Representations sampled from Gaussian distributions have been used in recent works, [19] to train classifiers for few-shot classification. These methods rely on transforming the distributions of experimental data to approximate Gaussian distributions for their functioning. In this paper, I propose a novel Gaussian transform, that outperforms existing methods on transforming experimental data into Gaussian-like distributions. I then utilise this novel transformation for few-shot image classification and show significant gains in performance, while sampling lesser data.
Bridge Diffusion Model: bridge non-English language-native text-to-image diffusion model with English communities
Sep 02, 2023Text-to-Image generation (TTI) technologies are advancing rapidly, especially in the English language communities. However, English-native TTI models inherently carry biases from English world centric training data, which creates a dilemma for development of other language-native TTI models. One common choice is fine-tuning the English-native TTI model with translated samples from non-English communities. It falls short of fully addressing the model bias problem. Alternatively, training non-English language native models from scratch can effectively resolve the English world bias, but diverges from the English TTI communities, thus not able to utilize the strides continuously gaining in the English TTI communities any more. To build non-English language native TTI model meanwhile keep compatability with the English TTI communities, we propose a novel model structure referred as "Bridge Diffusion Model" (BDM). The proposed BDM employs a backbone-branch network structure to learn the non-English language semantics while keep the latent space compatible with the English-native TTI backbone, in an end-to-end manner. The unique advantages of the proposed BDM are that it's not only adept at generating images that precisely depict non-English language semantics, but also compatible with various English-native TTI plugins, such as different checkpoints, LoRA, ControlNet, Dreambooth, and Textual Inversion, etc. Moreover, BDM can concurrently generate content seamlessly combining both non-English native and English-native semantics within a single image, fostering cultural interaction. We verify our method by applying BDM to build a Chinese-native TTI model, whereas the method is generic and applicable to any other language.
Open-Set Knowledge-Based Visual Question Answering with Inference Paths
Oct 12, 2023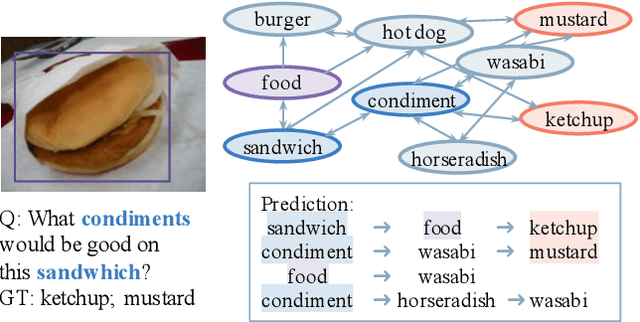
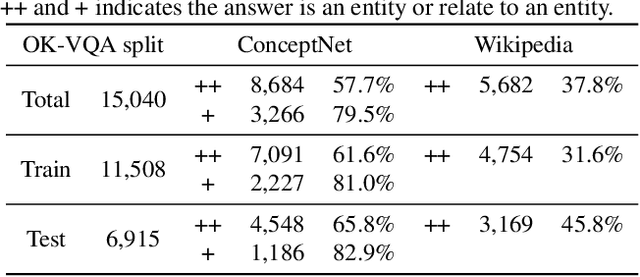
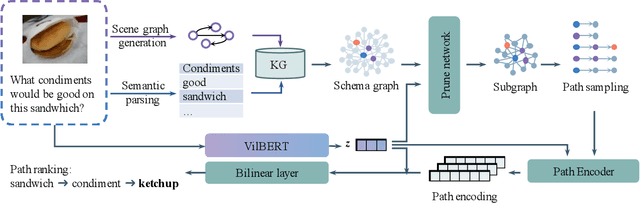
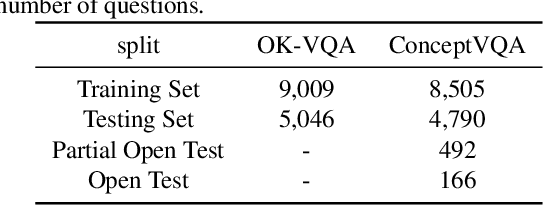
Given an image and an associated textual question, the purpose of Knowledge-Based Visual Question Answering (KB-VQA) is to provide a correct answer to the question with the aid of external knowledge bases. Prior KB-VQA models are usually formulated as a retriever-classifier framework, where a pre-trained retriever extracts textual or visual information from knowledge graphs and then makes a prediction among the candidates. Despite promising progress, there are two drawbacks with existing models. Firstly, modeling question-answering as multi-class classification limits the answer space to a preset corpus and lacks the ability of flexible reasoning. Secondly, the classifier merely consider "what is the answer" without "how to get the answer", which cannot ground the answer to explicit reasoning paths. In this paper, we confront the challenge of \emph{explainable open-set} KB-VQA, where the system is required to answer questions with entities at wild and retain an explainable reasoning path. To resolve the aforementioned issues, we propose a new retriever-ranker paradigm of KB-VQA, Graph pATH rankER (GATHER for brevity). Specifically, it contains graph constructing, pruning, and path-level ranking, which not only retrieves accurate answers but also provides inference paths that explain the reasoning process. To comprehensively evaluate our model, we reformulate the benchmark dataset OK-VQA with manually corrected entity-level annotations and release it as ConceptVQA. Extensive experiments on real-world questions demonstrate that our framework is not only able to perform open-set question answering across the whole knowledge base but provide explicit reasoning path.
Open-source Pulseq sequences on Philips MRI scanners
Oct 10, 2023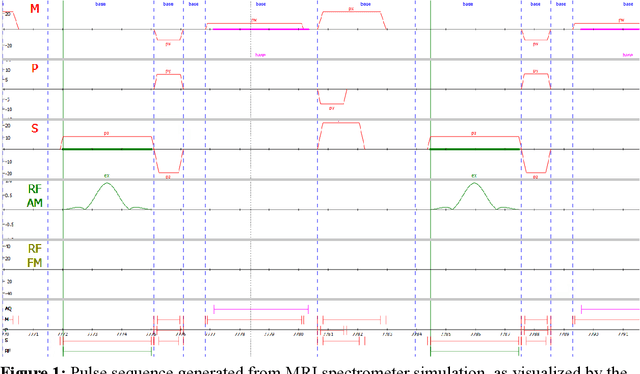

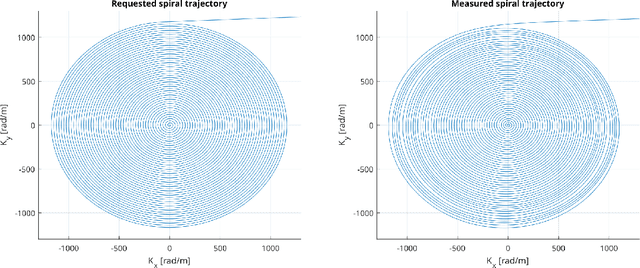
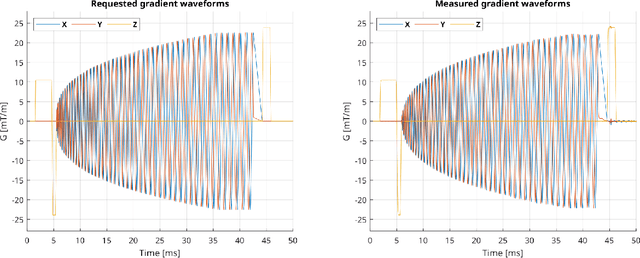
Purpose: This work aims to address the limitations faced by researchers in developing and sharing new MRI sequences by implementing an interpreter for the open-source MRI pulse sequence format, Pulseq, on a Philips MRI scanner. Methods: The implementation involved modifying a few source code files to create a Pulseq interpreter for the Philips MRI system. Validation experiments were conducted using simulations and phantom scans performed on a 7T Achieva MRI system. The observed sequence and waveforms were compared to the intended ones, and the gradient waveforms produced by the scanner were verified using a field camera. Image reconstruction was performed using the raw k-space samples acquired from both the native vendor environment and the Pulseq interpreter. Results: The reconstructed images obtained through the Pulseq implementation were found to be comparable to those obtained through the native implementation. The performance of the Pulseq interpreter was assessed by profiling the CPU utilization of the MRI spectrometer, showing minimal resource utilization for certain sequences. Conclusion: The successful implementation of the Pulseq interpreter on the Philips MRI scanner demonstrates the feasibility of utilizing Pulseq sequences on Philips MRI scanners. This provides an open-source platform for MRI sequence development, facilitating collaboration among researchers and accelerating scientific progress in the field of MRI.
EViT: An Eagle Vision Transformer with Bi-Fovea Self-Attention
Oct 10, 2023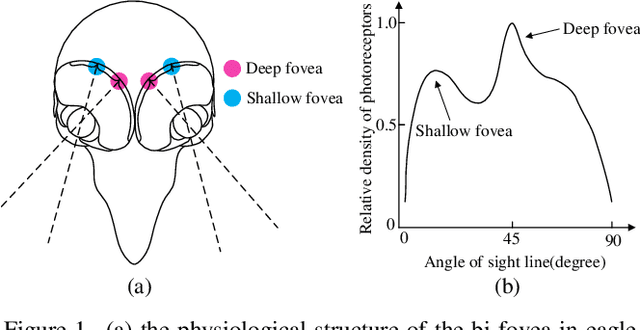
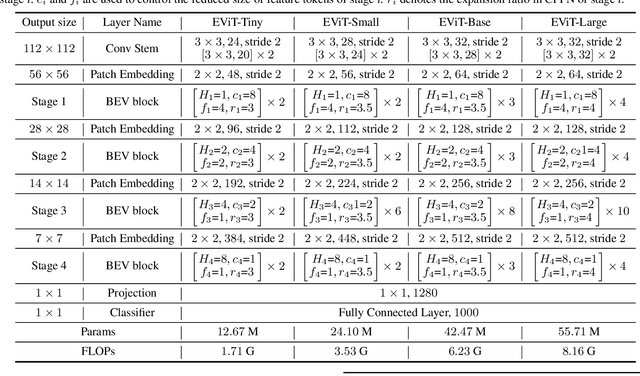
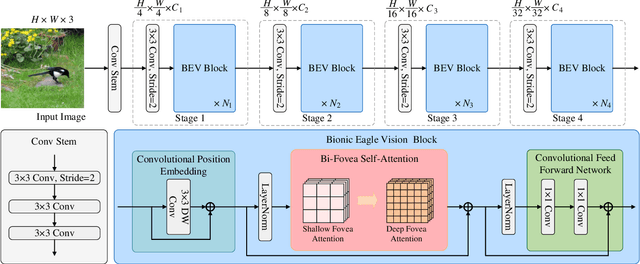
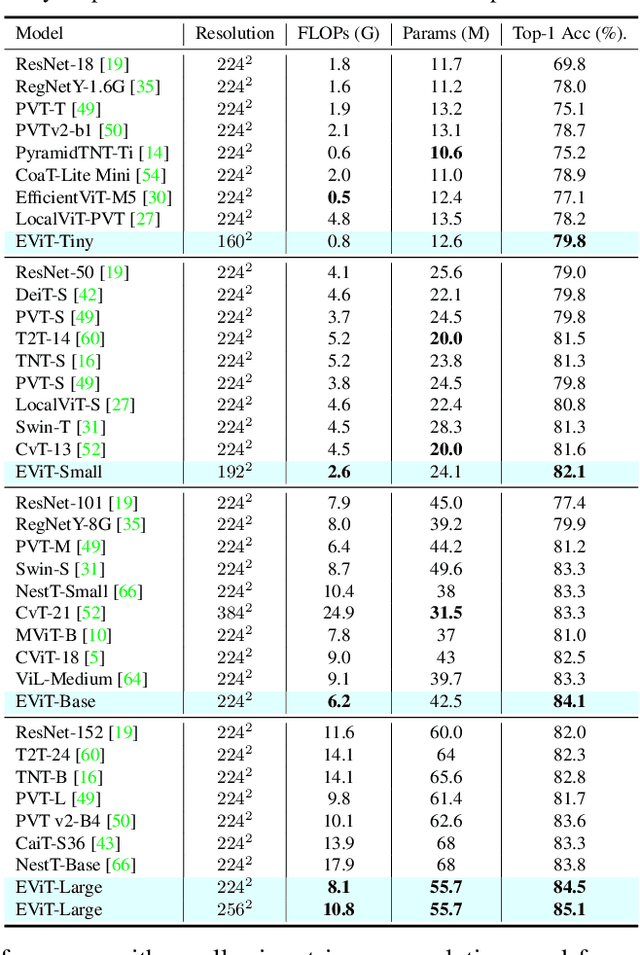
Because of the advancement of deep learning technology, vision transformer has demonstrated competitive performance in various computer vision tasks. Unfortunately, vision transformer still faces some challenges such as high computational complexity and absence of desirable inductive bias. To alleviate these problems, this study proposes a novel Bi-Fovea Self-Attention (BFSA) inspired by the physiological structure and characteristics of bi-fovea vision in eagle eyes. This BFSA can simulate the shallow fovea and deep fovea functions of eagle vision, enabling the network to extract feature representations of targets from coarse to fine, facilitating the interaction of multi-scale feature representations. Additionally, this study designs a Bionic Eagle Vision (BEV) block based on BFSA and CNN. It combines CNN and Vision Transformer, to enhance the network's local and global representation ability for targets. Furthermore, this study develops a unified and efficient general pyramid backbone network family, named Eagle Vision Transformers (EViTs) by stacking the BEV blocks. Experimental results on various computer vision tasks including image classification, object detection, instance segmentation and other transfer learning tasks show that the proposed EViTs perform significantly better than the baselines under similar model sizes, which exhibits faster speed on graphics processing unit compared to other models. Code will be released at https://github.com/nkusyl.
Efficient Annotation for Medical Image Analysis: A One-Pass Selective Annotation Approach
Aug 25, 2023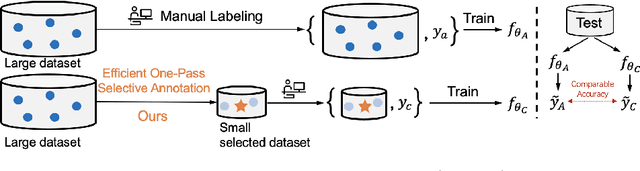
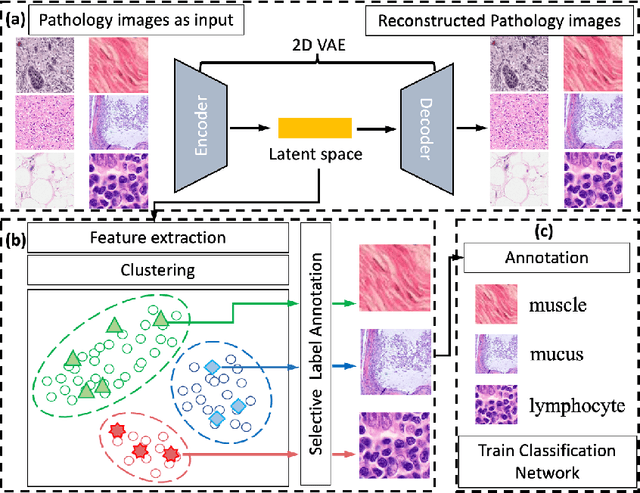
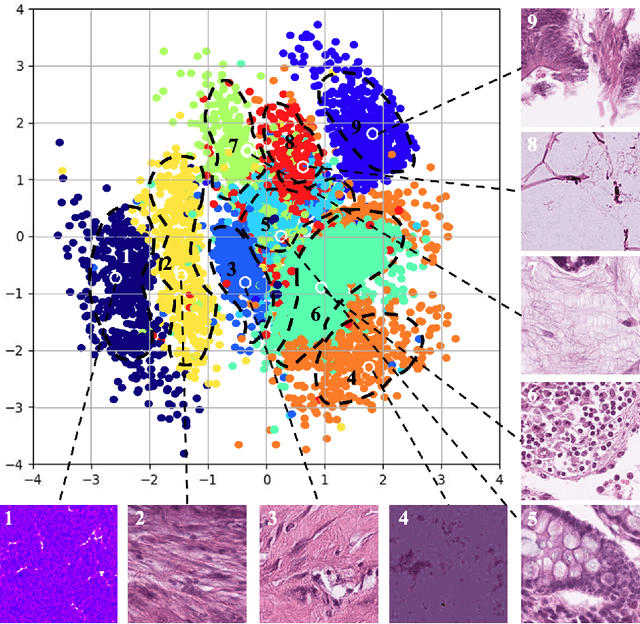
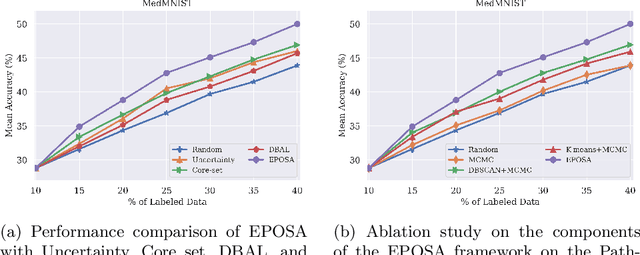
Annotating biomedical images for supervised learning is a complex and labor-intensive task due to data diversity and its intricate nature. In this paper, we propose an innovative method, the efficient one-pass selective annotation (EPOSA), that significantly reduces the annotation burden while maintaining robust model performance. Our approach employs a variational autoencoder (VAE) to extract salient features from unannotated images, which are subsequently clustered using the DBSCAN algorithm. This process groups similar images together, forming distinct clusters. We then use a two-stage sample selection algorithm, called representative selection (RepSel), to form a selected dataset. The first stage is a Markov Chain Monte Carlo (MCMC) sampling technique to select representative samples from each cluster for annotations. This selection process is the second stage, which is guided by the principle of maximizing intra-cluster mutual information and minimizing inter-cluster mutual information. This ensures a diverse set of features for model training and minimizes outlier inclusion. The selected samples are used to train a VGG-16 network for image classification. Experimental results on the Med-MNIST dataset demonstrate that our proposed EPOSA outperforms random selection and other state-of-the-art methods under the same annotation budget, presenting a promising direction for efficient and effective annotation in medical image analysis.