 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Jointly Training Large Autoregressive Multimodal Models
Sep 28, 2023
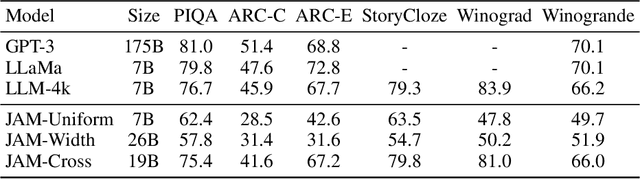
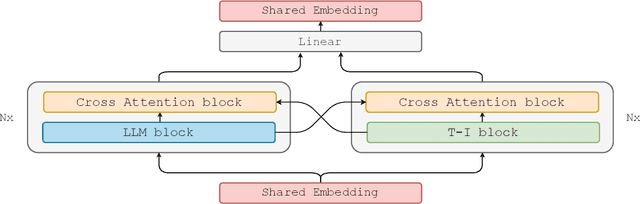
In recent years, advances in the large-scale pretraining of language and text-to-image models have revolutionized the field of machine learning. Yet, integrating these two modalities into a single, robust model capable of generating seamless multimodal outputs remains a significant challenge. To address this gap, we present the Joint Autoregressive Mixture (JAM) framework, a modular approach that systematically fuses existing text and image generation models. We also introduce a specialized, data-efficient instruction-tuning strategy, tailored for mixed-modal generation tasks. Our final instruct-tuned model demonstrates unparalleled performance in generating high-quality multimodal outputs and represents the first model explicitly designed for this purpose.
Self-Reference Deep Adaptive Curve Estimation for Low-Light Image Enhancement
Aug 16, 2023
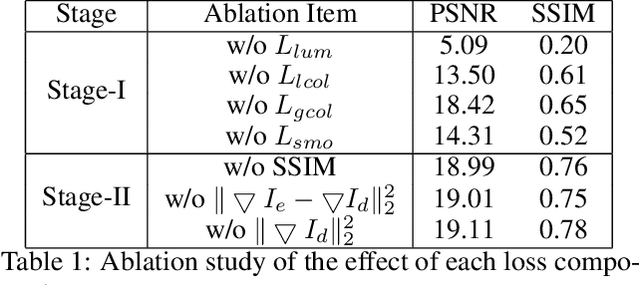
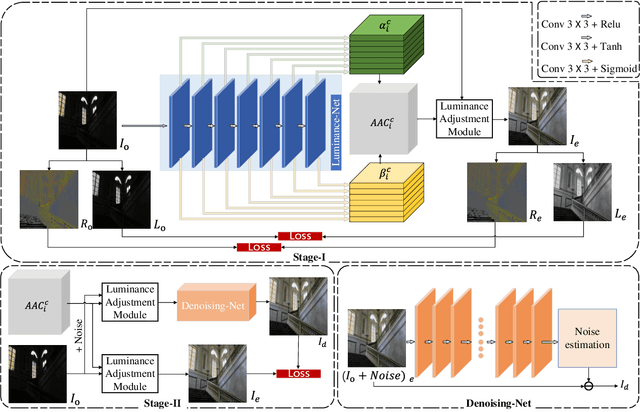
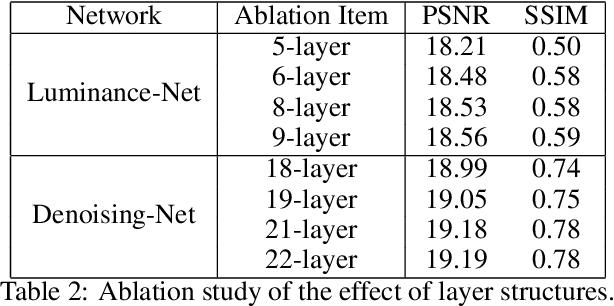
In this paper, we propose a 2-stage low-light image enhancement method called Self-Reference Deep Adaptive Curve Estimation (Self-DACE). In the first stage, we present an intuitive, lightweight, fast, and unsupervised luminance enhancement algorithm. The algorithm is based on a novel low-light enhancement curve that can be used to locally boost image brightness. We also propose a new loss function with a simplified physical model designed to preserve natural images' color, structure, and fidelity. We use a vanilla CNN to map each pixel through deep Adaptive Adjustment Curves (AAC) while preserving the local image structure. Secondly, we introduce the corresponding denoising scheme to remove the latent noise in the darkness. We approximately model the noise in the dark and deploy a Denoising-Net to estimate and remove the noise after the first stage. Exhaustive qualitative and quantitative analysis shows that our method outperforms existing state-of-the-art algorithms on multiple real-world datasets.
Geometry-Guided Ray Augmentation for Neural Surface Reconstruction with Sparse Views
Oct 09, 2023
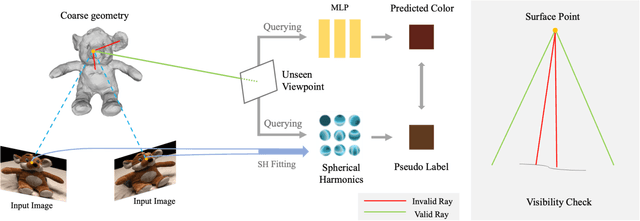
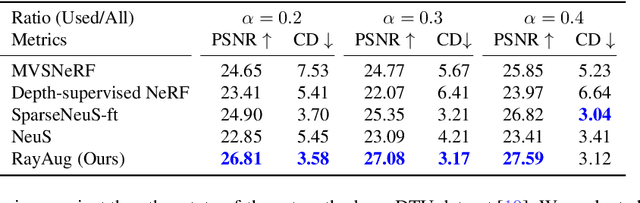

In this paper, we propose a novel method for 3D scene and object reconstruction from sparse multi-view images. Different from previous methods that leverage extra information such as depth or generalizable features across scenes, our approach leverages the scene properties embedded in the multi-view inputs to create precise pseudo-labels for optimization without any prior training. Specifically, we introduce a geometry-guided approach that improves surface reconstruction accuracy from sparse views by leveraging spherical harmonics to predict the novel radiance while holistically considering all color observations for a point in the scene. Also, our pipeline exploits proxy geometry and correctly handles the occlusion in generating the pseudo-labels of radiance, which previous image-warping methods fail to avoid. Our method, dubbed Ray Augmentation (RayAug), achieves superior results on DTU and Blender datasets without requiring prior training, demonstrating its effectiveness in addressing the problem of sparse view reconstruction. Our pipeline is flexible and can be integrated into other implicit neural reconstruction methods for sparse views.
Learning Layer-wise Equivariances Automatically using Gradients
Oct 09, 2023

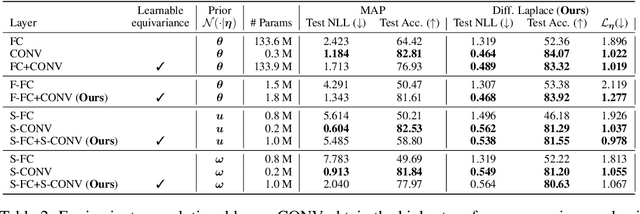

Convolutions encode equivariance symmetries into neural networks leading to better generalisation performance. However, symmetries provide fixed hard constraints on the functions a network can represent, need to be specified in advance, and can not be adapted. Our goal is to allow flexible symmetry constraints that can automatically be learned from data using gradients. Learning symmetry and associated weight connectivity structures from scratch is difficult for two reasons. First, it requires efficient and flexible parameterisations of layer-wise equivariances. Secondly, symmetries act as constraints and are therefore not encouraged by training losses measuring data fit. To overcome these challenges, we improve parameterisations of soft equivariance and learn the amount of equivariance in layers by optimising the marginal likelihood, estimated using differentiable Laplace approximations. The objective balances data fit and model complexity enabling layer-wise symmetry discovery in deep networks. We demonstrate the ability to automatically learn layer-wise equivariances on image classification tasks, achieving equivalent or improved performance over baselines with hard-coded symmetry.
Detecting Abnormal Health Conditions in Smart Home Using a Drone
Oct 08, 2023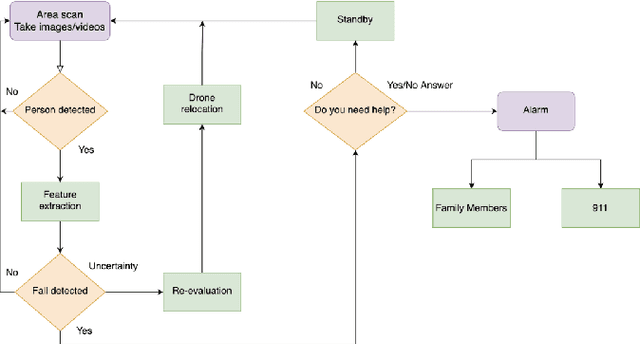


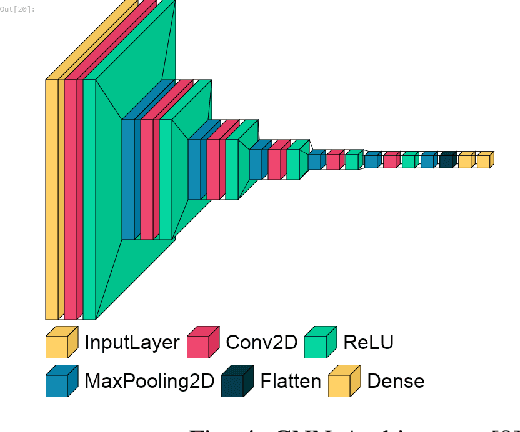
Nowadays, detecting aberrant health issues is a difficult process. Falling, especially among the elderly, is a severe concern worldwide. Falls can result in deadly consequences, including unconsciousness, internal bleeding, and often times, death. A practical and optimal, smart approach of detecting falling is currently a concern. The use of vision-based fall monitoring is becoming more common among scientists as it enables senior citizens and those with other health conditions to live independently. For tracking, surveillance, and rescue, unmanned aerial vehicles use video or image segmentation and object detection methods. The Tello drone is equipped with a camera and with this device we determined normal and abnormal behaviors among our participants. The autonomous falling objects are classified using a convolutional neural network (CNN) classifier. The results demonstrate that the systems can identify falling objects with a precision of 0.9948.
Neural Sampling in Hierarchical Exponential-family Energy-based Models
Oct 12, 2023Bayesian brain theory suggests that the brain employs generative models to understand the external world. The sampling-based perspective posits that the brain infers the posterior distribution through samples of stochastic neuronal responses. Additionally, the brain continually updates its generative model to approach the true distribution of the external world. In this study, we introduce the Hierarchical Exponential-family Energy-based (HEE) model, which captures the dynamics of inference and learning. In the HEE model, we decompose the partition function into individual layers and leverage a group of neurons with shorter time constants to sample the gradient of the decomposed normalization term. This allows our model to estimate the partition function and perform inference simultaneously, circumventing the negative phase encountered in conventional energy-based models (EBMs). As a result, the learning process is localized both in time and space, and the model is easy to converge. To match the brain's rapid computation, we demonstrate that neural adaptation can serve as a momentum term, significantly accelerating the inference process. On natural image datasets, our model exhibits representations akin to those observed in the biological visual system. Furthermore, for the machine learning community, our model can generate observations through joint or marginal generation. We show that marginal generation outperforms joint generation and achieves performance on par with other EBMs.
Reset It and Forget It: Relearning Last-Layer Weights Improves Continual and Transfer Learning
Oct 12, 2023
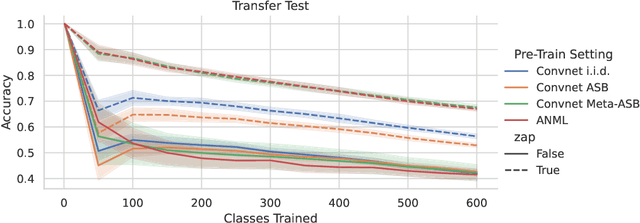

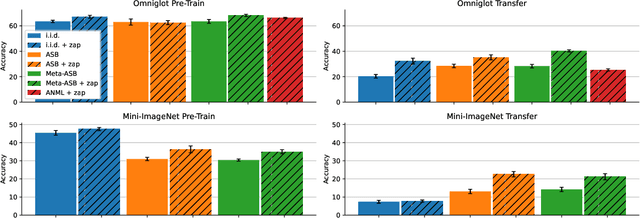
This work identifies a simple pre-training mechanism that leads to representations exhibiting better continual and transfer learning. This mechanism -- the repeated resetting of weights in the last layer, which we nickname "zapping" -- was originally designed for a meta-continual-learning procedure, yet we show it is surprisingly applicable in many settings beyond both meta-learning and continual learning. In our experiments, we wish to transfer a pre-trained image classifier to a new set of classes, in a few shots. We show that our zapping procedure results in improved transfer accuracy and/or more rapid adaptation in both standard fine-tuning and continual learning settings, while being simple to implement and computationally efficient. In many cases, we achieve performance on par with state of the art meta-learning without needing the expensive higher-order gradients, by using a combination of zapping and sequential learning. An intuitive explanation for the effectiveness of this zapping procedure is that representations trained with repeated zapping learn features that are capable of rapidly adapting to newly initialized classifiers. Such an approach may be considered a computationally cheaper type of, or alternative to, meta-learning rapidly adaptable features with higher-order gradients. This adds to recent work on the usefulness of resetting neural network parameters during training, and invites further investigation of this mechanism.
Learning from Label Proportions: Bootstrapping Supervised Learners via Belief Propagation
Oct 12, 2023Learning from Label Proportions (LLP) is a learning problem where only aggregate level labels are available for groups of instances, called bags, during training, and the aim is to get the best performance at the instance-level on the test data. This setting arises in domains like advertising and medicine due to privacy considerations. We propose a novel algorithmic framework for this problem that iteratively performs two main steps. For the first step (Pseudo Labeling) in every iteration, we define a Gibbs distribution over binary instance labels that incorporates a) covariate information through the constraint that instances with similar covariates should have similar labels and b) the bag level aggregated label. We then use Belief Propagation (BP) to marginalize the Gibbs distribution to obtain pseudo labels. In the second step (Embedding Refinement), we use the pseudo labels to provide supervision for a learner that yields a better embedding. Further, we iterate on the two steps again by using the second step's embeddings as new covariates for the next iteration. In the final iteration, a classifier is trained using the pseudo labels. Our algorithm displays strong gains against several SOTA baselines (up to 15%) for the LLP Binary Classification problem on various dataset types - tabular and Image. We achieve these improvements with minimal computational overhead above standard supervised learning due to Belief Propagation, for large bag sizes, even for a million samples.
Self-Supervised High Dynamic Range Imaging with Multi-Exposure Images in Dynamic Scenes
Oct 03, 2023
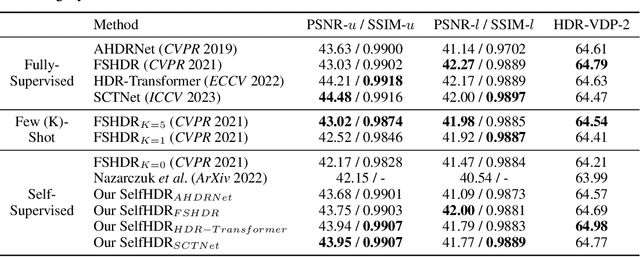
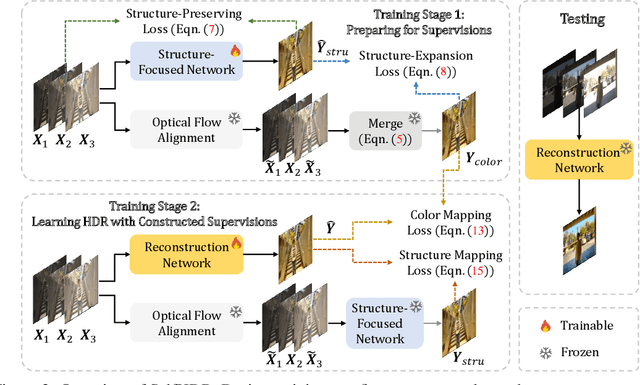

Merging multi-exposure images is a common approach for obtaining high dynamic range (HDR) images, with the primary challenge being the avoidance of ghosting artifacts in dynamic scenes. Recent methods have proposed using deep neural networks for deghosting. However, the methods typically rely on sufficient data with HDR ground-truths, which are difficult and costly to collect. In this work, to eliminate the need for labeled data, we propose SelfHDR, a self-supervised HDR reconstruction method that only requires dynamic multi-exposure images during training. Specifically, SelfHDR learns a reconstruction network under the supervision of two complementary components, which can be constructed from multi-exposure images and focus on HDR color as well as structure, respectively. The color component is estimated from aligned multi-exposure images, while the structure one is generated through a structure-focused network that is supervised by the color component and an input reference (\eg, medium-exposure) image. During testing, the learned reconstruction network is directly deployed to predict an HDR image. Experiments on real-world images demonstrate our SelfHDR achieves superior results against the state-of-the-art self-supervised methods, and comparable performance to supervised ones. Codes are available at https://github.com/cszhilu1998/SelfHDR
Augmenting medical image classifiers with synthetic data from latent diffusion models
Aug 23, 2023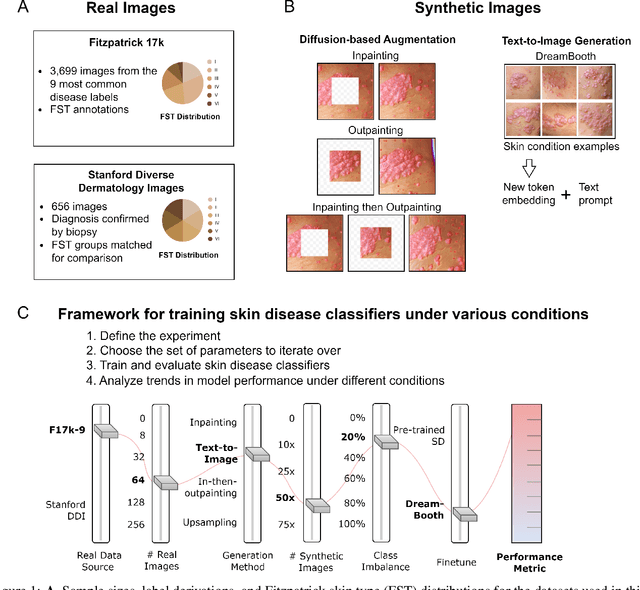
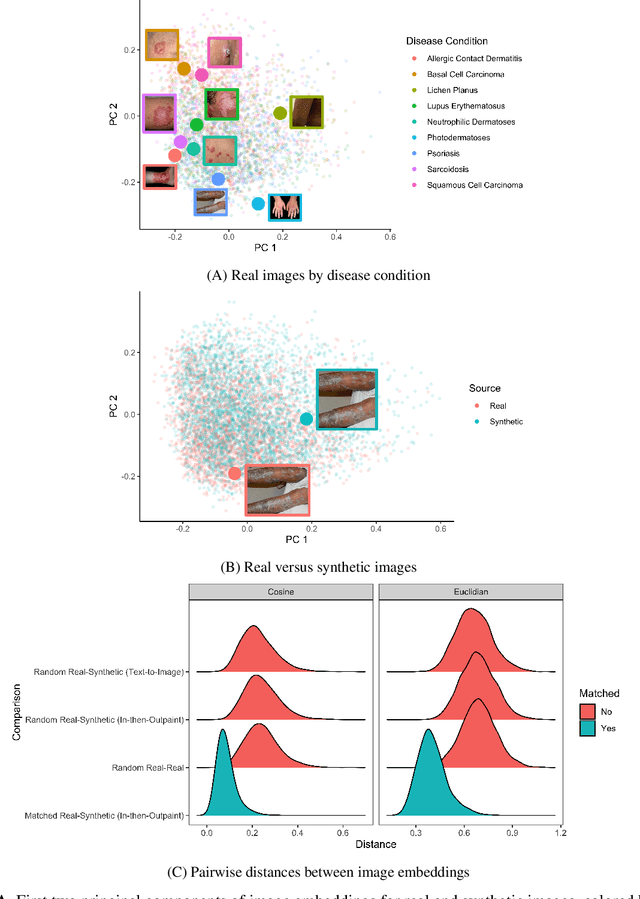
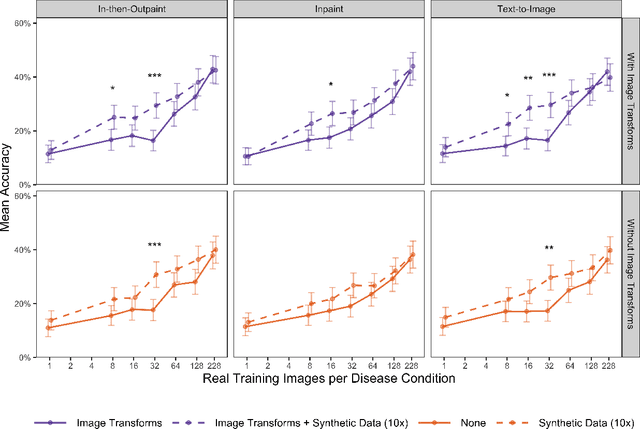

While hundreds of artificial intelligence (AI) algorithms are now approved or cleared by the US Food and Drugs Administration (FDA), many studies have shown inconsistent generalization or latent bias, particularly for underrepresented populations. Some have proposed that generative AI could reduce the need for real data, but its utility in model development remains unclear. Skin disease serves as a useful case study in synthetic image generation due to the diversity of disease appearance, particularly across the protected attribute of skin tone. Here we show that latent diffusion models can scalably generate images of skin disease and that augmenting model training with these data improves performance in data-limited settings. These performance gains saturate at synthetic-to-real image ratios above 10:1 and are substantially smaller than the gains obtained from adding real images. As part of our analysis, we generate and analyze a new dataset of 458,920 synthetic images produced using several generation strategies. Our results suggest that synthetic data could serve as a force-multiplier for model development, but the collection of diverse real-world data remains the most important step to improve medical AI algorithms.