 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Video-Teller: Enhancing Cross-Modal Generation with Fusion and Decoupling
Oct 11, 2023
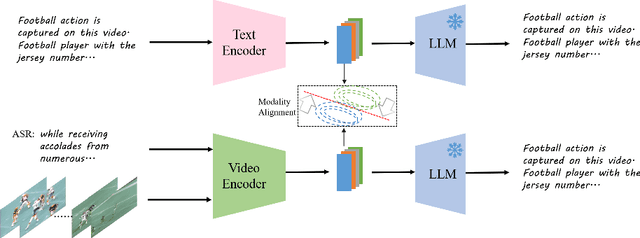
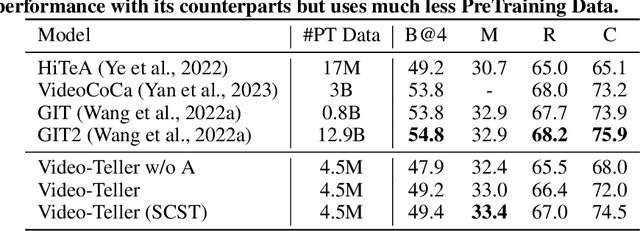
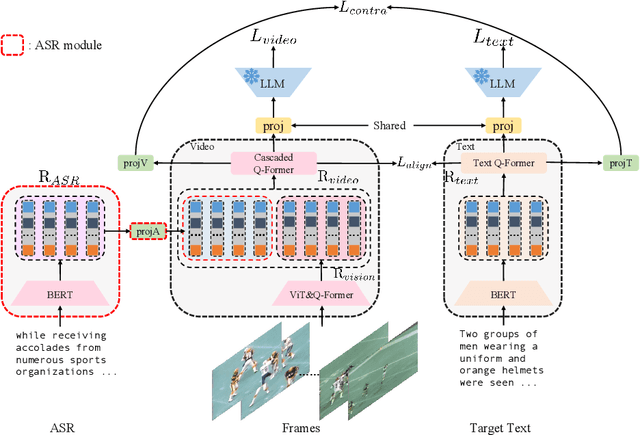

This paper proposes Video-Teller, a video-language foundation model that leverages multi-modal fusion and fine-grained modality alignment to significantly enhance the video-to-text generation task. Video-Teller boosts the training efficiency by utilizing frozen pretrained vision and language modules. It capitalizes on the robust linguistic capabilities of large language models, enabling the generation of both concise and elaborate video descriptions. To effectively integrate visual and auditory information, Video-Teller builds upon the image-based BLIP-2 model and introduces a cascaded Q-Former which fuses information across frames and ASR texts. To better guide video summarization, we introduce a fine-grained modality alignment objective, where the cascaded Q-Former's output embedding is trained to align with the caption/summary embedding created by a pretrained text auto-encoder. Experimental results demonstrate the efficacy of our proposed video-language foundation model in accurately comprehending videos and generating coherent and precise language descriptions. It is worth noting that the fine-grained alignment enhances the model's capabilities (4% improvement of CIDEr score on MSR-VTT) with only 13% extra parameters in training and zero additional cost in inference.
Under-Display Camera Image Restoration with Scattering Effect
Aug 08, 2023
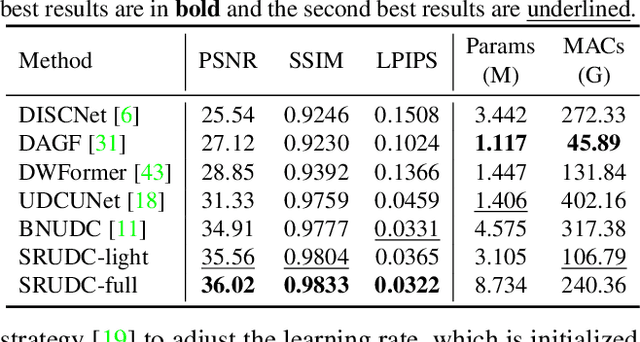
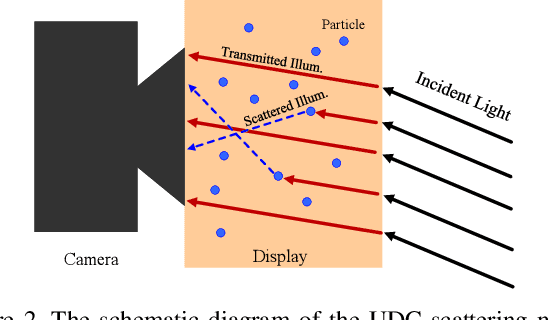
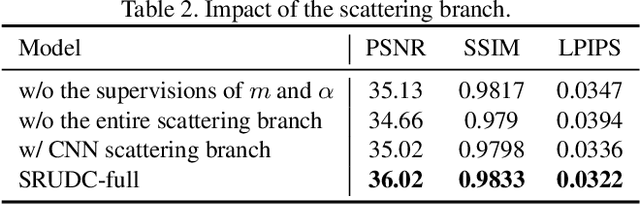
The under-display camera (UDC) provides consumers with a full-screen visual experience without any obstruction due to notches or punched holes. However, the semi-transparent nature of the display inevitably introduces the severe degradation into UDC images. In this work, we address the UDC image restoration problem with the specific consideration of the scattering effect caused by the display. We explicitly model the scattering effect by treating the display as a piece of homogeneous scattering medium. With the physical model of the scattering effect, we improve the image formation pipeline for the image synthesis to construct a realistic UDC dataset with ground truths. To suppress the scattering effect for the eventual UDC image recovery, a two-branch restoration network is designed. More specifically, the scattering branch leverages global modeling capabilities of the channel-wise self-attention to estimate parameters of the scattering effect from degraded images. While the image branch exploits the local representation advantage of CNN to recover clear scenes, implicitly guided by the scattering branch. Extensive experiments are conducted on both real-world and synthesized data, demonstrating the superiority of the proposed method over the state-of-the-art UDC restoration techniques. The source code and dataset are available at \url{https://github.com/NamecantbeNULL/SRUDC}.
The Role of Linguistic Priors in Measuring Compositional Generalization of Vision-Language Models
Oct 04, 2023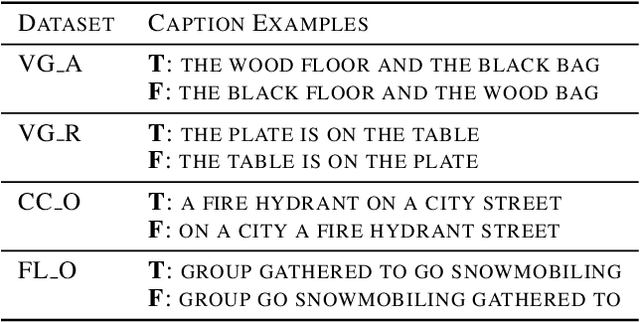
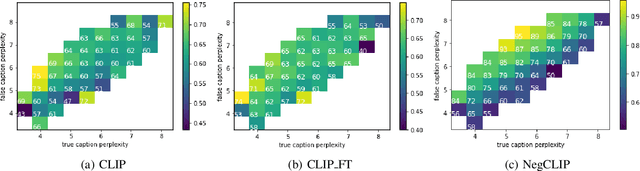
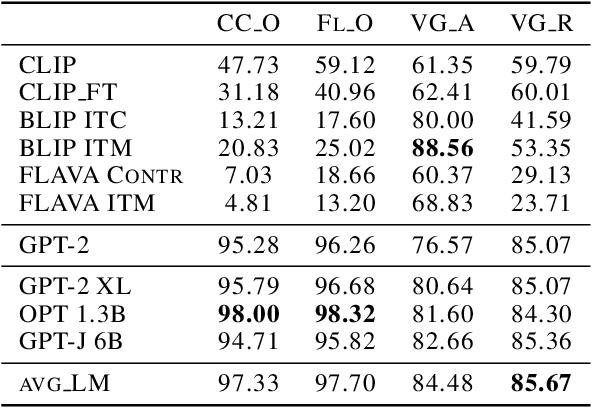
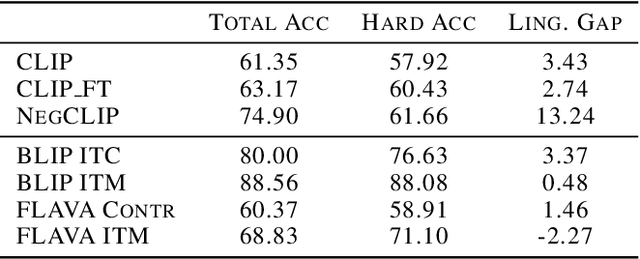
Compositionality is a common property in many modalities including natural languages and images, but the compositional generalization of multi-modal models is not well-understood. In this paper, we identify two sources of visual-linguistic compositionality: linguistic priors and the interplay between images and texts. We show that current attempts to improve compositional generalization rely on linguistic priors rather than on information in the image. We also propose a new metric for compositionality without such linguistic priors.
SatDM: Synthesizing Realistic Satellite Image with Semantic Layout Conditioning using Diffusion Models
Sep 28, 2023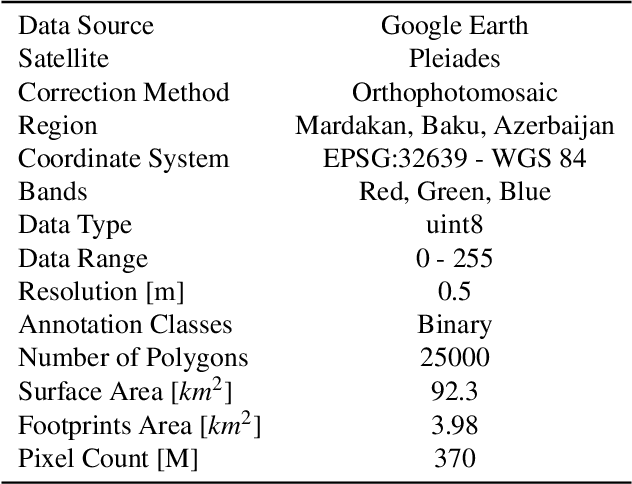
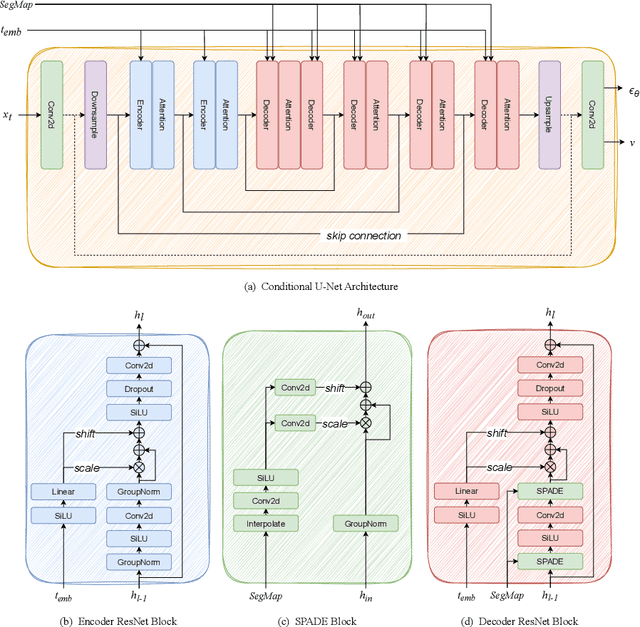
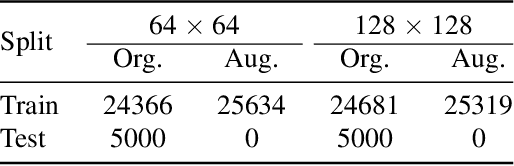
Deep learning models in the Earth Observation domain heavily rely on the availability of large-scale accurately labeled satellite imagery. However, obtaining and labeling satellite imagery is a resource-intensive endeavor. While generative models offer a promising solution to address data scarcity, their potential remains underexplored. Recently, Denoising Diffusion Probabilistic Models (DDPMs) have demonstrated significant promise in synthesizing realistic images from semantic layouts. In this paper, a conditional DDPM model capable of taking a semantic map and generating high-quality, diverse, and correspondingly accurate satellite images is implemented. Additionally, a comprehensive illustration of the optimization dynamics is provided. The proposed methodology integrates cutting-edge techniques such as variance learning, classifier-free guidance, and improved noise scheduling. The denoising network architecture is further complemented by the incorporation of adaptive normalization and self-attention mechanisms, enhancing the model's capabilities. The effectiveness of our proposed model is validated using a meticulously labeled dataset introduced within the context of this study. Validation encompasses both algorithmic methods such as Frechet Inception Distance (FID) and Intersection over Union (IoU), as well as a human opinion study. Our findings indicate that the generated samples exhibit minimal deviation from real ones, opening doors for practical applications such as data augmentation. We look forward to further explorations of DDPMs in a wider variety of settings and data modalities. An open-source reference implementation of the algorithm and a link to the benchmarked dataset are provided at https://github.com/obaghirli/syn10-diffusion.
Generating 3D Brain Tumor Regions in MRI using Vector-Quantization Generative Adversarial Networks
Oct 02, 2023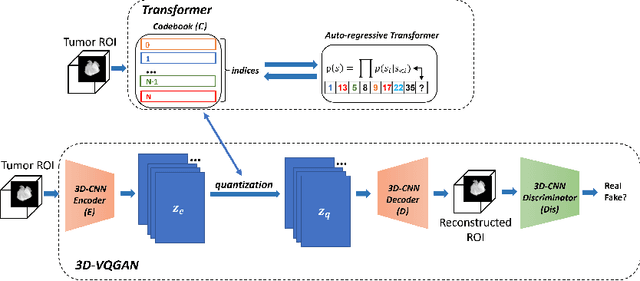
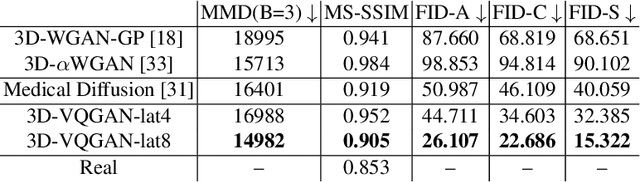
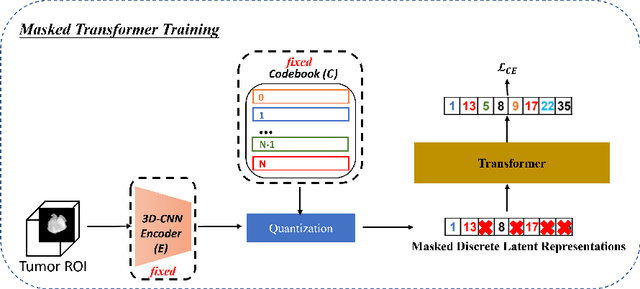
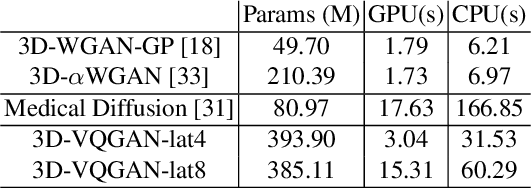
Medical image analysis has significantly benefited from advancements in deep learning, particularly in the application of Generative Adversarial Networks (GANs) for generating realistic and diverse images that can augment training datasets. However, the effectiveness of such approaches is often limited by the amount of available data in clinical settings. Additionally, the common GAN-based approach is to generate entire image volumes, rather than solely the region of interest (ROI). Research on deep learning-based brain tumor classification using MRI has shown that it is easier to classify the tumor ROIs compared to the entire image volumes. In this work, we present a novel framework that uses vector-quantization GAN and a transformer incorporating masked token modeling to generate high-resolution and diverse 3D brain tumor ROIs that can be directly used as augmented data for the classification of brain tumor ROI. We apply our method to two imbalanced datasets where we augment the minority class: (1) the Multimodal Brain Tumor Segmentation Challenge (BraTS) 2019 dataset to generate new low-grade glioma (LGG) ROIs to balance with high-grade glioma (HGG) class; (2) the internal pediatric LGG (pLGG) dataset tumor ROIs with BRAF V600E Mutation genetic marker to balance with BRAF Fusion genetic marker class. We show that the proposed method outperforms various baseline models in both qualitative and quantitative measurements. The generated data was used to balance the data in the brain tumor types classification task. Using the augmented data, our approach surpasses baseline models by 6.4% in AUC on the BraTS 2019 dataset and 4.3% in AUC on our internal pLGG dataset. The results indicate the generated tumor ROIs can effectively address the imbalanced data problem. Our proposed method has the potential to facilitate an accurate diagnosis of rare brain tumors using MRI scans.
NoSENSE: Learned unrolled cardiac MRI reconstruction without explicit sensitivity maps
Sep 27, 2023We present a novel learned image reconstruction method for accelerated cardiac MRI with multiple receiver coils based on deep convolutional neural networks (CNNs) and algorithm unrolling. In contrast to many existing learned MR image reconstruction techniques that necessitate coil-sensitivity map (CSM) estimation as a distinct network component, our proposed approach avoids explicit CSM estimation. Instead, it implicitly captures and learns to exploit the inter-coil relationships of the images. Our method consists of a series of novel learned image and k-space blocks with shared latent information and adaptation to the acquisition parameters by feature-wise modulation (FiLM), as well as coil-wise data-consistency (DC) blocks. Our method achieved PSNR values of 34.89 and 35.56 and SSIM values of 0.920 and 0.942 in the cine track and mapping track validation leaderboard of the MICCAI STACOM CMRxRecon Challenge, respectively, ranking 4th among different teams at the time of writing. Code will be made available at https://github.com/fzimmermann89/CMRxRecon
Evaluating Explanation Methods for Vision-and-Language Navigation
Oct 10, 2023The ability to navigate robots with natural language instructions in an unknown environment is a crucial step for achieving embodied artificial intelligence (AI). With the improving performance of deep neural models proposed in the field of vision-and-language navigation (VLN), it is equally interesting to know what information the models utilize for their decision-making in the navigation tasks. To understand the inner workings of deep neural models, various explanation methods have been developed for promoting explainable AI (XAI). But they are mostly applied to deep neural models for image or text classification tasks and little work has been done in explaining deep neural models for VLN tasks. In this paper, we address these problems by building quantitative benchmarks to evaluate explanation methods for VLN models in terms of faithfulness. We propose a new erasure-based evaluation pipeline to measure the step-wise textual explanation in the sequential decision-making setting. We evaluate several explanation methods for two representative VLN models on two popular VLN datasets and reveal valuable findings through our experiments.
Blind Dates: Examining the Expression of Temporality in Historical Photographs
Oct 10, 2023This paper explores the capacity of computer vision models to discern temporal information in visual content, focusing specifically on historical photographs. We investigate the dating of images using OpenCLIP, an open-source implementation of CLIP, a multi-modal language and vision model. Our experiment consists of three steps: zero-shot classification, fine-tuning, and analysis of visual content. We use the \textit{De Boer Scene Detection} dataset, containing 39,866 gray-scale historical press photographs from 1950 to 1999. The results show that zero-shot classification is relatively ineffective for image dating, with a bias towards predicting dates in the past. Fine-tuning OpenCLIP with a logistic classifier improves performance and eliminates the bias. Additionally, our analysis reveals that images featuring buses, cars, cats, dogs, and people are more accurately dated, suggesting the presence of temporal markers. The study highlights the potential of machine learning models like OpenCLIP in dating images and emphasizes the importance of fine-tuning for accurate temporal analysis. Future research should explore the application of these findings to color photographs and diverse datasets.
Hierarchical Mask2Former: Panoptic Segmentation of Crops, Weeds and Leaves
Oct 10, 2023
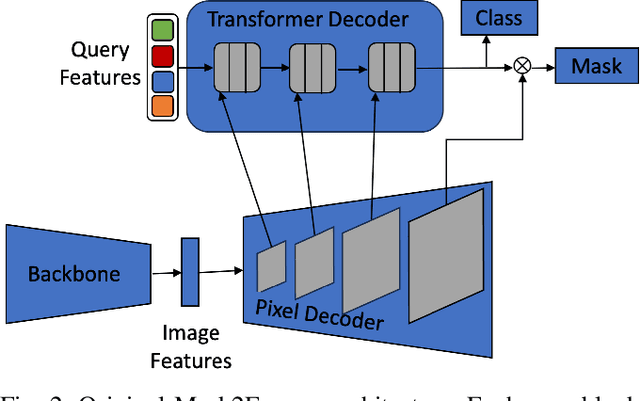
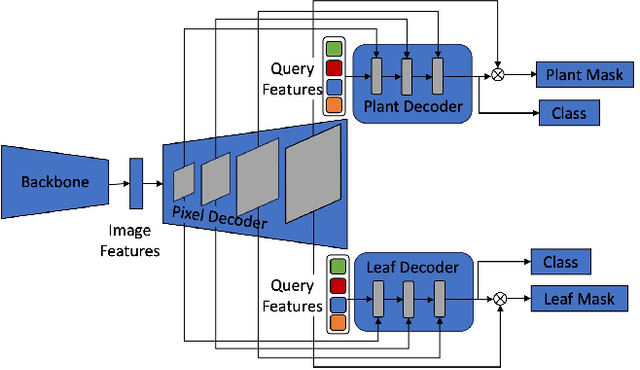
Advancements in machine vision that enable detailed inferences to be made from images have the potential to transform many sectors including agriculture. Precision agriculture, where data analysis enables interventions to be precisely targeted, has many possible applications. Precision spraying, for example, can limit the application of herbicide only to weeds, or limit the application of fertiliser only to undernourished crops, instead of spraying the entire field. The approach promises to maximise yields, whilst minimising resource use and harms to the surrounding environment. To this end, we propose a hierarchical panoptic segmentation method to simultaneously identify indicators of plant growth and locate weeds within an image. We adapt Mask2Former, a state-of-the-art architecture for panoptic segmentation, to predict crop, weed and leaf masks. We achieve a PQ{\dag} of 75.99. Additionally, we explore approaches to make the architecture more compact and therefore more suitable for time and compute constrained applications. With our more compact architecture, inference is up to 60% faster and the reduction in PQ{\dag} is less than 1%.
Compression Ratio Learning and Semantic Communications for Video Imaging
Oct 10, 2023
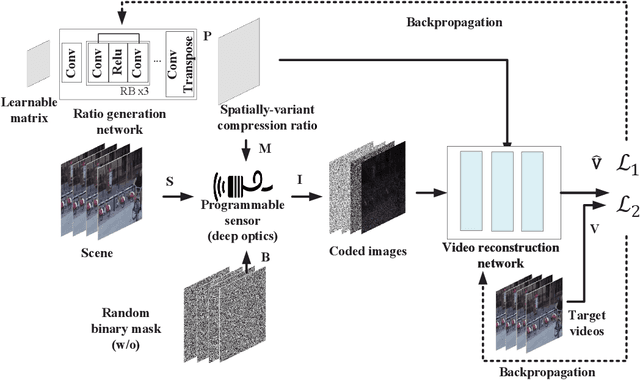
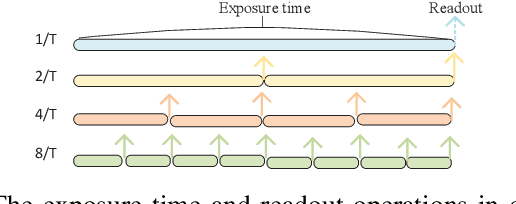
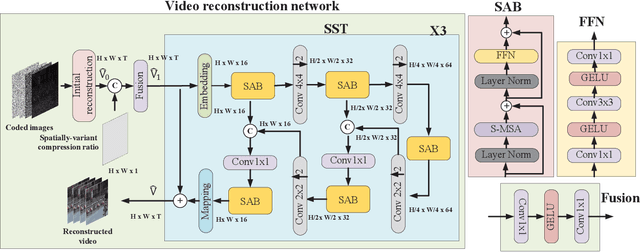
Camera sensors have been widely used in intelligent robotic systems. Developing camera sensors with high sensing efficiency has always been important to reduce the power, memory, and other related resources. Inspired by recent success on programmable sensors and deep optic methods, we design a novel video compressed sensing system with spatially-variant compression ratios, which achieves higher imaging quality than the existing snapshot compressed imaging methods with the same sensing costs. In this article, we also investigate the data transmission methods for programmable sensors, where the performance of communication systems is evaluated by the reconstructed images or videos rather than the transmission of sensor data itself. Usually, different reconstruction algorithms are designed for applications in high dynamic range imaging, video compressive sensing, or motion debluring. This task-aware property inspires a semantic communication framework for programmable sensors. In this work, a policy-gradient based reinforcement learning method is introduced to achieve the explicit trade-off between the compression (or transmission) rate and the image distortion. Numerical results show the superiority of the proposed methods over existing baselines.